
基于中英文单语术语库的双语术语对齐方法
2022-01-12 02:35:01向露,周玉,宗成庆
中国科技术语 2022年1期
向露,周玉,宗成庆






摘 要:双语术语对齐库是自然语言处理领域的重要资源,对于跨语言信息检索、机器翻译等多语言应用具有重要意义。双语术语对通常是通过人工翻译或从双语平行语料中自动提取获得的。然而,人工翻译需要一定的专业知识且耗时耗力,而特定领域的双语平行语料也很难具有较大规模。但是同一领域中各种语言的单语术语库却较易获得。为此,提出一种基于两种不同语言的单语术语库自动实现术语对齐,以构建双语术语对照表的方法。该方法首先利用多个在线机器翻译引擎通过投票机制生成目标端“伪”术语,然后利用目标端“伪”术语从目标端术语库中检索得到目标端术语候选集合,最后采用基于mBERT的语义匹配算法对目标端候选集合进行重排序,从而获得最终的双语术语对。计算机科学、土木工程和医学三个领域的中英文双语术语对齐实验结果表明,该方法能够提高双语术语抽取的准确率。
关键词:双语术语;单语术语库;术语对齐;语义匹配
中图分类号:TP391;H083 文献标识码:A DOI:10.12339/j.issn.1673-8578.2022.01.002
Bilingual Terminology Alignment Based on Chinese-English Monolingual Terminological Bank//XIANG Lu, ZHOU Yu, ZONG Chengqing
Abstract: Bilingual terminologies are essential resources in natural language processing, which are of great significance for many multilingual applications such as cross-lingual information retrieval and machine translation. Bilingual terminology pairs are usually obtained by either human translation or automatic extraction from a bilingual parallel corpus. However, human translation requires professional knowledge and is time-consuming and labor-intensive. Besides, it is not easy to have a large bilingual parallel corpus in a specific domain. But the monolingual terminology banks of various languages in the same domain are relatively easy to obtain. Therefore, this paper proposes a novel method to extract bilingual terminology pairs by automatically aligning terms from monolingual terminology banks of two languages. Firstly, multiple online machine translation engines are adopted to generate the target pseudo terminology through a voting mechanism. Secondly, the target pseudo terminology is used to retrieve from the target terminology bank to obtain the candidate set of target terminologies. Finally, a mBERT-based semantic matching model is used to re-rank the candidate set and obtain the final bilingual terminology pair. Experimental results of Chinese-English bilingual terminology alignment on three domains, including computer science, civil engineering, and medicine, show that our proposed method can effectively improve the accuracy of bilingual terminology extraction.
