
一种特征转移和域自适应的异质缺陷预测方法
2022-01-21 02:55虞慧群杨星光
小型微型计算机系统 2022年1期
黄 燕,徐 贤,虞慧群,杨星光
(华东理工大学 信息科学与工程系,上海 200237)
1 引 言
随着软件规模和软件复杂性的增加,发布高质量的软件系统是一个巨大的挑战.软件质量保证活动(例如软件测试,代码审查)是提高软件质量的有效方法.然而,在测试资源和软件发布时间的限制下,对所有程序模块进行质量保证活动通常是不现实的[1].
为此,研究人员提出了软件缺陷预测方法[2,3].软件缺陷预测通过挖掘软件的历史仓库,设计出与缺陷相关的内在度量元,然后借助机器学习等方法提前发现并锁定缺陷模块,从而能够合理地分配有限的资源[2].传统的软件缺陷预测是在项目内执行的,称为同项目缺陷预测(Within-Project Defect Prediction,WPDP)[2].然而,目标项目可能是新启动的软件系统,因此缺少足够训练数据.跨项目缺陷预测(Cross-Project Defect Project,CPDP)方法[4]是解决该问题的有效方法.它采用其他项目(源项目)的缺陷数据集来构建预测模型,并对目标项目进行缺陷预测.在CPDP中,需要源项目与目标项目有相同的特征集.然而,在实际情况中,由于不同项目使用的编程语言、适用的领域、开发人员的经验等差异[5],源项目和目标项目之间的度量元可能存在较大差异,此时若直接使用传统的CPDP方法,不能取得较好的预测性能.为此,研究者们提出了异质缺陷预测(Heterogeneous Defect Prediction,HDP)[6,7]方法.
当前,为了提高HDP性能,研究人员提出了多种方法,如HDP[6,8]、FMT[9]等.这些方法都是从特征匹配的角度出发解决异质问题,然而并没有考虑数据本身存在的分布差异对于模型性能的影响.为此,本文提出了一种基于特征转移和域自适应(Feature Transfer and Domain Adaptation,FTDA)的方法.该方法在进行特征迁移的同时,使用域自适应方法解决项目间数据分布的差异性问题,并采用综合采样方式处理不平衡数据.FTDA结构的详细信息将在第3部分中进行描述.
本文的主要贡献可归纳如下:
1)本文为解决异质缺陷预测提出了一个新的FTDA方法.与以前的工作相比,本文设计了一个新的特征匹配算法,用于将不同项目间的异质特征匹配起来,并为每个目标项目挑选最合适的源项目.除此之外,本文还应用了域自适应算法和类不平衡算法分别解决数据分布不同和数据类别失衡的问题.
2)本文在来自AEEEM、PROMISE、NASA和Relink的24个数据集上进行实证研究,并使用AUC作为指标来评估方法的性能.本文将FTDA方法与FMT和WPDP进行了比较,实验结果表明,FTDA比以前的工作更有效,且能有效解决异质缺陷预测问题.
2 相关工作
2.1 跨项目缺陷预测(CPDP)
跨项目缺陷预测旨在将其他成熟项目的标记数据用作训练集,以建立缺陷预测模型,并用该模型来预测新建立的项目的缺陷倾向性.Hosseini[4]、陈翔[5]、Zhou[10]等对于近年来的跨项目缺陷预测进行一定的归纳总结.
近年来,研究人员提出了许多跨项目缺陷预测方法.Tsang等[11]提出了一种迁移成分分析(Transfer Component Analysis,TCA)方法,这是一种基于特征迁移的学习方法.具体来说,源项目和目标项目被映射到一个潜在的公共空间,使得两者的数据分布趋于一致.然后使用传统的机器学习方法进行分类.经过进一步的实验研究,Nam等发现数据归一化对实验结果的影响很大,因此他们进一步提出了TCA+[12].Ryu等[13]提出了一种基于实例迁移和代价敏感的方法TCSBoost(Transfer Cost-Sensitive Boosting),它通过调整正确和错误分类的实例的权重来不断修改模型.
