
基于多时间段优化贝叶斯网络的车载容迟网络路由算法
2022-01-12 09:40:26吴家皋郭亚航蔡沈磊刘林峰
通信学报 2021年12期
吴家皋,郭亚航,蔡沈磊,刘林峰
(1.南京邮电大学计算机学院,江苏 南京 210023;2.江苏省大数据安全与智能处理重点实验室,江苏 南京 210023)
1 引言
传统网络需要依靠端到端的链路以及传输控制协议/网际协议(TCP/IP,transmission control protocol/Internet protocol)等来保证数据传输的低时延与可靠性,然而当地震、海啸等突发灾难导致端到端链路故障时,传统的基于“存储−转发”的路由模式将不再有效。因此,Jain 等[1]提出了延迟容忍网络(DTN,delay tolerant network)概念,并已广泛应用于星际网络[2]、水下传感网络[3]、移动自组织网络[4]、无线传感网络[5]、车载网络[6]等领域。其中,车载容迟网络(VDTN,vehicular delay tolerant network)将车载网络与容迟网络相结合,能为未来的自动驾驶和智能交通系统提供新的解决方案。DTN 采用新的基于“存储−携带−转发”的路由模式[7],消息需要通过节点的移动和相遇进行转发。但是,由于车辆的高速运动,可用于消息转发的车辆间的相遇接触时间非常有限。因此,对VDTN 路由算法的性能提出了更高的要求。
DTN 路由算法已有大量研究工作[8],其中,较著名的有Epidemic[9]、Spray and Wait[10]和Prophet[11]等。Epidemic 是基于泛洪策略的路由算法,通常具有最小的消息传输时延,但泛洪往往会导致网络拥塞。Spray and Wait 路由算法则通过限制消息副本的数目来解决消息泛洪问题。Prophet 路由算法则利用节点相遇的历史信息估计不同节点与消息目的节点之间的相遇概率,以此决定消息转发策略。然而,在VDTN 中,车辆的移动通常具有特定的模式,例如公交车遵循固定的路线和时刻表,私家车的移动倾向于有规律的轨迹,出租车的移动行为则体现了人流的热区等。Prophet 路由算法并没有很好地考虑车辆的这些移动模式。近年来,随着机器学习和人工智能技术的兴起,许多机器学习算法被应用到DTN 路由算法中,例如决策树[12]、强化学习[13]、人工神经网络[14]和朴素贝叶斯分类器[15-16]等。然而,决策树和人工神经网络容易出现过拟合问题,强化学习收敛速度较慢且容易导致额外的网络路由开销,朴素贝叶斯分类器则无法表达出属性间的依赖关系。贝叶斯网络(BN,Bayesian network)利用概率图模型表示属性间的依赖关系,能显著提高VDTN 中节点移动模式预测的准确性[17]。BN 结构学习是BN 模型的核心问题之一,已提出的算法包括基于依赖关系的互信息算法[18]、基于评分搜索策略的K2 算法[19]以及基于遗传算法的K2(K2GA,K2 based on genetic algorithm)算法[20]等。然而,VDTN中车辆节点的移动由于受到人类行为和生活习惯的影响有着明显的时段性、周期性的特点。因此,单一的BN 结构无法准确地表达车辆移动模式的时段性特点。虽然文献[21]也研究了基于多时间段BN的VDTN 路由算法,但其采用人工经验的时间段划分方案并非是最优划分。针对上述问题,本文开展了基于多时间段BN 的VDTN 路由算法研究。本文主要的研究工作如下。
1) 提出了新的多时间段BN 模型。引入了更多与节点移动模式相关的属性,包括剩余缓存比、平均时延、行驶距离等属性,以更准确地描述车辆的移动模式;同时,提出了新的节点分类动态奖励机制,使相遇和投递奖励的分配更合理,保证奖励值与节点实际的类别相一致。
