
基于华为AI开发平台的图像识别原型开发*
2022-02-19 04:26:54上海电机学院吕海龙迟冬祥
数字技术与应用 2022年1期
上海电机学院 吕海龙 迟冬祥
大数据时代,通过AI对数据就行识别及处理的方法得到了广泛的应用。对于无AI开发经验的个人或企业,不具备算法开发能力,但当有利用AI模型进行生产或数据分析的业务需求时再去学习AI开发,显然会消耗很多的时间成本。市面上有很多自动机器学习工具,开发者不需要较高的算法知识,只需要把数据上传并标注,选择合适的模型,点击开始训练,后台就能自动训练模型并部署上线。比如谷歌的AutoML、微软的Custom Vision,百度的EasyDL,以及华为云的ModelArts。
华为提供的ModelArts平台具有图形化操作界面,同时提供了常用的算法框架和预置算法,降低了AI开发的难度。针对有大量业务数据却不具备AI开发经验,无法进行高效生产的企业,本文提出了使用ModelArts平台高效开发AI模型的方案,以解决上述痛点问题,并以AI初学者为视角尝试在华为AI开发平台ModelArts上进行图像识别原型的开发和部署,完成了图片识别模型并将其部署到了网页端,验证了无经验的AI开发者基于ModelArts平台完成从AI模型开发到部署的可行性。
1 基于ModelArts的图像识别开发
ModelArts是由华为公司提供的、面向AI开发者的一站式开发平台,“一站式”是指AI开发的各个环节,包括数据处理、算法开发、模型训练、模型部署都可以在ModelArts上完成。提供海量数据预处理及半自动化标注、大规模分布式训练、自动化模型生成及端-边-云模型按需部署能力,帮助用户快速创建和部署模型,管理全周期AI工作流。笔者尝试在ModelArts平台开发了一个图片识别模型并将其部署到了网页端。
1.1 创建数据集
在进行模型开发或训练等操作之前,需要将数据集导入到华为的数据存储服务OBS中。在ModelArts中,可以在“数据管理”页面,完成数据导入、数据标注等操作,也可以导入现成的数据集,为模型构建做好数据准备。
(1)导入图片数据,标注标签并生成数据集。数据标注任务中,一般由一个人完成,但是针对数据集较大时,需要多人协助完成。ModelArts提供了团队标注功能,可以由多人组成一个标注团队,针对同一个数据集进行标注管理。
(2)导入现成的数据集。开发中,笔者尝试导入现成数据集。数据集文件格式如图1所示:

图1 数据集格式Fig.1 Data set format
1.2 使用预置算法训练数据集并生成模型
(1)选取合适的预置算法。如果不具备算法开发能力,可以使用ModelArts内置的预置算法,通过简单的调参,即可创建训练作业构建模型,提高了模型开发效率。ModelArts在AI Gallery中发布了较多官方算法,比如用于物体检测算法YOLOv5,图像分类算法ResNet等,可以帮助AI开发者快速开始训练和部署模型。笔者选用了AI Gallery提供的ResNet残差神经网络算法进行模型的图片识别模型的训练。
(2)创建训练作业训练。ModelArts提供了模型训练的设置页面(如图2所示),在此页面可以创建训练任务,调整训练参数和选取合适的算力资源。在设置模型完数据集的输入OBS路径和模型的输出OBS路径后,点击提交键即可进行训练,等待模型生成。
(3)模型部署。训练完成的模型存储在OBS路径中,可以将模型在模型部署界面(如图3所示)中导入并部署。部署为在线服务后,ModelArts提供了一个可调用的API接口,通过编写POST语句对API发起预测请求,即可预测服务返回的结果。笔者编写了调用在线服务API接口的.py程序以及基础Flask框架的Web端网页进行预测应用。整体项目分为三大部分:

