
基于稳定匹配的实时ETL弹性调度机制
2022-02-19 10:24刘旋律顾进广
计算机应用与软件 2022年2期
刘旋律 顾进广
(武汉科技大学计算机科学与技术学院 湖北 武汉430065)(智能信息处理与实时工业系统湖北省重点实验室(武汉科技大学) 湖北 武汉430065)(武汉科技大学大数据科学与工程研究院 湖北 武汉430065)(国家新闻出版署富媒体数字出版内容组织与知识服务重点实验室 北京 100038)
0 引 言
传统的ETL是通过批处理的方式,利用晚上或者周末空闲的时间来完成提取、转换和加载操作。然而,在如今竞争剧烈的商业环境下,面对着数据量大、数据需求多变、时间敏感等问题与挑战[1],传统的ETL无法应对。为了使数据能够及时、连续地转换到数据仓库,以便用户能够快速做出决策,实时ETL被提出。在实时ETL系统中,高可用、低延迟和横向可扩展是三个关键特性[2]。文献[3]通过分析ETL过程,并行化执行同优先级的ETL操作的方式来减少ETL过程的执行时间,而文献[4]通过将ETL过程运行到Hadoop计算引擎上,提高运行速度。文献[5]使用面向服务的体系结构,将ETL过程中每一个操作封装为一个RESTful API的方式来解耦ETL操作,通过升级和快速迭代服务的方式来解决数据需求多变的问题,通过集群部署的方式来提高ETL操作速度。
上述解决方案都能在一定限度上解决实时ETL中存在的问题。但是,以上解决方案都没有考虑到数据的动态性。在很多实际场景中,数据源的数据生产速度随着时间波动且波动区间较广,例如,医院药房药品数据、医疗传感器实时数据、人群听歌和购物的行为数据、物流仓库中的物流数据。
在实时ETL系统中,每个ETL过程中的ETL操作都是常驻服务。在上述解决方案中,ETL过程初始化完成后各个操作的进程数不会改变,如果需要更改某个操作并行的进程数,需要重新初始化该ETL过程。对于数据生产速度波动较大的场景,如果ETL过程以数据源的数据生产速度最大值初始化ETL过程,则在大多数时间,ETL过程的资源利用率都不能达到理想状态;如果ETL过程以低于数据生产速度最大值初始化,则存在一段时间,新增数据阻塞在数据源中;如果在允许的容忍时间范围内,不能够把新增数据及时转换到数据仓库中,则不利于用户快速地做出商业分析。
针对现有方案未考虑在数据生产速度波动较大的场景下,ETL过程不能够合理分配资源的问题,本文提出了一种基于稳定匹配的实时ETL弹性调度机制。
1 相关工作
1.1 实时ETL