2) 提出了2 种新的BN 时间段的优化划分算法:二分搜索 K2GA(BS-K2GA,binary search K2GA)算法和模拟退火K2GA(SA-K2GA,simulated annealing K2GA)算法。BS-K2GA 算法以二分贪心策略优化BN 的时间段划分和网络结构,具有简单高效优势;SA-K2GA 算法则将模拟退火算法和K2GA 算法相结合,能克服贪心算法容易陷入局部最优的缺点,进一步优化解的性能。
3) 提出了基于多时间段优化BN 的VDTN 路由算法,仿真实验结果表明,通过优化后的多时间段BN 模型能够准确地描述车辆的移动模式,显著提高消息的投递率,并降低消息的投递时延。
2 系统模型
BN 由有向无环图(DAG,directed acyclic graph)和条件概率表(CPT,conditional probability table)组成。令G=(V,E)为任意BN,其中,V是DAG的节点集,表示随机变量;E是节点间的有向边,表示随机变量之间的直接依赖关系。CPT 表示随机变量的联合概率分布,可以定量地描述变量之间的依赖关系。
设在VDTN 中,源节点ns产生了一个目的节点为nd的消息,该消息可以经过一系列的中继节点最终被转发到达nd,问题的关键在于如何找到一条较优的传输路径。因此,本文提出了一种优化的BN分类器模型用于估计VDTN 传输路径中车辆中继节点的消息投递能力。
在VDTN 中,车辆节点的移动模式受人们生活习惯影响具有时段性的特点。基于真实数据集的实验表明节点的活跃度呈现出规律性的分布[22]。在早晚高峰期,节点活跃度持续上升;在其他时间段,活跃度明显下降。由此可见,单一结构的BN模型显然无法描述所有时间段车辆的移动规律。因此,本文针对一天内的不同时间段构建不同的BN 模型,以更好地表达车辆的真实移动模式。如图1 所示,将一整天划分为σ个时间段,根据各个时间段的数据集来学习构造多个BN,这样的多时间段BN 模型能更加准确地描述车辆节点的移动行为。接下来,如何确定最优的时间段划分方案和各时间段对应的BN 结构则是本文要解决的首要问题。

图1 多时间段贝叶斯网络示意
图2 是本文的基于多时间段优化BN 的VDTN路由算法框架,主要包含4 个部分:属性选择、分类标准、结构学习、推理与消息转发策略。下面,先详细介绍VDTN 的节点属性选择和分类标准,有关BN 结构优化学习、推理与消息转发策略的内容将在第3 节中论述。

图2 基于多时间段优化BN 的VDTN 路由算法框架
2.1 属性选择
用于构建BN 的随机变量是与消息转发密切相关的车辆节点的属性。本文用向量X=<X1,X2,X3,X4,X5,X6,X7,X8,X9,X10>对其进行描述。
X1为区域码,表示VDTN中的节点在转发消息时所处的区域。整张地图被划分为k1个矩形区域,每个区域有相同的长宽和唯一的标识符。在本文中,整个区域的大小为35 km×25 km,被划分为35 个小矩形区域,每个矩形的尺寸为5 km×5 km。
X2为时隙,表示VDTN中的节点在转发消息时所处的时隙。选取这个属性是因为车辆在一天中不同的时间段有不同的移动模式,根据车辆轨迹历史数据集,车辆的移动主要集中在上午7 点到下午7 点。本文将粒度设置为15 min来离散化时间,因此共划分为k2=48 个时隙。
X3为运动方向,表示VDTN 中的节点在转发消息时的运动方向。本文将方向角粒度设置为π/4,车辆的运动角度可以离散化为k3=8 个方向,即东、西、南、北、东南、东北、西南、西北。
