
基于区块链的真实世界数据共享系统研究
2022-01-12 04:45刘尚麟廖思捷杨春霞
信息安全研究 2022年1期
刘尚麟 廖思捷 杨春霞 范 佳
1(工业信息安全(四川)创新中心公司技术研究部 成都 610041)2(中国电子科技网络信息安全有限公司区块链研究中心 成都 610041)
(sccdhanshan@sohu.com)
真实世界数据,指的是由非随机对照研究(简称RCT)而来的临床数据,主要来源于电子病历、医保索赔、患者报告结果、患者和疾病登记、前瞻性观察研究、生物标志物研究、可穿戴设备传感器、移动健康数据等.随机对照研究被定义为最高级别的循证证据,经常作为药品审批上市、临床诊疗指南更新的证据.根据以往规定,新药获准上市要经过临床试验RCT周期Ⅱ期、Ⅲ期等,过程至少需要8~10年.相比之下,真实世界临床数据来源更具多样性,可以评价药械的实际效果和安全性,并可观察到更长期的治疗效果以及不同特征人群的效果,能够为新药械上市开辟新的途径,带动医疗科技创新[1].
真实世界数据需要转化为真实世界证据才会发挥价值.要完成这种转化必须进行数据整合,同时解决数据可溯源性、隐私保护等问题.因为真实世界数据必须经过整合以后才能使用,这牵扯到同一数据库中数据表内容整合、不同数据库内容的整合,同时对缺失数据进行补全.数据整合后必须解决以下2方面的问题:
1) 可溯源性.整合数据需具备可追溯性,为分析结果提供可信证据.让分析结果可追溯,可查找原因.
2) 隐私保护.真实世界研究的数据,如患者的信息有可能会成为长期的研究资料,患者本身在某种程度上已成为“受试者”, 因此真实世界研究需要符合伦理要求、知情同意等,必须提供完善的隐私保护机制,防止用户隐私泄露.
我国医疗数量大,加上就诊医院、地域的不同,易形成信息孤岛,要实现开放利用需要突破数据可溯源性、隐私保护等关键技术,打通数据壁垒,将数据整合形成全面的多维数据链条,构建具有可溯源和隐私保护能力的真实世界数据共享体系.
本文的贡献在于对上述传统技术的增强:对于文本和数值型数据溯源,设计了最小哈希(MinHash)和局部敏感哈希(LSH)算法进行相似性比较,查找世系证据;对于隐私保护,提出了基于控制流图的程序身份指纹提取及验证算法,同时使用区块链对数据哈希特征指纹、计算程序指纹进行登记,实现数据溯源以及处理程序溯源.另外,设计了容器和虚拟机双层隔离保护的隐私计算隔离区,将加密发布的真实世界数据下载到隔离区内,解密后分析处理,用后数据立刻销毁,隔离区外不出现明文,从而防止个人隐私泄露.
1 总体框架和工作流程
真实世界数据共享体系框架图如图1所示:

图1 真实世界数据共享体系框架图
主要包括数据整合治理、加密发布存储、数据分析程序应用和区块链等模块,其中:
数据整合治理.主要按照标准表格,对来自各种数据源的数据进行内容整合导入,补全缺失数据.数据补全采取datawig机器学习算法[2].
补全数据.使用RCT数源的,需要记录数据源URL(数据表),补全之前的数据集合最小哈希MinHash;补全数据集合的最小哈希和补全算法.并采用区块链登记其最小哈希;
加密发布存储.采用分布式存储系统IPFSOrbitDB数据库,将标准化数据加密发布,提供目录方便授权管理以及数据使用.
隐私保护区.将通过授权的加密数据下载到隔离区,解密后采用分析程序进行处理,计算结果输出后,解密明文用后立即销毁,防止数据泄露.同时,使用区块链[3]对数据分析程序指纹特征和访问用户进行登记,实现数据使用可证、计算结果可信.
区块链模块.采用Hyperledger进行存证,登记的原始数据存储于IPFSOrbitDB数据库.
2 算法设计
2.1 数据溯源算法
文本和数据类数据溯源采用基于最小哈希的局部敏感哈希算法,计算数据相似度,追溯数据的演变过程[4].
