
基于深度特征聚类的高排放移动污染源自动识别
2021-12-31 03:53许镇义王仁军张聪王瑞宾夏秀山
交通运输系统工程与信息 2021年6期
许镇义,王仁军,张聪,王瑞宾,夏秀山
(1.合肥综合性国家科学中心人工智能研究院,合肥 230088;2.安徽大学,计算机科学与技术学院,合肥 230601;3.合肥市生态环境局,合肥 230601;4.中国科学技术大学,先进技术研究院,合肥 230088)
0 引言
随着国民经济水平的提高,机动车辆不断普及,持续增加的保有量使机动车排放的大量尾气成为城市污染的主要来源之一[1]。公安部交通管理局发布,截止2020年底,全国机动车保有量达3.72亿辆,其中,汽车2.81 亿辆。由于高排放移动污染源对城市空气质量构成巨大威胁,而被视为重点研究对象。
根据车辆数据处理方法的不同,高排放移动源识别主要分为传统的基于统计限值设定方法和基于机器学习的自动分类方法。本质上,统计学方法处理的是低维、简单的车辆监测数据,例如,COx、NOx等尾气的浓度值。根据统计结果,设定阈值划分高排放车辆和普通车辆。机器学习方法应对的是高纬、复杂的车辆监测数据,不仅包含污染气体的浓度值,还包括其他属性数据,例如,VSP、车速、加速度等。通过借助计算机的算法和算力,可以发现车辆监测数据的内在联系和规律,从而科学地划分车辆排放类别。
在传统的高排放源识别过程中,通过对CO、HC、NO 等污染物设定特定的百分比或者浓度值,判定车辆是否属于超排放。例如,文献[2]在高排放遥感检测中设定CO、HC、NO 的切割点分别为:3%、0.05%、0.2%,并且在201504 个遥感数据中确定了1373 个高排放目标。文献[3]中,根据包含NO/CO2、HC/CO2、CO/CO2的比值统计结果,确定污染物排放阈值,即以5%的高排放比例划分阈值。
上述研究属于采取预先设定阈值的方式将车辆划分成高排放和普通排放车辆。这种方式依赖于人工经验判定,难以适应数据集的分布变化[4]。
在实际的机动车尾气排放检测工作中,气体浓度不但随自身车长、车重、速度及加速度的变化而变化,而且还受风速、温度、空气湿度等环境因素的影响。道路遥感监测装置由于采取的是非接触式测量技术,不妨碍车辆的正常行驶,因此,具备高效快捷、尾气浓度反应灵敏等特点。同时,使得监测效果受到环境因素影响较大,导致数据稳定性不足。因此,在对高排放移动源的污染排放识别过程中,分析外部因素对检测数据的影响十分必要。
本文不仅考虑移动源自身属性对污染气体排放的影响,同时,还注意到外部环境因素的影响。本文的实验数据由道路遥感检测装置采集得到。由于遥测数据的复杂性,本文利用机器学习领域的方法分析数据,提出基于深度特征聚类的高排放移动污染源自动识别方法。
本文的难点来自于两方面:一是影响污染物排放的特征属性较多,使车辆数据分析的工作量较大;二是如何确定高排放移动源的类别标签以及实现高排放源的自动识别。
为解决以上问题,本文提出了一种新的解决方法。主要的贡献如下:
(1)使用随机森林实现特征选择,筛选出污染气体排放浓度的主要影响特征。
(2)由于移动污染源数据是无标签的,本文提出一种基于深度特征聚类的方法确定高排放类别标签,利用自适应的K-means聚类算法对污染物的多种影响特征进行深度聚类。
(3)考虑道路移动源排放分布的高度偏斜性,即高排放类别样本稀缺,本文采用一种基于样本平衡策略的深度森林分类模型,实现对高排放移动源的自动识别。
本文所提方法的具体过程及原理包括:随机森林特征选择、高排放类别标签的获取、深度森林分类预测模型;在车辆排放数据集上进行大量实验,验证基于深度森林的高排放识别模型的有效性。
