
基于CNN-A-BiLSTM 的太阳辐照度中长期预测
2022-01-23 07:10刘佟,赵军
宁夏工程技术 2021年4期
刘 佟,赵 军
(宁夏大学 信息工程学院,宁夏 银川 750021)
太阳辐照度预测的精度是影响光伏发电量的重要因素,目前国内外学者对太阳辐照度预测作了大量相关研究。根据预测时间跨度的不同,太阳辐照度预测分为超短期预测、短期预测、中长期预测。其中超短期预测为分钟预测,短期预测为小时预测,中长期预测为1~15 d 预测。根据预测方法的不同,辐照度预测模型可分为机器学习模型、神经网络模型以及混合神经网络模型。
A.Heinle 等[1]提出了K 近邻算法对天气进行判断,对训练子模型进行辐照度预测,其准确率可达74.85%。张玉等[2]提出了基于天气聚类的光伏电站辐照度预测,较传统辐照度预测模型其适应性更强。赵书强等[3]提出了基于长短期记忆神经网络的地表太阳辐照度预测,在太阳辐照度短期预测问题上,与传统人工神经网络相比,均方误差降低88.48%。钟振兴等[4]提出了基于云图与气象数据的辐照度预测,采用轻量级卷积神经网MobileNet 进行辐照度预测,实现了太阳辐照度短期快速预测。王建铭等[5]提出了基于CNN-LSTM 网络的太阳辐照度超短期预测方法,采用将卷积神经网络和长短期记忆神经网络混合的方法进行太阳辐照度短期预测。杨春熙等[6]提出了基于GRU 网络的太阳辐照度短期预测,均方误差(RMSE)仅为0.056。
综上,太阳辐照度预测中,应用较为广泛的深度学习模型包括BP 神经网络、长短期记忆网络、卷积神经网络、混合神经网络。目前,深度学习模型存在2 个问题:①模型泛化能力差;②中长期预测误差较大。
针对问题①,本文所提模型通过残差卷积神经网络进行特征提取,同时采用多地区数据进行训练,增强模型的泛化能力。针对问题②,本文所提模型在深度网络的基础上融合注意力机制,增强特征选择,减小中长期预测误差。
