
一种分布式声音档案数据挖掘方法研究*
2022-01-25 06:57:30鲜娅静
云南师范大学学报(自然科学版) 2022年1期
鲜娅静
(西安医学院,陕西 西安 710021)
1 引言
随着计算机科学与通信技术不断发展,电子档案技术已广泛应用于各行各业[1-2].档案管理中收集的数据量往往超过了使用传统串行处理技术分析和有效提取重要信息的能力.在过去的十年中,语音识别[3]、地震建模[4]和图像处理[5]等各种大数据应用表明,使用并行和分布式计算的高速数据处理是解决这一问题的有效方法.
声音档案数据[6]管理与分析是近年来一个研究热点,主要是实现对大量声音集合的管理与高级数据分析.国内外众多学者对此进行了研究,并取得了丰硕成果.董一超[7]根据英国声音档案馆建设方面积累的经验,为我国声音档案建设工作提供了一些合理性建议.Müller[8]论述了声音档案馆运营环境的日益数字化、网络化和用户化,以及其支持无数用户利用馆藏声音档案数据进行学习、体验和创作的应用需求.胡立耘对声音档案的数字化信息组织进行了研究,提出加强不同元数据的映射和互操作,实现声音记录的数字化转换与保存.上述大部分文章对各自领域声音电子档案数据管理建设方面进行了研究,对声音档案数据使用与分析研究有待提升.此外,目前比较典型的声音档案数据分析方法为串行处理方式[9],这在很大程度上影响系统执行效果.为此,本文提出了一种并行模式下挖掘大量声音档案数据的模型.通过将串行模型与解析映射和聚合算子相结合,实现了并行分布式分析方法.
2 声音档案挖掘算法
2.1 串行模型
图1所示为用于挖掘感兴趣信号的声音档案的系统框架图.系统中连续采样声源为s(n),其中n是最大长度N的离散时间索引.系统中处理硬件资源用符号Pw标记,其中P表示资源池,w表示工作索引序列.串行案例使用单个工作进程,此时Pw=1.数据挖掘算法用fi表示.
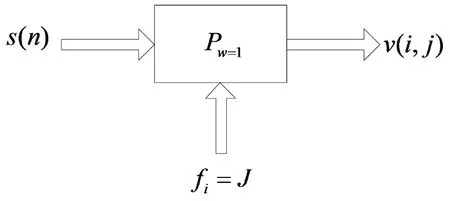
图1 声音档案数据挖掘中串行模式
在系统中,可以使用几种不同的算法来提取模式、形状和其他度量,且每个算法都可以使用索引{j=1,2,…,J},其中J为fi的最后一个算法.对于每个数据挖掘算法,输出结果都是以v(i)表示的事件.本文中v(i)可以看作是与输入序列的n个采样点重合的连续事件序列,即有‖i‖=‖n‖.令系统中所有算法的输出集合描述为v(i,j),则串行模型为
v(i,j)=s(n)·fi·Pw=1,
(1)
其中,s(n)为输入信号;fi为数据挖掘算法;Pw=1为单个工作进程的处理池.
2.2 数据块映射和聚合规则