1 相关工作
在使用机器学习方法识别高排放移动源的工作中,GUO 等[5]建立了一种反向传播神经网络(BPNN)模型预测高排放污染源,将加速度、速度、烟羽和多种污染气体等属性作为输入特征。JUN等[6]创建了一种改进策略的高排放预测神经网络,引入KNN 和遗传算法,分别用来剔除异常样本点和优化网络初始权值。但是,遥测数据集中本身具有高排放和普通排放的类别标签,且标签是依据传统设定阈值的方式划分得到的。同时,实验数据针对的是小型车型——出租车,对在路行驶的车辆不具备很好的代表性。
在没有类别标签的情况下,XIE 等[7]提出一种根据CO、HC、NO 浓度值自动产生判定阈值的算法,采用K-medoids 聚类算法对道路遥测数据进行聚类和标记,并利用KNN 算法检测高排放源。然而,这种方法只针对污染物测量值进行分析,并没有考虑外部属性测量数据。在高排放类别标签稀少的情况下,KANG 等[8]利用半监督学习方法扩增有标签数据集,同时,分别构建基于单分类支持向量机(OC-SVM)和半监督单分类支持向量机(S2-OCSVM)的高排放源识别模型。
在实现高排放源自动识别的过程中,核心是获取高排放类别标签。本文利用聚类算法将移动源数据集划分成多个类别,然后经过数据分析明确高排放源所对应的类别。由于没有任何一种聚类算法可以普遍适用于所有的多维数据集,从而展现出它们丰富多样的结构[9],因此,本文采用自适应聚类算法。聚类算法一般可划分4 种类型,分别为:层次化聚类算法,基于密度和网格的聚类算法,划分式聚类算法和其他聚类算法[10]。层次化聚类通过一定的联接规则将数据集划分出多个层次,形成树形的聚类结构;但是,这种算法具有较高的时间复杂度O(n2);并且,由于它是一种贪心算法,往往很难实现全局最优。基于密度的聚类通过数据分布的紧密程度划分类簇;基于网格的聚类是将空间量化为有限的单元,形成一个网格,再根据样本密度对网格单元进行聚类。通常,基于网格的聚类算法会和其他方法结合使用,尤其是与基于密度的聚类方法结合。 DBSCAN (Density- Based Spatial Clustering of Applications with Noise),OPTICS(Ordering Points to identify the clustering structure),DENCLUE(Density Clustering)等都属于经典的基于密度的聚类算法,但对超参数-半径和密度阈值是十分敏感的。划分式聚类算法是数据样本点围绕簇中心进行划分,迭代簇中心的更新与样本点的划分,直到两者不再发生变化。常见的划分式聚类算法有:K-means,K-medoids 和K-means++等。它们生成或更新簇中心的方式不同,并且都需要预设簇别个数。K-means算法的时间复杂度较低,聚类效率较高。除上述聚类算法外,都属于其他类算法,例如,高斯混合模型,利用概率模型划分类别。
本文采用K-means聚类算法,对多种影响污染物排放的外部影响因素综合考虑,将CO、HC、NO和各自的主要影响因素进行深度特征聚类,经分析后获取不同气体的高排放标签,再采用基于深度集成学习的深度森林算法实现高排放源的自动识别。
2 方法
