
基于改进的胶囊网络模型的高光谱图像分类方法
2022-02-19 10:23周衍挺
计算机应用与软件 2022年2期
周衍挺 韦 慧
(安徽理工大学数学与大数据学院 安徽 淮南 232001)
0 引 言
高光谱图像具有丰富的光谱与空间信息,已经被广泛应用于各个领域[1-3]。对高光谱图像的每个像元进行分类是高光谱图像研究领域的重要内容,然而高光谱图像具有波段多、数据量大的特点,导致传统的分类方法不能有效提取图像特征,进而对图像进行地物分类[4-6]。目前,卷积神经网络(Convolutional Neural Network,CNN)由于可以提取图像不同层次的特征,在图像处理领域得到了广泛的应用[7-10],许多研究人员开始利用CNN来对高光谱图像进行分类。
研究发现,CNN具有强大的特征提取能力,但是其无法充分地提取高光谱图像的特征信息,导致图像分类精度不高[11-12]。近几年,国内外研究者提出了结合图像空间信息和光谱信息的图像分类方法,图像分类的精度得到了显著的提高[13-16]。Xu等[13]利用长短期记忆网络(Long Short-Term Memory,LSTM)去提取高光谱图像的光谱信息同时利用CNN提取图像的空间信息,从而提升分类精度。欧阳宁等[14]利用双通道卷积网络同时提取图像的光谱与空间特征,并采用多模态压缩双线性池化来获得空谱联合特征,达到了提升图像分类精度的目的。然而文献[13-14]中的模型在提取空间信息时,对原始数据块进行主成分分析(Principal Component Analysis,PCA)降维处理,导致光谱信息有所损失,降低了模型的分类性能。Chen等[15]利用3D-CNN直接提取图像块的光谱-空间信息,保留了图像光谱高维特征。刘冰等[16]将残差学习引入3D-CNN,可以提取更深层次的光谱与空间特征,但是其网络结构复杂,参数量大,容易导致过拟合现象。
