
越江越海隧道入口段追尾事故风险预测模型研究
2021-12-31 03:52陈丰张婷黄雅迪陈慈河张曙光吕明
交通运输系统工程与信息 2021年6期
陈丰,张婷,黄雅迪,陈慈河,张曙光,吕明
(1.同济大学,道路与交通工程教育部重点实验室,上海 201804;2.中国城市规划设计研究院,西部分院,重庆 400000;3.中交西南投资发展有限公司,成都 610213)
0 引言
随着交通需求的不断增长,素有“交通咽喉”之称的越江越海隧道事故多发。越江越海隧道入口周边路网往往较为复杂,多为高速公路或城市快速路汇入区,与匝道、服务区或立交相邻,多股交通流相互交汇,交通流状态复杂。越江越海隧道入口段为发生交通事故和引起严重拥塞的关键区域。同时,由于地形限制,越江越海隧道入口段一般会设置长大纵坡,以实现与两岸路网的合理顺接,而隧道内外环境剧烈变化,易造成驾驶人对突发情况避让不及时,导致越江越海隧道入口段追尾事故频发。
智能交通系统的发展使得动态获取交通信息成为可能,极大地提高了交通信息的丰富程度,基于相关交通信息,事故风险实时预测模型应运而生,用于预测交通事故发生的概率。Abdel Aty等[1]先是基于事故发生前30 min 内事故点上下游断面的交通流数据构造事故样本,用广义估计方程(GEEs)研究交通流对高速公路行车安全的影响;然后利用配对案例对照逻辑回归方法,建立了二元Logit 事故预测模型,事故分类准确率可达69.4%。Ahmed 等[2]用AVI(Automatic Vehicle Identification)数据中的区间平均速度构造事故点附近7个路段、发生前5个时段的3个速度变量(平均速度、速度标准差、速度方差系数的对数值)共105 个解释变量,使用随机森林方法构建事故风险预测模型,取得70%的预测准确率。Zhang 等[3]基于弗罗里达州高速公路交通流数据,以机器学习方法与统计方法预测事故严重程度,发现机器学习方法中随机森林预测表现最佳。贾丰源等[4]基于上海市延安高架和南北高架线圈检测器所采集的事故数据和相应检测器数据,用随机森林模型筛选事故发生前5~10 min的交通流特征变量,构建基于贝叶斯网络的实时交通流事故风险预测模型,事故预测准确率达到82.78%。游锦明等[5]基于某高速公路道级交通流数据,采用配对案例对照的方法,建立追尾事故实时预测支持向量机模型,总体事故预测精度为84.85%。赵海涛等[6]提出一种采用激活函数Relu的卷积神经网络的交通事故预测算法,预测结果相比其他激活函数具有更高的准确度和更低的损失。