本文提出一种考虑外界影响因素的高排放移动源的自动识别方法(Automatic Identification of High-emitting Vehicle Based on Deep Feature Clustering,AIHEV-DFC)。首先,使用随机森林算法计算初步采集的包含CO、HC、NO和多个影响属性(例如,使用时间、车重、车速等)的尾气遥测数据集,得到各属性对污染物排放的影响比例,并筛选出各污染物的主要影响特征;然后,利用K-means算法聚类各污染物主要影响特征数据集,并经过分析得到高排放类别标签;最后,更新特征数据集为高排放和低排放类别并使用SMOTE方法解决两个类别样本的不平衡问题,进而训练深度森林高排放源分类模型,并在测试集上验证。AIHEV-DFC 流程如图1所示。

图1 基于深度特征聚类的高排放移动源自动识别方法结构Fig.1 Architecture of method for AIHEV-DFC
2.1 数据统计
移动源污染物排放受多种因素影响,在文献[11]的基础上,初步筛选出车辆基准质量,行驶速度,行驶加速度,VSP,风速,风向,气温,湿度,大气压,车身长度,使用年限及CO、HC、NO的实测浓度等多个属性。相关属性符号说明如表1所示。
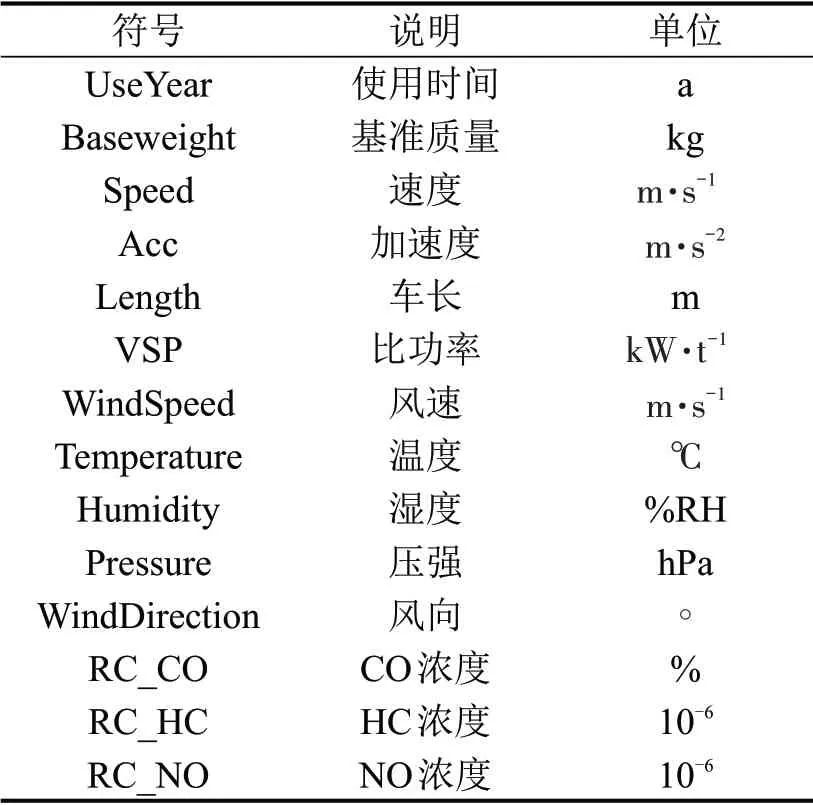
表1 影响因素符号Table 1 Symbols of influencing factors
本文所用尾气遥感监测数据,是由布设在合肥市蜀山区仰桥路的尾气遥感监测设备采集的2017年5月1~31日的55211条有效遥测数据,经车辆年检站匹配预处理后保留了3491条有效的实验建模数据。所采集的数据共16个属性,其中,包括上面介绍的车辆基准质量,行驶速度,行驶加速度,VSP,风速,风向,气温,湿度,大气压,车身长度,使用年限及CO、HC、NO 的实测浓度等11 个属性,还包括设备号、检测车辆的通过时间、车牌号码、车辆颜色、识别置信度等5个属性。相关属性的描述性统计分析结果如表2所示。
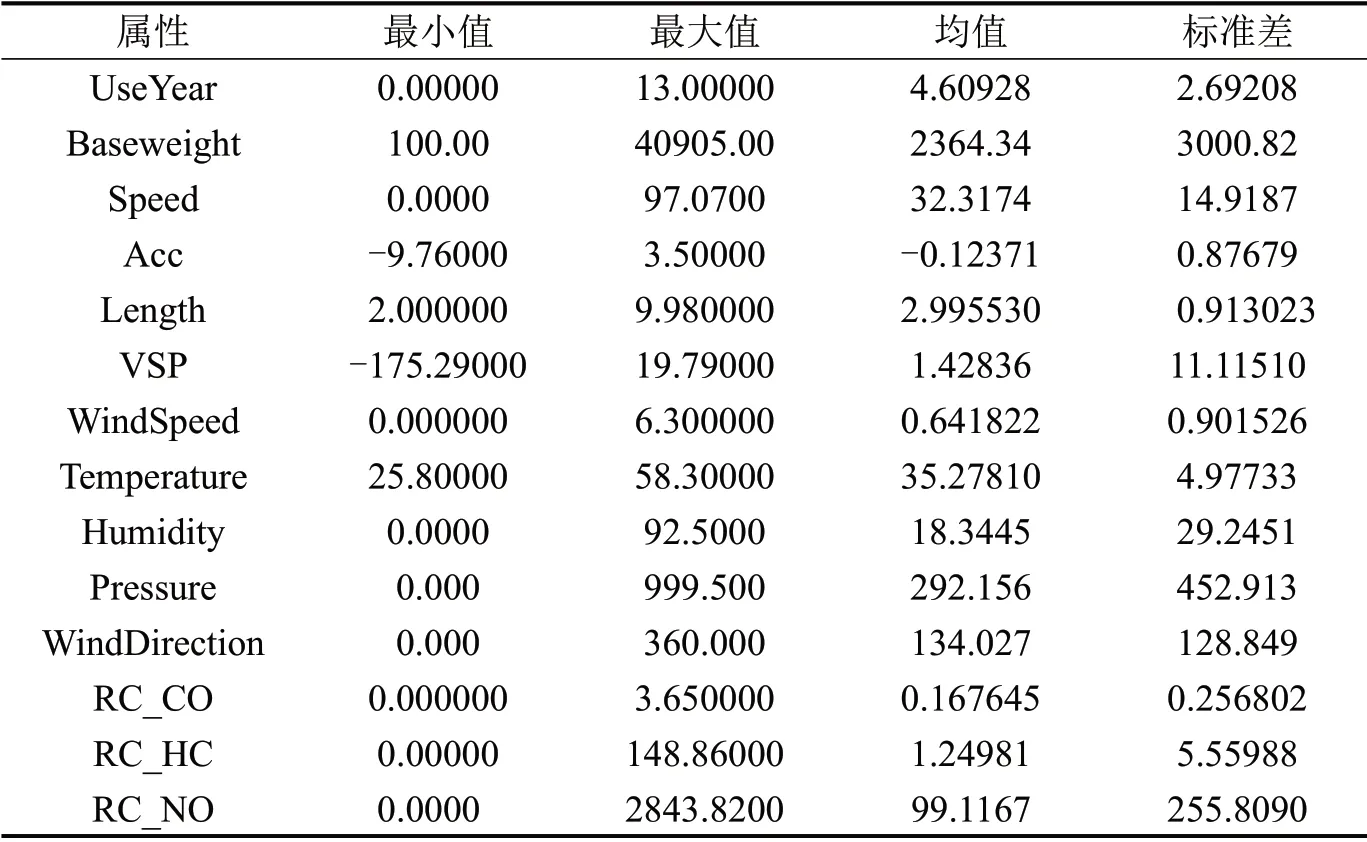
表2 相关属性的描述性统计Table 2 Descriptive statistics of relevant attributes
2.2 随机森林特征选择
影响污染物排放的特征属性不仅维度高,而且对各污染物排放的影响程度也不尽相同。因此,通过随机森林算法计算出各因素的重要性比例,完成特征选择。
计算步骤如下:
Step 1 输入污染物数据样本N和影响特征M。
Step 2 对输入样本进行bootstrap采样,同时对影响特征M随机采样,使用Gini 指数选择划分属性并采用完全分裂的方式构造决策树。
Step 3 重复Step 2构建K棵决策树组成森林,计算每棵决策树的袋外数据误差,Eerror1,Eerror2,…,EerrorK。
Step 4 随机对OOB(Out of Bag)数据中某个影响特征xi加入噪声干扰值,再次计算袋外数据误差,E′error1,E′error2,…,E′errorK。
Step 5 影响特征xi的重要性比例为
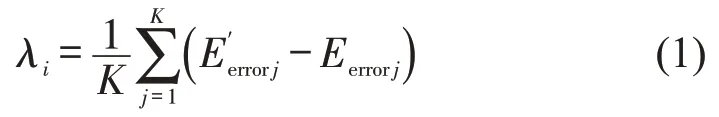
各属性对污染物CO、HC、NO的排放影响比例计算结果如表3所示,可视化如图2所示。
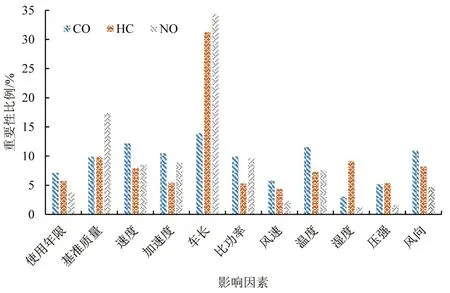
图2 各影响因素的重要性比例柱状图Fig.2 Importance percentages of attributes
本文选取影响比例不低于平均值的属性作为各污染物的主要影响因素。选择条件为

式中:i为第i种污染物,i=1,2,3,分别对应表3中的3 种污染物CO、HC、NO;j为第j种影响属性,j=1,2,…,11,分别对应表3中的各属性;λi,j为第i种污染物第j个属性的影响比例;α为影响比例平均值,即α=1/11 ≈0.090901。