X4为平均接触时间间隔,表示VDTN 中的节点遇见其他节点需要的平均时间。该值越小,说明车辆遇见其他车辆的概率越大,消息的投递能力也越好。根据车辆轨迹历史数据集,如公交车之间的平均相遇时间统计分布,本文设置平均接触时间间隔的最大值为3 000 s,离散化粒度为300 s,因此平均接触时间间隔被划分为k4=10 个时间间隔。
X5为速度表示VDTN中节点的移动速度。根据车辆轨迹历史数据集,VDTN 中车辆的最大速度为120 km/h,离散化粒度为24 km/h,因此速度被划分为k5=5 个级别。
X6为路线编号,表示VDTN 中节点在转发消息时的路线编号。VDTN 中的车辆移动具有一定的模式,而且通常会在固定的路线上行驶,例如公交路线。不同的车辆也可能在同一条道路上行驶,因此这些车辆具有相同的路线编号。本文主要以公交车编号作为线路编号,这个属性可以较好地反映车辆的移动行为。
X7为剩余缓存比,表示VDTN 中节点剩余可用缓存大小占总缓存的比率。VDTN 节点携带的消息都需要存储在缓存中进行转发。本文将剩余可用缓存占比的离散化粒度设置为0.1,将其划分为k6=10 个比率。
X8为平均时延表示消息从该节点转发到消息的目的节点所经过的平均时间。平均时延越小,说明该节点转发消息的效率越高。根据车辆轨迹历史数据集,VDTN 中消息的最大平均时延为7 000 s,离散化粒度为1 000 s,因此平均时延被划分为k8=7 个值。
X9为行驶距离表示VDTN 中车辆在转发消息时距离上次车辆相遇所行驶的距离。根据车辆轨迹历史数据集,VDTN 中车辆的最大行驶距离为35 km,离散化粒度为5 km,因此行驶距离可以离散化为k9=7 个值。
X10为投递等级,表示节点转发消息到消息目的节点的能力。投递等级越高,表示该节点拥有越大的可能性将消息成功转发到目的节点。
在上述的属性变量中,X1~X9均易观测获得,可当作证据变量;X10则不能直接得到,故作为查询变量。为了训练BN 模型,本文提出了一种基于动态奖励机制的节点分类标准,用奖励值的离散化来表示X10并对训练数据集进行标注。当BN模型训练完成后,X10便可由证据变量X1~X9经BN 推理预测得到。
2.2 分类标准
本节详细介绍基于蚁群优化算法的动态奖励机制及其改进方案,以此作为节点投递等级的分类标准。蚁群优化算法是一种寻找最优路径的概率算法[23],其路径上的信息素会随着时间的推移而挥发。同样,节点获得的奖励值也应随着时间的推移动态变化。在前期工作的基础上[20-21],本文提出新的VDTN 节点的动态奖励分配机制。首先,节点间的相遇有利于消息的转发,如果节点遇见一个消息投递能力更强的中继节点,那么该节点的消息投递能力也会较高,因此本文定义了新的相遇奖励值。其次,投递时延和跳数都是重要的路由性能指标,因此本文在跳数投递奖励值的基础上进一步加入了时延奖励值。当某一消息经过一系列中继节点,最终被投递到目的节点时,该消息的目的节点将广播一个小的确认(ACK,acknowledgement)数据包,该数据包包含该消息投递路径上的所有中继节点的标识(ID,identification)以及从各个中继节点到目的节点的时延,一旦某个中继节点接收到了该报文,该节点将会被分配一定的跳数奖励值和时延奖励值。
通过上述方法,可以得到节点ni在t+1 时隙的奖励值即

其中,ρ∈[0,1]表示奖励值的老化系数,该系数使消息的奖励值随着时间不断老化表示节点ni在t时隙内获得的相遇奖励值表示节点ni在t时隙内获得的投递奖励值。
