
基于改进LDA的社会化标签主题识别方法
2021-12-31 04:08:06李慧宗
安徽理工大学学报(自然科学版) 2021年5期
邰 悦,葛 斌,李慧宗
(1.安徽理工大学计算机科学与工程学院,安徽 淮南 232001; 2.南阳师范学院计算机科学与技术学院,河南 南阳 473061)
社会化标签是Web2.0时代的重要衍生资源,主要来源于电商平台、社交平台、医疗服务等众多应用场景中,但是这些社会化标签以及对应的资源存在着自发性、独立性和随机性。传统主题模型在对社会化标签资源进行主题识别时,往往采用词袋模型进行处理,会导致资源权重分布和采样过程不合理。因此,消除社会化标签资源之间的独立同分布特性,构建潜在关联关系并通过加权方法对资源内容和标签内容进行加权,再通过改进的LDA模型对资源进行主题识别是本文研究重点。
1 相关工作
1.1 社会化标注系统
社会化标注系统为互联网用户和研究人员提供了一个自由开放的平台,使得海量语义源数据进行了有效利用。可以用于主题识别与聚类、社会化推荐和web对象分类,方便用户进行搜索,组织和共享资源。
近年来对社会化标签的研究热度依旧不断。例如文献[1]提出构造UATM (User-based Aggregation Topic Model)用于分析社交数据,分析用户的偏好和意图分布,利用RNN(Recurrent Neural Network)和IDF (Inverse Document Frequency)来构造权重,并提出折叠的Gibbs采样算法用于UATM模型推断。
标签不仅仅局限于文本,也可以对图像标签进行研究,可以提高资源内容和对应标签的质量,从而提高社会化标签的推荐效果以及图片和视频的检索性能。文献[5]基于移动推荐系统提出一个基于社交标签聚类方法的移动应用个性化推荐系统框架,可以为未来移动推荐系统提供备选方案。这些处理方法都没有考虑社交数据的爆炸,即为信息超载,为了克服这一问题文献[6]采用多源社会大数据的跨领域推荐系统,通过结合跨领域方法的优势,将用户偏好从相关辅助域转移到目标域,提高推荐的多样性。
1.2 主题模型