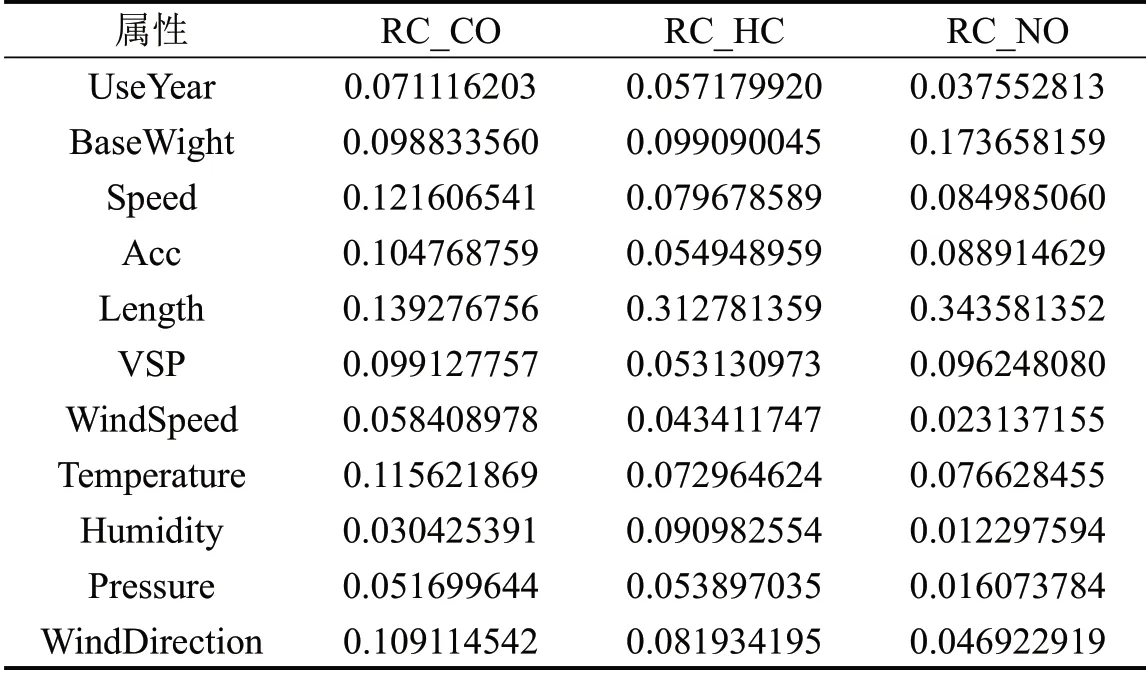
表3 各属性对污染物排放的重要性占比Table 3 Importance ratio of each attribute to pollutant emissions
从重要性统计结果中得出结论:车长对各污染物排放的影响比例最高。对于CO 排放而言,整体上各个属性影响程度较为接近;对于HC 和NO 而言,车长、基准质量的影响比重较大,其余多数属性影响比重较小且接近。表明:不同类型污染物的外部影响因素并不完全相同,因此,主要影响特征也不完全相同,需要独立分析;车长较长、质量较大的车型(例如,货车)成为高排放源的可能性更大,因此,很难设立统一的标准(例如,排放阈值)适用于所有车辆;温度、风向等环境因素对污染物排放的影响在分析与研究中不可被忽视。
2.3 深度特征聚类
通过随机森林选择出各污染物排放的主要影响属性后,分别对各污染物(CO、HC、NO)和其主要影响属性组成的数据集进行聚类分析,得到高排放移动源的类别标签。首先,对数据集进行标准化处理,目的是消除不同属性之间量纲的影响;然后,使用自适应聚类算法K-means、K-medoids、K-means++对数据集进行聚类,并借助DBI(Davies-Bouldin Index)作为衡量指标确定一种效果最佳的聚类算法;最后,绘制不同簇别所对应的污染物排放正态分布曲线,标记高排放类别。
标准化处理方式为
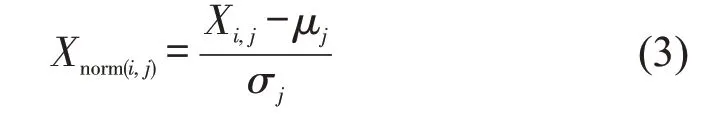
式中:i=1,2,3;j=1,2,…,n;μj为第j列的均值;σj为第j列的标准差。
K-means 算法被用来对污染物数据进行聚类。与其他划分式的聚类算法相比,K-means算法与K-medoids算法的区别在于簇中心u的选择方式上,簇中心u的表述形式为


式中:Dk为第k类样本点的集合,xi与xj为Dk中不同的样本点;Nk为Dk中样本点的数量。相较于K-medoids,使用K-means可以具有更高的效率。
K-means++算法确定k个簇中心的思想:首先,随机选取第1 个簇中心;之后,选取的第n个簇中心(2 ≤n≤k)应选择距离前n-1 个簇中心较远的样本点,即距离前n-1 个簇中心越远的点被选中作为第n个簇中心的概率越大。
本文使用DBI 衡量聚类结果的有效性。DBI通过计算距离度量相同类之间的相似性、不同类之间的差异性,计算方式为
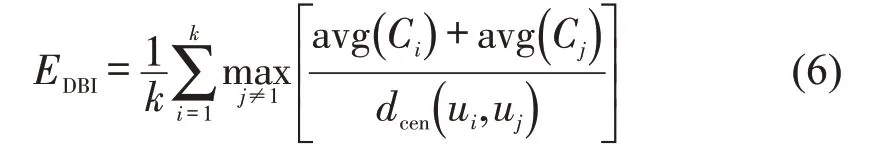
式中:k为簇别数;Cθ(θ=i,j)为类θ样本点,avg(Cθ)为类θ样本点与其簇中心uθ的欧式距离平均值;dcen(ui,uj)为第i类簇中心ui与第j类簇中心uj之间的欧式距离。DBI越小,表示相同类之间的相似性越高、不同类之间的差异性越大,聚类效果越好。
聚类之后,通过拟合不同污染物各个聚类类别拟合的正态分布曲线确定高排放移动污染源所对应的类别。正态分布函数表达式为
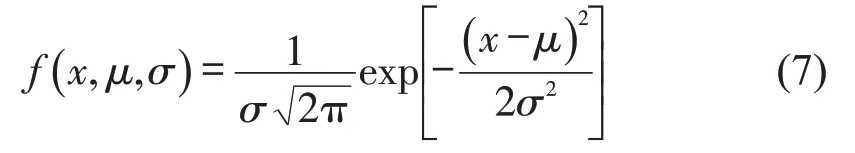
式中:x为污染物的测量值;μ为污染物浓度的平均值;σ为污染物浓度的标准差。
不同聚类算法在污染物及其属性特征数据集上计算得到的DBI 值如表4所示。通过比较,Kmeans算法在数据集上的表现更优异一些。
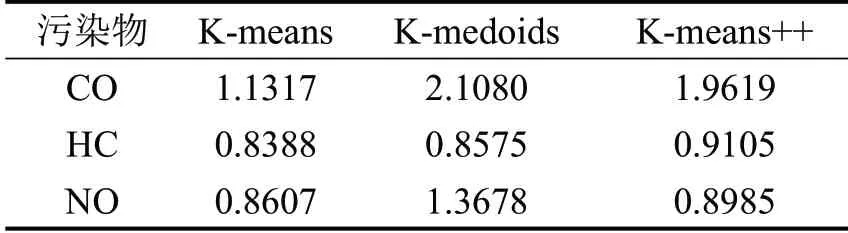
表4 各聚类算法的DBI值比较Table 4 DBI of various clustering algorithms
