
基于远程监督的关系抽取研究综述
2022-02-04 04:53:22尚兰兰
河北省科学院学报 2022年6期
尚兰兰
(河北经贸大学信息技术学院,河北 石家庄 050061)
随着大数据时代的发展,需要处理的数据集规模越来越大,从海量的数据集中找到自己想要的信息并把他们提取出来,成为了人们研究的重点。信息抽取的主要目的就在于挖掘出有用的信息,作为信息抽取中重要的一部分,关系抽取的目标是给未知实体对分配一个关系。关系抽取的方法主要分为有监督、无监督、半监督和远程监督。有监督关系抽取是指事先准备好带标签的数据集,将新来的数据集中实体对之间的关系归属于已经事先定义好的标签中,但这种方法不适用于大规模数据集,因为如果模型训练时需要学习每类关系对应的特征,满足这些特征的实体对,就属于该关系,这就需要标注大量数据,占用的人力资源太多。无监督关系抽取方法是将语料库中的冗余信息做聚类进行分类,这种方法确实可以提取出大量的关系对,但其召回率和准确率较低。半监督关系抽取方法将少量的数据集作为种子,根据已经存在的关系模板,去推理出更多的关系组合,但是这样就会导致后面生成的关系会对初始的关系模板比较敏感,并且准确率不高。
2009年,Mintz等人[1]第一次提出了远程监督关系抽取的方法,通过这种方法能获得带标注的数据集,主要思想就是将大量无标注的语料库与现存的知识库进行启发式对齐,快速建立大规模有标签的语料。远程监督关系抽取实现了对数据自动标注,从而快速高效地得到人们想获取的信息。远程监督关系抽取解决了有监督学习中人工标注资源浪费问题和无监督学习中召回率低的问题。近年来远程监督已成为自然语言处理技术研究的热点。为此,本文对远程监督关系抽取的研究进展作一综述。
1 远程监督关系抽取研究思路和流程
1.1 远程监督关系抽取相关工作
2009年Mintz等人[1]将远程监督思想引入关系抽取中,并提出假设:如果两个实体有关系,则包含这两个实体的句子都表达这种关系。2010年Riedel等人[2]将Mintz等人提出的观点称之为“远程监督假设”,并提出了at-least-one假设,即若实体对间存在某种关系,那么包含有这对实体的所有句子中至少有一个句子中的实体对存在这种关系。基于此,Riedel把多实例学习引入到远程监督中处理数据,将包含有这对实体的所有句子组成一个句袋,对每个句袋进行研究和关系区分,但其忽略了每个实体对可以存在多个关系。
Hoffmann等人[3]和Surdeanu等人[4]提出了用多标签结合多示例学习共同处理数据。随着深度学习的普及,Zeng等人[5]提出了PCNN并且结合多示例学习的算法对生成的数据集进行分类和提取。为了提升关系抽取的准确率,Lin等人[6]和Han等人[7]分别在提出的分段神经网络的基础上,对句子间特征提取运用了注意力机制,起到了很好的效果。之后,研究者致力于改进神经网络的模型以及在模型中加入注意力机制来提高模型准确度。近些年,学者们不断地对远程监督关系抽取技术进行研究和改进,白龙等人[8]将远程监督关系抽取的相关方法分为基于概率图的、基于矩阵补全的和基于嵌入的三大类;王嘉宁等人[9]针对远程监督关系抽取过程中面临的噪声、信息匮乏和非均衡的问题,总结了相关方法及优缺点;周筱松[10]将远程监督关系抽取任务分为句子级别和包级别,并对每个级别出现的问题进行了改进。远程监督虽然可以解决大规模数据的问题,但质量并不能保证,所以这就导致生成的带标签的语料中会有很多错误标注,目前很多学者的重点在于研究如何解决关系抽取过程中的噪声问题,但在过程中除了噪声会对模型产生影响之外,信息不全问题或者长尾问题等也会造成模型测试效果降低。
1.2 远程监督关系抽取基本概念及流程
1.2.1 远程监督关系抽取基本概念
(1)实体:现实生活中抽象或者实际存在的对象。
(2)关系:实体对象与实体对象之间的语义关系。
(3)知识库:将抽取到的信息做汇总,并将他们转化为有用的知识,例如FreeBase、YaGo库。