对标签数据进行主题建模是对社会化标签研究的重要环节,主题模型已被广泛应用于文本数据分析中,文献[7]对PLSA (Probabilistic Latent Semantic Analysis)模型进行扩展并提出了LDA主题模型来对文档集合进行建模,从而发现文档中潜在的语义结构。LDA是在PLSA的基础上引入了狄利克雷先验分布超参数,形成一个包含文档、主题和词的三层贝叶斯结构模型,该模型是一个基于产生式的概率模型。LDA模型是处理文本数据的有效手段并具有较好的主题挖掘效果。
结合或改进LDA主题模型进行文本处理的方法有很多,文献[9]在变分自编码器(Variational Auto-Encoder,VAE)的基础上,采用舍入重参数技巧(Rounded Reparameteriztion Trick,RRT)作用于VAE-LDA,舍入重参数化狄利克雷分布并提出RRT-VAE模型。文献[10]通过挖掘资源的深层次的语义,通过提取概念和命名实体来丰富评论,提出Concept-LDA模型用于挖掘在线评论系统的情感分析。也有通过使用VAE推断思想的主题模型AVITM(Autoencoded Variational Infer-ence for Topic Models),并将其应用于一个LDA变形形式的主题模型ProdLDA上以验证其在主题建模的效果和效率。文献[12]提出一种TagCDCTR (Tag-informed Cross Domain Collaborative Topic Regression) 模型,通过在标签对跨领域资源和资源相似性编码,并通过域间关系学习其中的潜在因素,可以更好地获取资源。
尽管多数主题模型对社会化标签的研究已有比较优异的表现,但是对结合消除独立同分布特性并加权处理方法依旧匮乏。
2 基于JFWW-LDA的主题识别方法
2.1 信息熵相似度
假设Web资源集合中有M
个资源,每个Web资源由文本评论资源和对应的标签资源组成并记为R
和T
,并将每个文本评论资源和标签资源视为文本文档,用集合来表示R
={r
,r
,…,r
,…,r
}(1)
T
={t
,t
,…,t
,…,t
}(2)
式中:r
表示文本评论集合中的第i
个评论资源,t
表示标签集合中的第i
个标签资源。设h
(r
)为资源第i
个文本评论信息熵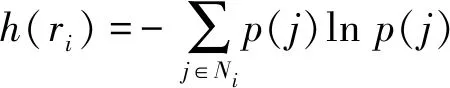
