
基于可见/近红外光谱技术的板栗产地识别*
2022-01-19 08:35:00杨雨图熊杰司万方会敏黄玉萍
中国农机化学报 2021年12期
杨雨图,熊杰,司万,方会敏,黄玉萍
(1.南京林业大学机械电子工程学院,南京市,210037;2.江苏大学农业工程学院,江苏镇江,212013)
0 引言
板栗营养价值与药用价值高,它富含蛋白质、碳水化合物、维生素以及矿物质元素,是一种较为理想的食品、药品加工原料[1-3],一直深受广大消费者的喜爱。我国盛产板栗,且种植分布广泛[4-5],在复杂的气候和地理条件下,不同产地板栗之间的大小、品质、口感有明显差异,价格也显著不同,因此,急需研究板栗产地识别技术对其进行快速分级,从而适应市场需求。
目前,常见的板栗品种检测方法主要有人工鉴别法和分析化学检测法。人工鉴别法通过直接观察板栗的外表性状特征,如坚果形状、果面光泽、果面绒毛等判别板栗的产地。然而,采用人工鉴别的方式不仅效率低下,耗用大量人力资源,而且经常会受到人的主观意识的影响,降低了判别的准确性。分析化学检测法则是测定板栗的化学成分从而对板栗的产地进行识别。分析化学检测方式虽然检测准确率高,但速度较慢,且需要破坏板栗果实的完整性和可食用性,只能进行小批量抽样检测,不适合规模化、工业化的食品加工产业。
近红外光谱技术具有快速、无损、无需样品制备等优点,被广泛用于食品定性和定量检测中。何勇等[6]采用近红外光谱技术结合主成分分析法,建立人工神经网络模型实现对杨梅品种的快速识别,识别率达到95%。李晓丽等[7]采用350~1 075 nm的可见/近红外光谱鉴别水稻的5个品种,应用小波变换进行光谱预处理,主成分分析降维结合反向传播人工神经算法,识别率达到96%。陈建等[8]在1 000~2 632 nm光谱区间对玉米品种进行判别分析,比较分析多种光谱预处理(如Savitzky-Golay平滑、多重散射校正)对分类结果的影响,最优分类结果达到95%。此外,也有一些学者运用近红外光谱技术,通过不同的数学模型对食品[9-15]、土壤[16-20]、药物[21-25]等成分特性进行研究。一些研究报道了近红外光谱分析技术能够被用于检测板栗样品,但大都集中在板栗化学组分的定量分析,在识别产地等方面定性分析的研究相对较少。
因此,本研究将采用可见/近红外光谱技术在600~1 100 nm光谱区间对板栗的产地进行判别分析。由于采集到的光谱信息中还掺杂着噪声和杂散光等,需要通过光谱预处理方法对数据进行校正,提高信噪比。另外,不同波长点对样品的响应特性也存在差异,研究不同波长范围对板栗产地的识别将有助于提高板栗的分级速度。
1 板栗光谱采集与分析
1.1 试验样品
试验所用的200个板栗样品均购买于南京市场,河北和安徽产地的板栗样品各100个(图1)。购买后将样品置于温度为4 ℃的冰箱内保存。试验前一天晚上将样品取出,放置室温一晚以备第二天光谱采集试验。

