
机器学习在材料服役性能预测中的应用
2022-02-18 01:32王红珂刘啸天林磊孙海涛吕云鹤张晏玮薛飞
装备环境工程 2022年1期
王红珂,刘啸天,林磊,孙海涛,吕云鹤,张晏玮,薛飞
(1.苏州热工研究院有限公司,江苏 苏州 215004;2.生态环境部核与辐射安全中心,北京 100082)
材料在服役过程中,由于受光照、热能、机械能、辐照、潮湿等因素的影响,会逐步发生老化,进而导致材料性能下降甚至失效。材料失效不仅带来巨大的经济损失,造成环境污染和资源浪费,甚至可能酿成安全事故,引发各种社会问题。因此,材料服役性能研究和服役寿命预测一直是材料领域的研究热点之一。
在早期研究中,通常将材料放置在自然环境或人工模拟环境中进行大量性能试验,并在试验过程中监测材料性能的变化情况。然后找出试验条件和材料性能之间的关系,进而预测材料服役性能的变化趋势和服役寿命。但这种方法通常需要投放大量的试样,试验周期漫长,无法真实反映出实际环境中不同因素之间的协同作用和综合效应,在客观性和普适性方面存在不足。
目前,材料服役性能研究主要分为四个方向:加速模拟实验、力学性能研究、数学模型和数据挖掘。其中,加速模拟实验是最简便可行的方案,但加速过程会掩盖材料服役的关键细节,难以区分不同条件对材料性能影响的细微差别。力学性能研究通过经典力学、断裂力学、疲劳力学、损伤力学等方法建立材料力学方程,然后进行力学分析和服役性能预测。但对于受力复杂的情况,建立的力学方程非常复杂,并且很难反映材料的真实受力情况。数学模型通过短期试验,推测长期服役条件下材料性能的变化情况,但该方法预测误差较大、计算复杂、普适性有待进一步研究。
数据挖掘通过机器学习,对大量材料服役数据进行学习和规律总结,然后对材料服役性能进行预测,目前已经在医药、生物信息、图像识别、故障诊断等领域取得了应用成果。文中首先阐述了机器学习在材料服役性能预测中的一般流程及常用机器学习模型原理,并对各种模型在材料服役性能研究应用中的特点进行总结;然后具体研究了机器学习在RPV钢辐照性能预测中的应用。研究结果为材料服役性能预测提供了新的方法和参考。
1 基于机器学习的材料服役性能预测
机器学习在材料服役性能预测的一般流程如图1所示,主要包括两个过程:1)从材料基因数据库中选择要处理的数据并进行预处理、特征选择和样本划分,然后通过机器学习模型进行训练、测试和评估,并获得最优模型及模型参数;2)通过最优模型对新数据进行服役性能预测,获得最终结果。
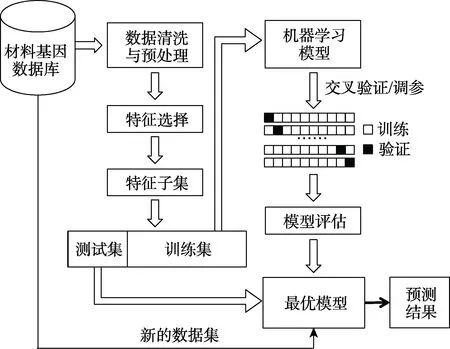
图1 基于机器学习的材料服役性能预测流程Fig.1 Prediction process of material service performance based on machine learning