与上述尝试通过设计有效的机器学习算法来构建预测模型的方法不同,有些CPDP方法专注于为目标数据找到合适的训练数据.Hosseini等[14]提出了遗传实例选择GIS(Genetic Instance Select)方法,这是一种旨在优化F-Measure和GMean的组合度量的训练数据选择方法.Liu等[15]提出了CPDP的两阶段迁移模型:在第1阶段,为目标项目选择两个相似度最高的源项目;在第2阶段,使用TCA +用于为两个选定的源项目分别构建两个预测模型.
除此之外,还有一些CPDP方法专注于不同的应用场景,例如跨项目缺陷预测中的隐私保护问题[16,17],基于不同粒度的缺陷预测[18-21]等.
2.2 异质缺陷预测(HDP)
为了解决项目之间度量元不同的问题,研究人员提出了异构缺陷预测[6],他们提出了许多从不同角度解决HDP的解决方案.陈翔、Chen等人[22,23]系统地概述了HDP的最新工作,并进行了一些比较.
Jing等[7]提出了一种基于统一度量表示UMR(Unified Metric Representation)和典型相关分析CCA(Canonical Correlation Analysis)的HDP迁移学习方法.首先,该方法分别为源数据和目标数据构造UMR,然后使用CCA使源项目和目标项目的数据分布相似.Cheng等[24]提出了CCT-SVM,这是CCA和支持向量机SVM(Support Vector Machine)的结合,他们使用CCA构造出了异构数据的联合特征空间,SVM则被用作分类器.同时,他们采取了不同的错误分类成本来减轻数据不平衡所带来的影响.
Yu等[9]提出了一种基于特征匹配与特征迁移的方法FMT(Feature Matching and Transfer).该方法首先使用基于相关性的特征选择方法CFS(Correlation-based Feature Selection)进行特征筛选,然后通过计算特征值分布曲线的距离,将源项目与目标项目的特征进行匹配,从而将异质特征转化为匹配特征.Nam等[8]设计了一种HDP(Heterogeneous Defect Prediction)方法,他们尝试了增益比等4种方法进行特征选择,百分位数、KS检验等3种方式评估特征对之间的相似度,最后使用最大加权二分匹配进行源项目和目标项目之间的特征匹配.
Li等[25]在解决HDP时考虑了多源和隐私保护问题,他们为了有效地利用多源数据,提出了一种基于多源选择的流形判别比对MSDA方法.同时为了在数据共享过程的隐私保护,他们设计了一种基于稀疏表示的双重模糊算法.
当前,大多数用于异构缺陷预测的工作旨在解决度量标准集的不一致问题.他们尝试了特征表示[7],特征选择和匹配[6,8,9],以使源和目标的度量标准集融合.但是他们没有考虑项目之间数据分布的区别.此外,在大多数工作中,过采样方法用于类不平衡.本文也是主要从解决异构特征出发,较之以前的工作,本文提出的方法设计了新的特征匹配方法,不仅将异构特征匹配起来,同时进行了源项目的选择;除此之外,还考虑了数据分布与类不平衡问题.本文将在第3节中详细介绍FTDA的框架结构和实验步骤.
3 基于特征迁移和域自适应的异质缺陷模型
本文为解决异质缺陷预测问题,提出了一种基于特征迁移和域自适应的方法FTDA.本文为特征匹配和项目选择设计了一个新的算法,此外,本文还将域自适应算法TCA应用于HDP中;在解决类不平衡问题时,本文采用了SMOTETomek,即将Tomeklinks加入SMOTE中,用于在生成少数类样本的同时,减少边缘样本对于分类的影响.本文将在这一部分详细介绍FTDA,FTDA的整体框架如图1所示.
首先,对每个项目(即Project1,Project2,…,ProjectN)进行特征筛选,便可以得到拥有最优子集的新项目Projcet1*,Project2*,…,ProjectN*.根据欧氏距离,将Target中的 特征与每个Project*中的特征进行匹配,并根据项目间的距离为Target*挑选一个最合适的项目作为Source.接着,应用域自适应算法,此时Source和Target*不仅拥有匹配的特征集,并且他们的数据分布是一致的.然后,将目标数据中的有标签数据作为训练集加入到源数据中,并应用SMOTETomek解决类不平衡问题.最终将平衡的数据进行模型训练,用于判断目标数据中未标注模块的缺陷性.

