
基于Transformer框架的3D车道线检测算法
2022-01-21 10:29李胜严华
现代计算机 2021年33期
李胜,严华
(四川大学电子信息学院,成都 610065)
关键字:深度学习;计算机视觉;3D车道线检测;自动驾驶
0 引言
车道线是自动驾驶系统环境感知中的重要环节,最常见的车道线感知的解决方案是使用单目摄像机作为解决任务的主要传感器,然后使用目标检测的方法从采集到的图像检测出车道线的位置[1-4]。然而这些方法大都是假设路面是平整的,且只能提供二维车道线位置信息,当这个假设被违反时会导致系统车道线检测结果与真实路面存在严重偏差,造成自动驾驶系统安全性的潜在隐患。3D车道线检测可提供可驾驶车道相对于主车辆的3D位置的精确估计,增强了自动驾驶环境感知系统的可靠性和鲁棒性。R.Schmidt等[5]在未假设道路平坦或俯仰角恒定的基础上提出了一种基于立体视觉的3D车道检测方法。Lu Xiong等[6]提出了一种基于车道线信息的结构路面三维估计方法。Noa Garnett等[7]提出了一种基于卷积神经网络的端到端3D车道线检测算法,该算法使用两条路径处理来自车辆视图和俯视图的信息。车辆视图路径处理并保留来自图像的信息,而顶视图路径处理顶视图中的特征以输出3D车道估计。Guo等[8]在新的坐标框架中引入了一种新的几何引导车道锚定表示法,设计一种将图像分割子网和几何编码子网学习解耦的两阶段网络模型,并应用特定的几何变换从网络输出中直接计算真实的三维车道点。
然而,由于透视现象的存在,在车载摄像机采集到的图像中,近处道路在图像中占据较大的像素区域,而中远处道路的所占像素则随距离增大而越来越小,因此导致以往的车道线检测算法在道路中远处的车道线检测结果与真实值经常存在着较大的偏差。本文提出了一种基于Transformer框架与卷积神经网络相结合的3D车道线检测算法。首先利用卷积神经网络的卷积核旋转不变性来提取输入图像的局部语义信息特征图并生成初步的道路与车道线的二值语义分割图像;其次利用透视变换将车载前景图像转化为俯视图,且再次使用卷积神经网络提取俯视图的车道线高级语义特征信息;最后将不同的视角的特征图融合,利用两个不同大小的Transformer网络来分别处理不同尺度下的特征序列,分级逐步定位车道线的三维坐标信息。实验表明,该方法相比最新的3D车道线检测算法在道路远处的检测结果更加准确。
1 Transformer网络
Transformer是一种人工神经网络[9],最初用于自然语言处理任务。相比循环神经网络和卷积神经网络,Transformer网络能够建模输入序列元素长远距离之间的依赖关系,并通过支持输入序列的并行处理来加快网络的推理速度。因此被广泛应用于自然语言处理、时间序列预测、计算机视觉等领域。
1.1 Tr ansf or mer网络框架
Transformer框架由编码器和解码器两部分组成,如图1所示,其中编码器是由N个相同的编码器层叠加而成。每个编码器层包括多头注意力、求和和归一化、前馈神经网络等子模块。解码器同样是由N个相同的解码器层叠加而成,每个解码器除了包括与编码器相同的四个子模块外,还添加了由掩码多头注意力模块,用于在解码过程中抹去需要被预测的后续序列信息。

图1 Transformer模型展开
1.2 位置编码
因为Transformer网络相对于传统的循环神经网络在输入计算时没有输入先后顺序,而是采用并行化的思想来加快运算,这样模型在前一个序列结果还没有出来的时候便可以同时处理下一个序列,这会丧失了序列的顺序性。因此为了不损失顺序性,在将序列输入之前还需要结合位置编码(positional encoding)。
1.3 多头注意力机制(multi-head attention)
将掩码注意力模块的输出作为查询向量(Query),并编码器输出的已经编码好的特征向量作为查询关键字(key)和相关值(value)来计算注意力,从而得到当前需要翻译的内容和特征向量的对应关系,从而表示出当前时间步的状态。
2 车道线检测网络
2.1 车道线表示模型