图3 部署界面Fig. 3 Deployment screen
(1)在线服务接口在接收到请求后需要进行用户提供鉴权信息Token进行身份认证,为保证预测服务安全,鉴权Token为动态的,故需要编写请求代码获取Token鉴权。部分代码如下:
Url='https://iam.cn-north-4.myhuaweicloud.com/v3/auth/tokens '
payload={}
Headers={"Content-Type":"application/json; charset=utf8" }
(2)编写请求代码通过POST方式调用预测API获取预测结果,包括用Request函数发送预测请求,其中请求参数包含在服务的API,请求头Header中包含第一部中的鉴权Token,还有本地文件的所在地址,用变量Path表示。部分代码如下:
url='http://'# 此url为在线服务提供
payload={}
files=[('images',open(path,'rb'))]
headers={'X-Auth-Token':token.get_token() }
response=requests.request("POST",url,headers = headers,data=payload,files=files )
(3)编写基于Flask的网页交互代码并在服务器端部署,包括导入Flask框架到Python环境,编写Html网页代码并用render_template函数作网页代码的映射。Flask是由Python实现的一个Web框架,使开发者可以使用Python语言快速实现一个网站或Web服务。部分代码如下:
from flask import Flask,render_template, request,jsonify
from werkzeug.utils import secure_filename
from datetime import timedelta
import os
app=Flask(__name__)
# 创建app应用
app.debug=True
# 输出
@app.route('/')
def hello_world():
return'Hello World!'
# 设置静态文件缓存过期时间
app.send_file_max_age_default=timedelta( seconds=1)
# 添加路由
@app.route('http://114.215.184.36:5000/upload',methods=['POST','GET'])
def upload():
if request.method=='POST':
# 通过file标签获取文件
f = request.files[ 'file' ]
# 当前文件所在路径
basepath=os.path.dirname(__file__)
# 一定要先创建该文件夹,不然会提示没有该路径
upload_path=os.path.join(basepath,'staticimage',secure_filename(f.filename))
# 保存文件
f.save(upload_path)
# 调用api函数
result=get_result(upload_path)
# 返回上传成功界面
return render_template('upload_ok.html',result= result)
# 重新返回上传界面
return render_template('upload.html')
if __name__=='__main__':
app.run(debug=True,port=8000)
网页端简单的交互界面如图4所示。

图4 具备图片识别功能的网页端Fig.4 Web page with image recognition function
2 使用PyCharm ToolKit工具基于算法代码实现模型开发
对于有人工智能编程基础的开发者,常使用PyCharm工具开发算法或模型。对于没有长期长时间训练作业的开发者,将本地代码提交到ModelArts训练环境进行训练,可以减少诸如GPU之类的算力硬件成本,ModelArts的AI平台也提供了多种高性能的GPU和CPU供开发和选择,提高模型开发的灵活性以及训练的效率和时间。为方便快速将本地代码提交到公有云的训练环境,ModelArts提供了一个PyCharm插件工具PyCharm ToolKit,协助用户完成代码上传、提交训练作业、将训练日志获取到本地展示等,开发者只需要专注于本地的代码开发即可。
笔者尝试通过ModelArts提供了的PyCharm插件工具PyCharm ToolKit开发一个基于keras框架的VGG16卷积神经网络算法的猫狗识别模型。
2.1 上传数据集
在实际生产中,用户可能会碰到训练数据为压缩格式文件,若此时依旧按照上述数据集文件格式上传OBS,则需要先对本地数据集进行解压操作,再上传至OBS,文件大小和数量的增加会导致上传操作过于繁杂,时间效率低。笔者提供了上传压缩文件后通过指令解压的方式解决了这一问题。用户可以通过导入Moxing Framework模块编辑本地和OBS间的传输代码来解决此问题。Moxing Framework为Moxing提供基础公共组件。目前,提供的Moxing Framework功能中主要包含操作和访问OBS组件。
在本开发过程中,需要将533MB的猫狗数据集压缩文件上传至OBS,在上传后,只需要在训练代码中添加通过Moxing库下载压缩文件进行解压的代码即可。
2.2 安装ToolKit工具并登录
(1)在华为ModelArts的开发手册中可以获取ToolKit工具包的文件,打开本地PyCharm,选择菜单栏的“File > Settings”,弹出“Settings”对话框。在“Settings”对话框中,首先单击左侧导航栏中的“Plugins”,然后单击右侧的设置图标,选择“Install Plugin from Disk”,弹出文件选择对话框,如图5所示。

图5 选择从本地安装插件Fig.5 Selecting to install the plug-in locally
(2)在弹出的对话框中,从本地目录选择ToolKit的工具包,然后单击“OK”,如图6所示。

图6 选择插件文件Fig.6 Selecting the plug-in file
(3)单击“Restart IDE”重启PyCharm。在弹出的确认对话框中,单击“Restart”开始重启。重启成功后,打开一个Project,当PyCharm工具栏出现“ModelArts”页签,表示ToolKit工具已安装完成,如图7所示。
图7 重启PyCharmFig.7 Restarting PyCharm
(4)当PyCharm工具栏出现“ModelArts”页签,表示ToolKit工具已安装完成,如图8所示。

图8 安装成功Fig. 8 Successful installation
2.3 导入训练代码并进行训练
(1)将训练代码的文件夹命名为‘src’,便于之后的文件路径填写,如图9所示。