(3)
式中:p
(j
)为第j
个词语的概率;N
是第i
个评论资源的文本长度,则每个文本评论信息熵可以用集合表示为H
(R
)={h
(r
),h
(r
),…,h
(r
),…,h
(r
)}(4)
同理,标签资源的信息熵也可以用集合表示为
H
(T
)={h
(t
),h
(t
),…,h
(t
),…,h
(t
)}(5)
本文提出一种基于信息熵相似度系数用来描述文本资源之间的相似性的度量方法。在信息熵的基础上计算资源集合中任意两个资源的相似性,记为sim(i
,j
),i
,j
∈{1,2,…,M
},其中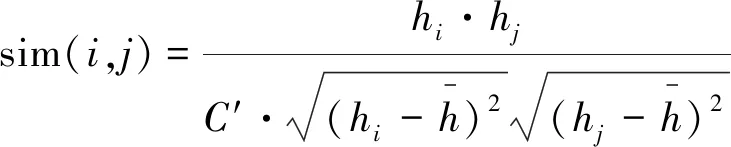
(6)
C
′为一个常数,本文取值为1 000。其中文本评论资源的信息熵相似度记为r
_sim(i
,j
),i
,j
∈{1, 2, …,M
},同理标签资源的信息熵相似度记为t
_sim(i
,j
)。利用信息熵相似性系数来建立资源集合之间的潜在关联性,并将其建立成评论资源无向图R
=(R
,ER
,),其中R
={r
,r
,…,r
,…,r
}为评论资源集合,ER
⊂R
×R
为评论资源无向图边的集合,为R
的邻接矩阵,同理建立标签无向图T
=(T
,ET
,)。根据信息熵相似度建立资源之间无向图的基本思想如下。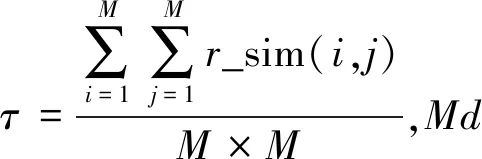
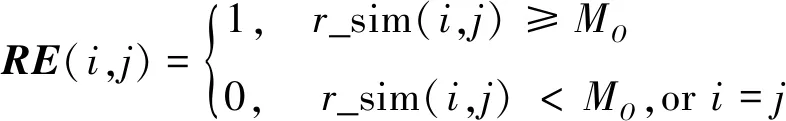
(7)
由式(7)可计算得到×矩阵。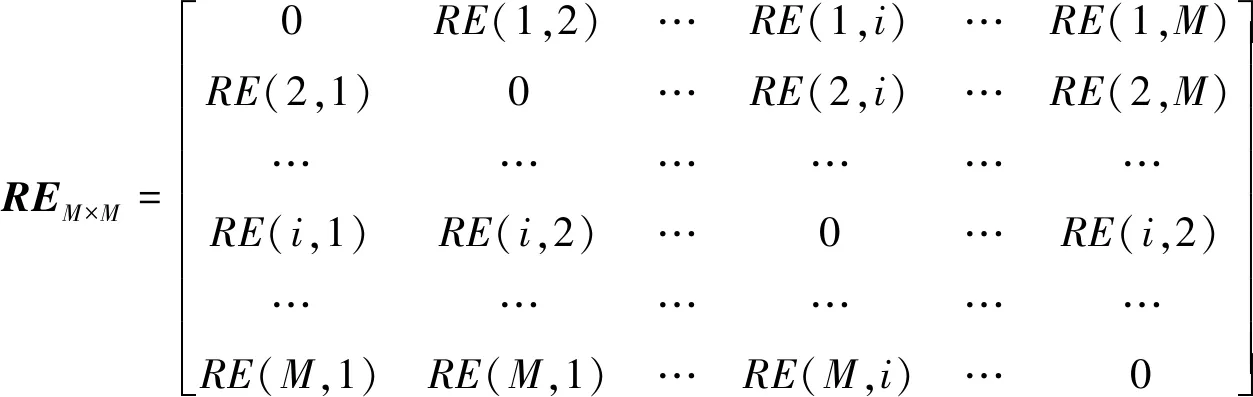
(8)
由×矩阵可以形成资源之间的无向图,对于矩阵中任意元素RE
(i
,j
),若RE
(i
,j
)=1,说明资源i
和j
之间存在相似性,则在图R
的结点i
和j
之间添加一条无向边;若(i
,j
)=0,则不添加无向边。基于这一思想,计算出所有资源之间的信息熵相似度并形成资源边矩阵×,由矩阵×构建出无向图R
,如图1所示。2.2 基于信息熵相似度下随机游走的资源潜在关系分析
在信息熵相似度建立资源潜在关系的基础上,通过信息检索领域的随机游走方法计算无向图R
与T
