
深度学习方法在兴趣点推荐中的应用研究综述
2022-01-14 03:01:46汤佳欣周孟莹
计算机工程 2022年1期
汤佳欣,陈 阳,周孟莹,王 新
(1.复旦大学计算机科学技术学院,上海 201203;2.复旦大学上海市智能信息处理重点实验室,上海 201203)
0 概述
智能手机的普及以及全球定位系统的发展促进了基于位置的社交网络(Location-Based Social Network,LBSN)的进步,如Foursquare、Yelp、Instagram、大众点评等社交网络得到广泛关注与应用。兴趣点(Point of Interest,POI)推荐是LBSN 提供的一项重要服务,其一方面可以方便用户规划行程、快速发现感兴趣的兴趣点,另一方面也可以帮助兴趣点服务提供商和广告商更全面深入地了解用户偏好,从而发掘更准确的市场目标群体并引入更有针对性的广告策略来吸引用户。
LBSN 中包含大量用户和兴趣点信息,能够为挖掘用户偏好提供支撑。在一个典型的LBSN 中,用户可以通过在兴趣点签到以记录其行程,一次签到(Checkin)可以用一个“<用户,兴趣点,时间戳>”三元组表示。一个用户的多次签到记录可以根据时间戳排序构成其签到序列,即用户轨迹。签到记录直接反映了用户对兴趣点的偏好。此外,用户还可以在LBSN 中发表对兴趣点的评价、上传照片、关注其他用户并分享他们对于兴趣点的感受、与其他用户之间形成社交好友关系等,上述内容信息和社交关系信息也隐含了用户偏好。因此,兴趣点推荐服务的实现可以依托于从LBSN 的丰富信息中挖掘出的用户偏好。
传统推荐系统中的一些经典方法可以直接应用于兴趣点推荐任务,其中,使用最广泛的是基于矩阵分解的方法[1-2],其通过分解“用户-兴趣点”签到矩阵获取表征用户和兴趣点关联的低维隐特征,但该方法没有考虑用户签到序列特征。另一类方法将签到序列抽象为Markov 链[3-5],仅根据上一次签到来决定下一次签到的推荐,而没有考虑更早期的历史签到中所体现的用户偏好信息对下一次签到的影响。此外,上述2 类方法都只使用了用户签到数据,LBSN中的其他信息没有得到充分有效地利用。随着人工智能技术的快速发展,深度学习已被证实可以有效地从大量数据中学习隐藏信息并预测未来状态。相比于传统的机器学习算法,深度学习可以通过模型自动化从数据中提取并处理特征。将深度学习应用于兴趣点推荐系统可以充分利用系统中丰富的特征并挖掘特征之间的复杂关联关系。
近年来,兴趣点推荐问题已得到广泛研究,现有一些代表性的研究综述[6-8]根据推荐目标将兴趣点推荐分为用户通用兴趣点推荐和用户下一个兴趣点推荐;根据用户偏好的主要影响因素将其分为地理因素、时间因素、社交因素和内容因素所主导的兴趣点推荐系统;根据使用的数据种类将其分为基于用户位置、轨迹、活动等兴趣点推荐系统。不同于上述综述对兴趣点推荐问题中涉及的要素进行分类,本文聚焦于该问题本身以及深度学习方法在该领域的应用,总结时空序列特征提取方法、内容社交特征提取方法、多特征整合方法以及无签到用户兴趣点信息处理方法在解决兴趣点推荐问题时的优势和不足,从特征提取和深度学习方法的角度对兴趣点推荐领域的现状进行总结并探索未来的研究方向。
1 兴趣点推荐问题
兴趣点推荐需要根据LBSN 中的大量相关信息对用户偏好进行总结和刻画,从而给出个性化的兴趣点推荐。针对兴趣点推荐系统的特性,本文将其所面临的挑战总结为以下4 个方面:
1)如何从签到数据中提取时空序列特征。用户的历史签到序列是LBSN 中用户对兴趣点偏好最直观的体现,与传统的“用户-商品”矩阵相比,签到序列包含了上下文时空信息,充分挖掘其时空序列特征可以有效改善用户偏好建模效果。
2)如何充分利用LBSN 中的信息。除了用户签到序列,LBSN 中还包含大量用户生成内容(User-Generated Content,UGC)和社交关系信息,如用户发布的关于某个兴趣点的照片评论、用户之间的关注关系等,这些信息能够反映用户的关注点和兴趣偏好,同时也隐含了兴趣点的特征,因此,可以被用来进一步改善兴趣点推荐的效果。
3)如何综合多特征的影响来实现兴趣点推荐。兴趣点推荐系统中包含大量体现用户偏好的特征,从特征对象的角度可以分为用户特征、兴趣点特征和外部环境特征;从用户偏好主要影响因素的角度可以分为时空因素、内容因素、社交关系因素等。一个有效且有拓展性的模型需要综合考虑这些特征的共同影响以实现个性化的兴趣点推荐。
4)如何处理“用户-兴趣点”签到矩阵的稀疏性问题。虽然LBSN 被广泛使用,但单个用户访问过的兴趣点数量相比于全部兴趣点而言是极少的。此外,对于新用户和新注册的兴趣点而言,LBSN 中关于它们的历史签到信息较少。基于以上原因,“用户-兴趣点”签到矩阵具有较强的稀疏性,如何挖掘有限的历史签到数据、利用没有历史签到的用户兴趣点本身的特性,以在一定程度上缓解数据稀疏性问题是许多研究工作关注的焦点。
基于上述分析,本文从时空序列特征提取、内容社交特征提取、多特征整合、无签到用户兴趣点处理4 个方面,对使用深度学习解决这些问题时的背景和方法进行分析和总结,具体内容如图1 所示。
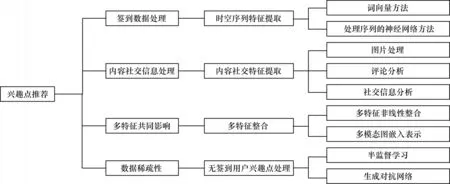
图1 应用于兴趣点推荐中的深度学习方法分类Fig.1 Classification of deep learning methods applied to POI recommendation
