
移动边缘计算中基于内容流行度的深度强化学习缓存机制
2022-02-11 09:44:02王朝炜石玉君于小飞王卫东
无线电通信技术 2022年1期
王朝炜,石玉君,于小飞,王卫东
(1.北京邮电大学 电子工程学院,北京100876;2.通信网信息传输与分发技术重点实验室,河北 石家庄 050081)
0 引言
随着技术的发展和5G的商用,越来越多的新应用对网络时延、带宽和安全性提出了更高的要求。 行业普遍认为,移动边缘计算 (Mobile Edge Computing,MEC)是应对“海量数据、超低时延、数据安全”发展要求的关键[1]。MEC是指将云端的计算能力和网络服务下放到通信网络边缘,即无线接入网中,使用户可以在更邻近的无线接入点(Access Point,AP)获取计算服务[2]。
随着智能手机和可穿戴设备的广泛使用,混合现实(Mixed Reality,MR)给经济、科技、文化、生活等领域带来深刻影响。典型的MR系统由5个关键组件组成:视频源、跟踪器、映射器、对象识别器和渲染器[3],本文只关注渲染模块。MR应用程序的性能会受到有限的MR设备的计算和缓存资源影响。如果将用户预取的渲染环境帧缓存在边缘服务器上,能提高混合现实应用服务质量。
文献[4]提出了一种基于博弈论的算法,首先预估内容的流行度,然后基于松弛方法制定缓存方案以减少延迟。文献[5]讨论了空间网络结构和设备之间通信,并提出了一种缓存方法来降低终端设备的能耗。文献[6]采用启发式 Q-learning预测车辆运动,实现有效的主动缓存策略并提高服务性能。文献[7]结合边缘计算提高面向网络的MR应用的服务质量。文献[8]将计算任务卸载到最近的MEC服务器来延长帮助盲人的MR设备的电池寿命。
本文提出了一种可行的MEC系统模型,针对MEC服务器上有限资源,提出了一种基于内容缓存方案的深度强化学习(Deep Reinforcement Learning,DRL)方法来做缓存决策,并提出一个新的效用函数来衡量缓存方案的性能。
1 系统模型和优化目标函数


图1 MEC场景架构图Fig.1 Network architecture of the MEC scenario
1.1 请求和缓存模型
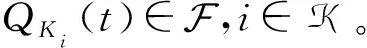
(1)
(2)
式中,CF_M是 MEC 中缓存内容大小的总和。
用户的请求到达SBS后,先检索MEC服务器缓存的内容。若在MEC服务器中检索到所请求内容,将直接传输给用户;否则,用户请求将被发送到云端,并从MR环境帧提供商检索并发送所需的内容;最后,中心云通过SBS 将内容交付给用户。
1.2 时延和能耗模型
本文系统总时延和能耗由两部分组成:数据检索和数据传输,只考虑MEC服务器所产生的能耗。
(1) 数据检索时延和能耗
用fC和fM分别表示中心云和MEC服务器的处理能力(即CPU每秒钟执行的周期数)。如果用户请求第i个内容,则获取该内容的检索时延可以表示为:
(3)

MEC的内容检索能力表示为Pr_M,由于只考虑 MEC服务器的能耗,则检索能耗表示为:
(4)
(2) 传输时延和能耗
由于请求信息的数据量明显小于请求内容大小,因此本文忽略了上行传输的成本。中心云和SBS采用光纤连接,且光纤数据传输速率表示为Dtrans_C。SB数据传输能力表示为Dtrans_M。假设每个用户获得相同的信道资源,则每个用户的下行数据传输速率为Dtrans_M/K。用Ptrans_M表示SBS的传输功率。如果用户请求第i个内容,则传输时延可以分为两部分:从中心云到SBS和从SBS到用户,记为
Ttrans_i=(1-Ci)·ttrans_i_C+ttrans_i_M,
(5)
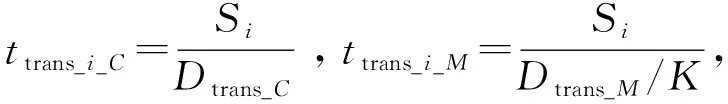
Etrans_i=Ptrans_M·ttrans_i_M。
(6)
(3) 时隙t的系统总时延和能耗