材料基因数据库为源数据,可源于试验、测试、仿真计算或其他数据库。数据库中数据的来源、格式、完整度等存在差异,需要进行数据清洗使其符合机器学习模型的输入要求。数据清洗包括异常值剔除、缺失值填充、重复样本删除、数字化等。对于不同量纲或存在数量级差异的特征值,还需要进行归一化或标准化处理,消除量纲带来的偏差。
数据清洗和预处理后需要进行特征选择,找出和目标相关度高的特征进行学习和训练,消除无关特征带来的噪声偏差。常用的特征选择方法有过滤式、包裹式和嵌入式,筛选后的特征子集可提高模型的训练效率和预测精度。
获得特征子集后,通过分层抽样将其划分为训练集和测试集,测试集约占总样本的20%~30%。然后选择合适的模型,并在训练集上进行模型训练和参数调优。模型训练后,根据预测结果进行模型评估,常用的评估指标有平均绝对误差、均方根误差和决定系数等。
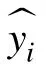
1)平均绝对误差MAE。

2)均方根误差RMSE。
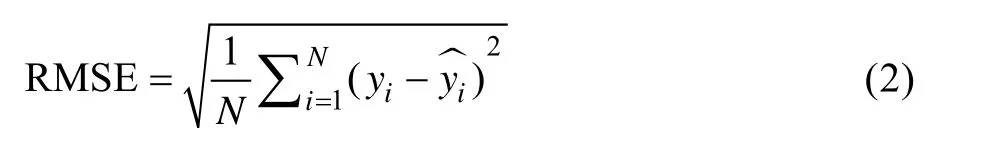
3)决定系数。
决定系数用来衡量模型对数据集波动的解释程度,最大值为1。越接近1,表明模型的拟合越好。
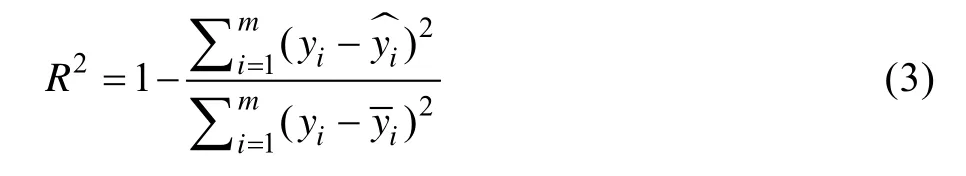
根据模型评估结果保存最优模型及参数,当有相同场景的新数据输入时,可直接通过最优模型对材料属性进行预测。
2 机器学习模型
根据训练数据是否拥有标记信息,机器学习可分为监督学习和无监督学习。材料服役性能预测属于监督学习,常用的学习模型有支持向量机、人工神经网络、决策树和随机森林等。
2.1 支持向量机
支持向量机的目的是获得N维空间的最优超平面,其用于二维空间的分类如图2所示。支持向量机可解决三类问题:1)样本线性可分,通过硬间隔最大学习一个分类器;2)样本近似线性可分,通过软间隔最大学习一个分类器;3)样本线性不可分,通过核技法将低维非线性问题转化为高维线性问题,然后学习一个非线性支持向量机。支持向量机可用于分类也可用于回归,回归问题的目标函数为:
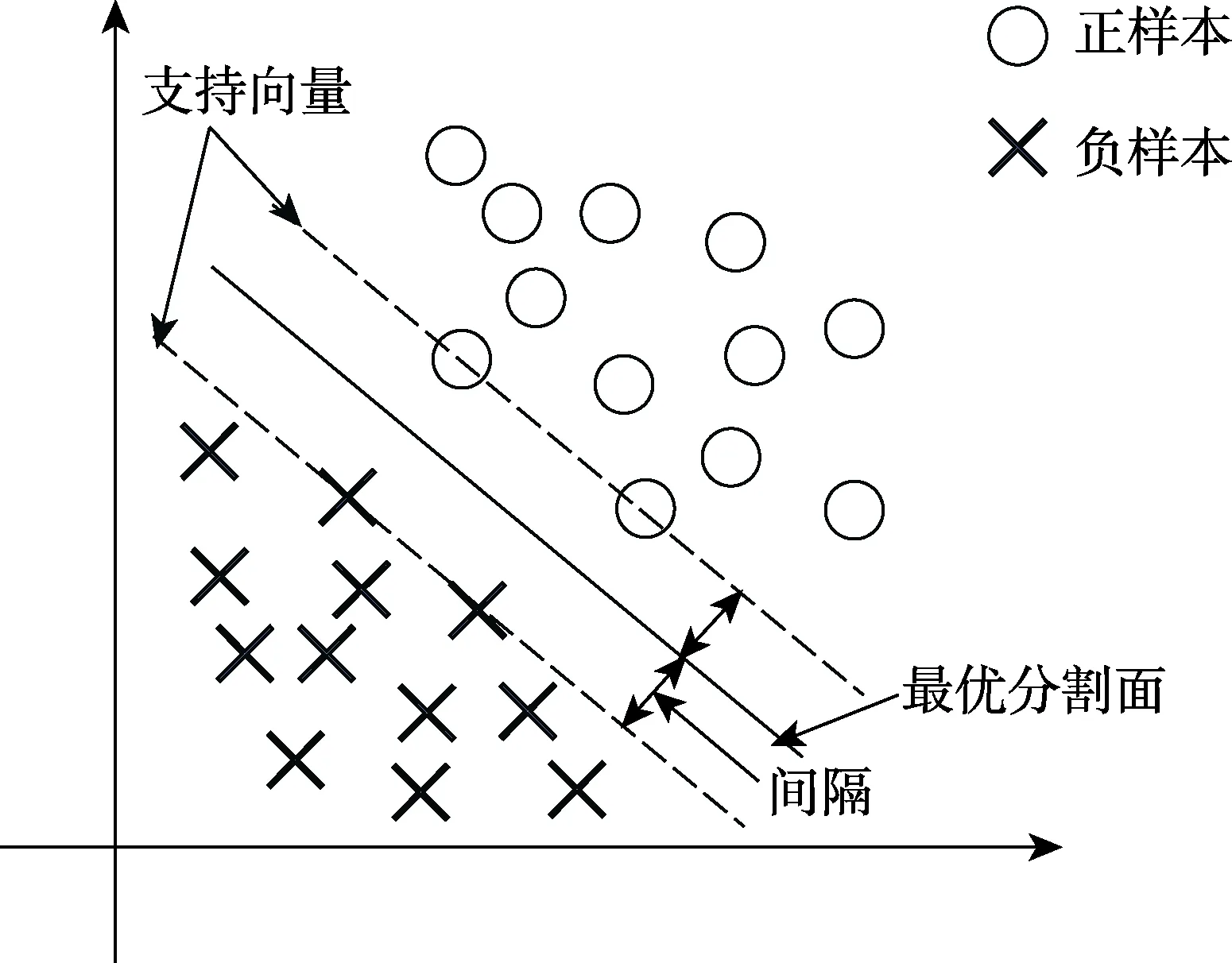
图2 支持向量机分类示意Fig.2 Classification schematic diagram of support vector machine (SVM)
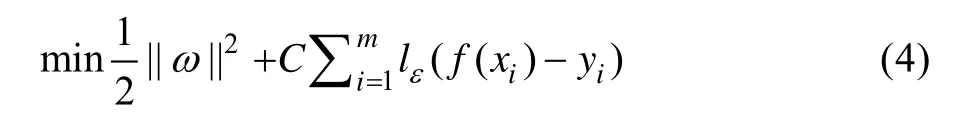
式中:= (,,… ,ω)为超平面的法向量;为正则化系数;l为损失函数。
加入核函数后,式(4)可表示为:
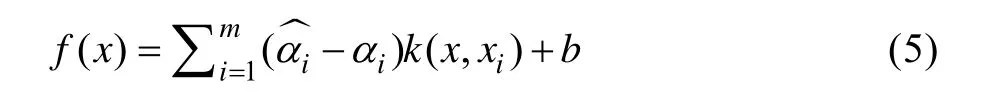