(a)安徽板栗
1.2 近红外光谱采集
本试验使用SupNIR-1100型光栅扫描式近红外光谱分析仪采集每个板栗样品的近红外反射光谱,光谱波长范围为600~1 100 nm,积分时间设置为80 ms,光谱平均次数为3次、分辨率为1 nm。试验过程中,环境温度在25 ℃左右,采集反射率为98%的白板光谱,将其作为参比光谱,再将样品放置于容器中依次扫描完成。
1.3 光谱预处理与建模分析
为避免系统误差,本试验采用相对光谱Sr建模分析,如式(1)所示。
(1)
式中:S——样品原始光谱;
W——参比光谱;
D——暗场光谱。
1.3.1 光谱预处理
标准正态变量变换(Standard Normal Variate,SNV),主要用于消除光谱数据中因样品大小不一、表面散射及光程差异产生的影响。SNV与标准化算法的计算类似,区别在于SNV对光谱矩阵的行进行变换,标准化则是对列进行变换。计算公式如式(2)~式(4)所示。
(2)
(3)
(4)

σi——第i个样本光谱的标准差;
n——波长点数。
Savitzky-Golay平滑属于低通滤波器,常被应用于数据流平滑去噪,在去除噪音的同时能够确保数据的主要信息不受影响。Savitzky-Golay平滑是通过多项式对移动窗口内的数据使用最小二乘法进行拟合,算出窗口内中心点关于其周围点的加权平均和。使用Savitzky-Golay平滑时,窗口宽度与拟合次数的选取至关重要,其直接决定了Savitzky-Golay平滑的微分点数,若微分点数过小,噪音无法完全去除,则达不到理想效果;反之,若微分点数过大,使数据过于平滑,导致数据所带的特征信息缺失,建模的可靠性就会降低。
导数处理也是光谱预处理常用的方法之一,例如差分求导,就是一种最简单的离散数据求导法。使用此方法会使输出矩阵维数减少,为解决此问题,一般在预处理前在矩阵头或尾增加一列或两列相同数据。
1.3.2 建模方法
本研究采用MATLAB 2018a分析软件结合PLS Toolbox 8.2建立板栗产地的偏最小二乘判别分析(PLSDA)模型。偏最小二乘判别分析是一种有监督模式识别的多元统计分析方法,其优点是能够减少变量间多重共线性产生的影响。
200个板栗被随机分在校正集(150个板栗样品)和验证集(50个板栗样品)。分别建立不同光谱预处理下的PLSDA数学模型,比较各模型的性能,运用威尼斯百叶窗交叉验证法,并根据最小交叉验证分类误差确定最佳潜在变量数量。
2 结果与分析
2.1 光谱分析
图2(a)显示了所有板栗样品的可见/近红外光谱,各光谱间差异较难分辨。从图2(a)中可以发现,600~750 nm以及1 000~1 100 nm区间的光谱不够光滑,这种现象同样也出现在图2(b)和图2(c)中,这可能是由于噪声导致的。但经过Savitzky-Golay平滑处理后,噪声影响相对较少,光谱曲线也相应变得光滑,如图2(c)所示。经过标准正态变量变换预处理后,光谱的形状发生变换,尤其在靠近800 nm处。此外,经过标准正态变量变换后,在970 nm处的水分吸收峰变得更加明显。经过一阶求导后,光谱曲线值大部分集中在0点位置。