相遇奖励值的计算式为

其中,Δψij(t)表示在t时隙相遇节点ni和nj的奖励值之差;ψc(Δψij(t))表示节点ni与节点nj相遇时,节点ni应分配的相遇奖励值;R表示基础相遇奖励值;R c表示增量相遇奖励值;γ表示超参数。因此,相遇奖励值不再以固定值分配,而是根据相遇节点的奖励值之差来决定。低奖励值节点与高奖励值节点相遇表明该低奖励值节点有机会将消息转发给投递能力更强的中继节点,有利于提高消息的投递率,因此低奖励值节点应当得到较高的相遇奖励值。另外表示节点ni在t时隙内相遇节点的集合,因此表达了节点ni在t时隙内获得的累计相遇奖励值。
令m表示第m个经过节点ni成功投递的消息,Om表示消息m的投递路径,则投递奖励值的计算式为

综上所述,节点的奖励值将随着节点的相遇频率、消息的成功投递数、投递跳数和等动态更新。为了将该奖励机制应用于BN 模型作为节点的分类标准,本文将奖励值按相同的间隔离散化为k10个等级分别对应投递等级X10的等级越高,表明节点有更大的概率将消息转发到目的节点,因此使用该动态奖励机制当作节点的分类标准可以帮助路由算法做出正确的路由决策。在进行路由决策时,携带消息的节点可以通过BN 模型推理并预测其邻居节点的投递等级,由此来决定是否将消息转发到邻居节点。
3 结构学习及消息转发
当基于属性向量X的训练数据集收集完成后,接下来的任务就是进行BN 结构的训练和学习。本节将在K2GA算法的基础上研究多时间段的最优划分和各时间段对应的BN 结构学习问题。
3.1 优化问题
设D表示时间范围为[0,τ)的全部训练数据集。现要将总时间范围划分成多个时间段;令σ表示要划分的时间段个数表示第k个时间段,其中,分别表示该时间段的起始时间和终止时间,且。根据时间段将数据集D划分为σ个子集,Dk表示在数据集D中处于第k个时间段的数据集。利用K2GA 算法,可以优化得到数据集Dk对应BN 结构Gk及其CH(Cooper-Herskovits)评分函数值Fk。这里,K2GA 算法采用的CH 评分函数是BN 结构学习中用来判断学习结果优劣的常用指标之一[24]。故上述过程可表示为

对于多时间段BN 结构学习,本文定义σ段BN的平均CH 评分值为F,以最大化F作为问题的优化目标,即
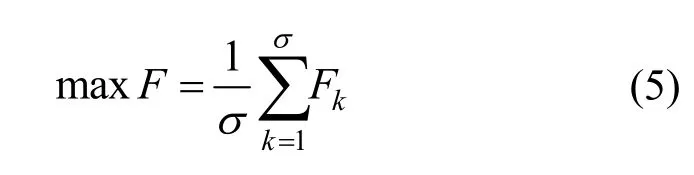
为了求解上述问题,需要寻找一个使F值最大化的时间段划分方案及相应的BN 结构。当σ较小时,可以采用遍历算法来搜索;但是当σ较大时,遍历算法的开销将呈指数上升。为了降低算法的时间复杂度同时提高优化效率,本文提出了2 种多时间段BN结构学习算法:BS-K2GA算法和SA-K2GA算法。
3.2 BS-K2GA 算法
BS-K2GA 算法以二分搜索方式进行多时间段BN 结构的学习和优化。该算法首先寻找最佳分割点,将整个时间范围分成2 个时间段;然后对这2 个时间段分别进行二分搜索;如此迭代,直到达到所需要的时间段划分个数。
算法1 给出BS-K2GA 的伪代码,其输入为需要的时间段划分个数σ和训练数据集D,输出为表示第k个时间段的解(包括时间段的划分、BN结构和评分等)。步骤1)~步骤3)利用K2GA 算法获得在全部数据集D下的初始解u1。步骤4)~步骤9)通过循环迭代从集合U中取出uk并利用BSplit算法求得最佳的二分方案,并将结果并入集合U中。由于评分较低的uk可能具有更大的优化空间,因此步骤5)每次都选取评分最低的uk进行二分。最后,步骤10)返回结果集U。BSplit 算法的伪代码由算法2 给出,该算法对输入的当前解uk进一步划分,得到最佳二分方案ul和ur。步骤1)以tc为分割点将数据集Dk二分为Dl和Dr;步骤2)~步骤3)调用K2GA 算法分别求得数据集Dl和Dr对应的BN 结构及其评分;步骤4)求最佳平均评分最高的最佳分割点步骤5)~步骤7)生成并返回最佳的二分解。由于将数据集Dk二分所生成的BN 能更好地描述实际规律,因此BSplit 算法总能找到一个较优的二分方案。