Keywords: bilingual terminology; monolingual terminological bank; terminology alignment; semantic matching
引言
术语是专业领域中概念的语言指称(GB/T 10112—959),也可定义为“通过语言或文字来表达或限定专业概念的约定性语言符号”[1-2]。术语通常由一个或多个词汇单元组成,包含了一个领域的基本知识。随着全球化进程的快速发展,不同语言间的知识、技术交流的需求愈加迫切和频繁。而术语作为知识的核心载体,其相互翻译却成为各国间知识、技术交流的最大障碍之一[3]。因此,研究双语术语自动抽取方法对于双语术语词典构建、跨语言信息检索和机器翻译等应用都具有十分重要的实用价值。
人工翻译构建是获得高质量双语术语的一种可靠方式,但是人工翻译需要一定的专业知识且耗时耗力。为此,许多研究者提出了从不同资源中抽取双语术语的方法,包括基于平行语料库的双语术语抽取[4-8]和基于可比语料库的双语术语抽取[9-10]。基于平行(可比)语料库的双语术语自动抽取通常分為两个步骤,首先通过单语术语抽取分别得到两个语言的单语术语候选表,而后通过计算候选术语在平行(可比)语料中的共现概率或基于双语词典计算术语对的翻译概率,其中概率高于预设阈值的候选结果将抽取作为双语术语。由于平行语料的文本是互为译文的关系,基于平行语料库的双语术语抽取能够获得较高的准确率。但是对于众多语言对,尤其是低资源语言,特定领域的双语平行数据非常稀缺且难以获取。此外,受限于可比语料库的规模和质量,从其中抽取双语术语对的准确率往往较低。
相比于双语平行(可比)语料库,同一领域中不同语言的单语术语库更容易获得。可以是已经构建好的单语术语库,也可以利用现有的单语术语抽取方法[11-14]对单语语料库进行自动抽取获得。
基于此,本文提出一种从两种不同语种的单语术语库中自动进行术语对齐以抽取双语术语对的方法。该方法仅利用单语术语本身的信息,而不依赖于上下文信息,在获取不同语言同一领域的单语术语库后,能够迅速抽取双语术语对。具体地,对于一个源端术语,该方法首先利用多个在线机器翻译引擎通过投票机制生成目标端“伪”术语,然后通过目标端“伪”术语与目标端术语库中的术语之间的文本相似度筛选出目标端术语候选集合,最后通过基于mBERT(multilingual bidirectional encoder representation from transformers)[15] 的语义匹配模型对源端术语和目标端术语候选集的语义相似度重排序,从而获得最终的双语术语对。本文提出的方法在计算机科学、土木工程和医学三个领域的中英单语术语库上进行了实验,实验结果表明本文所提方法能够显著地提高双语术语抽取的准确率。
本文的组织结构如下:第1部分介绍双语术语抽取的相关工作,第2部分对本文的任务进行形式化描述,第3部分对本文所提出的面向单语术语库的双语术语对齐方法进行详细介绍,第4部分介绍本文所使用的数据集和实验设置,并给出详细的实验结果和分析,最后进行总结和展望。
1 相关工作
1.1 单语术语抽取
自动术语抽取是从文本集合中自动抽取领域相关的词或短语,是本体构建、文本摘要和知识图谱等领域的关键基础问题和研究热点[11]。根据单语术语抽取的原理,可以将方法分为三类:基于规则的方法[12, 16-21],基于统计的方法[22-27] 和基于机器学习的方法[14, 28-31]。其中,基于机器学习的方法又可以细分为使用传统机器学习的方法和使用神经网络的方法。不同的术语抽取方法可以相互融合集成,使用多种策略以提升性能。
1.2 双语术语抽取