图2 车道正视图和俯视图
针对道路的车道线有三种表示模型,相机捕获的正面视角车道原图像、经投影变换至俯视角度的俯视图像和车道线三维坐标表图。本文采用锚定纵坐标的方式,预先定义一组水平的坐标集合,一组垂直坐标集合,则第t条车道线可以表示为一组点的集合。其中xit表示车道线与预先定义的垂直坐标偏移量,zit表示车道线高度信息,vit表示当前集合是表示车道线还是道路中心线,pit表示当前坐标点存在车道线的概率值。
本文提出算法的输入为车载前景摄像头的实时图像数据,假定图像为IO,其大小为(H,W,3)。则输出为当前车辆所在行驶道路的三维车道线位置信息。如图3所示,经两个CNN特征提取子网络,再经过两个Transformer网络,最后输出车道线的三维坐标信息。
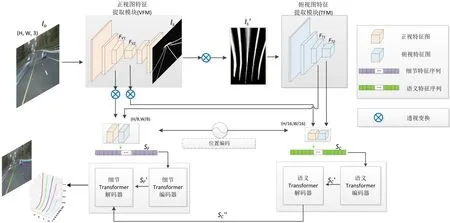
图3 3D车道线检测网络
2.2 CNN特征提取子网络
特征提取子网络包含正视图特征提取模块(VFM)和俯视图特征提取模块(TFM)。VFM模块是由轻量级语义分割网络erfnet[10]组成,TFM模块是由resnet-34[11]构成。输入图像经过VFM模块编码器的多次卷积和逐级下采样,得到车道正视角度的特征图FV1,FV2,再通过解码器的逐级上采样得到与原输入图大小一致的车道线二值语义分割图IS。通过使用透视变换将IS转换到车道俯视角度的分割图像IS′,使用TFM模块提取俯视角度不同尺度的车道特征信息FT1、FT2。
2.3 特征融合子网络
特征融合子网络由语义Transformer和细节Transformer两个模块构成,分别用于提取不同特征尺度下的车道语义信息。其中语义Transformer模块旨在判别车道线高级语义信息,在例如车道线存在车辆遮挡、车道线磨损不连续等情景下,依赖图像的上下文信息做出车道线的位置判断。细节Transformer模块在语义Transformer输出信息基础上在分辨率较高的特征图中进一步恢复出车道线细节位置信息。将特征提取模块输出的FV1,FV2,经透视变化后与FT1、FT2融合,再将其加入位置编码信息并展开成序列SC和SF。SC表示分辨尺度较小下的语义车道特征序列,而SF表示分辨尺度较大下的细节车道线特征序列,保留了更多的局部车道细节纹理信息。语义Transformer将SC作为输入,利用近处识别出的车道线信息,结合车道线具有长而细且连续的结构先验特征,输出的特征序列语义SC″保持了远近车道线结构的上下文一致性。细节Transformer则将SF作为编码器的输入序列,并将SC″作为解码器的查询向量,在分辨率更高的特征图中识别出的车道线细节信息。
2.4 损失函数
给定图像及其对应的地面真实三维车道,本文将三维车道检测的评估表述为预测车道和地面真实车道之间的二分匹配问题。每条地面真实车道曲线都被投影到虚拟俯视图上,并与最近的位于Yref的锚相关联。根据预定义的水平位置集合处的地面真值计算地面锚点的属性。给定成对的预测车道和相应的真值损失函数可以写成:

3 实验结果与分析
3.1 数据集
本文的实验基于Guo等人[8]提出的3D车道线公开数据集。该数据集基于美国硅谷的真实区域,并使用Unity游戏引擎构建的虚拟3D道路地图。其中包括虚拟高速路地图样本图像6000张、城市地图样本图像1500张、居住区道路样本图像3000张,还附加了以及相应的深度图、语义分割图和三维车道线信息。为了充分验证并说明本文算法的有效性和先进性,将数据集划分为三种不同的场景。
(1)平衡场景。本场景训练集和测试集数量保持相对平衡,场景变化保持相对稳定。
(2)长尾特征分布的场景。这个场景下训练集与平衡场景相同,但测试集仅使用复杂的城市地图。该划分方法中,由于测试图像稀疏地呈现在不同的位置,涉及剧烈的海拔变化和尖锐的转弯,测试数据中的场景很少从训练数据中观察到。该数据集拆分方法旨在验证模型对于长尾数据的泛化能力。
(3)具有视觉变化的场景。该场景下3D车道线数据训练数据集仅包含傍晚时分的道路场景,而测试数据使用一天之中其他时间段的道路场景。因此该分类中训练集与测试集的道路场景的光线存在较大的变化。
3.2 评价指标
本文将3D车道检测表述为预测车道和地面真实车道之间的二分匹配问题。对于用于表示一条车道线一组点集合如果有超过75%的点在其预定义的水平坐标y上的x偏移量和高度z与真实值的欧式距离不超过最达允许误差(1.5 m)时,则认定这条车道线模型与真实车道匹配成功,否则认定为误检或者漏检。匹配的地面真实车道线占总真实车道线百分比报告为召回,预测成功车道线占总预测输出数量的百分比报告为精度。最后将平均精度(AP)和F-score作为主要的评价指标。此外,在这些匹配车道上,近距离(0~40 m)和远距离(40~100 m)的误差(欧氏距离)也作为算法的辅助评价指标。

3.3 实验结果与分析
如表1所示,我们的方法在所有三个实验场景分组中都优于最先进的方法,F1-socre指标提升5~7个百分点。特别是,在第二类和第三类道路场景中,考虑到这些类型的场景具有较少的道路样本,并且道路环境更为多变,相对于最以往的检测算法,本文提出的模型实验结果的指标提升是非常明显的。这意味着我们的网络体系结构在3D车道检测任务中表现出更优越的鲁棒性和通用性。
为了客观全面地说明本文方法的有效性和先进性,本文在测试集上选择了几个不同的典型场景车道图像作为样本并可视化了3D车道线检测结果。如图4所示。

图4 车道线检测结果可视化

表2 模型的评估结果
四种典型的道路场景,场景一(左上部分)是在道路远处有较大曲率转弯的道路;场景二(右上部分)连续上坡道路;场景三(左下部分)连续下坡并存在较大曲率的转弯道路;场景四(右下部分)是先下坡再上坡的凹形道路。检测结果可视化表明,本文提出的模型在距离车辆近处的车道线检测结果与以往的方法相当,但在距离车辆较远的道路区域,以往检测方法出现了严重的偏差,而本文模型则依然能够捕捉到准确的3D车道线位置,且在存在大幅度曲率的转弯道路场景中依然表现出良好的性能。
3.4 Transformer模型大小的影响
为了研究Transformer模型中编码器和解码器层数对3D车道线检测结果的影响,本文研究了编码器和解码器不同层数的组合。实验结果如表3所示。

表3 Transformer模型大小对检测结果的影响
可以看出,随着网络层的加深,最终的3D车道线检测准确率不断提高。这也表明本文提出的模型结构的有效性和灵活性,在其单纯增加网络的深度的情况下,就能提升更加复杂场景下的3D车道线检测精度。
4 结语
以往的3D车道线检测算法在道路远处的检测结果误差较大,针对这个问题,本文提出了基于Transformer框架与CNN网络相结合的3D车道线检测模型。通过对不同尺度下的车道线特征信息来从语义到细节逐步定位车道线的位置。并且使用Transformer网络对长距离序列的特征提取能力,利用道路近处和远处车道线的具有连续性和一致性来改善车道线远处的检测效果,极大地提高了车道检测的正确率。实验表明,本文实现的算法具备较强的鲁棒性和较高的检测准确度。
猜你喜欢
当代陕西(2022年4期)2022-04-19
汽车实用技术(2022年5期)2022-04-02
小猕猴学习画刊(2022年3期)2022-03-28
金桥(2019年10期)2019-08-13
读写算·高年级(2015年1期)2015-07-25
长江学术(2015年1期)2015-02-27
人民周刊(2009年12期)2009-01-25