下面,简要分析BS-K2GA 算法的时间复杂度。先根据K2 算法[25],得到K2GA 算法的时间复杂度为O(wzhg2),其中,w为遗传算法的迭代次数,z为遗传算法的种群数,h为数据集中的样本数,g为用于构建BN 的属性个数。对于BS-K2GA 算法,设Δτ表示搜索的时间段步长,则每次最佳分割点的计算时间复杂度为O(τ/ Δτ),而总的时间段划分个数为σ。由此,得到BS-K2GA 的时间复杂度为O(στwzhg2/Δτ)。BS-K2GA 算法以贪心策略进行时间段划分,时间复杂度较低,但是该算法容易陷入局部最优,无法找到最优的时间段划分方案。
3.3 SA-K2GA 算法
模拟退火(SA,simulated annealing)算法[26]是一种通用的随机搜索算法,其基本思想为从某一较高初温出发,以热力学统计概率在解空间中随机寻找目标函数的最优解,使算法能概率性地从局部最优解中跳出,并随着温度参数的不断降低最终趋于全局最优。在SA-K2GA 算法中,设温度参数为C0,目标函数值为多时间段BN 的平均评分F。首先随机将整个时间范围[0,τ)划分为σ个时间段,通过K2GA 算法求得该划分下多时间段BN 结构及其平均评分F的解;根据当前温度和该解的评分值以一定概率接收其作为当前解;降低温度并对当前的时间划分做随机扰动得到新的划分方案,重复上述过程,直到温度降低为最低值。此时,算法的当前解即最优解。
算法3 给出了SA-K2GA 算法的伪代码,其中,C0表示初始温度,Cmin表示最低温度,λ表示温度的变化率,Δt表示时间段调整的步长。步骤1)~步骤7)生成初始化解。首先在整个时间范围[0,τ)内随机产生的σ-1个时间分割点其中根据Tc将数据集划分成σ个子集{D1,D2,…,Dσ},其中,Dk对应第k个时间段[t k-1,tk),k∈[1,σ],t0=0,tσ=τ。然后利用K2GA 算法计算Tc划分下的BN 结构及其CH 评分产生当前解U。步骤9)~步骤10)以步长Δt对Tc中的分割点进行随机扰动产生新的划分。同理,步骤11)~步骤15)利用K2GA 算法计算划分下的新解U′。步骤16)~步骤19)计算解U′和U的目标函数值之差ΔF。若ΔF>0,则直接将U′赋值给U,即接受新解为最优解当前解;否则,采用Metropolis准则[27]根据exp(-ΔF/C)>rand以一定概率接收新解,其中,rand 为能产生[0,1]范围实数的随机函数。步骤20)用于降低当前温度C,然后循环执行上述过程,直到C小于Cmin,步骤8)的循环条件不再满足,循环结束。步骤22)返回的解即当前的最优解。


由于SA-K2GA 算法在温度变化率λ的控制下由初始温度C0降至最低温度Cmin所需要执行的轮数为且在每轮循环中利用K2GA 算法计算σ个时间段BN 结构的评分,因此SA-K2GA算法的时间复杂度为。与BS-K2GA 算法相比,SA-K2GA 的算法复杂度略高,但后续仿真实验结果表明,SA-K2GA 的性能要优于前者。
3.4 消息转发策略