(2)
(3)
(4)
进一步,声音档案数据通过收集所有数据块重新组合,处理时使用的并集运算符描述为
(5)
逆映射通过应用于输出v(i,j)的聚合规则进行,具体定义为
(6)
2.3 并行分布模型
并行分布式声音档案数据挖掘模型如图2所示.与串行模型相比,添加了映射和阶段,以提供数据块(式(2))的创建和输出(式(6))的重构.分布式模型显示一个进程池,且有Pw>1和最大进程池Pw=W.
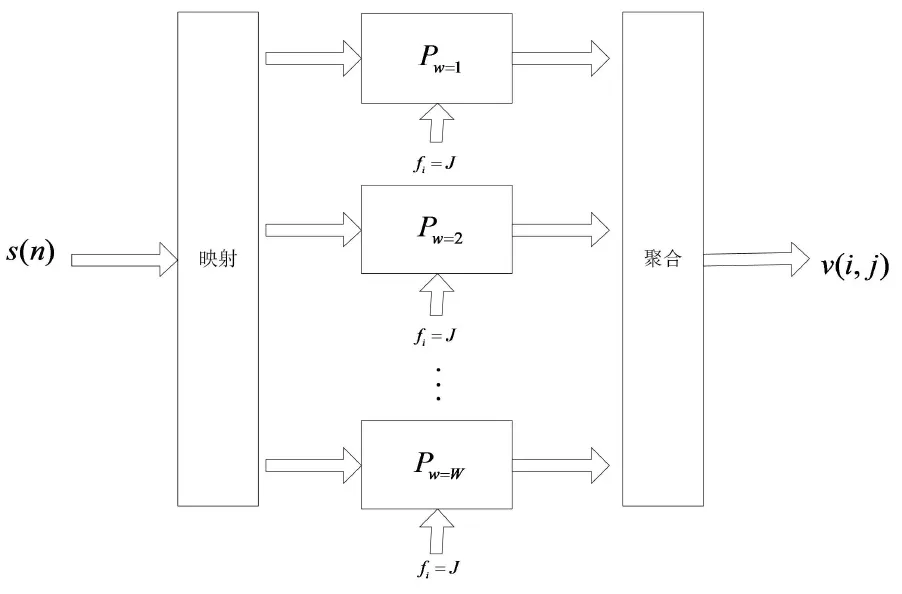
图2 档案声音数据的并行分布式提取模型
综合式(1)(3)和(4),则并行分布分析模型描述为
vw(i,j)=sw(n)·fj·Pw,
(7)
输出可进一步更新为
(8)
2.4 性能指标
采用程序运行时间和效率因子进行性能度量.对于串行进程,程序运行时间是数据挖掘作业的停止时间和开始时间之差.对于并行分布式处理,许多进程一起执行.每个进程将以不同的速率完成各自任务,然而磁盘管理系统只能为每个vw(i,j)结果处理有限数量的写操作请求.由于进程将在不同的时间完成,运行时间性能T由最后一个进程完成|vw|max的时间减去作业开始时间之差,即
T=|vw|max-tstart,
(9)
效率因子γ定义为运行时值的比率,即
(10)
其中,Tref是串行处理运行时间的参考值;T是工作进程池为w=W的分布式运行时间.
3 执行方法
3.1 数据集与数据挖掘算法
测试声音档案数据集以194 kHz和16位分辨率采样.声音档案中wav音频文件的存档大约630 GB的数据.本文采用两种数据挖掘算法,且每个算法都是一个检测器分类器.第一种是专门针对脉冲序列检测器分类器(算法f1)[10];第二种是常规数据源检测分类器(算法f2)[11].
3.2 可扩展性
可扩展性通过一系列本地网络连接的分布式服务器衡量.系统运行时同时有四个任务运行,每个任务使用不同的处理器的组合.运行包括四个可伸缩的工作配置:串行Pw=1、8工作进程池Pw=8、16工作进程池Pw=16和64工作进程池Pw=64.
采用式(9)度量每个算法的运行时间(见表2),并以性能Pw=1作为基线,使用式(10)度量每个工作进程池配置的效率.
3.3 并行性
并行性的测量分为两个步骤:
步骤1:使用串行模型(式(1))分别运行表1中的两个算法.其次,记录两个算法运行时间度量:算法f1的运行时间T1和算法f2的运行时间T2.再次,记录f1和f2的线性组合,记为T1+T2.
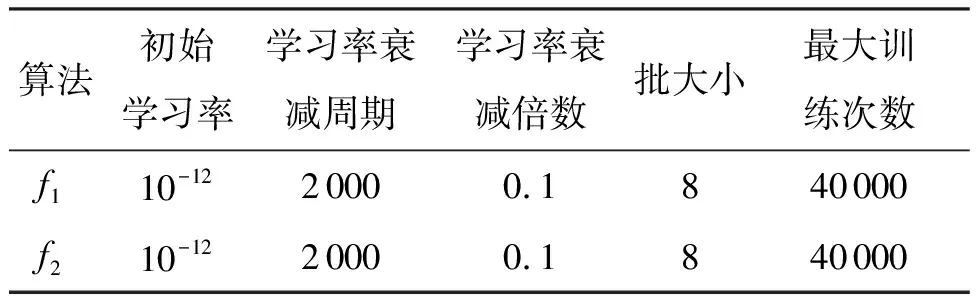
表1 数据挖掘算法部分参数
步骤2:使用声音档案数据挖掘模型同时运行两个数据挖掘算法(式(8)).对于1、8、16和64个工作池配置,测量其并行时间(记为T1,2).
4 仿真与分析
表2为串行情况下算法的运行时间,T1和T2分别是算法f1和f2的运行时间,串行运行时间的线性组合由T1+T2给出.

表2 串行模型性能
表3所示为本文算法扩展到更多进程池时的性能结果,其中不同算法运行时间由基于1、8、16和64个进程池确定.通过测量串行结果Tw=1与给定进程池和算法对Tw=W的运行时间的函数关系,计算每个算法的效率.可以看出,当进程池为1时,算法运行可理解为运行在串行模型.随着进程池数量增加,系统运行效率逐渐提高.当进程池为64时,效率可达到23.5倍.仿真结果符合实际情况,进一步验证了所提方法的有效性及实用性.

表3 多进程池模型运行性能结果
5 结语
对声音档案数据挖掘方法进行了研究与分析,并提出一种并行分布式声音档案数据挖掘模型.仿真结果表明,随着进程池的增多,系统运行效率明显提升.然而这将会导致系统能耗增多,实际使用时需要考虑资源受限及能耗损耗等情况.未来可将能耗、资源等限制条件引入模型,进一步增强系统实用性.
猜你喜欢
大众投资指南(2021年35期)2021-02-16 01:06:26
中国外汇(2019年20期)2019-11-25 09:54:58
能源(2017年10期)2017-12-20 05:54:07
能源(2017年5期)2017-07-06 09:25:54
电力与能源(2017年6期)2017-05-14 06:19:37
信息通信技术(2015年6期)2015-12-26 01:16:46
雷达与对抗(2015年3期)2015-12-09 02:38:50
自动化博览(2014年12期)2014-02-28 22:34:27
民主与科学(2014年3期)2014-02-28 11:23:03
电子设计工程(2014年18期)2014-02-27 12:00:13