2 时空序列特征提取
用户的历史签到数据是LBSN 中反映用户对兴趣点偏好最直观的信息,用户签到包括其访问的兴趣点和时间戳,用户偏好受到时空特征的限制和影响,例如:由于营业时间限制,一些兴趣点只会在特定的时间段被访问。此外,根据地理学第一定律[9]可知,兴趣点之间的距离远近在一定程度上决定了它们之间的关联紧密程度。同时,签到序列往往具有一些序列特征,如某些兴趣点之间访问的连续性、用户偏好的一致性、用户行为的周期性等。推荐系统中传统的矩阵分解方法没有考虑签到数据的时空序列特征,文献[10-12]试图使用传统统计和概率学的方法对矩阵分解方法进行改进,如最小化连续2 次访问的用户向量差[10]、最小化候选兴趣点向量与用户历史访问过的兴趣点向量之差[11]等。但是这些改进只能启发式地描述签到序列的一些显式宏观特征,用户签到数据中隐含的特征和联系依然很难被充分挖掘和利用。
近年来,随着自然语言处理技术的快速发展以及处理序列的神经网络模型的广泛使用,深度学习方法被证实在处理序列数据上具有很大优势,通过对循环神经元结构的改造、“门”的设计以及注意力机制的运用,这类方法可以有效地在序列数据中刻画复杂的上下文特征并捕捉用户的长短期偏好,因此,可以将其应用于LBSN 中包含时空信息的签到序列特征提取。本文主要总结归纳2 类时空序列特征提取方法:第一类方法使用自然语言处理中获取词向量的方法来处理兴趣点序列,这类方法更加关注局部的序列特性,即某些兴趣点常在短期内被同一用户访问的模式,使这些兴趣点拥有相近的隐特征向量,在推荐时根据隐特征向量给出符合用户历史偏好的兴趣点;第二类方法使用一些常用的处理序列的神经网络模块,如循环神经网络(Recurrent Neural Network,RNN)、注意力机制等,这类方法相比于第一类方法可以获取历史兴趣点序列的长期特征即用户的长期偏好,以及兴趣点被访问的前后关系特征,并充分挖掘利用兴趣点签到的相关上下文信息,如兴趣点地理位置、签到时间等,因此,该类方法应用更加广泛。
2.1 词向量获取方法
为获取签到序列的序列特征,兴趣点推荐系统需要挖掘兴趣点之间的潜在关联,一类常见的方式是借鉴自然语言处理中获取词向量的方法,将每个兴趣点类比为一个单词,将用户历史签到的兴趣点序列看作句子,最终刻画用户的兴趣点访问模式可以被转化为提取句子的语义特征。常用的词向量获取方法Word2vec 模型[13]分为2 种实现方式,即Skipgram 和CBOW(Continuous Bag-of-Words):Skip-gram根据当前的词来预测其周围的词;CBOW 根据周围的词来预测当前的词。这2 种模型均可应用于兴趣点推荐。
文献[14]利用Skip-gram 对用户的签到兴趣点序列进行建模,以获取每个兴趣点的隐特征,Skipgram 在兴趣点推荐中的目标方程是最大化兴趣点上下文(历史数据中曾经在某个兴趣点前后被访问的兴趣点)和该兴趣点同时出现的概率,该方法在推荐前10 个兴趣点时的准确率,比利用非一致性和连续性的特征来改进矩阵分解的算法[10]提高约0.03。文献[15]对上述方法进行进一步优化,将用户每一天的签到序列看作一个单独的句子,并对兴趣点在工作日和周末的签到进行区分。文献[16]使用CBOW,根据兴趣点序列获取兴趣点特征表示。
2.2 神经网络方法
将用户的兴趣点序列类比为句子,在使用词向量获取方法从用户签到序列中提取兴趣点特征表示时,仅考虑兴趣点短期被同一用户访问的情况,而没有考虑兴趣点之间更复杂的关联关系,签到数据的具体地理位置信息和时间戳信息没有得到充分利用。为了更加深入地挖掘带时空上下文的序列特征,一些处理序列的神经网络模块被应用于兴趣点推荐任务,具体情况总结如表1 所示。

表1 处理兴趣点序列的神经网络方法总结Table 1 Summary of neural network methods for processing POI sequences
循环神经网络[29]是处理带丰富上下文信息的序列数据的有效方法,将基于循环神经网络的方法引入兴趣点推荐可以有效地从签到序列中提取时空序列特征。由于传统的循环神经网络在刻画用户长期偏好时存在梯度消失的问题,因此基于长短期记忆(Long Short-Term Memory,LSTM)[30]网络的方法在相关工作中被广泛使用,其可以有效地刻画用户的长短期偏好。文献[17]引入兴趣点类别的概念并利用2 个长短期记忆网络编码器分别提取用户签到的兴趣点类别序列和具体兴趣点序列的时间特征,根据兴趣点类别特征进行初步筛选后根据每个兴趣点的特征和用户特征来实现推荐,通过刻画不同层次的序列特征能够有效减小推荐的搜索空间并提高兴趣点推荐的准确性。
传统循环神经网络和长短期记忆网络仅考虑兴趣点之间的顺序关系而没有考虑复杂上下文信息,如时间信息和地理信息。以最简单的循环神经网络为例,在tk时刻神经元输出的隐向量为:
htk=f(Mxtk+Chtk-1)