为了达到实时ETL的要求,文献[2]提出了高可用、低延迟和横向可扩展三个要求。Kim等[3]为了解决基于流的空间信息数据量过大的问题,采用分布式并行的方式设计并实现了一个空间ETL处理引擎来降低延迟。Zhang等[4]为了实时处理医疗传感器收集的流式数据,使用Hadoop来解决该问题。文献[4]监控了Map任务和Reduce任务的负载情况,如果某个MR任务节点负载高就分裂该任务。该方法具有一定的伸缩性,但未从数据源的角度和整体变化去考虑。另外,使用Map与Reduce组合的方式并不能灵活地表示ETL的各种复杂操作。Hsieh等[5]使用RESTful API提供数据迁移功能,该方法能够花费较少的时间来应对数据格式不断变更的问题,同时分布式的调度方式为该系统提供了可扩展性。Chen等[6]提出了一种基于多代理系统的并行ETL执行工作流框架,该系统通过初始化ETL过程时,将相同优先级的ETL操作并行化的方式来降低延迟。Santos等[7]为了能够应对海量数据的数据分析,提出了一种基于Spark的ETL平台。Diouf等[8]提出可以使用云上的技术来解决实时ETL带来的问题,同时也指出当前研究没有考虑到数据的动态性和资源使用不够合理的问题。以上解决方案都通过并行度降低了延迟,通过分布式环境保证了横向可扩展,但是都没有考虑从整体上考虑资源的利用问题,ETL操作的可扩展性较低,导致在数据生产速度变动较大的时候,资源利用不够合理。
1.2 匹配问题
匹配问题一直是众多研究者讨论的热点问题。在两个匹配集中,没有比当前匹配关系更优的匹配关系存在,则当前匹配为稳定匹配。稳定匹配是没有不稳定对的完美匹配。为了达到稳定匹配,多种匹配算法被提出。为了使云平台节点负载更合理,Wang等[9]提出了针对虚拟机分配的匹配算法,该算法根据虚拟机和主机各自的偏好进行匹配。Islam等[10]提出了一种基于延迟接受的资源分配算法,用于将用户蜂窝资源分配给D2D设备。Hamidouche等[11]提出了一种新的基于博弈论的匹配算法,用于解决小型基站和服务提供商服务器之间的多对多匹配博弈问题。Viet等[12]提出了一种双向局部搜索算法,用于搜索稳定婚姻问题中的平等和性别平等稳定匹配。Zhou等[13]提出了一种迭代匹配算法,该算法首先基于固定偏好产生一个稳定的匹配,然后根据每次迭代的最新匹配结果动态更新偏好。本文的重点是实现ETL上下游操作中服务的关系匹配,保证数据的消费速度最大,同时网络拓扑距离费用最低。
2 系统模型
2.1 执行流程
一个ETL过程(OP)表示从数据源(S)获取数据,经过多次ETL操作(O)后,加载到目标数据仓库(D)的过程。一个ETL过程包含多个ETL操作。每一个ETL操作在对应的ETL过程中都至少存在一个ETL服务(OS),多个相同的ETL服务构成一个ETL操作。
在实时ETL系统中,一个ETL过程初始化完成后,所有的ETL服务会常驻在系统中。本文通过调整ETL服务的个数来动态调整ETL过程的消费数据速度(CV)。根据调整的方式不同,本文将弹性调度机制分为弹性增长和弹性收缩两种。首先,根据预测的数据生产速度(PV)来计算出ETL过程的最小消费数据速度(CVm)。然后,比较CVm与当前ETL操作的消费数据速度(CV)。如果CVm大于CV,则当前ETL过程需要弹性增长;如果CVm小于CV,则需要弹性收缩。