图9 将训练代码的文件夹命名为srcFig. 9 Names the folder for the training code src
(2)在Pycharm工具栏中,选择“ModelArts->Edit Credential”进行登录。
为了确保服务的安全性,此处需要通过访问密钥(AK/SK)进行登录。登录华为云,在页面右上方单击“控制台”,进入华为云管理控制台。在控制台右上角的帐户名下方,单击“我的凭证”,进入“我的凭证”页面。在“我的凭证”页面,选择“访问密钥>新增访问密钥”。填写该密钥的描述说明,单击“确定”,如图10所示。

图10 登录框Fig.10 Login box
根据提示单击“立即下载”,下载密钥,即可获得一个名为“credentials”的csv格式文件,打开即可看到访问密钥,如图11所示。

图11 获取访问密钥Fig.11 Obtaining the access key
(3)登陆后,选择“ModelArts->Edit Training Job Configuration”在弹出的对话框中,如图12所示示例配置训练参数:

图12 配置训练参数Fig.12 Configuring training parameters
此处AI引擎为TensorFlow-TF-1.13.1-pytho3.6。“Boot File Path”为本地训练项目的路径,“Directory”为训练代码路径。“OBS Path”用于存放训练输出模型和训练日志的目录,“Data Path in OBS”为训练集所在目录。“Specifications”为训练使用资源类型,目前支持公共资源池的CPU和GPU,规格与ModelArts管理控制台中训练作业支持的规格一致且同步。“Compute Nodes”为计算资源节点个数。数量设置为1时,表示单机运行;数量设置大于1时,表示后台的计算模式为分布式。“Running Parameters”为运行参数。如果您的代码需要添加一些运行参数,可以在此处添加,多个运行参数使用英文分号隔开,例如“key1=value1;key2=value2”。此参数也可以不设置,即保持为空。
设置好后,点击“Apply and Run”,即可在本地开始调用云端ModelArts平台训练模型,开发者可以在“ModelArts Training Log”框内看到损失值,准确率等参数训练的更新情况如图13所示。
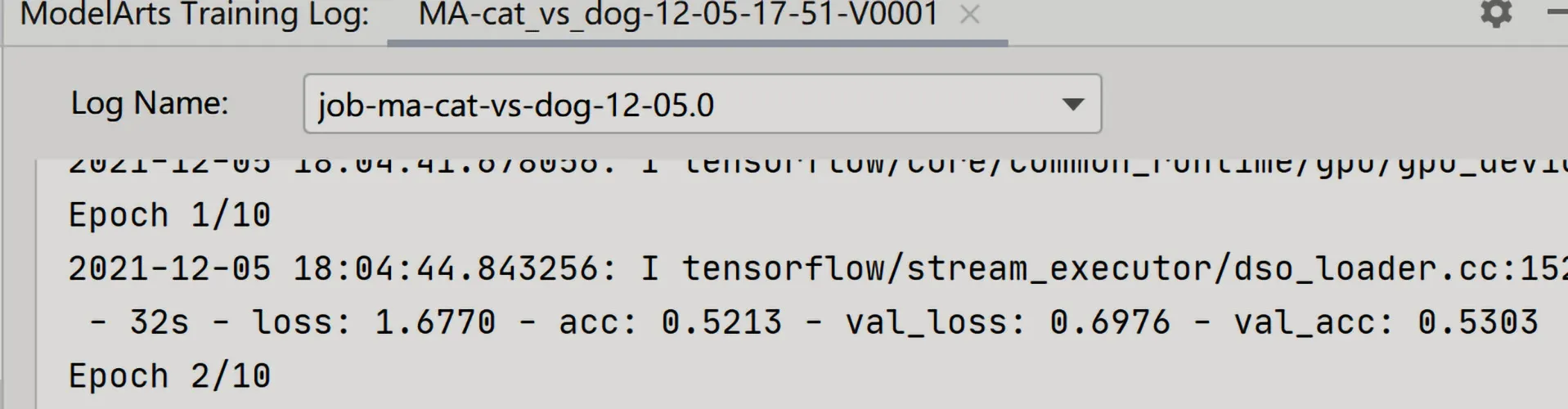
图13 训练更新情况Fig.13 Training update
当看到“ModelArts Event Log”框中出现下面的指示语时,即说明模型训练成功,如图14所示。

