
基于K⁃Means 聚类与深度学习的RGB⁃D SLAM 算法
2022-01-14 03:02:32张晨阳吴壮壮
计算机工程 2022年1期
张晨阳,黄 腾,吴壮壮
(河海大学地球科学与工程学院,南京 211100)
0 概述
同时定位与制图(Simultaneous Localization and Mapping,SLAM)是机器人在未知场景中构建地图和实时更新、环境自主定位的过程[1],SLAM 算法是机器人在未知环境作业的关键技术和机器人自动化领域的研究热点[2]。距离传感器常被作为SLAM 感知周围环境的数据源[3],相比声呐、雷达等测距传感器,其视觉相机体积较小、功耗较低且能够获取丰富的纹理信息,为机器人导航定位提供周围实时的环境信息。视觉SLAM 已被运用于美国NASA 火星探测计划以及我国嫦娥三号、嫦娥四号探月计划[4-6]。RGB-D 相机是一种新型的视觉传感器,由彩色相机和深度相机组成,能够同时感知未知环境的深度信息和彩色纹理信息[7]。目前,以微软Kinect 系列为代表的RGB-D 相机被广泛应用于机器人、计算机视觉、生物医学工程等领域[8-10]。因此,以RGB-D 相机作为数据源输入的传感器成为视觉SLAM 的研究热点。
本文提出一种结合全新的跨平台神经网络(NCNN)框架深度学习和K-Means 聚类的RGB-D SLAM 算法。该算法对动态场景中不同特征种类进行识别分割,根据相邻帧极线约束和深度值约束剔除动态特征点,并计算相机的位姿,从而准确地剔除动态特征。同时,保留静态特征以避免由特征点过少导致的SLAM 系统跟踪失效问题。
1 相关工作
大部分视觉SLAM 算法多数是基于静态环境条件下完成的,但是当场景中存在移动物体(如行人、车辆等)时,基于特征的SLAM 算法(ORB-SLAM2[11]、LSD-SLAM[12]、PTAM[13])和直接法的SLAM 算 法(DTAM[14])都无法区分这些场景中移动目标区域的特征种类。动态物体上的特征匹配点会产生数据错误关联,直接导致视觉SLAM 估计姿态精度退化甚至错误,使得现有许多鲁棒的视觉SLAM 算法应用受到了很大局限。近年来,众多研究人员关注基于动态场景的视觉SLAM 的研究。
文献[15]提出动态场景的视觉SLAM 算法,该算法主要包含动态特征的检测与跟踪,利用激光测距仪获取数据并验证算法的合理性。基于动态场景SLAM 算法的基本原理是在图像序列中检测动态物体并剔除。研究者利用稠密场景流识别5 m 范围内的移动物体,但这种方法识别动态物体存在距离范围限制且在低纹理场景易将静态的点特征误判定为动态点特征[16]。