
用于图像超分辨率重建的双通道残差网络
2022-02-14 10:55:32左龙张鹏荆树旭赵一李凡
西安交通大学学报 2022年1期
左龙,张鹏,荆树旭,赵一,李凡
(1.长安大学信息工程学院,710054,西安;2.西安电子科技大学通信工程学院,710071,西安)3.西安交通大学信息与通信工程学院,710049,西安)
图像超分辨率(SR)是从一张或多张低分辨率(LR)图像中恢复出高分辨率(HR)图像。近些年,随着深度学习技术的快速发展,基于深度学习的SR技术也随着取得了迅猛发展,并在行人识别、安全监控、医学成像等众多领域得到了广泛的应用[1-3]。然而,图像SR是一个不适定的逆问题,每个LR图像都可能对应多个重建方案。近些年,许多研究人员使用深度学习技术解决这种逆问题,取得了有效的成果[4-7]。最近的很多研究成果也表明,网络的深度对于提升模型的重建性能至关重要,更深的网络能够从输入的低分辨率图像中能学习到更多信息。然而,简单地堆叠网络深度并不会对网络带来太大的提升,甚至会使训练变得更加困难,使网络更难以收敛。
基于此,一些学者将残差结构和深度网络相结合,推出了一些效果十分出众的模型,如VDSR[8]、RCAN[9]等。这些模型通过加入网络之间的跳跃连接,让图像的低频信息可以绕过网络,使网络的主通道更加专注于学习图像的高频细节,提高了重建的效果。然而,这些算法在图像边缘和纹理重建方面仍然不尽如人意,经常会出现几何结构变形和扭曲、边缘模糊、细节纹理缺失等现象,导致重建图像的视觉效果及客观指标评价均不佳。
RCAN网络中提出的残差中的残差(RIR)结构试图通过结合残差网络的粗粒度和细粒度信息使网络专注于高频信息的学习,但是RCAN网络简单地堆叠RIR结构,导致网络训练过慢、参数量过大。另外,VDSR、RCAN等使用残差结构的网络在训练时使用不考虑人类视觉的L1损失函数,不利于网络对于图像边缘、纹理等高频信息的学习。
不同于传统超分网络使用单一通道学习图像特征,本文设计了一种用于图像超分辨率重建的双通道残差网络。使用包含跳跃连接和通道注意力模块的残差组作为网络的主通道,并在每一个残差组之外并构了一个包含自适应结构化卷积的辅助通道,为主通道提供了自适应的感受野,增强了网络学习图像结构、边缘等高频信息的能力,加快了网络的收敛速度,极大地提高了图像的重建质量。为了加强网络学习高频信息的能力,在损失函数中引入了能保留图像边缘和细节的多尺度结构相似度损失函数。实验结果表明,在重建效果类似的情况下,本文网络的层数远低于传统残差网络的。
1 相关研究