,获得每个评论资源和标签资源的权重值。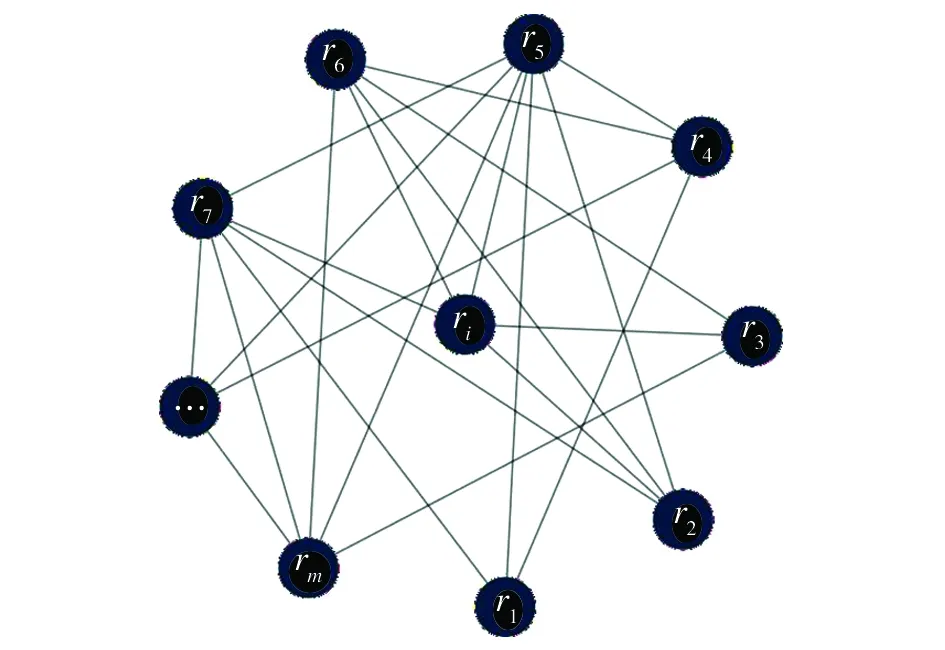
图1 基于信息熵相似度下的评论资源间无向图RG
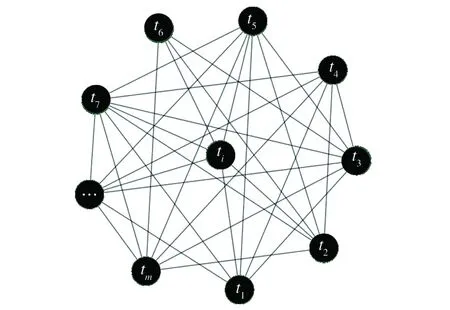
图2 基于信息熵相似度下的标签资源间无向图TG
例如图R
=(R
,ER
,)中任意两个顶点r
和r
,根据基于信息熵相似度下的资源潜在关联无向图模型,若存在一条从r
到r
的无向边,wr
,=1,否则wr
,=0,使用其邻接矩阵的行随机矩阵作为随机游走过程的转移概率矩阵。其中的节点P
,代表从资源r
跳转资源r
的转移概率,定义为式(9)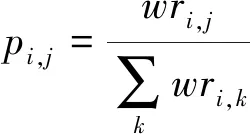
(9)
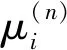
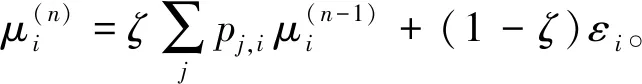
通过随机游走获取资源本身和对应标签的权重值,将该权重值作用于加权方法中,最终形成两种特征词权重向量。
2.3 加权方法
对R
和T
使用随机游走模型并获得资源和标签的权重值向量和,将该权重向量作用于加权方法中。假设M
个评论和标签资源共包含了V
个特征词, 本文需要对这些资源进行加权处理。 将每个评论资源视为一个文本文档, 其评论频次向量为式(10)FR
(m
)=[v
,fr
(v
,m
);v
,fr
(v
,m
);…,v
,fr
(v
,m
);…;v
,fr
(v
,m
)](10)
式中:fr
(v
,m
)表示评论资源m
中特征词v
出现的频次。评论资源m
的权重值为μ
,资源及其特征词的加权表示形式为式(11)g
_FR
(m
)=[v
,gfr
(v
,m
);v
,gfr
(v
,m
);…;v
,gfr
(v
,m
);…;v
,gfr
(v
,m
)](11)

标签资源频次向量为式(12)
FT
(n
)=[v
,ft
(v
,n
);v
,ft
(v
,n
);…;v
,ft
(v
,n
);…;v
,ft
(v
,n
)](12)
式中:ft
(v
,n
)表示标签资源n
中特征词v
出现的频次。标签资源n
的权威度分数为σ
,标签资源及其特征词的加权表示为g