(4)远程监督:将已经存在的知识库与未标注的非结构化数据进行比对,从而生成自动标注好的数据集。
(5)包:包中包含了这个实体对在数据集中所有关系的集合和这个实体对出现在哪些句子中的句子集合。
(6)词法特征:实体对中间或者两边的词汇相关信息,将这些成分的特征表示成向量拼接起来,体现出单词的特性。
(7)句法特征:对句子进行依存句法分析,分析词汇间的依存关系,例如并列、从属、递进,得到一条依存句法路径,再把依存句法路径中的各成分作为向量,拼接起来。
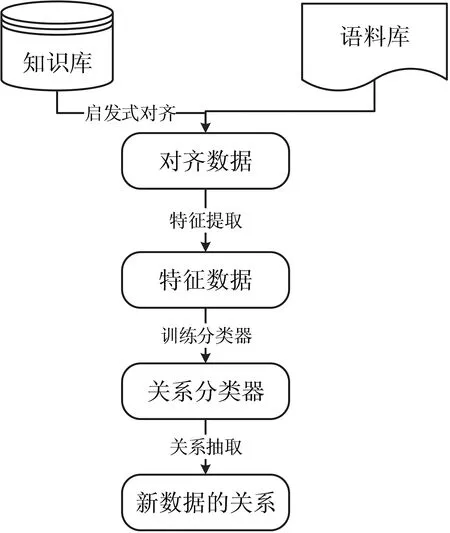
图1 远程监督关系抽取基本流程图
1.2.2 远程监督关系抽取基本流程
利用远程监督来进行关系抽取,首先需要将收集来的语料库进行实体识别,识别出语料库中的实体对,然后将语料库与现有的知识库进行对齐,得到初步的对齐数据。然后基于at-least-one假设,认为包含两个特定实体的句子都表示特定的关系,由此获得初步的对齐数据,之后提取文本的特征数据转化为特征向量,这些特征向量作为关系抽取模型训练的输入,最后得到标注数据。具体流程如图1所示。
2 远程监督关系抽取面临的主要问题及解决方法
远程监督关系抽取的优点是能够处理海量数据,且标注成本也大大降低,假设标注得到的实体关系没有误差,那这个任务就可归为分类问题处理。但基于“强假设”或者“至少一次假设”势必会引入错误的标注数据,其主要原因大概分为三个方面:噪声问题、信息不全问题以及长尾问题,下面将针对这三个方面进行详细阐述,如表1所示。

表1 远程监督关系抽取常见问题及解决方法
2.1 噪声问题
关系抽取中的噪声数据是指句子中包含实体对,但并没有体现这对实体的关系的句子。若句子为“Barack Obama is the 44th president of the United States.”,则生成的三元组,如表2所示。表3中给出的两个句子只有第一个句子符合知识库中保存的两个实体之间的关系,另一句中虽然包含的两个实体并没有描述这一关系,但是标签打的是“EmployedBy”,这就带来了噪声。
2.1.1 基于规则特征的方法
基于规则特征的方法针对词与词之间的联系,挖掘实体间显式的结构信息这一问题,采用了模式匹配的思想进行关系抽取,其优点在于基于语料库能够快速地给出词与词之间的语义关联,处理海量句子间的语义关联关系,但是由于语料库并不会包含所有的语义关联,因此准确率也会受到影响。为此,研究者围绕提高词与词之间关联关系准确率展开研究。

表2 三元组展示表

表3 远程监督公共服务均等化关系抽取过程示例表
Riedel等人[2]提出一种概率图的方法,给每个数据集的句子都分配一个隐形的变量,通过给隐形的变量进行赋值,从而达到关系抽取的目的。Takamatsu等人[11]模拟远程监督的方法对Riedel等人的方法进行了改进,提出了概率生成模型,提高了分类准确度。刘鑫[12]提出了不含参数的贝叶斯算法模型,解决了Horiuchi K等人[13]所运用的训练模型中参数过多的问题。但这种模型不适合较大的数据集,而且矩阵需要根据数据集随时更新。
黄蓓静等人[14]提出了结合词向量筛选关系描述候选词的方法,解决了相似的关系描述词没有被提取的问题,针对关系表达模糊或不能表达关系的句子,提出了句子模式提取、相似度计算、句子聚类,再进行模式评分的研究方法。黄杨琛等人[15]考虑到自然语言多因子等特征,提出了多示例学习思想与TF-IDF结合的过滤算法,利用词法和句法特征相结合的多参数综合的特征向量来解决将分类效果更准确问题。
虽然针对提高训练模型准确率问题的研究很多,但各种方法都有相应的局限性,目前还没有相对完善的方法解决这一问题。
2.1.2 基于深度学习的方法
基于深度学习的远程监督关系抽取实现了在大规模数据集中自动对齐提取有效的关系信息,并且可移植性较强,面对传统的方法和有监督学习方法已经有了自己的优势,但是同时也带来很多问题,例如层与层之间的传播误差,噪声问题等仍待解决和探索。