目前,短时交通事故风险预测研究依赖于高密度、高频率的交通流数据,过往研究中采用的交通数据主要是线圈检测器数据,国内部分学者已经开始探索基于其他交通数据源的事故风险预测方法,包括AVI 数据、RTMS 数据和雷达检测器数据等,但在交通风险预测中,引入驾驶模拟器实验数据配合实际数据进行验证的研究较少,驾驶模拟器可较为真实的重现实际道路,重复性好、实验成本低,能够有效测评驾驶人的驾驶感受。此外,现阶段短时事故风险预测模型大多基于高速公路场景,针对越江越海隧道的研究较少,而越江越海过江隧道行车环境和交通流特性等与其他隧道、公路存在较大差别,现有的短时事故风险预测模型难以应用于越江越海隧道场景,同时越江越海隧道多为交通咽喉节点,事故的影响范围也会更大,因此本文依据越海越江隧道交通环境特性,选取上海长江隧道入口段作为典型越江越海隧道入口段,以小汽车为研究对象,基于驾驶模拟实验,研究越江越海隧道入口段驾驶人行为特性及追尾事故风险预测。
1 实验与数据准备
本文选取上海长江隧道入口段为例开展研究,为研究越江越海隧道入口段驾驶人行为特性和实现追尾事故风险预测,首先利用驾驶模拟器对驾驶人在经过越江越海隧道入口路段的车辆操控数据进行采集。
1.1 实验设备
本次实验使用的仿真软件是SCANeR studio 1.6,该软件可以进行3D 道路路径设计、道路景观设计、车辆动力学模型构建,同时可以通过软件提供的API 接口编写程序以调整能见度、风速、路面附着系数、天气状况等实验条件。此外,该软件能够根据时间和距离实时记录实验车辆及其他车辆的速度、加速度、横向偏移等运行参数,方向盘转角、油门踏板、制动踏板操作等驾驶员操作参数等,为实验设计及数据分析提供了全面的技术保障。
驾驶模拟器的硬件设备包括3块LED显示屏、驾驶座椅、油门刹车踏板、罗技G27方向盘、操纵杆等。此外,后视镜和仪表盘内置在显示屏中。3 块屏幕可提供约135°的视野,营造出更真实、立体的驾驶感受。
1.2 实验场景建立
(1)道路场景
实验依据上海长江隧桥入口段的实际线形进行场景设计,如图1所示,上海长江隧桥南入口段场景模型以过渡直线段-匝道-隧道外直线段-隧道内直线段为一个场景单元,参照上海长江隧桥南入口段设计资料,实验场景匝道、主线设计车速80 km · h-1。根据设计的实验场景,使用SCANeR StudioTM仿真软件中的terrain 模块建立场景的道路逻辑层。
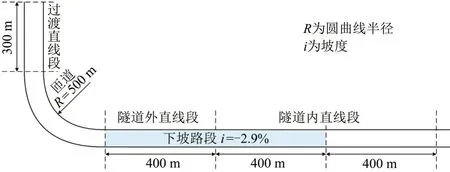
图1 实验场景分段示意图Fig.1 Section diagram of Experiment scene
(2)天气场景
考虑到恶劣气象条件对行车能见度、路面附着系数等方面的负面影响,有必要设置不同天气环境及其对应的路面附着系数,来研究天气-附着系数对驾驶人驾驶行为的影响规律。本实验共设置3种天气场景,分别为晴天、雨天、雪天。雨雪天气下隧道外受气象环境的影响,路面附着系数降低,而隧道内路面相对干燥,附着系数变化不大,因此,隧道入口内外的路面附着系数存在突变的情况,实验中3 种气象条件和隧道内外路面附着系数参数设置如表1[7]所示。

表1 SCANeR StudioTM仿真软件天气参数设置Table 1 Weather parameters setting in SCANeR StudioTM
(3)交通流场景
