
涉及隐私侵占类APP识别与分类方法研究*
2022-01-05 14:25:46邱秀连彭艳兵
网络安全与数据管理 2021年12期
易 黎,邱秀连,马 芳,彭艳兵,程 光
(1.南京烽火星空通信发展有限公司,江苏 南京210019;2.东南大学 网络空间安全学院,江苏 南京211189)
0 引言
中国互联网络信息中心(CNNIC)发布的第48次《中国互联网络发展状况统计报告》表明,截至2021年6月,中国手机网民的数量已高达10.07亿,如此巨大的用户量具有不可估量的商业价值,而其背后如此巨大的用户个人信息在当前信息时代环境下更是蕴含着巨大价值[1]。但在实践中,如此众多的用户使用量其问题也接踵而至,最明显的是关于用户个人信息泄漏事件层出不穷,对用户个人信息的侵害可谓无孔不入,智能手机APP为用户带来便利的同时,也成为个人信息泄漏的根本原因之一。
依据敏感程度和安全性不同,用户个人信息内容分为用户核心隐私信息、用户的重要隐私信息与用户的普通隐私信息三个类别[2]。其中关于通讯录联系人、手机账号、账户密码、聊天记录以及定位用户当前所在地点等内容被划分为核心隐私信息;关于手机发送接收短信信息、拨通电话、调用手机自带的摄像头权限等内容信息归属于重要隐私信息一类;最后用户的Wi-Fi连接无线网络、蓝牙连接无线设备、手机数据网络流量使用等信息属于普通隐私信息。
在实际应用中,往往不仅想判别该APP是否有隐私侵占行为,更希望对该APP做深入挖掘,即进行类型的判别。在已发现的电信网络新型违法犯罪所使用的移动APP的类型中,有下述三种常见的侵占隐私类APP:
(1)“套路贷”APP
该类型APP除了作为套路贷活动的签约、借款、还款平台,还会在受害人手机中索取权限获取机主的短信、通话记录、通讯录、照片视频等各类隐私信息,并在未经允许的情况下收集上传,从而进行后续的催收骚扰或敲诈勒索违法行为[3]。
(2)“裸聊”APP
“裸聊”APP主要方式是与受害人进行视频聊天,欺骗诱导受害人安装恶意APP,录制受害人隐私音视频,同时收集并上传受害人手机中的短信、通话记录、通讯录、地理位置以及照片视频等各类隐私信息[4]。
(3)网络赌博APP
诱导境内受害人安装网络赌博APP,进行所谓“在线直播”、“线上下注”等违法活动,犯罪团伙通过操纵后台、修改数据以及直接下线跑路的方式侵吞受害人的钱财。部分APP会收集受害人手机中隐私数据,用于开展“套路贷”等其他类型违法犯罪行为。
为此,针对现在市面上较常见的非法侵占隐私类移动应用的识别问题,提出一种基于多模态特征的多策略组合识别算法。通过静态和动态检测相结合,针对移动应用APP进行先分类后判别的模式分析,包含基本类别信息、是否通信传输行为、是否境外服务器、外在舆情、涉及敏感权限等多维度安全检测。
1 基于Word2vec+CNN的APK分类方法
文本特征提取是文本挖掘中非常重要的一个环节,无论是聚类、分类还是相似度任务,都需要提取出较好的文本特征,才能取得较好的结果[5]。特征抽取的主要功能是在不损伤文本核心信息的情况下尽量减少要处理的单词数,以此来降低向量空间维数,简化计算并提高文本处理的速度和效率。文本语料的不同文本特征提取方案也会不同,例如在长篇幅的对话文本中,上下文衔接语义非常重要,用基于计数的模型(如词袋)处理单词不能捕获单词之间的语义关系,不能单用TF-IDF这类词袋模型的提取方案。
本次实验数据的xml文本、APP名称文本均具有上下文的语义信息,所以需要使用基于神经网络的特征提取方法。首先需要对文本进行预处理,处理流程如下文。
1.1 文本预处理
(1)删除标签:利用BeautifulSoup库提取xml文件中所有的文本内容,丢弃标签。
(2)删除特殊字符:使用正则表达式过滤非字母和中文的其他字符。
(3)切分句子:将长文本切分为中英文片段,再对每个片段判断中英文,对于纯英文片段利用wordninja包切词;对于含有中文的片段,利用jieba进行切词。
(4)删除干扰词:将APP中经常出现的如“同意、更新、返回”此类不能表征APP内容的词汇列入白名单,在完成切词后滤除掉白名单词汇。
另外,一些文本的处理操作可以当做调优参数对待,例如是否对切词后的集合去重。
1.2 Word2vec提取特征
Word2vec是一种基于预测的深度学习模型,用于计算和生成高质量的、连续dense的单词向量表示,并捕捉上下文和语义相似性[6]。本质上,这些是无监督的模型,可以接收大量的文本语料库,创建可能的单词词汇表,并为表示该词汇表的向量空间中的每个单词生成dense的单词嵌入。通常可以指定单词的嵌入向量的大小,向量的总数本质上反映词汇表的大小。这使得该向量空间维度大大低于传统的词袋模型构建出的高维稀疏的向量空间。训练好词向量后,每篇文本经过文本预处理到转为对应词向量后,可以送入神经网络进行分类模型的训练和测试。具体的演化流程如表1所示。

