
基于行人重识别的目标跨镜追踪系统的设计与实现
2022-02-14 07:04:56王乾隆
成组技术与生产现代化 2022年3期
韩 珂,贾 冕,王乾隆
(华北水利水电大学 信息工程学院,河南 郑州450046)
我国“十三五”规划以来,大力建设天网工程、雪亮工程和平安城市重大工程,目前已拥有世界上最先进的视频监控网络。数量众多的摄像头产生了海量的视频数据,然而这些视频数据并没有得到充分有效的利用。传统的视频监控系统只能将拍摄的图像或视频存储起来,若要提取这些视频图像,则需要采用人工值守或人工浏览的方式,完成分析与处理过程。随着深度学习方法的广泛应用,能够自动分析与处理视频的软硬件系统不断涌现,而行人作为大多数视频监控的主要对象,对其视频进行有效的分析和处理,自然就成了研究的热点。
目前较成熟的人脸识别技术已广泛应用于人的身份认证,但在实际场景中,行人的遮挡、摄像头分辨率的高低、光线的明暗等限制性因素的影响,往往会导致所拍摄正面人脸的图像不清晰、不完整问题,这给行人识别造成了不小的麻烦。行人重识别(Person Re-identification,ReID)技术能对人脸识别做重要补充,根据行人的身形体态、着装特点等信息进行匹配识别后,把目标人员在不同监控视频中出现的视频信息关联起来,进行视频结构化分析后形成清晰的踪迹[1],以实现跨场景、跨摄像头的行人目标追踪。本文拟设计一种基于行人重识别的目标跨镜追踪系统,使系统具有行人目标图像匹配和行人目标跨镜追踪两大核心功能,以便有效地对目标人员进行多场景下多摄像头的持续追踪。
1 行人重识别技术
1.1 重识别流程
ReID是一种判断图像或者视频中是否出现某个行人的技术,通常被看作图像检索的子问题[2]。该技术可以根据行人的穿着和身形姿态,判断不同区域的不同摄像头所拍摄图像中的行人是否为同一个人。行人重识别的流程主要包括特征提取和相似度度量(图1)。早期的ReID系统需要手工设计提取特征,且其提取特征的能力有限,难于学习;新的ReID系统能通过卷积神经网络(Convolutional Neural Network, CNN)进行特征提取,通过相似程度的计算来训练特征提取网络,并能在推理阶段精确计算两张图像的相似程度。

图1 行人重识别的流程
从图1可以看到,一个完整的行人重识别流程包括:首先从监控摄像头处获取原始视频帧;然后对这些视频帧进行行人检测,截取行人图像后构成图片集;再利用ReID技术进行特征提取和相似度度量;最后输出已排序的识别结果。