交通场景设计中,设置自由流、拥挤流、拥堵流这3种交通流状况,为反映隧道入口段的交通流状态,根据上海长江隧道入口内50 m 处监控视频(如图2所示),选取2018年10月1日高峰时段11:00-12:00 交通流调查数据,统计隧道入口段内侧小客车车道共计1351 条车速数据,使用K 均值聚类算法分别对拥堵流、拥挤流两种状态下的车速值进行划分。车速聚类结果如表2所示。根据聚类结果,实验中自由流、拥挤流、拥堵流情况下的前车速度分别为80,40,20 km·h-1。

表2 基于车速的交通流聚类结果Table 2 Results of traffic flow clustering based on speed

图2 道路监控视频截图Fig.2 Screen capture of monitor video
1.3 实验人员选取
驾驶模拟实验最终选取33 名实验人员,年龄跨度在25~45岁,驾驶经验在2年以上,女性占比为30%,接近2020年中国驾驶人中女性占比(32%),矫正视力均在5.0 以上。通过预实验,所有被试驾驶人均无不适,能够完成实验。
1.4 实验过程
首先,被试驾驶人需了解本次实验规则及驾驶模拟器操作方法,填写基本信息调查表和多维驾驶风格量表(MDSI-C)[8],完成实验前的准备工作。随后被试驾驶人在指定预实验场景进行启动、加速、减速、变道、转弯等适应性操作。正式实验中,每位驾驶人需完成3 种天气场景(晴天、雨天、雪天)中3种交通流状态实验,并在3种交通流状态下分别设置了1 次前车急刹车事件,以研究驾驶员的应急反应情况,实验事件脚本设计如图3所示。

图3 实验事件脚本设计Fig.3 Plan of experiment
1.5 数据提取
实验数据主要包括驾驶人在实验前填写的问卷数据,驾驶模拟器自动收集的车辆行驶状况数据以及驾驶人的驾驶数据等。具体采集的实验数据类型如表3所示。

表3 实验数据类型Table 3 Type of experimental data
2 变量选择
2.1 变量初选
由于本研究旨在建立事故风险预测模型,对数据按事故是否发生进行分类。因此需使用驾驶员在正常跟驰中的行为数据,初步选择如表4所示的数据建立样本集,涵盖天气、交通流、驾驶风格、正常跟驰阶段纵横向驾驶行为等一系列数据,具有较好的代表性。

表4 初选变量说明Table 4 Description of primary variable
2.2 相关性分析
变量初选时考虑到模型的全面性,除驾驶员编号外共选择了19 个变量,但部分变量之间可能存在一定的相关性。为进一步提高模型的运行效率及简洁性,对拟纳入模型的变量进行相关性分析。利用Pearson相关系数反映两个变量之间线性相关性的强弱水平,当 |r|≥0.6 时,认为两变量间为强相关。计算结果如表5所示,可知,两车速度差标准差和车头间距标准差、车头时距最小值和车头间距最小值、拥堵流和车头时距标准差这3对数据的相关系数大于0.6,可认为这3对变量之间存在强相关性,只保留每对其一,综合考虑后去掉车头间距标准差、车头间距最小值、车头时距标准差这3 种变量。