图1 FTDA整体框架Fig.1 Overall framework of FTDA
3.1 特征筛选
软件缺陷数据是由专家和学者从软件仓库中收集而来的.例如,AEEEM存储库由D′Ambros等收集[26,27],AEEEM有61个指标,包含源代码指标、之前预测的指标、变更熵指标、源代码熵指标和源代码流失指标5类.这些度量指标可以在一定程度上反映软件模块的特征,但是它们不一定与类别具有很强的相关性.因此,为了更好地构造模型,特征选择是必不可少的一步.特征筛选有很多方法[28-30],而本文中选择的是基于相关性的特征选择算法CFS[31].该算法的核心是以启发式的方式评估特征子集的值,也就是说,好的特征子集应包含与类高度相关但特征之间彼此不相关的特征.在先前的工作中,CFS被证明对CPDP有效[32].
3.2 特征匹配
在HDP中,源项目和目标项目中的特征集并不完全相同,不同之处在于特征的含义以及特征的数量.在本小节中,特征匹配的目标有两点:1)是过滤目标项目的特征,使之与源项目中的特征一一匹配;2)是为每个目标项目挑选最合适的一个源项目.本文采用欧氏距离来表达特征之间的相似性,计算公式如下:
(1)
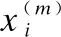
FTDA的特征匹配算法有如下的步骤,算法的细节描述如算法1所示.
算法1.特征匹配
输入:SS*=S1,S2,…,SN:特征筛选后的源项目集
T:目标项目
输出:S:被挑选的且拥有匹配的特征的源项目
T*:拥有匹配的特征的目标项目
1.N:源项目集中的项目数量;
2.F:目标项目T的特征数量;
3.获取T中的所有特征,记做FTi={FT1,FT2,…,FTF},1≤i≤F;
4.foreachSiinSS*(1≤i≤N):
5.fk:Si的特征数量;
6. 获取Si中的所有特征,记做FSj={FS1,FT2,…,FTfk},1≤j≤fk;
7.foreachFTiandFSj:
8. 从FTi和FSj中随机选取g个实例,将它们分别按照值的大小升序排列,并进行标准化;
9. 基于公式(1)计算特征对之间的距离,记做dij;
10.endfor
11. 每次从距离矩阵中取最小的值,直至目标项目中的每个特征都被匹配,此时获得新的目标项目Ti*;
12. 计算Si与Ti*配对的特征之间的距离和,记做DSi;
13.endfor
14.选择距离和最小的项目S作为目标项目T*的源项目;
15.returnS,T*;
1)对于每一个目标项目,与该项目不属于同一组的其他项目都是源项目的备选项目(line 1和line 2),并获取目标项目的特征(line 3);
2)每次从备选项目中选择一个项目,获取它的特征集(line 5和line 6).通过计算特征之间的欧几里得距离,可以得到一个距离矩阵(line 8和line 9),每次从该矩阵中获取最小值,该最小值对应的行和列分别为备选项目的特征和目标项目的特征,记录下该值以及对应的特征,并将它从矩阵中删除,重复上述步骤,直至将目标项目的特征与该项目的特征进行一一匹配(line 11).
3)记录每对项目匹配的特征的距离和,其中距离和最小的项目被挑选作为目标项目的源项目(line 12和line 14).
3.3 域自适应
域自适应(Domain Adaptation,DA)是一种旨在于克服项目之间数据分布的差异性的迁移学习.迁移成分分析(Transfer Component Analysis,TCA)[33]是一种经典的边缘分布自适应算法,它的主要目的是找到一个潜在的特征空间,在这个空间中项目之间的数据分布差异很小,并且同时保留了其原始数据特征.经过调研,TCA在先前的工作中,主要用于跨项目缺陷预测中,并取得较好结果[12].本文认为,即使源项目和目标项目的特征匹配成功,它们之间仍然存在数据分布不同的问题,解决这个问题可以一定程度上提升HDP的性能.
