
中国卫生人力资源配置公平性测量方法及应用综述*
2022-02-15 12:45朱斌毛瑛何荣鑫张宁宁伟刘锦林
中国卫生事业管理 2022年1期
朱斌,毛瑛,何荣鑫,张宁,宁伟,刘锦林
(1. 南方科技大学公共卫生及应急管理学院 , 广东 深圳 518055;2. 西安交通大学公共政策与管理学院;3. 西北工业大学公共政策与管理学院)
卫生人力资源是实现健康的载体,是开展医疗卫生服务的基本条件,是满足社会成员基本卫生服务需求、实现人人享有健康的基础。世界卫生组织(WHO)将卫生人力资源定义为“所有从事的首要活动目的为提高健康的人员”[1]。这一说法延伸自WHO对于卫生系统的概念:“所有首要目的为促进、恢复或维护健康的组织、人和行动”[2]。
卫生人力资源价值的实现需要卫生人力资源的合理配置。世界卫生组织(World Health Organization,WHO)提出的卫生人力资源配置框架[3](图1)显示,仅仅是卫生人力资源总量的提升并不足以实现医疗卫生服务的有效覆盖。在卫生人力资源的可获得性(即数量)得到保障后,卫生人力资源的可及性(即合理的配置)是实现卫生人力资源价值的首要条件。
学术界已有大量从区域视角对卫生人力资源配置的研究,因为卫生人力资源是有限的,所以各国的卫生人力资源均会面临分布不均衡问题,因此以往宏观层面对于卫生人力资源配置的研究均聚焦于卫生人力资源配置的公平性分析[4-7],WHO亦将公平(equity)作为卫生资源配置的准则之一[8]。截止目前,卫生人力资源配置公平性的分析方法使用较为混乱,不同方法的优势和劣势不清晰,部分方法使用有误,亟需系统的回顾和梳理。本研究将通过对既往研究文献的梳理来对比主流分析方法的优势和劣势,纠正部分方法的使用误区,为今后卫生人力资源配置公平性研究提供参考。
1 资料来源和研究方法
本研究采用文献分析法对既往中国卫生人力资源的配置研究进行检索和整理。文献检索时借鉴系统综述方法,参考PRISMA(Preferred Reporting Items for Systematic reviews and Meta-Analyses)[9]文献检索策略,使用“卫生人力资源”和“配置公平性”两个关键主题词,检索了三个中文数据库:《中国学术期刊(网络版)》(CAJD)、《中国学术期刊数据库》(CSPD)、《VIP维普期刊数据库》,以及使用“Health Workforce、Health Manpower、Human Resource for Health”和“China”作为关键主题词,检索了两个英文数据库:PUBMED和Web of Science核心期刊数据库。论文纳入标准为与中国卫生人力资源配置直接相关的原始性学术论文,剔除相关新闻、采访报道、短论等。筛选出相应文献后,本研究对纳入文献的研究对象、数据年限、地理尺度和使用方法进行梳理,并比较不同卫生人力资源配置公平性测量方法的优势和劣势。
2 中国卫生人力资源配置公平性研究回顾与梳理
目前,大量学者围绕中国卫生人力资源配置公平性开展了相关研究(表1)。从研究区域可以分全国、省级、市级三个层面,在省级层面主要包括四川、西藏、新疆、陕西、甘肃、辽宁等西部和边远省份,在市级层面包括深圳、西安、长沙、衡阳等城市。从分析的时间跨度来看,早期研究以横截面数据为主,近年研究多使用面板数据。从研究对象来看,既往研究覆盖卫技人员、执业医师、注册护士、妇幼、中医、眼科、儿科等子类卫生资源以及村卫生室、疾控、基层医疗卫生机构、县级综合医院等特定机构的卫生人力资源。从分析方法来看,现在卫生人力资源配置公平性分析方法众多,比较主流的是经济学中用于测量收入公平性的基尼系数、泰尔指数,纳入社会经济因素的集中指数,产业经济学中的集聚度方法,简单易于计算的差别指数以及新兴空间统计量。