算法1.数据溯源算法.
输入:文件(文本或者数据);
输出:LSH相似度.
计算过程:
第1步.数据分割k-shingles:将数据文件切分为小数据集合.
第2步.最小哈希MinHash降维:将数据集合转化为短签名,将数据比较转化为签名比较.
第3步.局部敏感哈希(LSH)降维,最小哈希MinHash得到的签名数据集依然很大,通过LSH进一步缩减处理的数据量.只是比较存在高相似概率的签名.下面重点介绍MinHash和LSH.
Jaccard系数是常见的衡量2个向量(或集合)相似度的度量:A,B两个集合,其相似性Jaccard系数为Jaccard(A,B)=(A∩B)/(A∪B),其值域为[0,1].
Jaccard(A,B)可采用MinHash的计算,步骤如下:
1) 对A,B的n个维度,作一个随机置换(即对索引i1,i2,…,in随机打乱).
2) 分别取向量A,B的第1个非0行的索引值,即为MinHash值,得到A,B的MinHash值后,可以有以下重要结论:
P[MinHash(A)=MinHash(B)]=
Jaccard(A,B).
具体计算时,首先会对向量A,B作m次置换permutation(m一般为几百或更小,通常远小于原向量的长度n),每一次置换permutation得到MinHash值的映射记为h1,h2,…,hm,那么向量A,B就分别被转换为2个签名signature向量:
Sig(A)= [h1(A),h2(A),…,hm(A)],
Sig(B)= [h1(B),h2(B),…,hm(B)].
向量A,B的Jaccard相似度:
Jaccard(A,B)=(Sig(A)∩Sig(B))/
(Sig(A)∪Sig(B)).
计算Sig(A)和Sig(B)与向量MinHash值相等的比例.
局部敏感哈希LSH算法,在MinHash签名signature向量的基础上,将每一个向量分为几段,称之为band,每一个向量,每一段有r行MinHash值.计算任意一个band的哈希,放到哈希桶中,作为候选相似数据集进行比较.
设2个向量的相似度为t,则其任意一个band所有行相同的概率为tr,至少有一行不同的概率为1-tr, 则所有band都不同的概率为(1-tr)b,至少有一个band相同的概率为 1-(1-tr)b,令s≈(1/b)1/r,s(一般由实验或者经验确定)作为阈值,决定将数据分到相同的哈希桶中,作为LSH计算相似度的候选集合.
同源数据可以定义为LSH相似度超过一定值的数据文件.整合治理其本质就从各种数据源抽取内容填写标准化数据表,同时补全缺失内容.真实世界数据可溯源性就是由系列同源性证据组成的链条.基于最小哈希局部敏感哈希数据相似度登记以及查找溯源,计算过程如图2所示:
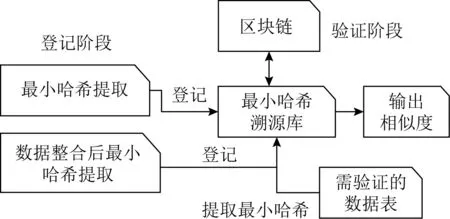
图2 基于最小哈希局部敏感哈希数据溯源流程
溯源验证算法分为登记和验证2个阶段:
1) 登记阶段.主要涉及整合过程的数据源表.
计算获取源数据MinHash哈希Hmin,将Hmin,k-shingles参数登记到数据库,作为数据溯源依据.
2) 验证阶段.主要涉及整合后的数据表、数据世系(从源系统抽取数据开始,经过数据转换到最终的数据形成的过程信息)证据.
将需要溯源的数据表计算最小哈希,在已登记所有数据的最小哈希集合中,搜索计算TOP-3数据集合及LSH相似度作为同世系数据依据.
2.2 隐私保护技术
2.2.1 程序身份指纹提取及验证算法
程序身份指纹基于控制流图实现.控制流图(CFG)是有向图,代表了程序执行过程中会遍历到的所有路径,它用图的形式表示程序所有基本块执行的可能流向, 也能反映程序实时执行过程.主要研究了常用的Python程序身份提取验证算法.
Python程序CFG使用执行函数以及函数调用关系构建,具体过程如图3所示.