接下来是对TCA基本思想的简单介绍.由于源域和目标域的边源分布不相同,即P(Xs)≠P(Xt),那么直接减小两者之间的距离是不可行的.TCA假定存在一个特征映射φ,使得经过映射之后的数据分布P(φ(Xs))≈P(φ(Xt)),所以主要目的是找到一个合适的φ.TCA采用最大均值差异MMD(Maximum Mean Discrepancy)来计算映射后的源域和目标域的平均值之差.假设已知φ,n1和n2分别表示源域和目标域中的样本数,然后计算MMD,如公式(2)所示.D(Xs,Xt)表示两个分布P(φ(Xs))和P(φ(Xt))之间的距离,可以由两个域Xs和Xt映射之后的均值之差计算得来.
(2)
3.4 类不平衡
类不平衡问题广泛存在于缺陷数据中,在缺陷数据中,无缺陷的模块占据大多数.而在学习过程中,分类器将趋向于无缺陷实例,从而导致有缺陷实例的分类不佳[34].类不平衡的调整方法大体可以分为数据层面和算法层面两类[2].数据层面主要从数据出发,对不平衡的数据进行调整以达到平衡.算法层面是指设计出适用于类不平衡问题的缺陷预测分类算法,如代价敏感学习方法[13]、集成学习方法[35]等.本文采用的是数据调整方法中的采样方法,大多数情况下,样本量越大,预测的性能越好,因此目前大多数工作都采用的是过采样技术.然而过采样也可能带来一些问题,因此,本文尝试采用过采样方法和欠采样方法的组合来解决类不平衡问题.
人工少数类过采样法SMOTE(Synthetic Minority Oversampling Technique)[36]是一种广泛使用的过采样方法.它的基本思想是分析少数样本并基于它们人工合成新的少数类样本,以期达到类平衡的效果.由于少数样本的分布决定了其可选邻居,因此,如果少数类样本位于少数样本集的分布边缘,那么由这些样本生成的“人工”样本也将位于该边缘.这就会导致少数类样本和多数类样本之间原本模糊的边缘变得更加模糊,这将很不利于分类.本文考虑将Tomeklinks添加到SMOTE中,以解决边界模糊的问题.假设样本x和样本y属于不同类别,d(x,y)表示x与y之间的距离,并且如果没有其他样本z,使得d(x,z) 为了研究FTDA的有效性,本文对AEEEM[27],PROMISE[37],NASA[38,39],Relink[40]的24个数据集进行了实证研究.本文使用的是Weka 3.8[41]和python 3.7,所有的实验都在处理器Intel(R) Core(TM) i5-7200U CPU 2.50GHz、内存12GB的PC机上完成. 如表1所示,本文分别从AEEEM中选择5个项目,从PROMISE中选择8个项目,从NASA中选择8个项目,从Relink中选择3个项目. 表1涵盖了每个数据集的基本信息,包括度量集数量、模块总数、有缺陷的模块数量、缺陷比率、预测粒度等.值得注意的是,NASA数据集中的特征并不完全相同.CM1、MW1、PC1、PC3和PC4数据集中有37个特征,PC2数据集中有36个特征,MC1和PC5数据集中有38个特征. 为了全面展示FTDA的有效性,本文设计了以下3个研究问题(Research Questions,RQ). 