表5 变量相关性矩阵Table 5 Matrix of variable correlation
2.3 基于随机森林的变量选择
随机森林(Random Forest)是一种包含多个决策树的有效分类器,其输出的最终分类取决于个别树输出分类的众数。基于基尼系数降低的变量排序可以用来解释变量对随机森林模型数据异质性的影响,有助于确定每个变量的重要性。
对变量进行相关性分析后,确定了存在强相关性的3 对变量,为防止重复,剔除了每对中的一个变量。在模型建立时,为了保证模型的简洁性和高效性,还需考虑变量对模型结果的重要性,因而有必要对拟采用的变量进行重要性排序。
利用随机森林算法,经过反复实验,决策树分类节点(mtry,可确定每次迭代的变量抽样数值,用于二叉树的变量个数)设置为5,决策树数目(ntree,指定随机森林所包含的决策树数目,默认为500)设置为500时,结果如图4所示,模型的误差趋于稳定的最小值。

图4 随机森林模型误差变化Fig.4 Error trend on random forest model
变量重要程度根据MDA(Mean Decrease Accuracy)和MDG(Mean Decrease Gini)两个指标判断。由图5可知,根据MDA 和MDG 指标排序,车头时距最小值、两车速度差最大值、急躁、加速度标准差、拥堵流这5个变量对追尾事故风险预测模型精度重要性最高,而天气因素对于追尾事故预测模型影响甚微。为有效降低模型的复杂度,减少模型运算时间,提高预测精度,基于变量重要性分析将重要性较小的变量予以剔除,选取车头时距最小值、两车速度差最大值、急躁、加速度标准差、拥堵流这5个变量建立随机森林模型。
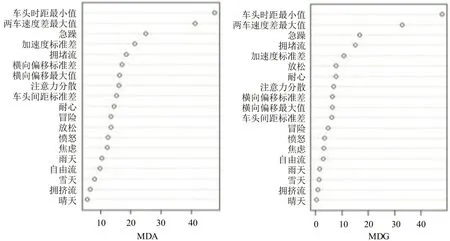
图5 初选变量重要性排序Fig.5 Sequence of importance of primary variables
3 模型建立与评价
随机森林是一种基于决策树理论构建分类和回归树集成,引入随机属性进行训练的机器学习算法。该算法可有效避免过拟合和局部收敛问题,对异常值和噪声有很强的容忍度,具有预测精度高、调节参数少等优点。因而,本文选取随机森林算法构建越江越海隧道入口段追尾事故风险预测模型。
3.1 随机森林模型
随机森林计算过程可以简要描述如下:假设每个样本具有N个特征,分配一个小于N的常数n,并从N个特征中随机选择n个特征子集。每次树分支时,它都会从n中选择最佳分支。随机森林在生成时不考虑剪枝,每棵树均以最大的程度生长。对每个样本,计算它作为OOB样本树的分类情况,之后通过简单多数投票作为该样本的最终分类结果。随机森林OOB错误率是错误分类的数量与总数的比率,随机森林方法原理如图6所示[9]。
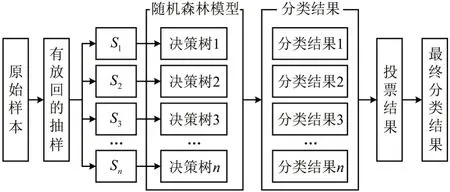
图6 随机森林方法原理示意Fig.6 Principle of random forest