其中:xtk为tk时刻的输入,即tk时刻签到的兴趣点特征;htk-1为tk-1时刻神经元的输出;M表示转移矩阵。这种神经网络结构具有较强的可拓展性,可以通过对循环的神经元(即Mxtk+Chtk-1部分)进行改进以融入时空特征,因此,文献[18-19]改进了上述传统的循环神经网络模型,以挖掘签到序列时空上下文之间的序列特征。ST-RNN[18]是一种典型的结合了时空上下文特征的循环神经网络模型,其将循环神经网络中的转移矩阵M替换为与时间、地理距离有关的转移矩阵的乘积,与时间相关的矩阵可以描述近期历史的影响同时考虑时间间隔,与距离相关的矩阵可以获取用户签到行为的地理特征。相比于原始的循环神经网络模型,ST-RNN 在Gowalla 数据集上AUC 值[31]提高了约0.03。文献[20-22]对长短期记忆网络进行改进,文献[20]中作者认为连续签到之间的关联性大小会随着时间间隔和地理距离的增大而减小,而这种关联性对于用户短期偏好的影响较大,因此,他们将长短期记忆网络中的细胞(cell)状态拆分为短期状态和长期状态,利用关于时间间隔和距离的衰减函数对每次签到的短期状态进行修正,与ST-RNN 相比,该模型在Gowalla 数据集上的推荐准确率又提升了约0.02。
上述研究通过改进循环神经网络的循环神经元使得其更加适应于兴趣点推荐系统中时空序列特征的处理,但这类方法的缺点在于循环神经元无法有区别地处理签到序列中不同的签到,而事实上历史签到对未来签到的影响并不完全随着时间间隔的增大而衰减。注意力机制是另一类处理序列的神经网络方法,可提取兴趣点序列的时空特征。从地理位置来看,每一对兴趣点之间的影响力大小不同。文献[27]提出一种地理注意力网络来刻画兴趣点之间基于位置的关系,考虑2 个兴趣点之间的距离以及他们各自的地理属性——地理影响力(即该兴趣点引导用户去其他兴趣点的能力)和地理被影响力(即该兴趣点吸引其他兴趣点的访客的能力),使用候选兴趣点的地理被影响力作为注意力机制中的查询(Query)、该用户历史访问过的兴趣点的地理影响力作为键(Key),影响力系数根据2 个兴趣点之间的距离使用RBF 核获得,最终计算出注意力权重,模型输出的对于候选兴趣点的用户偏好为历史兴趣点地理影响力的加权求和。地理注意力网络使得模型的推荐性能在Foursquare 和Gowalla 数据集上均获得了较大提升。
在处理时序特征时,注意力机制一般与循环神经网络或长短期记忆网络一起使用,一类方法是使用后者获取每次签到的隐特征,再利用注意力机制加权聚合签到序列中多次签到的隐特征;另一类方法则并行使用这2 种方法以从多维度提取签到序列的特征。文献[23]为推荐下一次签到的兴趣点,先将用户签到序列(将候选兴趣点和推荐时间作为序列的最后一个节点)中每一次签到的兴趣点特征和时空上下文特征输入长短期记忆网络以获取其隐特征,由于每个历史签到对未来签到兴趣点预测的贡献程度不同,因此该文再利用注意力机制根据历史签到的隐特征和候选兴趣点的隐特征计算注意力权重加权的决策向量,基于此向量来预测该候选兴趣点被访问的概率,访问概率最高的候选兴趣点将作为推荐结果。文献[24]提出一种基于长短期记忆网络模块的编码器-解码器模型,以预测下一个被访问的兴趣点,其中,编码器中的长短期记忆网络被用来获取签到序列中每个签到兴趣点的隐特征,解码器同样利用长短期记忆网络根据编码器的结果进一步挖掘签到兴趣点特征,时间注意力机制根据编码器输出的历史签到的隐特征和解码器计算的候选兴趣点特征来计算注意力权重,考虑历史签到与候选兴趣点之间不同大小的相关性来获取更准确的候选兴趣点特征并进行推荐预测。不同于上述2 个研究工作,文献[25]并行地使用注意力机制和长短期记忆网络来共同刻画用户偏好的整体特征,该文认为用户签到行为从短期来看往往呈现出一定的连续性和一致性,长短期记忆网络适用于建模用户签到的序列行为以获取用户的短期偏好;而从长期来看,用户偏好在不同的情景和位置下往往具有非一致性,注意力机制可以更有效地刻画用户的整体长期偏好。为了刻画用户偏好在一天中具体时间段的特征,文献[17]区分工作日和周末,并根据签到的分布密度将一天分为12 个时间窗口,该文将长短期记忆网络输出的兴趣点隐特征划分到不同的时间窗口中,并利用用户和窗口中兴趣点的隐特征的相关性计算每个时间窗口的注意力权重,实验结果表明,该方法大幅提升了兴趣点推荐的准确性。
上述相关工作都是针对用户的单个签到序列进行分析并预测下一个签到兴趣点,文献[26]对多条用户签到轨迹进行分析并利用签到轨迹之间的相关性预测当前轨迹的下一个兴趣点,该文设计基于历史的注意力机制模块,通过计算历史轨迹和当前轨迹之间的相关性即注意力权重,以获取最相关的上下文向量并进行兴趣点推荐,该模型相比单序列模型可以更有效地挖掘用户签到轨迹的多层次周期性和复杂连续性特征。
为综合考虑签到序列的时空特征,文献[28]提出一种基于自编码器(Autoencoder,AE)的模型,使用基于自注意力机制的编码器从签到兴趣点中提取时间特征,再利用地理距离因素与序列连续性相结合的解码器来处理地理位置信息。
2.3 相关工作的不足
时空特征是兴趣点推荐系统中最重要的特征之一,目前大多数关于兴趣点推荐和位置预测的研究都聚焦于时空特征的提取和分析。大部分的现有工作侧重于利用深度学习模型提取时间序列特征,尽管一些学者引入了时间影响力和时间间隔的概念,但具体的时间点特征目前还没有被充分挖掘。例如,用户更倾向于在某些特定日期访问某些兴趣点,或某些兴趣点只在某些特定的时间段可被访问,粗粒度的时间窗口无法描述这些特征。与时间相关的用户访问模式,如多层次的周期性和一致性特征有待进一步挖掘。