弹性增长流程需要判断当前ETL过程中各个操作的消费数据速度(OCV)是否不小于CVm。若当前ETL操作不满足条件,则计算当前操作需要调整的服务数量(SN),并添加相应数量的服务到该ETL过程中。最后,对于存在新增服务的操作Oi,重新确定与上下游操作Oi-1、Oi+1中各服务的匹配关系,保证所有的操作都能满足CVm。
弹性收缩流程则是需要移除服务节省资源。本文不会将所有ETL操作的CV降低到CVm大小,这样需要移除的ETL服务将覆盖所有的ETL操作,执行代价太大。由于发生变更的ETL操作是少部分,因此本文只会移除新增的ETL服务。遍历所有存在变更的ETL操作,根据计算的SN移除新增的服务。若SN不小于新增服务数量(IN),则只移除IN个服务;否则,按照加入顺序依次移除SN个。
计算完SN后,需要调整ETL服务的数量。在分布式场景下,每个物理机器节点的性能不同,负载也不同,一次性添加或移除SN个ETL服务都会影响节点的负载。因此,需要考虑平衡物理节点的负载。
在调整完成后,需要确定与上下游ETL操作匹配关系。在分布式场景中,为了保证各节点的负载均衡,同一个ETL操作的ETL服务可能会分配到不同节点上。在数据量较大的情况下,跨节点ETL服务之间数据的转发将增加网络开销,影响ETL过程的消费数据速度。因此,在调整ETL服务数量后,如何保证在新的匹配关系中,消费数据速度最大且网络拓扑距离费用最小是需要考虑的另外一个问题。
ETL过程弹性调度流程如图1所示。
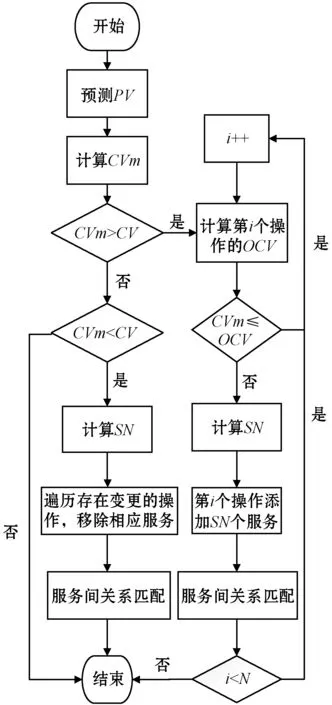
图1 弹性调度流程图
本文将整个调度流程分为以下四个步骤:(1) 预测数据生产速度PV;(2) 计算ETL操作中需要调整的服务数量SN;(3) 调整服务数量;(4) 确定上下游ETL操作匹配关系。本文中出现的主要的符号见表1。
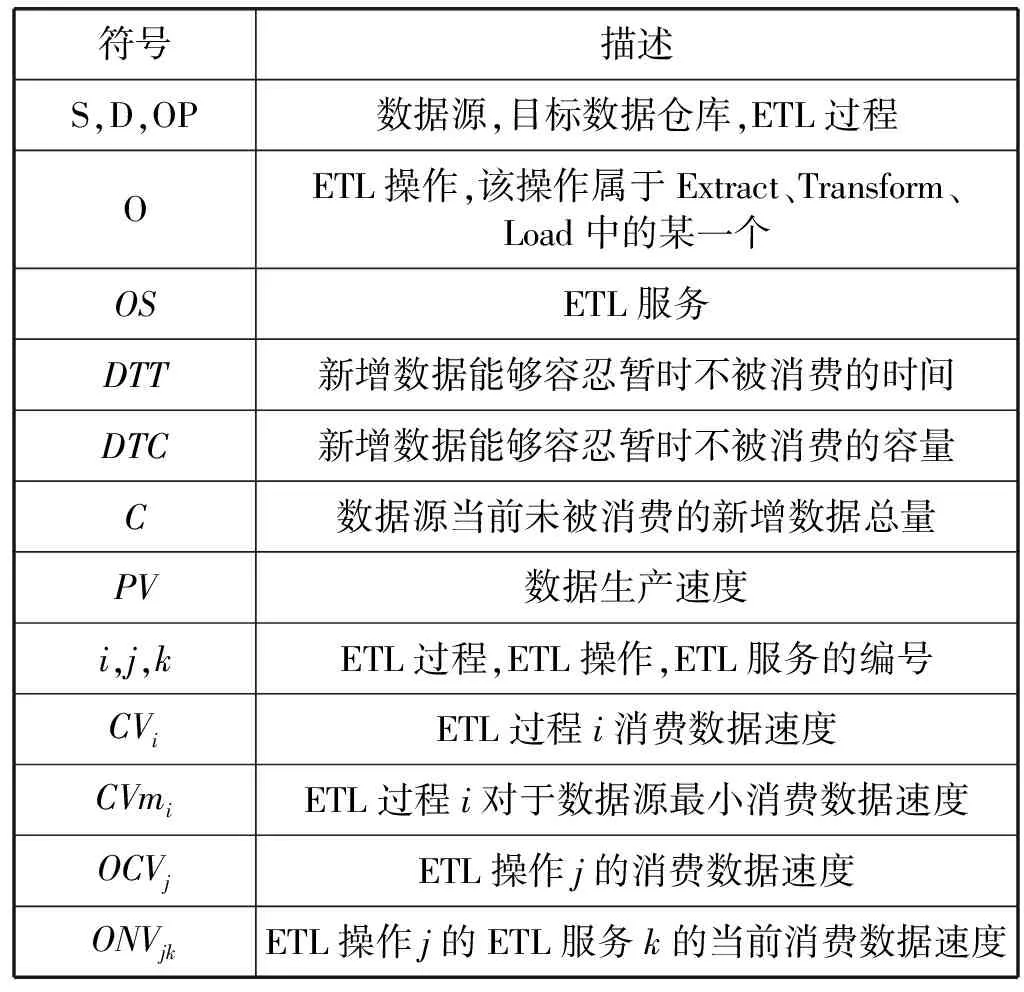
表1 符号表
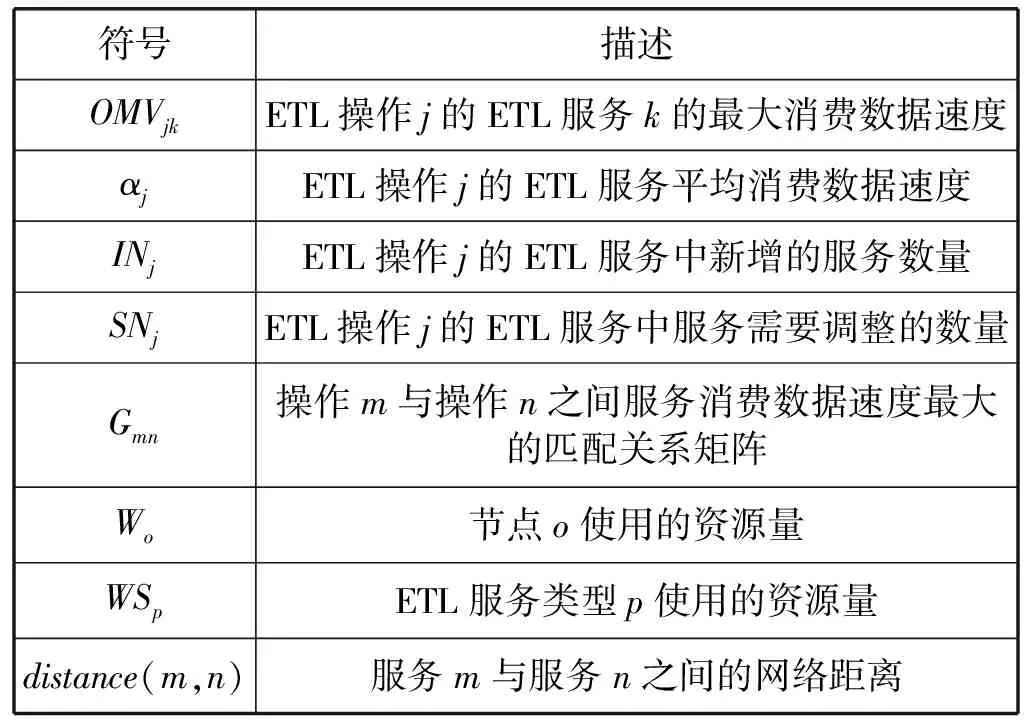
续表1
2.2 预测数据生产速度
不管是弹性增长还是弹性收缩,只有预测出数据生产速度,才能执行弹性调度的策略。在数据生产速度波动较大的场景中,数据生产速度并不会一直增加,而是达到最大值后下降或者维持一段时间。所以,ETL过程的CV与PV不要求相等。当生产数据速度增长时,系统可以容忍一段时间内新增的数据不用立即处理而是缓存到数据源中。如果数据速度增长后长期保持不变,则CV不能继续小于PV,而是需要继续增长避免未被消耗的数据数量持续增长。
