
电力系统二次设备缺陷数据挖掘与分析方法研究
2022-01-05 08:25:30胡福金梁锦来
能源与环保 2021年12期
胡福金,梁锦来
(广东电网有限责任公司 佛山供电局,广东 佛山 528000)
电力系统不出现异常运行模式即表明电力系统二次设备的正常运行,因电力行业发展速度逐渐提升,电网结构复杂度随之日益增大。二次设备属于电力系统的核心设备,直接影响电力系统的运行状态[1]。因此,保证电力系统设备运行状态不出现异常,成为电力部门运维人员关注的重点问题,相关学者研究表明,对二次设备缺陷数据挖掘与分析是判断电力系统设备运行状态是否正常的基础。
目前,我国对二次设备缺陷数据挖掘与分析的研究仅处于探索与试验的阶段,即使某些研究资料对二次设备状态分析进行了深层次分析,但因为理论基础不足,资料信息与历史数据欠缺,致使相关研究方法的适用性较差,可推广性不足。文献[2]方法虽然能够实现变电站二次设备缺陷分析,但是该方法的分析过程较为烦琐;文献[3]方法的使用过程虽然操作简单,但是评估结果的精度有待进一步优化。
为此,为了克服上文所述存在的种种问题,本文基于数据挖掘技术,研究电力系统二次设备缺陷分析方法,具体分析过程分为2步,并分别引入层次聚类算法、XGBoost模型,实现二次设备状态的准确分析,在实验中,此方法的使用效果被验证优于文献[2]、文献[3]方法。
1 二次设备缺陷分析方法设计
为了实现电力系统二次设备缺陷数据分析,在保证数据分析准确的基础上降低分析耗时,设计二次设备缺陷分析方法,具体处理流程如图1所示。
根据图1所示流程,逐一分析处理过程。
1.1 二次设备缺陷数据挖掘方法
基于层次聚类算法的电力系统二次设备缺陷数据挖掘方法操作流程如下。输入:存在m个e维电力系统二次设备运行数据的数据集R;输出:正常数据聚类结果与缺陷数据聚类结果。
①把电力系统二次设备运行数据集R设成q个数据组,各组存在多个数据目标;②在各个数据组中启动原子聚类算法;③在原子簇集合中启动原子簇合并算法;④缺陷数据挖掘完毕。
1.1.1 原子聚类算法
原子即为电力系统中随机一个二次设备运行数据目标,原子聚类算法把数据组中的电力系统二次设备运行数据聚类设置为原子簇[4],原子聚类算法如图2所示。

图2 原子聚类算法示意Fig.2 Schematic diagram of atomic clustering algorithm
输入:电力系统二次设备运行数据集合R中一个数据组,电力系统二次设备运行数据目标Q、原子距离参数dAC;输出:原子簇集合∑BD。
(1)运算电力系统二次设备运行数据集合中数据目标q与另一数据目标p的距离D(q,p),如果D(q,p)小于原子距离参数dAC,2个数据目标则隶属相同原子簇BD。
(2)原子簇集合得出中心点DBD设置为每个原子簇的形心。
原子聚类算法属于一种分类算法,此算法和别的聚类算法之间差异是:原子聚类算法的参数不具有复杂性,主要参数是原子簇数值的距离阈值dAC,且该算法迭代次数仅需要一次,操作简单。
电力系统二次设备运行数据目标和原子簇核心点间的距离通过曼哈顿距离运算:
(1)
式中,不同电力系统二次设备运行数据目标依次为qj、pj;j为第j个数据目标。
1.1.2 原子簇合并算法
原子聚类变成原子簇后,启动原子簇合并算法,把原子簇合并后便可获取聚类簇[5-7]。原子簇合并算法属于凝聚聚类算法,可逐步合并近邻原子簇。
输入:根据上述原子聚类算法获取的原子簇集合∑BD以及原子簇距离参数dGD;输出:聚类簇集合∑GD。
(1)运算原子簇集合∑BD中不同原子簇GDj、GDi的距离D(GDj,GDi),如果D(GDj,GDi)不大于dGD,原子簇GDj、GDi则隶属相同聚类簇GD。
(2)运算每个聚类簇的密度。原子簇合并算法在运行过程中,若2个聚类簇具有“邻居”关系,便把这2个聚类簇相融为一体[8]。2个原子簇间距可看作两者中心点的密度:
(2)
其中,DGDj、DGDi分别为两个原子簇的簇心。
1.1.3 基于层次聚类算法的缺陷数据识别算法
根据上述分析,设计二次设备缺陷数据识别算法流程如下。输入:不存在电力系统二次设备运行数据分类信息的聚类簇集合∑GD、标准聚类簇密度Es、电力系统二次设备正常运行数据Sm和电力系统二次设备缺陷数据比率参数Sa;输出:存在电力系统二次设备运行数据分类信息的聚类簇集合∑GD。①将聚类簇集合∑GD中聚类簇按照从大至小的顺序进行排列;②运算正常聚类簇的密度;③运算各个聚类簇密度和正常聚类簇密度之比,如果此比值不大于缺陷数据比率参数Sa,则隶属为缺陷数据[9]。
1.2 基于XGBoost的二次设备缺陷分类模型
1.2.1 特征指标集的建立
电力系统二次设备种类和数目具有多样性,为此,在挖掘电力系统二次设备缺陷数据之后,为准确分类电力系统二次设备缺陷类型,需要提取缺陷数据中的具体数据特征,构建电力系统二次设备缺陷特征指标集[10]。电力系统二次设备缺陷分类指标集详情见表1。