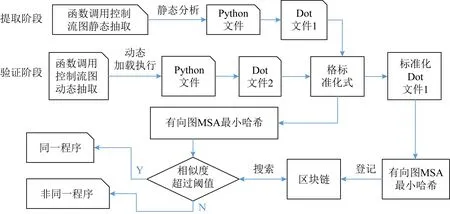
图3 Python程序动态验证步骤示意图
算法2.程序身份指纹提取及验证.
输入:Python可执行文件;
输出:Python文件指纹特征相似度.
算法过程:分为提取和验证2个步骤.
1) 提取阶段
① 采用静态分析工具(Pyan)提取1个或多个Python源文件,整理形成所有对象以及函数之间的调用关系CFG dot格式文件文件1,对dot图文件的顶点以及边的命名进行格式标准化(静态和动态CFG提取由于采用软件包不同,因此形成的图的描述会有差异,标准化后便于比较);
② 使用软件包graph-tool计算标准化dot文件文件中有向图的MSA以及最小哈希HfGC1,作为程序特征指纹登记写入区块链.
2) 验证阶段
① 采用pycallgraph软件包动态提取程序执行过程中函数以及函数之间的调用关系CFG,输出dot格式文件文件2,标准化后计算文件2中有向图的MSA以及最小哈希HfGC2;
② 搜索区块链登记的所有最小哈希文件集合、 TOP-3程序及LSH相似度,作为程序指纹验证依据.
2.2.2 数据用后即毁技术
隐私保护区是基于kata虚拟机和容器2层隔离环境,采用Web jupyter的开放交互式方式,安装数据防泄露系统,对数据流向进行管控,加密数据可以从发布存储设备下载到该环境,进行解密计算,计算结果经过审计后输出到指定网盘,解密明文使用后销毁;数据使用过程都基于区块链生成了不可篡改的记录,可以像“录像机”一样回播数据使用细节,进行追责.
3 实验结果
3.1 数据溯源实验
使用美国data.word医疗数据集Medical-records-10-yrs,该数据集包含大量患者的实验室结果、诊断、用药详细数据.选用medication_fulfilment.csv数据表的pharmacy_name列进行文本数据补全实验,选用dose列进行数值补全实验.文本数据实验步骤如下:
1) 采用Order_ID逆序排序,计算文档最小哈希H1,写入数据库,使用区块链存证;
2) 保持Order_ID逆序排序,随机选10%,删除pharmacy_name列的数值;
3) 采用datawig机器学习文本补全算法,对数据表进行补全,计算数据表最小哈希H2;
4) 在数据库中,搜索TOP-3 LSH相似度文件.
数值数据实验步骤和上述步骤相同,只是数据列选择为dose列,数据补全算法选用datawig机器学习数值补全算法.实验结果如表1所示:
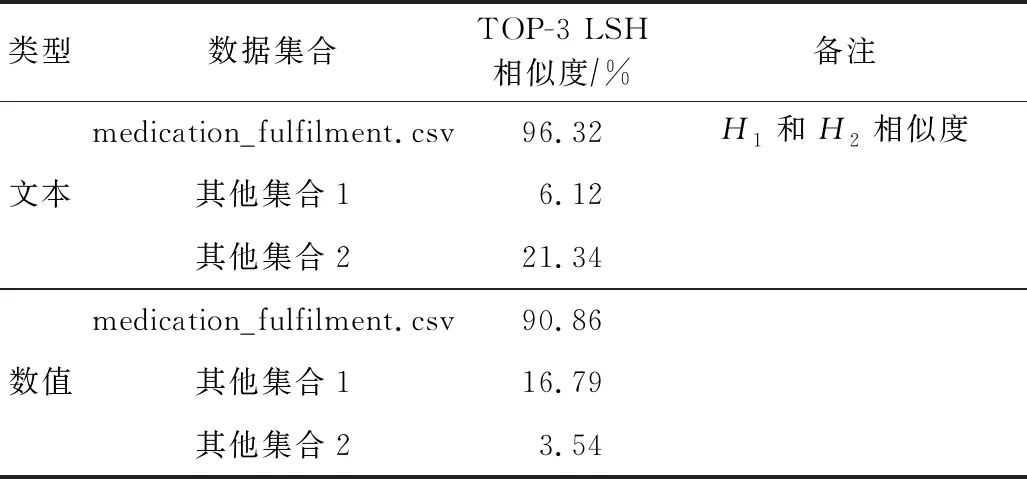
表1 数据溯源实验结果
3.2 程序身份指纹验证实验
步骤如下:
1) Python scikit-learn线性回归算法程序skregression.py,静态提取CFG图,计算最小哈希指纹特征集合Hs,写入数据库进行登记,基于区块链存证;
2) 运行skregression.py,动态提取CFG图,计算最小哈希指纹Hd,在数据库中,搜索TOP-3 LSH相似度文件.
