
基于LSTM-GRU的污水水质预测模型研究
2022-01-05 08:24:44邹可可李中原穆小玲李铁生于福荣
能源与环保 2021年12期
邹可可,李中原,穆小玲,李铁生,于福荣
(1.河南省平顶山水文水资源勘测局,河南 平顶山 467000; 2.河南省水文水资源局,河南 郑州 450003;3.河南省郑州水文水资源勘测局,河南 郑州 450006; 4.郑州大学 化学与分子工程学院,河南 郑州 450052;5.华北水利水电大学,河南 郑州 450046)
水质是由水资源内所含物理、化学和生物等多种参数共同定义而成[1]。在用于饮用水、农业、娱乐和工业用水等各种预期用途之前,确定水资源质量至关重要。一般情况下,污水水质预测模型可分为机理式[2]水质预测模型和非机理式[3]水质预测模型。机理式水质预测模型复杂,且普适性较弱,目前国内外普遍采用非机理式水质预测模型,预测水质的长期和短期变化趋势。常用的方法有时间序列预测法、人工神经网络预测法、回归分析预测法、熵值法等。梁中耀等[4]利用时间序列预测法对滇池外海的水质指标的时间序列数据进行递归迭代,并对水质趋势的时、空变化特征进行识别和判定。然而该方法属于无原因变量的统计预测模型,其特点是数学理论基础完善,实践难度较大,误差较大。袁宏林等[5]运用Levenberg-Marguardt优化算法对学习样本进行训练,建立以上游断面水质监测数据预测下游水质变化的反向传播(Back Propagation,BP)神经网络水质预测模型。该方法建立的预测模型的预测精度可以达到令人满意的程度,但从预测模型中尚不清楚水质变化趋势的具体原因和内在联系,从而影响了模型的预测精度。笪英云等[6]提出了一种基于关联向量机回归的水质时间序列预测模型,该方法通过对大量数据样本进行相关分析,得出相关性,并建立回归方程,在考虑预测误差的基础上确定未来水质预测值,然而模型复杂,对数据和样本的分布要求较高。陈昭[7]应用熵值法改进集对分析模糊评价方法,实现河流水质状况等级评价。然而该方法容易受到数据不稳定性的影响,从而产生较大的预测误差。
由于水质参数是一个动态的时间序列,因此更适合使用递归神经网络[8-9](RNN)。另外,水质参数的预测过程是渐进的,即当前水质参数与历史水质参数相关联。这就要求RNN能够动态地记忆历史水质参数信息,并在学习新信息的同时保留历史水质参数信息。为此,本文引入了一种改进的长—短记忆网络结构(LSTM-GRU)来增加RNN的隐层,从而高效学习历史水质参数信息,使得预测结果更加精确。
1 神经网络模型
1.1 RNN神经网络模型
递归神经网络(RNN)通常用于机器视觉和自然语言处理,它具有特征学习能力,能够从输入数据中提取高级特征。一维CNN(1D RNN)可用于时间序列数据处理,二维CNN(2D RNN)可用于图像识别等视觉处理。
1D-RNN的结构如图1所示,它由输入层、卷积层、池化层、全连接层和输出层组成。卷积层通过不同大小的卷积核提取特征,池化层通过压缩数据来降低信息的维数。为了有效地提取和保留数据特征,卷积层和池层交替出现。全连通层将从不同空间提取的分布特征展平,实现回归或分类。RNN注重局部特征提取,通过参数共享减少权值,大大减少了网络的计算参数。
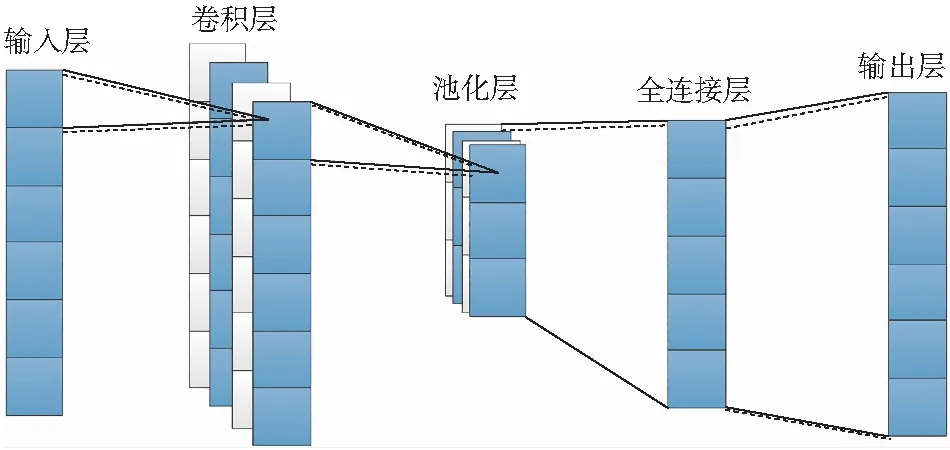
图1 1D-RNN的结构Fig.1 1D-RNN structure
1.2 GRU和LSTM
门控递归单元(GRU)和长短时记忆(LSTM)可以看作是递归神经网络(RNN)的变种,常用于处理序列问题。它们可以解决传统RNN中的长时记忆和反向传播算法中的梯度爆炸问题。
GRU和LSTM采用门结构代替标准RNN结构中的隐藏单元,可以选择性地记忆重要信息而忘记不重要信息。与LSTM相比,GRU用更新门zt和复位门rt代替LSTM的输入门、遗忘门和输出门。在GRU的预测精度不低于LSTM的预测精度的前提下,可以减少训练参数,以获得更快的收敛速度。传统RNN和GRU的结构如图2所示。