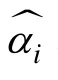
2.2 人工神经网络
人工神经网络结构如图3所示,主要包括正向传播和误差反向传递两个过程。其中,正向传播的输出可表示为:
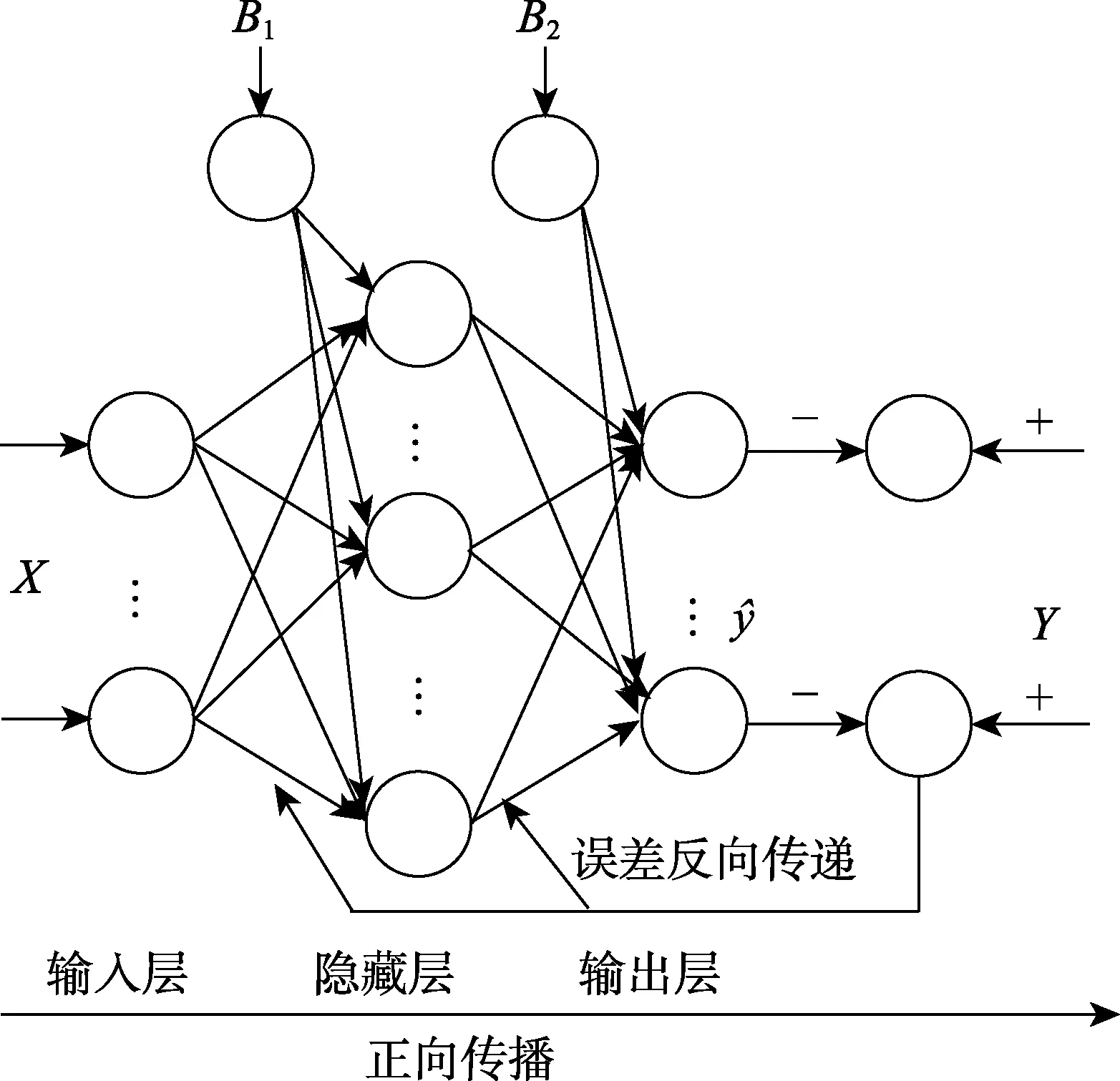
图3 人工神经网络结构Fig.3 Structure of artificial neural network
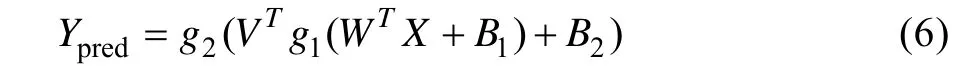
式中:、、分别为输入层到隐藏层的权重、偏置项和激活函数;、、分别为隐藏层到输出层的权重、偏置项和激活函数,为模型输出。
误差反向传递是根据预测值与期望值的偏差逐层回归计算正向传播过程中的误差,并迭代更新各层神经元的权值,回归问题的损失函数为:
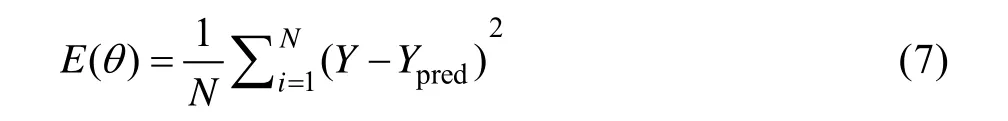
然后根据损失函数和正向传播公式迭代更新各层的权值及偏置项,并使损失函数越来越小。通过建立多层神经网络结构,适当增加神经元个数和样本数量,可提高模型的拟合能力。
2.3 决策树
决策树是一种基于树结构划分的学习算法,可分为分类树和回归树,图4为一个深度为3层的分类树。决策树主要包括决策树生长和剪枝两个步骤:1)决策树生长采用的属性选择方法有ID3、C4.5和Gini指数,ID3和C4.5分别采用信息增益和信息增益率进行属性选择;2)决策树剪枝是为了防止模型过拟合,并提高模型的训练速度和识别能力,通常采用“预剪枝”和“后剪枝”两种策略。
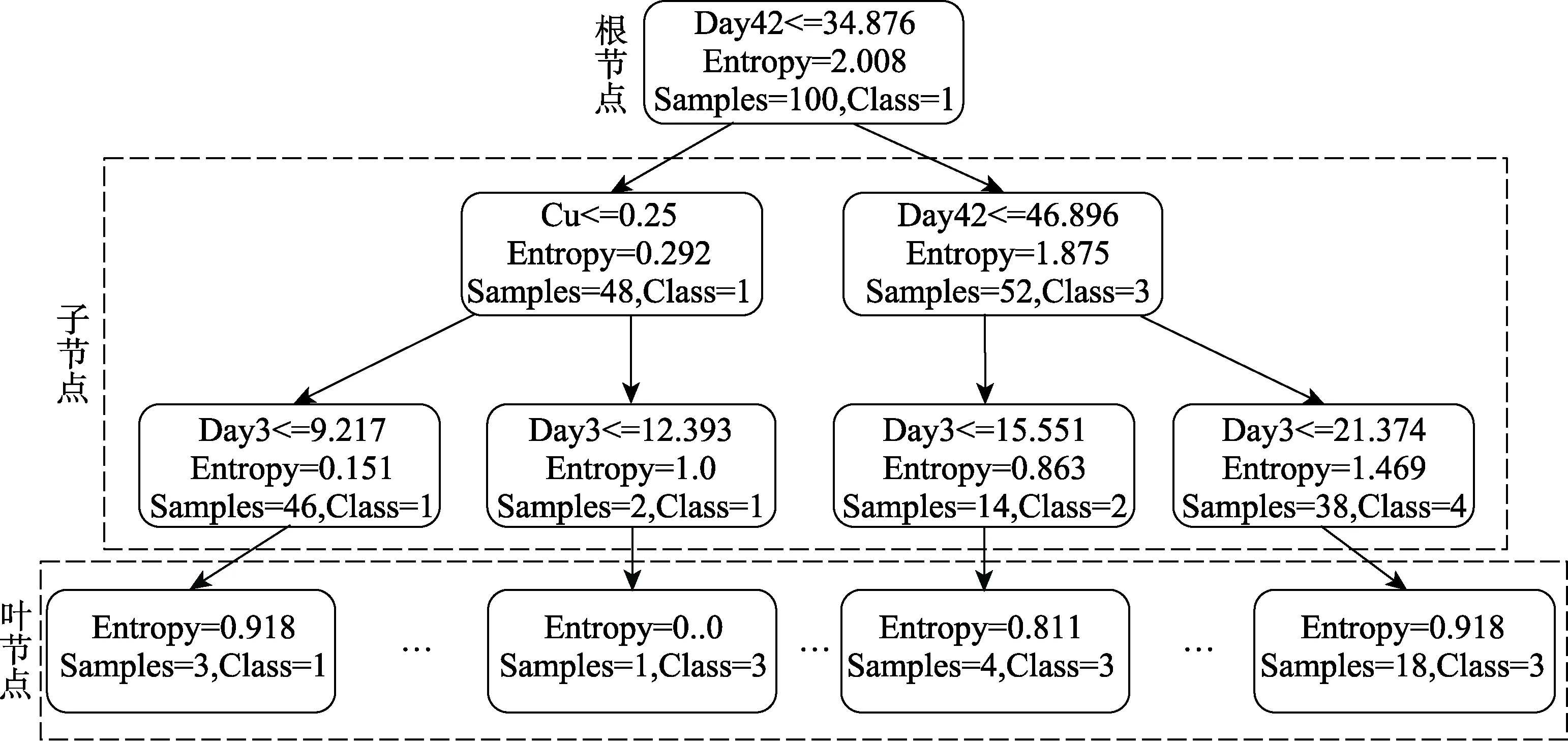
图4 决策树结构示意Fig.4 Schematic diagram of decision tree structure
2.4 随机森林
随机森林回归算法的流程如图5所示,其是一种基于决策树模型的Boosting集成算法,可用于分类、回归和特征选择。首先从原始数据中随机抽取若干个样本组成样本子集,然后基于每个样本子集建立决策树,并构成树模型集合{(,),= 1,2,…}。对于回归问题,(,)采用CART算法生成回归树,θ决定每棵树的生长过程。
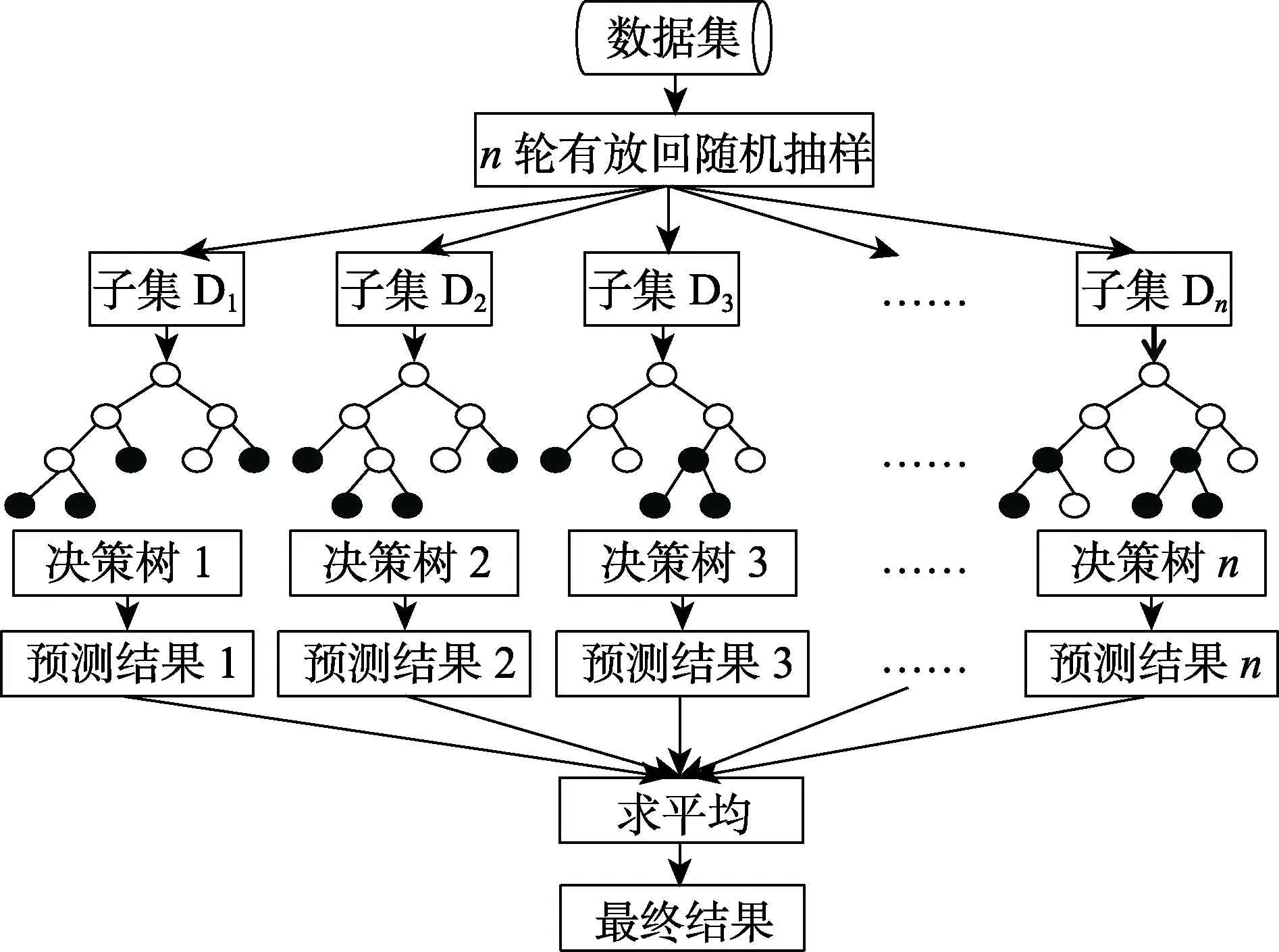
图5 随机森林回归模型结构Fig.5 Structure of random forest regression model
3 机器学习在材料服役性能预测中的应用
材料服役性能与其结构、成分、环境条件等密切相关,不同因素之间的相互作用复杂。机器学习可以从大量服役数据中获得各因素之间的影响规律,并对服役性能进行预测。材料的服役性能主要包括腐蚀、磨损、辐照和疲劳等。