表1 缺陷数据集基本信息Table 1 Basic information of defect datasets ·RQ1:本文提出的的FTDA方法是否比FMT更好? FMT(Feature Matching and Transfer)[9]也是HDP的一种解决方案,该方法的主要思想是将目标项目的特征与源项目特征根据一定的算法进行匹配.结果表明,它在PROMISE上是有效的,并且其性能优于HDP[6].本文提出的方法FTDA同样尝试使用特征匹配来解决数据异构的问题.但是除此之外,为了获得更好的性能,本文还为每个目标项目增加了源项目选择步骤;为解决数据分布不同问题应用了域自适应算法,并从采样角度对不平衡的数据进行了处理.这些部分是FTDA与FTM的不同之处,与FTM进行比较可以直观地表明,本文提出的方法较之以前的工作的先进性,这就是本文选择FMT作为基准的原因.为了验证有效性,本文在4个组上进行了实证研究,具体的实验结果在5.1节中. ·RQ2:FTDA的性能是否比WPDP好? 在WPDP实验中,对24个数据集分别进行预测.选取数据集的10%作为模型训练集,使用Logistic Regression作为分类器,采用10倍交叉验证,重复实验50次.FTDA与WPDP之间的实验比较将在5.1节中详细介绍. ·RQ3:FTDA采用的综合采样方法是否比单独使用过采样或欠采样技术性能更好? 本文使用SMOTETomek作为采样技术,这是过采样与欠采样的综合采样方法,为了验证该采样方法在模型中的有效性,本文还分别单独使用SMOTE和Tomeklinks作为采样方法进行实证研究,比较结果如5.1节所示. 本文使用Logistic Regression(LR)[42]作为预测模型,该模型是在Weka中实现的,并使用Weka中对LR模型设定的默认参数. 在软件缺陷预测的实证研究中经常使用的评估指标有精确率、召回率、F值等,这些指标是根据分类后的混淆矩阵计算得出的.机器学习中的许多算法首先是基于所有特征计算出一个“评分”,然后根据这个“评分”,依靠一定的阈值进行分类.因此,这些指标与阈值的设置有关,而阈值的设定都是人为的.然而,ROC本质上是在不同阈值下的硬分类(即,直接给出分类结果的分类器)的集合.此外,Jiang等人[43]通过实证分析发现,在这些指标中,AUC的方差最低.因此本文选择AUC[44]作为性能指标,它表示接收器工作特性曲线(Receiver Operating Characteristic,ROC)下的面积.AUC的值介于0和1之间,AUC的值越大,模型的性能越高,AUC被广泛用于软件缺陷预测中. 当前的研究[45,46]表明,使用目标项目中的少量标记数据可以提高跨项目缺陷预测模型的性能.因此,本文将目标项目中前10%的数据作为已标记数据,并将其添加到训练集中,用于模型的训练. 在本节中,本文将从上述3个RQ的角度详细显示实验结果.此外,本文还将讨论所提出方法面临的有效性威胁. 5.1.1 FTDA和FMT的比较 根据FTDA的整体框架和第3节中的描述,首先,对表1中的每个数据集进行特征选择.基于选定的特征,再进行特征匹配.从而可以为每个目标项目筛选得到最合适的源项目,并且配对的项目间的特征也是一一匹配的.接着,使用TCA算法将源项目和目标项目映射到潜在的公共空间,以解决数据分布上的差异.