_FT
(n
)=[v
,gft
(v
,n
);v
,gft
(v
,n
);…;v
,gft
(v
,n
);…;v
,gft
(v
,n
)](13)

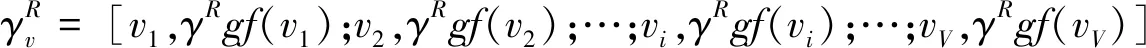
(14)
其中
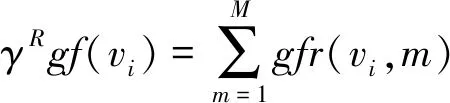
(15)
表示将所有评论资源中的特征词v
加权后出现的频次进行累加,即M
个资源中对于特征词v
加权后出现的频次进行累加,即每一个特征词v
拥有对应的权重值形成γ
向量。同理,M
个标签资源中V
个特征词的赋权向量γ
为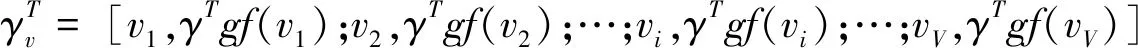
(16)
其中
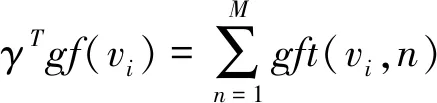
(17)
通过基于信息熵相似度的随机游走方法处理得到资源和对应标签的权重值,并对这些权重值进行加权方法处理,最终获得资源字典单词的特征词权重向量γ
和标签字典单词的特征词权重向量γ
,将两种向量作用于LDA模型中,形成联合特征词加权-LDA。2.4 联合特征词加权-LDA
基于联合特征词加权-LDA模型(Joint Feature Word Weighting-LDA,JFWW-LDA)如图3所示。
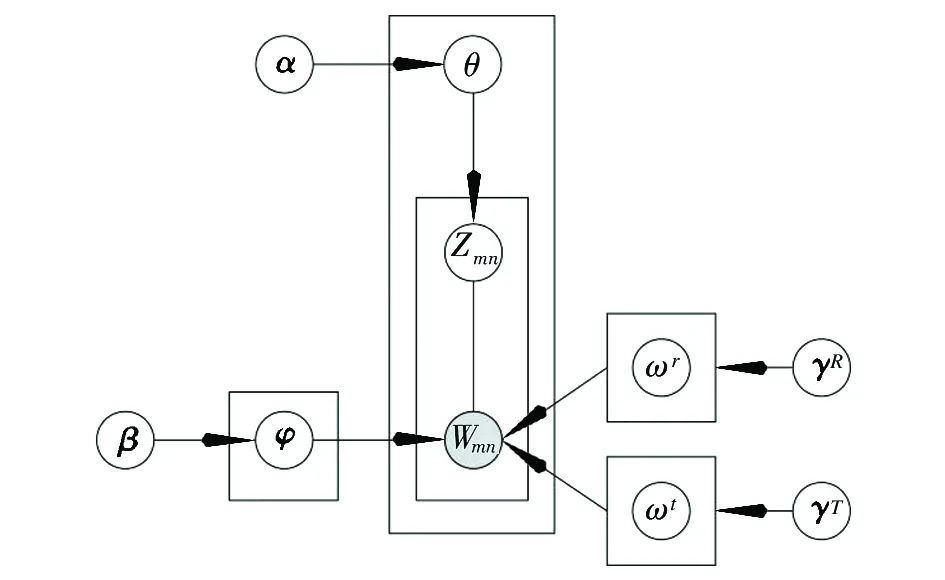
图3 联合特征词加权-LDA模型
已知社会化标签系统中有M
个评论资源和对应的标签资源以及假设涉及K
个主题,有V
个单词,基于联合特征词加权-LDA模型生成过程如下。每个隐含主题都有各自的词分布,即先验参数为β
的Dirichlet先验分布;从Dir(β
)中采样隐含主题生成词的分布参数φ
;从Dirichlet先验分布Dir()和Dir()中采样隐含主题生成词的分布参数ω
和ω
。此时将评论资源和对应的标签资源融合为一个数据集合,即视为M
个资源,对于每个资源都有各自的主题分布,且主题分布是多项分布,该多项分布的参数服从Dirichlet分布且该分布的先验参数为α
,即对于某一资源m
从先验参数为α
的Dirichlet先验分布Dir(α
)中采样资源m
的隐含主题分布θ