(a)原始光谱
分别将100个安徽板栗和100个河北板栗的可见/近红外光谱图进行平均,如图3所示。
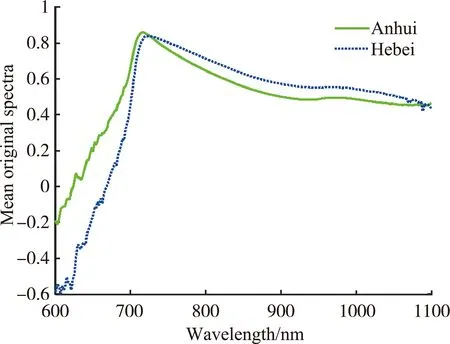
(a)两产地板栗原始平均光谱
获得的两条可见/近红外平均光谱图,如图3(a)所示,不同产地的板栗光谱曲线存在差异,尤其在750~1 000 nm区间,这说明不同产地的板栗成分和物理结构可能不同。经过标准正态变量变换预处理后,增加了两种板栗光谱曲线的差异性,如图3(b)所示。经过Savitzky-Golay平滑后,光谱曲线变得更平滑,尤其在光谱的端部(600~750 nm和1 000~1 100 nm),而形状与原始光谱未有太大差异。但经过一阶导数预处理后,光谱的形状有了较大改变,光谱端部变化较大,这可能是由于噪声引起的。
2.2 基于可见/近红外光谱的板栗产地的识别
表1显示了基于偏最小二乘判别分析(PLSDA)模型全波长条件下不同光谱预处理对板栗产地的判别结果。原始光谱建立的PLSDA模型对板栗产地识别的决定系数为0.859,验证集决定系数为0.839,校正集和验证集的均方根误差分别为0.188和0.204。经过SNV光谱预处理后,校正集决定系数提高了2.8%,均方根误差减少了9.0%,但验证集的决定系数提高不明显,仅为1.0%左右,而均方根误差也仅减少了3.4%。相较于SNV,一阶导数光谱预处理可以进一步提高校正集和验证集的决定系数,其决定系数分别为0.884和0.863,比原始光谱建立的PLSDA模型均提高2.9%,同时,校正集和验证集的均方根误差分别降低了9.6%和6.4%。然而,当经过Savitzky-Golay平滑光谱预处理后,校正集和验证集的决定系数反而减小了5.2%和11.6%,且均方根误差分别增大了14.9%和27.9%,这可能是由于平滑处理使得数据所带的特征信息缺失,导致模型的可靠性降低。综上所述,光谱预处理对模型的性能影响较大,合适的光谱预处理能够有效提高模型的可靠性。
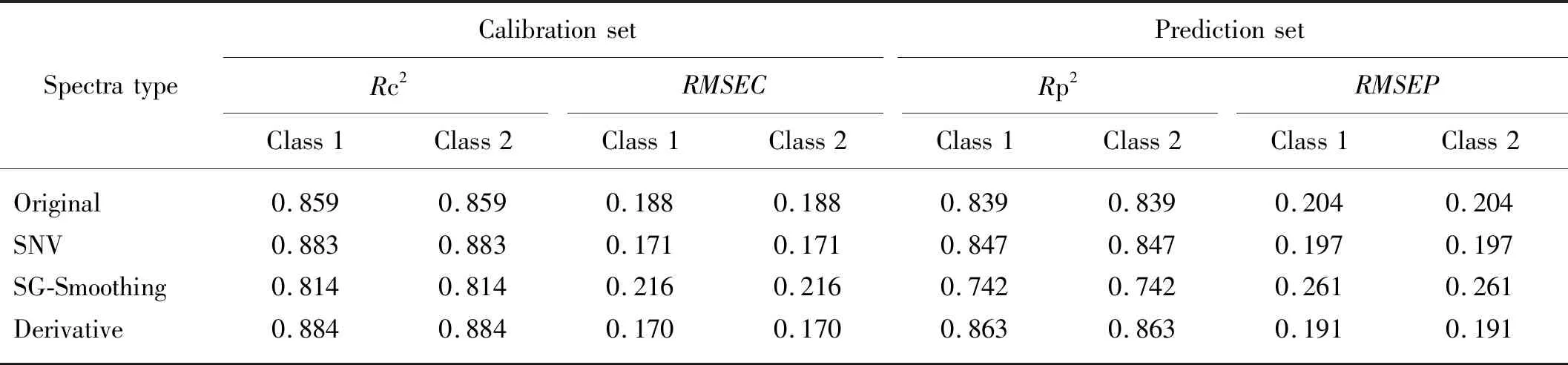
表1 基于偏最小二乘判别分析模型全波长条件下各光谱预处理对板栗产地的校正集和验证集识别结果Tab.1 Classification results for chestnut geographic origin based on PLSDA models using different spectral preprocessing methods at full wavelength range for calibration and prediction sets
