
基于有效距离的复杂网络节点影响力度量方法
2022-02-19 02:52马媛媛
复杂系统与复杂性科学 2022年1期
马媛媛,韩 华
(武汉理工大学理学院,武汉 430070)
0 引言
现实世界中的许多复杂系统可以抽象为复杂网络模型。近年来,网络科学研究受到了物理、数学、化学、医学、生物学、计算机科学等领域学者的广泛关注[1-3],其中度量节点的影响力并挖掘关键节点是网络科学的重要研究之一。一方面,关键节点的数量通常较少,但对网络结构和功能有着很大的影响,例如,在电力网络中某主要区段的线路故障将导致整个网络瘫痪;另一方面,识别关键节点在检测金融风险、防止恐怖袭击、控制流行病传播等方面有广泛的应用价值[4-5]。
目前,许多经典的中心性被提出,其中度中心性[6]、介数中心性[7]、接近中心性[8]、特征向量中心性[9]、PageRank[10]和k-shell中心性[11]等在度量节点影响力中得到了广泛的应用。现有的算法研究可分为三大类:一是基于网络局部信息,如度中心性,仅利用节点本身的信息,时间复杂度低,适合于大规模网络,但忽略网络的大部分信息,精度较低;二则基于网络全局信息,如介数中心性、接近中心性和特征向量中心性,根据整个网络的结构特征确定节点的传播能力,具有较高的准确性,但计算复杂度较高,不适合大规模网络;此外,近年来出现了一种介于局部中心性与全局中心性之间的折衷方法—半局部中心性算法,具有精度高、时间复杂度低、考虑的信息较全面的特点。例如,胡钢等[12]通过研究节点与其直接邻居及间接邻居之间的关联关系,提出了基于邻接信息熵的网络节点重要性识别算法;Wang等[13]基于网络中节点与多阶邻居的壳值,利用向量形式表示节点在复杂网络中的相对重要性,提出了多阶邻居壳数向量中心性算法。
近几年,学者们认为用单一的中心性算法来描述网络节点的重要性是片面的,尝试从不同角度来度量节点的重要性,并将多属性决策方法(MCDM)[14-15]和机器学习方法[16]应用到节点的影响力度量上。如Bian等[17]将多种不同的中心性作为复杂网络的多属性度量指标,利用层次分析法(AHP)对多属性指标进行聚合,评价节点的影响力;郭强等[18]采用多属性排序方法(TOPSIS)对时序网络不同时间片段节点的影响力进行综合评价;韩忠明等[19]选取了7个经典节点重要性度量指标,并引入List Net排序学习方法构建了一个基于结构洞的节点重要性排序综合评价方法。
节点的影响力是指节点传播信息的能力,而信息传播依附于具体的网络,故网络结构必定会对信息的传播过程产生影响,进而影响节点的重要性,然而上述研究并未充分考虑网络结构特征对节点重要性的影响。因此,本文基于网络结构特征引入有效距离函数,同时从节点和邻居两个角度度量节点的传播能力,提出一种新的半局部中心性度量方法,然后根据熵权法计算权重,并用VIKOR方法对节点的重要性进行排序。
1 相关研究
假设无向网络G=(V,E)包含|V|=N个节点和|E|=M条边,网络的邻接矩阵用A=(aij)N×N表示,当节点vi与节点vj之间存在连接时aij=1,否则aij=0。
1.1 度中心性
度为网络拓扑结构的基本参数,度中心性(DC)是一种简单直观的排序方法,节点的度表示节点vi的邻居个数,其中τ(i)表示节点vi的邻居集合。
(1)
1.2 接近中心性
接近中心性(CC)反应节点在网络中居于中心的程度,式(2)中dij表示节点vi到节点vj的距离。
(2)
1.3 介数中心性