。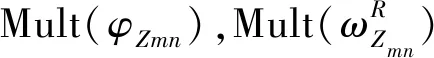
在JFWW-LDA中,采用Gibbs采样方法来估计参数,吉布斯采样的工作原理是根据潜在变量的后验分布生成样本,但需要大量样本才能消除初始噪声,本文提出的JFWW-LDA吉布斯采样规则计算因子推导过程如下
p
(|,,,)=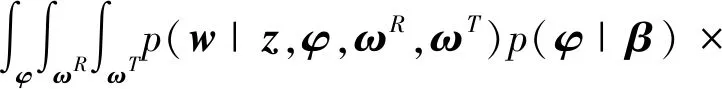
p
(|,,,)p
(|)×p
(|,,,)p
(|)ddd=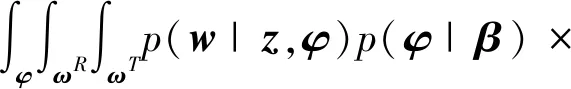
p
(|)p
(|)×p
(|)p
(|)ddd=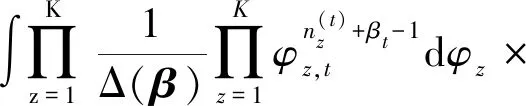
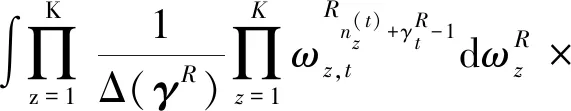
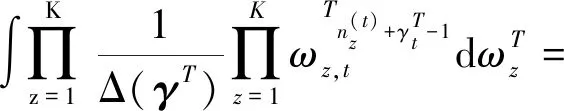
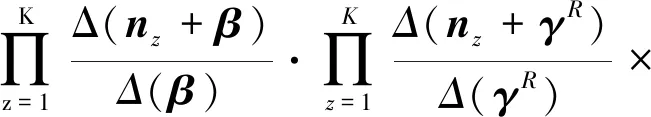
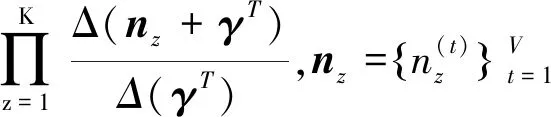
(18)
对于p
(|)可以得到下面的推论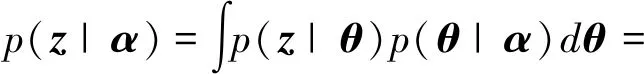
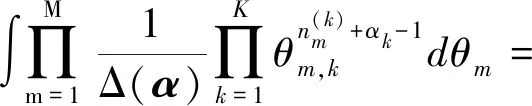
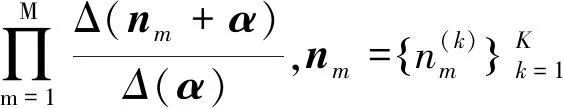
(19)
因为多项式分布的共轭分布是Dirichlet分布,将计算因子式(18),式(19)带入化简得到最终吉布斯采样的更新规则并得到式(20)

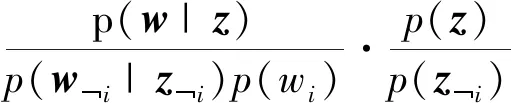
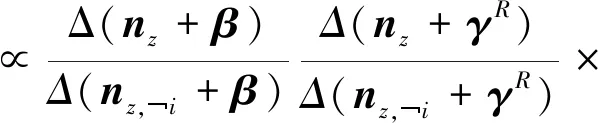
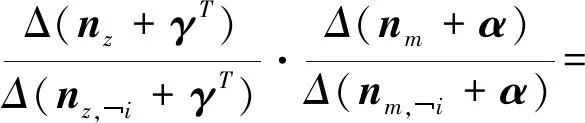
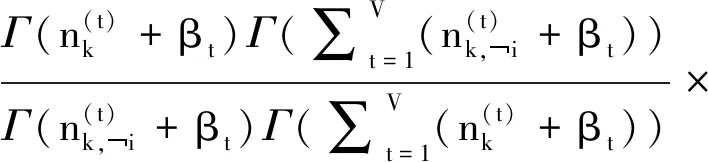
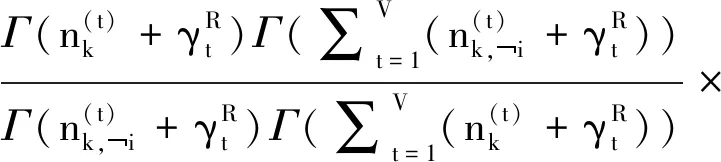
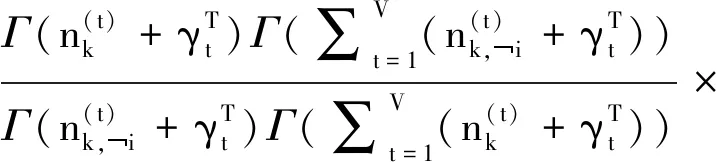