由于视觉场景中大部分特征都处于静止状态,只有少数特征处于运动状态,文献[17]将这一假设融入动态与静态特征分割从而提出稠密的RGB-D SLAM 算法。文献[18]通过假设相邻图像帧是匀速运动,对于图像序列上运动的物体而言,运动物体上的特征点速度大于静态特征点速度,根据这一准则实现动态特征点剔除。此外,与上述方法不同,文献[19-20]提出不依赖于先验假设信息,结合基于粒子滤波的最大后验估计和码书模型以实现动态特征的稠密分割,并融合在稠密视觉里程计(Dense Visual Odometry,DVO)中,最后在RGB-D 公开数据集完成测试。
以上动态场景的视觉SLAM 算法都是通过建立直接探测移除动态特征,且假设约束条件比较苛刻。另外一类是利用鲁棒的数学模型处理算法尽可能探测动态特征并剔除。文献[21]利用随机有限元模型表达视觉特征和测量结果,并用贝叶斯递归表示静态和动态地图点位置。文献[22]针对动态场景利用多个相机提出一种CoSLAM 算法,CoSLAM 模型利用特征点二维重投影误差区分特征点的种类。文献[23]利用位姿图表示机器人姿态,根据位姿图节点误差阈值剔除尺度动态特征关联。由于RGB-D 相机能实时提供深度测量值,研究人员利用深度值检测动态物体,文献[24]通过估计深度场景的背景模型和帧间位姿以消除移动物体的影响。文献[25-26]分别利用深度学习建立深度滤波器结合语义信息识别运动物体,文献[27]利用基础矩阵以及结合深度聚类约束相机之间姿态,消除动态点特征错误的关联匹配。基于数学模型剔除动态特征的方法定位精度较低且不能准确地区分动态特征和静态特征。此外,光流也被应用在图像动态物体检测,例如,文献[28]利用光流和高斯混合模型识别动态场景点,文献[29]结合光流和基础矩阵剔除动态特征。在实际的动态场景中,由于相机存在运动,基于光流法的视觉SLAM 通常效果不佳且受光照影响较大。除了基于光流场原理,研究人员还借助额外的传感器来剔除动态场景中外点,文献[30]结合GMS 特征点匹配原理和滑动窗口借助于多个传感器消除动态场景中的外点。惯性测量单元(Inertial Measurement Unit,IMU)被运用在动态SLAM中以移除外点。文献[31]利用RGB-D相机和IMU 以实现动态场景SLAM,其中IMU 测量信息被当作位姿估计的先验信息以消除动态场景中的错误视觉关联。