(3)
1.4 k-shell中心性
k-shell分解是一种粗粒度的网络分解算法,主要根据节点的度数的更新不断地删除网络中的节点,进而得到节点的核值,一般用字母ks表示节点的核值,分解过程如下:
1)首先计算网络中节点的度数,删除节点度数k≤1的节点及其相连的边,更新网络并重新计算度数,再删除度k≤1的节点,直到网络中不存在度数k≤1的节点,记这些删除的节点ks=1。
2)递归地删除网络中节点度数k≤2的节点及其相连的边,之后更新网络并重新计算度,记ks=2。
3)重复上述过程,直到每个节点都被赋予ks值。
1.5 GIN中心性
GIN中心性[20]是一种同时考虑节点和邻居信息的节点重要性评估算法,式(4)中ki表示节点vi的度,dij表示节点vi到节点vj的距离。
(4)
2 一种新的节点影响力度量算法
2.1 有效距离
任意相邻节点之间的距离设置为1,是计算节点间距离最基本的方法,但它与现实网络中信息流交互的原理相违背。信息通过节点后,根据节点与邻居的连接情况,将信息流分配到不同的路径,故任意两节点间距离不应总相等。2013年,Brockmann和Helbing等[21]基于网络拓扑的局部信息,提出了两个连通节点之间的有效距离,将任意两个节点vi和vj间的有效距离定义为
d(i,j)=1-logPji
(5)

2.2 SN中心性
考虑到节点的重要性不仅与节点本身有关,还与邻居节点的信息有关,本文从两个角度考虑节点的重要性,提出了一种基于节点度值和有效距离量化节点影响力的中心性—SN中心性。
从节点的本身考虑,用度属性来表征节点的重要性,定义为
(6)
从邻居角度考虑,用邻居度与相对距离的比值来表征节点的重要性,定义为
(7)
为接近真实传播情况,式(7)中τ(i)表示节点的两步内邻居。避免两角度结合的主观性,本文采用VIKOR方法[22]得到距理想解最近的折衷可行解SN,权重依据熵权法确定,具体过程如下:
1)根据网络中所有节点的SEi和NEi值,建立一个决策矩阵D。
(8)
2)标准化决策矩阵D,并构建标准矩阵R。
(9)
(10)
3)计算第j个属性的熵。
(11)
4)则第j个准则的权重为
(12)
5)确定出正理想解r+和负理想解r-。
(13)
其中,J和J′是效益标准集(标准越高,节点越重要)和成本标准集(条件越高,节点越不重要),文中这两个标准都是效益标准。
6)各节点的群体效用值Si和个体遗憾值Ri按式(14)计算:
(14)
7)计算节点i的VIKOR重要度。
SNi=v(Si-S-)/(S+-S-)+(1-v)(Ri-R-)/(R+-R-)
(15)
S+=maxSi,S-=minSi,R+=maxRi,R-=minRi
(16)
其中,v为决策机制系数,取v=0.5,兼顾群体效用最大化和个体遗憾最小化。SNi是第i个节点重要性的综合评价值,SNi越小则第i个节点越重要。节点重要性的向量可表示为
Te=[SN1,…,SNi,…,SNn]
(17)
8)根据节点的重要性值将Te升序排列。
(18)

2.3 算例分析
示例网络中节点在不同排序方法下的排序结果如表1所示,其中最后一列补充了各节点SN算法的值。由表1可知,DC算法给予节点3、节点7相同排名,但删除节点7后,图1将不是一个连通图,故节点7的影响力应强于节点3;KS算法区分节点的能力较差;BC算法给予8个节点相同的排名,表明算法的稳定性较差;CC算法给节点8的排名靠前,而其他算法中节点8则处于较后的排名,是因其侧重与其他节点间距离而出现的偏差;GNI、SN算法的排序结果较优,但GNI算法给出节点8的排名低于节点10,从两节点的连边情况看,节点8应优于节点10的排名,故SN算法的排序结果更优。