这里引入容忍时间(DTT)和容忍容量(DTC)两个变量,ETL过程可以容忍一个DTT后,新增数据的容量不超过DTC的大小。令C为当前未被消费的数据总量。
当C≤DTC时,此时可以容忍CV小于PV,即:
DTT×(PV-CV)≤DTC-C
(1)
当C>DTC时,此时为了恢复到容忍容量以内,所以CV应大于PV,即:
DTT×(CV-PV)≥C-DTC
(2)
2.3 计算调整的服务数量
为了使得ETL过程满足要求,只有计算出需要调整的服务数量才能够向相应的ETL过程中添加或移除服务。一个ETL过程包含多个ETL操作,每个ETL操作包含多个相同的ETL服务。在实时ETL中,数据是通过数据流的方式在操作之间流转。因此,ETL过程的消费数据速度取决于属于该ETL过程i的所有操作中消费数据速度最小的操作。即:
CVi=min{OCV0,OCV1,…}
(3)
式中:CVi为ETL过程i的消费数据速度;OCV0为ETL操作0的消费数据速度。
对于ETL操作j,其消费数据速度OCVj为该操作中所有的服务消费数据速度之和,即:
(4)
式中:OCVj为ETL操作j的消费数据速度;OMVjk为ETL操作j的ETL服务k的最大消费数据速度。
在分布式环境中,一个ETL操作的多个服务虽然逻辑相同,但是由于分布不同,其消费数据的速度不是绝对的相等,而是会在某个固定范围内波动。本文使用该ETL操作的所有服务的消费数据速度的平均值作为添加的服务所使用的消费数据速度,即:
(5)
式中:αj表示ETL操作j的ETL服务平均消费数据速度;OCVj为ETL操作j的消费数据速度;OMVjk为ETL操作j的ETL服务k的消费数据速度。
2.4 调整ETL服务数量
调整SN个数量的ETL服务,会使得多个节点的负载不够均衡。一个节点的负载由该节点上的服务个数和服务类型决定,即:
Wm=WS1×n1+WS2×n2+WS3×n3+…
(6)
式中:Wm表示节点m使用资源量;WS1表示ETL服务类型1的资源量;n1表示ETL服务类型1的在节点m上的数量。这里需要考虑如何调整SN保证各节点的负载能够均衡。
2.5 ETL操作关系匹配
一个ETL过程的消费数据速度不仅仅由ETL操作最大消费数据速度决定,也与操作之间的关系匹配有关。以图2和图3两种匹配为例:ETL操作j的最大消费数据速度为:OMVj1+OMVj2+OMVj3=83;ETL操作j+1的最大消费数据速度为:OMVj+1,1+OMVj+1,2=95。
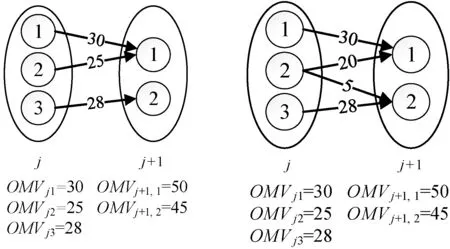
图2 不合理匹配 图3 合理匹配
如果按图2匹配,则当前ETL过程的最大消费数据速度为OMVj+1,1+OMVj3=78;
如果按图3匹配,则当前ETL过程的最大消费数据速度为OMVj1+OMVj2+OMVj3=83。