近年来,随着深度学习的快速发展,人们结合深度学习来识别并移除动态特征实现动态场景的视觉SLAM 算法。文献[32]通过结合卷积神经网络Fast-RCNN[33]提出一种动态的RGB-D SLAM,利用卷积神经网络探测矩形框中的人物,然后移除特征关联位于矩形方框的特征点关联。文献[34]根据ORB-SLAM2 结合RGB-D 相机深度值确定动态物体并移除动态物体实现SLAM。文献[35-36]提出利用YOLO 深度学习模型识别图像序列中的移动物体。此外,文献[37]将Dyna-SLAM 结合多视图几何以及Mask-RCNN 识别动态场景物体并提供开源的代码程序,文献[38]在Dyna-SLAM 基础上结合语义信息剔除动态特征从而提出DM-SLAM,文献[39]构建自适应窗格匹配模型并利用Mask-RCNN 实现语义信息识别,实现动态场景的三维重建。文献[40]利用YOLO 深度学习模型以及对极约束识别动态特征点提出DS-SLAM,文献[41]利用YOLO 学习模型结合贝叶斯滤波后验估计识别动态特征,在ORB-SLAM2 基础上提出一种改进的动态SLAM。基于深度学习的视觉SLAM 算法定位精度较高,但是目前大部分基于深度学习的视觉SLAM 算法易造成动态物体的过剔除现象,导致静态特征大量丢失,使得视觉SLAM 精度退化,最终位姿估计失败。
2 算法流程
本文算法流程如图1 所示,主要分为前端动态特征检测和后端平差两部分。对于输入的RGB和深度图像数据,本文算法利用RGB 图像提取ORB[42]点特征,基 于NCNN 网络框架识别动态特征获取对应的动态区域。同时,在深度图像中,本文利用K-Means 进行深度值聚类,根据潜在动态特征占据深度区域内绝大多数像素对其进行识别和分割,然后根据相邻帧极线约束和深度值约束,剔除动态特征点。最后,通过相邻帧匹配的静态特征点计算相机姿态。本文结合前端获取的静态特征,在后端进行光束法平差从而获取高精度相机位姿。
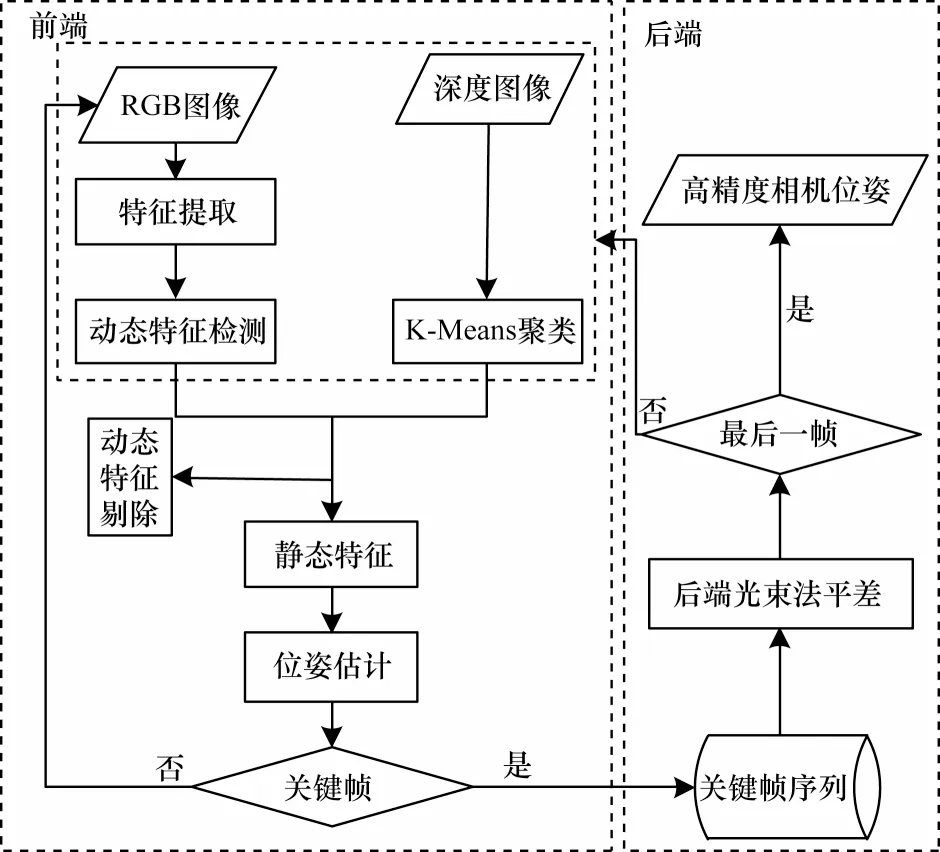
图1 本文算法流程Fig.1 Proceduce of the proposed algorithm
2.1 准动态信息检测
为保证目标检测算法的实时性,本文以Mobile Net 网络作为目标检测网络的前端特征提取网络。Mobile Net[43]是谷歌团队推出的一款轻量级网络模型。Mobile Net 利用深度分离卷积代替传统卷积,从而减少模型参数数量并提升整体运行效率。Mobile Net 模型是基于深度可分离的卷积,该分解卷积是将标准卷积分解成一个深度卷积和一个1×1的逐点卷积。对于移动网络,深度卷积在每个输入通道用一个滤波器。逐点卷积用1×1 的卷积来组合输出深度卷积。标准卷积在一个步骤对深度卷积和逐点卷积输入过滤并组合为一组新的输出。深度上可分离的卷积分为用于过滤的单独层和单独的结合层,这种因式分解大幅减少了运算量和模型。传统卷积与深度可分离卷积示意图如图2所示。