表1 APP中短文本到词向量的转换过程
1.3 分类模型
将Word2vec训练好的词向量替代CNN的embedding层,利用类似于图像分类的原理,用不同大小的卷积核对特征矩阵做卷积,即可以提取到不同景深下的特征维度,然后合并不同景深的特征矩阵,经过max_pooling层后输出最终的分类类别,具体的网络结构如图1所示。

图1 基于文本分类的APP类型识别
2 多策略组合的隐私侵占识别方法
为了进一步对APP是否存在隐私侵占行为进行研究,在APP的类别得到有效识别后,将分类识别的结果作为新的特征输入到隐私侵占识别模型中,通过与通信传输行为、境外服务器、外在舆情(如百度贴吧是否涉及该APP)、涉及敏感权限等一批新的行为特征相组合,利用互信息、卡方分布等特征选择方法,逐步过滤并选择信息量较大的特征子集表征应用程序。
2.1 框架介绍
图2 所示为多策略组合的隐私侵占检测框架,该框架执行了四个主要的模块:行为特征抽取与量化、特征选择、初级检测和投票判别。行为特征抽取模块通过解压缩并反编译应用程序的APK文件,从AndroidManifest.xml和classes.dex文件中抽取多种行为特征数据[7]。数据特征会直接影响预测模型的性能,因此为了删除无用特征以构造具有最佳分类效果的特征集,特征选择模块使用三种过滤式特征选择方法,逐步过滤并选择信息量较大的特征子集表征应用程序。初级检测和投票判别模块设计一种复合分类模型,通过结合多种不同的基分类器,采用硬投票或者软投票的方式预测应用类别,从而降低了因分类算法对恶意行为的选择性所带来的误报、漏报等风险,提高了检测的准确性[8]。

图2 多策略组合的隐私侵占识别
2.2 特征提取与量化
根据对侵占隐私类APP的分析,本文首先提取了八个层面的行为特征表征应用程序,包括APP所属类别、回传通讯录特征、服务器是否境外、外网舆情信息、应用程序文件大小、APP来源、敏感权限、逆泛域名,表2所示为部分行为特征及其所属类别的介绍。

表2 可疑行为特征
将文本类特征转换为数值型特征,比如分类类别、APP来源、APP服务器位置;将定性自变量转化为离散的数值型变量;将定量自变量用标准化或者归一化处理。
2.3 特征选择
为了提高算法的性能,研究人员一般都会选用大量的特征表征数据,但并不是特征维度越高越好,在众多的属性中,一定含有冗余特征,如果不经处理直接进行分析,会影响模型的性能[9]。所以选择信息量较大的特征子集表征应用程序,不仅可以降低模型的复杂度并缩短模型运行时间,还可以提高模型的准确率和检测效率。
针对不同数值类型的特征,需要不同的特征选择方法。对于定性自变量对定性因变量的相关性检验,一般不采用相关系数法,可以使用卡方检验和互信息法进行检验;当自变量的数值为连续型时,可以使用简单的方差选择法,也可以采用互信息法的变迁模式最大信息系数法。
(1)卡方检验
卡方检验通过观察值和理论值之间的偏差来判断理论值的正确率是多少。如果正确率很大则被认为理论值是正确的,即假设成立,否则假设不成立。