现有文献中大部分分类方法都能够有效地提取高光谱图像的光谱与空间信息,然而绝大多数方法无法有效识别特征之间的空间位置、平移与旋转关系,从而限制了模型的分类能力。文献[17]中提出胶囊网络可以较好地提取特征之间的空间位置。现有文献中,将胶囊网络应用到高光谱图像分类的相关研究还比较罕见[18-19]。Paoletti等[18]提出的胶囊网络在降低网络设计复杂度的同时,可以提取高光谱图像的抽象特征,显著提升了模型在高光谱图像上的分类精度。Deng等[19]提出了2种浅层胶囊网络结构,可以充分提取小样本高光谱训练数据的特征,进而提升模型在小样本高光谱图像上的分类性能。
基于胶囊网络的优势,结合双通道卷积网络模型,本文提出一个基于胶囊网络的改进模型(Improved Capsule Networks,ICAP)。该模型不仅能够充分提取高光谱图像光谱和空间特征,同时考虑到特征之间的空间位置关系,降低在高光谱图像上的分类误差。
1 胶囊网络简介
1.1 胶囊网络结构
胶囊网络中包含许多胶囊结构,胶囊是由许多神经元组成的,其输入输出都是向量。胶囊向量的长度表示胶囊所代表实体的存在概率,方向表示了实体的颜色、方向、位置等属性。
胶囊网络主要由普通的卷积层、PrimaryCaps层以及DigitCaps层组成。卷积层负责提取图像的初级特征。这一层对图像进行卷积操作,再经过激活函数得到输出值。PrimaryCaps层是初始胶囊层,这一层开始使用胶囊来传递信息,可以组合前一层卷积层提取的初级特征,并将特征信息以胶囊的形式保留下来。PrimaryCaps层到DigitCaps层之间的连接是向量与向量之间的连接,由动态路由算法[17]迭代计算出这两层之间的最优参数。DigitCaps层的胶囊个数为最终的分类种数,每个胶囊代表一种实物,其长度代表实物出现的概率。胶囊网络采用的是Margin loss损失函数,其函数表达式如下:
Lk=Tkmax(0,m+-‖vk‖)2+
λ(1-Tk)max(0,‖vk‖-m-)2
(1)
式中:Lk表示类别k的损失,如果类别k存在,则Tk为1,否则为0。‖vk‖表示胶囊向量的模长,即类别k存在的概率。m+、m-为阈值函数,表示胶囊之间的连接强度,大于0.9可以认为胶囊之间完全连接,小于0.1可以认为胶囊之间没有连接。m+为上边缘阈值,通常取值为0.9,m-为下边缘阈值,通常取值为0.1。λ为稀疏系数,可以调整两者的比重,通常取值为0.5。
1.2 动态路由算法
图1为动态路由过程。
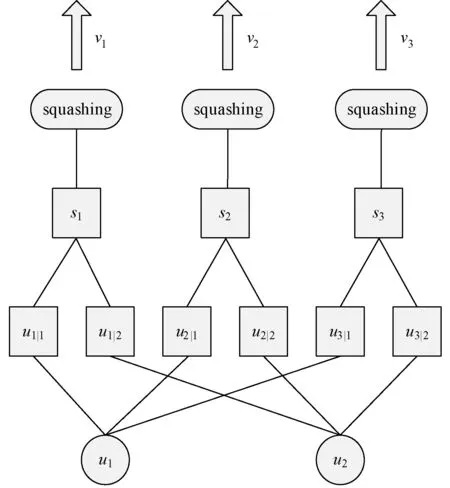
图1 动态路由过程
如图1所示,一个胶囊的输入sj是上一层预测向量uj|i的加权总和,uj|i为上一层输出向量的线性组合,如式(2)所示。
(2)
输入向量sj经过挤压函数(squashing)处理,得到输出向量vj,挤压函数表达式如下:
(3)
动态路由算法的主要目的是希望找到一组耦合系数cij,使得预测向量uj|i符合输出向量vj。cij是由路由softmax计算得到的,即:
(4)
其中bij初始化为0,其更新方式为:
bij←bij+ui|j·vj
(5)
2 ICAP模型结构
高光谱图像是复杂的三维立方体数据,且标注训练样本的代价过于昂贵,导致训练样本较少。从小样本高光谱图像中高效提取出图像的特征信息是解决高光谱图像分类问题的关键。浅层CNN结构无法充分提取高光谱图像特征信息,深层CNN结构可以提取图像更加抽象的高级特征,然而深层的网络架构参数量大,在小样本高光谱图像分类中容易过拟合。此外,CNN模型中神经元之间的传递数据是标量,无法表示出特征之间的位置关系。胶囊网络利用胶囊向量可以表示出特征的位置、方向以及形变等信息,极大地提升了模型的特征提取能力。