鉴于数据集的特征维度较高,因此,采用T-sne降维显示以便于聚类效果可视化。污染物CO、HC、NO采用K-means算法聚类后的可视化效果及正态分布曲线如图3所示。
图3中clu0、clu1 和clu2 表示聚类之后不同的类别。通过观察3 种污染物不同类别的拟合分布曲线可以得出:CO 的clu1,HC 的clu1,NO 的clu2这3条曲线具有共同的特点——均值最大,并且上限值最大,因此,对应的类别被标记为污染物的高排放类(即类别标签为高排放),其余类别被标记为低排放类。结合聚类可视化图可以看出,高排放类别样本数占总样本数的比例较低,表明在路行驶的高排放移动源数量较少。
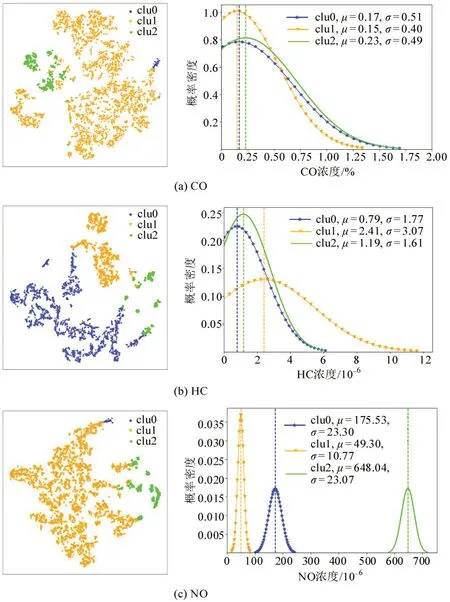
图3 不同污染物的聚类可视化及拟合分布曲线Fig.3 Clustering visualizations and fitting distribution curves of pollutants
2.4 分类
获得污染物的高排放类别标签后,进行高排放移动源分类识别。经统计,高排放类别污染物的样本数量比例较低。统计结果如表5所示。

表5 各污染物高排放类别样本的统计结果Table 5 Statistics of high emission samples of pollutants
若直接进行高排放类别分类预测,极易造成模型过拟合。因此,在正式构建分类模型之前,引入样本平衡策略解决高排放标签数量稀少的问题。
在高排放移动源的自动识别中,本文构建的分类模型是基于深度森林的深度集成学习算法。经过实验对比验证,相较于传统的分类方法,即随机森林(Random Forest,RF)、支持向量机(Support Vector Machine,SVM)和k 近邻算法(k-Nearest Neighbors,KNN),深度森林(gcForest,DF)具有更高的识别准确率。
2.4.1 样本不平衡处理
SMOTE(Synthetic Minority Oversampling Technique)算法可被用来解决高排放类别的样本不平衡问题。SMOTE是一种基于随机过程采样算法的改进方案,舍弃了直接复制少数类样本以增加其数量的策略,从而使模型在一定程度上避免了过拟合问题。SMOTE算法的基本思想是对少数类样本进行分析并将随机合成的新样本扩充到原始数据集中。新样本点合成过程如图4所示,图中,d1、d2表示不同的空间维度,圆圈表示普通样本,五角星表示合成新样本的候选样本。

图4 样本合成示意Fig.4 Process of synthesizing samples
采用SMOTE算法对高排放类别样本进行合成的主要流程为:
(1)对于高排放类中某一样本xi,计算它到其他高排放样本的欧式距离,得到n个最近邻样本。
(2)根据预先设定的采样倍率,从高排放类样本xi的n个近邻中随机选择若干个样本(可重复)。
(3)若样本x′i被选择,则新合成的高排放类别样本xnew计算方式为
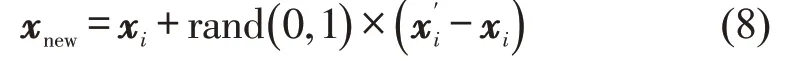
2.4.2 分类模型构建
对3 种污染物主要影响属性数据集聚类得到高排放标签后,利用深度森林(gcForest,DF)、随机森林(RF)、支持向量机(SVM)和k 近邻算法(KNN)实现排放源的分类,并对有效性进行验证和比较。
gcForest是一种基于决策树的深度集成学习方法,主要由级联森林和多粒度扫描两部分组成。gcForest模型结构如图5所示,图中,RF和CRF分别为“随机森林”“完全随机森林”。