为了实现本文提出的VDTN 路由算法,首先需要收集所有车辆的历史信息并生成训练数据集。然后使用BS-K2GA 或SA-K2GA 算法训练学习最优的时间段划分方案和各时间段最优的BN 结构。然后,基于优化后的多时间段BN 模型,通过BN 推理预测VDTN 中车辆节点的消息投递等级X10,由此决定消息的转发策略。而对于某一确定时间段的BN 模型,X10推理方法如下。

由此,本文提出基于多时间段优化BN 的VDTN 路由算法,其消息转发策略如下。
设携带消息的当前车辆节点与另一车辆节点相遇,则当且仅当满足以下2 种情况时,当前车辆节点才会把消息转发给相遇车辆节点。
1) 相遇节点为消息的目的节点时,消息将被直接投递到目的节点。
2) 当相遇节点非消息的目的节点时,两车将根据所处的时刻,选择相应时间段的BN 模型,并利用式(6)推理得到各自的投递等级X10。若当前节点的X10低于相遇节点的X10,则将消息转发给相遇节点;否则当前节点不进行消息转发,继续携带消息移动,直到遇见目的节点或投递等级更高的相遇节点。
4 实验结果与分析
4.1 移动轨迹与仿真参数
本文进行仿真实验所使用的数据来自巴西里约热内卢公交系统所记录的真实公交车运行轨迹。该数据是从CRAWDAD[29]获得的,其中包含了覆盖1 200 km2、涉及17 723 辆公交车的运动轨迹。尽管原始数据集提供了一天内完整的24 h 移动数据,但为了使实验环境更接近真实的生活环境,这里选取其中98 辆车在上午7 点到下午7 点的数据,并将范围缩小为35 km×25 km 的区域内,其中包含了这个城市较繁华的商业区。
本文中的多时间段优化BN 结构学习算法以及团树构造算法是使用MATLAB[30]软件来实现的,同时该算法调用了BN 工具箱获取BN 的CH 评分值。当离线完成BN 学习以及团树构造后,使用DTN仿真软件THE ONE(the opportunistic network environment simulator)[31]对本文提出的路由算法进行仿真实验。仿真参数如表1 所示。

表1 仿真参数
4.2 生成训练数据集
由于BN 结构学习需要VDTN 中车辆的属性数据,因此需要先采集车辆的历史数据构造训练数据集。虽然数据集包含一个月的数据,但由于采集轨迹数据时的设备故障,导致期间有数天的轨迹数据不连续,因此本文使用了其中14 天的数据来进行仿真实验。从14 天的轨迹数据中随机选取10 天的数据作为训练集,剩下4 天的数据作为测试集。在构造训练数据集的仿真实验中,VDTN中车辆的路由算法设置为基于泛洪方式的Epidemic 算法,这样能获得更全面的路由信息。而动态奖励机制的参数设置为ψ d=600,ψ l=100,R=50,Rc=100,ρ=0.25。车辆的属性数据表起初为空表,当车辆相遇时,车辆当前的属性值(X1~X9)以及奖励值就被记录到属性表内。当仿真结束时,就可以取出所有车辆本地存储的属性表合并成训练数据集了。
4.3 性能指标
为了评价VDTN 路由算法的有效性,通常采用以下3 个指标来衡量路由协议性能的好坏。
投递率:成功投递到目的节点的消息数目与源节点产生的消息个数之比。
投递时延:成功投递到目的节点的消息所经过的平均时间。
开销:在消息成功投递到目的节点时,网络中所产生的平均消息副本个数。
在实验中,本文主要采用消息报文的生存时间(TTL,time to live)作为变量对上述性能指标进行评价,这是路由协议中的重要参数之一。
4.4 参数σ 取值分析
本节主要探讨参数σ对多时间段贝叶斯网络性能的影响。通过改变参数σ的取值,利用SA-K2GA 算法学习不同的BN 结构。根据学习获得的BN 结构设计VDTN 路由算法,并对其性能进行对比实验,如图3 所示。

图3 不同时间阶段BN 路由算法性能比较