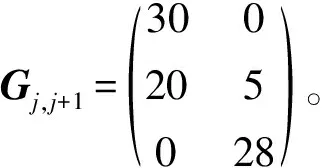
另外,为了保证各节点的负载,同一个ETL操作的ETL服务可能分布在不同的节点上。因此,在数据量大的情况下,节点之间数据传输的带宽消耗不容忽视。因此,如何确定匹配关系保证网络拓扑距离费用最小也是需要考虑的问题。本文节点间网络距离的计算参照Hadoop中网络拓扑距离计算定义的方法,即:

(7)
3 流程实现
步骤一预测数据生产速度。数据源的数据生产速度的变化与其应用实际场景有关,可以将数据生产速度预测问题转为一个网络流量预测问题,通过构建时序预测模型来解决。Local Regression Robust(LRR)算法是文献[8]提出的用来预测虚拟机关键主机用量的算法。该算法是一种自适应预测检测算法,它通过趋势多项式拟合当前的最后k个观测值的方式来预测下一个观测值。由文献[8]中给出的结果可以看出,该算法优于其他算法。因此,本文使用LRR算法来预测数据源生产数据速度。
步骤二计算调整服务数量。
根据式(1),可以推导出:
(8)
根据式(2),可以推导出:
(9)
因此,对于预测数据生产速度PV,要求的最小ETL过程消费数据速度为:
(10)
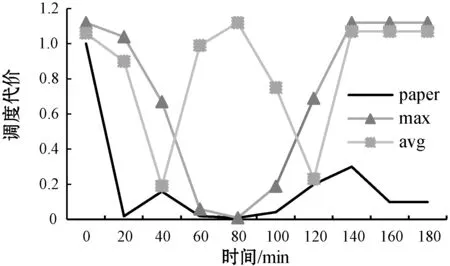
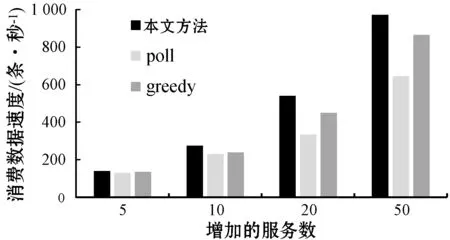
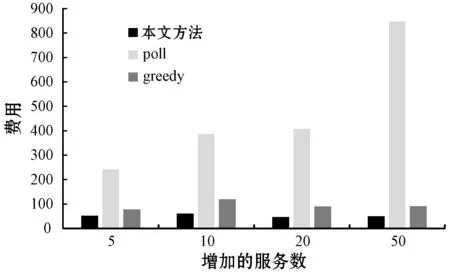
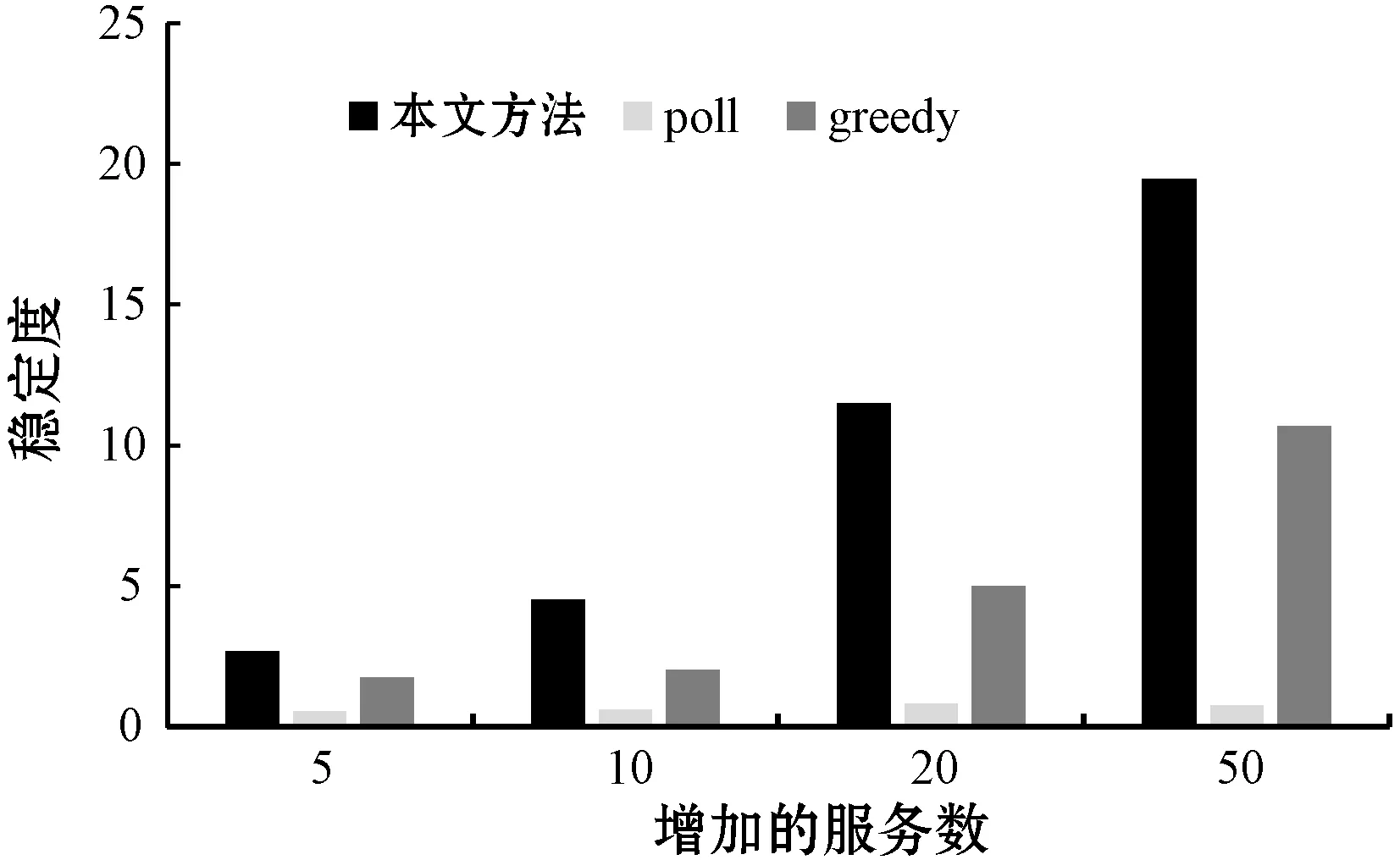
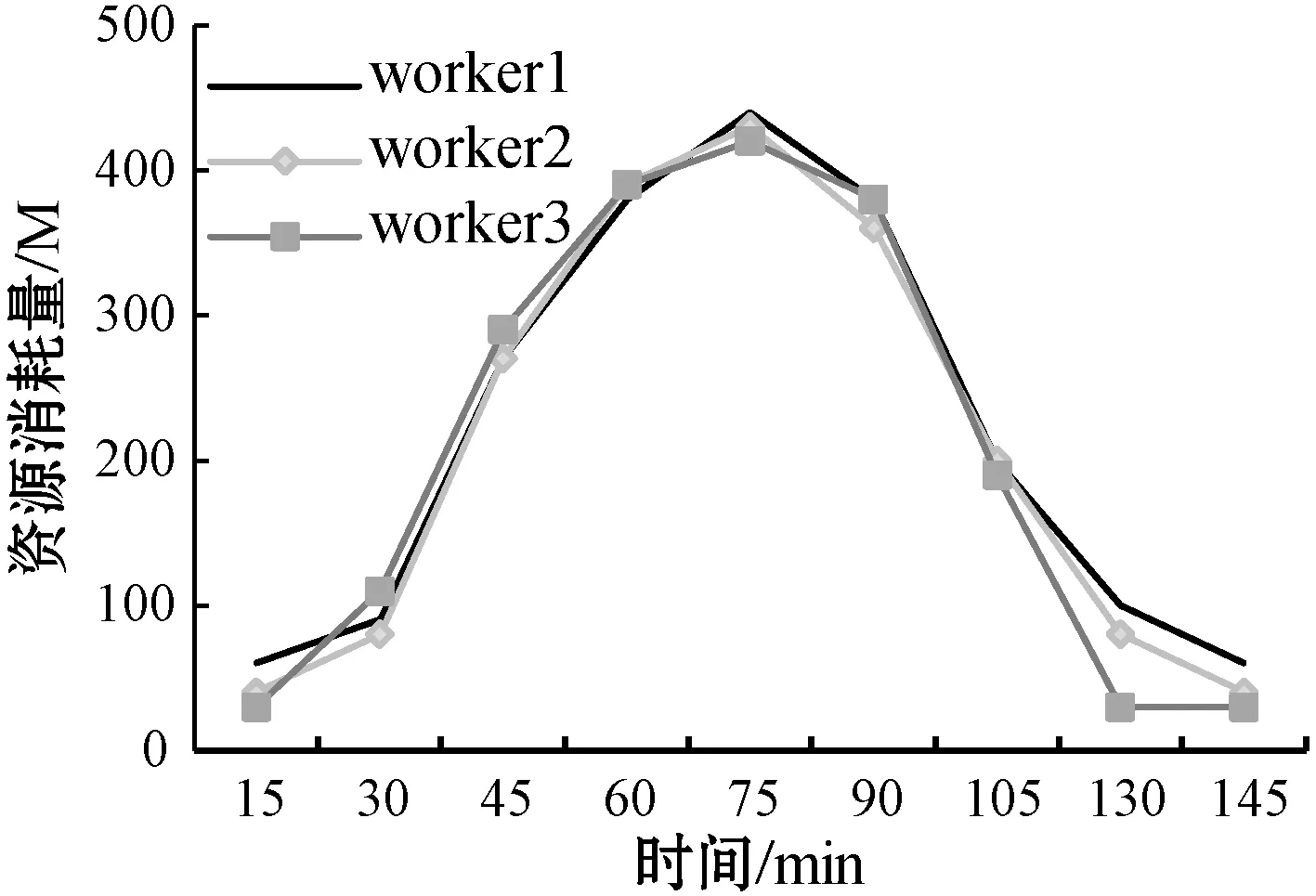
弹性增长流程中,若对于ETL过程i,存在ETL操作j的消费数据速度OCVj (11) 弹性收缩流程中,此时CV>CVm,对于存在变更操作j,存在ETL服务n个,新增的服务数量为INj,该操作理应移除的服务数量Uj为: (12) 本文只是对存在变更的ETL操作进行移除,且移除数不会超过新增的服务数量,因此ETL操作j应该移除的服务数量为: (13) 步骤三调整ETL服务数量。为了保证在调整ETL服务数量的时候,各个物理节点的负载均衡,本文提出了基于资源的贪婪负载均衡(Greedy Load Balance,GLB)算法。在弹性增长流程中,GLB算法选择资源使用最小的节点分配。另外,GLB算法不会将SN个数量一次都分配到每个节点,而是采用依次分配的方式保证负载的均衡。在弹性收缩流程中,GLB算法选择存在该ETL服务的最大资源使用节点移除。算法过程如算法1所示。 算法1GLB 输入:ETL操作的当前消费数据速度v;ETL操作目标速度t;当前ETL操作数量n;ETL操作的平均速度a;每个节点的资源利用集合U。 输出:被选择节点的索引。 