本文所提CNN-A-BiLSTM 模型通过残差卷积网络提取序列的时序特征,再由基于时间步注意力机制的双向长短期记忆网络提取空间特征,从而完成太阳辐照度的预测。该模型旨在解决太阳辐照度中长期预测误差较大的问题,提高太阳辐照度预测模型的精度以及泛化能力。
1 模型设计
1.1 残差卷积神经网络
卷积神经网络是一种通过卷积运算对数据进行抽象特征提取的多层前馈神经网络,其结构常包含输入层、卷积层、池化层、全连接层、输出层5 部分。卷积神经网络CNN 基本结构见图1。
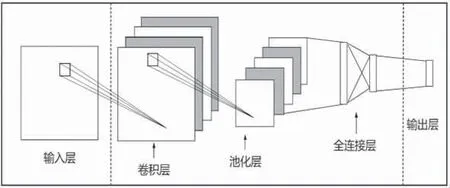
图1 CNN 基本结构
2016 年K.M.He 等[7]提出残差网络,其内部的残差块采用跳跃连接,有利于减小梯度消失和梯度爆炸的风险。残差网络基本结构见图2。
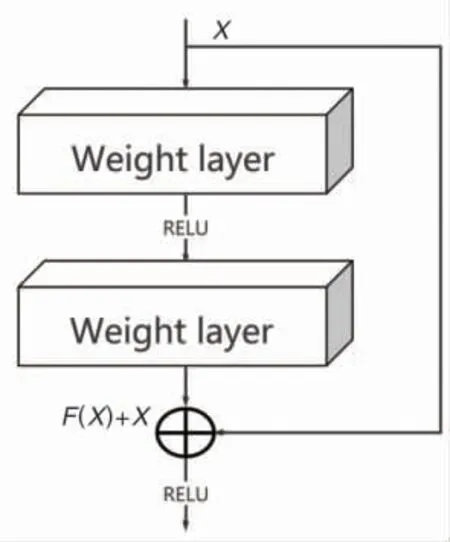
图2 残差网络基本结构
本文提出的CNN-A-BiLSTM 模型中,残差卷积神经网络由卷积层、池化层组成,并融合残差块。残差卷积神经网络结构见图3。
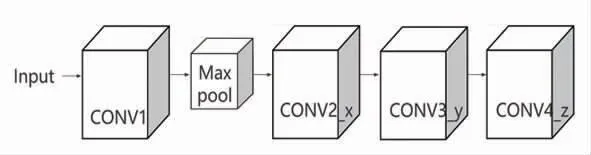
图3 残差卷积神经网络结构
图3 中,输入数据Input 为10×7 的时序数据,卷积层CONV1 是独立卷积层,采用32 个大小为7×7,步长为2 的卷积核;Maxpool 为最大池化层,池化窗口大小为3×3,步长为2;CONV2_x、CONV3_y、CONV4_z 为3 个不同的卷积残差块,每个卷积残差块由3 个卷积层和跳跃连接组成,输出大小分别为10×32,10×64,10×128;经由残差卷积网络处理后的数据将作为后接BiLSTM 模型的输入。
残差卷积网络的激活函数采用自门控激活函数Swish。该激活函数在深层模型上的效果优于RELU。Swish 激活函数为

式中:x 为神经网络每一层的输出;Sigmoid 为常用激活函数;β 为可学习参数。当β=0 时,Swish 激活函数为线性函数;当β→∞时,Swish 激活函数变为0或x。