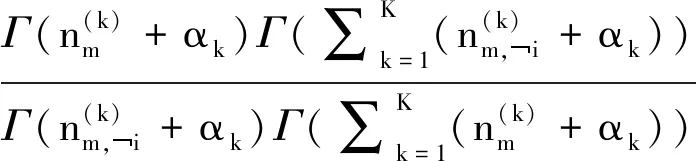
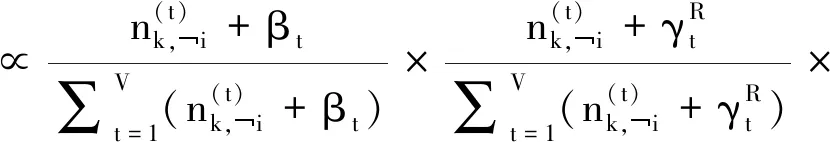
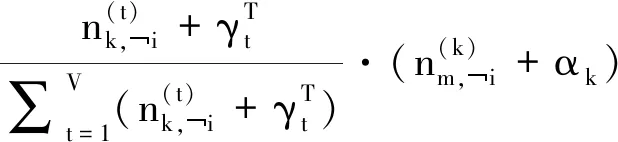
(20)
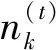
2.5 方法步骤
JFWW-LDA在对评论特征词和标签特征词加权的基础上使用隐含主题挖掘各类资源内容,经过采样迭代学习,最终采样分布结果逐渐收敛。
基于信息熵相似度下随机游走的JFWW-LDA具体过程如下:
(1)计算所有资源及其对应标签资源的信息熵相似度,分别形成评论资源无向图的资源边矩阵RE
×和标签资源无向图的资源边矩阵TE
×,依据RE
×和TE
×分别形成评论资源和标签资源的关联关系无向图R
=(R
,ER
,)和T
=(T
,ET
,),建立资源之间的隐含关系;(2)在资源之间的无向图R
=(R
,ER
,)和T
=(T
,ET
,)基础上,利用随机游走模型分别对两个无向图计算每个资源r
和t
的权重值;(3)使用式(14),式(16)对每个资源r
和t
的特征词出现频次进行加权,再根据特征词频次加权基础上对M
个资源中的V
个特征词分别经过加权方法分别形成和向量。综合这两个加权结果建立JFWW-LDA;(4)在JFWW-LDA进行主题识别过程时,将评论资源和对应的标签资源视为一个资源,即为M
个资源。依据式(20) LDA的吉布斯采样算法,从加权后的语料库中学习得到资源的K
个隐含主题及所有特征词分别在K
个隐含主题上的概率分布。3 实验及结果分析
3.1 实验数据集
本文的实验数据集分别采用CiteULike,Twitter,Yelp三种公开原始数据集对本文模型进行评估。这三个数据系统提供包含资源的标题、评论、摘要及资源的标签等信息。
实验时采用数据集资源的摘要或评论以及对应的资源标签并经过预处理操作,并分别形成评论资源数据集合和标签数据集合,经过上述预处理形成操作形成最终的数据集,各个数据集合的统计信息如表1所示。
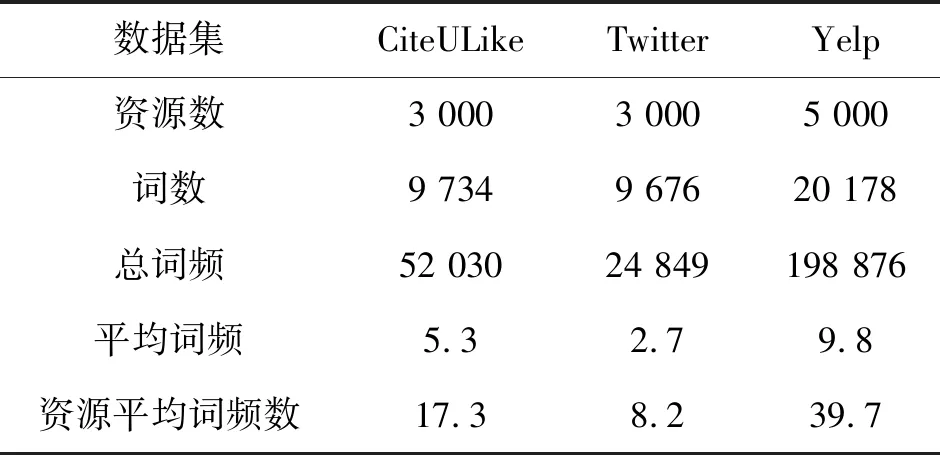
表1 数据集的统计信息
3.2 评价方法