根据所使用语料的不同,双语术语抽取可以分为基于平行语料库的双语术语抽取[3-8, 32-33]和基于可比语料库的双语术语抽取[9-10, 34-35]。其中,双语平行语料由互为翻译的源语言文本和目标语言文本组成,而可比语料则是由不同语言同一主题的非互译单语文本组成。双语术语对齐的基本思路是术语及其翻译往往出现在相似的上下文中[36]。
从抽取方法上,双语术语抽取以单语术语抽取为基础,也可以划分为两种方法:对称策略抽取法,即先分别对两种单语语料进行单语术语抽取,然后对单语术语抽取的结果进行双语术语对齐;非对称策略抽取法,即使用一种语言单语术语抽取的结果在另外一种语言单语语料上查找对应的术语翻译。
在基于平行语料库的双语术语抽取上,孙乐等[4]根据词性规则进行单语术语抽取,然后融合句子字符长度信息计算翻译概率,从而抽取双语术语对。孙茂松等[3]使用短语对齐、组块分析相结合的方法在双语语料上进行候选术语的抽取。张莉等[37]在孙乐等[4]的研究基础上将术语语序位置信息引入术语对齐。刘胜奇等[38]提出使用多策略融合Giza++术语对齐方法,使用多种关联和相似度提升术语对齐的对准率。在基于可比语料的双语术语抽取上,Rapp等[39]和Tanaka等[40]通过建立源语言文本与目标语言文本的共现矩阵并进行矩阵相似度计算来抽取翻译等价对。Yu等[41]通过句法分析获得细粒度的上下文信息,从而抽取中英双语词语对。Lee等[42]使用一种基于EM框架结合统计学、词法、语言学、上下文和时空特征的无监督混合模型来从可比语料中抽取双语术语。
不同于前述工作,本文主要关注的是从两种语言的单语术语库中自动进行术语对齐,从而抽取双语术语对。单语术语库可以是已经构建好的单语术语库,也可以利用现有的单语术语抽取方法进行构建。该方法仅利用单语术语本身的信息,而不依赖于上下文信息,在获取不同语言同一领域的单语术语库后,能够迅速抽取双语术语对。
1.3 预训练模型词向量
深度学习给自然语言处理领域带来了突破性的变革,其中一个关键的概念就是词嵌入。作为最常见的文本特征表示方法之一,词嵌入已被广泛应用于各种自然语言处理任务。分布式词向量是利用神经网络模型来学习单词的共现性,通过无监督学习得到能够表达词语语义信息的低维度向量。
最近,许多预训练模型通过不同的策略提升了语言表征能力。其中,Devlin等[15]提出了BERT模型。BERT模型的基础是自注意力(self-attention)机制,利用自注意力机制可以获取双向的上下文信息,通過在海量的无监督语料库上训练获得句子中每个单词的上下文表示信息。BERT在多种自然语言处理任务上取得了最优的研究成果[15, 43]。
2 任务定义
给定源端术语,双语术语对齐任务旨在从目标端术语集合中找到其对应的翻译,其形式化定义如下:
给定源语言S中的一组术语集合QS,和目标语言T中一组术语集合QT,QS和QT是同一领域(如医学领域)不同语言的术语集合,本文的目标是为每个源端术语wS∈QS,从目标端术语集合QT中找到对应的翻译wT,从而获得双语术语对wS,wT。此处将双语术语对wS,wT抽取的问题转换为跨语言文本相似度度量任务。为了减小目标端术语比对范围,对于源端术语wS,首先利用多个在线机器翻译引擎通过投票机制生成目标端“伪”术语w'T,然后利用w'T和文本相似度算法对目标端术语集合QT进行筛选,获得目标端术语候选集合QcandT,最后对wS与候选集QcandT中的候选术语进行语义相似度重排序,选取相似度最高的作为最终术语翻译对。
3 本文方法
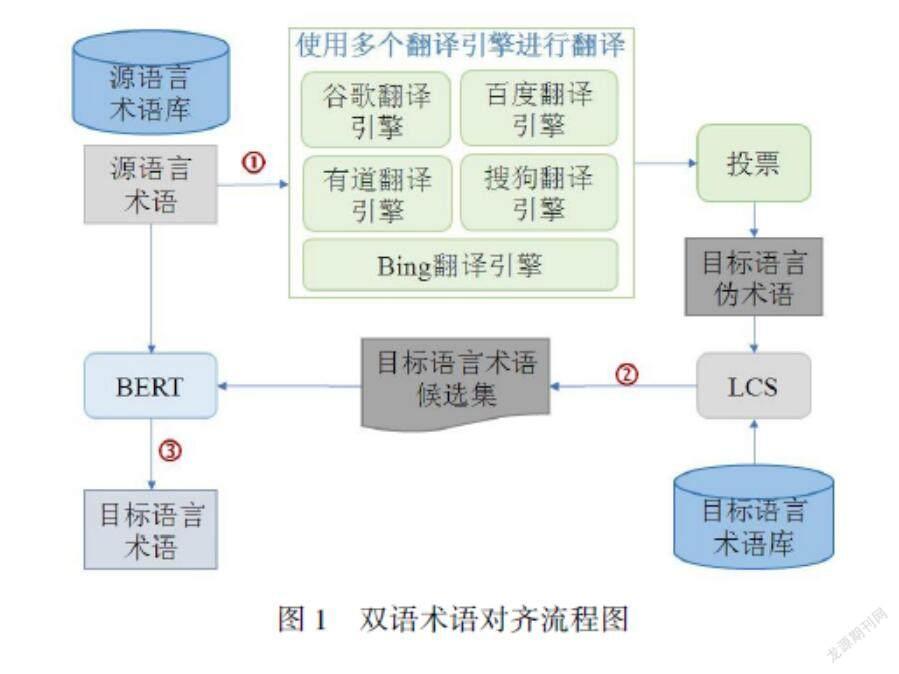
本文提出一种从两种不同语种的单语术语库中自动进行术语对齐以抽取双语术语对的方法。如图1所示,该方法采用“生成—筛选—比较”的方式,共分为三个步骤:(1) 目标语言伪术语生成,即利用多个在线翻译引擎通过投票机制生成目标语言伪术语;(2) 目标语言术语候选集生成,通过最长公共子串(longest common sub-sequence, LCS)算法[43]对目标语言术语库进行筛选,生成目标语言术语候选集;(3) 基于语义相似度的重排序,通过预训练语言模型BERT对目标语言术语候选集进行基于跨语言语义相似度的排序,得到得分最高的目标端术语,生成最终的双语术语对。
3.1 目标端伪术语生成
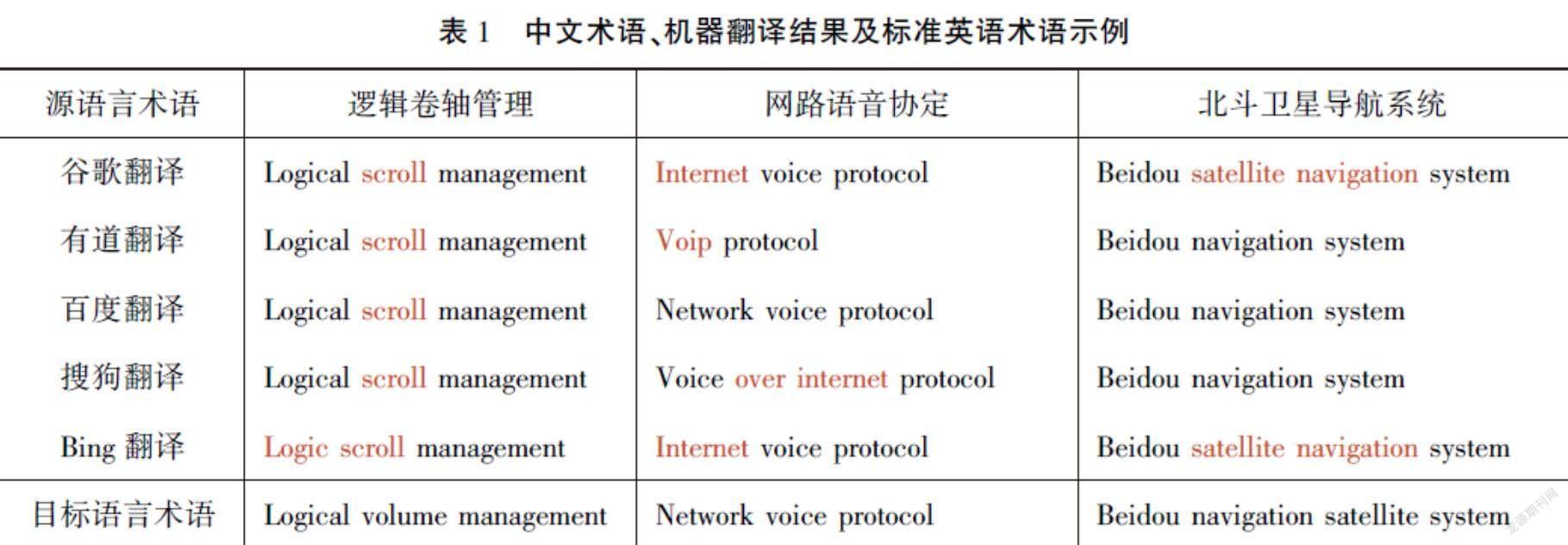