此外,上述相关工作多是对单个用户的签到序列进行建模,尽管每个单序列中都包含了丰富的时空序列特征,但序列之间关系的挖掘和利用可以进一步提升用户偏好预测的效果,目前该方面的研究工作较少。由于存在某些相同或相近的兴趣点,不同序列可以联合进行时空特征提取,通过多序列特征提取来获取更加全面的时空序列特征。
3 内容社交特征提取
除了用户签到数据,LBSN 中还包含大量用户生成内容和社交关系信息,如用户评论、照片、用户之间的社交关系等,这些信息也能够反映用户的偏好和兴趣点的特征,在数据集中包含这类辅助信息时,充分利用这些信息可以有效提升兴趣点推荐的效果。
根据用户评论可以分析出用户访问某个兴趣点时的感受和情绪,用户上传的照片不仅可以反映其关注点和偏好,还可以提供更多关于兴趣点的信息。此外,由于这些数据都是公开可见的,它们也会影响其他用户对该兴趣点的预期,进而影响用户是否会选择访问该兴趣点,因此,在进行兴趣点推荐时需要考虑评论、照片等用户生成内容中包含的语义特征。
根据社交网络中的同质性(Homogeneity)[32],用户的社交关系往往也可以反映用户的偏好,好友之间的偏好存在一定的相似性,好友的评论和信息反馈相比其他陌生用户更能影响用户的偏好,因此,社交关系特征也是兴趣点推荐中需要考虑的重要因素。
本文对LBSN 中除了签到序列以外的其他信息以及利用这些信息进行兴趣点推荐的工作进行总结,具体如表2 所示。

表2 LBSN 中的内容社交信息提取方法Table 2 Methods of content social information extraction in LBSN
3.1 图片处理
卷积神经网络(Convolutional Neural Networks,CNN)[41]近年来被广泛应用于计算机视觉和自然语言处理领域以进行图片和文本分析处理。文献[33]通过Instagram API 获取了Instagram 中大量用户发布的图片数据,为了提升兴趣点推荐的准确性,该文提出了VPOI 模型,利用这些视觉内容即照片信息辅助推荐,作者认为用户发布的照片的视觉特征符合该用户的偏好,关于某个兴趣点的照片也反映了该兴趣点的特征,因此,可以利用照片的视觉特征指导用户、兴趣点的隐特征学习,该文使用经典的图片分类模型VGG16[42]获取每张照片的图嵌入(embedding),并将上述思想与概率矩阵分解的目标方程相结合,实验结果表明,该模型的准确性相比原始概率矩阵分解方法有较大提升。文献[34]同样使用了卷积神经网络来提取LBSN 中的图片内容。
图片是某些LBSN 中用户分享内容的重要媒介,但目前在兴趣点推荐中应用计算机视觉技术来处理图片信息的相关工作较少,一方面是由于大多数LBSN 数据集中图片数据较少,另一方面原因是用户的偏好基本体现在用户的签到行为中,图片包含的额外信息可能较少。
3.2 评论分析
用户的评论体现了其对某个兴趣点的偏好程度,也是对推荐效果的直接反馈。传统的兴趣点推荐系统中用户历史偏好主要通过签到矩阵体现,签到行为是一种对兴趣点的二元选择(访问或不访问),不能反映用户对兴趣点的具体偏好程度,此外,用户对兴趣点发表的负面评论可能比未访问过该兴趣点所反映的偏好程度更低。LBSN 中Foursquare包含丰富的评论信息,以下利用评论内容辅助进行兴趣点推荐的相关工作均基于Foursquare 数据完成。相关工作中对于用户评论的挖掘大多集中在情感分析和主题分析上,最简单的情感倾向估计方法是根据评论中的形容词计算情感分数[43]或计算评论中的词汇与强烈情感词(如excellent、cool、bad 等)的相似性[44],但这种方法在处理否定句式时存在无法准确判断出情感倾向的可能,并且无法处理描述性的评论。另一部分工作使用主题模型,即LDA(Latent Dirichlet Allocation)模型[45]来估计评论的隐含主题[46],这类方法更适用于描述性的评论,但没有考虑情感因素。为了综合分析评论的内容,文献[35-37]引入深度学习卷积神经网络模型来挖掘用户评论辅助兴趣点推荐,文献[35]利用Text-CNN 模型[47]对评论进行内容情感信息提取,计算用户对兴趣点的情感嵌入,使用该嵌入来调整用户兴趣点偏好分数,并根据该分数排序给出推荐结果,其有效地提高了兴趣点推荐的准确性。
3.3 社交关系信息利用
LBSN 是一种特殊的社交网络,用户之间可以建立关注等社交关系,也可以由地理位置的相关性而形成地理邻居社交关系,最终构成用户社交关系图,有社交关系的用户之间的偏好可能会互相影响。文献[38]利用社交关系信息来提高兴趣点推荐性能,该文为每个用户构建社交签到图,图中的节点表示该用户、其好友用户以及他们签到过的兴趣点,利用图上的随机游走可以获取该用户历史未访问过但好友访问过的潜在兴趣点集合,转移矩阵中的概率取决于2 个用户之间的相似度和2 个兴趣点之间的关联度(即兴趣点之间的距离),最终稳态时可获得用户的潜在兴趣点。该文认为相比没有被注意到的兴趣点,用户更倾向于访问这些潜在兴趣点。
图片和评论数据受限于数据源,即只有某些特定的LBSN 才提供这些特殊类型的数据。大多数LBSN 数据集中都包含丰富的社交信息,对于社交信息的利用主要受限于社交关系本身对于用户签到行为偏好的影响程度。由于用户的兴趣点访问模式受时空等物理因素的限制,社交关系对其的影响比传统社交网络小,社交关系信息更多时候作为兴趣点推荐系统实体关系异构图中用户节点之间的边或应用于半监督学习中的无监督部分。