(1)基于PCNN及拓展模型的远程监督关系抽取。在Mintz等人[1]提出的远程监督算法基础上,Zeng等人[5]提出了利用分段神经网络自动捕捉文中的上下文信息,如图2所示。
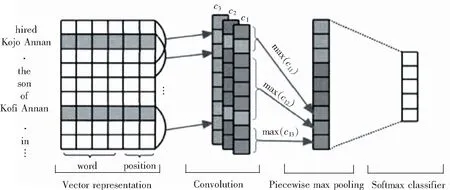
图2 PCNN结构图
这一模型首先将预训练的单词向量进行降维,然后将文本分成三段,分别对每一段进行最大池化,还考虑到了词向量所在的位置信息,此方法提高了处理文本较长时上下文相关信息丢失的问题,降低了时间复杂度。Lin等人[6]认为如果只选用包里的一个句子作为样本,会浪费好多数据,于是采用PCNN对包里的每个句子都做最大池化,提出注意力机制将每个句子与关系向量做乘积计算他们之间的相似度然后换算成权重,如图3所示,将包里所有句子的权重相加获得表示包的特征,通过对错误句子的权重进行降权处理从而降低噪声数据对分类结果的影响,然后将包的特征作为神经网络的输入进行分类。

图3 注意力模型结构图
Jat等人[16]认为句子中的每个词在句子中的权重是不一样的,所以提出了基于单词级别的注意力机制,将单词向量和句子向量的权重结合来获得更关键的语义信息提高分类效率。Yu等人[17]认为句子与句子之间有相关性,包与包之间也可以计算相关性,基于包的注意力机制,将句子权重和包权重结合更好地降噪。
蔡强等人[18]针对目前大多数关系特征利用不充分等特点,利用池化层中构建权重矩阵来评测句子中词语之间的关系相关程度。彭正阳等人[19]认为基于句子和单词的的注意力机制并不能很好地降低噪声数据带来的干扰,于是提出利用动态改变损失函数的方法,先将句子的词向量和位置向量放入卷积层得到特征向量,再进行分段最大池化,利用注意力机制计算每个句子最大池化后的权重系数,通过这一权重系数降低噪声数据的影响,之后将样本中交叉熵损失分布通过tanh函数对损失值进行了归一化统计,根据每个区间的样本密度,在损失函数中针对不同的数据样本赋予不同的权重,然后再将改变了权重的损失函数进行重新训练。
一要突出督查重点。党建工作涉及政治建设、组织建设、思想建设、作风建设、纪律建设等许多方面,既有日常性、经常性工作,也有突击性、阶段性工作,不可能每一次督查都把所有工作都纳入其中。为此,要根据上级部门的工作部署,根据年度党建工作计划,筛选出诸如专题教育、民主生活会、党风廉政建设等重点工作,排出运行表进行督查,以重点工作的落实,带动其它工作的全面规范。
乐毅等人[20]针对关系抽取中语义特征提取不充分及数据集缺乏的问题,提出了先用分段神经网络将文本分为三段,针对每一段进行最大池化,提取特征,然后在池化特征层和多示例层都引入注意力机制,这一模型在评价指标上比传统方法提高了5%左右,有效地降低了噪声数据的干扰。
钱小梅等人[21]针对运用密集连接方式的深度卷积神经网络模型,通过将不同层次的语法、句法和语义特征结合,来提高网络学习的的特征获取能力,从而充分提取输入数据中的语义信息。李艳娟等人[22]为提高关系抽取的准确性,将整个关系抽取模型分成域本体对抽取的结果进行约束,从而提高了抽取效率。
经典的关系抽取会因为误差传播,影响关系抽取的效果,因此采用PCNN方法来解决噪声问题效果会更好。
(2)基于残差网络的远程监督关系抽取。Alsabeh等人[23]结合了双向RNN和具有残差特性的CNN的优点,设计了ResNet和双向GRU模型,比仅运用残差网络模型效果提高了3%左右,并且移植性较强。
薛露等人[24]采用多通道的注意力机制解决了单通道注意力机制分配权重时出现的忽略重要词汇的误差情况,另外针对利用卷积神经网络处理数据集进行分类时,会忽略实体的位置信息和特征之间的空间关系这一问题,郭晓哲等人[25]提出用基于注意力机制及胶囊网络的多通道关系抽取模型来进行分类。
2.2 信息不全问题