图14 训练成功Fig.14 Successful training
训练成功后,可以在OBS的模型输出路径看到训练输出模型的PB文件,开发者可以使用模型文件在ModelArts云端进行在线部署。有后端开发经验的开发者也可以将模型下载到本地,部署在自己的服务器上。本次实验笔者选择将模型文件在ModelArts云端进行在线部署。
此次的训练代码是基于TensorFlow的Keras框架的VGG16神经网络算法。VGG16卷积神经网络算法对图片识别非常有效。Keras是一个用Python编写的高级神经网络API,它能够以TensorFlow,CNTK,或者Theano作为后端运行。自2017年起,Keras得到了TensorFlow团队的支持,其大部分组件被整合至TensorFlow的Python API中。在2018年TensorFlow 2.0.0公开后,Keras被正式确立为TensorFlow高阶API,即tf.keras。tf.keras是Keras API在TensorFlow里的实现。这是一个高级API,用于构建和训练模型,同时兼容TensorFlow的绝大部分功能。tf.keras使得TensorFlow 更容易使用,且保持了灵活性和性能。
2.4 在线部署
(1)在OBS服务中,进入训练设置时自定义的训练模型输出路径下面的output文件夹下,放入编写好的模型配置文件“config.json”和模型推理文件“customize_service.py”。模型配置文件描述模型用途、模型计算框架、模型精度、推理代码依赖包以及模型对外API接口。模型推理文件执行预测数据的预处理功能,如图15所示。

图15 在输出路径放入推理及配置文件Fig.15 Puts the inference and configuration files in the output path
(2)上传后回到Pycharm界面,点击左下页面的“ModelArts Explorer”,在跳出来的界面中,选择训练本次训练项目的最高版本(当前为V0001),点击右键,选择“Deploy to Service”,如图16所示。

图16 部署服务Fig.16 Deploying the service
在弹出窗口内点击“Auto Stop”可设置在线服务的自动关闭时间(当前为1小时候关闭)。在 “Specifications”选项中选择在线服务的资源(当前为“gpu型”)设置完毕后点击“ok”,即可进行在线服务部署,如图17所示。

图17 选择部署资源Fig.17 Selecting deployment resources
开发者依旧可在“ModelArts Event Log”中查看在线服务部署进度。部署成功后,“ModelArts Event Log”中会出现在线服务的API供开发者调用,如图18所示。

图18 显示在线服务部署成功Fig.18 Shows the successful deployment of the online service
3 结论
与传统AI开发流程相比,ModelArts平台的图形化界面大大减轻了开发这的代码学习成本。在数据集的制作与创建流程中,平台完全为图形化界面,对于图像数据,用户只需对图像进行分类标注或者对内容圈选操作,无需制作例如XML等格式的图像信息文件,降低了学习成本和时间成本。同时平台具有团队标注功能,可进行多人线上标注,提高了数据集制作效率。在模型训练流程中,ModelArts在AI Gallery中提供了较多的官方算法以及华为自研的高效算法,通过简单的调参,即可创建训练作业构建模型,大大提高了模型开发效率和模型的准确率,在最后的模型部署流程中,华为提供了在线服务API,通过简单的调用即可完成模型的预测功能。笔者从数据集导入到模型部署,在ModelArts平台完成了完整的AI开发流程,最终生成了具有图片识别的功能的网页端,验证了无经验的AI开发者利用AI开发平台进行模型开发实现业务需求的可行性。
另外对于有一定基础的AI开发者,ModelArts平台也提供了将训练代码上传云端进行训练的模型开发方式,如果订阅算法不能满足需求或者用户希望迁移本地算法至云上训练,可以考虑使用ModelArts支持的预置训练引擎实现算法构建。在ModelArts中,这种方式称为“使用自定义脚本训练”。ModelArts支持了诸如TensorFlow、pytorch、以及华为自研的Ascend等大多数主流的AI引擎。同时,平台提供多种高性能的GPU和CPU供开发和选择,可以减少诸如GPU之类的算力硬件成本,提高了模型开发的灵活性以及训练的效率和时间。
使用AI开发平台进行AI模型的开发和部署大大提高了生产效率。因此,无论是资深的AI开发人员还是AI初学者,使用类似ModelArts的AI开发平台进行生产必然是未来的趋势。
猜你喜欢
成都信息工程大学学报(2021年5期)2021-12-30 06:25:14
今日农业(2021年7期)2021-07-28 07:07:16
非公有制企业党建(2020年5期)2020-06-16 08:46:00
动漫星空(2018年11期)2018-10-26 02:24:02
动漫星空(2018年2期)2018-10-26 02:11:00
动漫星空(2018年9期)2018-10-26 01:16:48
动漫星空(2018年5期)2018-10-26 01:15:02
太空探索(2016年9期)2016-07-12 10:00:02
CHIP新电脑(2016年3期)2016-03-10 13:06:42
电脑迷(2015年8期)2015-05-30 12:27:10