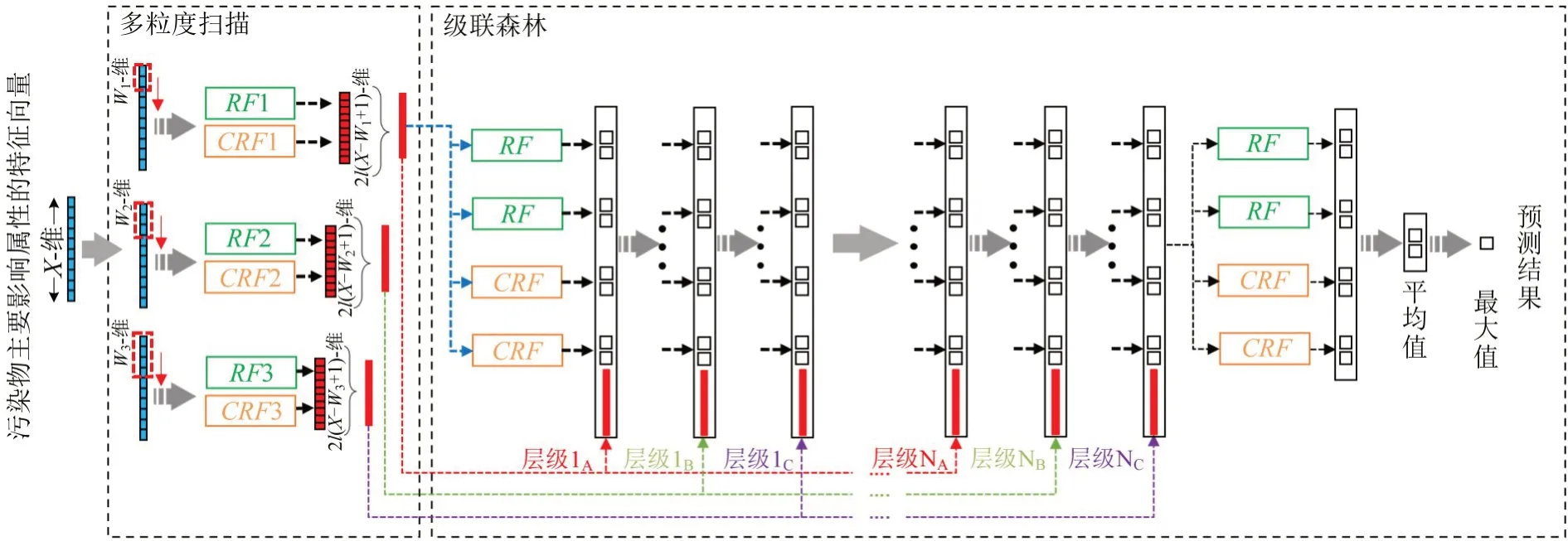
图5 gcForest结构Fig.5 Structure of gcForest
因受到深度神经网络的启发,gcForest 引入了级联森林结构,类似于层层连接传播信息的多层节点网络。级联森林的每一级都是由完全随机森林和随机森林组成的,并且它们的基本组成单位都是决策树。在构造时,完全随机森林与随机森林的不同点在于,完全随机森林的决策树节点是在所有属性中随机选择1个属性进行分裂的,而非在随机采样的属性子集中选择最佳属性进行分裂。森林的个数是个超参数,可根据实际问题的规模进行适当地调整。在高排放识别问题中,将每一级森林设定为2个完全随机森林和2个随机森林。
图5中,级联森林拥有多个层级,层级中的每个森林均产生1个类向量,代表该森林对输入特征的类别预测概率,并且类向量的维度与预测的类别个数保持一致。本文每个森林会产生一个2 维的类向量,每层级联森林输出的结果和多粒度扫描的输出特征经拼接后共同构成了下一层的输入。在训练过程中,层级将会不断增长,直到模型预测准确度的提升幅度不足够大或算法达到预设的最大层数。最终,对最后一层的类向量求得平均值,并选择概率最大的类别输出为gcForest 的预测结果。
为了增强级联森林对样本特征向量的学习效果,gcForest 设置了多粒度扫描结构。该结构具有数个多粒度滑动窗口,可以对输入样本的特征向量进行扩充。例如,在图5中,首先输入一个X维的污染物特征向量,经长度为Wx维(x=1,2,3)的滑动窗口扫描,可得到(X-Wx+1)个W维的特征向量集合;然后,该集合经随机森林和完全随机森林训练后产生2×(X-Wx+1)个l维的属性向量;最后,拼接得到一个2l(X-Wx+1)维的多粒度扫描输出向量,被用来参与级联森林结构的运行过程。其中,l为模型的分类数,即特征向量不同类别标签的个数。本文排放源被划分为高排放类和低排放类,因此,l=2。
Random Forest:随机森林是一种基于统计学理论的集成分类器,通过bootstrap重抽样方法构建多棵决策树,并采取投票的方式输出最终的判定结果。本质上,该算法是一个包含有限个树形分类器的集合[12]。由于是一种集成学习模型,因此,对离群值并不十分敏感。同时,在高量级的数据集上具有较优的运行效率。通常,对所有决策树采用平均法计算随机森林的输出结果。平均法分为加权平均法和简单平均法,加权平均法为

式中:wi为个体决策树hi的权重,特殊地,当wi=1/T时,式(9)为简单平均法。

gcForest模型实现分类功能的伪代码
Support Vector Machine:支持向量机将样本实例映射为特征空间中的点,并寻找到一个超平面对不同类别的实例进行最大程度地间隔和划分。然后,将新的待预测实例映射到同一特征空间中,并根据它所处的被超平面划分的区域来判断其所属类别。
例如,在二分类样本空间中,用于划分的超平面可以使用方程表示为

式中:w和b分别为超平面的法向量和截距。当实例xi(i=1,2,…,n)处于超平面不同侧时,分别表示其类别yi属于正例或负例。
通常,遇到的问题多数是非线性问题。SVM利用核技巧(kernel trick)将线性支持向量机推广到非线性支持向量机。核技巧主要分为两个过程:(1)使用核函数将原始空间的样本点映射到更高维的空间中;(2)在新的高维空间中使用线性方法进行分类。