图1 示例
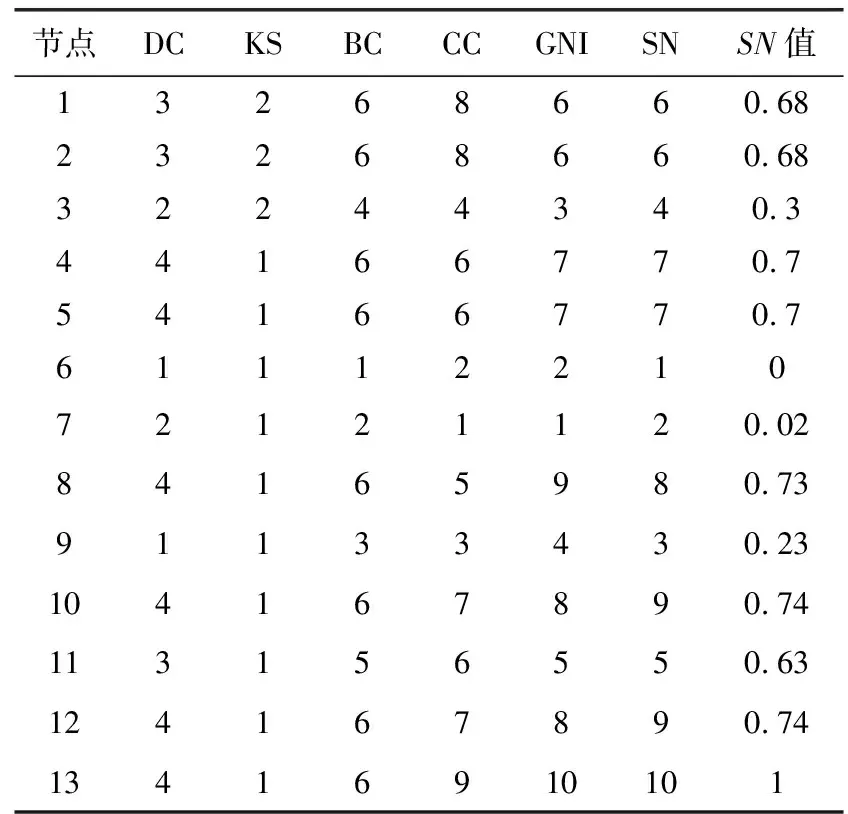
表1 示例网络的排序结果
2.4 算法流程
算法在引入有效距离的基础上,从两个角度考虑了节点重要性。已知网络的邻接矩阵A,具体算法步骤如下:

2)根据式(6)和式(7)分别计算各角度下节点的重要性;
3)构建决策矩阵D并将其标准化得到标准化矩阵R;
4)根据式(11)计算各重要性的信息熵;
5)根据式(12)计算权重;
6)根据式(13)确定正理想解r+和负理想解r-;
7)根据式(14)计算各节点的群体效用值Si和个体遗憾值Ri;
8)根据式(15)计算VIKOR重要度,并得到Te;
9)将Te按升序排列,得到节点排序。
3 评价标准
3.1 SIR模型
为衡量各种指标影响力排序结果的准确性,需已知节点的实际影响力排序。SIR(Susceptible-Infected-Recovered)模型[23]被广泛用于描述疾病、谣言、信息传播过程,故采用SIR模型对传播过程进行模拟,得到节点影响力的标准排名σ。在SIR模型中,节点处于易感状态S,感染状态I,恢复状态R三种状态之一。个体被感染后以概率λ被治愈,治愈后对该疾病免疫,不再被感染。初始阶段,设定网络中任意一个节点为感染状态,其他节点为易感状态。传播过程中,每个处于感染状态的节点试图用感染概率α(α也称为传播概率)感染其处于易感状态的邻居,然后以概率β进入恢复状态,且不再被感染。这个过程重复进行,直到网络中没有受感染的节点。不失一般性,本文取传播概率在传播阈值附近,恢复概率β为1。Φ′为网络中最后处于恢复状态的节点总数,等同于初始感染节点的影响力。为了保证计算结果的可靠性,取M次试验的平均值作为节点的实际影响力Φ(i)。
(19)
3.2 评估指标
3.2.1 区分度
TRF指标[24]的数值反映某种指标下节点得分的内部情况,TRF=0表示所有节点被赋予不同的中心性值,TRF=1表示所有节点被赋予相同的中心性值,故TRF指标值越小,节点获得相同得分的数量越少,算法效果越好。TRF指标的定义如式(20)所示:
(20)
其中,n为将要排序数据的个数,一般是网络中节点的个数,ns为数据中获得相同得分的节点的数目。
3.2.2 相关性
实验采用Kendall tau相关系数[25]衡量各指标排序结果准确性,其表达式为
(21)

4 实验数据及分析
4.1 实验数据
为评估提出算法的效果,实验选取6个真实网络数据,包括Karate[26],Dolphin[27],Jazz[28],Football[29],USAir[30],Netscience[31]。这些网络的拓扑结构统计特征如表2所示。其中,N与M分别为网络节点数与连边数,C为网络集聚系数,〈k〉为节点平均度。