从图3(a)可以看出,随着σ的增大,多时间段贝叶斯网络路由算法的投递率不断升高,σ=3 时的投递率比σ=1 时的投递率高5%,然而当σ=4 时,虽然在TTL<100 时,投递率较高,但是随着TTL 的增加,投递率反而低于σ=3 时。这是因为较大的σ对时间段的划分可能过细,容易造成BN 模型的“过拟合”问题。从图3(b)可以看出,随着σ的增大,消息投递的平均时延不断减小。同理,当σ=3 时,平均时延达到最低,而σ=4 的平均时延比σ=3 并未有所改进。从图3(c)可以看出,随着σ的增大,路由算法的网络开销不断降低,当σ=3时,网络开销达到较低水平,而σ=4 的网络开销相比于σ=3 的改进并不明显。综上所述,三阶段BN 路由算法可以更准确地学习到车辆的移动模式,在消息转发上的性能也更好。本文在后续实验中均取时间段个数σ=3。
4.5 BN 多时间段优化划分算法的比较
本节主要比较不同的BN 多时间段优化划分算法对VDTN 路由性能的影响。除了本文提出的BS-K2GA 和SA-K2GA 算法,实验还比较了以下2 种算法。
Opt 算法:利用K2GA 算法通过全局遍历得到评分F取值最高的σ阶段BN 结构。
Avg 算法:将整个时间范围等分为σ个阶段,再利用K2GA 算法学习得到σ阶段BN 结构。
图4 给出了采用不同BN 多时间段优化划分算法的VDTN 路由性能比较结果。从图4(a)可以看出,采用Opt 的路由算法在投递率上表现出了最优的性能,而SA-K2GA 的投递率仅次于Opt。当 TTL=120 min 时,SA-K2GA 的投递率比BS-K2GA 高3%,比Avg 高7%。由于采用Opt的三阶段BN 是通过遍历得到的,因此该网络结构具有更高的评分,相应的投递率也最高。SA-K2GA 的投递率与Opt 相差不大,从侧面说明了SA-K2GA 算法确实能获得较优的多时间段BN划分方案。BS-K2GA 的投递率低于SA-K2GA,因为BS-K2GA 基于简单的贪心算法进行求解,通常无法获取最优的划分方案。但BS-K2GA 算法采用了将评分最低的BN 所对应的时间段进行二分策略,因此其投递率要明显高于采用时间等分策略的Avg 算法。同理,如图4(b)所示,投递时延由低到高的算法依次仍为Opt、SA-K2GA、BS-K2GA 和Avg。这里,通过Avg 算法得到的BN 对节点投递等级的预测效果最差,无法筛选出较优的中继节点,导致消息传递的时延最高,而Opt 和SA-K2GA 的BN 则表现出了较强的节点投递等级预测能力。
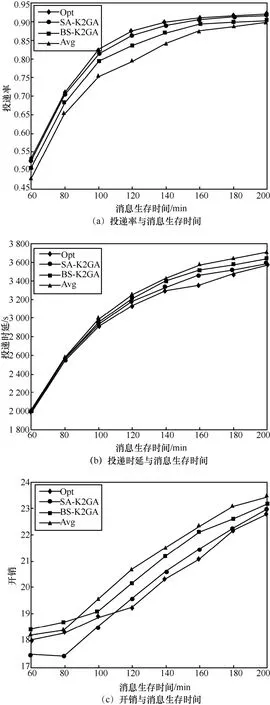
图4 采用不同BN 多时间段优化划分算法的路由性能比较
图4(c)表明Opt 和SA-K2GA 的路由开销都比较低。当TTL≤110 min 时,SA-K2GA 的开销低于Opt;当TTL>110 min 时,Opt 的开销更小。综上所述,虽然采用Opt 算法的VDTN 路由性能总体最好,但其采用的遍历算法复杂度太高,当σ较大时,该算法将无法在多项式时间内求得划分方案。SA-K2GA算法将模拟退火与K2GA 算法相结合降低了时间复杂度,并且在路由性能上媲美Opt,因此SA-K2GA算法对求解多时间段划分方案是可行有效的。
4.6 与经典路由算法的比较
本节将所提出的VDTN 路由算法与经典的Epidemic[9]、Prophet[11]以及基于朴素贝叶斯的(NB,naive Bayesian)路由算法[15]进行性能比较,其中,多时间段优化采用SA-K2GA 算法。