(7)
(8)
总的传输延迟和能耗可以表示为:
(9)
(10)
因此,在时隙t的系统总时延和能耗可以表示为:
(11)
(12)
1.3 缓存命中率和效用函数
本文还考虑缓存命中率这一指标。使用hk∈{0,1}表示用户请求的内容是否在MEC服务器缓存空间缓存命中。 如果用户k的请求命中,hk=1,否则hk=0。时隙t的缓存命中率可以表示为:
(13)
然后,基于用于多目标权衡加权求和法[9],定义了时隙t的归一化系统成本,包括时延、能耗和缓存空间资源,表示为:
(14)
ω+φ+μ=1,
(15)
式中,ω、φ、μ是超参数,表示时延、能耗和缓存空间资源的所占比例。Tmax(t)和Emax(t)表示系统在时隙t的最大时延和能耗。
此外,本文定义了一个新的效用函数,即缓存命中率与归一化系统成本之比,效用函数表示为:
(16)
1.4 优化目标函数
令τ表示一个时期的时隙数。由于很多应用更关注一段时间内的体验而不是瞬时体验,因此平均效用函数为:

(17)
优化目标函数为:

(18)
(18a)
(18b)
(18c)
hk∈{0,1},∀k∈K,
(18d)
ω+φ+μ=1。
(18e)
2 基于深度强化学习的缓存策略
2.1 深度强化学习
V(s)=
(19)

(20)
式中,s′表示下一状态。R(s,a) 为在时间τ的期望奖励值,P(s′|s,a) 为在状态s执行动作a到s′的转移概率。最优策略应满足贝尔曼方程:
(21)
采用Q-learning方法解决上述问题,Q函数为:
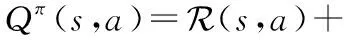
(22)
在状态s执行动作a后,可以获得折扣累积奖励。 智能体学习如何在每次迭代中选择Q值最大的动作,并在多次迭代后根据最佳解决方案智能地执行动作。公式化(21) 可以表示为:
(23)
设学习率为α,则Q函数表示为:
(24)
然后,收敛到最优动作值函数Qπ*(s,a)。
但是,在更复杂的环境中,状态空间面临维度灾难,RL方法将不再适用。文献[11]引入了DRL方法来解决尺寸爆炸问题。 深度Q网络(Deep Q-network,DQN)是DRL的典型例子,它通过深度神经网络逼近Q函数:Q(s,a)≈Q(s,a;θ),其中θ表示深度神经网络(Deep Neural Networks,DNN)的权重参数。目标Q网络的权重参数需要每周期更新一次(例如Nu步)。通过在每次迭代中最小化损失函数来训练它达到目标值:
Lloss=[(Qtarget-Q(s,a;θ))2]。
(25)
整个训练过程是Q值向目标Q值逼近的过程,目标Q值表示为:
(26)
2.2 马尔可夫决策过程
① 状态:在t时刻的系统状态为当前MEC服务器缓存情况s(t)=[CF1,CF2,…,CFF]。
② 行动:在每个时期,SBS应该决定缓存哪些内容以最大化效用函数。 因此,动作可以表示为Action(t)=[AF1,AF2,…,AFF],其中AFi={0,1}。
③ 奖励:系统会在每个状态返回一个奖励,设为优化目标。由于优化目标是最大化效用函数,将强化学习的奖励定义为U(χ)。
2.3 所提策略的实现
本文提出的基于DRL缓存方案的核心算法为Q-network。输入s(τ)和输出Q(s(τ),a(τ);θ) 之间的映射由神经网络结构决定。使用DNN 逼近非线性函数来实现Q-network。DNN的结构与文献[12]相同,包括3个全连接隐藏层,每层有256、256、512 个神经元。在DNN中,前两个隐藏层的激活函数设置为线性整流函数(Rectify Linear Units,ReLUs),第3个隐藏层函数设置为tanh函数。
此外,利用经验重放训练Q-network以提高方案的稳定性,经验数据(s(τ),a(τ),r(τ),s(τ+1))存储在容量为NB的回放池B中。当存储的经验元组数量大于ND时,从回放池B随机选择NM个经验数据来训练网络。采用ε-贪婪策略选择动作a(τ)来平衡开发和探索。探索率从初始值εs线性下降到最终值εe。基于DRL的缓存方案的详细过程如算法1所示。