为此,本文给出了一种改进的胶囊网络浅层模型,可以在较少的训练数据条件下,充分提取高光谱图像特征信息,从而取得较高的分类精度。图2为改进的胶囊网络结构,含有5个卷积层、2个PrimaryCaps层、1个融合层(Concat Layer)以及1个DigitCaps层。图像信息在经过卷积处理后,都会经过批标准化(Batch Normalization,BN)[20]处理,从而加快训练速度,降低模型过拟合。1×1卷积核可以对原始图像块进行降维,从而减少模型参数,提升模型的运行效率。双通道的设计可以让图像信息同时经过5×5卷积核与7×7卷积核处理,多尺度提取图像初级信息,充分获取图像的局部与全局特征。虚框里是2个PrimaryCaps层,可以将图像初级信息封装为胶囊向量,提取出高光谱图像特征之间的相对位置信息,并在融合层将2个PrimaryCaps层进行拼接。最后,在DigitCaps层计算出各个地物类别存在的概率,以及Margin Loss损失函数。
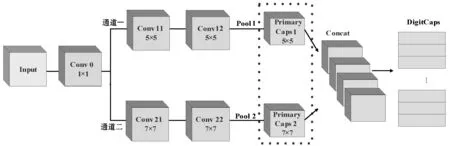
图2 改进的胶囊网络机构
3 实验仿真
3.1 实验环境与数据集
实验操作系统为Windows7,主频为2.60 GHz,显卡为GTX-1060,并且以keras为框架,使用Python3.6为开发语言。实验数据为Indian Pines和Pavia University两个高光谱数据集。
Indian Pines数据集(IP)由AVIRIS传感器在美国印第安纳州西北部采集得到。数据集大小为145×145pixel,包含16种地物,各个地物的样本数目如表1所示。空间分辨率为20m/pixel,共有224个波段,去除受覆盖区域水吸收的24个波段,保留剩余的200个波段。最后实验的Indian Pines数据集大小为145×145×200。