3.1 腐蚀性能预测
影响材料腐蚀的因素包括化学成分、组织结构、加工工艺、服役条件等,并且不同因素又包含多个维度信息,通常采用人工神经网络、支持向量机等拟合能力强、适用纬度高的模型进行腐蚀性能预测。
杜翠微等采用人工神经网络建立了碳钢和低合金钢的腐蚀速率预测模型,探究了化学成分、环境因素及多因素耦合作用对海水中金属材料腐蚀性能的影响。训练数据为我国典型海水区域长达16 a的腐蚀样本,模型输入为合金主要元素成分、pH、温度、溶解氧、盐度、生物附着物等。当仅考虑环境因素时,模型的预测精度达到75%;当同时考虑环境因素和材料元素含量时,模型的预测精度可提高到90%以上。
LY12CZ铝合金是飞机承重构件的主要材料,刘延利等]通过盐雾试验获得了铝合金材料的腐蚀试样,并对试样进行疲劳试验和腐蚀深度测量。然后基于腐蚀温度、腐蚀时间、最大点蚀深度及疲劳额定强度, 建立了人工神经网络模型,模型对试样最大腐蚀深度的预测误差为7.24%,对疲劳额定强度的预测误差为1.63%。
为验证RE-Ni-Cu合金铸铁在碱液中的腐蚀性能,王玉荣等通过静态质量损失腐蚀试验获得了35组腐蚀样本数据,然后建立了合金成分、腐蚀时间、碱液温度与合金铸铁腐蚀深度的RBF神经网络模型。RBF神经网络对合金铸铁腐蚀深度的预测误差为8.09%,对样本的耐腐蚀等级和耐腐蚀评价准确率达到100%。
海底管道腐蚀速率的有效预测可减少管道失效风险,李响等基于Q235钢材海洋挂片的腐蚀数据建立了环境温度、含氧量、含盐量、pH和腐蚀速率之间的SVM模型。首先采用遗传算法对模型参数进行优化,优化后的模型对试样腐蚀速率的预测误差小于3%,优于BP神经网络模型。
针对长输管道腐蚀速率的预测,马钢等建立了PSO-SVM模型,模型输入为CO含量、硫化物含量、输送温度、输送压力和流速,输出为管道腐蚀速率。然后分别采用粒子群算法(PSO)、遗传算法(GA)、交叉验证(CV)、最小二乘法(LS)和果蝇算法(FOA)对模型参数进行优化。预测结果见表1,其中PSOSVM模型的平均绝对误差和均方根误差最小,分别为0.58%和6.18×10,但该模型的训练时间较长,仍需进一步优化。
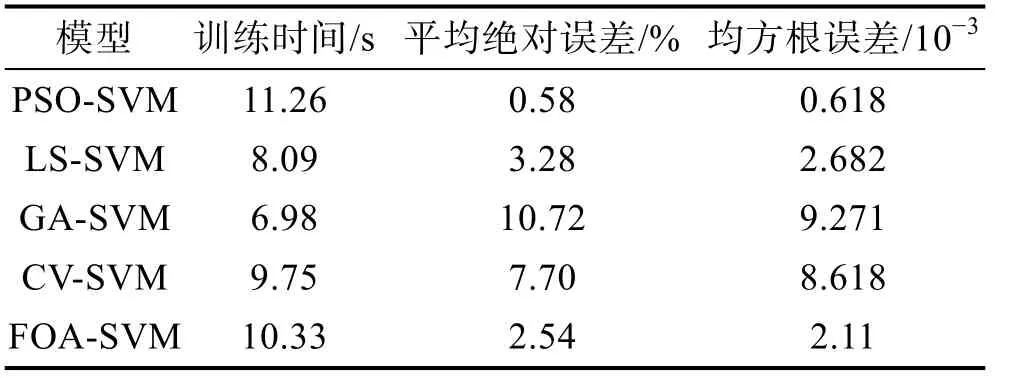
表1 不同模型的时间及预测误差[17]Tab.1 Prediction time and error of different models[17]
支持向量机(SVM)可有效避免过拟合和局部极小值问题,适用于数据样本较小、特征维度中等的数据集。但是SVM模型参数对预测结果影响较大,通常结合主成分分析法、遗传算法、粒子群优化算法、交叉验证和最小二乘法等对模型参数进行优化,并采用优化后的参数进行模型训练和预测,从而提高模型效率和预测精度。