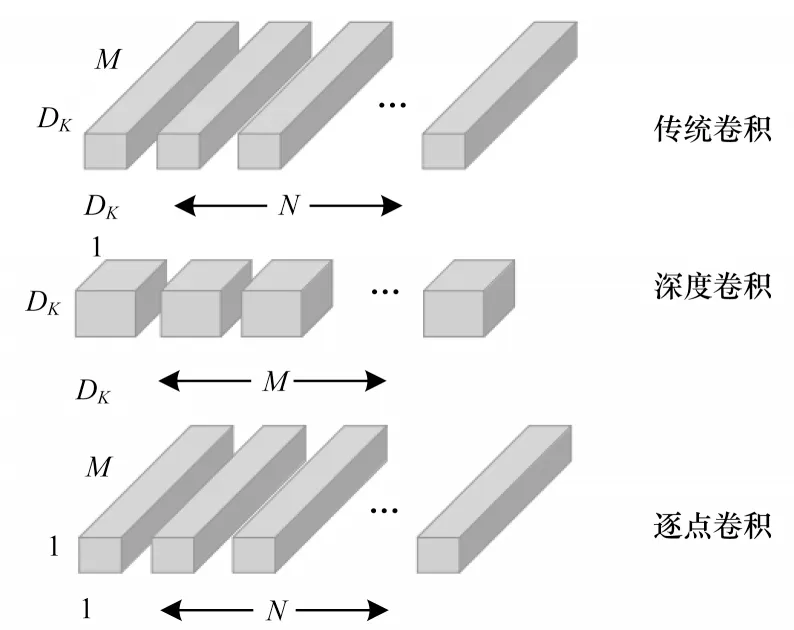
图2 传统卷积与深度可分离卷积示意图Fig.2 Schematic diagram of traditional convolution and deeply separable convolution
传统卷积的运算量P1如式(1)所示:

其中:Df为输入图像的宽和高;M为输入通道数;Dk为卷积核的长和宽;N为卷积核的个数。此外,为获取输入通道数的深度,传统卷积需要对每个输入通道深度卷积用单个卷积核进行卷积,随后利用1×1逐点卷积来线性组合深度卷积新的输出项。深度可分离卷积的运算量P2如式(2)所示:
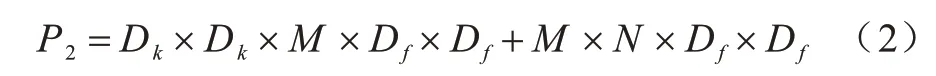
深度可分离卷积与传统卷积的运算量之比如式(3)所示:

因此,深度可分离卷积能够大幅降低运算量。根据Mobile Net 目标检测网络可以在普通PC 机上使用,本文基于NCNN 平台框架近似地实现准动态语义信息检测范围。语义目标检测范围如图3所示。

图3 语义目标检测范围Fig.3 Detection range of semantic target
2.2 深度图像K-Means 聚类与动态特征识别
K-Means 聚类是一种简单的迭代型聚类算法。距离被作为相似性指标,实现划分给定数据集为k类,且每个聚类的中心都是通过所属类中所有元素的均值获得。对于给定的一个包含一维以及n维以上数据点的数据集S和需要聚类的类别数量k,一般以元素间的欧氏距离作为相似度指标,代价函数为聚类后最小化每类的距离平方和。假设数据Si需要划分为k类,每个数据所属的类别记作qi,且k个聚类中心表示为cj。对应的代价函数如式(4)所示:

K-Means 聚类算法首先随机选取k个样本作为聚类中心,然后按照以下4 个步骤迭代进行:1)计算各样本与各个聚类中心的距离;2)将各样本回归于与其距离最近的聚类中心;3)求各类样本的均值,并将其作为新的聚类中心;4)若各个聚类中心不再变化或者算法迭代次数超过设定阈值,则退出,否则返回步骤2 循环。
本文根据Mobile Net 获取图像上语义信息对应的像素范围(图3 方框中),从而得出范围内的特征点;然后利用深度图像获取对应特征点的深度值并对这些特征点深度实行K-Means 聚类,在本文中聚类获取分为准动态特征聚类和静态特征聚类。由于语义信息框中动态信息所占区域范围远大于静态背景信息,本文根据聚类值最大的一类划分为准动态特征,剩下的划分为静态特征;依次对每帧彩色图像和深度图像进行语义信息识别以及语义信息对应的深度图像聚类。动态特征剔除流程如图4所示。
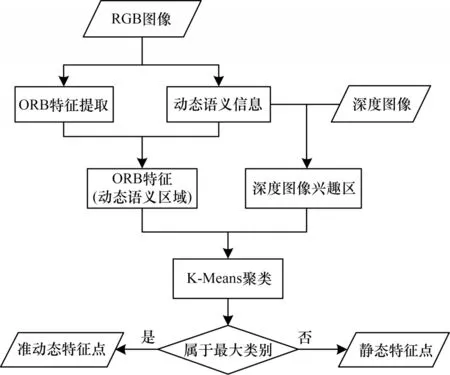