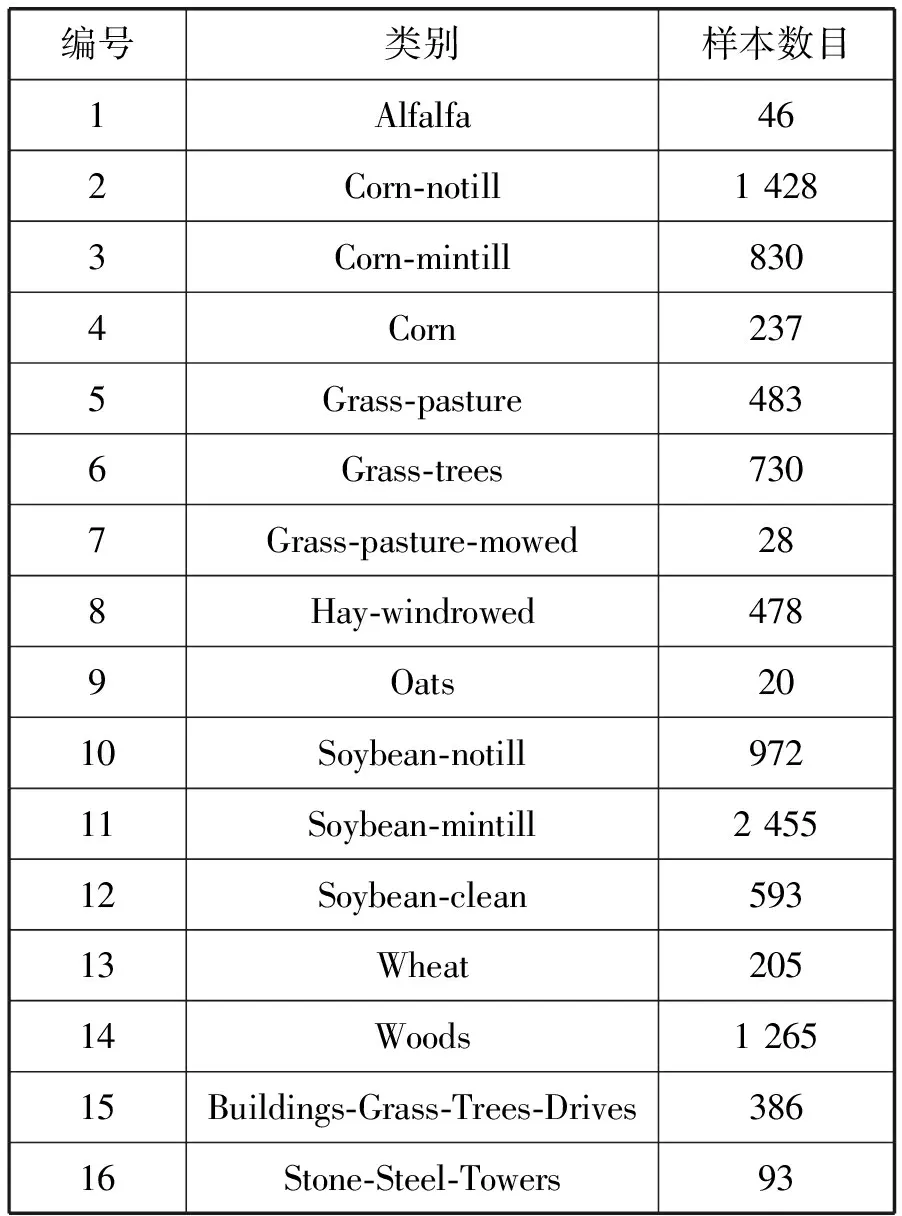
表1 Indian Pines数据集地物样本数目
Pavia University数据集(PU)是用ROSIS传感器在帕维亚大学拍摄的高光谱数据。数据集大小为610×340pixel,包含9种地物,各个地物的样本数目如表2所示。空间分辨率为1.3m/pixel,共有115个波段,去除受噪声影响的12个波段,保留剩余的103个波段。最后实验的Pavia University数据集大小为610×340×103。实验数据集在输入模型之前,要先对数据集进行边缘填充以及数据归一化处理,然后取出图像块对模型进行训练。
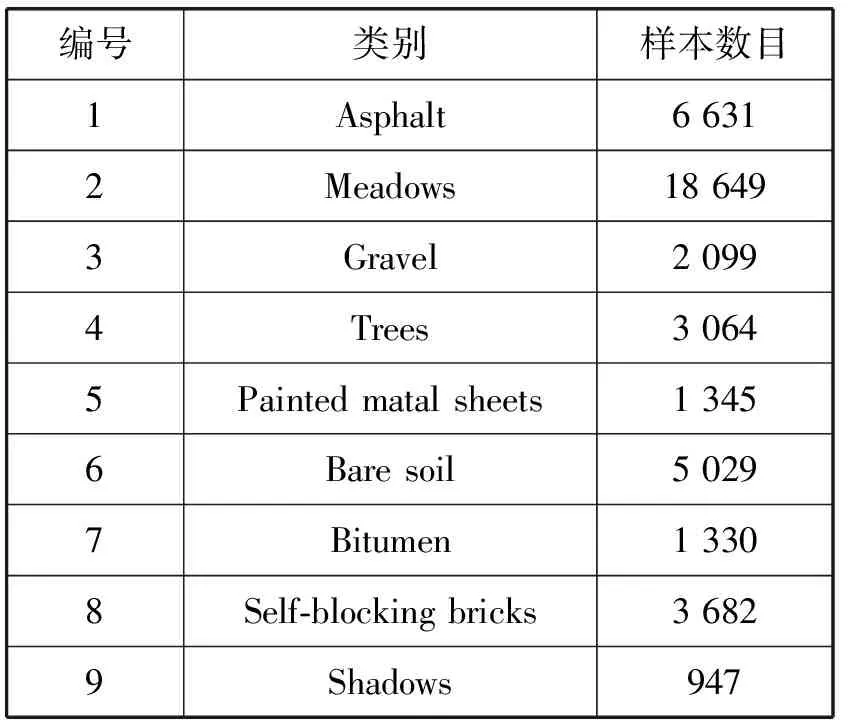
表2 Pavia University数据集地物样本数目
3.2 实验设置
表3列出了改进模型的参数,模型的卷积填充方式均为same模式。
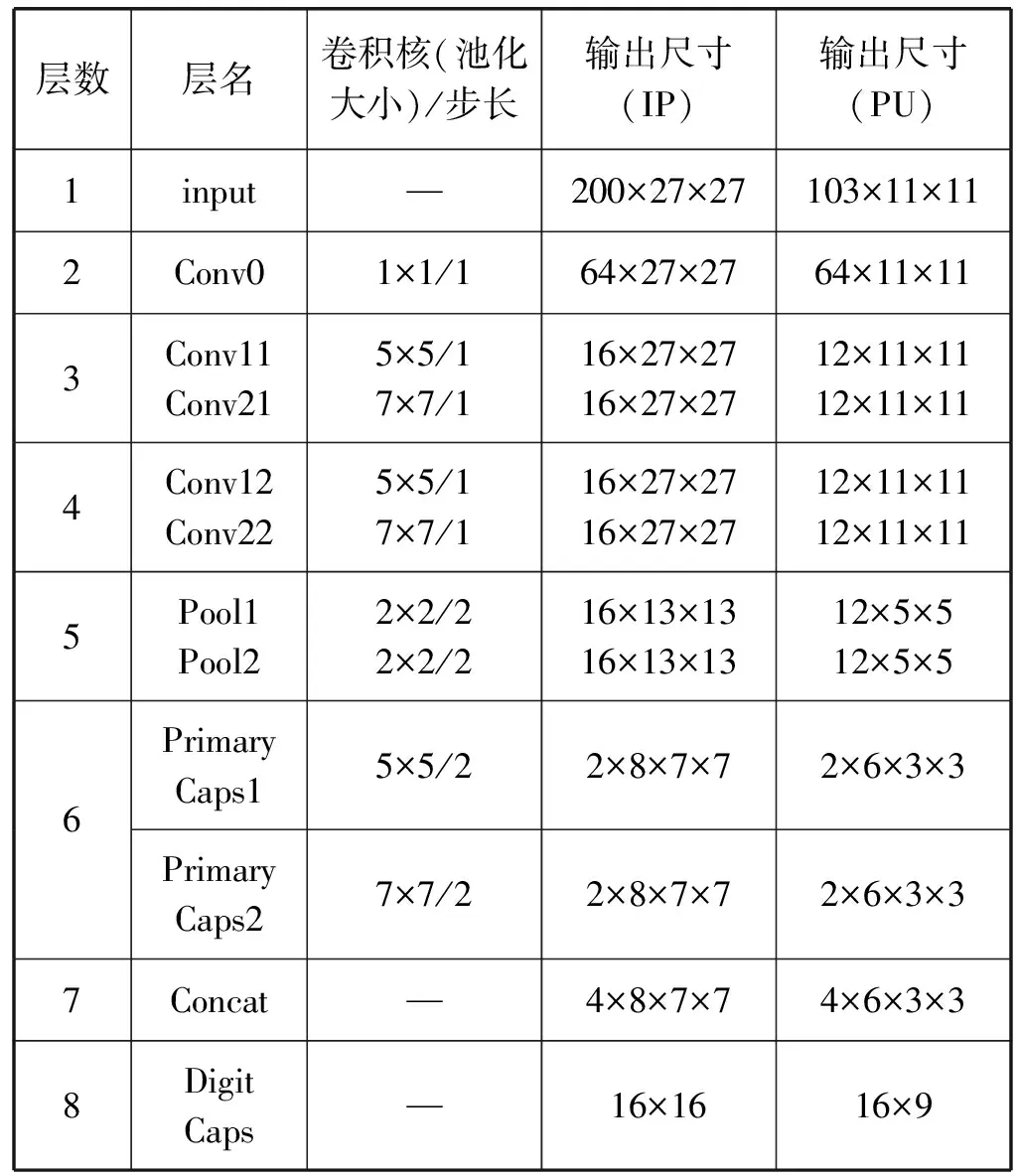
表3 改进模型参数
Indian Pines数据集输入的图像块大小为200×27×27。图像块经过1×1卷积核的降维处理后,得到64幅大小为27×27的特征图。然后将64幅特征图分别输入两个卷积通道,经过2个卷积层与1个平均池化层的处理,均得到16幅大小为13×13的卷积特征图。将16幅特征图在PrimaryCaps层封装成2×8×7×7的四维张量,并将两个通道的输出张量在第一维度上进行拼接,得到4×8×7×7的张量。最后输入DigitCaps层,得到16个类别胶囊向量。每个胶囊向量的模长代表了对应类别存在概率,并以此计算出分类损失。Pavia University数据集输入的图像块大小为103×11×11,其分类过程与Indian Pines数据集类似。