表2 6个真实网络的拓扑参数
4.2 结果及分析
在6个真实网络数据集上,将提出的SN中心性分别与度中心性、K-Shell中心性、介数中心性、接近中心性、GIN中心性进行对比。
不同指标值的排序即节点传播能力的排名,当排名结果出现某一排名下频率较高时,说明该排名下的节点众多,对应的中心性性能较差;当排名长度相对更接近网络中节点数时,排名结果分散,中心性性能较好。图2展示了6个真实网络中各指标下节点的排名分布情况,显然,DC和KS在6个网络中排名分布的高频数高于其他中心性,且排名长度较短,表明DC和KS区分节点的传播能力较弱。相比之下,DC、CC比BC、CC排名分布较好。几乎所有情况下,GIN和SN的排名分布似一条直线,且排名分布长度与网络中节点个数接近,表明其排名分布效果很好;同时从排名频率高于直线的部分观察,SN更优一些。

图2 6个真实网络中各指标下节点的排名分布情况
不同指标在不同网络数据的TRF值见表3,结果表明所提出的SN算法在Karate,Dolphin,Football,Netscience网络中得到的排序具有最高TRF值,即SN算法对节点排名有较好的差异性。SN算法在Jazz,USAir网络中单调性值也处于第二位,优于DC,KS,BC,CC的排序结果。
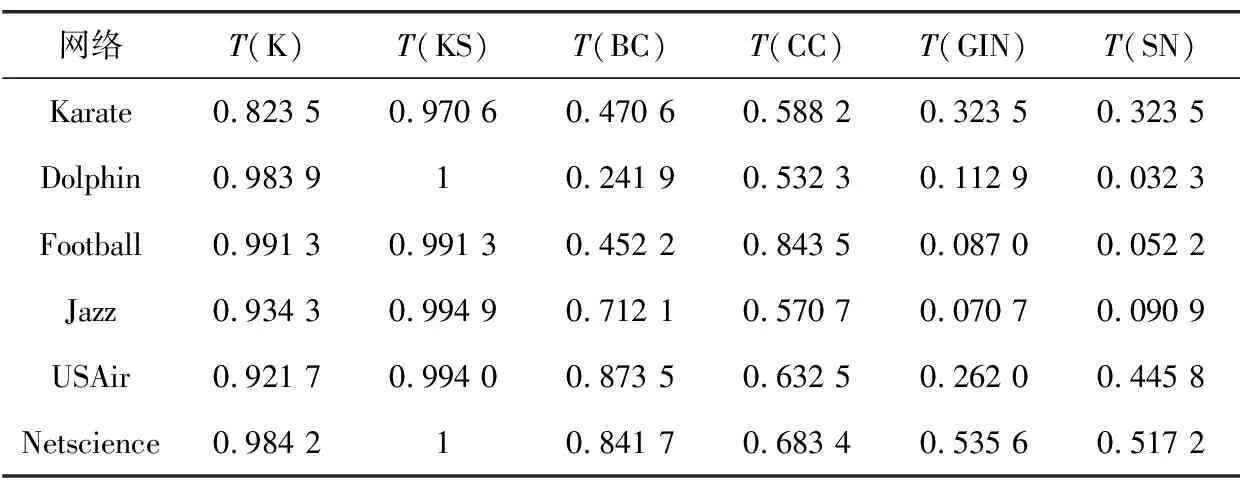
表3 不同指标在不同网络数据的TRF值
各个指标在不同的传播率下的排序准确性如图3所示,当传播率较小时,度中心性的准确性较高,是因为传播率较小时,单节点开始的SIR传播过程易局限于节点的局部邻域,此时节点的度越大,感染到的节点也越多。当传播率变大,接近传播阈值时,SN中心性的准确性逐渐高于前者,说明同时考虑节点与邻居的度与有效距离更接近于真实结果。