表2显示了在600~1 100 nm光谱区间,基于PLSDA模型,各光谱预处理的校正集和验证集的敏感性与特异性统计分析。不管是校正集还是验证集,原始光谱、SNV光谱预处理和一阶导数预处理的敏感性和特异性都一样,校正集中安徽板栗和河北板栗的敏感性分别为1和0.973,特异性分别为0.973和1。验证集中安徽板栗和河北板栗的敏感性和特异性均为1,说明PLSDA模型能100%识别验证集中两个产地的板栗。而Savitzky-Golay平滑预处理的敏感性和特异性相对较差,校正集中安徽板栗和河北板栗的敏感性分别为0.987和0.945,特异性为0.945和0.987,验证集中敏感性分别为1和0.889,而特异性为0.889和1,相对较低的敏感性和特异性可能是由于模型可靠性不高导致的。
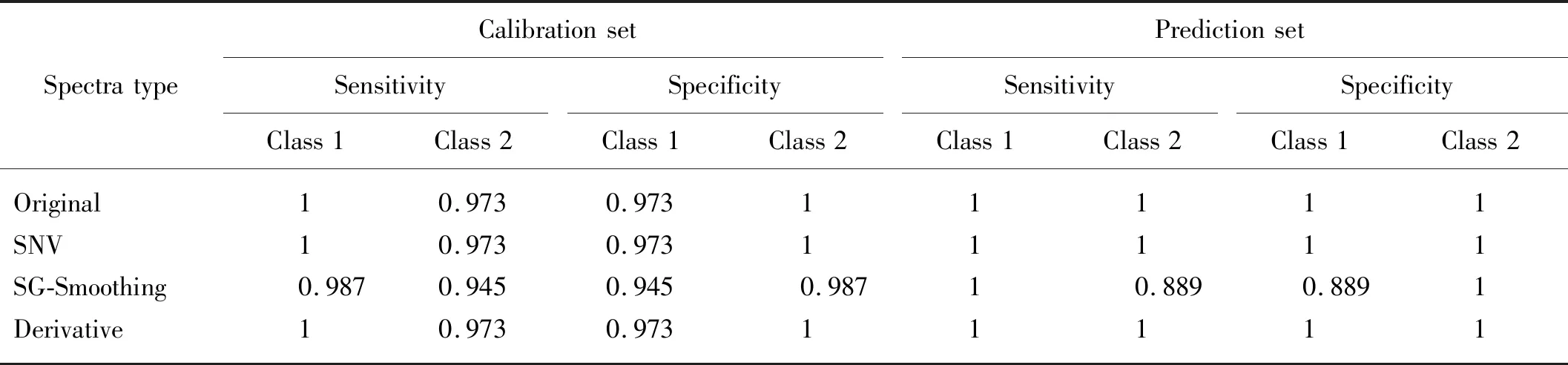
表2 基于偏最小二乘判别分析模型全波长条件下各光谱预处理的敏感性与特异性分析Tab.2 Performance of the PLSDA models developed by different spectral preprocessing methods at full wavelength range
由图2可知,光谱曲线端部(600~750 nm以及1 000~1 100 nm)信噪比较弱,且750~1 000 nm光谱区间两个产地板栗的差异较大,见图3。因此,选取750~1 000 nm区间的光谱再次建模分析,结果如表3所示。相较于表1,虽然原始光谱的校正集的决定系数没有改变,但验证集的决定系数提高了3.2%,均方根误差减少了8.3%,说明噪声会影响模型的性能。另外,各光谱预处理在消除噪声影响后,不管是校正集还是验证集,决定系数均有所提高,均方根误差降低。针对验证集,提高最为明显的是Savitzky-Golay平滑预处理,决定系数提高了16.3%,均方根误差减少了27.6%。相较于一阶导数预处理后,验证集提高并不明显,而校正集决定系数提高3.3%,均方根误差降低了13.5%。经过SNV光谱预处理,校正集和验证集均有较为平稳的提高,决定系数分别提高了2.3%和4.3%,均方根误差降低了8.8%和10.2%。

表3 基于偏最小二乘判别分析模型在750~1 000 nm波长范围各光谱预处理对板栗产地的校正集和验证集识别结果Tab.3 Classification results for chestnut geographic origin based on PLSDA models using different spectral preprocessing methods over the spectral range of 750~1 000 nm for calibration and prediction sets
