
算法竞赛题目推荐系统的设计与实现
2022-02-20 01:25刘昕宇徐柔聂盼红郑金龙
电脑知识与技术 2022年34期
关键词:推荐系统
刘昕宇 徐柔 聂盼红 郑金龙


摘要:文章基于本地在线评测系统和第三方在线评测系统的大量的评测数据,利用基于用户的协同过滤算法,设计和实现了竞赛题目的推荐模块,并将其引入在开源HOJ在线评测平台。该模块通过推荐算法给本地的系统用户推荐合适的算法竞赛题目,提高算法竞赛训练的针对性和效率。
关键词:协同过滤算法;HOJ;在线评测;算法竞赛;推荐系统
中图分类号:TP391 文献标识码:A
文章编号:1009-3044(2022)34-0054-03
1 引言
随着“互聯网+教育”模式的快速发展,以程序在线评测技术为基础而构建的在线编程学习平台在计算机教育领域得到了广泛的应用。目前,很多高校和教育机构根据自己的实际需求开发了各自的在线评测系统,如国内外的比较著名的ACM训练平台HDUOJ、ZOJ、POJ、Codeforces、UVA、TopCoder、AtCoder等,还有牛客、PTA、希冀等在线编程学习平台。其目的主要有两个:一个是基于在线评测系统开展程序设计类课程的日常实践教学,另一个是促进程序设计类竞赛的组织和训练。同时,为了实现跨平台的题目共享和竞赛组织训练,VOJ(虚拟OJ) 也得到更加广泛的应用,而且部分OJ平台已经将虚拟评测技术引入系统,从而实现本地和远程评测功能。
本文在开源的在线评测系统HOJ(Hcode Online Judge)的基础上进行二次开发,通过设计网络爬虫对第三方平台的系统中本校ACM集训队学生的评测记录进行收集整理,获取用户过题情况。在此基础上利用协同过滤[1]算法对用户做题记录建模分析,构建竞赛题目推荐模型,由系统辅助用户选择合适的题目,从而提高训练效率。
2 系统概述
HOJ(Hcode Online Judge) [2]是基于前后端分离、分布式架构的在线评测系统,支持本地和第三方评测,本系统是在HOJ开源评测系统的基础上进行二次开发,在前台模块新增:推荐题目训练模块,动态显示系统推荐给用户的竞赛问题,用户可以在本模块选择推荐的题目进行训练;新增用户中心实现用户基本信息的维护和用户在第三方平台的个人账号管理,便于系统后台利用用户在第三方平台的账号进行数据爬取,收集用户在第三方平台上的做题记录;在系统后台新增:第三方平台个人账号管理、第三方平台数据的统一管理模块和第三方平台学生问题提交记录,数据爬虫和推荐模型参数的管理等。根据不同的第三方平台,开发爬虫程序,从第三方系统获取指定用户的做题记录。同时随机从第三方平台上爬取非本校用户的提交记录,优化和改进推荐程序的效果。图1为系统模块图,黑色粗线框为新增的功能模块,本文重点阐述推荐功能的实现。
3 推荐模块设计