随着深度学习的不断发展,许多学者将深度学习技术应用于图像SR领域,提出了许多优秀的算法,较传统算法有了显著的效果提升。Dong等在2014年提出了一种基于卷积神经网络的图像超分辨率重建算法(SRCNN)[10]。这是一个3层的卷积神经网络(CNN),虽然网络较为简单、感受野小、收敛速度慢,但是相较于传统的图像超分辨算法,其在重建效果与速度方面均有质的提升。为了提升网络的图像SR重建效果,必然使用更宽或者更深的神经网络,但是简单地提升网络深度必然会带来网络难以训练与收敛、梯度爆炸等一系列问题,因此许多研究人员在卷积网络的设计中加入了残差结构。Kim等在2016年提出的20层VDSR网络首次将残差结构与卷积网络相结合应用于图像SR任务中[8]。由于加深了网络的深度,VDSR算法的学习能力显著加强,网络重建图像的效果也更好。Tai等在2017年提出了结合局部残差连接和残差单元的递归学习算法和52层的深度递归残差网络(DRRN)[11]。为进一步加深网络深度,Tai等还将记忆模块引入图像SR任务,提出了深度达到80层的长期记忆网络(MemNet)[12]。Li等在2018年首次将图像多尺度特征应用于残差结构中,提出了多尺度残差网络(MSRN)[13]。Ahn等在2018年将局部级联和全局级联的方式引入SR网络设计,提出了级联残差网络(CARN),该网络使用了多级表示和快捷连接,网络更加轻量化[14]。He等在2019年借鉴微分动力学系统设计了一种轻量型的图像超分辨率重建网络(OISR),使用改进的前向欧拉公式设计网络的残差块,使网络更容易收敛[15]。Zhang等在2018年首次将通道注意力机制应用于图像超分辨问题中,设计出残差通道注意力网络RCAN,通过自适应的学习通道之间的相互依赖性使得网络专注学习重要的通道特征,从而提高网络的性能[9]。RCAN网络中设计了RIR结构,通过在残差结构中结合使用长跳连接和短跳连接,有效加快了网络的收敛速度,提高了网络的重建性能。但是,现有算法在重建图像的几何结构、纹理细节方面等高频信息方面仍然表现不尽如人意,所以本文提出了一种双通道残差网络来解决这个问题。
2 用于图像超分辨率的双通道残差网络
2.1 网络结构
本文网络由浅层特征提取模块、特征映射模块以及重建模块共3大模块组成,网络结构如图1所示。本文用ILR表示网络的输入。在特征预提取模块中,使用了一个卷积层对输入图像进行浅层特征的提取,抽象为公式
F0=HSF(ILR)
(1)

图1 网络结构Fig.1 Network structure
式中:HSF表示提取浅层特征的卷积运算;F0表示从ILR中提取的浅层特征。
在特征映射模块中,使用双通道的残差结构作为网络的基础模块,通过堆叠基础模块加速网络。这种结构增加了残差学习的感受野与速度,加强了网络的学习能力。将第N个残差组的输入与运算分别表示为FN-1与RN(FN-1),辅助通道的运算表示为AN(FN-1),则第N个基础模块的输出为主通道输出与辅助通道输出的点积,表示为
FN=RN(FN-1)⊗AN(FN-1)
(2)
式中:FN表示第N个基础模块的输出结果;⊗表示矩阵的点乘运算。特征映射模块的输出FFM视作图像的深层特征,FFM由第G个基础模块的输出FG和浅层特征得到