3.4 相关工作的不足
在兴趣点推荐中对于内容社交信息的利用和特征提取,一方面受限于可获取的公开数据源较少,常用的公开数据集均没有同时包含这些类型的信息;另一方面,相比于时空类型的数据分析和特征提取,目前在兴趣点推荐这种特定场景下的计算机视觉和自然语言处理的应用研究较少。从研究内容的角度来看,现有的对LBSN 中用户评论的分析多数局限于情感和主题分析,而写作风格和语义信息没有得到充分利用,这些信息不仅隐含用户性格等特征,往往还直接反映兴趣点的优劣,充分挖掘这些信息可以促进兴趣点推荐系统更全面地刻画用户和兴趣点的特点,获得更准确的用户、兴趣点隐特征,进而提升推荐效果;从模型方法的角度来看,目前已有研究只利用了一些经典的图片和文本分类模型方法,更多的深度学习方法,如双向长短时记忆网络与多层注意力网络的结合[48]、双向长短时记忆网络与条件随机场(Conditional Random Field,CRF)的结合[49]等,尚未被用于LBSN 中的内容特征提取。
4 多特征整合
从LBSN 中的历史签到、用户生成内容、用户社交关系信息等数据中可以提取出丰富的特征,用户对于兴趣点的偏好受这些特征共同影响。从对象的角度,这些特征可以分为用户特征、兴趣点特征、外部环境特征;从影响因素的角度,这些特征可以分为时空特征、序列特征、内容语义特征、社交关系特征等。传统的协同过滤方法使用矩阵分解来获取用户和兴趣点的隐特征向量,这种方法将用户和兴趣点之间的关系刻画为隐特征之间的内积关系,缺陷在于其要求用户和兴趣点的隐特征具有相同的维度,限制了用户兴趣点特征提取的效果。此外,线性运算无法全面地刻画用户和兴趣点之间的复杂关联关系,难以建模多特征的共同影响。
神经元中非线性激活函数的设计以及神经元之间的网络结构,使得神经网络模型可以刻画输入和输出之间的复杂非线性关联关系,因此,可以将其用于兴趣点推荐中的多特征整合过程。此外,LBSN 中各个实体(如用户、兴趣点等)之间存在不同类型的关系,构建多实体关系图并使用图嵌入的方法,可以在特征整合的过程中有效保留不同实体之间的不同关系结构特征。
4.1 多特征的非线性整合
整合不同特征时需要挖掘不同特征之间的线性及非线性关联,其中,线性关联可通过简单的内积方法获取,而非线性关联通常利用不同的神经网络模块提取,最终通过构建神经网络模型来结合线性与非线性关联并获取不同特征共同作用的结果。文献[50]提出基于神经网络的协同过滤模型,其根据用户和兴趣点的特征计算兴趣点推荐分数,该模型将用户特征和兴趣点特征相联合,利用多层感知机(Multi-Layer Perceptron,MLP)[51]提取它们之间的非线性关系,同时并行地使用一个广义的矩阵分解模块获取其线性关联,将两者的结果相结合计算得到最终的分数。类似地,文献[52]使用深度信念网络(Deep Belief Networks,DBN)[53]作为一个确定性函数来提取多特征连结的深层表示。
尽管多层感知机和深度信念网络可以有效提取特征之间的非线性关联,但它们的可解释性较差,无法获取不同特征对用户偏好的贡献程度。为了实现可解释的特征整合,文献[24]使用基于注意力机制的方法,通过分配不同的注意力权重,使得更重要的特征可以对用户偏好预测作出更大贡献,其模型包括两级注意力模块,其中,宏观上下文注意力度量不同特征的重要程度,微观上下文注意力分配权重给隐向量中的每个值。
无论是多层感知机、深度信念网络还是注意力机制,它们的优势均在于神经网络结构和非线性激活函数的使用,从而可以对特征之间的非线性关联进行充分挖掘,在应用时根据具体的场景要求选择具体方法,其中,在对可解释性要求较高的场景中使用注意力机制。
4.2 多模态的图嵌入表示
图结构是表示兴趣点推荐系统中不同实体之间复杂关系的有效方式,利用图结构对不同类型的特征进行整合也是兴趣点推荐中一种常用的方法。表3 所示为在兴趣点推荐系统中使用图嵌入表示以整合特征的方法总结。

表3 兴趣点推荐中的图嵌入方法总结Table 3 Summary of graph embedding methods in POI recommendation
图2 所示的异构图是LBSN 中一种典型的图表示,图中包括4 种类型的节点,即用户节点、兴趣点节点、时间戳节点、活动节点。节点之间的边具有不同的含义,用户节点之间的边表示社交关系,兴趣点之间的边表示地理邻居关系或连续访问的关系,签到信息也使用边表示,即一条连接一个用户、兴趣点、时间戳和活动的超边表示一次签到。根据图的整体结构特征和图中每个点自身的特征计算不同类型节点的嵌入,是另一种整合不同特征的方法。
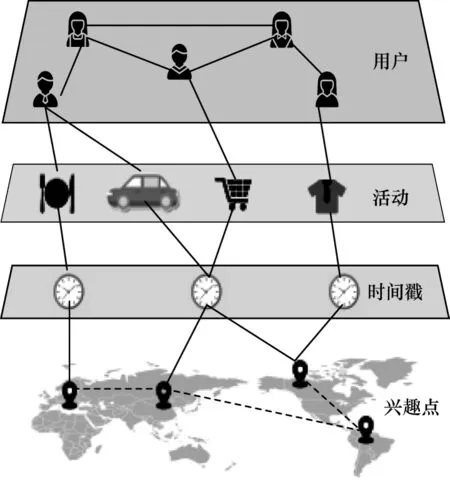
图2 LBSN 的异构图表示Fig.2 Heterogeneous graph representation of LBSN
