融入页面跳出率的权威页面鉴别算法
2022-02-08 12:55:18王嵘冰
辽宁大学学报(自然科学版) 2022年4期
王嵘冰,刘 鹤
(辽宁大学 信息学院,辽宁 沈阳110036)
0 引言
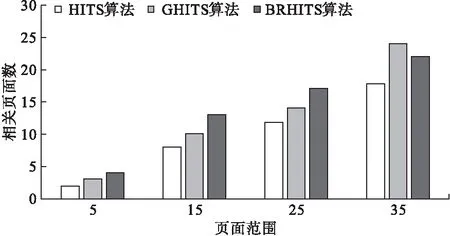
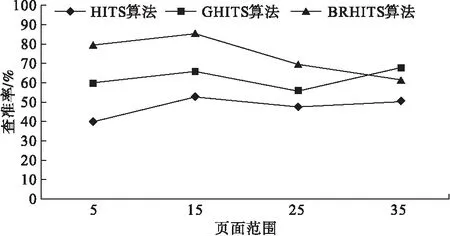
在信息技术蓬勃发展的今天,如何快速并且准确地查询到自己想要浏览的信息已成为一种挑战.Web链接结构分析算法是搜索引擎的一部分,对人们所获取的Web网页信息有着重要的评估作用.网络节点重要性排序是网络科学领域最基本的问题之一,节点排序算法在搜索引擎、社交网络和推荐系统等许多应用场景中都是必不可少的一部分,代表性排序算法为PageRank算法和Hyperlink-Induced Topic Search(HITS)算法[1-2].为了改进传统排序算法的排序效果,相关研究从用户历史行为角度出发,将用户兴趣度因子融入页面排序算法中[3],考虑到用户对网页的访问量、网页转载次数等,提高了搜索结果的准确性.但是具体来说,现有研究并未考虑影响页面流量质量这一重要指标,降低无关页面对排序质量的影响.即使网页访问量较多但仅凭该条件并不能说明网页的权威性,如果一个用户只是点击进入了该页面,但并没有点击该页面的任何链接就直接跳出,这只是增加了页面访问量.本文考虑了评估网页内容黏性突出的指标——跳出率[4],将它以网页权重因子的形式融入传统网页排序算法HITS中,从而可对权威页面进行鉴别,更新融入页面跳出率的权威页面鉴别算法的Authority值.本文拟搭建实验环境,对比实验验证搜索结果相关度情况,以期提高搜索结果的查准率.
1 相关研究
1.1 传统的HITS算法
HITS 算法是由康奈尔大学的JonKleinberg 博士于1997 年首先提出的[5],它的主要思想是根据网页的入度与出度来判断网页的重要程度,如果一个网页具有很高的权威性,那么这个网页所指向的其他网页也具有较高的权威性;如果这个重要性高的网页被其他的网页所指,那么指向这个网页的其他网页也具有着较高的权威性.在HITS算法中,Authority值也称为权威值,Authority值a(p)与Hub值h(p)的公式如下[5]:
(1)
(2)
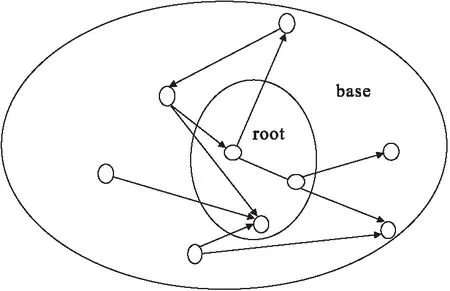
图1 将根集拓展为基集
对于每个网页p,权威值更新为所有导入链接所在的页面中枢纽值的和,枢纽值更新为网页p上所有导出链接指向网页的权威值的和.在反复迭代后,确定节点的最终权威值与枢纽值.由于直接按照两者的更新规则进行迭代会导致结果值出现偏差,因此有必要在每次迭代后进行归一化,使最终获得的值收敛.
HITS算法是基于一小部分网页进行计算的:首先通过文本搜索找到相关网页得到根集,然后找到与这些根集直接相连的网页得到基集.图1展示了将根集拓展为基集的示例[5].
吴江等[6]在HITS算法的基础上,运用网页排序改进算法识别意见领袖,从而衡量用户影响力.HITS算法不仅提供了网络节点的排名,还有助于了解不同域上的权威节点.基于HITS算法,李文静等[7]提出节点群发现算法HubsRank,基于引文网络中节点影响力,通过多轮迭代,得到引文网络中多主题覆盖的枢纽节点群,使提取枢纽节点群的速率得到了提高.此外,Liu等[8]提出了一种HITS结合PageRank进行蛋白质远程同源性检测的HITS-PR-HHBLITS预测方法.随着网络规模的扩大,针对页面排序算法在符号网络中的局限,陈晓威等[9]提出其改进算法,以识别社会网络中的关键节点.
1.2 相关改进算法
HITS算法和PageRank算法是两种具有代表性的排序算法[10],相关学者的研究大多基于这两种算法开展的.早期的HITS算法还存在着很多不足,例如主题漂移、网页欺诈、忽略用户行为的个性化需求.HITS算法利用内容权威和链接权威两个相互影响的权重来评估网络内容的价值和网络中超链接的价值[11-12].超链接多样性分析的网页排序算法,能够在寻找优质页面的同时抑制网页排名的作弊[13].杨博等[14]通过引入时间权值函数、分段函数、网页权值比函数、兴趣度函数改进页面排序算法中存在的问题.由于Web结构挖掘中HITS算法只考虑页面之间的链接关系而忽视了页面的具体内容,影响了搜索结果,为了抑制主题偏离现象,Wang等[15]把超链接信息检索方法与页面内容相结合,提出了一种改进的基于内容相关性改进的HITS算法(GHITS),虽然搜索结果与主题的相关度得到了提高,但未考虑无用链接对算法的干扰.