图3 6个真实网络中不同指标评估准确性对比
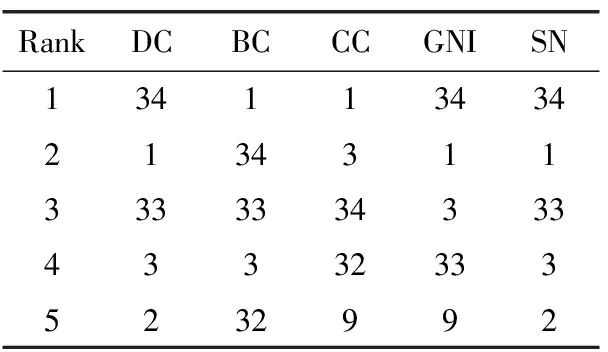
表4 各指标下Karate网络中排名前五的节点
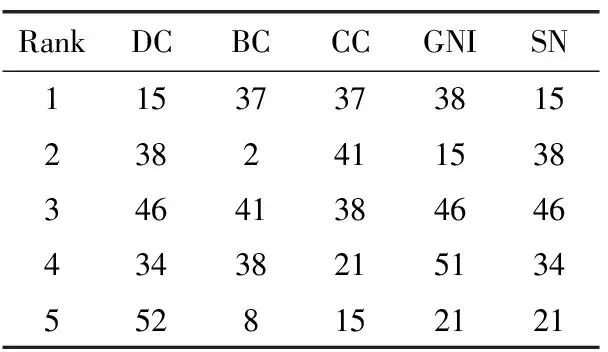
表5 各指标下Dolphin网络中排名前五的节点
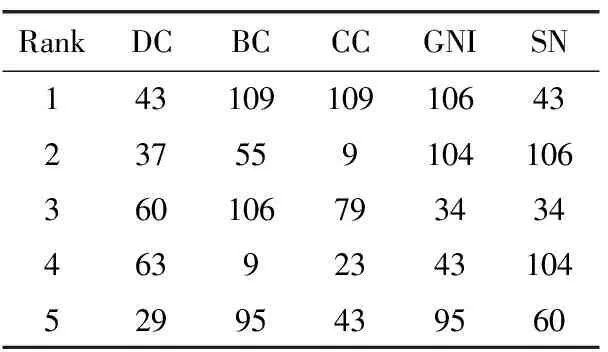
表6 各指标下Football网络中排名前五的节点
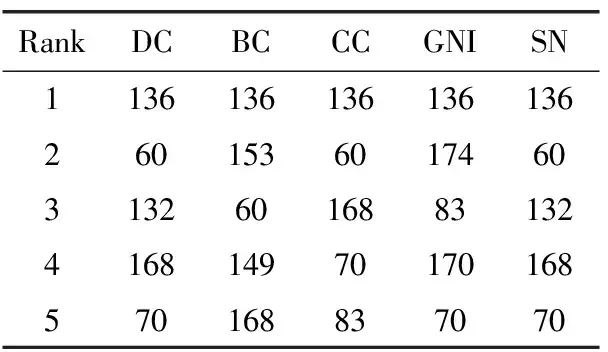
表7 各指标下Jazz网络中排名前五的节点

表8 各指标下Usair网络中排名前五的节点
表4~表9分别比较6个不同网络中各中心性度量排名前5的节点。KS算法将较多节点分解在同一层,故未在此比较。SN算法融合了DC,BC,CC,GIN四者中出现频率高的节点,排名的相关性较高。
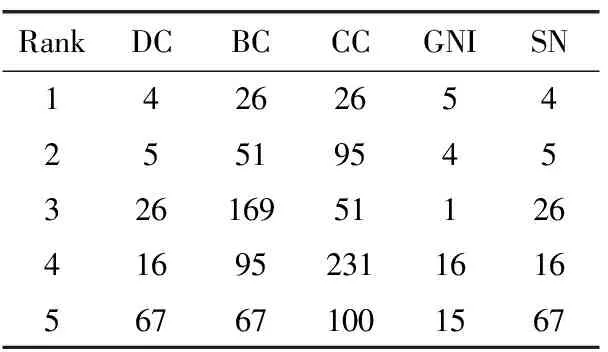
表9 各指标下Netscience网络中排名前五的节点
5 结论
准确度量复杂网络中节点的重要性对于加快积极信息在网络中的传播、预防网络攻击、抑制传染病的爆发具有现实意义。本文考虑到任意相邻节点间距离不等的情况,引入相对距离,提出了考虑节点度与节点间距离的中心性,并用熵权法和VIKOR法对节点重要性进行排序。在6个实际网络进行了数值仿真,验证所提方法的可行性和有效性。实验结果表明,该方法不仅可以得到更准确的排序结果,而且有效减少了相同排序节点的出现频率。
猜你喜欢
导航定位学报(2022年4期)2022-08-15
现代电子技术(2022年4期)2022-02-21
智能计算机与应用(2021年4期)2021-06-05
金桥(2021年3期)2021-05-21
名家名作(2021年4期)2021-05-12
科普童话·学霸日记(2020年1期)2020-05-08
阅读(快乐英语高年级)(2019年8期)2019-09-10
华东师范大学学报(自然科学版)(2019年3期)2019-06-24
小天使·一年级语数英综合(2019年2期)2019-01-10
人大建设(2017年11期)2017-04-20