1.2 常见数据集
实际应用场景下拍摄监控视频的质量会受到很多因素的影响,例如视角变化、行人姿态、遮挡现象、穿着配饰、光照强度、背景变化、摄像机参数等,给行人重识别的顺利进行带来了不小的挑战[3]。基于深度学习的行人重识别过程离不开大量的图像数据[4],而数据集质量的好坏会直接影响最终训练的效果。此前,学术界已公开许多高品质的图像数据集。表1所示为常见的5种ReID图像数据集的情况。
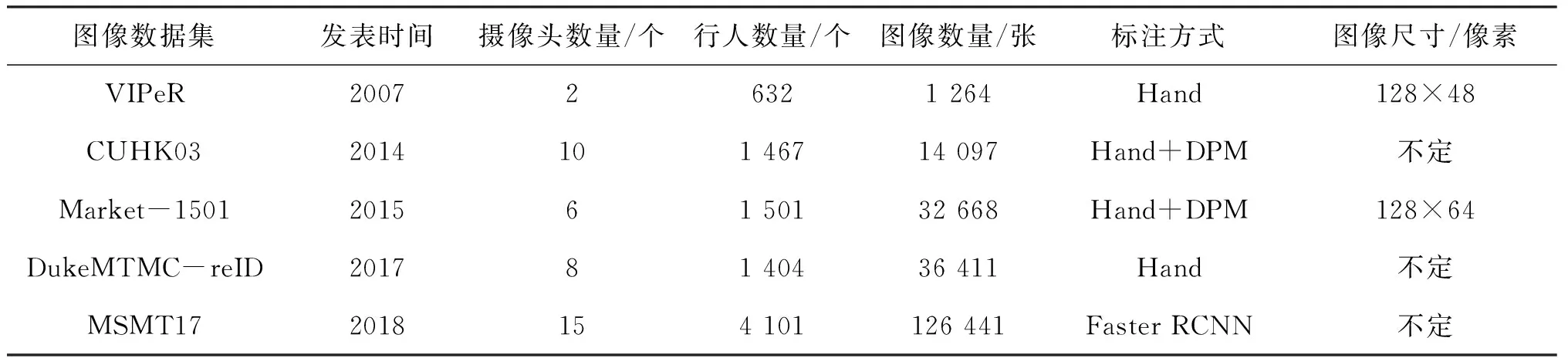
表1 常见的5种ReID图像数据集的情况
Market-1501图像数据集是由清华大学采集并于2015年发布的一个大规模ReID图像数据集[5]。该数据集的室外摄像头包括1个低清的和5个高清的;行人检测框是通过可变形部件模型(Deformable Parts Model,DPM)目标检测算法生成的;训练集由751个行人的12 936张图像构成,测试集由750个行人的19 732张图像构成,且测试集中包含作为干扰项的2 793张行人图像。该数据集采集的图像大部分是光照条件较好的,但有些图像只检测到了行人的局部,比较符合真实场景。它是该领域最常用的数据集之一。
1.3 评价指标
ReID算法模型的常用评价指标有Rank-k、CMC和mAP。
指标Rank-k表示匹配列表中排序前k张行人图像中能正确匹配的图像比例。而Rank-1为首位命中率(或Rank-1 Accuracy),是指按照相似度排序后生成的匹配列表中,排在第一张的行人图像占正确匹配图像的比例。指标Rank-k的计算式为:
(1)
式中:n表示待查询图像的总量;Si表示匹配列表中排序前i张图像是否能匹配成功,如果能则Si为1,如果不能则Si为0。k的值一般取5和10。相比存在波动的Rank-1来说,用Rank-5和Rank-10对算法模型的评价会更加全面。
指标CMC是累积匹配特征曲线(Cumulative Matching Curve),可以理解为Rank-k的一种可视化方式。该指标综合考虑了Rank-1至Rank-k的所有值,并可以直观地反映算法模型的性能。评价时,首先计算Rank-1至Rank-10;然后以k为横坐标,以Rank-k为纵坐标作曲线即可。
一般来说,为更加全面地衡量算法模型的质量,往往需要同时考虑准确率和召回率,然而指标CMC注重准确率而忽略了召回率。针对这个问题,Zheng等提出了指标mAP[6]。mAP是所有查询样本平均精度的平均值,能够兼顾准确率和召回率,较全面地评价ReID算法模型的性能。