在算法竞赛题目推荐方面,由于竞赛编程题目描述往往带有迷惑性,题目中经常有背景和引导用户思考到错误方向的关键词,所以关键词难以精准地描述题目,编程问题的相似需要研究思考难度相等或知识点相似,因此对于编程问题的个性化推荐,本文使用协同过滤推荐算法构建推荐模型。协同过滤分为基于用户的协同过滤和基于物品的协同过滤,对于竞赛问题来说,问题之间的相关性比较复杂,选择使用基于用户的协同过滤算法较为合适,因为用户之间的相似性表达了用户编程水平的相似性,编程水平相当的用户能通过的问题基本相同[3]。该算法主要出发点:做题记录相近的用户可能会对同样的题目感兴趣。
本系统的推荐模块的基本流程如下:
1) 构建用户-题目评分矩阵
2) 使用余弦相似性计算相似度
3) 基于阈值的邻居用户
随着时间的推移,系统中用户数量和编程问题数量都快速增加,将导致用户-题目评分矩阵维度变大,引发数据稀疏性问题将导致推荐的计算效率和推荐的准确度下降。同时系统中用户群体编程水平参差不齐,简单问题通过的人数多,难题通过的人数少。如果使用所有用户计算对未通过问题的评分,将会导致推荐结果对水平高的用户来说偏简单,对水平低的用户来说偏难。因此根据相似度阈值,取出和目标用户更为相近的用户。计算中用户之间的水平更加接近,计算出的评分也更为准确。
4) 预测推荐
推荐算法的最后一步,根据用户和邻居之间的相似度,计算对未通过问题的评分值,用户u对问题i的预测评分用式(3) 表示。最后,将用户所有未通过题目的评分值从大到小排序,取评分值最高的TOP-N个题目推荐给用户,完成编程问题个性化推荐过程。
4 推荐模块的实现
4.1 第三方平台账号管理
在程序在线评测系统上,每位学习者提交代码后可以得到代码的运行结果,包括答案正确,答案错误,运行超时,运行时错误等。评测系统中存储了题目信息、用户的提交信息和评测结果,这些数据为实现问题推荐提供了基础[6]。根据上文提出的基于用户协同过滤推荐模型,实现问题推荐功能。
为了自动爬取第三方平台上,本集训队学员的评测记录,系统维护了学员的第三方平台账号,并且允许学生自己修改维护。
管理员可以查看到系统中所有录入的用户名,同时查看到账号今日昨日过题数的数据,点击用户名可以跳到对应第三方网站的用户主页,如图2所示。
4.2 推荐系统的训练数据
本系统使用的训练数据目前主要来自Codeforces编程竞赛平台,后面将逐步增加其他第三方平台。Codeforces提供了API:https://codeforces.com/api/user.status?handle=Fefer_Ivan&from=1&count=10,通过该API接口逐一获取在该平台用户的所有提交记录。本系统通过爬虫共获取7647个题目、1262位有通过题目的用户,共获取556546条提交记录,其中答案正确有249089条,占总记录的44.75%。并不是所有表项都有意义,通过对数据的筛选,取出USERNAME,PROBLEM_ID和STATUS分别表示用户编号,题目编号和运行结果,从而构建用户-题目评分矩阵[7],当通过该题(简称AC)表示成status为1,将其余结果合并为解答错误(简称WA) 表示成status为0。用户-题目矩阵的大小为1262×7647,矩阵中233140个位置存在有效值,数据稀疏率为2.4%,部分数据如图3所示,其中行表示用户,列表示题目。