表1 电力系统二次设备缺陷分类指标集Tab.1 Details of defect classification index set of secondary equipment in power system
由表1可知,与电力系统二次设备缺陷存在关联的特征量类型主要是种类特征、数值特征。
1.2.2 特征和缺陷级别标签的设置
考虑到XGBoost模型的输入仅支持数值,必须将二次设备缺陷数据的种类特征实施编码,把种类特征变换成数值特征[11-13]。
围绕输入的种类特征,因为各个特征存在的属性数目较少,本文使用独热编码的模式实现二次设备缺陷数据的种类特征编码:通过0与1描述此类种类特征,通过M位状态寄存器编码M个状态、各个状态均存在具有独立性的寄存器位。
按照我国电力设备权限管理的相关标准,把电力系统二次设备缺陷根据严重程度依次设成A级缺陷、B级缺陷,C级缺陷(表2)。

表2 二次设备缺陷严重程度Tab.2 Defect severity of secondary equipment
1.2.3 缺陷分类模型
根据上文分析内容,在设置特征和缺陷级别标签的基础上,构建电力系统二次设备缺陷分类模型(图3)。

图3 缺陷分类模型示意Fig.3 Schematic diagram of defect classification model
根据图3缺陷分类模型可知,构建模型实现过程如下:①在章节1.1挖掘的电力系统二次设备缺陷数据中提取缺陷特征设置为XGBoost模型的输入数据;②去除所输入电力系统二次设备缺陷数据中不完备特征[19];③将所输入电力系统二次设备缺陷数据中的种类特征和缺陷级别标签依次实施编码;④按照比例把处理完毕的缺陷数据集设成训练集与测试集;⑤把训练数据集导入XGBoost模型实施训练,以参数调节的形式,完成模型参数最优化[20];⑥通过调优后模型对测试集中数据实施缺陷级别分类。
2 应用性能分析
2.1 实验设置
实验硬件运行环境:计算机的中央处理器是i5-5257U(2.7GHz),内存 58 GB;软件运行环境为Windows 10,VC++6.0。
为测试本文方法的应用性能,在Matlab软件中,以Gephi数据集为测试数据集,对本文方法的应用性能进行仿真测试。此数据集中存在50 000个二次设备运行数据目标,数据来源于某电力公司某年度的电压表、电流表、功率表、继电器、蓄电池组、直流发电机、高频阻波器7种二次设备的缺陷数据。在实验过程中本文将该电力公司某年度的二次设备缺陷数据进行预处理后,随机提取2 000个数据目标作为本文方法挖掘与分析的数据。
(1)按照章节1.1提出的基于层次聚类算法的电力系统二次设备缺陷数据挖掘结果形成二次设备缺陷数据库。
(2)补全缺失数据。由于电力系统二次设备具备高可靠性,二次设备缺陷类型具备分散性。在此情况下,盲目删除部分属性缺失的记录会缩小样本,易丢失一些小样本包含的关联规则,因此本文不删除部分属性缺失的记录,而是通过查询检修报告补全缺失数据。
(3)统计缺陷原因。经统计,二次设备缺陷原因包括“调试质量不良”“制造质量不良”“设备老化”“运行维护不良”“其他缺陷原因分类”5种类型,以设备老化为主要测试指标,分别利用不同方法进行挖掘测试。
(4)输出测试结果。
2.2 缺陷数据挖掘结果
为测试本文方法对电力系统二次设备数据挖掘性能是否具有优势,以文献[2]、文献[3]方法作为对比,测试3种方法在随机提取的2 000个二次设备运行数据中对缺陷数据的挖掘效果。挖掘效果主要以缺陷数据样本的挖掘量作为描述,对比结果见表3。分析表3数据后可知,本文方法、文献[2]方法、文献[3]方法对电压表、电流表、功率表、继电器、蓄电池组、直流发电机、高频阻波器7种二次设备的缺陷数据挖掘结果存在差异。对比之下,本文方法的挖掘结果和实际缺陷数据样本数一致,文献[2]方法、文献[3]方法的挖掘结果和实际缺陷数据样本数分别存在1个、5个偏差,本文方法的挖掘结果最精准。