由于图2 的结构较复杂,一些相关工作从图2 中提取不同的子图,如用户社交关系图、兴趣点邻居关系图等,分别计算这些相对较简单的图中节点的嵌入再进行相加以得到不同类型节点的最终嵌入。文献[39]提出一种图注意力机制,其结合用户社交关系图、兴趣点邻居图(一个兴趣点与其地理位置最近的k个兴趣点之间有边相连)和“用户-兴趣点”签到关系图中的上下文信息,该文认为用户的朋友对该用户的影响力大小与用户自身的特征以及朋友关系特征相关,同时,针对不同的兴趣点,朋友对用户的影响力也不同,因此,模型根据用户自身的特征、候选兴趣点的特征以及用户社交关系图中其朋友的关系特征,计算不同朋友节点的注意力权重并获得该用户的社交特征嵌入。在兴趣点邻居关系图中,对于每个兴趣点,模型根据该兴趣点与邻居兴趣点之间的距离、目标用户的特征以及邻居关系特征,计算注意力权重并获得该兴趣点的邻居特征嵌入。模型中还包括一种双重注意力网络模块,其在“用户-兴趣点”签到关系图中综合考虑用户和兴趣点的访问模式,计算不同兴趣点对用户访问特征的注意力权重和不同用户对兴趣点访问特征的注意力权重,分别获得用户和兴趣点的访问特征嵌入。最终的用户嵌入为用户自身特征嵌入、用户社交特征嵌入和用户访问特征嵌入之和,兴趣点嵌入为兴趣点本身特征嵌入、兴趣点邻居特征嵌入和兴趣点访问特征嵌入之和。这种图注意力机制的提出使得模型推荐命中率在多个数据集上均获得了提升。文献[54]设计一种基于图神经网络(Graph Neural Network,GNN)的图自编码器,以挖掘兴趣点访问和地理关系图,其结合邻居兴趣点的特征获得每个兴趣点的最终出特征和入特征,多层图神经网络的使用可以捕捉到兴趣点之间的高阶非线性关联关系。进一步地,其利用图神经网络从“用户-兴趣点”访问图中根据兴趣点出特征计算出用户的最终隐特征表示,根据用户隐特征和候选兴趣点入特征完成推荐。
上述工作在多个子图中对特征进行多步图嵌入计算,在一定程度上可以实现多实体特征整合,但无法充分挖掘LBSN 实体异构图的整体特征。另一类工作直接在整体异构图中计算图嵌入,克服了前者的缺陷。文献[56]基于图卷积网络(Graph Convolutional Network,GCN)[60]设计一种时空感知的多层次图嵌入方法,对于不同类型的边使用不同的转移矩阵进行信息传播,并使用多层网络进行信息聚合。此外,还通过改进随机游走的采样方法以处理多实体异构图。文献[57]为用户-兴趣点、兴趣点之间、用户之间这3 种边分别设计3 种转移概率。文献[58]针对图2 设计一种带停留的随机游走机制,除了根据社交关系在用户之间游走采样之外,还会在某个用户节点停留以采样该用户的签到信息,通过不断迭代最终获得每个点的嵌入从而完成兴趣点推荐。
近年来,知识图嵌入方法[61]逐渐成熟,文献[59]使用知识图的结构来刻画兴趣点推荐系统中的复杂关系,模型认为下一个签到兴趣点是由用户及其所处的时间、地点共同决定的,因此,将一个时间戳和一个地点组合成一个时空上下文“
4.3 相关工作的不足
现有工作对多个特征进行整合后可以较准确地刻画用户的偏好并进行推荐,但特征对于推荐结果作用的可解释性目前还未得到充分重视,只有明确每个特征对于推荐结果的贡献,兴趣点提供商才能更有针对性地改进服务以吸引用户。部分现有工作引入注意力机制,通过注意力权重在一定程度上反映各种特征的重要性,但各种特征之间的相互影响以及各个特征的变化对最终用户偏好的影响依然不够明确,相关工作缺乏对各特征的作用机制进行深入探讨。
此外,由于LBSN 中的实体类型较多,如用户、兴趣点、时间戳等,不同实体之间的关系较复杂,如社交关系、邻居关系、访问签到关系等,使用包含多种实体、多种关系的异构图的表示形式可以更有效地描述特征之间的关系,现有用于兴趣点推荐的图嵌入方法在解决规模性和异构性问题时还存在一些不足。由于LBSN 中用户和兴趣点数量在快速增长,除了硬件的提升,还需要在模型设计时考虑空间和时间资源的占用情况。在针对异构性的分析处理中,一些工作为了规避对异构图中不同关系的处理,通过提取子图的方法分别处理每种关系,但一些节点是由不同类型的边经过多跳连接的,这类方法没有充分利用节点之间的间接关联,难以全面地刻画兴趣点推荐系统中实体间关系的结构特征。另一些工作使用基于随机游走的采样方法,未考虑多个不同类型相邻节点之间影响程度不同的问题。为解决异构性问题,不同类型的边之间的相似性和关联性还有待进一步挖掘。图卷积网络在刻画每个节点特征的同时挖掘整张图的结构特征,此外也可通过设计转移矩阵来处理不同类型的节点,目前该方法在兴趣点推荐系统中运用较少,在兴趣点推荐中使用更高效的图神经网络模型,可以使LBSN 多实体异构图中的特征得到更深入地挖掘,进而提升兴趣点推荐的效果。
5 无签到用户兴趣点处理
兴趣点推荐系统一个值得关注的特征就是其兴趣点数量规模巨大,由于时间和地理位置的限制,单个用户只能访问其中很少一部分,因此,兴趣点推荐系统存在严重的数据稀疏性问题。能否有效处理正样本(历史访问过的兴趣点)和负样本(历史未访问过的兴趣点)之间的数量不平衡性,对于用户偏好建模的效果至关重要。一方面需要根据少量历史访问数据来从大量未访问过的候选兴趣点中推荐用户可能感兴趣的兴趣点;另一方面用户历史未访问过的兴趣点也可以借助其自身的地理位置信息以及LBSN 中的社交信息等进行辅助推荐。
近年来,在深度学习领域,介于监督学习和无监督学习之间的半监督学习引起研究人员的广泛关注。利用少量有标签数据和大量无标签数据,结合数据分布特征来构建模型,可以有效提升模型的准确性,同时降低训练成本,因此,半监督学习被广泛应用于有标签数据不足的场景。在兴趣点推荐系统中,历史签到数据可以被看作有标签数据,而历史未访问的兴趣点是无标签数据,虽然有标签数据量较少,但兴趣点的时空特征、用户的社交特征等分布具有一定的规律性,因此,半监督学习的思想可以被应用于兴趣点推荐任务中以缓解数据稀疏性问题。