1.begin 2.ifv 3.sn←calculated adjusted number(v,t,n,a) 4.fork←0tosndo 5.i←find minimum resource usage node(U); 6.endfor 7.else 8.sn←calculated adjusted number(v,t,n,a) 9.fork←0tosndo 10.a←resource usage array sorted by maximum(U); 11.forl←0tolength(a)do 12.ifexist ETL service in lthen 13.i←l 14.break 15.endif 16.endfor 17.endfor 18.endif 19.returni; 20.end 步骤四ETL操作关系匹配。对于ETL操作,其各个ETL服务处理完数据后可以随机转发给下游的任意服务。因此,一定存在一种匹配关系使得操作j与操作j+1的整体消费数据速度为min{OCVj,OCVj+1}。当ETL操作j中添加了服务,需要确定Oj与Oj-1、Oj与Oj+1的匹配关系。通过步骤二已经保证各个操作的消费数据速度都满足条件。因此,只需要确定匹配关系使得{Oj-1,Oj}和{Oj,Oj+1}这两组的消费数据速度CV分别为min{OCVj-1,OCVj}和min{OCVj,OCVj+1}即可满足条件。 从可行流开始增广时,最终的增广量是一定的。所以为了满足最小费用,只需要每次找最小费用的增广路即可。本文提出基于Dicnic算法的改进(Dicnic Improved,DI)算法来解决该问题。传统的Dicnic算法通过先广度优先搜索(BFS)分层,后深度优先搜索(DFS)的方式来找寻增广路。本文求解的流量网络是一个由Oj、Oj+1两个操作的所有服务组成的网络,其具有二分图的性质,每个操作即可为一层。因此,DI算法不需要通过BFS分层。由于操作已经分层,因此,可以直接使用层次遍历的方式来找寻最小费用增广路。算法的步骤如算法2所示。 算法2DI算法 输入:上层服务流量集合S;基础服务层流量集合T; 输出:匹配关系矩阵G;匹配成本C;最大消费数据速度V。 1.begin 2.s←calculate total service traffic(S), t←calculate total service traffic(T), needTranspose←false 3.ifs>tthen 4.M←S,S←T,T←S,needTranspose←true 5.endif 6.i←0,C←0,V←0,G←[length(S)][length(T)] 7.whiletruedo 8.whilei 9.i++ 10.endwhile 11.ifi 