k-Nearest Neighbors:KNN 是一种原理简单的算法。在分类过程中,它的思想是通过某种度量方式,寻找到距离待预测样本点最接近的k个邻近样本点,并选择这些临近样本点中出现次数最多的类别标签作为预测结果。因此,k是一个预设定的超参数,并且尽可能取值为奇数,从而避免不同类别标签出现相同次数的情况。度量距离的方式有很多种,例如,Minkowski距离是较为常用的一种,即
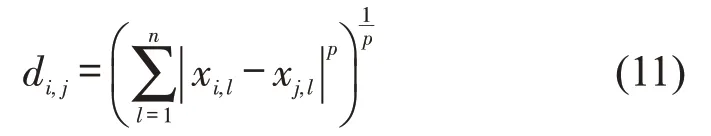
式中:样本点i′=(xi1,xi2,…,xin) ;样本点j′=(xj1,xj2,…,xjn)。p是一个参数,当p=1 时,式(11)为曼哈顿距离(Manhattan distance);当p=2 时,式(11)为欧几里得距离(Euclidean distance)。
2.4.3 评价指标
分类模型的分类性能使用分类精度(Eaccuracy)、查准率(Eprecision)、查全率(Erecall)和F1值进行评价。其中,F1值为查准率和查全率的均值。计算方式为

式中:ETP、ETN、EFP、EFN分别为真正例、真负例、假正例和假负例。
3 实验和讨论
为了验证所提方法的有效性和优越性,设置多个对比实验。所有实验均基于Windows10-64bit operation system with an Intel Core I5-6300HQ 2.3 GHz CPU and 12 GB RAM。
本文基于合肥市机动车尾气遥测数据,经过样本平衡处理后,得到高排放样本与低排放样本数量比为1∶1的3种污染物(CO、HC和NO)数据集。按照7∶3的比例,随机地分为训练集和测试集。样本非平衡情形下,各分类模型对不同类别污染物的识别精度如表6所示。
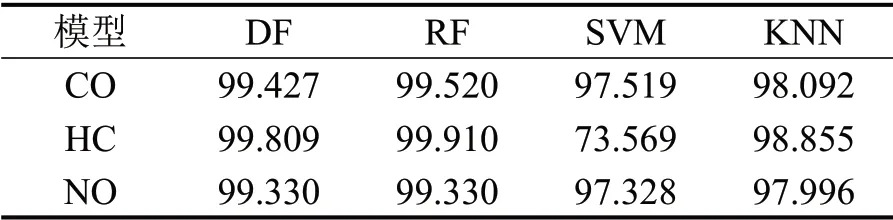
表6 非平衡样本上的模型分类精度Table 6 Accuracy of models on imbalance samples (%)
从表6中可以看出,在未引入高排放样本平衡策略下,不同分类模型的识别精度不但十分高而且相近(在高排放标签数量占比中,HC 明显高于CO和NO,因此,SVM在HC数据集上的预测准确度最低),模型易过拟合。同时,由于高排放类别标签稀缺,且数据集划分具有随机性,因此,容易导致模型训练不充分,不能真正反映模型的识别能力。
基于以上原因,本文通过引入样本平衡策略增加高排放标签的数量,验证所提方法的有效性。经SMOTE 算法处理后,污染物平衡样本的数据统计结果如表7所示。
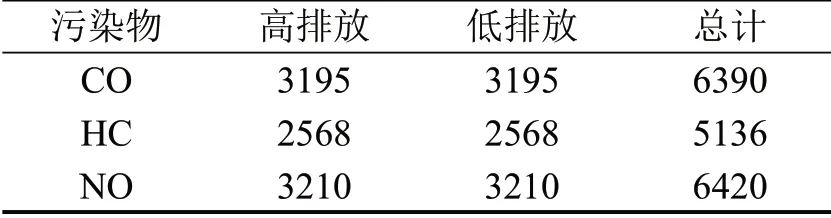
表7 污染物的平衡样本统计Table 7 Balance sample statistics of pollutants
分类模型深度森林(DF)(本文)、随机森林(RF)、支持向量机(SVM)和k近邻算法(KNN),在3种污染物(CO、HC和NO)测试集上的分类精度如表8所示。

表8 平衡样本上的模型分类精度Table 8 Accuracy of models on balance samples (%)
从表8的统计结果可以看出,深度森林分类模型在3 种污染物测试集上表现都是最佳的。与之效果接近的是拥有类似组成结构的随机森林模型,在HC 测试集上,和深度森林模型输出相同的预测结果,得到相同的识别准确率。
各模型在平衡样本与非平衡样本上的分类精度如图6所示。通过引入平衡策略、增加高排放标签的数量,深度森林模型在各污染物数据集上的预测效果几乎达到最高。
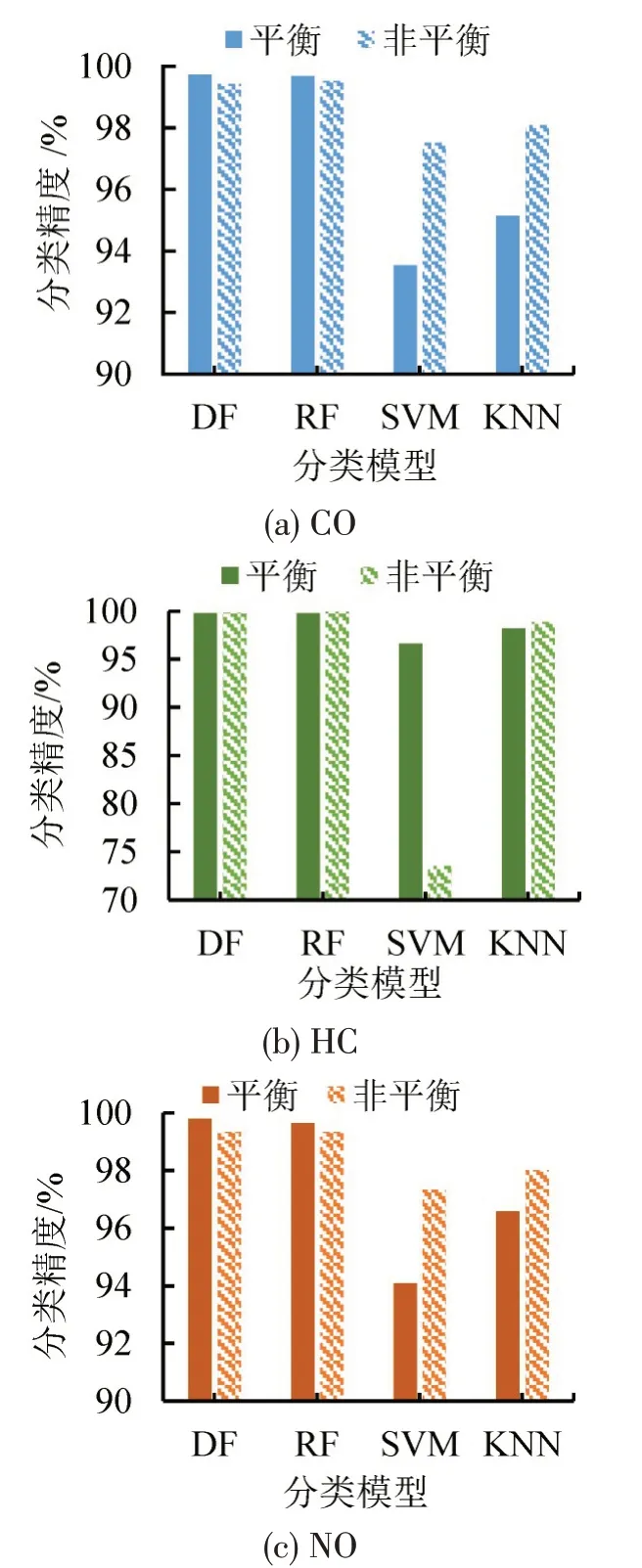