1.2 基于时间步注意力机制的BiLSTM 模型
长短期记忆网络(Long Short-Term Memory,LSTM)是循环神经网络(Recurrent Neural Networks,RNN)的一种。与RNN 相比,LSTM 在具有记忆模块的同时,能够克服梯度消失或梯度爆炸等问题,因此其在时间序列建模预测问题中相比于传统神经网络拥有更强的优越性[8-9]。LSTM 网络结构包含1 个输入层、1 个输出层以及若干个隐藏层。隐藏层由内部记忆单元构成,见图4。每个单元由遗忘门、输入门、输出门3 种门结构组成。
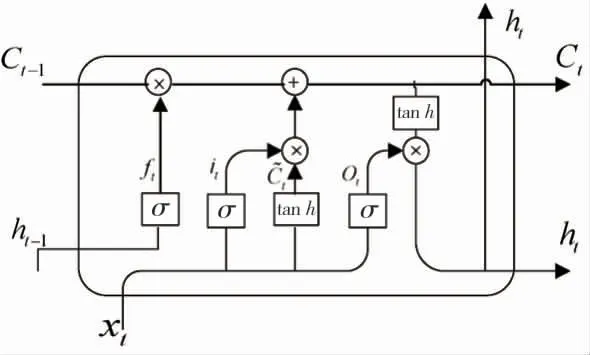
图4 LSTM 单元结构
为更好地挖掘辐照度序列的时序关系,采用基于时间步注意力机制的LSTM 模型计算每个时间步与前10 个时间步的关系,即时间步T 隐层值ht与时间步T-1,T-2,…,T-10 隐层值ht-1,ht-2,…,ht-10 的联系,联系越强表示所占权重越大。
时间步注意力机制见图5。每个时间步所占的权重不同,可表示为
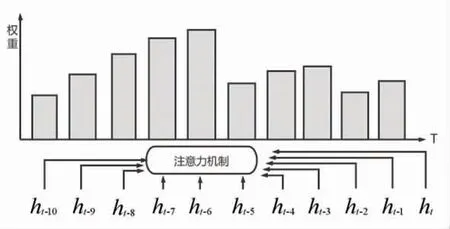
图5 时间步注意力机制
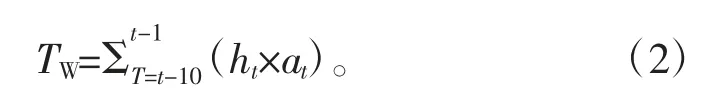
式中:TW表示时间步T 之前10 个时间步的注意力权重总和;ht表示时间步T 的隐层值;at表示时间步T 的权重。
为了使模型能够更好地学习序列数据中每个属性点与前后属性的关系,采用BiLSTM。每一层双向长短期记忆网络(BiLSTM)由前向LSTM 和后向LSTM 组成。前向LSTM 和后向LSTM 分别负责正向特征提取和反向特征提取。