算法1 基于DRL的缓存方案初始化系统和网络参数Forepisode=1,2,…,Mdo 初始化初始状态s(0)为随机缓存状态 Forτ=1,2,…,Tdo 基于ε-贪婪策略选择动作a(τ): 获取奖励值r(τ)和下一状态s(τ+1) 储存元组(s(τ),a(τ),r(τ),s(τ+1)) If τ≥ND 从B中随机选取少量样本进行训练 最小化loss函数使梯度下降 更新Q-network参数 每Nu步重置Q-network End ForEnd For
3 仿真实现
本文使用Python进行数值分析来评估所提方案的性能。所有的仿真都是使用在 Pycharm3.7 和 Tensorflow 2.4.0实现的,计算机的配置为:Intel (R) Core (TM) i7-8700 CPU、8 GB RAM。
3.1 模拟设置
在仿真实验中,考虑一个由MR环境帧提供商、中心云、小型基站和MEC服务器组成的小型网络。SBS覆盖区域半径为 200 m,用户服从泊松分布。中心云和 MEC服务器的 CPU 周期频率分别为fC=64 GHz和fM=16 GHz[13]。光纤数据传输速率为Dtrans_C=2 Gbit/s。数据传输速率为Dtrans_M=9.6 Gbit/s。MEC服务器的数据检索功率为Pr_M=2 500 mW。SBS的发射功率为Ptrans_M=20 mW[14]。内容的数据大小在[100,500] Mbit内随机分布。DRL中的相关参数设置如下:学习率α=0.000 1,折扣因子=0.9,初始探索率εs=0.9,结束探索率εs=0.001。假设所请求内容的流行度被建模为Zipf分布[15]。因此,用户请求的第i个内容的流行程度为:表示 Zipf 分布的形状参数,设置为常数值0.56。
本文将所提方案与以下方案进行比较:
① 遗传缓存:通过N代种群遗传、变异、交叉、复制得出问题的最优解。随机生成50对缓存方案作为父染色体,迭代500次,交叉概率和变异概率分别设置为0.7和0.02。
② 贪婪缓存:由于 MEC服务器的缓存内存空间大小限制,缓存尽可能多的流行内容。
③ 随机缓存:随机选择满足MEC服务器缓存内存空间大小限制的缓存方案。
3.2 仿真结果分析
基于DRL的缓存方案算法的收敛性能如图2所示,其中,ω=0.7,φ=0.2,μ=0.1,K=7,CM=1 400 Mbit,F=10。随着迭代次数的增加,损失值逐渐收敛。损失函数在前10 000次迭代中急剧下降,然后在15 000次迭代内基本稳定,因为开始执行的动作对奖励值的影响更显著。
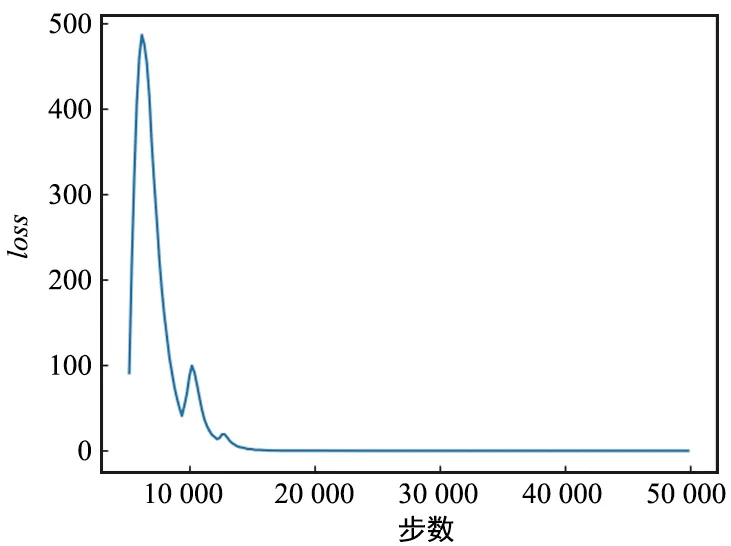
图2 Loss函数Fig.2 Training loss
图3显示了算法的时间复杂度和用户个数的关系,用单步平均运行时间表示时间复杂度。随着用户数目的增加,DRL缓存算法输出层神经元数变多,时间复杂度变大,但仍比其他算法时间复杂度低。