机器翻译就是实现从源语言到目标语言转换的过程[44]。随着深度学习和人工智能技术的快速发展,机器翻译技术得到了快速发展,包括谷歌、百度、有道、搜狗等在内的许多互联网公司都已经部署了各自的在线机器翻译引擎。因此,本文借助已有的机器翻译引擎作为不同语言之间的桥梁,将源语言术语转换为目标语言表述。由于术语翻译的准确性和专业性要求较高,通过机器翻译引擎生成的目标语言表述虽然一定程度上能够表达源语言术语的含义,但是不能确保是完全正确的目标语言术语,本文将其定义为“目标端伪术语”。这些源语言术语对应的目标端伪术语需要和目标端术语库进行进一步的相似度计算才能最终确定其对应的目标端术语。表1给出了中文术语(源语言)、机器翻译引擎翻译结果以及标准的英语术语(目标语言)的示例。
利用多个在线翻译引擎对源语言术语进行翻译,生成多个目标端表述后,须从中选择一个合适的表述作为源语言术语对应的目标端伪术语。本文采用多数投票法选择最终目标端伪术语。多数投票法以单个模型的预测结果为基础,采用少数服从多数的原则确定模型预测的结果。
假设对于一个源语言术语wS,采用N个在线翻译引擎对其进行翻译,得到目标端伪术语集合Q'T=w'T1,w'T2,…,w'TN,统计w'Ti∈Q'T在目标端伪术语集合中出现的次数countw'Ti,则目标端伪术语w'T定义为:
w'T=argw'Timaxcountw'Ti,w'Ti∈Q'T (1)
即w'T为得票数最多的翻译结果,若同时有多个翻译结果获得最高票数,则从中随机选取一个作为最终目标端伪术语。
3.2 目标端候选集生成
在获得目标端伪术语的基础上,若直接利用目标端伪术语与目标端术语集合中的每个目标端标准术语进行比对,则会存在噪声多、时间成本高的问题。因此,本节将利用目标端伪术语对目标端术语集合进行筛选,生成目标端候选集,从而缩小标准术语的搜索空间。具体而言,通过目标端伪术语和目标端术语集合中的每个术语进行相似度计算,这里采用LCS算法,保留相似度得分最高的K个术语形成候选集。
如算法1所示,遍历目标端术语集合QT,计算由上一步获得的目标端伪术语w'T与目标端术语集合中的术语wTi的相似度simscore(第4行),当候选集中目标端术语的个数小于K时,直接将wTi加入到候选集U中,并更新候选集中相似度得分最小值LCSscore_L(第5—第11行)。当候选集中目标端术语个数等于K且simscore大于候选集中相似度得分最小值,则将得分最小的术语从候选集U中剔除,并从相似度得分集合scoreset删除一个数值为LCSscore_L的元素,然后将wTi加入到候选集U中,同时更新候选集中相似度得分最小值LCSscore_L(第12—第20行)。当遍历完QT后,即可获得目标端候选集U。
3.3 基于语义相似度的重排序
由于LCS算法只考虑了词形上的相似关系,而忽视了语义层面的相似关系,因此即便LCS相似度得分最高,在很多情况下依然无法获取正确的目标端术语。同时,使用机器翻译系统生成目标端伪术语的过程也存在一定程度上的语义失真,因此,本文提出同时利用源语言术语和目标端伪术语对目标端候选集进行语义层面的相似度计算,利用源语言术语信息进一步增强目标端术语选择的性能。
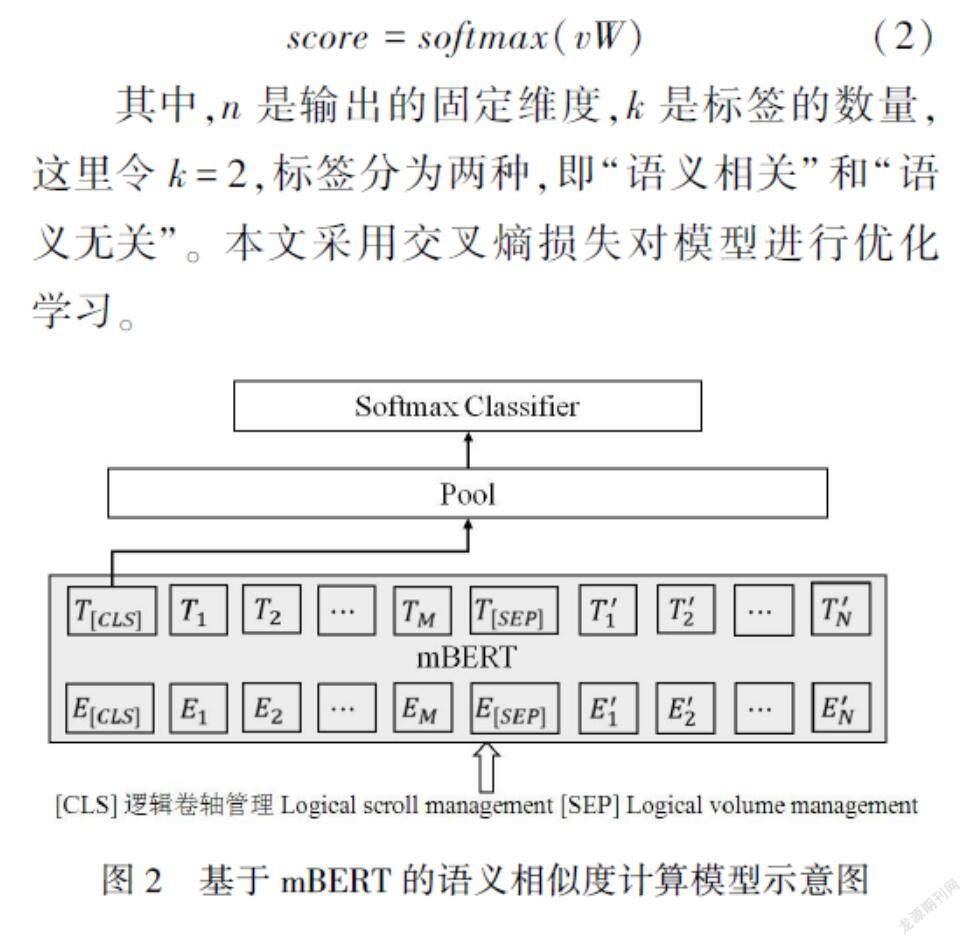
本文采用多语言预训练的BERT(mBERT)模型对源语言术语、目标端伪术语和目标候选集中的术语进行语义表示。如图2所示,输入为“[SEP]”分隔的字符串,取第一位隐层源语言术语、目标端伪术语和候选词并按标识符单元“[CLS]”的输出,其中中文以字符为单位,英文以词为单位,经过非线性变化映射到一个固定维度的向量v作为“源语言术语—候选词”的语义表示,并和可训练权重矩阵W∈
Euclid Math TwoRA@
n×k进行相乘,如式(2)所示。
score=softmax(vW) (2)
其中,n是输出的固定维度,k是标签的数量,这里令k=2,标签分为两种,即“语义相关”和“语义无关”。本文采用交叉熵损失对模型进行优化学习。
使用mBERT语义相似度模型对候选集中所有术语进行语义相似度打分后,按照得分从高到低依次进行排序,得分最高的目标端术语即为源语言术语对应的目标端术语(如图1所示)。
4 实验与结果
本文在计算机科学、土木工程和医学三个领域进行了中英双语术语对齐的实验。
4.1 数据集构造
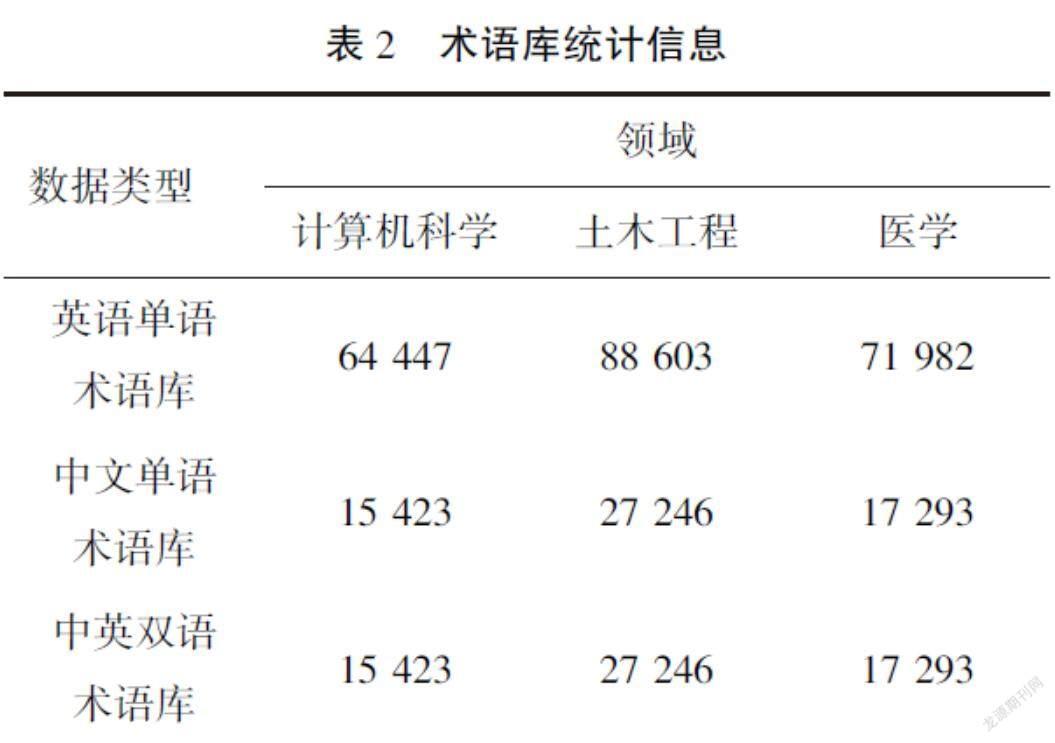
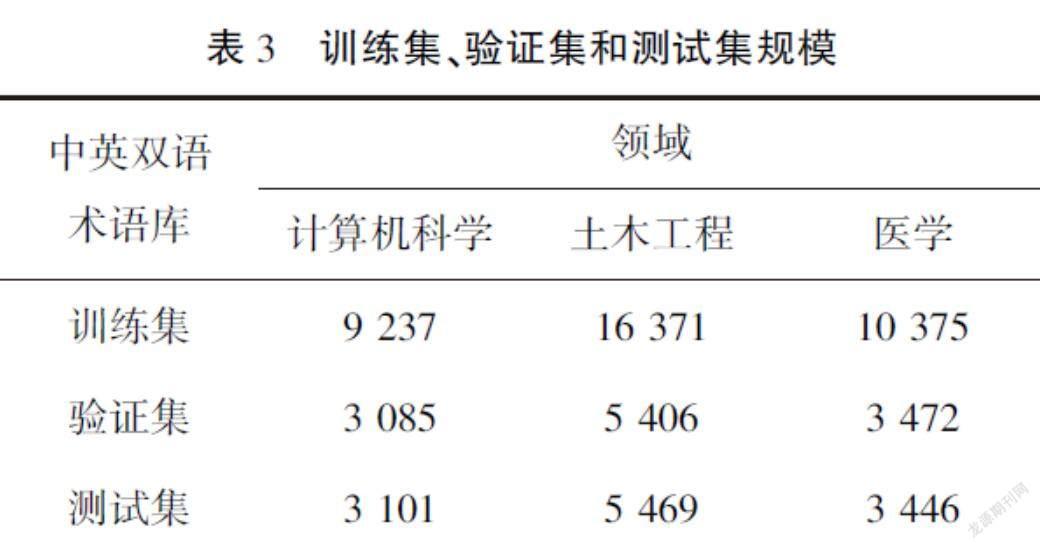