由于目前的知识库和语料库都比较稀缺,导致语料库输入之后与知识库中对齐的实体对数量较少,造成实体对关系抽取训练不够充分,最终导致得到的关系信息不全。在本身就存在大量噪声数据的前提下,信息不全问题,更不利于数据集的训练,
白龙等人[8]基于多示例的思想对人物关系进行提取,提出了基于同义词林和规则的关系抽取方法。先将包含这两个人物实体的句子放到一个包里,然后利用同义词林对关系描述词进行词频统计,找出最多的关系词和次多的关系词将他们作为关系候选词,之后再利用判别规则判断人物之间的关系。在包中判断出人物关系之后,再对其进行多关系预测,最终得到人物关系预测结果。解决了数据测试集中未能标出的人物关系的问题,这一模型的缺点是可移植性不强,得到的结果噪声数据可能会较多。
2.3 长尾问题
长尾问题是远程监督中遇到的新问题,其主要体现在各个关系的标签对应的实体对或者在与知识库对齐的过程中语料库中数据量不均匀。长尾问题主要表现在少部分标签对应的实体对较多,大部分的实体对对应的数量较少,较少的关系标签对应的语料缺乏,导致这一部分实体对不能够充分地训练,最终得到的模型有大的偏差。
2018年,Peng等人[26]提出将分层关系结构利用关系依赖的信息构造一个分层注意力机制的范式,然后将分层注意力范式作为特征输入到神经网络中,得到的关系抽取结果较为理想,能够较好解决长尾问题。在此基础上,Gui Y等人[27]认为头数据和尾数据是有关系的,利用头数据上面的学习知识,能够增强尾数据的学习。难点在于学习关系之间的依赖和利用关系间的依赖。为了学习关系的表示,Gui Y等人采用类别嵌入的方法来表示关系类别,并且利用KG和GCN分别显示隐式和显式的关系嵌入,对关系嵌入进行了初始化。
3 远程监督关系抽取的主要应用领域
3.1 面向开源情报处理的远程监督关系抽取
王丽客等人[28]从关联和倾向两个角度出发,建立时间序列模型拟合关系网络的变化,达到获取情报信息的目的。赵国清等人[29]将海量的半结构化或非结构化开源情报文本数据作为数据源,对其进行将实体与远程数据库对齐的操作,使得数据源自动标注,大大降低了成本。
3.2 面向少数民族实体领域远程监督关系抽取
与英文知识库相比,中文资源库虽然相对较少,但近几年仍在快速发展,潘云等人[30]引入标签传播算法与部分未标注的任命对进行配对,但这个算法并没有对噪声部分进行处理。黄蓓静等人[14]利用词向量与句子模式聚类、模式评分的方法,对原始数据集中出现标注错误的部分进行筛选降噪。黄杨琛等人[15]提出了引入多示例学习思想到训练数据的方法,采用基于TF-IDF的关系指示词解决降噪问题。对于地方方言的知识库更是少之又少。王丽客等人[28]将藏文材料作为数据源与已经构建的藏文知识库进行比对,将分段神经网络结构和多示例学习结合提高了关系抽取的准确率,利用动态语言模型和多级注意力融合机制结合的远程监督关系抽取方法降低了噪声干扰的影响。黄杨琛等人[15]提出了远程监督的多因子任务关系抽取模型。
3.3 面向军事领域远程监督关系抽取
郑杜福等人[31]针对军事文本提出了基于ERNIE的军事文本三元组关系抽取模型。苟继承[32]构建了小型的军事知识库,利用基于PDCNN的多注意力机制关系模型对军事语料中的关系进行去噪,提出基于实体名称相似度来扩大军事知识库。韩丹[33]提出了多元数据采集方法为挖取出更多有价值的数据做了强有力的支撑,用基于神经网络和注意力机制进行军事装备之间的关系抽取,通过远程监督获取大量训练集,采用GUR模型克服了长距离依赖问题,为了噪声数据带来影响,在句子层面又加入了注意力机制。
3.4 面向招投标领域远程监督关系抽取
陈雨婷等人[34]针对招投标数据的特点,提出了基于因子图模型与领域特征相结合的关系抽取方法,并针对噪声问题提出了基于负例数据学习的降噪方法,结合知识融合从而提高了招标领域知识库远程监督关系抽取的质量。
4 研究重难点
基于远程监督关系抽取的方法越来越多,但随着研究的深入,远程监督关系抽取技术也发现了一些重难点。