3.2 磨损性能预测
磨损与材料硬度、受力状态、摩擦系数等因素有关,但这些参数通常难以全部准确获得,容易造成数据缺失,通常采用对缺失值容忍度好的随机森林模型进行预测。由于磨损也是设备机械故障的一个重要原因,但磨损故障样本较小,容易造成样本不均衡,因此可选择适用于小样本的支持向量机模型进行预测。
随机森林具有可解释性好、对缺失值及异常值容忍度高等特点,可用于降维和重要特征筛选。赵帅等提出了一种基于随机森林和主成分分析法相结合的刀具磨损状态评估模型,首先通过降维获得刀具磨损的特征主分量,然后对刀具磨损状态进行评估,模型对刀具磨损状态的评估准确率达到94.3%。降维和重要特征筛选提高了模型的效率和评估精度,降低了噪声对评估结果的影响,增强了模型的鲁棒性。
铁谱分析法是航空发动机磨损故障诊断的常用方法,但该方法依赖于专家经验和人工判断,诊断误差较大且效率很低。张建等提出一种基于免疫算法优化的支持向量机模型,首先通过免疫算法对模型的惩罚因子、松弛变量等进行优化,然后对航空发动机故障类型进行预测,预测准确率可达98%,添加了2%的噪声后,预测准确率仍大于95%。
人工神经网络具有自适应性好、非线性建模能力强等优点,适用于特征维度高、规律复杂的场景。针对聚酰胺复合材料(PA6)磨损性能的预测,吕若云等提出一种基于BP神经网络和RBF神经网络的混合神经网络,结构如图6所示。模型输入为材料成分、载荷和转速,输出为摩擦因数和磨损率。混合神经网络对材料的摩擦因数、磨损率的预测误差分别为3.01%和0.32%,为材料磨损性能的研究节省更多时间和成本。
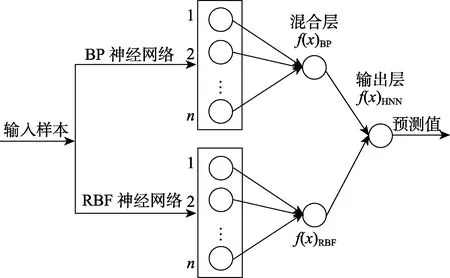
图6 混合神经网络结构[20]Fig.6 Structure of hybrid neural network[20]
磨损量和切削力通常采用解析法或经验公式进行预测,但存在预测精度低、数学模型复杂等局限性。李鑫等将改进后的神经网络用于合金车削刀具磨损量和切削力的预测,预测结果见表2,神经网络的平均预测误差为2.4%,小于经验公式4.9%的预测误差。但是神经网络的预测精度高度依赖于训练样本,更倾向于训练样本范围内的数据,并且缺乏对切削加工过程中物理本质的描述,可解释性差。
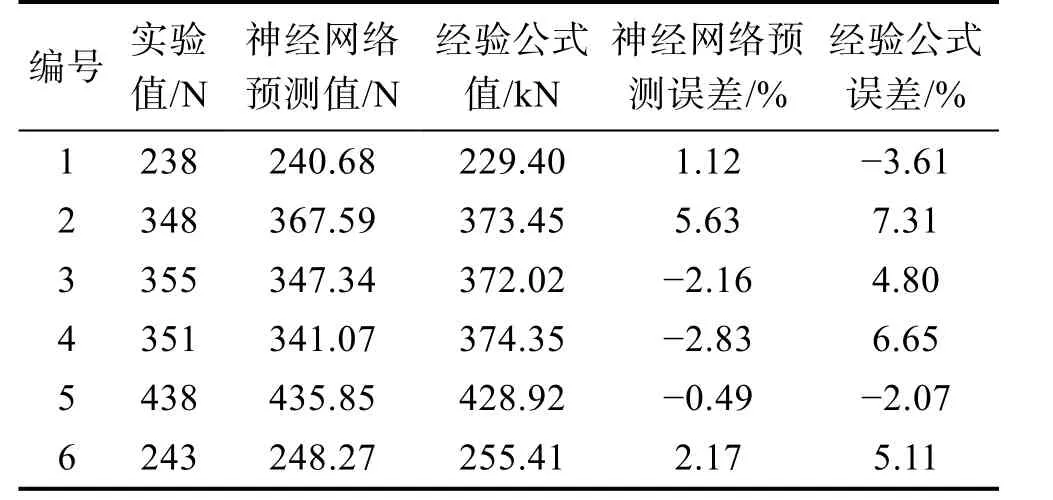
表2 神经网络模型与经验公式对刀具铣削力的预测结果[21]Tab.2 Prediction results of tool milling force by neural network model and empirical formula[21]
3.3 辐照性能预测