图4 动态特征剔除流程Fig.4 Culling proceduce of dynamic features
为了能最大程度保留静态特征,本文在获取最大聚类集合M时,按照升序排序后的M′,获取S、B的阈值,如式(5)所示:

其中:m为M’的数量个数;[]表示集合中元素索引对应的元素值。本文根据计算每个语义信息的S和B作为阈值范围,以区别动态和静态特征。为了不过大分割动态特征导致静态丢失,本文选择的区间位于集合总数的10%~90%。如果特征点深度值位于选择的阈值区间时,该特征点属于准动态特征,否则属于静态特征。因此,本文根据上述原则实时自定义检测准动态特征点和静态特征点。在TUM 数据集序列中准动态特征提取识别的示例如图5 所示(彩色效果见《计算机工程》官网HTML 版)。红色十字表示准动态特征点,绿色十字表示静态特征点。从图5 可以看出,在不同的场景中,本文算法能较准确地识别静态和准动态特征点,以提高相机位姿估计的精度。

图5 准动态特征提取识别示例Fig.5 Extraction and recognition example of quasi dynamic features
本文在获取静态特征点后,首先利用当前帧和参考帧进行静态特征点匹配获取匹配点集合Q;其次根据静态匹配点集合Q计算相机运动的基础矩阵F。对于上述的每个准动态特征点,本文利用对极约束识别动态特征点,设置一定的阈值并根据式(6)计算每个准动态特征点到极线的距离,若距离大于阈值则认为是动态特征点,否则归为静态特征点。对极几何约束如式(6)所示:

其中:Ci和Ri分别为当前帧和参考帧匹配点的齐次坐标;F为基础矩阵。
对极几何约束如图6 所示。
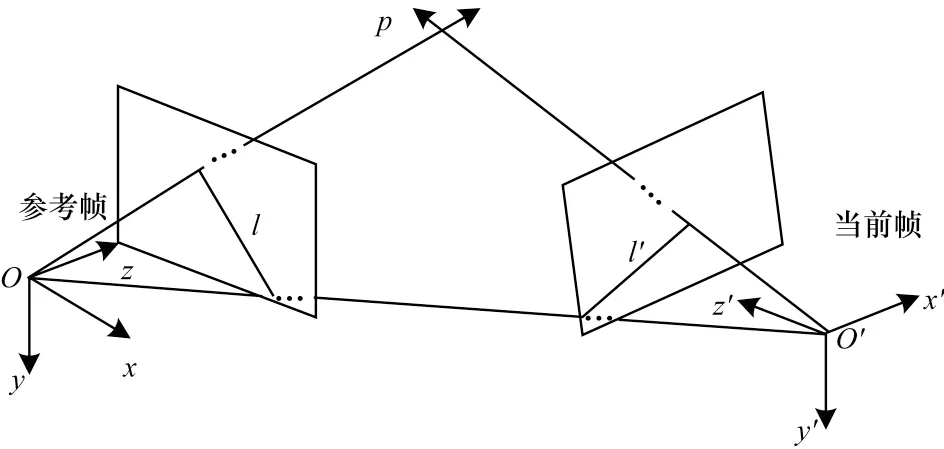
图6 对极几何约束Fig.6 Constraints of epipolar geometry
由于每帧彩色图像对应深度图像,本文通过两帧匹配点对应的深度差再次识别动态特征点,利用上述静态特征点和对应的深度值结合P3P 算法计算当前帧和参考帧之间的位姿。本文根据计算的参考帧和当前帧的位姿,采用潜在动态特征点对应的深度值恢复当前帧匹配点,匹配点在三维空间下的距离差Derror如式(7)所示:

其中:Xref为参考帧三维坐标;Xcurr为当前帧三维坐标。
本文根据每对匹配点在三维空间下坐标差获取匹配点误差集合并进行降序排列,定义匹配点误差集合中元素总数量的20%作为动态特征点的阈值,即集合元素值索引排在总数的前20%将被视为动态特征点且剔除。动态特征点识别算法流程如图7 所示,最后保留的静态特征点匹配如图8所示。