3.2 基于随机过采样策略的随机森林预测模型
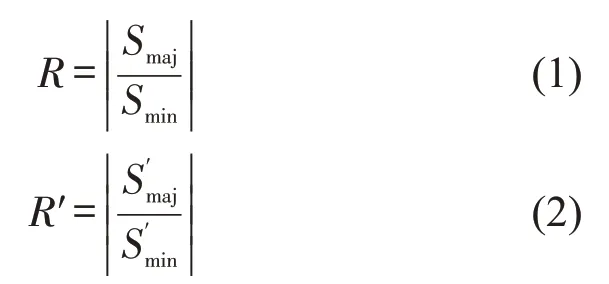
在驾驶模拟实验采集的297条数据中,仅有22条数据为追尾事故数据,不平衡系数R=13.5,是一个典型的不平衡样本。随机森林在处理不平衡数据集时,其Bootstrap重抽样方法的随机性和决策树的局限性会加剧数据集的不平衡性,导致随机森林算法的性能降低[9]。
针对不平衡数据集问题,引入数据平衡方法对随机森林算法进行优化,要求经过预处理的训练样本抽样后得到训练子集不平衡系数R′低于2,降低训练样本的不平衡系数,将不平衡以适应随机森林算法,提高算法预测准确度。不平衡系数计算公式为
式中:Smaj为原始样本多数类数据数量;Smin为原始样本少数类数据数量;S′maj为预处理抽样后多数类数据数量;S′min为预处理抽样后少数类数据数量。常用的样本平衡方法有过采样法和欠采样法。随机过采样法通过增加少数类样本的数量来提高误分类该类样本的代价,进而控制分类界面的偏移,可以改善分类器性能。而随机欠采样法通过随机删除大类的观测直至数据集平衡,本文数据不平衡程度较大且样本量较小,不适宜采用欠采样算法,故采用随机过采样法对训练集进行平衡化处理,降低数据不平衡系数,以提升算法性能。将原始数据随机分为训练集(70%)和测试集(30%),通过随机过采样法进行平衡化处理后得到训练样本,基于随机过采样策略的随机森林算法流程如图7所示。
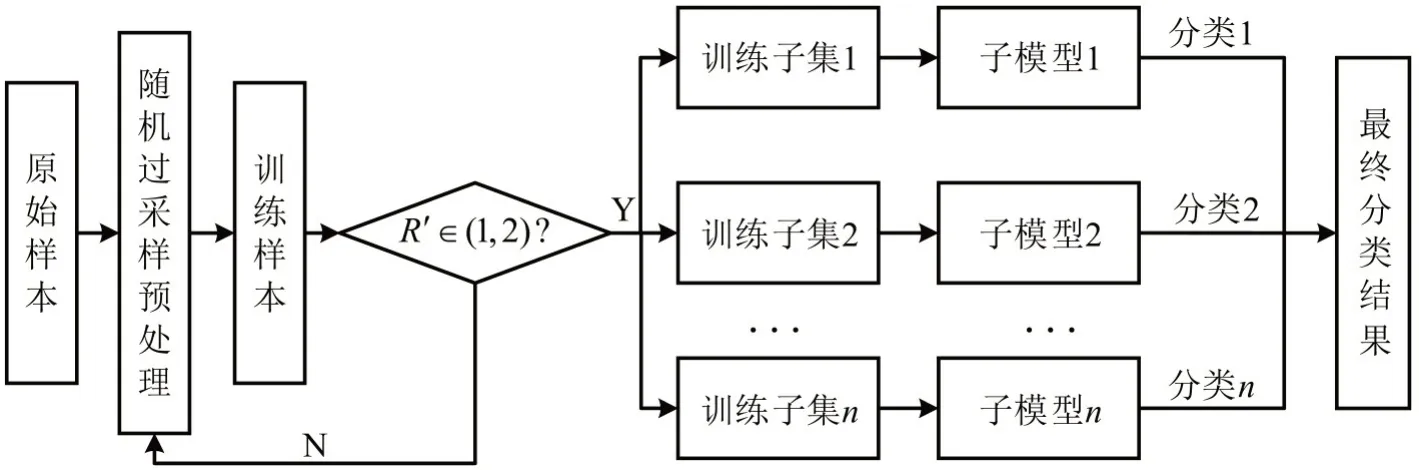
图7 随机过采样-随机森林模型流程图Fig.7 Flowchart of random oversampling-random forest model
3.3 模型评价指标
在非平衡数据分类中,准确率指标难以衡量模型的有效性,混淆矩阵(表6)是非平衡数据分类中模型评价的常用方法[10],本文选取几何均数和ROC曲线的AUC(Area Under Curve)作为模型评价指标,其中,几何均数G为
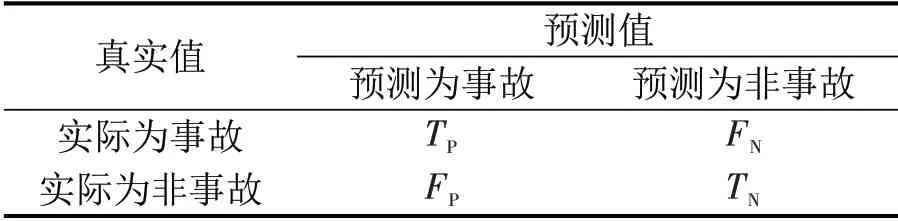
表6 混淆矩阵Table 6 Mixed matrx

式中:Se为灵敏度;SP为特异度;F为误报率;TP为真阳性;FP为假阳性;TN为真阴性,FN为假阴性。
4 模型结果与讨论
综合对比基于随机过采样策略的随机森林模型和传统随机森林模型、XGBoost 模型、支持向量机模型在越江越海隧道入口段追尾事故风险中的预测性能,以评估本文构建的随机过采样-随机森林模型的有效性。
4.1 模型优缺点对比
为了更全面地分析和比较4种算法的优劣,从理论角度出发,比较4种算法的优缺点,如表7所示。

表7 随机森林、XGBoost和支持向量机算法优缺点比较Table 7 Advantages and disadvantages of random forest,XGBoost and support vector machine