压力容器的辐照性能与材料成分、辐照条件、微观结构等密切相关,Mathew等提出一种基于人工神经网络的压力容器辐照脆化预测模型,模型输入为化学成分、辐照温度、中子注量和注量率,输出为材料的转变温度。人工神经网络可以较好反映出材料成分、辐照条件与辐照转变温度之间的关系,预测结果与试验结果基本一致。
针对辐照环境下材料硬度的预测,Kemp等提出了一种基于贝叶斯框架的人工神经网络模型,并分析了温度、辐照剂量、化学成分对辐照后马氏体钢屈服应力的影响。神经网络模型可以很好地捕捉到屈服应力与化学成分及辐照条件之间的非线性关系,预测结果有助于材料性能试验设计及缺失信息的补充。
Castin等提出了两种不同的人工神经网络模型,并用于压力容器钢辐照后屈服应力的预测。其中贝叶斯训练神经网络的预测结果更接近于试验值,预测精度要好于BP神经网络。通过对现有数据的训练和模型优化,实现了高中子注量条件下材料的辐照性能预测。
高功率微波辐照条件下电子元器件会发生损伤失效,金焱等采用支持向量机对电子元器件的损伤概率进行预测,同时采用模糊神经网络在相同条件下对算例进行了预测分析。支持向量机和模糊神经网络都较好地获得了预测结果,但在小样本条件下支持向量机的预测精度更高,预测结果也更为稳定。
3.4 疲劳性能预测
疲劳是指交变载荷作用下结构产生裂纹或断裂的一种现象,通常用疲劳寿命或疲劳强度表示。材料疲劳失效的因素有很多,如材料成分、加工工艺、表面状态、受力情况等。不同因素的细微差别都可能造成疲劳性能的较大差异,因此需要根据材料疲劳失效因素的维度、样本数量、数据完整度等选择合适的学习模型。
Agrawal等基于NIMS提供的钢材料疲劳数据集,对材料疲劳性能影响因素进行重要性筛选,然后采用数十种模型对材料疲劳寿命进行预测。其中人工神经网络、决策树、多项式回归模型的预测精度都达到了预期效果,模型均方根误差最小为26.44。
为预测316不锈钢的低周疲劳寿命,Mathew等采用神经网络对不同温度和氮含量条件下各因素对材料疲劳性能的影响进行研究。其中,人工神经网络可准确预测316不锈钢在任何温度条件下的疲劳寿命,预测误差为5.4%,具有较高的精度和鲁棒性。
尽管人工神经网络已经在复杂材料疲劳性能预测中发挥出良好的作用,但在材料疲劳样本较少时容易出现过拟合和局部极小值,模型预测精度大大降低。吴峰崎等建立了基于支持向量机的材料疲劳寿命预测模型,模型预测误差为7.91%,可以在较少样本条件下实现材料疲劳寿命预测。
3.5 模型对比分析
通过对各种机器学习模型在材料服役性能预测中的应用分析,不同服役数据的特征不同、数据分布及特征复杂度存在差异。因此需要根据具体的应用场景及数据特点选择合适的模型进行训练和性能预测,常用机器学习模型的特点及使用场景见表3。
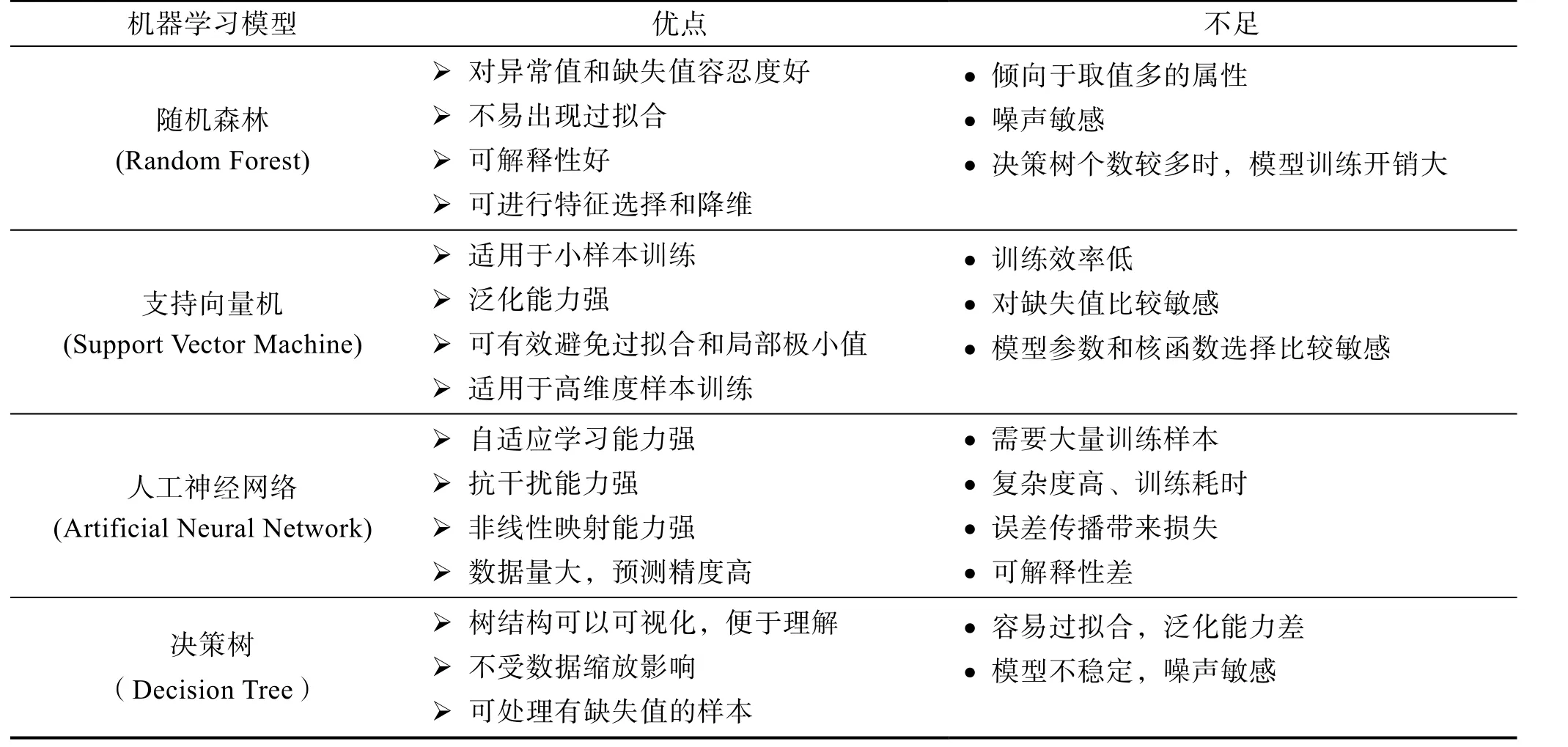