亓国涛[16]通过Web日志对用户网页浏览行为的访问页数、访问时长、访问深度、网页跳出率进行分析,并将用户停留页面时长与该页面平均停留时长的比值作为权重因子融入到网页排序算法中,但是即使在该页面的停留时间较长,但不再对该页面进行任何点击便跳出,上述情况说明该页面仍存在着网页排序质量的问题,其质量需要进一步提高.
2 改进的HITS算法
本文的目标是改善页面排序质量,使得搜索结果与主题相关度得到提高,而影响页面流量质量的重要指标为跳出率.文献[17]使用百度统计软件采集网站访问者行为数据,应用回归分析模型研究访客跳出率及网站流量的关联指标,得出访客跳出率与平均访问页面数有关,而网站流量与访问次数、新访客数、平均访问页数相关.因此考虑到页面跳出率因素,本文拟将其以网页权重因子形式融入页面排序算法HITS中,更新融入页面跳出率的权威页面鉴别算法的Authority值.
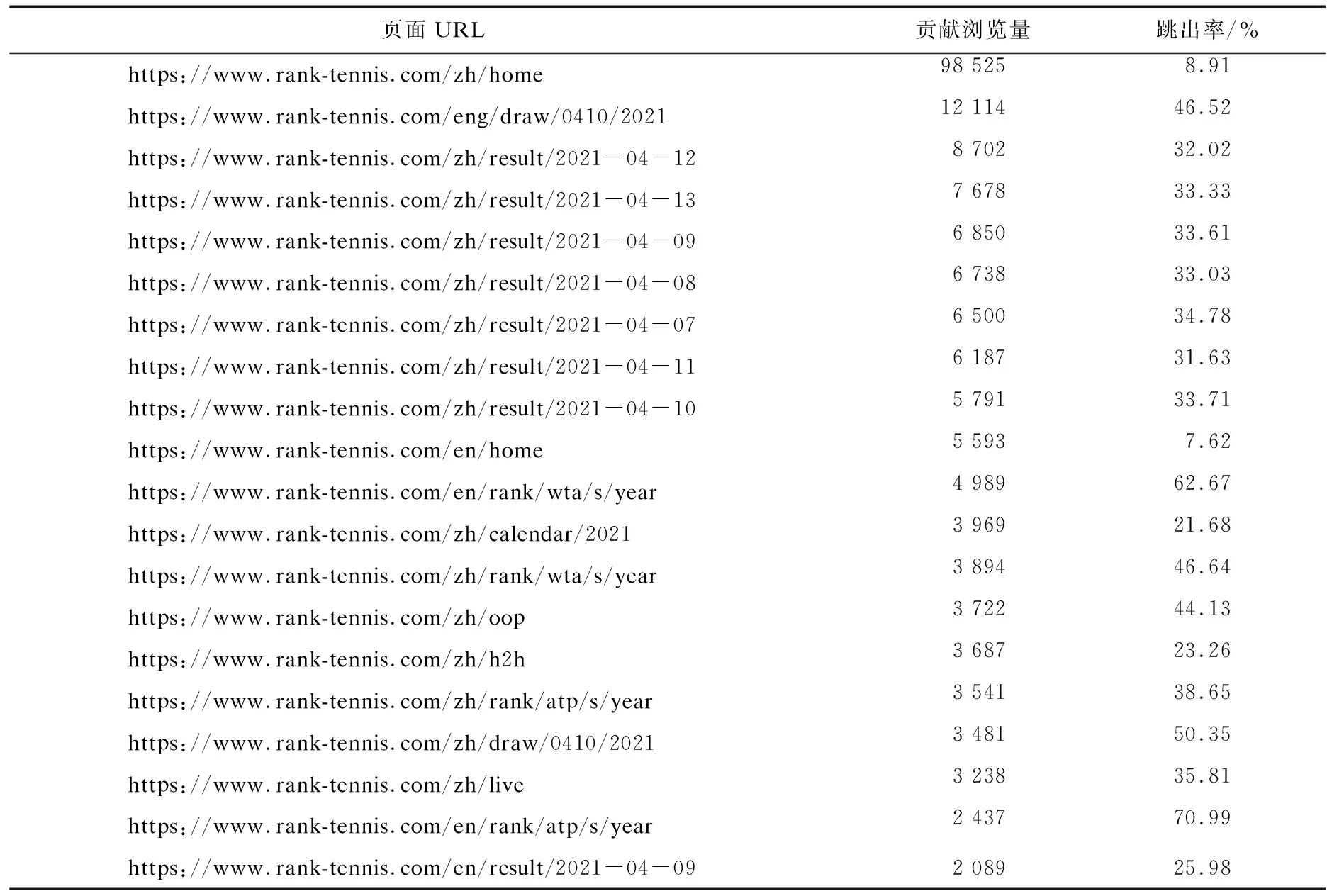
跳出率指浏览了一个页面便离开网站的访问次数占总的访问次数的百分比.页面跳出率可通过百度统计网站获取JavaScript跟踪代码,并复制此代码.如果是自己编写的一般网站,通常将跟踪代码粘贴到要跟踪的网页底部的