除了直接利用用户未访问过的兴趣点的分布特征,另一种解决方案是利用生成模型从未访问的兴趣点中筛选出一些与用户历史访问兴趣点特征更相似、用户可能更感兴趣的兴趣点,即有条件的负采样(negative sampling)。传统的负采样往往是从大量负样本中随机选择的,选出的负样本和正样本在数量上属于同一数量级,从而在一定程度上减轻了数据不平衡带来的负面影响,但其无法获得更重要、更有价值的负样本。随着生成对抗网络(Generative Adversarial Networks,GAN)[62]的出现和普及,该问题得到了有效地解决,使用生成器获取更有可能被访问的兴趣点可以提升兴趣点推荐的性能。
5.1 半监督学习
为了充分利用兴趣点的地理位置信息和用户之间的社交关系以缓解数据稀疏性问题,文献[40]在模型有监督的损失函数之外又引入无监督损失部分,从而保存上下文图中的上下文信息,上下文图包括基于地理位置的兴趣点邻居图和基于好友信息的用户社交图,模型借鉴了Skip-gram 算法的思想,对于图中任意一个节点,最小化根据其嵌入预测上下文节点(图中与该点距离较近的节点)嵌入的对数损失,该方法使得拥有相同上下文的2 个节点拥有相近的嵌入。在模型的每一轮训练,先采样历史签到数据中的用户和兴趣点(即有标签数据)来训练模型的监督部分,再利用随机游走在2 个上下文图中按一定比例分别采样出一定数量的正样本和负样本,即节点和其上下文节点对、节点和其非上下文节点对,以训练模型的无监督部分。实验结果表明,相比没有无监督部分的模型,该模型在Gowalla 数据集上推荐10 个兴趣点时的命中率提高约15%。
半监督学习的核心思想是通过引入无监督损失以利用无标签数据本身的特征辅助预测用户感兴趣的兴趣点,无监督损失一般基于用户和兴趣点之间的关联所隐含的相似性和一致性特征,因此,通常需要利用4.2 节的LBSN 图表示,LBSN 本身作为一种特殊社交网络的属性,为半监督学习在其中的应用提供了基础。
5.2 生成对抗网络
除了使用半监督学习引入无监督损失,直接利用无标签数据本身的分布特征辅助兴趣点推荐之外,文献[63]提出另一种思路,即利用对抗学习模型缓解数据稀疏导致的模型欠拟合或过拟合问题并增强模型的鲁棒性,文中针对兴趣点推荐设计一种结合地理特征和生成对抗网络的对抗学习模型Geo-ALM,该模型包括一个生成器(Generator)和一个鉴别器(Discriminator):生成器的目标是从未访问过的兴趣点中筛选出与访问过的兴趣点最相似的集合,即采样出更重要的负样本;鉴别器的目标是对兴趣点进行排序,使得访问过的兴趣点排在未访问过的兴趣点之前,并使用地理特征辅助排序。在训练时,鉴别器根据排序正确的概率进行监督式训练,生成器使用强化学习中的策略梯度方法进行训练,鉴别器排序正确的概率越小,奖励越大。生成器的使用提高了鉴别器的训练速度,训练完成后的鉴别器可以根据候选兴趣点的排序结果给用户提供兴趣点推荐。实验结果表明,相比基准方法,该模型在Foursquare 数据集上推荐3 个兴趣点时准确率提高约7%。文献[64]也基于生成对抗网络架构提出一种APOIR 模型,不同于文献[63]工作,该模型直接以一种生成模型的方式学习用户的偏好,即最终的推荐结果由生成器产生,而不是由鉴别器的排序结果决定。这里的生成器可以看作推荐器,用来刻画用户偏好并推荐用户可能感兴趣的兴趣点;鉴别器则用来区分推荐的兴趣点和真实被访问过的兴趣点,其输出也可看作用户对一个输入的兴趣点的偏好程度,从而判断生成器推荐结果的准确性。在训练完成后,生成器可以基于用户偏好的分布推荐更可能被访问的兴趣点。模型训练的目标方程由2 个最优化问题组成:其一针对鉴别器,最大化辨别出的历史真实访问过的兴趣点和生成器生成的兴趣点之间的概率;另一个针对生成器,最大化生成的未访问过的兴趣点被预测为用户感兴趣的兴趣点的概率,即最小化鉴别器能分辨出生成器生成的兴趣点和真实被访问的兴趣点的概率。在Yelp 数据集上进行兴趣点推荐,相比不使用对抗学习的基准方法,APOIR模型在推荐5 个兴趣点时准确率至少提升10%。
在候选兴趣点数量较大的情况下,使用生成对抗网络可以使得生成器从大量未访问过的兴趣点中筛选出与历史访问过的兴趣点更相似的兴趣点,鉴别器也能更精确地分辨出用户感兴趣的兴趣点。相较于传统的随机负采样,生成对抗网络不仅可以在每一轮训练时使用数量尽可能平衡的正负样本,还可以使得训练样本更具针对性,从而提高训练速度。
5.3 相关工作的不足
上述现有工作对兴趣点推荐准确率的提升,验证了半监督学习和生成对抗模型可以有效缓解兴趣点推荐系统中的数据稀疏性问题,但这些工作只将这2 种思想引入兴趣点推荐任务,未对LBSN 中的其他特征进行充分利用。无监督损失和生成器是整个预测模型中相对独立的模块,可以针对各个LBSN的特点,将半监督学习、生成对抗模型与其他兴趣点推荐方法相结合,以提高模型的推荐效果。例如,基于社交和地理特征相似性的无监督损失可以与其他性能更优的监督学习模型目标方程相结合,生成对抗网络中的鉴别器也可以替换为更高效的基于排序的兴趣点推荐模型。
6 未来研究方向