2 行人重识别网络模型的训练方法
综合考虑系统的性能需求、实用程度和训练难度后,本文对基于全局特征的行人重识别网络模型结构进行适当调整,并采用特定的训练技巧在Market-1501图像数据集上进行了训练和测试。
一般来说,骨干网络模型在执行计算机视觉任务中的主要作用是对图像进行特征提取,网络结构的性能直接取决于骨干网络的质量。AlexNet和ResNet50都是图像处理时常用的网络模型,但已有的实验结果表明,ResNet50网络模型的特征提取能力要明显强于AlexNet网络模型[7]。对于Market-1501图像数据集来说,这两种网络模型的性能对比如表2所示。通过对比网络模型的性能,可在后续执行行人重识别任务中进行训练时,选择性能更优的ResNet50作为骨干网络模型。
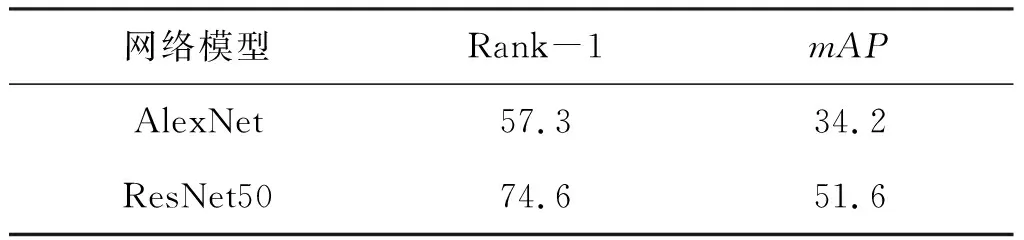
表2 两种网络模型的性能对比 %
首先,针对P个行人各抽取K张图像,组成一个批处理脚本,并将其输入网络模型;其次,这些图像的尺寸会自动调整为256×128(像素),且约有50%的图像会发生水平翻转;然后,在得到经过骨干网络ResNet50的图像全局特征后,将全连接层的输出维度改为训练数据集中的行人专属号码(Identity Document,ID);最后,根据之前所得全局特征分别计算三联体损失(Triplet Loss)[8]和专属号码损失(ID loss),并完成网络模型的训练。在训练过程中,计算Triplet Loss,旨在让网络模型对图像的相似程度进行学习,使同一行人的差距更小,不同行人的差距更大;计算ID Loss,旨在让网络模型将行人重识别看作图像分类任务,能结合Triplet Loss进行联合训练,并让骨干网络模型学习具有较强代表性和鲁棒性的行人特征。
为提高行人重识别网络模型的性能,更好地提取图像特征, He等提出了一种称作BNNeck的新结构[9]。在BNNeck结构中,一个批量归一化层被放在了全连接层之前,并消除了全连接层中的偏置项。这使得池化后的特征能先用于计算Triplet Loss,再通过批量归一化层,用于计算ID Loss,以便更好地进行特征提取,获得具有更高区分度的特征。在基本的训练流程中加入BNNeck结构,使用随机擦除、标签平滑等一些训练中常用的技巧[10],即可形成图2所示的网络模型训练流程。
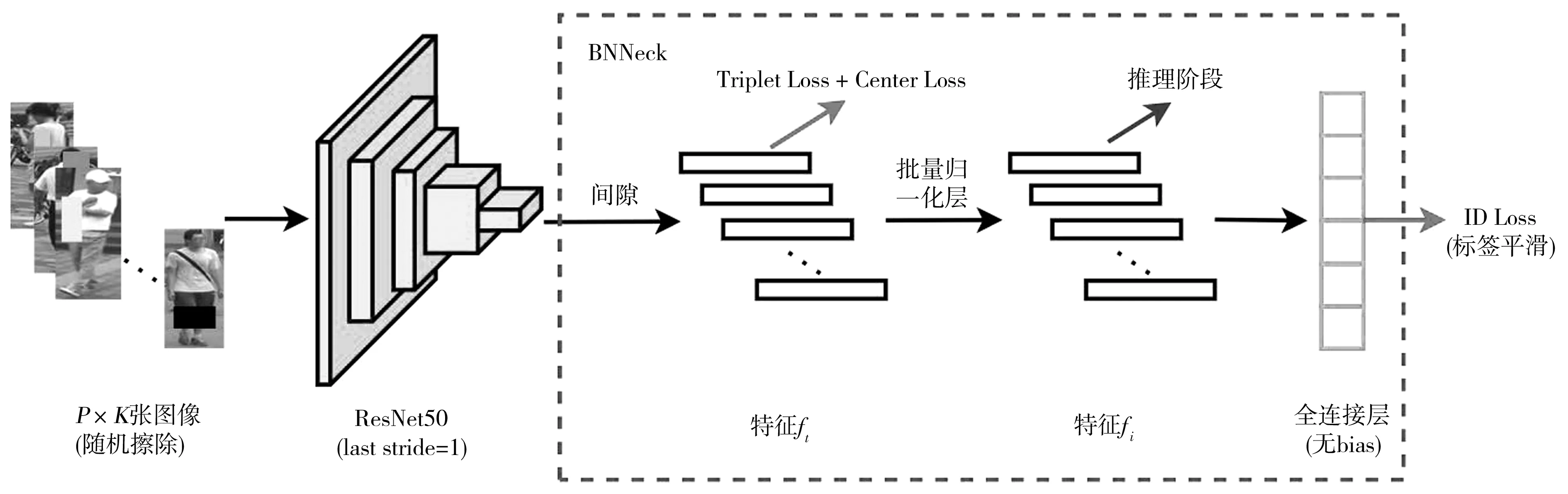