图2 RNN和GRU网络结构Fig.2 RNN and GRU network structure
复位门rt确定新输入与先前存储器的组合,并且更新门zt定义保存到当前时间步长的先前存储器的数量。zt值越大,从前一时刻到当前时刻的状态信息就越多。rt值越小,先前时刻的状态信息被遗忘得越多。
因此,GRU的工作原理可以概括如下:①根据当前时刻的输入状态信息xt和前一时刻存储的隐藏层信息hi-1来计算zt和rt。②使用复位门来确定存储在节点hi-1中新信息的数量。③通过更新门计算当前时刻的隐藏层输出。GRU的计算过程如下:
(1)

2 网络模型设计
2.1 模型框架
LSTM-GRU预测模型的总体框架如图3所示,包括5个功能模块:输入层、隐藏层、输出层、网络训练和网络预测。输入层负责对原始河流水质参数内容进行初步处理,以满足网络输入要求。隐藏层使用LSTM-GRU单元构建的网络,输出层提供预测结果。网络训练采用随机梯度下降法(SGD)作为优化器,网络预测采用迭代法。
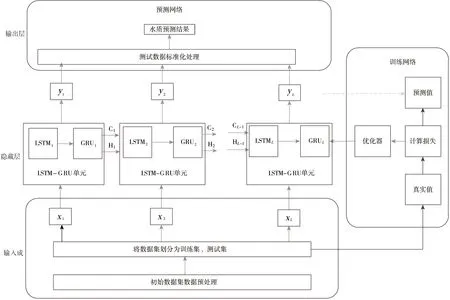
图3 预测模型的总体框架Fig.3 Overall framework of forecasting model
2.2 模型训练参数设置
采用程序自寻优法确定最优参数,需要调整的主要参数是存储单元数、模型结构和训练集的时间窗口大小。每例均监测100次错误率,该模型的效果波动很小,各参数的误差率小于5%。当LSTM-GRU模型层数设为3层、训练集时间窗为460、隐层存储单元数为20时,效果较好。将每个时间点的数据输入LSTM-GRU网络,预测下一个时间点高锰酸钾指数(COD含量)。然后,将下一个时间点的真实COD含量作为已知的输入网络继续预测,并进行在线滚动。由于模型稳定性高,采用自动优化的方法建立模型无需人工调试。
3 仿真与分析
3.1 数据预处理
河流水质指标包括总磷(P)、总氮(N)、溶解氧(BOD)、氨氮(NH4-NO3)和高锰酸钾指数(COD),河流水质参数预测的目的是判断采集水样的污染等级,为污染防治和水源保护提供依据。由于在水质预测中COD与水污染直接相关,因此选取COD作为反映河流水质参数评价的综合指标。为了防止由于不同自变量幅值的巨大差异而引起奇异解,对测量数据进行归一化处理,将输入变量线性变换成[-1,1],使数据适应sigmoid和tanh激活函数。数据规范化使用以下函数:
(2)
式中,xmin、xmax分别为测得的最小值和最大值;ymin、ymax分别为归一化处理后最小值和最大值,通常取0.01和0.99。
实测指标值对应的水质分级等级见表1。

表1 地表水环境质量标准Tab.1 Environmental quality standard of surface water mg/L
选择LSTM模型和GRU模型作为河流水质参数的对比预测模型,以重庆市某河流COD含量日监测数据中的460组实测数据作为LSTM模型、GRU模型和LSTM-GRU模型的训练数据集,将其中25组实测数据作为上述3种模型的测试数据集。
3.2 评价指标的选取
为了保证误差测量结果的有效性,采用均方根误差(RMSE)和平均绝对百分比误差(MAPE)作为预测精度的评价标准,RMSE和MAPE值越小,预测结果越准确。计算公式如下:
(3)
(4)

3.3 性能评估
采用LSTM模型、GRU模型和LSTM-GRU模型的指标预测值与真实值对比结果如图4所示。对3个模型的RMSE和MAPE值分别进行了分析,结果见表2。

图4 不同方法预测与真实值对比结果Fig.4 Comparison results between predicted and real values by different methods

表2 不同模型预测结果的性能指标Tab.2 Performance index of prediction results of different models
从图4可以看出,用LSTM模型和GRU模型预测COD含量偏差值较大,预测效果不理想。采用LSTM-GRU模型预测COD含量,预测值与真实值变化趋势基本一致,数据跟踪效果较好,预测精度高,在污水处理预测上比使用单个预测模型的预测精度高、效果好。
由表2可以看出,与LSTM模型和GRU模型相比,LSTM-GRU模型的预测评价指标值均小于传统水质模型,说明就河流水质参数预测而言,与传统的水质参数预测模型相比,LSTM-GRU模型的泛化能力更强,预测精度更高。
4 结论
水资源质量检测对于饮用水、农业、娱乐和工业用水等水资源的管理及保护具有重要作用。然而水质参数的预测过程是一个渐进过程,需要同时考虑当前水质参数与历史水质参数相关性。为此,本文对递归神经网络中LSTM和GRU模型进行了研究,该技术提高了水质检测精度。
猜你喜欢
环境(2023年5期)2023-06-30 01:20:01
黄河之声(2022年10期)2022-09-27 13:59:46
中学生数理化(高中版.高二数学)(2022年4期)2022-05-25 13:08:00
中学生数理化(高中版.高二数学)(2022年4期)2022-05-25 13:08:00
电子制作(2019年19期)2019-11-23 08:42:00
当代水产(2019年1期)2019-05-16 02:42:04
中学生数理化·八年级物理人教版(2017年11期)2017-04-18 11:22:51
重型机械(2016年1期)2016-03-01 03:42:04
大连工业大学学报(2015年4期)2015-12-11 04:06:52
海军航空大学学报(2015年4期)2015-02-27 13:45:47