3 卫生人力资源配置公平性测量方法梳理
3.1 基尼系数与洛伦兹曲线
基尼系数最初是设计用于测量收入公平性,常和洛伦兹曲线组合使用[70]。以人口或其他对应指标(如面积)的累积百分比和卫生人力资源的累积百分比作为横纵坐标构建坐标系,绘制连接零点与各个坐标点的曲线,即为洛伦兹曲线,根据洛伦兹曲线与绝对平均线围成的区域大小即可计算基尼系数,基尼系数的取值范围为[0,1],取值越小代表卫生人力资源配置越公平。
基尼系数的定义为:
(1)
式(1)虽然是一个极为简明的数学表达式,但它并不具有实际的可操作性,所以基尼系数的计算公式都是近似估计,这也导致基尼系数的计算公式多种多样[71]。以常用的梯形近似法为例,先将洛伦兹曲线与X轴和X=100%围成的面积拆分为若干个直角曲边梯形,然后近似计算每一个梯形的面积进行求和:
(2)
其中Xi为按照人均卫生人力资源拥有量排序后的人口累计百分比,Yi为卫生人力资源的累计百分比,即用于绘制洛伦兹曲线的各点坐标,这样基尼系数的值可以表达为:
(3)
(3)式经过化简,可以得到更为常用的基尼系数计算公式
(4)
3.2 泰尔指数
泰尔指数最初适用于衡量个人和地区之间收入差距的指标,有泰尔-L和泰尔-T两种分型,计算公式分别为(5)式和(6)式,其中Pi为各地区人口数占总体人口数比例,Yi为各地区卫生人力资源数占总体卫生人力资源数比例。泰尔-T指数以Yi为权重,对上层卫生人力资源配置水平的变化比较明显,泰尔-L指数以Pi为权重,对底层卫生人力资源配置水平的变化比较明显。
(5)
(6)
在卫生人力资源配置公平性的分析中,泰尔-L指数的应用更广,原因在于在分析卫生人力资源配置时以人口作为权重更能体现对于各个地区的代表性。泰尔-L指数的本质在于为每一个地区赋值,如果人口占比高于卫生人力资源占比则是正值,如果人口占比低于卫生人力资源则是负值,赋值后以人口所占比例为权重求和。泰尔指数的取值范围为[0,1],取值越小代表卫生人力资源配置越公平。
如果将各地区分组,泰尔-L指数可以被分割为T组间和T组内[72]。
T组内T组内为小组内部卫生人力资源配置的泰尔指数,T组间T组间表示不同小组之间的差异,其计算方法为:
(7)
其中,Tg为各小组泰尔指数,Pg为各小组人口数占总体人口数比例,Yg为各地区卫生人力资源数占总体卫生人力资源数比例。
3.3 集中指数与集中曲线
集中曲线同样由洛伦兹曲线发展而来,但X轴代表的经济分组下的人口或其他对应指标的累计占比,纵轴为卫生人力资源的累计占比。集中指数有两种主要的计算方法:协方差法和集合法。
协方差法集中指数的计算方法如(8)式所示:
(8)
其中r为经济水平排序,h为卫生资源量排序,μ为卫生资源量均值。
几何法的集中指数计算公式同基尼系数相同,但是由于对于集中曲线X轴代表的是按照的经济水平排序后的人口累计百分比,所以集中曲线可能会出现在均等线上方,从而取值为负。集中指数为 0是代表绝对公平,为1或-1时表明绝对不公平; 为正值时,说明较多的卫生人力资源配置在经济水平高的地区; 为负值时,说明卫生资源倾向于配置在经济水平低的地区。
3.4 集聚度
集聚度方法来自于产业经济学领域,近年来也被引用到卫生人力资源配置研究中。卫生人力资源集聚度(Health Workforce Agglomeration Degree,HWAD)被定义为某一地区占整体研究区域1%的面积上集聚的卫生人力资源数量的比例。