表4显示了在750~1 000 nm波长区间,经过各光谱预处理,基于PLSDA模型对两个产地板栗的敏感性与特异性的统计分析。原始光谱和Savitzky-Golay平滑预处理的校正集和验证集的敏感性和特异性均达到最优,说明这两种光谱建立的PLSDA模型对板栗产地的识别率最优,校正集和验证集识别率均可达到100%。经过SNV预处理,虽然校正集的敏感性和特异性能达到1,但验证集中的河北板栗的敏感性与安徽板栗的特异性均只有0.963,这是由于有一个河北板栗被误判到安徽板栗。然而,经过一阶导数预处理,不管是校正集还是验证集,敏感性与特异性均没有达到最优,这主要是因为在校正集中,有一个河北板栗被误判到安徽板栗,而在验证集中,有一个安徽板栗被误判到河北板栗。
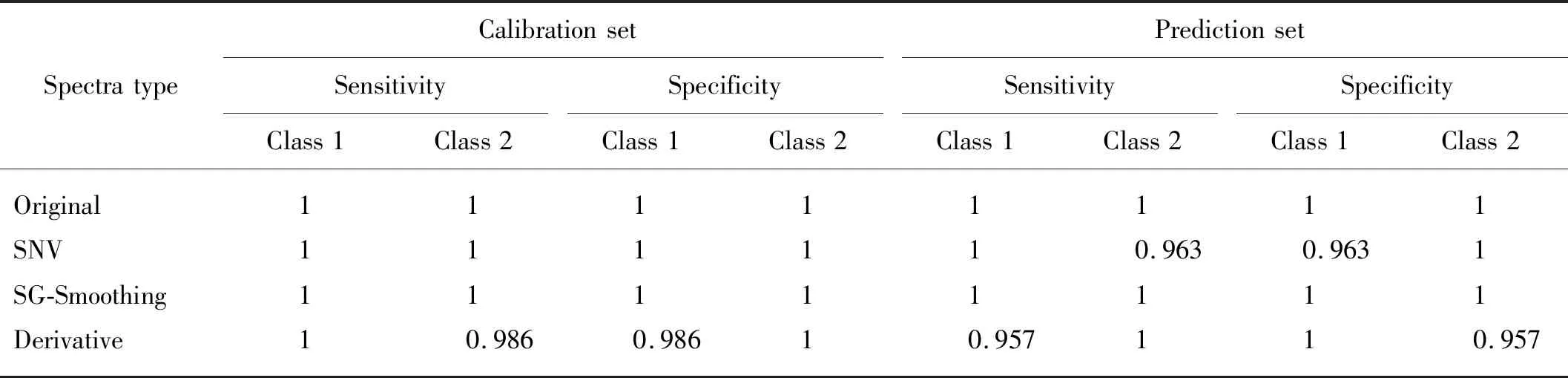
表4 基于偏最小二乘判别分析模型750~1 000 nm波长范围各光谱预处理的敏感性与特异性分析Tab.4 Performance of the PLSDA models developed by different spectral preprocessing methods over the spectral range of 750~1 000 nm
3 结论
分析比较不同光谱预处理所建立的偏最小二乘判别分析模型对板栗产地的识别能力,结果表明,光谱预处理对板栗产地的识别具有影响,一阶导数对全波长数据较有效,两产地板栗的预测决定系数均能达到0.863。对比全波长与近红外光谱区域光谱建立的偏最小二乘判别分析模型的性能,结果显示,波长为750~1 000 nm的近红外光谱区域光谱对板栗产地的识别更具有优势,原始光谱和Savitzky-Golay平滑光谱建立的偏最小二乘判别分析模型的敏感性与特异性均能达到1,说明750~1 000 nm区域的光谱能有效鉴别板栗的产地。
猜你喜欢
公民与法治(2022年12期)2023-01-07 09:18:02
小学生作文(低年级适用)(2022年11期)2022-12-02 09:01:10
电脑与电信(2021年10期)2021-02-10 06:53:44
南方农业学报(2020年4期)2020-06-04 15:51:13
南方农业学报(2020年10期)2020-01-21 15:36:41
创新作文(小学版)(2019年10期)2019-09-25 08:12:24
中国外汇(2019年22期)2019-05-21 03:14:56
意林·全彩Color(2018年9期)2018-10-12 01:06:54
中成药(2018年8期)2018-08-29 01:28:16
科学与财富(2018年12期)2018-06-11 01:49:24