图2 网络模型的训练流程
在网络模型训练流程中,中心损失(Center Loss)指标[11]用来弥补Triplet Loss指标忽略的正负样本对特征距离绝对值的影响。把Triplet Loss、Center Loss和ID Loss 3项指标结合起来考虑,可得总的损失L,即
L=LID+LTriplet+βLCenter
(2)
式中:LID表示ID Loss ;LTriplet表示Triplet Loss;LCenter表示Center Loss;β为控制Center loss的权重。
本文选取行人重识别领域最常用的Market-1501图像数据集,在基于ResNet50调整后的网络模型上进行大量的训练和测试,所得指标Rank-1和Rank-10分别达92.9%和98.7%,mAP则达到了82.9%,基本上满足了工程需求。
3 目标跨镜追踪系统的功能模块
基于行人重识别的目标跨镜追踪系统内嵌了常用的行人重识别算法,可采用Python语言设计其功能模块,以便有效地对目标人员进行多场景下多摄像头的跨镜持续追踪。该系统的实现流程为:操作人员通过图形化用户界面与系统进行交互,首先在一个主要的监控视频中手动裁取要追踪的行人图像;然后选取其他多个摄像视角的监控视频,借助行人检测和行人重识别技术在视频中识别目标人员,并对其进行标注。
基于行人重识别的目标跨镜追踪系统应具有本地视频图像导入、行人图像裁取、行人检测、目标图像匹配、目标跨镜追踪、系统使用记录等功能模块(图3)。其中,目标图像匹配、目标跨镜追踪为核心功能模块。经过充分调研,这些功能模块基本可以满足系统在实际场景下对目标人员的追踪需求。
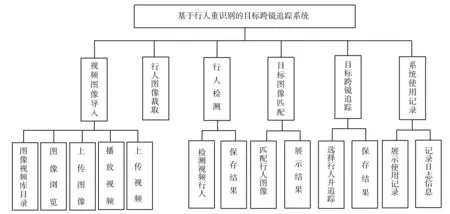
图3 目标跨镜追踪系统的功能模块
3.1 目标图像匹配模块
目标图像匹配模块工作时,能通过相似度匹配,从系统数据集中找出与指定行人似为同一人的图像,并对匹配结果进行展示。该模块的工作流程如图4所示。
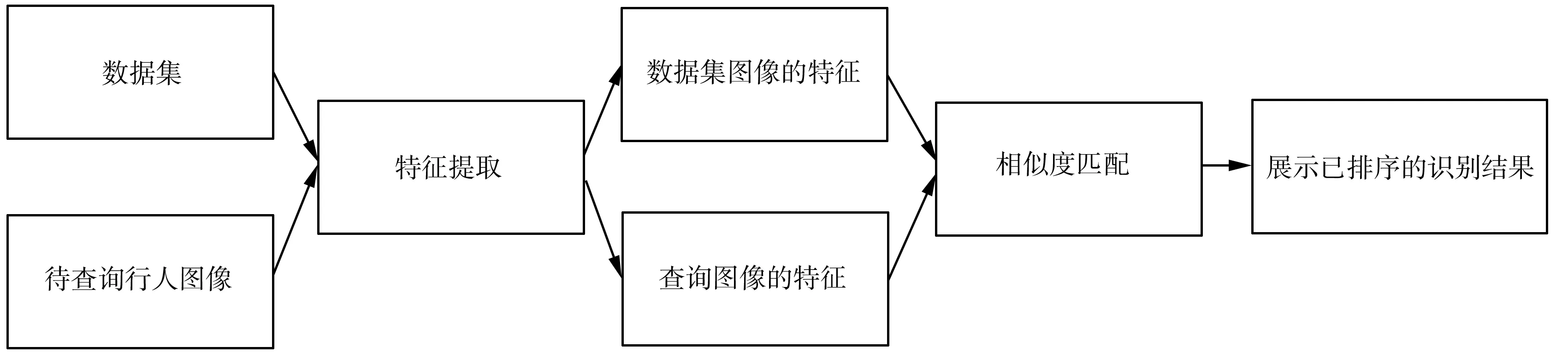
图4 目标图像匹配模块的工作流程
具体来说,通过目标图像匹配模块,首先选取一张待匹配的行人图像(该图像可以是之前在监控视频中裁取的),将其和系统数据集中的图像一起输入网络模型,进行特征提取;然后计算图像之间的特征向量差距;最后在系统用户界面中展示匹配度最高的12张行人图像和相关信息。目标图像匹配界面如图5所示。其中实线边框表示匹配的是同一个行人,虚线边框表示匹配的不是同一个行人。