12.I←MAX,J←MAX,minCost←MAX 13.fork←itolength(S)do 14.ifS[i] has trafficthen 15.forj←0tolength(T)do 16.ifT[j] has trafficthen 17.cost←calculatecost(i,j) 18.ifminCost>costthen 19.minCost←cost,I←i,J←j 20.endif 21.endif 22.endfor 23.endif 24.endfor 25.C←C+minCost, 26.minStream←min(S[i],T[j]) 27.S[i]←S[i]-minStream,T[j]←T[j]-minStream, G[I][J]←minStream,V←V+minStream 28.else 29. break 30.endif 31.endwhile 32.ifneedTransposethen 33. transpose(G) 34.endif 35.returnG,C,V; 36.end 本文基于容器调度平台kubernetes构建了一个分布式调度平台。每个ETL服务都被封装成为一个RESTful API的服务并转化为一个docker镜像保存到镜像仓库中。当需要调整ETL服务数量的时候,通过kubernetes来进行调整。该平台配置如表2所示。 表2 平台配置 在实时ETL系统中,ETL服务常驻在ETL系统中,数据以数据流的方式在ETL服务之间流转。通过随机构造了100个正态分布函数用来模拟数据生产速度随时间发生波动较大变化的场景,并以此变化的数据生产速度不断地向初始化后的ETL过程提供实时数据。在弹性调度方面,与传统的调度方案在资源利用方面进行了比较。在匹配问题方面,与贪婪(greedy)匹配算法和轮询(poll)匹配算法在消费数据速度和网络距离费用方面进行了比较。 为了验证实时ETL平台弹性调度比传统的调度在数据波动较大的场景下,资源的利用具有优越性,本文构建速度浪费μ和堆积浪费ε两个变量。 如果当前的PV>CV,则ETL过程以最大消费数据速度运行,因此速度浪费μ=0,但是会造成堆积浪费,其值为: (14) 如果当前的PV (15) 式中:Δt为单位时间;W为ETL过程投入的内存大小。本文使用速度浪费和堆积浪费之和作为资源代价的衡量指标。结果越大,代表浪费越多,资源利用率越低。 本文匹配算法的提出是为了确定ETL操作匹配关系使得在消费数据速度最大的同时网络距离费用最小。如果消费数据速度越大,或者网络距离费用越小,则该匹配越稳定。因此,本文构建了稳定度θ来表示匹配是否达到稳定。其值为: (16) 式中:COST表示的是匹配后网络距离费用。θ越大表示匹配关系越稳定。 