从数据库中获取到用户提交数据,根据前文提到的基于用户的协同过滤模型进行计算得出图4的问题推荐结果。针对冷启动问题,可以向新用户推荐通过人数多的习题。
5 推荐结果分析
推荐系统通过计算平均预测覆盖率APC(Average Prediction Coverage) ,衡量系統的优劣[8],如式(4) 。
其中N表示系统中用户数量,上式计算了所有用户的平均准确率,平均准确率越高说明系统推荐的质量越好。测试中对于数据集的数据取随机数种子1随机打乱,分为训练数据集和测试数据集,评估下列各种因素对推荐质量的影响。
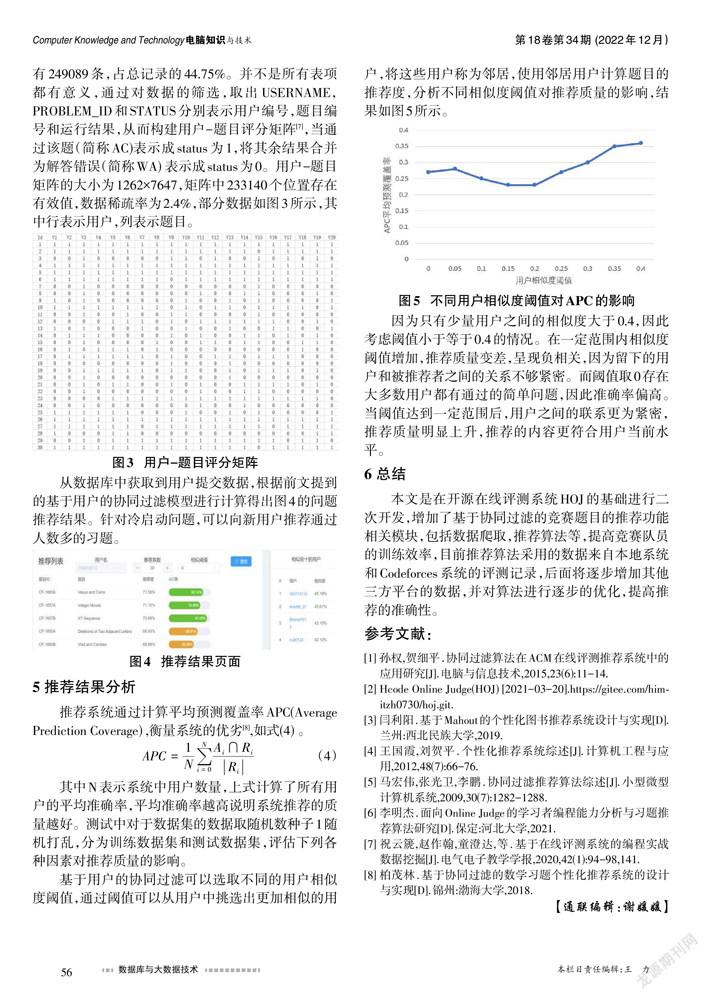
基于用户的协同过滤可以选取不同的用户相似度阈值,通过阈值可以从用户中挑选出更加相似的用户,将这些用户称为邻居,使用邻居用户计算题目的推荐度,分析不同相似度阈值对推荐质量的影响,结果如图5所示。
因为只有少量用户之间的相似度大于0.4,因此考虑阈值小于等于0.4的情况。在一定范围内相似度阈值增加,推荐质量变差,呈现负相关,因为留下的用户和被推荐者之间的关系不够紧密。而阈值取0存在大多数用户都有通过的简单问题,因此准确率偏高。当阈值达到一定范围后,用户之间的联系更为紧密,推荐质量明显上升,推荐的内容更符合用户当前水平。
6 总结
本文是在开源在线评测系统HOJ的基础进行二次开发,增加了基于协同过滤的竞赛题目的推荐功能相关模块,包括数据爬取,推荐算法等,提高竞赛队员的训练效率,目前推荐算法采用的数据来自本地系统和Codeforces系统的评测记录,后面将逐步增加其他三方平台的数据,并对算法进行逐步的优化,提高推荐的准确性。
参考文献:
[1] 孙权,贺细平.协同过滤算法在ACM在线评测推荐系统中的应用研究[J].电脑与信息技术,2015,23(6):11-14.
[2] Hcode Online Judge(HOJ) [2021-03-20].https://gitee.com/himitzh0730/hoj.git.
[3] 闫利阳.基于Mahout的个性化图书推荐系统设计与实现[D].兰州:西北民族大学,2019.
[4] 王国霞,刘贺平.个性化推荐系统综述[J].计算机工程与应用,2012,48(7):66-76.
[5] 马宏伟,张光卫,李鹏.协同过滤推荐算法综述[J].小型微型计算机系统,2009,30(7):1282-1288.
[6] 李明杰.面向Online Judge的学习者编程能力分析与习题推荐算法研究[D].保定:河北大学,2021.
[7] 祝云篪,赵作翰,童澄达,等.基于在线评测系统的编程实战数据挖掘[J].电气电子教学学报,2020,42(1):94-98,141.
[8] 柏茂林.基于协同过滤的数学习题个性化推荐系统的设计与实现[D].锦州:渤海大学,2018.
【通联编辑:谢媛媛】
猜你喜欢
计算机应用(2016年12期)2017-01-13
计算技术与自动化(2015年3期)2015-12-31
现代电子技术(2015年12期)2015-06-15