图5 目标图像匹配界面
3.2 目标跨镜追踪模块
通过目标跨镜追踪模块,系统能够对比指定行人图像与监控视频中行人图像的相似度,识别目标人员并对其进行持续追踪。目标跨镜追踪模块的工作流程如图6所示。
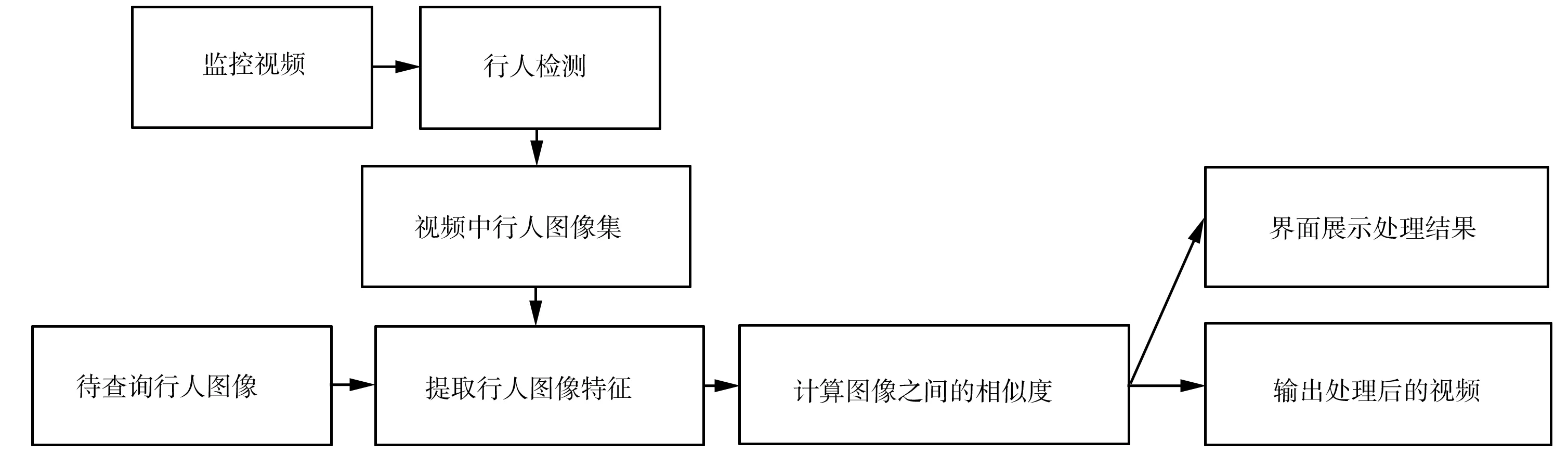
图6 目标跨镜追踪模块的工作流程
目标跨镜追踪模块工作时,首先选定待追踪行人图像和监控视频,并对从监控视频中抽取的图像帧进行检测,将检测到的行人组成视频中行人图像集,取代之前行人图像匹配模块中使用的系统数据集;然后采用行人重识别算法,对视频中行人图像集进行特征提取和相似度对比,对监控视频中相似度最高的行人涂加彩色或标记其他特定形式的矩形框,并在用户界面(图7)中展示;最后将处理好的视频保存到输出文件夹中。

图7 目标跨镜追踪系统的用户界面
4 结 语
行人重识别技术广泛用于智慧安防、智能寻人等领域。本文在行人重识别算法的基础上,使用Python语言设计并实现了一种基于行人重识别的目标跨镜追踪系统,用于跨摄像头跨场景追踪行人目标。该系统选用算法模型的性能较好,总体上能满足用户的工程需求,但从完善系统功能和进一步提高用户使用体验感考虑,仍可进行以下优化:①为避免所用算法模型在实际场景中运算开销增大而影响系统的实时性,应在保证高准确率的前提下,尽可能使网络模型轻量化;②鉴于该系统对行人目标跨摄像头跨场景的追踪仍需要人为参与才能分析行人目标的移动轨迹,并未完全实现自动化,后续可通过视频结构化管理,在识别的基础上自动分析行人目标的移动轨迹,并进行可视化展示。
猜你喜欢
黑龙江大学自然科学学报(2022年4期)2022-11-17 08:08:06
意林(2021年5期)2021-04-18 12:21:17
作文小学中年级(2020年6期)2020-07-24 08:33:10
扬子江(2019年1期)2019-03-08 02:52:34
计算机测量与控制(2017年6期)2017-07-01 16:23:31
小天使·一年级语数英综合(2017年6期)2017-06-07 23:51:16
集美大学学报(自然科学版)(2015年1期)2015-02-28 01:13:32
西安建筑科技大学学报(自然科学版)(2014年5期)2014-11-10 02:34:46
航天器工程(2014年4期)2014-03-11 16:35:37
自然资源遥感(2014年3期)2014-02-27 11:56:38