4.1 错误标注问题
远程监督中的句子是通过与现有的知识库进行对齐自动标注的,因此得到的结果中难免会出现很多的带有错误标签的实体对。造成错误标注,即出现噪声的原因有两种,一种是因为提出的“如果知识库中存在两者实体对之间是这种关系,那么所有包含这两个实体的句子中都有表达这两个实体的关系联接词”和“如果知识库中存在这两个实体的关系,那么在所有包含这两个实体的句子中至少有一个存在这种关系联接词”这两种假设理论,引出了将包含这两个实体的句子都放到同一个包里,但是如果包里的句子都不能表达这两个实体的关系,那么就会出现错误标注的情况。另一种是知识库中原本就没有这两种实体之间的关系,那么当知识库对齐时,反馈回来的结果就是两个实体没关系。
基于以上两种原因,目前学者都在做降低错误标注权重的工作,即将注意力机制引入使得错误标注的数据权重降低,减少对关系抽取结果的影响,因此这一问题值得大家继续探究。
4.2 跨句多元关系抽取问题
综合来讲,远程监督关系抽取的方法和实现效果已经得到了很好的反馈。但是,虽然远程监督关系抽取能缓解数据标注问题,可是这种对知识库的质量要求很高,所以为了使得样本关系更准确,可以利用关系之间的依赖关系和语篇之间的上下文联系结合,利用远程监督的思想实现跨句关系抽取。
如示例“EGFR基因第19外显子缺失突变16例,第21外显子L858E点突变10例。所有患者均接受吉非替尼治疗,所有的病人都被治好了。”中,这两个句子都展现了同一个事实,三个实体之间存在三元组关系,但是在句子中并没有体现出来。EACL方法主要是利用图表示将依存关系和语篇关系结合,从多条路径提取特征,明显提高了特征提取的准确性和鲁棒性。针对将数据直接划分为正负示例时产生的噪声问题,提出了共现实体对间最小跨距,来减少噪声数据的产生。ACL是一种graph LSTMs框架,可将句间和句内的各种依赖关系综合,高效地利用上下文表示,使得与关系相关的多任务学习成为可能。EMNLP方法是graph-state LSTM模型,使用并行状态对每个字进行建模,通过消息传递递归的更新状态值,优点在于保留了之前的图结构,加快了计算速度。
5 结语
由于信息时代数据量的急剧增加,基于远程监督关系抽取的方法目前越来越受大家关注。本文对远程监督关系抽取的研究现状、存在问题和解决方法作了总结分析。
初期基于规则特征的方法应用到关系抽取中,虽然可以对文本数据进行关系抽取,但在效率及信息知识完整等方面仍有欠缺。学者们将远程监督思想应用于自然语言处理领域的关系抽取任务中,利用机器学习和深度学习,研究并拓展了各种训练模型,在一定程度上提高了关系抽取结果的准确性。之后,强化学习也应用到了此领域,例如在解决关系抽取的长尾问题中,利用强化学习做数据增强的辅助任务等。相信以后会有更多学者利用人工智能技术来研究改进远程监督关系抽取模型,从而提高关系抽取任务的效率和准确率。此外,在远程监督关系抽取模型的评估方法方面,由于目前智能评估存在有错误标注影响评估结果,但全部采用人工评估又浪费财力和人力,因此,学者们仍在探究更好的评估方法。
猜你喜欢
军事文摘(2022年20期)2023-01-10 07:18:38
英语文摘(2021年11期)2021-12-31 03:25:18
中国外汇(2019年18期)2019-11-25 01:41:54
制造技术与机床(2019年6期)2019-06-25 10:17:46
学生天地(2018年19期)2018-09-07 07:06:30
哲学评论(2017年1期)2017-07-31 18:04:00
领导决策信息(2017年9期)2017-05-04 04:04:49
领导决策信息(2017年9期)2017-05-04 04:04:49
中国交通信息化(2016年9期)2016-06-06 07:42:23
图书馆研究(2015年5期)2015-12-07 04:05:48