地区i的HWAD计算公式为
(9)
同理,地区i的人口集聚度(Population Agglomeration Degree,PAD)计算公式为
(10)
其中,HWi为该地区卫生人力数量,Pi为该地区人口数,Ai为该地区面积,当HWADi=1时,表示某一区域卫生人力资源按照地理面积配置处于绝对公平,当HWADi/PADi=1时,表示地区i卫生人力资源按照人口规模配置处于绝对公平。
3.5 差别指数
差别指数(Index of Dissimilarity,ID)常被用来作为衡量健康公平性的指标,近年来学者在对卫生人力资源的公平性研究时也逐渐引入了该指标。它的基本思想是基于各地区卫生人力资源所占的比重和它的人口比重来测算各地区卫生人力资源配置水平的差异。其计算公式为:
(11)
Rsn为第s组卫生人力资源拥有量多占比重,Rsp为第s组人口数量所占比重,其取值在0~1之间,越接近0,表明卫生人力资源配置公平性越好,反之越差。
3.6 Moran’s I指数
Moran’s I(莫兰指数)是用于衡量有关指标在空间分布特征的统计量,可以反映卫生人力资源在空间的集中程度。根据适用范围可以将Moran’s I分为整体Moran’s I 和局部Moran’s I。整体Moran’s I是衡量指标整体相关性的指数,局部Moran’s I是衡量指标局部相关性的指数。
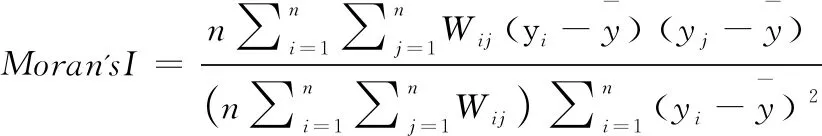
(12)
局部Moran’s I的计算公式如下所示。
(13)
3.7 Space-scan空间统计量
Space-time scan空间统计量由Kulldorff于1995 年提出的,该方法基于移动的圆形窗口,通过不断改变圆形窗口的位置和半径大小,来比较窗口改变后内外指标的差异,计算不同窗口下的对数似然比(Log Likelihood Rotio, LLR)和相应的P值。
LLR=Log{(C/n)C[(C-c)/(C-n)]C-c}
其中,C为所有地区卫生人力资源指标(如每千人口医师数或每平方公里医师数)平均值,c为窗口内卫生人力资源指标实际值,n为窗口内卫生人力资源指标预期值。LLR值显著的窗口被称为集聚,其中LLR值最大的窗口被称为I类集聚(Most likely cluster),代表窗口内外卫生人力资源指标的差异最为显著。其他集聚被称为II类集聚 (Secondary cluster)。
3.8 卫生人力资源公平性测量方法优缺点比较
目前学术界主流的对于卫生人力资源配置公平性的测量方法主要从经济学领域借鉴而来,最常用的是基尼系数和泰尔指数。基尼系数易于计算和解释,与洛伦兹曲线的结合便于直观对比和展示结果;泰尔-L和泰尔-T有不同特点,在测量卫生资源配置公平性时,往往采用泰尔指数对区域进行分组,通过分解组内差异和组间差异及计算各组贡献率分析不公平来源[73,74],如计算我国东中西部的组间差异;集中指数将社会经济水平指标纳入其中,可以反映卫生人力资源在不同收入阶层的集中程度;集聚度方法可以同时考虑人口和地理面积,但研究对象是每一个具体的地理单位,因此有利于各地区之间的对比。相比之下,差别指数是计算最为简便直接的方法,但每一种方法都有一定的缺点(见表2)。

表2 现有卫生人力资源配置公平性测量方法的数据要求及优缺点
4 讨论与建议
4.1 目前卫生人力资源配置公平性测量方法使用存在误区