图4给出了传统的实时ETL调度机制中,以消费数据速度最大值调度(max)、以消费数据速度的平均值进行调度的代价变化(avg)及本文弹性调度机制的代价变化(paper)曲线图。图5给出了三种调度方式随着时间增加消费的数据总量变化图。从图4中可以看出,在生产数据速度发生波动的时候,弹性调度机制的代价一直都是低于传统的调度方式的代价。从图5中可以看出,弹性调度的方式并不会影响数据消费的速度,其消费数据的总量和最大消费数据速度配置的ETL过程差不多。因此,本文的弹性调度机制与传统的调度机制相比,在数据生产速度波动较大的场景下,其消费数据速度与最大消费数据配置的ETL过程相差不多,但资源代价更小。 图4 不同的调度机制资源代价变化曲线 图5 不同的调度机制消费数据总量变化图 图6给出了相同的ETL过程增长相同的服务个数后,使用不同算法确定匹配关系的消费数据速度变化图。图7给出了不同算法匹配后网络拓扑距离费用变化图。图8给出了不同算法匹配后匹配度的变化图。可以看出,本文提出的匹配算法能够保证消费数据速度最高的同时费用最小,匹配的稳定度最高,匹配更稳定。 图6 不同匹配算法消费数据速度变化图 图7 不同匹配算法网络距离费用变化图 图8 不同匹配算法的稳定度变化图 图9给出了实验环境中三个工作节点在数据波动过程中资源消耗情况。由图9可以看出,使用GLB算法来调度服务的个数,能够保证节点的负载均衡。 图9 GLB算法节点资源消耗变化曲线图 本文提出了一种基于稳定匹配的实时ETL弹性调度机制,用于处理在数据波动较大的情况下,传统实时ETL方案资源配置不合理的问题。该机制通过预测生产数据速度来计算需要调整的ETL服务个数。然后使用GLB算法和DI算法来分别完成服务的调度问题及服务的匹配问题。通过实验验证了方案的有效性,也为ETL过程调度提供了参考。针对实时ETL平台中多个ETL过程的资源弹性调度是下一步工作的重点。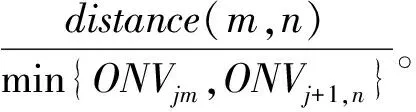
4 实 验
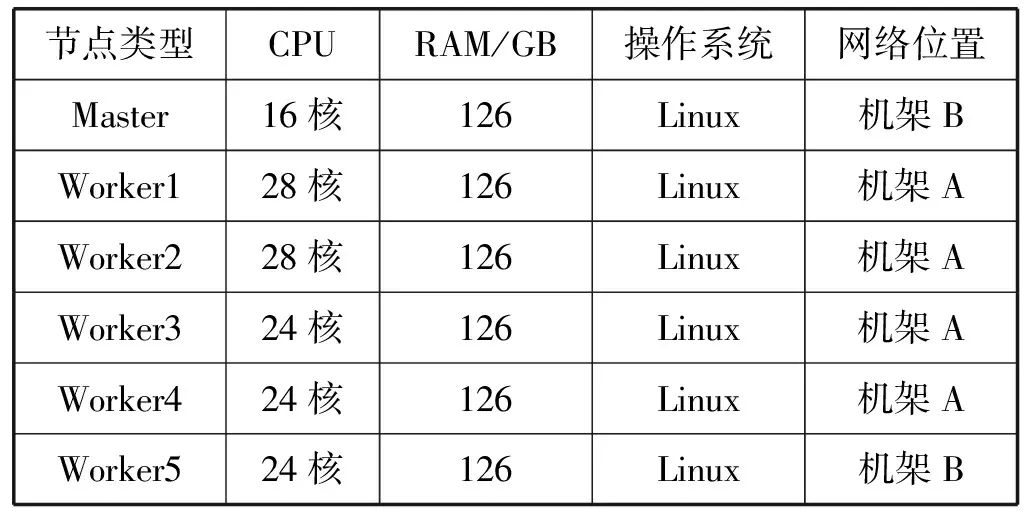
4.1 实验环境
4.2 评测方法
4.3 结果分析

5 结 语
猜你喜欢
中国交通信息化(2022年9期)2022-10-28计算机与数字工程(2022年7期)2022-08-26南方农业·下旬(2022年4期)2022-05-24现代电子技术(2022年4期)2022-02-21军事文摘·科学少年(2021年9期)2021-10-13智能计算机与应用(2021年4期)2021-06-05科技研究·理论版(2021年20期)2021-04-20华东师范大学学报(自然科学版)(2019年3期)2019-06-24中国化妆品(2017年12期)2017-06-27网球俱乐部(2009年13期)2009-11-23
