
基于YOLO的街景影像中行人车辆检测方法
2022-01-24 06:32王朝辉王润哲郭震冬
北京测绘 2021年11期
王朝辉 王润哲 郭震冬 黄 亮
(江苏省测绘工程院, 江苏 南京 210013)
0 引言
移动测量车[1]以车辆为搭载平台,集成全球导航卫星系统(Global Navigation Satellite System,GNSS)接收机、惯性测量单元(Inertial Measurement Unit,IMU)、里程计、全景相机、三维激光扫描仪等传感器,可以获取城市道路环境的360°街景影像[2-3]和三维激光点云。街景影像广泛应用于交通信息采集[4-5]、城市部件调查[6]、城市兴趣点测量[7]、导航数据采集[8]、街景地图等领域中。街景影像中包含大量的行人车辆信息,不做脱密处理直接发布会侵犯他人隐私[9],同时行人车辆信息也是提升城市治理能力的重要数据内容。
街景影像和一般近景影像具有较大区别:首先是表达的环境复杂,街景影像里可能有建筑、车辆、行人、植被、道路、交通标示、城市部件等各种各样的地物;其次是数据量庞大,单张街景影像的经纬映射图可达到数千万甚至上亿的像素;最后是目标距离变化大,导致同样的目标在影像中尺寸和清晰度差异很大。这就导致现有的行人、车辆检测方法在应用到街景影像中时均存在一定的局限性。为此,本文提出一种兼顾效率和精度的街景影像中行人车辆检测方法,在检测前,利用球形投影原理和先验知识从街景的经纬映射图中划分出目标区域[10],减少算法的搜索数据量和范围,提高后续检测的速度并降低误检率;检测时,针对街景的海量数据和复杂背景,选用你只观察一次(You Only Look Once,YOLO) v4模型从目标区域快速寻找行人和车辆[11]。实验证明,本文方法具有检测速度快、准确率高等优势,可以应用到实际项目的数据生产中。
1 方法理论
1.1 街景有效区域提取
街景影像通常采用的是三维球形投影,但在计算机中为了便于存储、传输,采用了经纬映射图的格式。经纬映射图的图像坐标(x,y)与球面经纬度(θ,φ)的转换关系如图1所示[10]。其中P为实际地物点坐标,P′为地物点在全景球面上的坐标,p′为地物点在经纬映射图中的坐标,r为全景球的半径。

图1 经纬映射图
根据经纬映射图的原理,其y坐标与影像高度的比值φ,即摄影中心到地物连线与天顶的夹角。其x坐标与影像宽度的比值θ,即摄影中心到地物连线的方位角。在图2所示的经纬映射图中,w和h分别表示经纬映射图的宽度和高度,A区域代表的是全景相机所在水平面以上的场景,由于全景相机安置在汽车顶部,且自身有一定高度,因此,该区域影像内出现行人、车辆的概率很小。B区域代表的是以全景相机为顶点,过全景相机的垂线为轴线,半径和高度均等于全景相机到地面距离的圆锥内的场景,该区域内主要是移动测量车本身,基本不会出现其他行人、车辆。A、B区域占街景影像数据量的3/4,如果检测时跳过这些无效区域,不仅可以有效提高检测速度,而且大大降低了误检率。
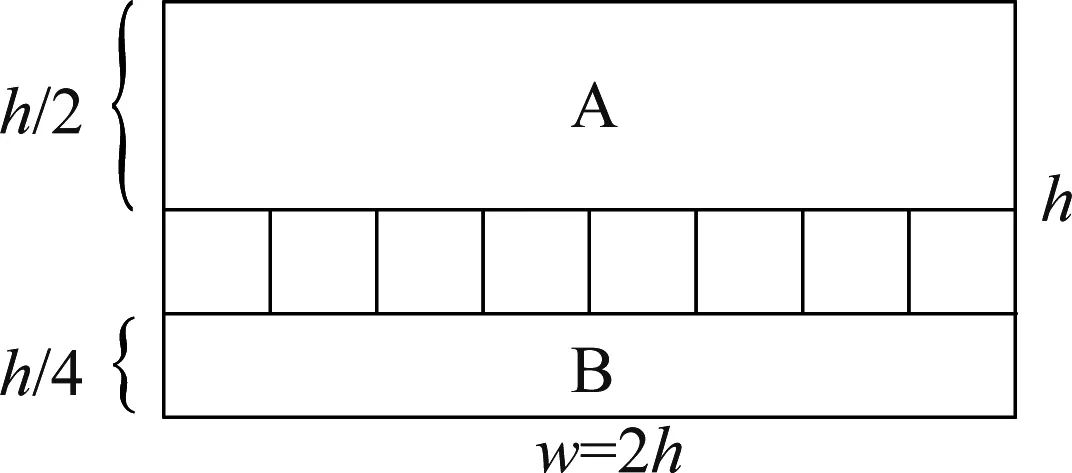
图2 有效区域分割
剩下的区域是需要重点检测的部分,按照深度学习处理图像的特点,继续将其划分为8块边长为h/4的正方形图像块。
1.2 目标检测
目标检测包含物体识别和物体定位两个任务,其深度学习模型可以分为两类:第一类是Two-Stage(两步)形式,将物体识别和物体定位分为两个步骤,以结合区域候选的卷积神经网络(Region Convolutional Neural Networks,R-CNN)、快速R-CNN(fast R-CNN)、 更快R-CNN (faster R-CNN)为典型代表,优点是误检率低、漏检率低,缺点是运算速度慢,不适用于街景的大数据量。另一类是One-Stage(一步)形式,以YOLO系列、单向多框探测器(Single Shot MultiBox Detector,SSD)等为典型代表,将物体分类和物体定位在一个步骤中完成,识别速度非常快,准确率也能接近faster R-CNN的水平。通过对已有研究成果的分析总结,YOLO v4是一种适用于街景影像中行人车辆检测的模型[12]。
主要步骤如下:(1)加载网络,导入标准的配置文件YOLO v4.cfg和权重文件YOLO v4.weights;(2)将街景影像的有效检测区域分割为8个正方形图像块,并进行空间尺寸、图像深度、光照处理等预处理;(3)将输入的图像块分别构造二进制大型对象(Binary Large Object,BLOB),然后执行检测器的前向传递,得到检测对象的边界框、检测对象的置信度、检测类标签;(4)YOLO会对每个检测对象框给出约3个候选框,利用非最大值抑制,将置信度最大的框保存;(5)标记显示:将边界框、置信度、类别等信息绘制到街景影像中。
2 试验与分析
2.1 数据采集
利用SSW移动测量车(图3)搭载全景相机、GNSS接收机、惯性测量单元等传感器,在城区采集街景影像,取出典型区域的500张进行数据测试。