卡方检验的基本公式,即x2的计算公式,为观察值和理论值之间的偏差:其中A代表观察频数(观察值),E代表期望频数(理论值)。通过计算x2数值以及自由度去对照卡方分布表,即可知道该假设条件下成立的概率值。自由度的计算公式通常为df=n-k。其中n为样本数量,k为被限制的条件数或变量个数。在本次实验中,对于一个N分类模型,自由度为1*(N-1)。
(2)互信息法
互信息法指选择一个能提供给类别尽可能多“信息”的特征子集,从而得到更多关于类别的“信息”,进而为分类提供帮助。通过计算某个特征与标签列的互信息熵的值,即可以得到该特征与分类的相关度。首选介绍下互信息的计算公式:

其中,I(X;Y)表示事件X和Y共同提供的信息,I(X;Y)值越大,代表该项特征对提供分类信息越多。
对于互信息法可以设置阈值,低于阈值的特征被认为对于分类无效,在训练模型时将丢弃该项特征。
(3)方差法
方差计算公式:

其中M为数据的平均数,n为样本个数,s2为方差值。如果某列特征值均为一个数值或者波动很小的话,对应的方差则越小,该特征对样本分类的贡献也越少,可以通过阈值滤除掉方差值较小的特征。阈值的选择理论上应该根据分类模型结果与阈值的曲线来确定,需要多次进行模型训练。在计算方差之前,需要将数值型的几列特征的值调整到相同的数量级,这里采用的是区间缩放法,将数值均缩放到[0,1]区间。
2.4 初级检测
特征选择模块之后,可以得到与应用程序类别相关性较高的特征子集。接下来为了得到更加精确的识别效果,选用了四种不同类型的分类算法对应用程序进行分类:逻辑回归算法(Logistic Regression)、随机森林算法(Random Forest)、bagging和adaboost,四种分类算法都被广泛应用于二进制分类问题。
2.5 投票判别
借助集成学习的思想,通过结合多种不同的分类算法创建了一种复合分类模型,即投票判别模型[10]。将不同的分类算法定义为基分类器,投票判别应用程序类别的基本原理被描述为:基于应用程序训练样本学习得到n个基分类器M1,M2,…,Mn,对于待分类应用程序,由n个基分类器对其进行类别预测,每个基分类器都对自己的预测结果进行投票,最终得票数最多的类别为投票判别结果。
采用硬投票的方式得到最终结果。硬投票又称多数投票,通过统计多种基分类器的预测结果,以少数服从多数为原则,最终输出得票数最多的类别。
3 实验过程及结果
3.1 实验数据
本文实验使用的数据集是包括小米应用商城、360手机应用市场、非凡软件站在内的多家应用市场数据,共包含765 821万条APP的有效动静态数据,筛选有效类别的APP类别有11种,分别为博彩、工具-购物、视频、交友直播、虚拟币、借贷、工具-兼职、色情、游戏、VPN、位置伪装多开。以初始类为基础再次筛选是否存在隐私侵占行为,筛选有效类别的数据集作为训练和测试样本,均按照8:1:1的比例进行训练集、验证集以及测试集的划分,实验数据集的分布情况如表3所示。
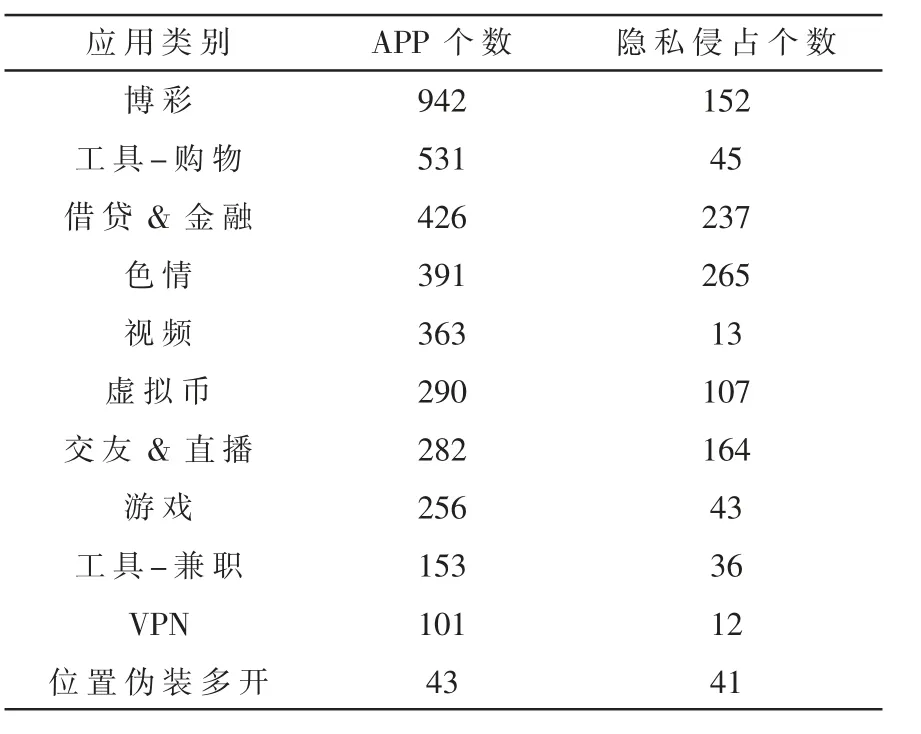
表3 各类应用数据分布
3.2 实验参数
基于Word2vec+CNN网络的APP基础类识别网络参数如表4所示。