为了进行双语术语对齐的实验,本文利用维基百科构造了三个领域的中文术语库和英文术语库,包括计算机科学、土木工程和医学。本文利用PetScan工具从维基百科上获取符合特定条件的标题列表,例如,使用“Language = en & Depth = 4 & Categories = Computer science”获取计算机科学领域下的英文条目。在获取对应语言和领域下的标题条目后,经过简单的规则处理,比如去掉纯数字的条目、语言不正确的条目等,将过滤之后的标题条目作为对应领域的单语术语库。在获取单语术语库后,由于在维基百科上,中文的页面数远小于英文的页面数,因此,本文遍历中文单语术语库,利用維基百科的跨wiki链接(Interwiki links)来获取对应的英文术语,从而获得双语术语库。利用上述方法获取的术语库的统计信息如表2所示。
为了训练3.3节中的语义相似度模型,本文将中英双语术语库划分成了训练集、验证集和测试集,具体数据规模如表3所示。在训练过程中,双语术语是“语义相关”样本,需要构造“语义无关”样本,对于训练集和验证集中的每一个中文术语,通过其对应的英文端术语,采用LCS算法与英语单语术语库中的其他术语进行相似度计算,取相似度前5的英语端术语作为“语义无关”训练样本,使训练语义相似度模型时的正负样本比例为1∶5。
在测试阶段,源语言术语库为测试集中的中文术语,目标语言术语库为英语单语术语库,目标是为中文术语找到其对应的英语术语。
4.2 实验设置
在线翻译引擎:在实验过程中,本文采用了5个在线翻译引擎将中文单语术语库中的术语翻译成英文“伪”术语:谷歌翻译、百度翻译、有道翻译、搜狗翻译以及Bing翻译。
mBERT:在谷歌发布的多语言预训练模型BERT-Base、Multilingual Cased基础上进行微调,数据采用4.1节所述方式进行构建,batch大小设为32,训练轮数设为30,输入序列最大值为100,初始学习率为0.00005,其余保持默认参数。
评价指标:本文采用正确率(Accuracy)作为评价指标:
Acc=|predict∩reference|reference (3)
其中,predict为模型获得的双语术语对集合,reference为标准的双语术语对集合。|predict∩reference|代表模型预测正确的双语术语对的个数,reference代表标准双语术语对的个数。
基准模型:为了对比所提“生成—筛选—比较”方法的有效性,本文将与以下基线模型进行比较:
(1)多翻译引擎投票方法(基线系统1):使用4.2节所述的5种翻译引擎对测试集中的中文术语进行翻译,然后采用多数投票法获得对应的英语术语。
(2)跨语言相似度方法(基线系统2):直接使用预训练语言模型BERT-Base、Multilingual Cased对测试集中的中文术语和英语单语术语库进行编码,得到对应的句向量表示,然后计算一个中文术语和任意一个英文术语的句向量的余弦相似度,得分最高的为中文术语所对应的英文术语。
(3)多翻译引擎投票+余弦相似度方法(基线系统3):该方法与基线系统2类似,都是通过BERT-Base、Multilingual Cased获取句向量表示,然后计算余弦相似度。所不同的是,这里计算的是通过多翻译引擎投票产生的英语表述与英语术语的相似度,得分最高的为中文术语所对应的英文术语。
4.3 实验结果
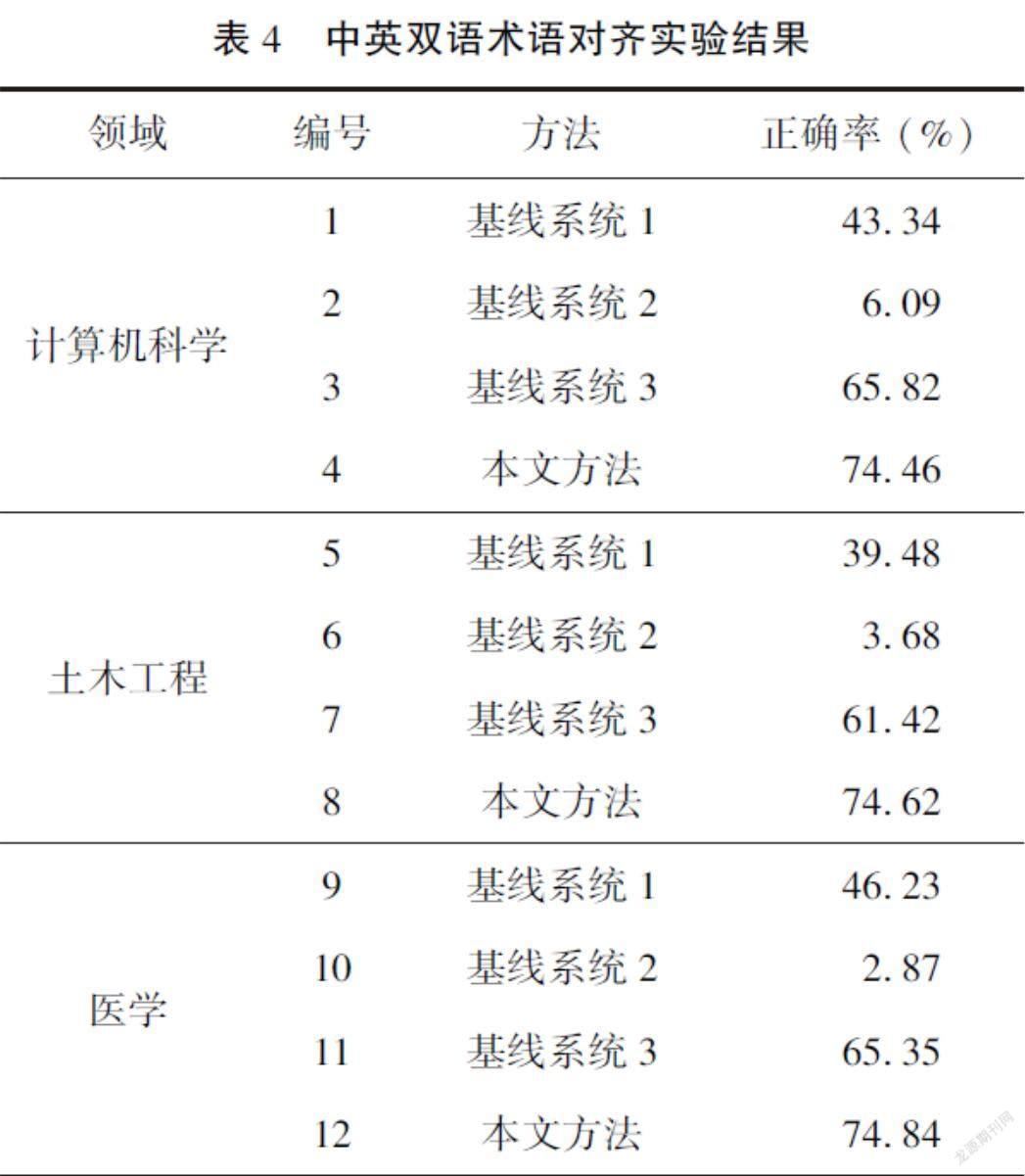
在计算机科学、土木工程和医学三个领域上进行了中英双语术语对齐的实验,实验结果见表4。
通过该实验结果,可以看出以下信息。
(1)当前机器翻译引擎对于术语的翻译性能还有待提升。利用5个在线翻译引擎通过投票机制生成的英语术语在计算机科学、土木工程和医学领域上仅有43.34%/39.48%/46.23%的正确率。这也说明了自动构建双语术语库对于提升翻译系统的性能有着重要意义。
(2)多语言BERT在中英语义相似度计算上表现很差(基线系统2:6.09%/3.68%/2.87%),其性能远低于基线系统1,这可能是由于多语言BERT没有在任务对应的双语术语数据上微调,中英文的语义空间对齐较差。而多语言BERT直接对英语伪术语和英文术语进行语义相似度计算(基线系统3),其性能显著优于基线系统2,这表明多语言BERT在单一语言上能較好地表征语义相似度。
(3) 本文所提方法在三个领域的双语术语对齐上均显著优于基线系统,该方法以基线系统1生成的结果作为输入,使用LCS算法与英语标准术语库比对,返回得分最高的10个英语术语组成候选集,最后利用mBERT进行语义相似度重排序,实验结果表明所提方法能够显著提升双语术语对齐的性能,从而得到更好的双语术语库。