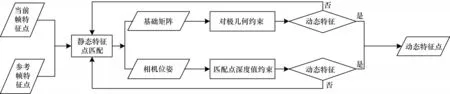
图7 动态特征点识别算法流程Fig.7 Proceduce of dynamic features point for recognition algorithm

图8 静态特征点匹配Fig.8 Static features point matching
本文算法在完成相机位姿估计的同时,判断当前帧是否为关键帧,若是,则插入关键帧序列同时进行后端光束平差(Bundle Adjustment,BA)计算,否则该帧将继续与下一帧进行特征匹配完成相机位姿估计。当完成所有数据序列前端位姿跟踪估计及后端平差时,最终输出高精度相机位姿估计结果。
3 实验与结果分析
本文使用公开的TUM RGB-D 数据集进行验证并利用绝对路径误差(ATE)进行评估。TUM 数据集[44]是慕尼黑工业大学计算机视觉组提供的RGB-D 数据集,动态场景数据集主要是fr3/sitting_xx 系列和fr3/walking_xx 系列,其 中fr3/sitting 和fr3/walking 分别表示低动态和高动态场景数据集。本文实验计算机的硬件参数为:ThinkPad T480,CoreTMi5-8250U CPU@1.60 GHz,4 GB内存。算法基于C++、g2o、OpenCV3.2.0等进行编写,并在Ubuntu 16.04 操作系统上实现,最后利用fr3/walking_rpy 公共数据序列验证算法有效性。本文对所有的fr3 数据序列进行定性和定量实验,进一步验证算法的精度和鲁棒性。
为了验证算法的有效性,本文首先使用数据集fr3/walking_rpy 分别对经典的ORB-SLAM2 算法、基于Mobile Net 深度学习动态SLAM 算法以及本文(Mobile Net+K-Means)算法进行实验对比。不同算法的相机绝对位姿误差对比如表1 所示,其中,RMSE 表示均方根误差,Mean 表示均值,Median 表示中位数,Std 表示方差,Min 和Max 分别表示最小值和最大值。

表1 不同算法的相机绝对位姿误差对比Table 1 Absolute pose error of camera comparison among different algorithms m
从表1 可以看出,ORB-SLAM2 算法的相机位姿估计结果受动态特征的影响精度较差;利用Mobile Net 剔除动态特征的视觉SLAM 位姿估计精度有所提高;本文算法可以最大程度地保留多数静态特征点,因此获得较高精度的相机位姿估计结果。