表4 APP基础类识别网络参数
基于多特征融合的投票方式隐私侵占APP识别模型参数如表5所示。

表5 多分类器的网络参数
经过特征相关性检验,实验一共确定了18个特征值。其中,原始敏感权限对应了124维的特征矩阵,从124维的权限中筛选部分核心的权限作为特征,分别使用卡方检验和互信息法推荐12个敏感权限特征。
3.3 评价指标
系统完成建模之后,需要对模型的效果做评价。采用评价指标准确率(Precision)、召回率(Recall)、F值(F-Measure)来衡量分类模型的效果。
(1)准确率(Accuracy)
准确率(Accuracy)计算公式如下,模型预测正确数量所占总量的比例。

(2)召回率(Recall)
召回率是覆盖面的度量,度量有多个正例被分为正例。

(3)F1值(H-mean值)
F1值为算数平均数除以几何平均数,且越大越好。将Precision和Recall的上述公式带入会发现,当F1值小 时,True Positive相对增加,而false相 对 减少,即Precision和Recall都相对增加,也就是F1对Precision和Recall都进行了加权。

3.4 实验结果
表6 和图3分别列出了在验证集上对APP粗分类和基于分类后的结果对是否存在隐私侵占行为的检测效果。实验结果显示,对于APP的初始分类效果达到优异的成绩,准确率均高于95%,部分类别的召回率偏低;基于分类结果再融合异常侵占隐私行为特征的二次分类结果显示,多个分类器的联合投票结果优于单个的分类器。

图3 分类器性能示意图

表6 APP基础类识别验证集效果
4 结论
本文方案针对市场中较常见的涉及隐私侵占类的APP,达到了预期的实验效果,不仅分类领域达到较高的水准,还将各个不同类别中带有隐私侵占性质的APP进行了二次识别。但是本文方案仍有许多值得研究和改进的地方,首先由于样本的限制,导致分类类别有限,对于未知类别中的涉及侵占隐私APP没有涉及;其次是对于多分类器投票环节,实验中只利用了4种二分类器,对于更多不同的分类器组合效果是否更好有待进一步验证。
猜你喜欢
电脑报(2019年12期)2019-09-10 05:08:20
电子测试(2018年1期)2018-04-18 11:52:35
光学精密工程(2016年4期)2016-11-07 09:05:00
光学精密工程(2016年3期)2016-11-07 09:03:33
新校长(2016年8期)2016-01-10 06:43:59
商事法论集(2014年1期)2014-06-27 01:20:42
电测与仪表(2014年15期)2014-04-04 12:05:20
中国中医药现代远程教育(2014年16期)2014-03-01 04:28:46
食品科学(2013年8期)2013-03-11 18:21:31
电脑迷(2012年15期)2012-04-29 17:09:47