4.2 模型预测性能对比
表8给出4 个模型在测试集上的灵敏度、特异度、误报率、几何均数和AUC 指标。可以看出,随机森林和XGBoost 模型的灵敏度达到100%,但非事故误报为事故的比例较高;从几何均数来看,随机森林模型的综合预测效果优于XGBoost模型、支持向量机模型;相比原随机森林模型,随机过采样法-随机森林模型的灵敏度有所降低,但其几何均数提高了1.8%,AUC指标提高了6.8%,且误报率控制在13.54%,表明在越江越海隧道入口段追尾事故风险预测中,随机过采样法-随机森林模型的整体预测性能最优。
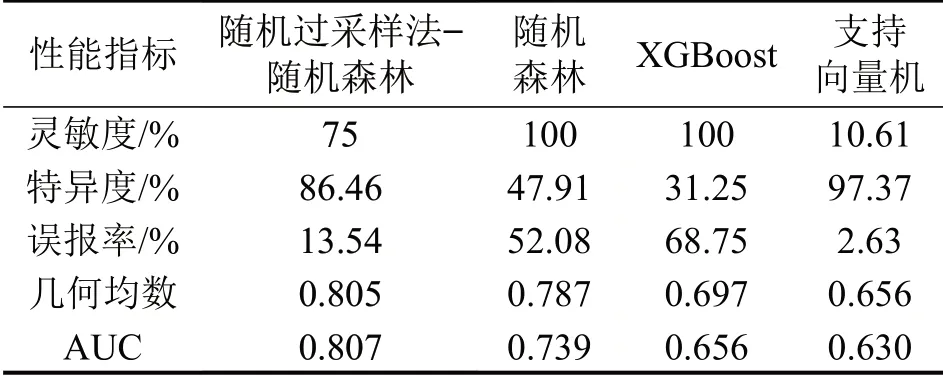
表8 预测模型效果对比Table 8 Comparison of prediction effect
图8为基于随机过采样策略的随机森林模型的变量重要性排序,可知,决定越江越海隧道入口段追尾事故发生与否的最主要因素是车头间距、速度差、加速度标准差等车辆运行状态数据,这表明在事故发生前正常跟驰阶段的车辆运行状态是决定事故发生与否的最主要因素。对此,采取优化限速控制措施及增设车距确认标志、可变信息标志等管控措施,增强驾驶人感知准确性,有望降低隧道入口事故的发生率。
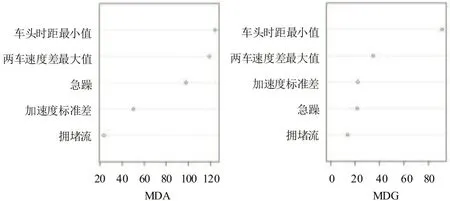
图8 基于随机过采样法-随机森林模型变量重要性排序Fig.8 Sequence of importance of variables on random oversampling-random forest model
5 结论
(1)在越江越海隧道入口段追尾事故风险预测中,随机森林模型的整体预测效果优于XGBoost和支持向量机模型。
(2)本文引入随机过采样对随机森林模型进行不平衡数据处理,基于随机过采样策略的随机森林模型AUC 提高了6.8%,达到0.807,这表明随机过采样-随机森林模型在越江越海隧道入口段追尾事故风险预测中具有较好的适用性。
(3)基于随机过采样策略的随机森林模型变量重要性排序表明,车辆运行状态是影响事故风险的最主要因素,可通过采取优化限速控制措施及增设车距确认标志、可变信息标志等管控措施,增强驾驶人感知准确性,以期降低隧道入口事故的发生率。
猜你喜欢
汉语世界(The World of Chinese)(2021年4期)2021-09-05
青少年科技博览(中学版)(2019年1期)2019-04-25
测控技术(2018年5期)2018-12-09
测控技术(2018年2期)2018-12-09
好日子(2018年9期)2018-10-12
作文大王·笑话大王(2017年1期)2017-02-21
作文大王·笑话大王(2016年10期)2016-10-18
作文大王·笑话大王(2016年7期)2016-08-08
西南交通大学学报(2016年3期)2016-06-15
作文大王·笑话大王(2016年2期)2016-02-24