4.4 消融分析
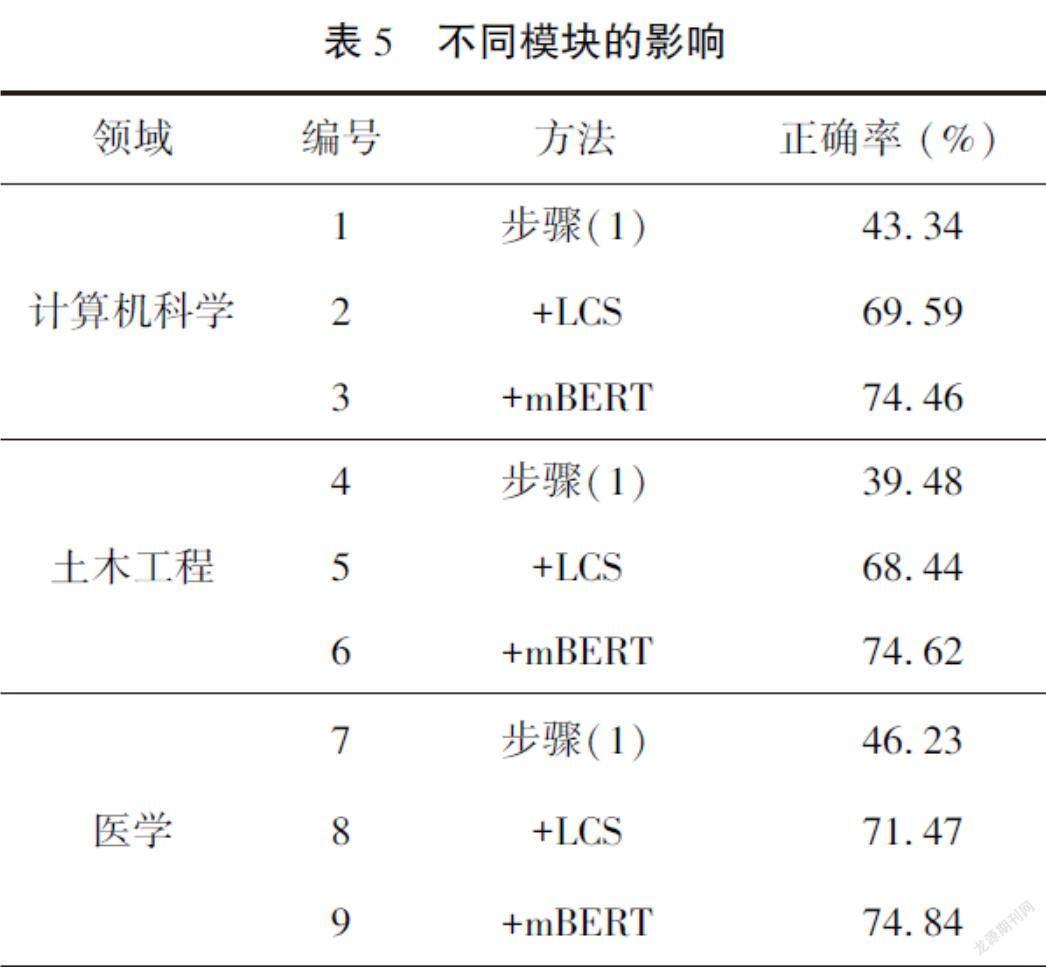
基本模块分析:本文所提方法包含三个步骤:(1) 目标语言伪术语生成,即利用多个在线翻译引擎通过投票机制生成目标语言伪术语;(2) 目标语言术语候选集生成,通过文本相似度算法LCS对目标语言术语库进行筛选,生成目标语言术语候选集;(3) 基于语义相似度的重排序,通过预训练语言模型mBERT对目标语言术语候选集进行语义相似度重排序,得到得分最高的目标端术语,生成最终的双语术语对。表5展示了所提方法中不同模块对最终结果的影响。
其中,步骤(1)表示利用多个在线翻译引擎通过投票机制生成目标语言伪术语,+LCS表示使用目标语言伪术语与目标术语库进行LCS相似度计算,将得分最高的术语作为对应的目标端术语,+mBERT则是利用mBERT对LCS返回的得分最高的10个候选集进行语义相似度重排序,取相似度得分最高的为目标端术语。
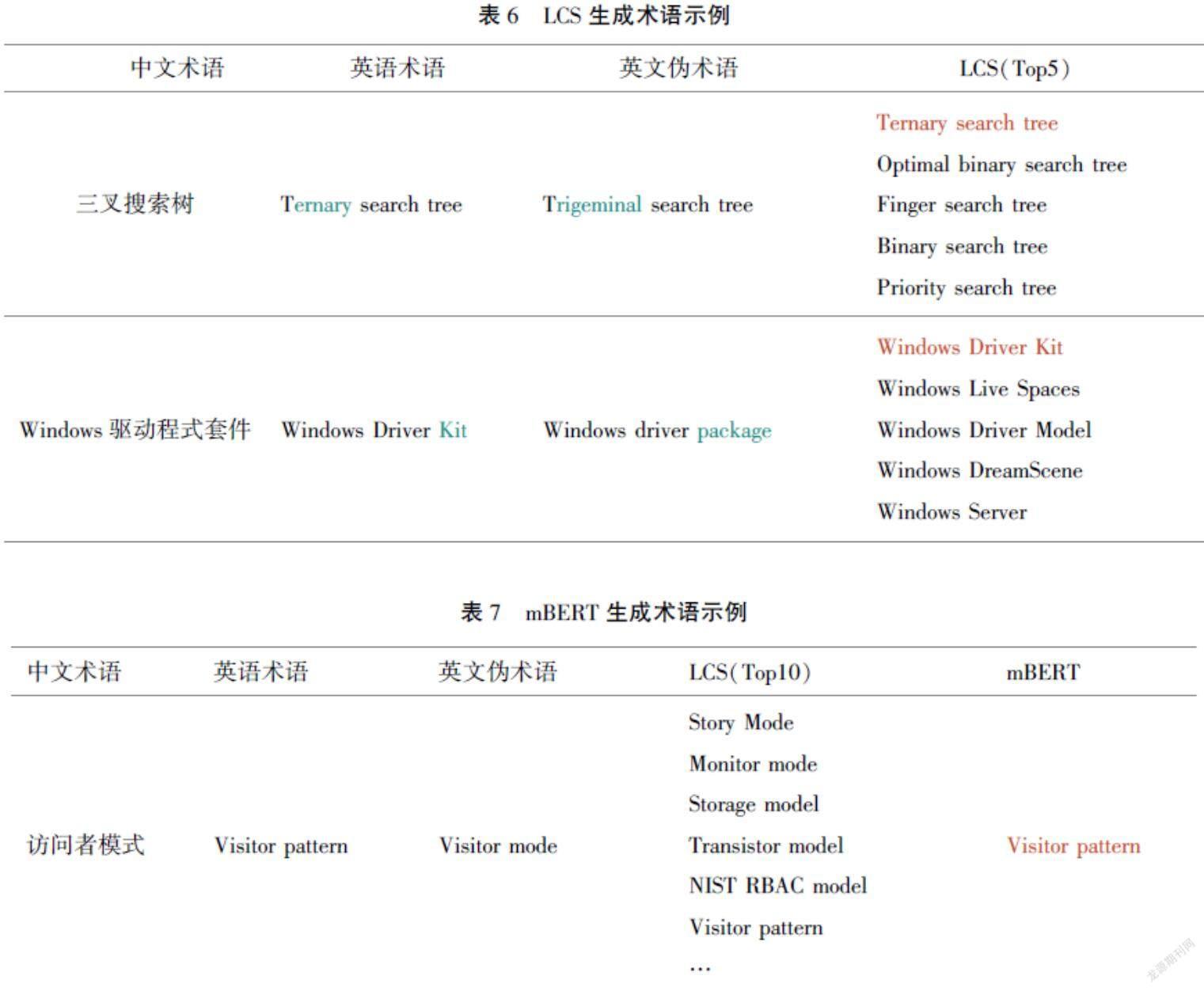
通过表5可以看出,相比于步骤(1),+LCS的性能有大幅提升,这说明对于部分术语,机器翻译虽然不能将其完全翻译正确,但部分能够翻译正确,LCS相似度计算能够对这种类型的术语进行校正。表6展示了两个示例,其中英文术语表示术语库中正确的术语,英文伪术语表示步骤(1)产生的术语,LCS(Top5)表示LCS得分前5的术语,标红的术语为得分最高的术语。当术语部分翻译错误时,通过LCS可以从标准术语库中找到对应的正确术语。使用LCS产生候选集后,交由mBERT进行语义相似度重排序,能够进一步提升双语术语对齐的性能。表7展示了经过步骤(1) → +LCS → +mBERT 三个步骤后,生成正确英语术语的例子。
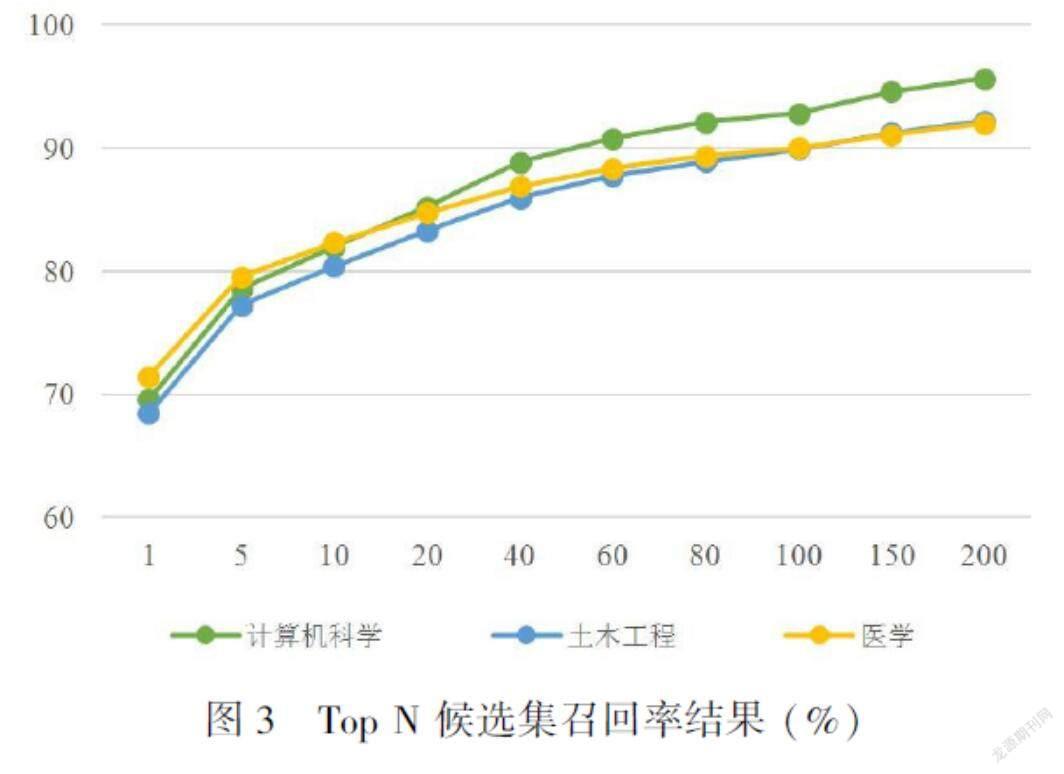
候选集规模的影响:步骤 (2)通过LCS相似度生成候选集。这里分析了生成候选集的质量和候选集规模对最终双语术语对齐的影响。图3给出了LCS相似度前1—前200(Top 1—Top 200)的召回率。
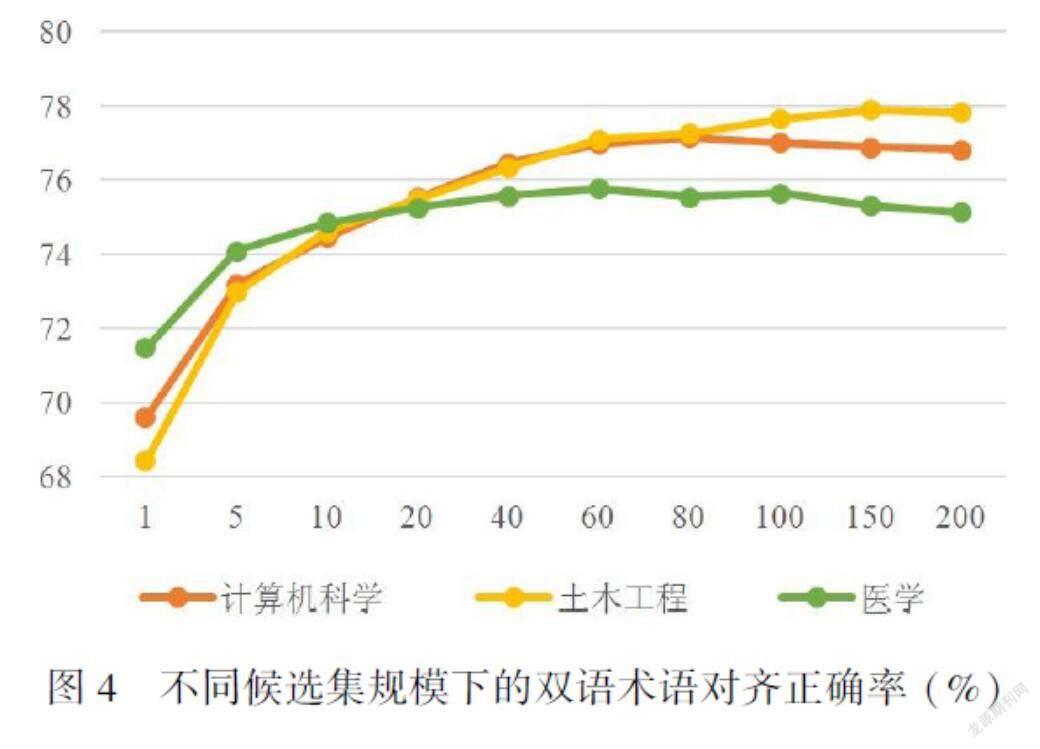
随着候选集数目的增加,召回率也在增加。取LCS相似度前200的候选术语组成候选集后,计算机科学领域的召回率达到95.65%,土木工程领域的召回率达到92.19%,医学领域的召回率达到91.99%。在获得候选集之后,通过mBERT模型进行语义相似度重排序选出最终术语。本文探讨了候选术语数目对于最终双语术语对齐的影响,将生成的不同规模的候选集交由mBERT模型进行语义相似度重排序,最终正确率结果如图4所示。
可以看出,随着候选集的增加,通过mBERT语义相似度重排序获取双语术语对的性能也会有一定的提升。当候选集规模从5增加到60,双语术语对齐的正确率提升较为明显。当候选集规模继续增加,从60增加到200时,虽然目标端标准术语的召回率提升明显,但是通过mBERT进行语义相似度重排序后得到的结果并没有明显提升,在医学领域和计算机领域上还出现了下降趋势,经过分析发现是由于过大的候选集会不可避免地带来更多的噪声,从而对语义相似度模型的排序造成一定干扰。此外,本文在构造训练集的时候,正例和负例的比例是1∶5,这也会对语义相似度重排序的准确率产生一定的影响。
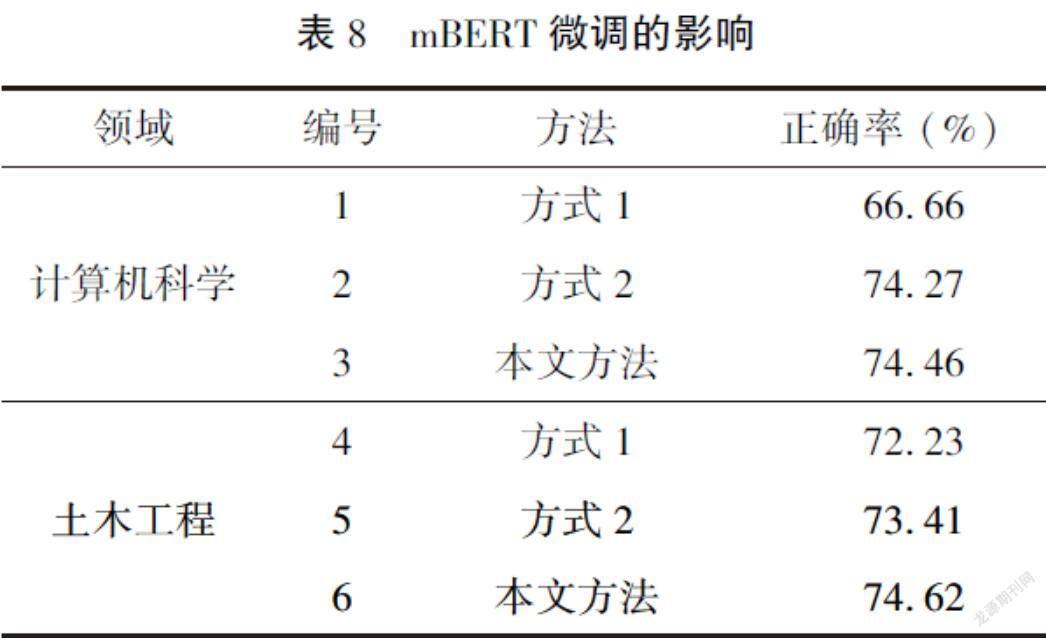
mBERT微调的影响:所提方法最后一步是利用mBERT对候选集进行重排序得到最终结果。本文提出同时利用源语言术语和目标端伪术语对目标端候选集进行语义层面的相似度计算。为了验证源端术语和目标端术语对于mBERT模型性能的影响,本文在计算机科学和土木工程领域上对比了两种微调方式:
方式1:仅利用源语言术语和目标端候选集对mBERT进行微调,以圖2中的例子为例,模型输入为“[CLS] 逻辑卷轴管理[SEP] Logical volume management”。
方式2:仅利用目标端伪术语和目标端候选集对mBERT进行微调,以图2中的例子为例,模型输入为“[CLS] Logical scroll management[SEP] Logical volume management”。