最后使用SMOTETomek进行采样后,用Logistic Regression进行分类预测. 表2 FTDA VS.FMT实验结果Table 2 FTDA VS.FMT experimental results 在FMT[9]中,PROMISE中的数据集被视为目标项目,而NASA中的数据集被视为源项目.为了显示FTDA的有效性,本文也将PROMISE中的每个数据集都看做目标项目,但是源项目是其他组(即AEEEM,NASA,Relink)中的一个.实验结果如表2所示.第1列是目标项目,第2列列出了根据FTDA方法从候选数据集中选择出的最合适的源项目,第3列显示了FTDA的AUC值,第4列是FMT中AUC的最大值,而第5列展示了FMT中AUC的最小值. 从表2中,本文可以得出这两个结论:1)除camel-1-6外,FTDA算法选择的最合适的源项目并非来自NASA,在这8组实验中,FTDA在6个数据集上表现出更好的性能.这意味着从更大的范围为每个目标项目选择合适的源项目的有效性;2)在FMT中,当源项目为camel-1-6且目标项目为CM1时,AUC值为0.636,并且是使用NASA数据集对其进行预测的最优结果.而当使用本文提出的FTDA进行预测时,同样选取的是“CM1→camel-1-6”,此时AUC值为0.721,这表明FTDA使用的域自适应和类不平衡算法有效地提高了性能. 5.1.2 FTDA和WPDP的比较 本文还将FTDA与WPDP进行了比较,以验证FTDA是否比直接使用同一项目中的数据进行预测性能更好.在WPDP中,本文将10%的数据设置为训练集,其余部分作为测试集,选用的分类器是逻辑回归.本文在24个数据集中进行了实验,结果显示如表3所示.FTDA和WPDP的AUC分别列于第2列和第3列.通过表3,可以很直观地发现,在24组实验中,FTDA可以在22个数据集中获得更高的AUC值,且FTDA的AUC平均值为0.718,WPDP的AUC平均值为0.605.由此可以得出结论,在大多数数据集中,本文提出的FTDA方法确实具有更好的性能. 5.1.3 采样方法的比较 上述两组实验分别比较了FTDA与FMT和WPDP,以证明FTDA结构的有效性.而本RQ旨在探讨不同的采样方法是否会影响FTDA的性能.本文分别使用SMOTE和Tomeklinks作为采样方法,对相同的数据集进行实验.实验结果展示于表3的第4列和第5列,实验结果中的较大值以粗体表示.由表3可以发现,FTDA在11个数据集上的表现要优于其他两种采样方式.单独使用SMOTE作为采样方式和FTDA使用的综合采样方式在EQ、ivy-2.0、tomcat、xalan-2-4、PC1、PC2和safe的7个数据集上均获得了一致的AUC值,仅将Tomeklinks用作采样方法的性能较差. 本文提出的方法FTDA包括了4个阶段,分别是特征选择、特征匹配与源项目选择、域自适应和类不平衡的处理,时间开销较大的是特征匹配与源项目选择阶段,且时间开销与项目集中包含的项目的数量、项目包含的特征数有关.例如,本文在预测ant-1-7项目的缺陷倾向性时,项目集是由AEEEM中的8个项目、NASA中的8个项目和Relink中的3个项目组成的.