为进一步验证该算法的位姿估计精度,本文在TUM RGB-D 数据集上完成实验并与MR-SLAM[19]算法、基于光流(Optical Flow)的动态SLAM(OFDSLAM)[29]算法、ORB-SLAM2 算法、Dyna-SLAM[37]算法和DS-SLAM[40]算法分别比较相机绝对位姿估计的均方根误差。在数据集序列中不同算法的均方根误差对比如表2 所示,其中“—”表示该算法没有提供对应的数据。从表2 可以看出,在8 个实验数据序列中,本文算法的相机位姿估计精度相对于ORB-SLAM2 和OFD-SLAM 算法都有很大的提升。与其他动态SLAM 算法的实验结果对比,本文算法在5 组数据集上表现更优,在剩余的3 组数据集中获取次优结果。
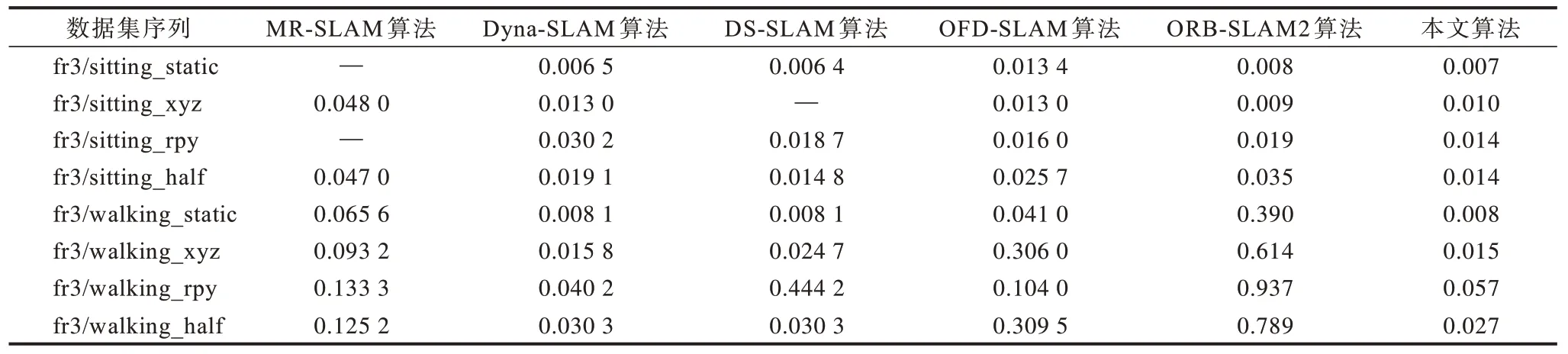
表2 在数据集序列中不同算法的均方根误差对比Table 2 Root mean square error comparison among different algorithms on data set sequence m
不同算法的相机绝对轨迹误差如图9 所示(彩色效果见《计算机工程》官网HTML 版),红色线表示相机轨迹真实值和估计值之间的差,黑色实线表示相机轨迹真实值,蓝色实线表示相机轨迹估计值。从表2 和图9 可以看出,ORB-SLAM2 和OFD-SLAM算法在低动态场景下轨迹误差相对较小,在高动态场景下相机绝对轨迹误差较大并且OFD-SLAM 算法容易丢帧。由于ORB-SLAM2 算法不能区分场景中静态和动态特征,高动态场景中受动态特征影响易导致精度退化。由于相机存在运动,在高动态场景下光流往往不能较准确地区分动态和静态特征,从而导致相机位姿估计精度退化。相比其他经典的动态SLAM 算法,本文算法能够最大程度地保留静态特征点,获取相对绝对误差较优的定位结果。因此,本文算法在低动态场景和高动态场景均能表现较优的准确性和鲁棒性。
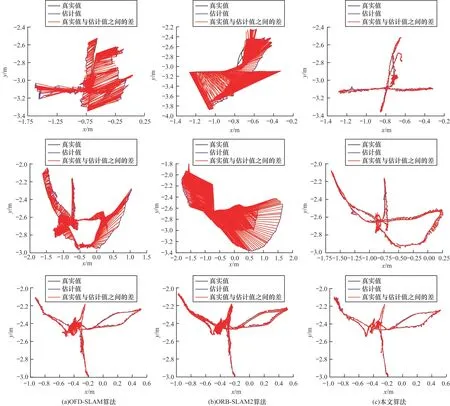
图9 在TUM 数据集上不同算法的相机绝对轨迹误差对比Fig.9 Absolute trajectory error of camera comparison among different algorithms on TUM dataset