程序身份指纹验证实验结果如表2所示:

表2 程序身份指纹验证实验结果
3.3 实验结果分析
实验对以下2点进行了验证:1)文本和数值型数据最小哈希和局部敏感哈希算法世系证据搜索,补全数据;2)Python程序控制流图CFG最小哈希和局部敏感哈希相似度.
从结果来看,文本数据世系采用TOP-3 LSH搜索算法,可保证已登记数据世系证据的准确性.数值型数据其相似度较文本型数据低6.6%,主要原因是,将数值当作文本处理,而没有考虑数值型数据分布特征.对于数值型,可考虑使用DTW(dynamic time warping)[5]动态时间规整等数值相似性比较的专门算法,以提高准确性.
Python程序控制流图CFG MSA最小哈希和局部敏感哈希相似度算法,同一程序,静态提取的指纹和动态提取的指纹相似度为97%,采用TOP-3 LSH搜索算法可保证已登记数据计算程序指纹验证准确性.没有达到理论相似度(99%)的原因是,提取工具的CFG图根节点表达差异以及程序动态执行路径.
4 相关工作
数据溯源方法可归纳为2大类,即基于批注(annotation-based)的方法和非批注(non-annotation-based)的方法.基于批注的方法将每个数据项变换为三元组标签,通过在数据处理过程中进行标签传播,实现数据的勾连,以支持数据溯源.对于非批注的方法,在处理数据的过程中不需要对源数据和目标数据(处理的结果)附加额外的信息,但是,需要日志库记录存储、计算等过程中对数据进行了何种处理[6].非标注的数据溯源可用于数据变换、数据集成过程的调试,当源数据与目标数据之间的数据模式改变时, 非批注方法具有较大实用价值.本文使用了文本和数值型数据基于MinHash的LSH相似度世系证据搜索算法,利用数据本身LSH相似度,参考区块链数据溯源研究成果[7],记录数据世系及演化过程.
程序函数CFG信息安全领域主要用来识别恶意软件[8],本文把这种方法扩展到整个程序,用来提取整个程序的指纹特征.为了降低特征维度,引入了MSA,并计算其最小哈希和局部敏感哈希相似度算法,来比较程序文件相似度.
在隐私保护方面,当前常用手段是数据防泄露技术[9],通过文本和数据特征识别,结合深度检测技术,防止敏感数据泄露出安全域.本文参考云安全虚拟架构[10],采用容器和虚拟机双层隔离保护机制,结合用后即毁,降低数据计算环节泄露风险.
5 结 语
文本和数值型数据基于MinHash的LSH相似度世系证据搜索算法,Python程序控制流图CFG MSA基于MinHashLSH相似度比较算法,结合容器和虚拟机双层隔离保护隔离区内数据分析、用后数据立刻销毁,辅助基于区块链的数据溯源、数据分析程序指纹验证,可以跟踪数据演变以及被哪些计算处理,可为真实世界数据共享提供一种有效的解决思路.
猜你喜欢
现代仪器与医疗(2022年2期)2022-08-11
承德医学院学报(2022年2期)2022-05-23
中国现代医生(2022年6期)2022-04-23
电脑爱好者(2021年8期)2021-04-21
电脑爱好者(2021年1期)2021-01-13
电脑爱好者(2020年20期)2020-10-22
党员生活·下(2020年3期)2020-04-20
党员生活·下(2020年2期)2020-04-20
党员生活(2020年2期)2020-04-17
中国中药杂志(2017年2期)2017-03-25