基于时间步注意力机制的BiLSTM 模型(ABiLSTM)见图6。由图6 可知,A-BiLSTM 第1 层为单向LSTM,神经元个数为64;第2 层为注意力机制层,通过自定义层实现,其内部结构将第1 层LSTM的输出置换维度,通过全连接层训练权重,然后将维度复原,最后将训练后的权重与第1 层LSTM 的输出相乘,作为下一层的输入;接着为3 层双向LSTM层,神经元个数分别为64,128,256,并加入dropout层,随机停用模型20%的神经元。同残差卷积一样,A-BiLSTM 采用自门控激活函数Swish。
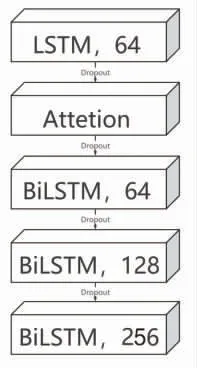
图6 A-BiLSTM 模型
2 数据处理
2.1 数据描述
辐照度数据采用宁夏回族自治区14 个地区近10 年的日辐照度数据。采用多地区数据,可以使模型学习不同地区在不同情况下的数据,并将已经训练好的模型用于其他地区进行验证。可以证明,融合多地区数据的模型具有较强的泛化能力。
将日期正余弦数值化并转换后作为特征输入模型训练,可以更好地挖掘辐照度的周期性。公式为
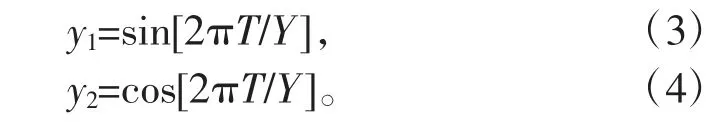
式中:Y 为365.2425,d;T 为日期,d;y1为日期正弦;y2为日期余弦。
2.2 相关性分析
为了提高辐照度预测的准确性,需要考虑各种特征对辐照度的影响,因此使用Pearson 相关性分析法对特征做相关性分析,见式(5)。相关系数取绝对值,其值见表1。选取相关系数大于0.1 的影响因素。
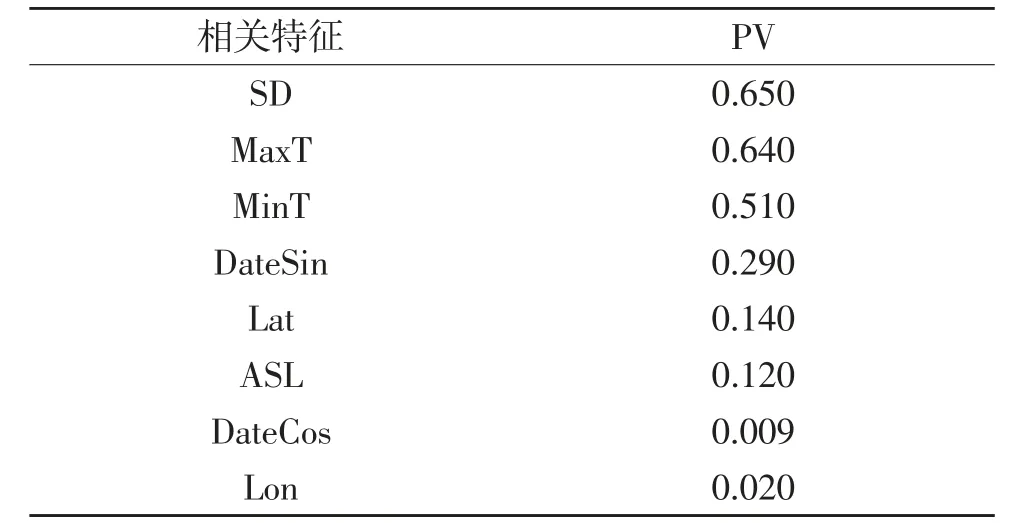
表1 相关系数值
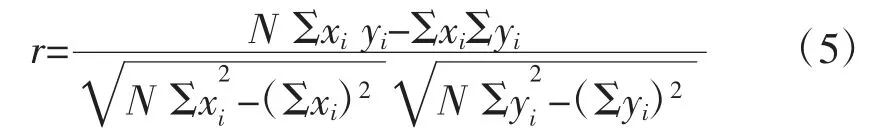
式中:N 为变量个数;x 和y 是计算相关性的2 个变量。
2.3 数据预处理
由于多地区时序数据存在缺失值,采用时序插值算法Hermite 进行缺失值填充。Hermite 多项式见式(6)~式(8)。同时,为避免龙格现象(Rungephenomenon),采用分段3次Hermite 插值多项式(PCHIP)。
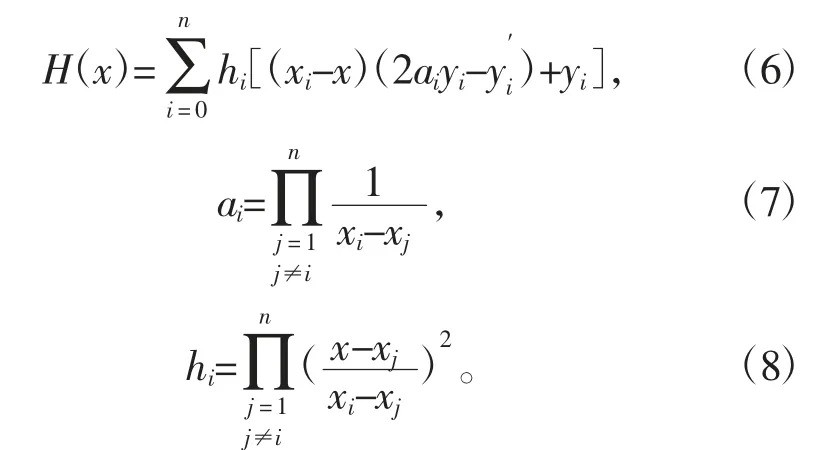