图3 移动测量车示意图
2.2 目标检测
程序开发使用Visual Studio 2017作为开发工具,C++作为编程语言,OpenCV 4.4作为图像引擎,YOLO v4作为检测模型。硬件环境为ThinkStation P520W图形工作站,配备了大容量内存、固态硬盘、高性能显卡、多核中央处理器。
OpenCV读取街景影像后,将有效区域的8个图像块抠出,如图4所示。

图4 街景影像
利用8核并行处理,进一步提高YOLO v4检测速度。如图5所示,从分块3的检测结果可以看出,三个行人(男人、女人、小孩)均检测出来,三辆车(轿车、SUV、面包车)均检测出来,只有一个人蹲在汽车后面,拍到的部分太少,漏检了。从分块6的结果可以看出,两个骑车的行人均检测出来,一辆轿车也检测出来,位置、数量、类别完全正确。

图5 检测结果
2.3 结果分析
经过统计,本文方法的检测结果如表1所示。对于车辆的检测,正确检测的数量占样本总数的91.3%,遗漏检测的数量占样本总数的8.7%,错误检测的数量占样本总数的6.5%。对于行人的检测,正确检测的数量占样本总数的73.1%,遗漏检测的数量占样本总数的26.9%,错误检测的数量占样本总数的6.2%。
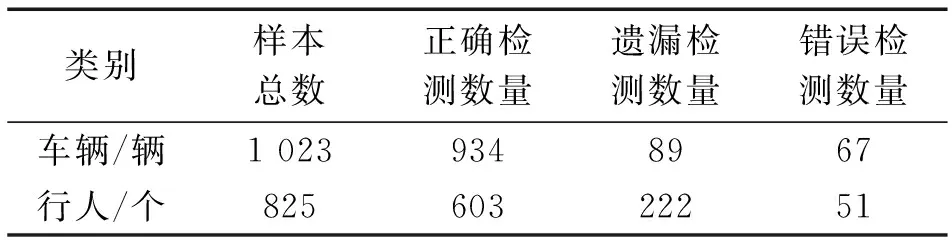
表1 检测结果
经过有效区域分割提取再检测,本文方法的行人车辆检测准确率和直接使用YOLO检测整张影像相当,但错误检测的比例有效降低。通过剔除街景影像中四分之三的无效区域,并将有效区域分割为8块做并行处理,每张街景影像的检测时间缩短到21 ms,优于直接处理整张影像的49 ms,速度提升57%。
3 结束语
街景影像具有记录场景复杂、单张数据量大、目标距离变化大的特点,导致现有的行人和车辆检测算法无法完全适用。为此,本文根据街景球面投影的原理分割出候选区域,减少了四分之三的数据量,同时降低了误检率。将候选区域划分为8个正方形图块,利用YOLO v4模型并行检测行人和车辆,取得了比较理想的检测精度和运行速度。
车辆和行人检测的结果还无法直接用于街景影像的脱密处理,进一步的研究工作,要在行人和车辆被准确检测的基础上,继续捕捉人脸区域、车牌区域,利用模糊算法进行脱密处理,实现自动化的数据发布预处理。
猜你喜欢
China Textile(2022年3期)2022-07-12
兵团工运(2021年5期)2021-12-07
北京大学学报(自然科学版)(2021年3期)2021-07-16
电脑爱好者(2020年19期)2020-10-20
学生天地(2020年1期)2020-08-25
小学生(看图说画)(2019年12期)2019-12-21
集装箱化(2018年2期)2018-04-03
幼儿智力世界(2017年5期)2017-07-12
儿童故事画报(2016年5期)2017-02-07
集装箱化(2016年4期)2016-05-26
