
优化的GM(1,1)模型在水泥用石灰岩产量预测中的应用研究
2022-01-05 13:22薛东剑
中国非金属矿工业导刊 2021年6期
赵 磊,薛东剑,方 坤
(1.成都理工大学地球科学学院,四川 成都 610059;2.四川省国土科学技术研究院,四川 成都 610045)
灰色系统是由我国著名学者邓聚龙在1982年提出来的,灰色系统的提出解决了大量预测问题,灰色系统着重于小样本、贫信息和不确定性问题的研究,并依据信息覆盖,通过序列算子的作用探索事物运动的现实规律,其特点是“少数据建模”,着重研究“外延明确,内涵不明确”的对象[1]。预测的任务就是探寻研究客观事物发展变化的规律,由于预测的对象、目标和内容的不同,形成了多种多样的预测方法[2],薛东剑等[2]采用灰色系统预测模型进行矿产预测,并证实了灰色系统预测模型在矿产预测中的适用性,此后灰色系统预测方法在矿产预测中被广泛使用,为矿产资源编制工作提供了新的方法与思路。然而面对矿产产量数据的无规律性,灰色预测系统模型在对矿产预测过程中时,仍存在精度偏低等问题。所以本次研究通过对比多种背景值改良后的灰色系统模型及原始灰色系统模型,通过对模拟值、残差、相对误差和平均相对误差等多个方面进行对比分析,为矿产预测选择更加合理、精确的预测方法。
模型的初始值、模型的背景值和模型的参数估计方法等是影响GM(1,1)模型的预测精度的常见因素[3],其中背景值构造方法的改良在探索提高GM(1,1)精度的过程中有非常重要的意义,并且一大批学者致力于背景值构造改良方法的研究。刘乐等[4]将x(1)(t)抽象为x(1)(t)=B·exp(A·t)+C,从而构造出更加精确的背景值构造公式,该公式提高了预测精度,同时还适用于高、低指数增长序列的建模。李星毅等[5]利用非齐次指数函数模拟依次累加生成序列,在考虑原始模型误差出现原因之后,根据序列与累加生成序列的关系重新构造了背景值计算公式,以实际曲线在区间上与x轴围成的面积作为新背景值。蒋诗泉等[6]基于积分几何意义,将原区间平分成若干小区间,利用函数逼近的思想,同时利用复化梯形公式代替原公式,提出了新的GM(1,1)模型背景值优化方法,并取得了较好的效果。江艺羡等[7]根据模型的指数性质及积分特点,利用黎曼积分的核心思想,用不规则梯形面积代替传统梯形面积,从而提出了新的背景值构造方法。徐宁等[8]根据GM(1,1)模型时间响应式的函数形式,利用积分中值定理拟合真实模型背景值,在研究发展系数与背景值之间的关系的基础上,提出了基于误差最小化的GM(1,1)模型背景值优化方法。李凯等[9]提出了利用辛普森3/8公式和牛顿插值公式的组合插值方法来构造出新的GM(1,1)模型背景值。虽然改良后的各种模型具有较好的预测稳定性,增强了GM(1,1)模型的适用性,但是对于数据较大且无规律的矿物产量而言,不论是原始GM(1,1)模型还是改良后的GM(1,1)模型都只能进行短期预测,所以本文提出了利用新陈代谢模型与改良后的模型相结合,以便于进行矿物产量的长期预测,从而达到更高的精度。
1 灰色系统预测模型的建立
1.1 建模原理及方法
GM(1, 1)模型的算法如下:
设时间序列x0有n个观察值:

累加生成新序列:X1={x1(1),x1(2)…x1(n)},其中
X1(k)为X0(k)的一次累加序列,记作1-AGO,有:

(1)式为GM(1,1)模型的基本形式,也称作灰微分方程;其中a、b分别为发展系数和内生控制灰数为待估计参数变量,通常利用最小二乘法可以解得:
其中:

B矩 阵 中z(1)(k)=1/2{x(1)(k)+x(1)(k-1)};k=2,3,…,n,z(1)(k)即为模型的背景值。

(3)式即为灰微分方程式(1)的白化方程,时间响应式为:

利用(4)式累减得可到还原序列,即预测方程:

1.2 GM(1,1)建模数据合格性检验
计算建模序列的级比:

若数据符合(6)式,则认为建模序列是合格的。其中:
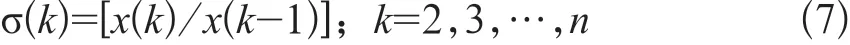
若不满足上述条件,则需要对数据序列进行一定的变换处理,从而达到建模要求。
1.3 预测结果精度检验
灰色模型精度检验一般有三种方法:相对误差大小检验法,关联度检验法和后验差检验法。常用的为后验差检验法。

(2)计算残差。

(3)分别计算原始序列x0的方差S1和残差e(k)的方差S2。

(4)计算后验差比。

其中C表示原始数据离散程度的大小。
(5)计算小误差概率并查表观察效果(表1)。

表1 精度等级对照表
小误差频率:P=P{|ε(k)-ε(k)|<0.6745S1},其中P表示残差与残差平均值之差小于0.6745S2的点的数量。
2 灰色系统预测模型的改良
在传统的GM(1,1)模型的建模过程中,常利用梯形面积代替积分与X轴围成的面积,从而在预测结果上产生了误差,同时GM(1,1)模型的预测精度取决于a和b的值,同时模型中a,b的值又取决于背景值z(1)(k),因此本文选取原始GM(1,1)模型以及三种背景值改良后的GM(1,1)模型进行对比分析。
2.1 模型一
令区间[k-1,k]=[p,q],在区间[k-1,k]中平均插入n-1个点,将区间[k-1,k]平均分成了n个小区间,则每个点的表达式为xk=p+kh;k=0,1,…,n,其中h=(q-p)/nh,对每个小区间进行积分并求和得到:

最终得到背景值公式:
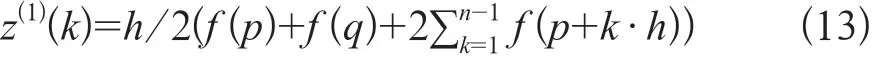
2.2 模型二

2.3 模型三

最终根据待定系数A、D、C并结合式z(1)(k)=1/A[x(1)(k)-x(1)(k-1)]+C=[x(0)(k)/A]+C得到新背景值构造公式为:x(1)(k)≠x(1)(k-1)时,


3 四川省水泥用灰岩产量预测
3.1 产量数据预测分析
水泥用灰岩2011年至2019年产量数据来自2011年至2019年《四川省矿产资源年报》、《四川省统计年鉴》,具体产量数据可见下表2。

表2 四川省水泥用灰岩2011~2019年产量
利用表2水泥用灰岩2011~2019年9组产量数据进行建模:X(0)={5855.2,6267.9,6789.1,7564.2,7464.7,7811.9,8420.6,8670.9,9355.3}

表3 水泥用灰岩产量预测结果

表4 水泥用灰岩预测产量误差分析结果
原始GM(1,1)模型及三种基于背景值改良的GM(1,1)模型预测精度都达到了1级,但是水泥用灰岩产量数据较大,所以对精度要求较高,通过对三种改良模型的预测数据的平均误差进行分析对比后发现,M3改良模型较原始GM(1,1)模型及其他改良模型都有一定优势,成功降低了水泥用灰岩产量预测的误差。原始产量数据与M3模型预测值拟合度如图1所示。
从表4和图1可以看出原始产量数据与M3模型预测值拟合度较高,M3模型预测值最高相对误差为5.37%,平均相对误差为1.72%,预测精度为1级,适合对水泥用灰岩进行中长期预测研究。

图1 2012~2019年水泥用灰岩原始值与预测值
3.2 新陈代谢模型与改良模型M3结合
在原始数据序列中,新预测数据x(0)(n+1)代替旧数据x(0)(1),新预测序列则更新为:

反复进行此过程,直到完成预测任务,这个新数据代替旧数据,并反复利用新序列来进行GM(1,1)建模的过程就是灰色新陈代谢模型,通过这个过程可以提高预测精度。
利用表2水泥用灰岩2011~2019年9组产量数据进行建模,通过预测公式计算得到2020年水泥用灰岩产量为9 819.7万t。
利用新陈代谢模型将x(0)(10)代替原x(0)(1)形成新的建模序列,计算得到2021年水泥用灰岩产量预测模型:
同理可得未来4年水泥用灰岩预测模型。
2021~2025年水泥用灰岩产量预测模型分别为:

3.3 水泥用灰岩产量预测结果分析
通过上述2021~2025年水泥用灰岩产量预测模型得到预测结果(表5)。
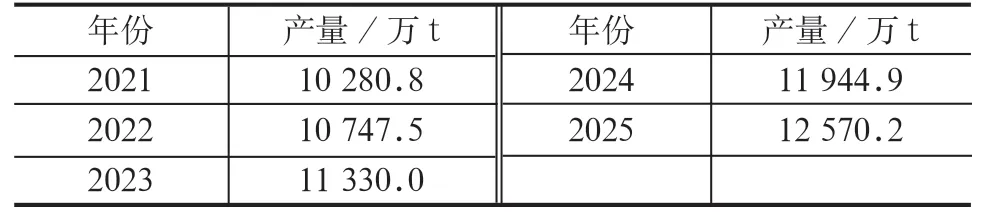
表5 水泥用灰岩产量预测结果
未来五年的产量预测结果表明,水泥用灰岩产量呈上升趋势。水泥用灰岩在水泥工业中占主导地位,是国民经济及人民生活必不可少的原料,其工业总产值稳步上升,需求呈现上升的趋势,水泥用灰岩产量预测结果与需求趋势一致。
4 结论
(1)本次研究以四川省第四轮矿产资源规划为背景,利用表2中水泥用灰岩2011~2019年产量数据,分别采用原始GM(1,1)模型及三种背景值改良后的GM(1,1)模型,利用水泥用灰岩2011~2019年产量对其进行预测,在四种预测模型预测精度都为一级的情况下,对四种模型的预测精度进行对比分析,最终选择出了更加适合水泥用灰岩产量预测的模型。
(2)矿物产量受政策、价格等因素变化而波动,旧数据已经不再适合继续作为GM(1,1)建模数据进行研究,新陈代谢模型利用新数据代替旧数据,将改良后的GM(1,1)模型与新陈代谢模型相结合,利用水泥用灰岩2011~2019年产量数据进行建模,成功预测出未来5年水泥用灰岩产量,水泥用灰岩产量预测结果呈现上升趋势。
此次研究为动态建模过程,提高了对水泥用灰岩产量长期预测的准确性,为其他矿物产量的长期预测提供了方法和思路,也为矿产资源规划提供了更加精确的数据,合适的预测模型和精确的预测数据是矿产规划顺利完成的有力保障。
猜你喜欢
导航定位学报(2022年5期)2022-10-13
机械工业标准化与质量(2022年8期)2022-10-09
军事文摘(2022年16期)2022-08-24
建材发展导向(2021年7期)2021-07-16
建材发展导向(2020年16期)2020-09-25
科学导报·学术(2019年21期)2019-09-10
科技创新导报(2019年32期)2019-04-07
西部资源(2019年3期)2019-01-03
华人时刊(2016年16期)2016-04-05
科技致富向导(2013年9期)2013-06-04