式中:x 为某特征量;y 为辐照度。
将天气情况[10]数值化,结果见表2。
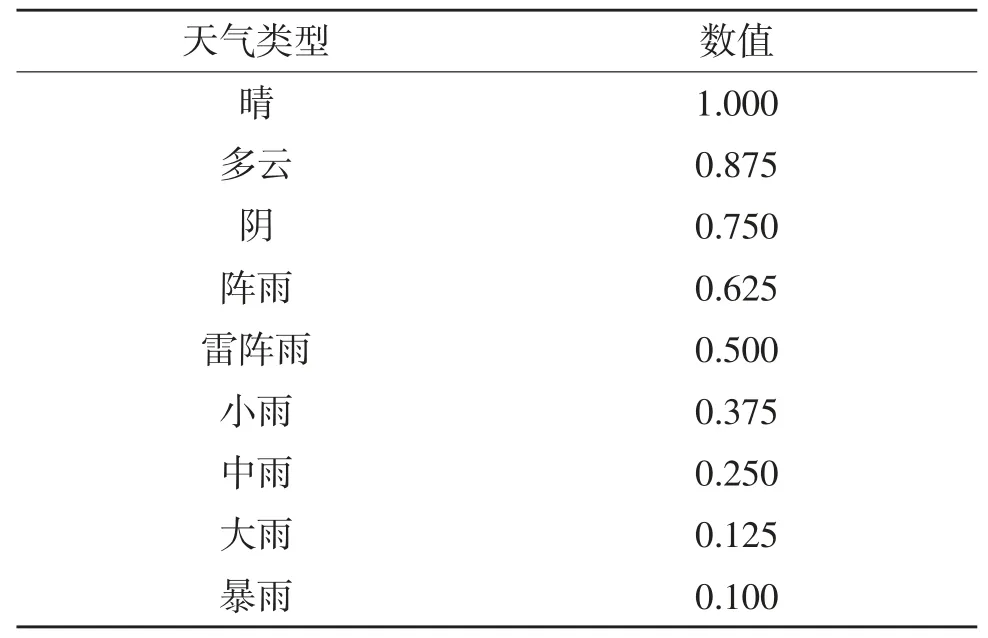
表2 天气数值化表
将数据归一化,公式为

式中:x 为初始值;xmin为最小值;xmax为最大值;为归一化后的值。
3 实验结果
3.1 实验数据
实验数据采用宁夏回族自治区14 个地区近10 年的日辐照度和天气数据,共43 836 条数据,其中12 个地区的数据用作训练集,2 个地区的数据用作验证集。数据包括9 个影响属性,根据相关性分析,选取相关性大于0.1 的6 个影响属性和辐照度。根据前文所提数据处理方式,本文对时序数据进行缺失值填充,并进行数值化和归一化。自相关系数公式如下,将时间步长设置为10。
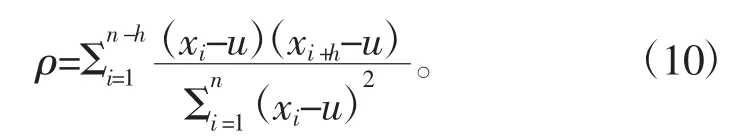
式中:h 为时间步长;u 为序列的平均值;xi和xi+h分别为对应于2 个时间点的值。
3.2 模型训练
实验采用Python 3.7 及TensorFlow 2.2 实现,在Anaconda 环境下的Jupyter Notebook 中搭建和训练模型。损失函数采用MSE(Mean Squared Error),公式为

式中:n 为样本个数;ε 为真实值与预测值的差值。
采用常用优化器Adam(Adaptive Moment Estimation)进行优化。学习率初始化为0.001,最大迭代次数为2 000。为防止模型学习后期学习率较大导致跳过全局最优点,采用迭代次数衰减与指标衰减(Reducel Ron Plateau)双策略结合的方法,每100 个epoch 或损失值累计5 次未发生改变时,学习率减小为之前的0.1倍。同时为防止过拟合,采用L2 正则化算法,迭代次数达到最大值时停止训练。
3.3 模型性能评估及误差分析
使用平均绝对误差(MAE)、平均绝对百分误差(MAPE)、均方根误差(RMSE)验证模型的鲁棒性,公式为