表3 常用机器学习模型性能对比Tab.3 Performance comparison of common machine learning models
4 基于模型融合的RPV钢辐照性能预测
4.1 辐照数据
文中所用的RPV钢辐照数据来源于文献数据及试验数据,共有390条有效样本,数据分布如图7所示。首先剔除与辐照性能相关性较小的特征,最终选择中子注量、注量率、辐照温度、Cu含量、Ni含量、Mn含量、Si含量、P含量作为模型输入,辐照后的转变温度增量Δ作为模型输出。
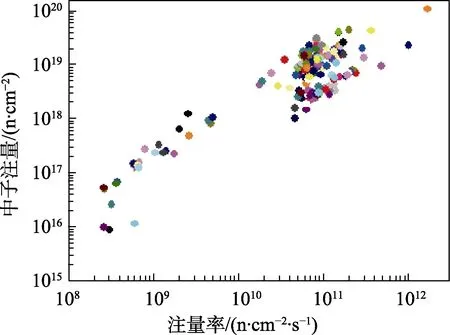
图7 辐照数据分布Fig.7 Distribution of radiation data
4.2 数据划分
由于RPV钢辐照数据样本较小且离散性大,因此需要保证数据划分后仍保持原始数据的分布规律,避免数据不均衡造成预测偏差。首先对相关性较高的Cu含量进行区间划分并标记为4个类别,然后按类别进行分层抽样,抽样结果见表4。其中,分层抽样后的样本分布与原始数据基本相同,Cu含量类别“4”的样本占比误差最大,为-4.76%;随机抽样后的样本分布与原始样本差异较大,最大的占比误差为8.57%。分层抽样后,将80%的数据用作训练,20%用作测试。
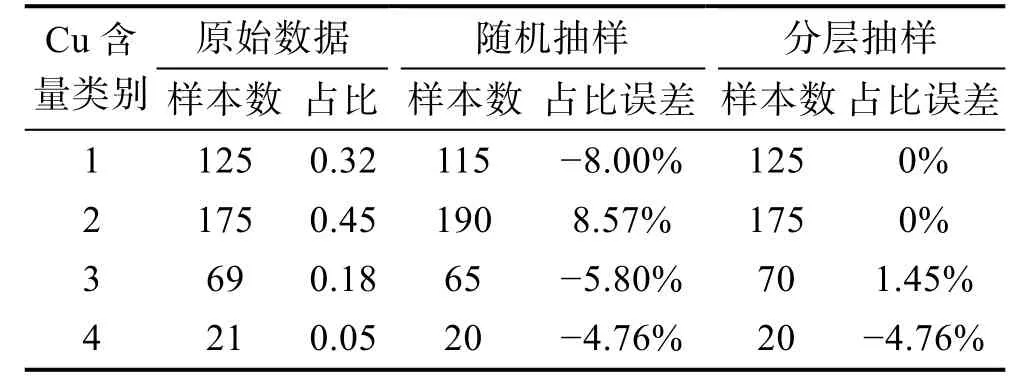
表4 数据抽样结果及误差Tab.4 Results and errors of data sampling
4.3 模型预测
数据划分后采用单一模型进行训练和预测,并对各种模型的预测结果进行评估,结果如图8所示。其中,极端梯度增强算法模型(Extreme Grandient Boosting, XGBoost)的均方根误差最小为10.16,达到0.88。基于树模型的集成算法,如随机森林(Random Forest, RF)、梯度提升决策树(Grandient Boosting Decision Tree, GBDT)、自适应提升算法(Adaptive Boosting, AdaBoost)、XGBoost和轻量级梯度提升算法(Light Grant Boosting Machine,LightGBM)等模型的预测平均绝对误差均小于10,表明树模型对本数据集的预测精度相对较高。
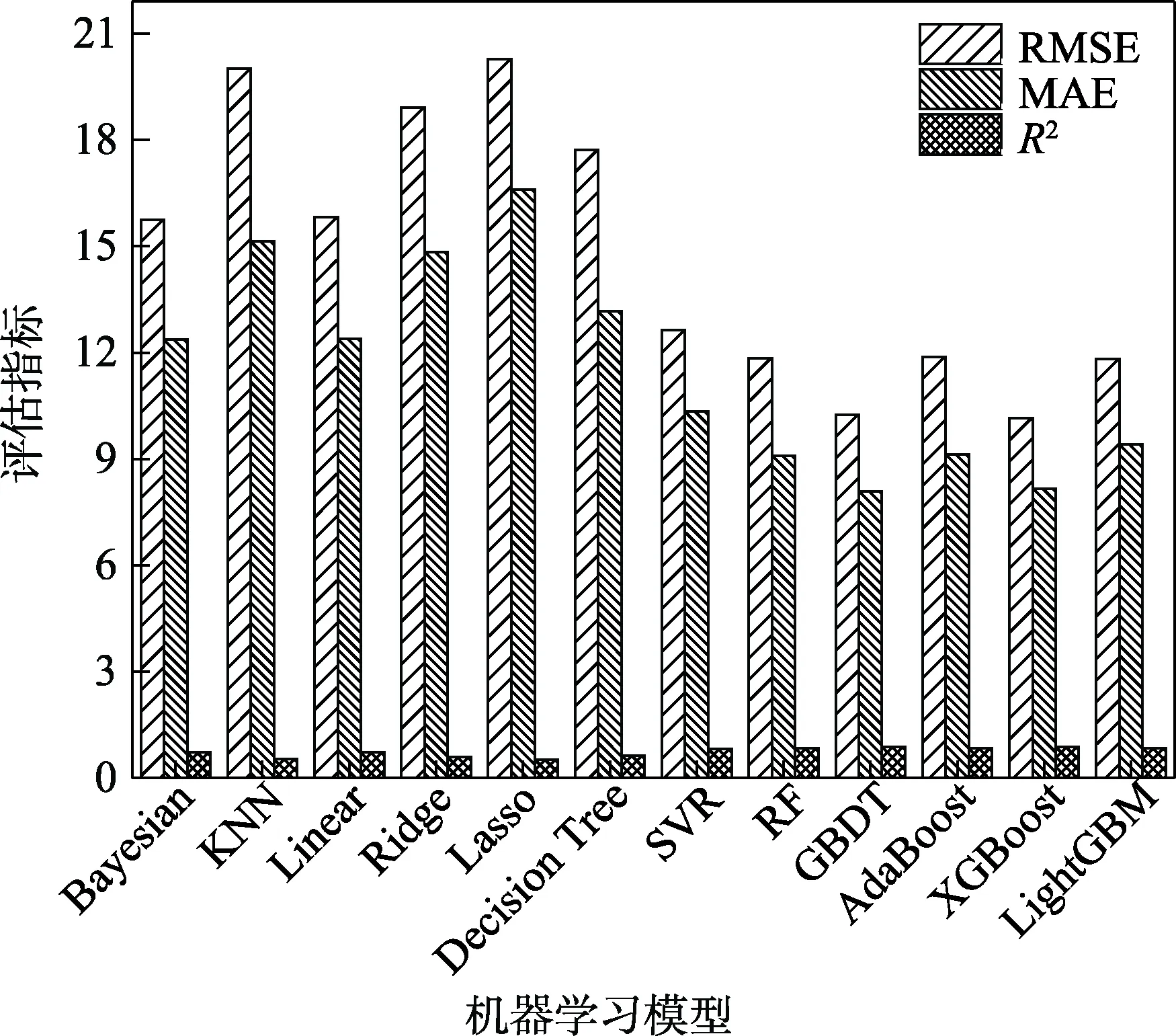
图8 各种模型评估结果Fig.8 Evaluation results of various models
为提高辐照性能的预测精度,采用Stacking方法在单一模型预测结果的基础上再次进行模型训练和预测。方法流程如图9所示,具体步骤如下:
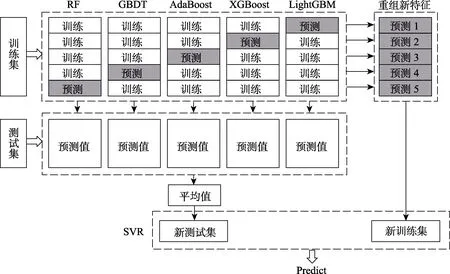