模型训练过程中的参数与4.2节所述参数一致,训练数据中正负样本比例为1∶5。模型训练完成后,对LCS算法返回的得分最高的10个英语术语组成的候选集进行重排序,得分最高的术语为源端术语对应的目标端术语。实验结果如表8所示。其中,第1行到第3行显示的是在计算机科学领域上的实验结果,第4到第6行显示的是在土木工程领域上的实验结果。实验结果表明,相比于单一使用源语言术语或者目标端伪术语,联合使用这两者的信息能够增强语义相似度重排序的性能(第3行和第6行),提高模型抽取双语术语对的能力。
5 结语
本文提出了一种面向两种语言单语术语库的双语术语对齐方法,该方法由“生成—筛选—比较”三步组成,首先利用多个在线机器翻译引擎通过投票机制生成目标端“伪”术语,然后利用目标端“伪”术语从目标术语库中检索得到目标端术语候选集合,最后采用基于mBERT的语义匹配算法对目标端候选集合进行重排序,从而获得最终的双语术语对。该方法可以仅仅利用单语术语库本身的信息抽取双语术语对。在计算机科学、土木工程和医学三个领域上的中英双语术语对齐实验结果表明,与基线系统相比,所提方法能够有效地提高双语术语抽取的性能。
在未来的研究中,需要进一步探索如何利用术语库之外的信息提升双语术语对齐的质量,如利用互联网大规模文本信息,学习更加准确的融合上下文信息的术语表示。
注释
① PetScan工具:https://petscan.wmflabs.org。
② 跨wiki链接(Interwiki links):https://www.mediawiki.org/wiki/Manual:Interwiki。
③ 多语言预训练模型BERT-Base, Multilingual Cased:https://huggingface.co/bert-base-multilingual-cased。
参考文献
[1] 冯志伟.现代术语学引论[M].北京:语文出版社,1997.
[2] 杜波,田怀凤,王立,等.基于多策略的专业领域术语抽取器的设计[J].计算机工程, 2005(14):159-160.
[3] 孙茂松,李莉,刘知远.面向中英平行专利的双语术语自动抽取[J].清华大学学报(自然科学版), 2014,54(10):1339-1343.
[4] 孙乐,金友兵,杜林,等.平行语料库中双语术语词典的自动抽取[J].中文信息学报, 2000(6):33-39.
[5] HUANG G P, ZHANG J J, ZHOU Y, et al. A simple, straightforward and effective model for joint bilingual terms detection and word alignment in smt[C]//Proceedings of the Fifth Conference on Natural Language Processing and Chinese Computing & The Twenty Fourth International Conference on Computer Processing of Oriental Languages. Kunming, China, 2016:103-115.
[6] LEFEVER E, MACKEN L, HOSTE V. Language-independent bilingual terminology extraction from a multilingual parallel corpus:A simple, straightforward and effective model for joint bilingual terms detection and word alignment in smt[C]//Proceedings of the 12th Conference of the European Chapter of the ACL (EACL 2009). 2009: 496-504.
[7] FAN X, SHIMIZU N, NAKAGAWA H. Automatic extraction of bilingual terms from a chinese-japanese parallel corpus[C]//Proceedings of the 3rd International Universal Communication Symposium. 2009: 41-45.