Indian Pines数据集随机分为10%训练集、10%验证集、80%测试集,其中类别Grass-pasture-mowed与Oats的训练样本数目增加到5个,其余类别不变。Pavia University数据集随机分为2%训练集、2%验证集、96%测试集。此外,本文采用总体分类精度(OA),平均分类精度(AA),Kappa系数来评估模型的性能。每个模型迭代100次,并将在验证集中损失函数最小的模型作为最终测试模型。每个模型均测试5次,取5次实验精度的平均值为最终结果。
为了验证ICAP模型的图像分类能力,本文设计了1个2D-CNN模型,图3为2D-CNN模型的结构图,该模型全连接层的神经元个数都设置为128,并在全连接层后都添加Dropout机制,其值设置为0.5,其余参数与ICAP模型相同。此外,为了验证双通道网络的特征提取能力,本文还设计了两个胶囊网络,记作CAP-1、CAP-2。CAP-1仅保留通道一,CAP-2仅保留通道二,其余参数与ICAP相同。
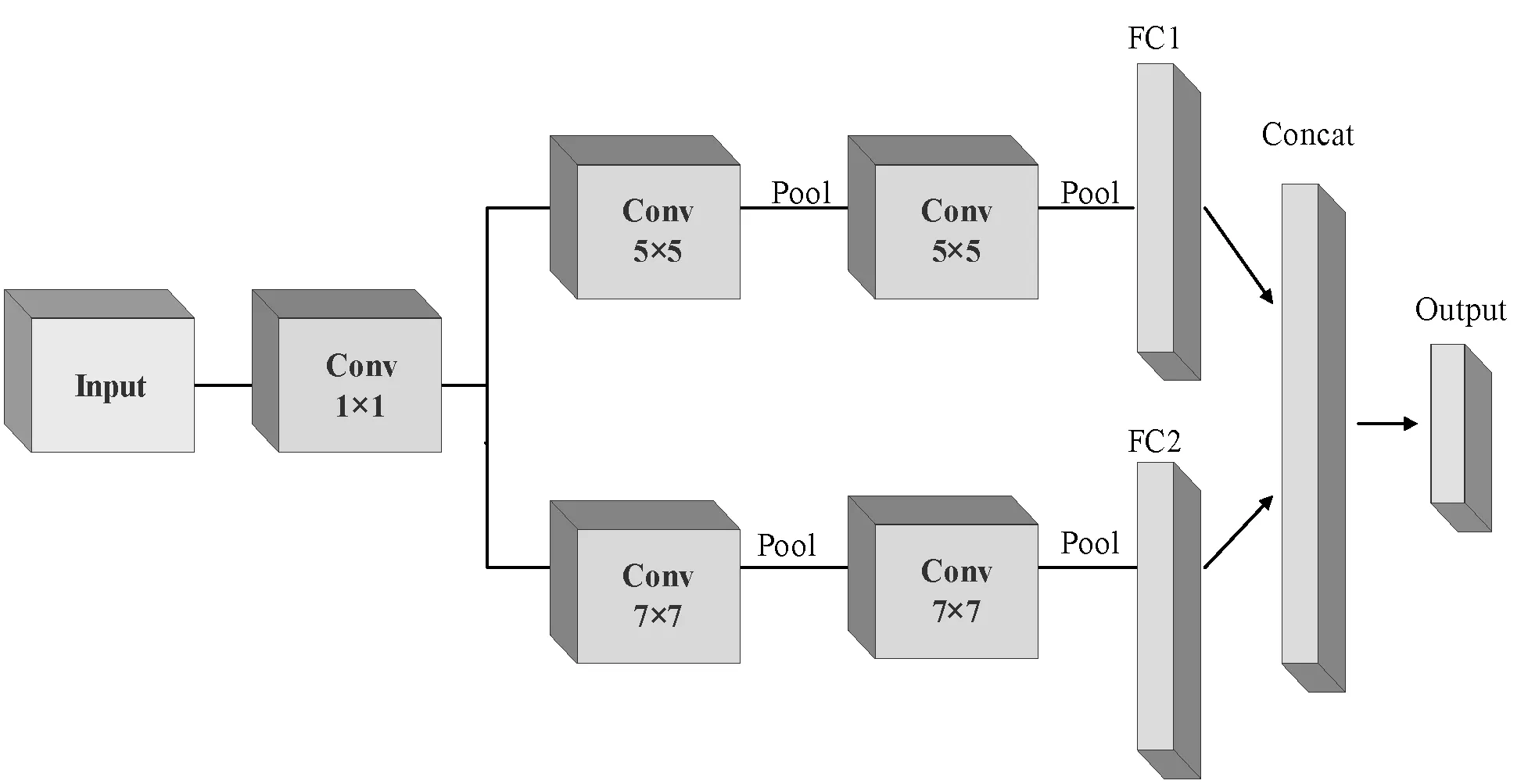
图3 2D-CNN结构
3.3 实验结果与分析
图4与图5为各模型在Indian Pines数据集与Pavia University数据集上的分类结果图,图4(a)与图5(a)为真实值标记图。从图中可以看出本文的ICAP模型在2个数据集里的分类效果要优于2D-CNN、CAP-1、CAP-2。表4为各模型在两个数据集上的分类精度。从表4中可以看出,本文提出的ICAP模型的分类精度要优于其他模型。ICAP模型在2个数据集里的OA、AA、Kappa系数均优于2D-CNN,说明了胶囊网络相比于2D-CNN,可以更好地提取图像中的光谱与空间信息,并识别特征之间的空间位置信息、平移与旋转关系,从而提升模型的图像分类能力。此外,ICAP模型相比于CAP-1、CAP-2模型,OA、AA、Kappa系数也得到一定的提高。说明了包含5×5、7×7卷积核的双通道模型可以多尺度的提取图像初级信息,减少了卷积过程中的信息损失,进而改善模型的分类精度。