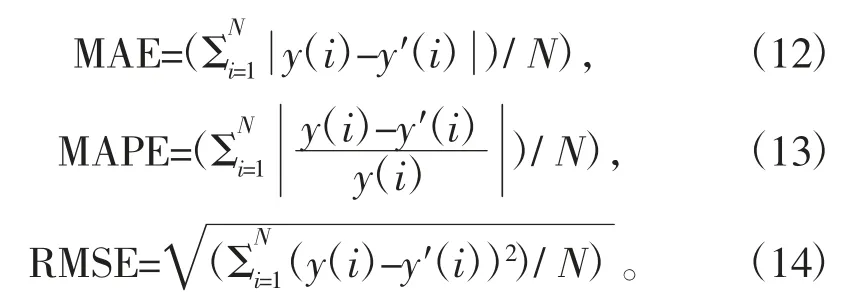
式中:y(i),y′(i)分别为i 时刻的测试值和预测值;N 为测试样本数。
(1)实验1。为验证模型在辐照度中长期预测中的有效性,采用滑动窗口的方法,对未来1,7,15 d的辐照度进行预测;使用CNN-A-BiLSTM、LSTM[3]、CNN-LSTM[5]、GRU[6]模型分别对所选取的数据进行预测。表3 列出了4 种模型对于不同预测天数的实验结果。
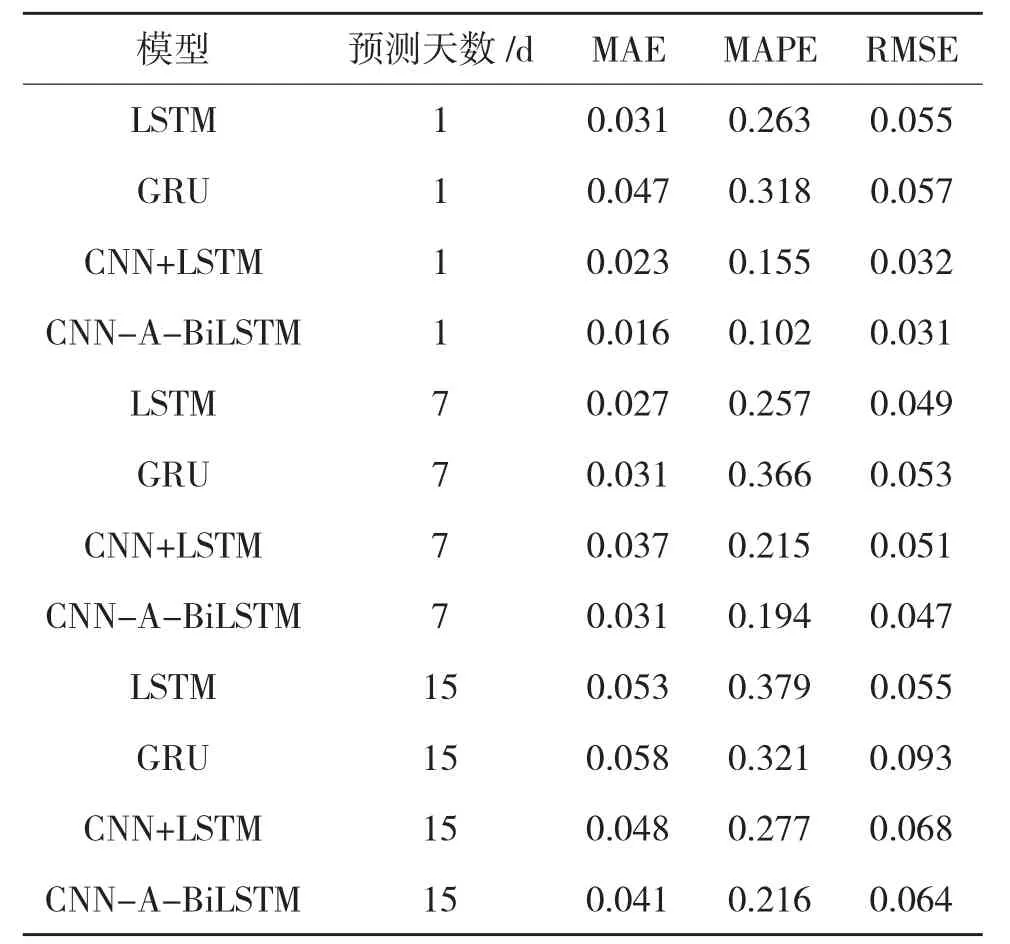
表3 模型性能评估
在数据集相同的情况下,根据MAE、MAPE、RMSE 性能评估方法,本文提出的CNN-A-BiLSTM 相较于深度学习网络误差更低。日预测中,与效果次佳的CNN+LSTM 相比,MAE 降低误差30.4%。未来7 d 预测中,CNN-A-BiLSTM 的MAE 为0.031,MAPE 为0.194,RMSE 为0.047,较混合模型CNN+LSTM,误差分别降低19.3%,9.7%,7.8%。未来15 d 预测中,CNN-A-BiLSTM 与CNN+LSTM 相比,MAE、MAPE、RMSE 分别降低14.6%,22.1%,5.9%
综合未来1,7,15 d 的辐照度预测情况,本文提出的CNN-A-BiLSTM 模型在辐照度中长期预测中,误差较LSTM、GRU、CNN+LSTM 更低,预测精度更高。
(2)实验2。为测试基于时间步的注意力机制对模型预测误差的影响,将CNN-BiLSTM 模型与CNN-A-BiLSTM 进行对比。同时,为测试不同训练集对模型预测误差的影响,对2 种模型在不同训练集比例下的预测误差进行对比,训练集划分比例为9∶1,8∶2,7∶3。2 种模型在不同训练集比例下,预测未来1,7,15 d 的对比结果见表4。
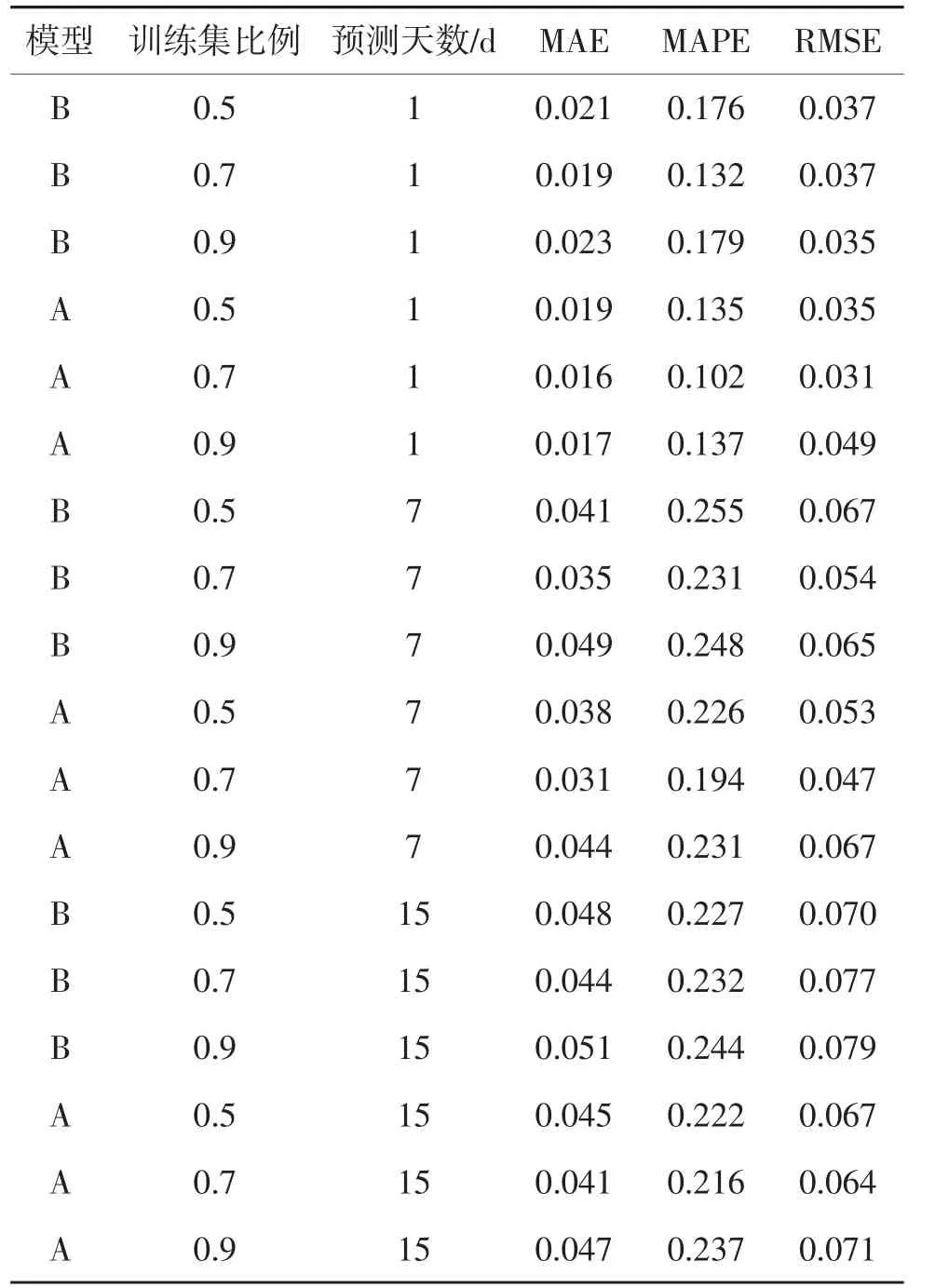
表4 不同训练集比例对比