FFM=F0+HC(FG)
(3)
式中HC表示特征映射模块最后的卷积层运算。将FFM通过重建模块即一个上采样块和一个卷积层后,输出网络重建的图像
(4)
2.2 辅助通道
现有的图像SR中,重建算法经常会使自然图像中所包含的几何结构以及边缘信息出现断裂、弯曲、模糊等现象,导致重建图像难以获得良好的视觉效果。为了在重建过程中更好地保留原始图像的几何结构和边缘信息,本文在主通道之外并构了一个辅助通道,增大了网络的宽度。在辅助通道中加入了自适应结构化卷积,本文改进了传统的膨胀卷积,将输入图像按尺寸比例划分为不同的块,在图像的不同块中采用不同的膨胀率,膨胀卷积可以适应图像局部结构信息的变化,也使辅助通道有了自适应的感受野,让基础模块可以更加专注于图像的高频特征的提取。第N个残差组的辅助通道运算可表示为
AN(FN-1)=HC(HIC(HC(FN-1)))
(5)
式中HIC为自适应结构化卷积运算,公式为
(6)
其中,I、J为图像横纵的分块上限,r为膨胀卷积的膨胀率,HDC表示膨胀卷积。
2.3 残差通道注意力块
每一个主通道模块都由K个残差通道注意力块构成,在第g个主通道模块中,第b个残差通道注意力块的输出可表示为
Fg,b=Fg,b-1+HCA(Xg,b)
(7)
式中Xg,b和通道注意力函数HCA分别为
Xg,b=HC(δ(HC(Fg,b-1)))
(8)
HCA(Xg,b)=Xg,b⊗S(HC(δ(δC(HG(Xg,b)))))
(9)
其中δ、S和HG分别表示ReLU激活函数、Sigmoid激活函数和全局平均池化函数。
2.4 损失函数
Ltotal=(1-α)GguL1+αLMS_SSIM
(10)
式中:α为平衡参数;Ggu为高斯分布变量。L1损失函数和LMS_SSIM损失函数的定义如下
(11)
(12)
式中:k为训练图像数量;MS[17]为多尺度结构相似性运算。
3 实验结果与分析
3.1 数据集
本文的训练数据集为DIV2K,测试数据集为Set5[18]、Set14[19]、BSD100[20]、Urban100[21]。网络的输入通过对数据集中的原始图像进行双3次插值下采样得到。
3.2 参数设置
特征预提取模块使用64个尺寸为3×3像素的卷积核。特征映射模块的主通道由7个主通道模块和一个额外的卷积层构成。每个主通道模块为3个相同的残差通道注意力结构的叠加,其中的卷积层均采用尺寸为3×3像素的卷积核和0填充,激活函数使用ReLU,池化层采用全局池化。特征映射模块尾部的卷积层使用3×3像素的卷积核。辅助通道深度为3,第二层使用自适应的膨胀卷积。重建模块中的最后一个卷积层使用3个3×3像素的卷积核完成重建图像输出。平衡参数α取0.84,自适应膨胀卷积的膨胀率上限设为4,图像横纵的分块上限I、J设为10。网络的搭建、训练与测试均在Ubuntu16.04系统上使用Pytorch深度学习框架完成,实验硬件平台如下:CPU型号为Intel(R)Core(TM)i9-9900K CPU @3.60 GHz,内存容量为32 GB,GPU使用两块RTX2080Ti。