表3 对二次设备缺陷数据的挖掘结果对比Tab.3 Mining results of secondary equipment defect data
2.3 缺陷数据分析结果
为测试本文方法对电力系统二次设备数据分析性能是否具有优势,以文献[2]方法、文献[3]方法作为对比,测试3种方法在随机提取的2 000个二次设备运行数据中对缺陷数据的分析效果。分析效果主要通过3种方法对7种二次设备的缺陷级别识别效果体现,识别效果需要通过准确率Q1、召回率Q2、F1值3种指标进行分析。
(3)
(4)
(5)
式中,MTP、MFP、MFN分别为真正类、真负类、假正类。
3种方法的准确率、召回率、F1值测试结果如图4所示。分析图4数据后可知,本文方法、文献[2]方法、文献[3]方法对电压表、电流表、功率表、继电器、蓄电池组、直流发电机、高频阻波器7种二次设备的缺陷级别识别后,本文方法对电力系统二次设备缺陷的识别结果准确率、召回率、F1值高达0.99,均高于对比方法,由此可知代表本文方法对二次设备缺陷识别级别识别精度极高。

图4 3种方法对二次设备缺陷级别识别效果Fig.4 Effect of three methods on defect level identification of secondary equipment
识别耗时主要体现了3种方法的操作难度,操作难度小,则识别耗时短。3种方法对7种二次设备的缺陷级别识别耗时测试结果如图5所示。分析图5数据后可知,本文方法、文献[2]方法、文献[3]方法对7种二次设备的缺陷级别识别耗时差异较为明显,本文方法的识别耗时低于400 ms,文献[2]方法、文献[3]方法的识别耗时均大于500 ms,对比之下,本文方法的识别耗时最短,表示本文方法在识别电力系统二次设备缺陷级别时操作难度最小。
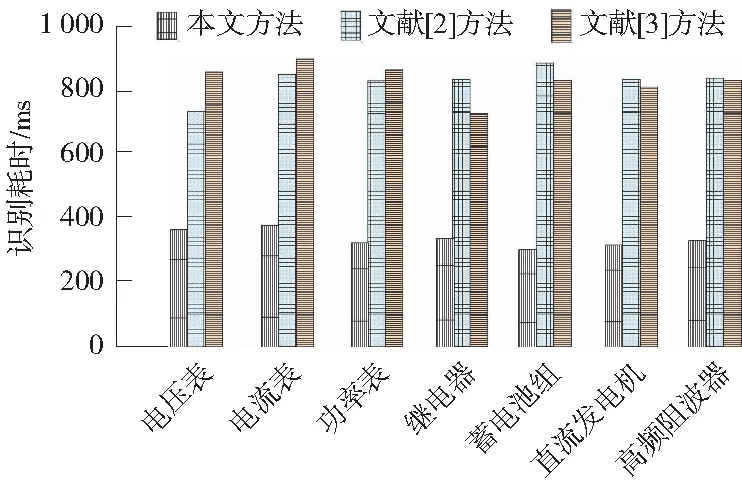
图5 对7种二次设备的缺陷级别识别耗时测试结果Fig.5 Test results for defect level identification of seven kinds of secondary equipment
综上所述,本文方法对电力系统二次设备缺陷数据的挖掘与分析性能占有优势。
3 结论
文章以电力系统二次设备缺陷数据挖掘与分析为研究内容,提出利用缺陷数据挖掘的方法,实现高精准度快速的缺陷数据挖掘与分析。在实验测试中,本文研究方法对电压表、电流表、功率表、继电器、蓄电池组、直流发电机、高频阻波器7种二次设备缺陷数据挖掘并分析后,挖掘的缺陷数据样本数量和实际样本数量一致,挖掘精度高于对比方法,对7种二次设备缺陷级别的识别精度也大于对比方法,可优化电力系统二次设备缺陷问题的分析效果。
猜你喜欢
速读·下旬(2021年11期)2021-10-12 01:10:43
大众投资指南(2021年35期)2021-02-16 01:06:26
大东方(2019年12期)2019-10-20 13:12:49
电子测试(2017年15期)2017-12-18 07:19:27
科学与财富(2017年22期)2017-09-10 13:20:02
电力与能源(2017年6期)2017-05-14 06:19:37
商情(2017年1期)2017-03-22 16:56:36
智能系统学报(2015年4期)2015-12-27 09:38:39
信息通信技术(2015年6期)2015-12-26 01:16:46
电子设计工程(2015年6期)2015-02-27 12:04:53