本文使用RGB-D 相机(X-Tion)在实际的动态场景中进行验证测试,在场景中存在移动人员的情况下,通过RGB-D 相机连续采集图像进行实验,同时利用实时跟踪设备记录相机真实的运行轨迹[41]。本文完成实际动态场景实验并与ORB-SLAM2、OFD-SLAM 算法进行对比。在实际场景中不同算法的相机绝对位姿误差如表3 所示,在实际场景中不同算法的相机绝对轨迹误差如图10 所示(彩色效果见《计算机工程》官网HTML 版),红色线表示相机轨迹真实值和估计值之间的差,黑色实线表示相机轨迹真实值,蓝色实线表示相机轨迹估计值,方框表示相机存在跟踪丢帧现象。ORB-SLAM2 算法不需要识别动态特征点,跟踪一帧时间约0.032 s;OFD-SLAM算法需要识别动态特征,跟踪一帧时间为0.062 s。本文算法基于K-Means 聚类和深度学习需要耗费大量的运算时间,跟踪一帧时间约为0.680 s,与本文实验使用的硬件配置也有一定的关系。
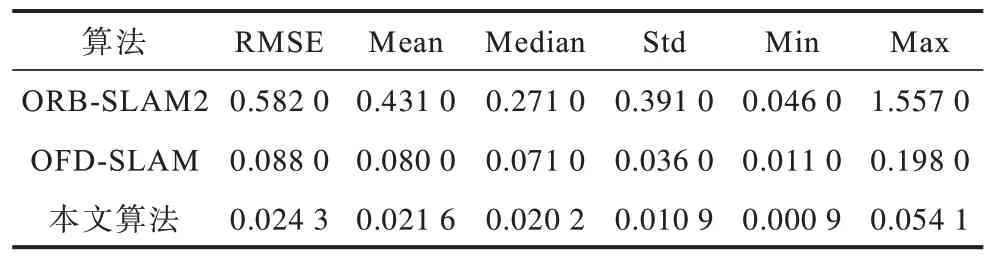
表3 在实际场景中不同算法的相机绝对位姿误差对比Table 3 Absolute pose error of camera comparison among different algorithms in actual scenario m
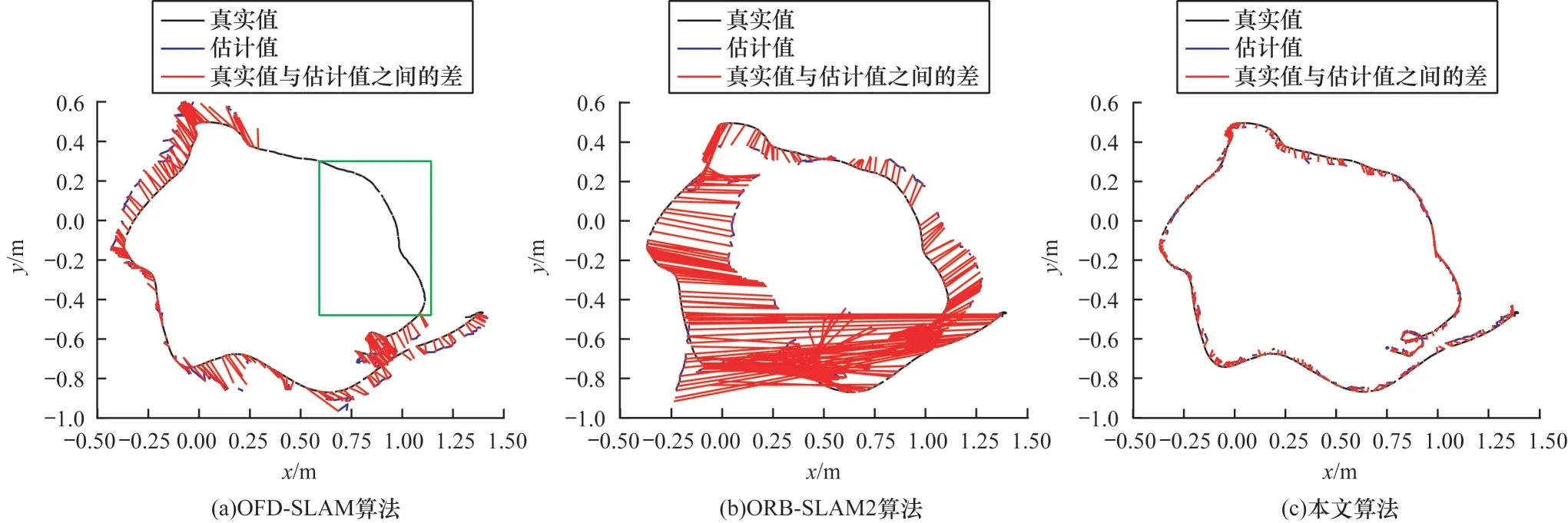
图10 在实际场景中不同算法的相机绝对轨迹误差对比Fig.10 Absolute trajectory error of camera comparison among different algorithms in actual scenario
4 结束语
本文提出一种结合深度学习和K-Means 聚类的目标检测算法RGB-SLAM,通过对动态特征点和静态特征点进行分类处理,以减少动态特征点对相机位姿跟踪产生的误差。实验结果表明,本文算法能够有效提高检测精度,其相机绝对位姿估计性能优于ORB-SLAM2 和OFD-SLAM 算法。后续将通过提取点线特征处理动态场景区域,进一步提高相机位姿估计的准确性和鲁棒性。
猜你喜欢
北京航空航天大学学报(2021年9期)2021-11-02 08:24:26
北京航空航天大学学报(2021年6期)2021-07-20 07:24:00
电子制作(2019年11期)2019-07-04 00:34:38
北京航空航天大学学报(2018年1期)2018-04-20 06:38:17
光学精密工程(2016年5期)2016-11-07 09:05:55
光学精密工程(2016年4期)2016-11-07 09:05:11
湖北工业大学学报(2016年5期)2016-02-27 13:14:48
机电信息(2015年9期)2015-02-27 15:55:56
电子设计工程(2015年15期)2015-02-27 12:07:33
电视技术(2014年19期)2014-03-11 15:38:20