因此,当备选的项目集的范围更大时,会导致更大的时间开销. 5.2.1 结构有效性的分析 影响本文提出的方法的有效性的第一个威胁是目标项目数据添加到训练数据集中的百分比.根据参考,本文从目标项目中随机选择了10%的数据.为了减轻随机性,本文重复了50次实验.但是,选择不同比例的目标数据可能会导致不同的性能.这不是本文的重点,而是未来工作的一个研究方向.此外,在本次实验中,本文对源项目和目标项目中包含的所有指标都进行了实证研究,对于HDP中不同类型指标的会产生的影响也是未来的一个研究方向. 表3 实验结果Table 3 Experimental results 5.2.2 内部有效性的分析 数据不平衡的解决方案可能是对内部有效性的威胁.SMOTETomek用于人工生成少数样本并删除边界样本,以达到数据平衡且易于分类的效果.实验结果表明,通过使用SMOTETomek,FTDA是有效的.为了更好地进行比较,本文还在SMOTE和TomekLinks上进行了实验.在未来的工作中,作者将探索不同方法对数据集的不平衡数据的更有效解决方案. 5.2.3 外部有效性的分析 选择更广泛的数据集可能会更好地得出一个一般性结论.在本文的研究中,作者从4个组中选择了24个数据集,并且源项目的选择也在此范围内,这意味着本文的实验结果可能不会推广到其他数据环境.但是,这些数据集已广泛用于软件缺陷预测的先前工作中.为了在一定程度上减轻这种可能的威胁,在将来的工作中,作者将对更多开源或来自商业软件项目的缺陷数据集进行更多的实验. 近年来,异质缺陷预测得到了广泛的研究与关注,为软件缺陷预测提供了新角度和新思路.它解决了目标项目训练数据稀疏的问题,同时突破了源和目标的特征需要保持一致的局限.本文提出了一种基于特征匹配和域自适应的方法,该方法利用欧式距离进行特征匹配与项目筛选,采用TCA算法解决不同的数据分布问题,最后使用SMOTETomek进行数据采样.本文对来自4个小组(AEEEM,NASA,PROMISE,Relink)的24个公共项目进行了实验,实验结果表明,FTDA的性能优于以前的工作. 在未来,作者将尝试一些新的特征匹配方法和领域适应方法.此外,还将尝试其他一些方法来解决HDP问题,例如深度学习.4 实验与分析
4.1 实验环境
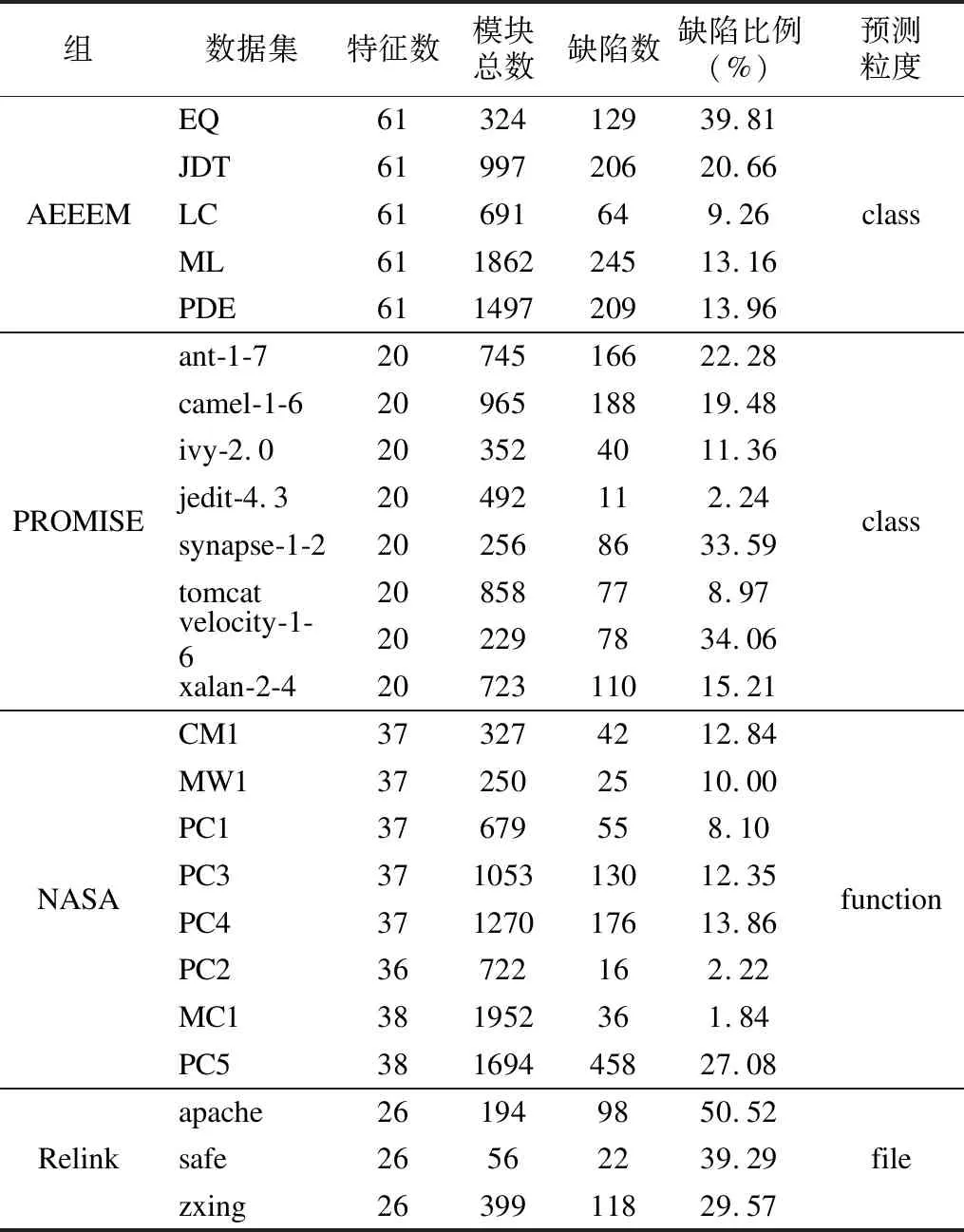
4.2 实验数据
4.3 实验设计
5 实验结果分析与讨论
5.1 实验结果

5.2 对有效性的分析

6 结 论
猜你喜欢
中学生数理化·高二版(2022年4期)2022-05-09
中学生数理化·高二版(2022年4期)2022-05-09
阅读与作文(英语初中版)(2019年8期)2019-08-27
中学生数理化·高一版(2017年1期)2017-04-25
中学生数理化·高一版(2017年1期)2017-04-25
中学生数理化·高一版(2017年1期)2017-04-25
数学学习与研究(2017年3期)2017-03-09
计算技术与自动化(2014年1期)2014-12-12
金点子生意(2014年4期)2014-04-10
中学生英语高效课堂探究(2008年9期)2008-11-17