3.3 实验结果及分析
3.3.1 视觉效果 将本文网络与现有同类网络SRCNN[10]、VDSR[8]、DRRN[11]、MemNet[12]、MSRN[13]、CARN[14]、OISR[15]进行了对比,结果如图2所示。可以看出:SRCNN网络重建图像的几何结构效果最差,重建二幅图像中的框架形状均出现严重扭曲变形;MSRN网络及OISR网络恢复图像的视觉效果较好,但是重建图像的几何结构仍然有部分失真;本文网络可以准确恢复两幅图像中的框架结构,重建图像具有最佳的视觉效果,而且在纹理细节视觉效果上也优于其他网络的。这是由于本文网络在主通道之外并构了一个辅助通道和使用L1与LMS_SSIM相结合的损失函数。辅助通道使得网络对于图像高频信息的学习能力更强,让网络保留了更多图像的几何结构信息。实验的视觉效果证明,本文网络学习结构信息的能力更强,重建图像的效果更为逼真。

图2 自然图像上不同网络的性能比较Fig.2 Performance comparison of different networks on natural images
3.3.2 定量分析 图像超分辨重建质量的评价指标分为主观和客观两种。主观评价一般采用人眼判定图像质量的方法,这种方式较为主观,评价较为片面,因此一般将主观评价作为评价图像质量的辅助指标。早期人们一般采用峰值信噪比(PSNR,用符号IPSNR表示)作为客观评价指标,其为信号最大功率与噪声功率的比值,在本文的计算中取图像最大像素值的平方与图像均方误差比值的对数。然而,峰值信噪比是对重建像素点误差敏感的评价指标,没有考虑到人眼的视觉特性。因此,常常会出现PSNR评价与人的主观评价不一致的情况。所以,学界提出了另一个客观评价指标——结构相似性(SSIM,用符号ISSIM表示)[22]。该指标分别从亮度、对比度、结构共3个方面对比与原始图象的相似度,更注重人的主观感受。将两种指标结合可以更客观全面地评估重建图像的质量。
本文网络与现有7个网络在4个数据集上进行了2、3、4倍放大重建,PSNR与SSIM如表1所示。可以看出:只采用了3个卷积层的SRCNN网络的重建结果客观评价指标最差;MSRN网络将全局特征与局部多尺度特征相结合,使得网络对于特征的提取更加高效;OISR网络改进了残差块的结构,使得网络的学习能力更强,MSRN和OISR这两种网络的客观评价指标更优;本文网络的两种客观指标均为最高,在几何结构内容较多的Urban数据集上进行放大倍数为2的重建时,PSNR以及SSIM分别为32.87 dB和0.933 4,均优于现有结果最好的OISR算法的,在自然景色占比更多的BSD100数据集上进行放大倍数为2的重建时,PSNR以及SSIM分别为32.31 dB和0.901 0。实验结果表明,本文网络对于图像几何结构的学习能力更强。