图6 平衡与非平衡样本的分类精度比较Fig.6 Confusion matrix for CO
各分类模型在CO、HC、NO测试集上的混淆矩阵如图7~图9所示。图中,H表示高排放样本,L表示低排放样本,色度条表示样本数量(颜色越深,数量越多;颜色越浅,数量越少)。
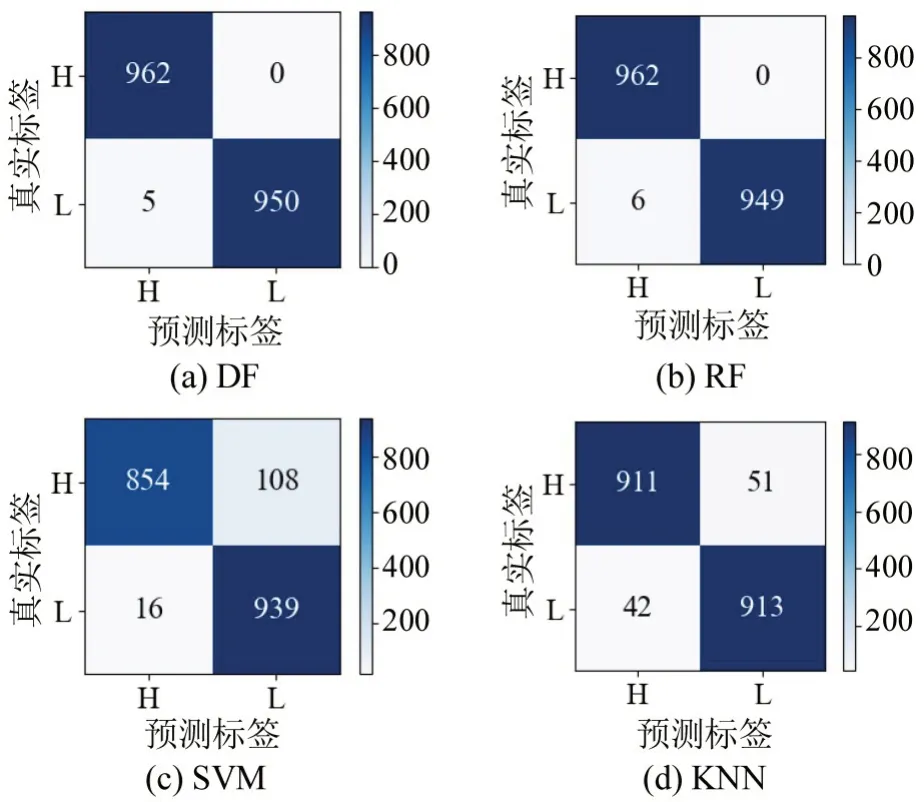
图7 CO测试集混淆矩阵Fig.7 Confusion matrix for CO
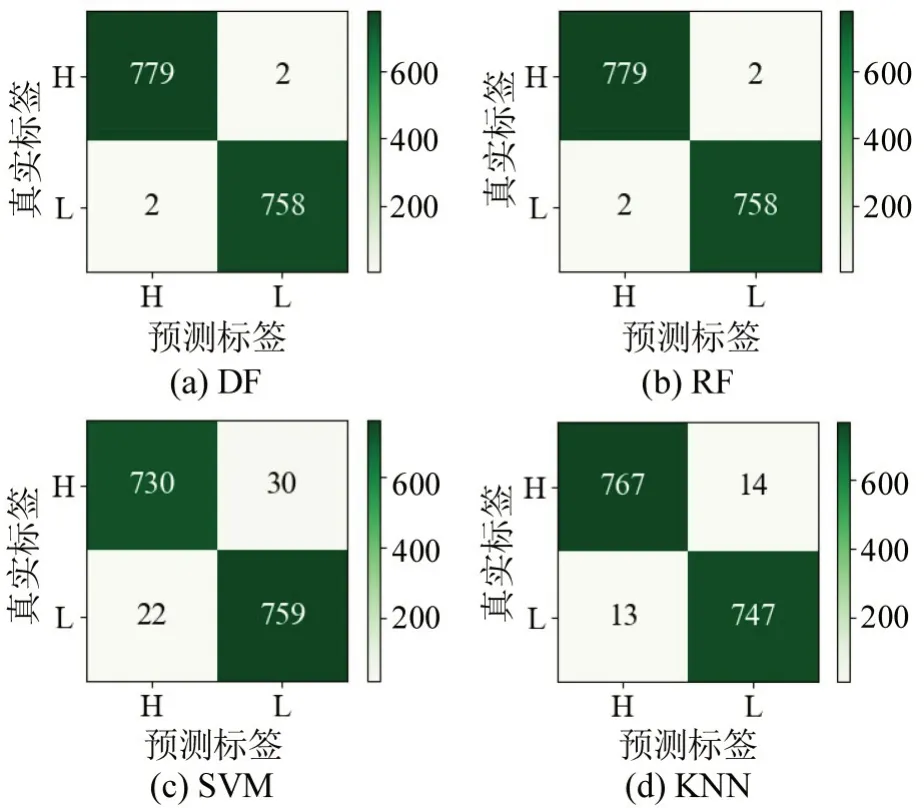
图8 HC测试集混淆矩阵Fig.8 Confusion matrix for HC
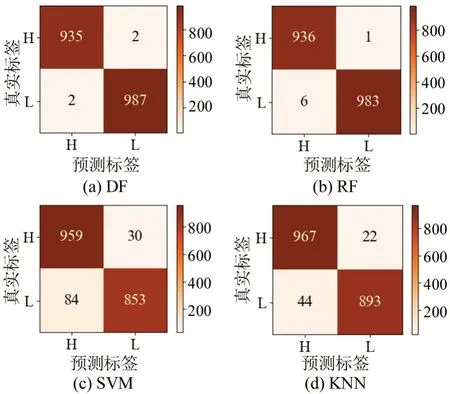
图9 NO测试集混淆矩阵Fig.9 Confusion matrix for NO
各种污染气体的混淆矩阵的统计结果如表9~表11所示。包含:查准率(P)、查全率(R)和F1值。
从表9~表11可以看出,深度森林(DF)模型在污染物CO、HC、NO 的测试集上基本都取得了最好的预测效果。因为深度森林具备传统集成学习方法的优势,相较于SVM 和KNN 这类独立的学习算法,能够利用“团队”力量更好地处理高维特征数据;同时,它的多层级联结构允许输入特征被更大程度地计算和流动,比随机森林具备更高的集成程度。
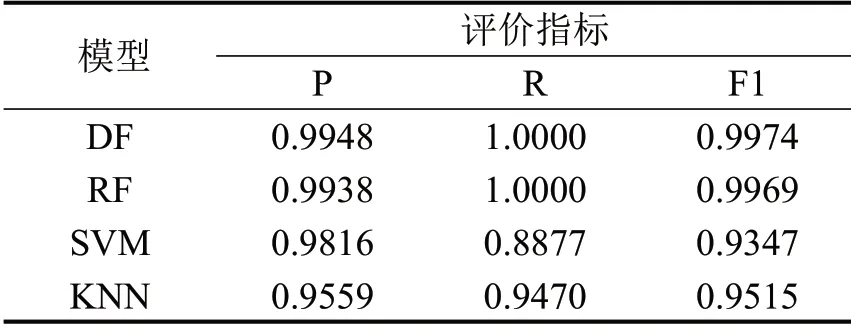
表9 CO测试集Table 9 Test_set of CO
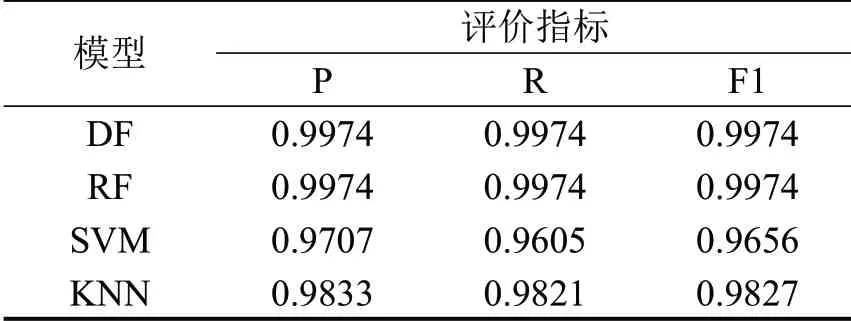
表10 HC测试集Table 10 Test_set of HC

表11 NO测试集Table 11 Test_set of NO
4 结论
本文提出了一种基于深度特征聚类的高排放移动源自动识别方法,综合考虑到实际场景中外部因素对污染物排放产生的影响,避免传统车辆检验中使用人为设定阈值方式的缺陷。
首先,利用随机森林算法计算出车辆使用时间、基准质量、速度、加速度等11 种外部因素对移动源污染物(CO、HC、NO)排放浓度的影响占比,选择比重大于平均水平的属性作为各污染物排放的主要影响特征。然后,采用K-means算法对各污染物的主要影响特征数据集进行深度聚类,通过分析不同簇别的污染物浓度分布曲线确定高排放目标标签。经统计,高排放簇别的样本数量占总样本数量的比重较低(3 种污染物的高排放样本数量平均占比为14.322%),符合道路移动源排放分布的高度偏斜性。最后,构建基于深度森林的高排放移动源自动识别模型。由于高排放标签稀缺,容易导致模型过拟合,因此,本文采用SMOTE 样本平衡策略,增加高排放样本数量,提高模型泛化能力。在合肥市机动车污染监测数据集上对各方法进行评估。相较于其他传统分类算法,较为先进的集成学习模型——深度森林,不但具有最高的分类精度,而且预测指标查准率、查全率和F1 值基本上都是最高的,验证了本方法的有效性。
猜你喜欢
铁道通信信号(2019年6期)2019-10-08
车迷(2018年11期)2018-08-30
民族古籍研究(2018年1期)2018-05-21
海峡姐妹(2018年3期)2018-05-09
雷达学报(2017年6期)2017-03-26
公民与法治(2016年10期)2016-05-17
新校长(2016年8期)2016-01-10
少儿科学周刊·少年版(2015年2期)2015-07-07
浙江大学学报(工学版)(2015年1期)2015-03-01
电子设计工程(2015年6期)2015-02-27