[8] 蒋俊梅.基于平行语料库的双语术语抽取系统研究[J].现代电子技术, 2016, 39(15):108-111.
[9] 康小丽,章成志,王惠临.基于可比语料库的双语术语抽取研究述评[J].现代图书情报技术, 2009(10):7-13.
[10] AKER A, PARAMITA M L, GAIZAUSKAS R. Extracting bilingual terminologies from comparable corpora[C]//Proceedings of the 51st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). Sofia, Bulgaria: Association for Computational Linguistics, 2013:402-411.
[11] 张雪,孙宏宇,辛东兴,等.自动术语抽取研究综述[J].软件学报, 2020,31(7):2062-2094.
[12] 李思良,许斌,杨玉基. DRTE:面向基础教育的术语抽取方法[J].中文信息学报,2018,32(3):101-109.
[13] CRAM D, DAILLE B. Termsuit: Terminology extraction with term variant detection[C]//Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics. Berlin, Germany: Association for Computational Linguistics, 2016:13-18.
[14] ZHANG Z, GAO J, CIRAVEGNA F. Semre-rank: Improving automatic term extraction by incorporating semantic relatedness with personalised pagerank[J]. ACM Transactions on Knowledge Discovery from Data (TKDD), 2018, 12(5): 1-41.
[15] DEVLIN J, CHANG M W, LEE K, et al. Bert: Pre-training of deep bidirectional transformers for language understanding[C]//Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers). Minneapolis, Minnesota: Association for Computational Linguistics, 2019:4171-4186.
[16] BOURIGAULT D, GONZALEZ-MULLIER I, GROS C. Lexter, a natural language processing tool for terminology extraction[C]//Proceedings of the 7th EURALEX International Congress. Gteborg, Sweden: Novum Grafiska AB, 1996: 771-779.
[17] JUSTESON J S, KATZ S M. Technical terminology: some linguistic properties and an algorithm for identification in text[J]. Natural language engineering, 1995, 1(1): 9-27.
[18] 化柏林. 針对中文学术文献的情报方法术语抽取[J]. 现代图书情报技术, 2013 (6): 68-75.
[19] 祝清松, 冷伏海. 自动术语识别存在的问题及发展趋势综述[J]. 图书情报工作, 2012, 56(18): 104-109.
[20] 向音, 李苏鸣. 领域术语特征分析:以军语为例[J]. 中国科技术语, 2012, 14(5): 5-9.
[21] 张乐,唐亮,易绵竹.融合多策略的军事领域中文术语抽取研究[J].现代计算机, 2020(26):9-16,20.
[22] 屈鹏,王惠临.面向信息分析的专利术语抽取研究[J].图书情报工作, 2013,57(1):130-135.
[23] 曾文,徐硕,张运良,等.科技文献术语的自动抽取技术研究与分析[J].现代图书情报技术, 2014(1):51-55.
[24] 胡阿沛,张静,刘俊丽.基于改进C-value方法的中文术语抽取[J].现代图书情报技术, 2013(2):24-29.
[25] JONES K S. A statistical interpretation of term specificity and its application in retrieval[J]. Journal of documentation, 2004.
[26] CAMPOS R, MANGARAVITE V, PASQUALI A, et al. A text feature based automatic keyword extraction method for single documents[C]//European conference on information retrieval. Grenoble, France: Springer International Publishing, 2018:684-691.
[27] VU T, AW A, ZHANG M. Term extraction through unithood and termhood unification[C]//Proceedings of the Third International Joint Conference on Natural Language Processing: Volume-II. 2008:631-636.
[28] 賈美英,杨炳儒,郑德权,等.采用CRF技术的军事情报术语自动抽取研究[J].计算机工程与应用,2009,45(32):126-129.
[29] 刘辉,刘耀.基于条件随机场的专利术语抽取[J].数字图书馆论坛, 2014(12):46-49.
[30] KUCZA M, NIEHUES J, ZENKEL T, et al. Term extraction via neural sequence labeling a comparative evaluation of strategies using recurrent neural networks[C]//19th Annual Conference of the International Speech Communication Association. Hyderabad, India: ISCA, 2018: 2072-2076.
[31] HAZEM A, BOUHANDI M, BOUDIN F, et al. Termeval 2020: Taln-ls2n system for automatic term extraction[C]//Proceedings of the 6th International Workshop on Computational Terminology. Marseille, France: European Language Resources Association, 2020:95-100.
[32] SEMMAR N. A hybrid approach for automatic extraction of bilingual multiword expressions from parallel corpora[C]//Proceedings of the Eleventh International Conference on Language Resources and Evaluation (LREC 2018). Miyazaki, Japan: European Language Resources Association (ELRA), 2018: 311-318.
[33] REPAR A, PODPEAN V, VAVPETI A, et al. Termensembler: An ensemble learning approach to bilingual term extraction and alignment[J]. Terminology. International Journal of Theoretical and Applied Issues in Specialized Communication, 2019, 25(1): 93-120.
[34] HAZEM A, MORIN E. Efficient data selection for bilingual terminology extraction from comparable corpora[C]//Proceedings of 26th International Conference on Computational Linguistics: Technical Papers (COLING).Osaka, Japan: The COLING 2016 Organizing Committee, 2016: 3401-3411.
[35] KONTONATSIOS G, KORKONTZELOS I, TSUJII J, et al. Combining string and context similarity for bilingual term alignment from comparable corpora[C]//Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP).Doha, Qatar: Association for Computational Linguistics, 2014: 1701-1712.
[36] DAILLE B, MORIN E. French-English terminology extraction from comparable corpora[C]//Second International Joint Conference on Natural Language Processing: Full Papers. Berlin, Heidelberg: Springer, 2005: 707-718.
[37] 张莉,刘昱显.基于语序位置特征的汉英术语对自动抽取研究[J].南京大学学报(自然科学), 2015,51(4):707-713.
[38] 刘胜奇,朱东华.基于多策略融合Giza++的术语对齐法[J].软件学报, 2015,26(7):1650-1661.
[39] RAPP R. Identifying word translations in non-parallel texts[C]//Proceedings of the 33rd Annual Meeting of the Association for Computational Linguistics. Cambridge, Massachusetts, USA: Association for Computational Linguistics, 1995:320-322.
[40] TANAKA K, IWASAKI H. Extraction of lexical translations from non-aligned corpora[C]//Proceedings of the 16th International Conference on Computational Linguistics. Copenhagen, Denmark. 1996:580-585.
[41] YU K, TSUJII J. Extracting bilingual dictionary from comparable corpora with dependency heterogeneity[C]//Proceedings of the Annual Conference of the North American Chapter of the Association for Computational Linguistics, Companion Volume: Short Papers. Boulder, Colorado: Association for Computational Linguistics, 2009: 121-124.
[42] LEE L, AW A, ZHANG M, et al. Em-based hybrid model for bilingual terminology extraction from comparable corpora[C]//Proceedings of the 23rd International Conference on Computational Linguistics. Beijing, China:Coling 2010 Organizing Committee, 2010: 639-646.
[43] LIU Y, OTT M, GOYAL N, et al. Roberta: A robustly optimized bert pretraining approach. arXiv preprint arXiv:1907.11692, 2019.
[44] BAKKELUND D. An lcs-based string metric[J]. Olso, Norway: University of Oslo, 2009.
[45] 宗成慶. 统计自然语言处理[M]. 北京: 清华大学出版社, 2013.
作者简介:向露(1988—),女,中国科学院自动化研究所模式识别国家重点实验室博士研究生, 主要研究方向为人机对话系统、文本生成和自然语言处理。通信方式:lu.xiang@nlpr.ia.ac.cn。
通讯作者:周玉(1976—),女,博士,中国科学院自动化研究所研究员,主要研究方向为自动摘要、机器翻译和自然语言处理。通信方式:yzhou@nlpr.ia.ac.cn。
宗成庆(1963—),男,博士,中国科学院自动化所研究员,中国科学院大学岗位教授,中国计算机学会会士,中国人工智能学会会士,主要从事自然语言处理和机器翻译研究,出版专著《统计自然语言处理》和《文本数据挖掘》(中、英文版),发表论文200余篇。通信方式:cqzong@nlpr.ia.ac.cn。