训练集比例分别为0.5,0.7,0.9 时,根据MAE、MAPE、RMSE 性能评估方法,训练集比例为0.7 的模型预测效果最佳。以CNN-A-BiLSTM 为例,在未来1 d 预测中,较训练集比例为0.5 时,MAE、MAPE和RMSE 分别降低15.7%,24.9%,11.4%;较训练集比例为0.9 时,MAE、MAPE 和RMSE 分别降低6%,25.5%,36.7%。同时,在未来7,10 d 预测中,训练集比例为0.7 时,MAE、MAPE 和RMSE 较其他训练集比例都有不同程度的降低。
在训练集比例相同的情况下,融合注意力机制模型预测误差较CNN-BiLSTM 更低,以训练集比例0.7 为例,在未来1,7,15 d 的预测中,CNN-A-BiLSTM 较CNN-BiLSTM 的MAE 分别降低15.7%,11.4%,6.8%。
4 结论
基于CNN-A-BiLSTM 的太阳辐照度中长期预测模型通过深度残差卷积网络提取数据特征,并结合基于注意力机制的双向长短期记忆网络完成中长期太阳辐照度预测。通过宁夏回族自治区14 个地区近10 年的辐照度以及天气数据完成模型训练与评估。经验证,基于CNN-A-BiLSTM 的太阳辐照度中长期预测模型在未来1,7,15 d 的预测中,与传统单模型、传统混合模型相比,具有更低的误差和更强的泛化能力。
猜你喜欢
成都信息工程大学学报(2022年2期)2022-06-14
网络安全与数据管理(2022年3期)2022-05-23
北京航空航天大学学报(2021年9期)2021-11-02
北京航空航天大学学报(2020年10期)2020-11-14
电子制作(2019年13期)2020-01-14
北京航空航天大学学报(2019年9期)2019-10-26
电子制作(2019年11期)2019-07-04
北京航空航天大学学报(2018年1期)2018-04-20
山东工业技术(2017年17期)2017-09-13
中国建筑科学(2017年6期)2017-07-20