图4 Indian Pines分类结果

图5 Pavia University分类结果
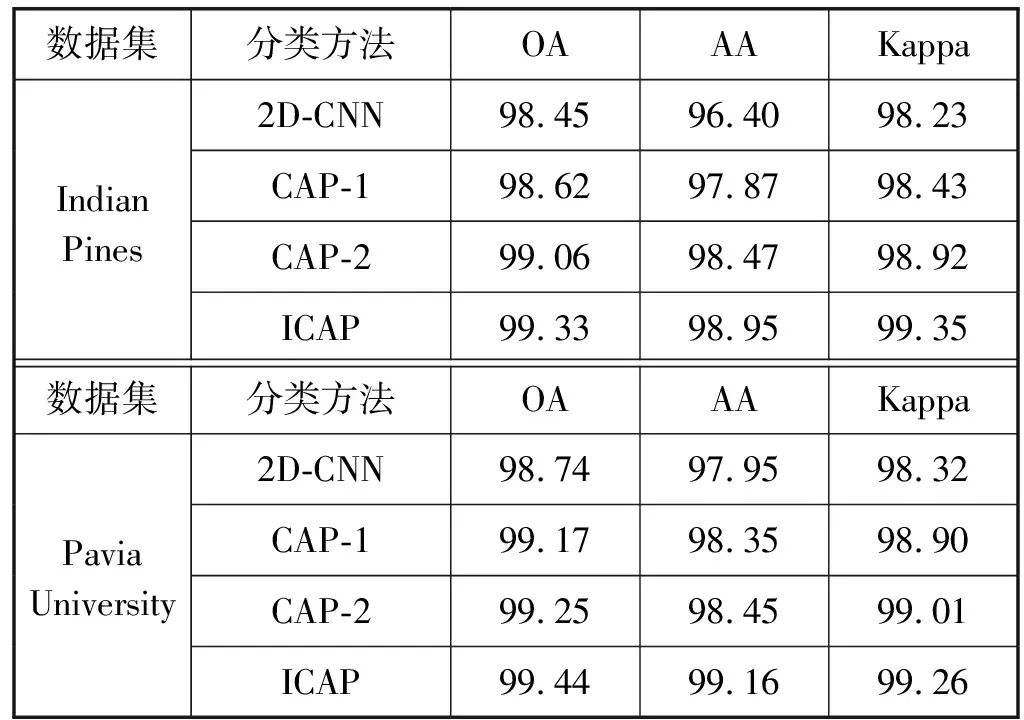
表4 各模型的分类精度对比(%)
3.4 与其他分类方法对比
为了对比其他文献中的模型,本文使用与文献中模型相同数量的训练样本与测试样本进行实验。
表5列出了各模型在两个数据集上的分类精度,文献[14]中的SSF-Net模型利用双通道卷积神经网络同时提取图像的光谱与空间信息,并采用多模态压缩双线性池化来获得空谱联合特征,进一步提升了图像分类精度。文献[15]中3D-CNN模型利用三维卷积核来提取高光谱图像的光谱与空间信息,并利用L2正则化、Dropout与构造虚拟样本技术来减轻模型的过拟合,使得模型在有限的训练样本下,仍旧有着较高的分类精度。文献[18]中的胶囊网络重新定义了胶囊结构,使其可以充分提取高光谱图像的特征信息,在多个高光谱数据集上具有较高的分类精度。文献[19]提出了一种适用于高光谱图像分类的胶囊网络模型,可以提取小样本高光谱数据集中的光谱与空间信息,具有较高的图像分类精度。
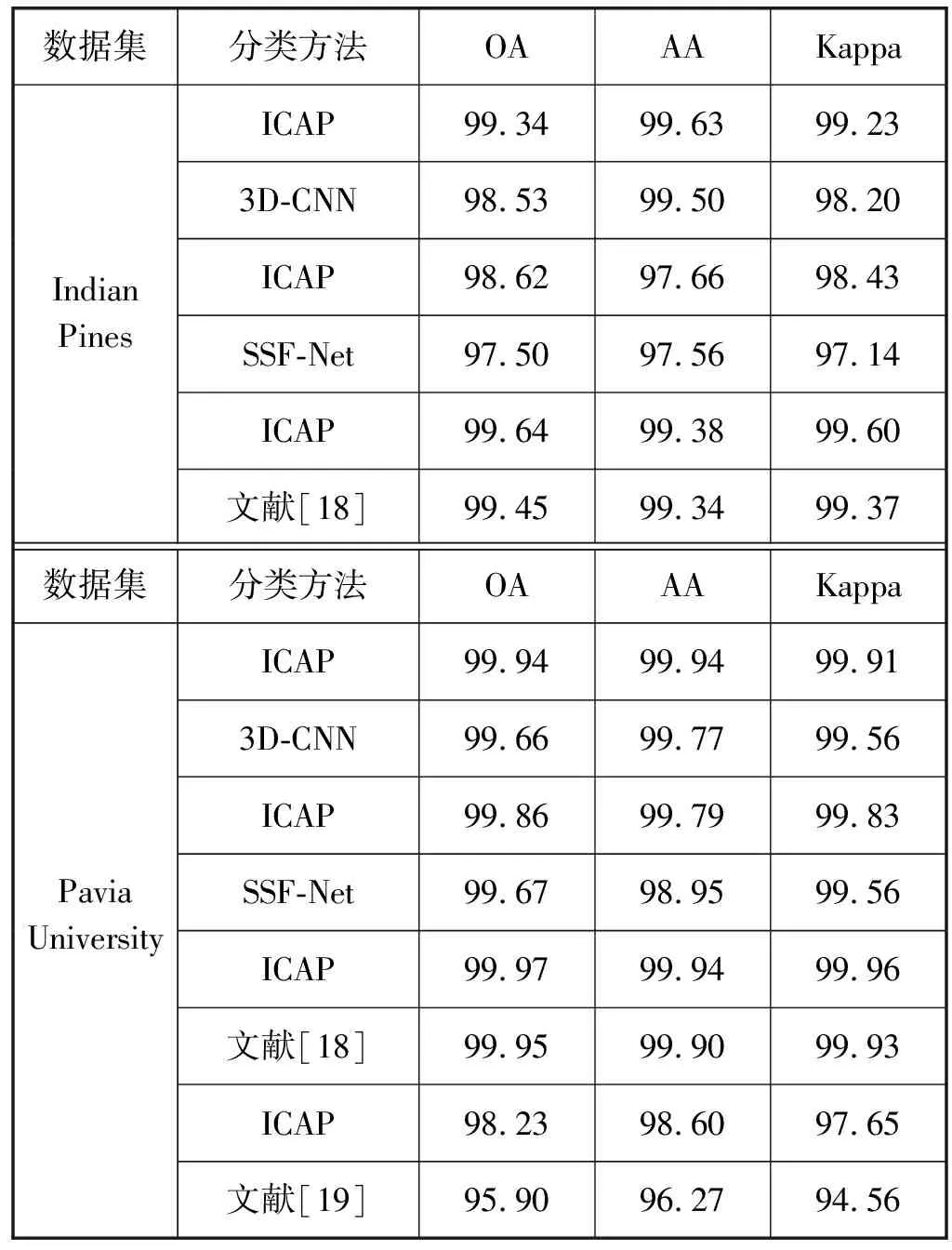
表5 各模型在两个数据集上的分类精度对比(%)
从表5中可以看出,本文ICAP模型不需要添加虚拟样本,而在Indian Pines数据集上的OA、AA、Kappa系数相比于3D-CNN模型要高出0.81%、0.13%、1.03%,在Pavia University数据集上的OA、AA、Kappa系数相比于3D-CNN模型要高出0.28%、0.17%、0.35%。