目前卫生人力资源配置公平性测量方法在使用时存在一定误区。第一,在卫生人力资源配置分析中照搬经济学对于结果的评价标准[75]。举例而言,目前尚没有专门的针对卫生资源配置基尼系数的评价标准,基本都是借鉴经济学中对于收入公平性的标准,但是这样有失偏颇,原因在于居民收入的差异可以高达几十倍甚至上百倍,但是卫生人力资源人均拥有量的差异至多只有几倍。第二,洛伦兹曲线绘制错误。在部分研究中出现洛伦兹曲线绘制错误甚至超越绝对平均线的情形,原因在于在绘制前未按照卫生人力资源量与人口数(或面积其他指标)的比值对各区域进行排序。第三,在使用泰尔指数时不区分泰尔-L和泰尔-T。第四,很多既往研究直接将人口数量替换为地理面积计算卫生人力资源按照地理面积配置的公平性,需要注意的是按地理面积进行医疗卫生资源配置公平性评价对于人口比较密集的东中部区域意义不大,按照按地理面积分布进行卫生人力资源配置公平性评价时一定要结合区域的实际情况,因地制宜选择评价方法而不要盲目套用[75],在本文介绍的方法之外,还有一些较少使用的测量方法如首位度[76]和阿特金森指数[19]值得关注。
4.2 新兴的空间分析方法弥补了传统经济学分析方法的劣势
传统的经济学分析方法(基尼系数、泰尔指数等)用于分析卫生人力资源配置公平性时可以帮助我们直观了解卫生人力资源整体的配置情况,但是存在一定局限。卫生人力资源配置的公平性和收入公平性存在很大不同,卫生人力资源配置的公平性是指资源在不同空间位置上配置的公平性,而收入公平性则无需考虑地域因素。因此,仅仅使用传统的经济学分析方法(如基尼系数和泰尔指数等)难以直观展示卫生人力资源具体的分布状态。空间分析方法的引入则可以弥补传统经济学分析方法的劣势,协助识别卫生人力资源不均衡配置的具体区域,辅助循证决策。目前,空间分析方法在卫生人力资源配置中的主要用途包括以下几个方面,第一,用区域颜色差异在地图中直观展示不同地理尺度(省、市、县)下卫生人力资源的分布现状;第二,借助空间统计量识别城乡不同子类卫生人力资源的集聚区域;第三,加入时间维度展示卫生人力资源配置现状随时间的变化,同时可以识别高增长率和低增长率地区;第四,借助于空间计量模型探究各种潜在区域因素(GDP、卫生投入、医学教育实力等)对卫生人力资源配置状态的影响。这些计算和地图绘制已可以通过入门级的空间分析软件Geoda[77]、SaTScan和统计软件R、Stata实现。
4.3 未来研究应同时关注卫生人力资源的质量差异和年龄结构
现有研究主要基于各地区卫生人力资源的总量或某一类别卫生人力资源的总量进行公平性分析,忽视了卫生人力资源的质量和年龄结构,严谨性有待提高。未来研究应将卫生人力资源的质量差异和年龄因素考虑其中,如基于资源异质性假设,将不同层次的卫生人力资源按照一定标准进行折算后再进行公平性分析[79]或对不同职称、不同学历的卫生人力资源分类讨论。
猜你喜欢
小读者·爱读写(2021年10期)2021-11-05
世界汽车(2019年7期)2019-07-23
福建基础教育研究(2019年6期)2019-05-28
思维与智慧·下半月(2018年1期)2018-01-24
计算机应用(2016年10期)2017-05-12
中国证券期货(2017年3期)2017-03-30
中国证券期货(2017年3期)2017-03-30
中小企业管理与科技·上旬刊(2016年12期)2017-01-05
实践·党的教育版(2014年4期)2014-05-15
高中生学习·高一版(2013年3期)2013-04-01