图3 时间复杂度对比Fig.3 Time complexity comparison
图4展示了4种方案在不同MEC服务器缓存内存空间大小的效用函数值。其中,ω=0.7,φ=0.2,μ=0.1,K=7,F=10。DRL缓存算法的效用函数值高于其他3种算法,说明本文提出的缓存方案的性能优于其他3种算法。此外,随着MEC服务器缓存大小的增加,DRL缓存、遗传缓存和贪婪缓存的效用函数值增加,因为MEC服务器有更多的缓存资源,可以缓存更多的内容,提高缓存命中率,时延会减少,但能耗和消耗缓存空间会增加。延迟在归一化系统成本中所占比例最大,故效用函数随着MEC服务器缓存内存空间的增加而增加。

图4 效用函数U(χ)vs MEC服务器缓存空间大小CMFig.4 Utility function U(χ) vs MECs caching size CM
图5显示了相同环境条件下不同用户数量对效用函数的影响。其中,ω=0.7,φ=0.2,μ=0.1,CM=1 400 Mbit,F=10。效用函数随着用户数的增加而逐渐减小。 因为随着用户的增加,分配给每个用户的带宽减少,传输速率降低,时延增加,导致效用函数值降低。此外,随着用户数量的增加,效用函数的降低程度逐渐减小,是因为随着用户数量的增加,传输速率的降低率变得更小。

图5 效用函数U(χ)vs 用户数KFig.5 Utility function U(χ) vs.User number K
图6显示相同环境条件下不同内容数量对效用函数的影响。
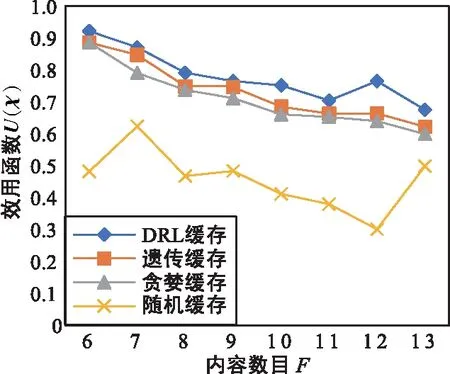
图6 效用函数U(χ) vs 内容数目FFig.6 Utility function U(χ) vs.Content number F
图6中,ω=0.7,φ=0.2,μ=0.1,CM=1 400 Mbit,K=7。随着内容数量的增加,整体效用函数值呈现下降趋势。因为随着内容数量的增加,用户请求的目标越来越多,缓存命中率降低,时延增加。效用函数值有起伏,在每种内容数情况下,会随机生成大小不同的内容,当内容总数较小时,相同的MEC服务器缓存内存空间可以缓存更多的内容,以提高命中率,减少时延,增加效用函数值。
4 结束语
本文针对5G混合现实应用中MEC服务器上缓存资源有限的问题,提出一种深度强化学习方法进行缓存决策,并构造一种新的效用函数衡量缓存性能,提高混合现实应用服务质量。详细研究了用户数、内容数、缓存空间大小对效用函数的影响,仿真结果表明,提出的算法与传统遗传和贪婪算法相比,可以用较小的时间复杂度做出更好的缓存决策,并可以改变用户数、内容数、缓存空间大小的权重,满足不同场景的要求,从而提高服务质量。
猜你喜欢
成都大学学报(自然科学版)(2021年1期)2021-05-22 01:31:20
电子制作(2019年23期)2019-02-23 13:21:12
测控技术(2018年6期)2018-11-25 09:50:10
铜仁学院学报(2018年6期)2018-07-05 09:47:50
黑龙江电力(2017年1期)2017-05-17 04:25:16
经济研究导刊(2016年30期)2016-12-24 08:08:52
CHIP新电脑(2016年9期)2016-09-21 10:31:09
系统工程与电子技术(2016年7期)2016-08-21 13:59:18
电测与仪表(2016年17期)2016-04-11 12:38:28
发明与创新·大科技(2015年9期)2015-05-30 10:48:04