本文ICAP模型在提取高光谱图像像素的空间邻域信息与光谱信息的同时,考虑了特征之间的位置关系,并且通过在模型中加入1×1卷积层与批标准化层来减轻模型的过拟合,进而提升了模型的分类能力,在Indian Pines数据集上的OA、AA、Kappa系数相比于SSF-Net模型要高出1.12%、0.10%、1.29%,在Pavia University数据集上的OA、AA、Kappa系数相比于SSF-Net模型要高出0.19%、0.84%、0.27%。此外,ICAP模型采用了双通道结构,进一步提升了胶囊网络的特征提取能力。从表5中可以看出,在相等数量训练样本的前提下,ICAP模型在高光谱数据集上的OA、AA、Kappa系数均优于文献[18-19]中的胶囊网络。
4 结 语
胶囊网络是目前深度学习领域的研究热点,在高光谱图像分类领域里有着巨大的发展潜力。由于传统CNN模型不能充分提取高光谱图像特征信息,从而导致图像分类精度不高。针对这个问题,本文基于胶囊网络给出了一种ICAP模型。实验结果表明,ICAP模型中多尺度卷积核的选择有效地改善了高光谱图像特征信息的细节提取,充分利用了胶囊网络对高光谱图像细节特征的提取能力,提取出特征之间空间位置关系,以提高图像分类精度。
猜你喜欢
农业工程学报(2022年12期)2022-09-09
计算机仿真(2022年7期)2022-08-22
农业工程学报(2022年8期)2022-08-08
计算技术与自动化(2022年1期)2022-04-15
上海师范大学学报·自然科学版(2019年5期)2019-12-13
科学24小时(2019年6期)2019-09-05
妇女之友(2018年8期)2018-09-17
光学仪器(2016年6期)2017-04-24
小学阅读指南·高年级版(2009年3期)2009-03-27
家庭医药(2009年1期)2009-02-05