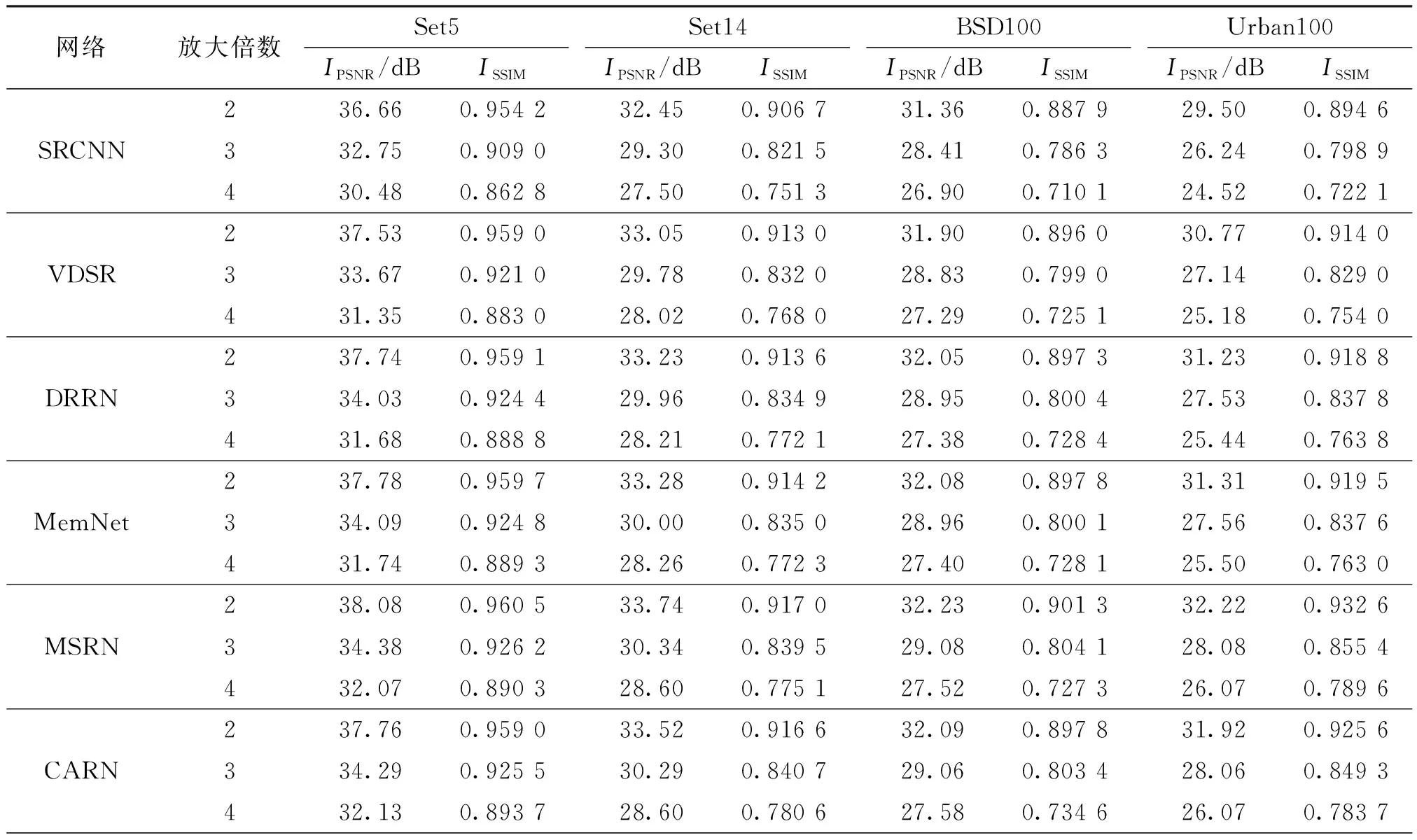
表1 不同网络的峰值信噪比和结构相似性Table 1 PSNR and SSIM of different networks

续表
为了证明本文网络设计的有效性,进行了放大倍数为2的消融实验,结果如表2所示。可以看出:在去掉辅助通道的情况下,在Set5数据集上进行重建,相较于双通道网络的PSNR以及SSIM分别下降了5.86 dB和0.068 1,在Urban数据集上进行重建,相较于双通道网络的PSNR以及SSIM分别下降了6.7 dB和0.141 4;在仅使用L1损失函数的情况下,在Set5数据集上重建,相较于使用Ltotal损失函数的PSNR以及SSIM分别下降了2.98 dB和0.048 7,在Urban数据集上进行重建,相较于使用Ltotal损失函数的PSNR以及SSIM分别下降了4.18 dB和0.112。消融实验证明,本文设计的辅助通道和损失函数能够有效提升网络的学习能力。
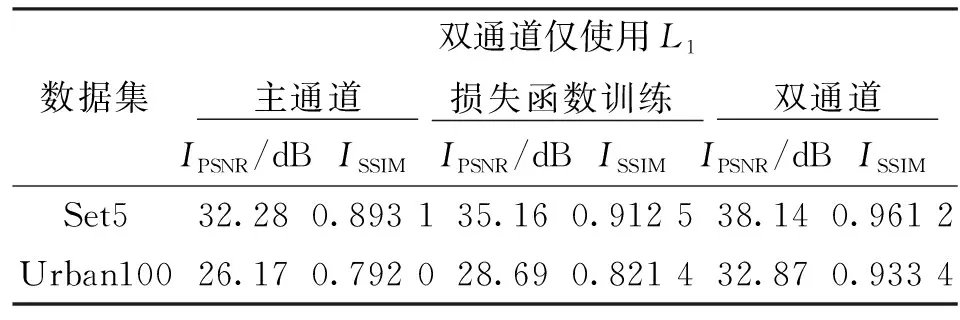
表2 消融实验结果Table 2 Ablation experiment results
4 结 论
(1)本文提出了一种用于图像超分辨重建的双通道残差网络。使用带有跳跃连接和通道注意力模块的残差组作为主通道,并加入使用自适应结构化卷积的辅助通道,组成了双通道的残差块,使得低频信息得以更好地绕过网络,加强了高频信息在网络中的作用,为模块增加了自适应的感受野,获得了更佳的重建效果。
(2)本文使用L1损失函数和多尺度结构相似度损失函数,在训练中即能够较好地保持图像的颜色和亮度,也能够保留图像的边缘、纹理细节等高频信息。
(3)实验结果证明,本文网络在自然图像SR重建领域的客观评价指标与视觉效果均优于现有网络的。本文网络重建的自然图像具有更完整、准确的几何结构。
猜你喜欢
网络安全与数据管理(2022年3期)2022-05-23 13:26:48
交通企业管理(2022年1期)2022-03-02 04:39:18
昆明医科大学学报(2021年4期)2021-07-23 01:21:56
北京航空航天大学学报(2020年10期)2020-11-14 09:26:02
——浙江舟山港主通道百年品质工程建设的理念与措施
中国公路(2020年3期)2020-03-24 07:20:28
自动化学报(2019年6期)2019-07-23 01:18:32
中国建设信息化(2018年10期)2018-08-29 08:50:56
科技创新与应用(2016年8期)2016-10-21 20:41:16
河南科技(2015年8期)2015-03-11 16:23:52
电子设计工程(2015年16期)2015-02-27 12:07:56