图9 基于Stacking集成方法的预测流程Fig.9 Prediction process based on stacking integration method
1)将训练集均分为5个样本子集,4个用于训练,1个用于预测;
2)采用RF、GBDT、AdaBoost、XGBoost和LightGBM模型分别在4个训练子集上进行训练,并对剩余1个样本子集进行预测。五个模型的预测结果重组为新训练集,大小与训练集相同;
3)采用上述五个模型分别对测试集进行预测,并将预测结果求平均后作为新测试集;
4)将新训练集和新测试集组成一个新数据集,然后采用支持向量机回归(Support Vector Regression,SVR)模型在新数据集上进行训练。
基于Stacking方法的预测结果如图10所示,模型预测值与试验值基本一致,全部落在45°线附近区域。模型预测结果与试验值的均方根误差RMSE为9.94,平均绝对值误差MAE为8.01,达到0.89。相比于单一模型,基于Stacking方法的集成模型预测性能得到提升,对RPV钢辐照性能预测具有较高的准确度和可靠性。
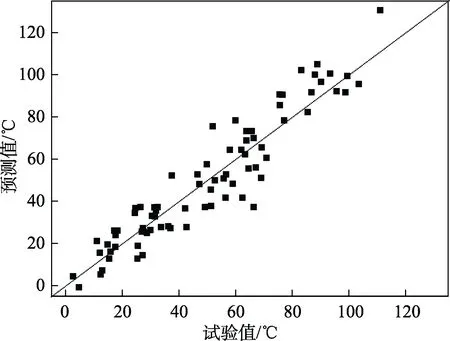
图10 集成模型预测结果Fig.10 Prediction results of the integrated model
5 总结与展望
从机器学习流程出发,首先概括了常用机器学习模型的原理及其在材料服役性能预测中的应用;然后采用多种机器学习模型对RPV钢的辐照性能进行预测,并采用Stacking方法提高了模型的预测精度。主要结论如下:
1)机器学习可用于材料服役性能预测,具有较高的预测精度和可靠性;
2)模型选择应考虑材料服役数据的质量、模型特点及样本数量;
3)重要特征提取、模型融合和参数优化算法可提高模型的精度和运算效率。
目前,机器学习在材料服役性能预测中的应用仍处于初级阶段,大量工作仍需进一步开展。如丰富完善已有的材料基因数据库,开展更高精度机器学习算法研究,优化机器学习模型参数,提高运算效率,结合物理模型及相关理论,增强机器学习模型的解释性。
猜你喜欢
中国教育信息化·高教职教(2022年4期)2022-05-13
计算技术与自动化(2022年1期)2022-04-15
装备环境工程(2022年2期)2022-03-15
煤气与热力(2022年2期)2022-03-09
民生周刊(2020年18期)2020-09-08
科技传播(2018年21期)2018-11-15
软件(2017年6期)2017-09-23
科学与财富(2016年34期)2017-03-23
计算技术与自动化(2014年1期)2014-12-12