图5 为各种路由算法在不同TTL 条件下的性能仿真结果。图5(a)表明SA-K2GA 的投递率高于Prophet 和NB。当TTL=100 min 时,SA-K2GA的投递率比Prophet 高10%,比NB 高8%。因为SA-K2GA 不仅考虑到了消息传递的历史信息,还可以学习到在不同时间段车辆的移动模式。NB在投递率上的表现也优于Prophet,说明NB 也能较好地学习车辆的移动模式,但其条件独立性假设限制了其性能。另外,由于Epidemic 采用泛洪策略进行消息转发,因此其投递率最高。在图5(b)中,SA-K2GA 的投递时延低于Prophet 和NB。这是因为在SA-K2GA 中节点的投递等级是根据节点的奖励值来划分的,其中,在投递奖励值中,距离目的节点越近或传输时延越低的中继节点都能得到较高的奖励值,因此路由算法就选择时延较低或跳数较少的传输路径进行消息转发。同理,Epidemic 的投递时延也是最低的。从图5(c)可以看出,随着TTL 的增加,路由开销总体上呈上升趋势。但是与Epidemic、Prophet 和NB 相比,SA-K2GA 的开销最低,因为SA-K2GA 只会将消息转发给投递等级较高的中继节点。但是,Epidemic 的开销却明显高于其他算法。

图5 各种路由算法在不同TTL 条件下的性能比较
图6 给出了各种路由算法在不同VDTN 节点缓存大小条件下的性能仿真结果。如图6(a)所示,随着节点缓存的不断增加,消息的投递率也在不断上升。当节点缓存为17 MB 时,SA-K2GA 的投递率比Prophet 高近7%,比NB 高4%。如图6(b)所示,SA-K2GA 的投递时延明显低于Prophet 和NB,因为其改进的奖励值机制将消息的投递时延也考虑在内。如图6(c)所示,随着节点缓存的不断增加,SA-K2GA 的网络开销不断下降,而且相比Epidemic、Prophet 和NB,SA-K2GA 具有最低的路由开销。
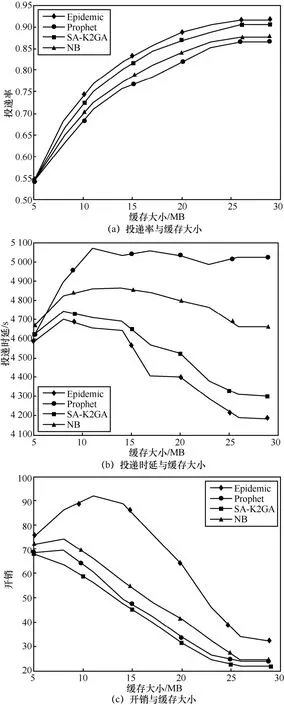
图6 各种路由算法在不同节点缓存大小条件下的性能比较
5 结束语
本文研究VDTN 的消息转发问题,根据车辆节点移动模式的时段性以及节点属性之间的依赖关系,提出并建立了改进的多时间段BN 模型。为解决多时间段优化划分和BN 结构学习问题,提出了BS-K2GA 和SA-K2GA 这2 种算法。在此基础上,提出了基于多时间段优化BN 的VDTN 路由算法。仿真实验结果验证了多时间段BN 模型及其优化算法的可行性和有效性。同时,本文提出的VDTN路由算法也具有高投递率、低时延和低开销的性能表现。
在未来的工作中,笔者将继续优化模型,如对车辆属性的选择及其离散化标准进行优化,进一步提高算法效率;同时,研究VDTN 的时变特征,建立基于时序概率的动态BN 模型等。
猜你喜欢
工业设计(2023年1期)2023-03-02 10:08:12
中外文摘(2022年13期)2022-08-02 13:46:16
今日农业(2020年13期)2020-08-24 07:35:24
电子制作(2019年23期)2019-02-23 13:21:12
测控技术(2018年6期)2018-11-25 09:50:10
意林(2017年8期)2017-05-02 17:40:37
系统工程与电子技术(2016年7期)2016-08-21 13:59:18
电测与仪表(2016年17期)2016-04-11 12:38:28
红领巾·萌芽(2015年5期)2015-06-16 02:35:40
医学研究杂志(2015年5期)2015-06-10 06:43:26