根据上述分析可以得出,深度学习方法的应用可以有效解决兴趣点推荐系统中存在的问题,但是,目前兴趣点推荐的相关工作依然存在不足,未来可以针对上述4 个方面的不足进行探索。此外,除了本文总结的兴趣点推荐所存在的挑战之外,深度学习相关技术还可用于解决兴趣点推荐中一些尚未得到重视的问题,具体如下:
1)目前大多数的兴趣点推荐相关工作都着力于提高推荐的准确率,而推荐方法的时空复杂度没有得到足够重视。多数研究都是离线推荐,它们在已有的数据集上进行分析和预测,但实际运用这些推荐算法时,在线推荐是不可避免的。由于每时每刻都会有大量的用户签到数据产生,历史可用作训练的数据集的规模较大且增长较快,其中体现出的用户偏好也会不断变化,因此,需要不断更新模型以适应这种偏好变化。为在效率和有效性之间进行权衡,一种折中方案是将训练和推断模型拆分为离线和在线2 个部分,离线部分根据最近收集的数据定期重训练模型,其效率问题是可容忍的;在线部分基于最新的模型实时产生每个用户的兴趣点推荐结果,其对效率敏感,但这种方案推荐的准确率在一定程度上取决于模型的更新频率。未来可以考虑利用增量学习(incremental learning)[65]来持续性地对兴趣点推荐模型进行更新[66],增量学习不断利用新收集的数据来扩展模型知识,训练过程高效且节省资源,同时模型可以快速捕捉用户偏好的变化。
2)冷启动是兴趣点推荐的一个经典问题,预测新用户或新到访一个地区的用户的偏好是一项挑战。目前已有的兴趣点推荐方法往往需要挖掘用户的历史数据,但在一个LBSN 中新用户的相关信息较少,不足以反映他们的偏好。随着智能手机的普及以及各类应用数量的增加,用户往往会使用多个社交网络应用,即一个LBSN 中的新用户很可能是其他社交网络的老用户。因此,可以通过跨站链接(cross-site linking)[67]的方式从其他网络中获取更多用户相关数据以实现兴趣点推荐。迁移学习[68]也是一种可以被使用的技术,其根据2 个任务之间的相关性,重利用在一个任务上训练的模型去处理另一个任务。目前仅有很少一些工作[69-70]尝试使用迁移模型,根据本地用户的偏好来推断新移民或游客的偏好。在未来,一个LBSN 可以从其他LBSN 或传统社交网络中获取更多反映用户、兴趣点特征以及社交关系的信息,从而提升兴趣点推荐的效果。此外,由于时空特征是兴趣点推荐的一个重要影响因子,因此一些交通数据可以被用来辅助推荐。
3)用户的偏好是动态变化的,一个LBSN 提供的兴趣点推荐服务不是一次性的服务,兴趣点推荐取决于已知的用户偏好,但同时用户偏好的变化也会受历史推荐的影响。现有工作仅仅最优化了当前一次推荐的用户满意度而忽视了本次推荐对未来用户偏好的影响。强化学习[71]可以被引入兴趣点推荐以建模用户偏好的动态特征,该方法已被广泛应用于其他推荐系统,如商品推荐[72]、新闻推荐[73],其主要思路是将推荐系统看作一种追求用户效用(即奖励)最大的策略,每次推荐根据当前状态计算出最优的动作,即推荐的兴趣点,再根据该行为进行状态转化,最终目标是最大化用户访问的兴趣点序列的效用之和,进而提高综合推荐效果。对于具体强化学习方法的选择,由于用户状态的刻画较复杂,状态空间较大,因此推荐系统中一般使用深度强化学习模型,文献[72-73]均采用基于值函数的DQN[74]算法。由于候选兴趣点数量较大,动作空间也较大,因此在未来兴趣点推荐研究中也可尝试使用基于策略梯度的深度强化学习算法,如DDPG 算法[75]。为了解决兴趣点推荐中由于缺乏用户对历史签到具体评分反馈而导致效用无法判定的问题,可以使用逆强化学习(Inverse Reinforcement Learning,IRL)的方法在构建策略的同时获得奖励方程[76]。强化学习方法在模型训练时相较于监督学习需要的数据量更多,但在在线推荐场景下不会带来额外的效率损失,其在推荐时考虑用户的未来长期满意度,可以有效提升长期使用该LBSN 的用户的体验质量,进而提高应用的用户粘性。
7 结束语
本文针对兴趣点推荐系统的特性,总结实际场景中兴趣点推荐所面临的挑战,对深度学习方法在该领域的应用进行总结归纳。深度学习的引入有助于兴趣点推荐系统更充分地从LBSN 中的历史签到数据、用户生成内容、社交关系等信息中提取特征,并获取多特征对于用户偏好的综合影响,也可以在一定程度上缓解数据稀疏性问题,从而提升兴趣点推荐的效果。但是,深度学习方法应用于兴趣点推荐时依然存在一定不足,下一步将改进深度学习模型使得其更适用于兴趣点推荐任务,此外,引入增量学习、迁移学习、强化学习等方法,以实现更新速度更快、效率更高、用户体验质量更好的兴趣点推荐系统也是今后的研究方向。
猜你喜欢
英语世界(2023年6期)2023-06-30 06:28:28
意林彩版(2022年2期)2022-05-03 10:25:08
第一财经(2020年4期)2020-04-14 04:38:56
疯狂英语·新策略(2019年10期)2019-12-13 08:43:28
电子制作(2019年19期)2019-11-23 08:42:00
当代陕西(2019年10期)2019-06-03 10:12:04
文苑(2018年17期)2018-11-09 01:29:28
数学小灵通·3-4年级(2017年9期)2017-10-13 08:10:54
重型机械(2016年1期)2016-03-01 03:42:04
大连工业大学学报(2015年4期)2015-12-11 04:06:52