本文使用主题平均相似度和困惑度验证JFWW-LDA模型的主题表达性能。
文献[14]提出利用主题间的平均相似度评价LDA主题模型,如果主题间平均相似性系数值越小,则说明模型主题识别效果越好,主题间的平均相似度为式(21)
Topic_avg_corre=
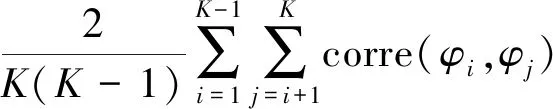
(21)
其中
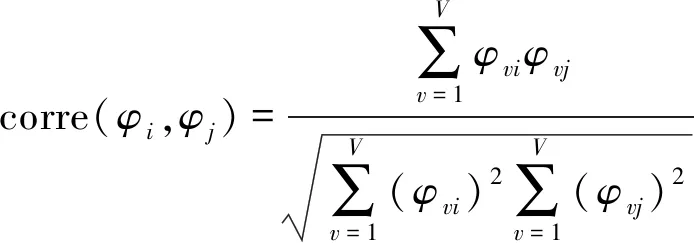
V
表示总词数。困惑度评估是信息论中的一种测量方法,是评估主题模型的一种常用方法。某个统计模型的困惑度值定义为基于统计的熵值,表示预测数据的不确定性。困惑度值越低,主题模型的表达效果越好,并且模型主题价值越高,以式(22)表示
perplexity(M
)=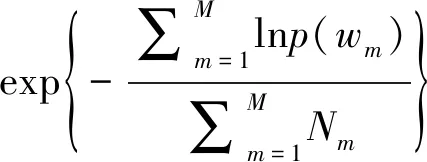
(22)
M
是实验数据集,即为M
篇文档,w
是数据集中词数,N
是资源m
中词汇的数量。3.3 参数设定
本文对先验参数α
和β
设定的初始值全部依据经验设定。其中设定α
=50/k
,设定β
=0.01,实验的迭代次数设定为1 000次。在实验过程中,所有数据集上设定的主题采样个数均为k
=20,40,60,80,100,120,140,180,200。3.4 JFWW-LDA模型性能
为验证联合特征词加权-LDA在社会化标签下的主题识别方法的有效性,采用主题间平均相似度和困惑度指数两个评价方法分别在CiteULike、Twitter和Yelp数据集上分别验证PLSA、LDA、Labeled LDA (LLDA)、Gaussian LDA (GLDA)、基于资源加权的标签LDA(Tag LDA based on Resource Weighting,TLRW)、基于资源加权的标签联合LDA(TagJoint LDA based on Resource Weighting,TJLRW)和联合特征词加权LDA(Joint Feature Word WeightingLDA,JFWLDA)七种主题模型的主题表达能力。
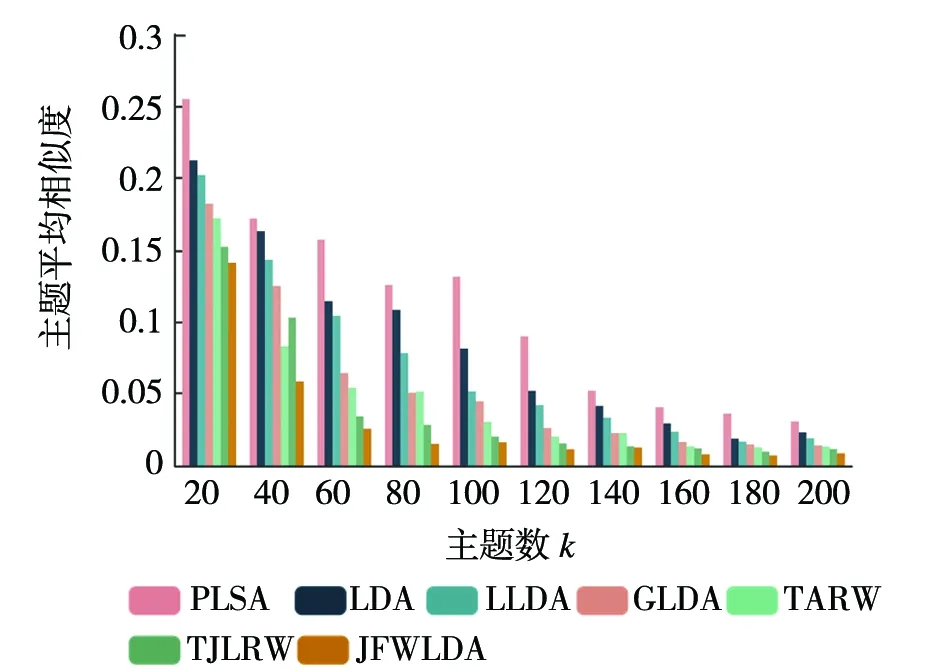
图4 各方法在CiteULike上主题间相似度对比
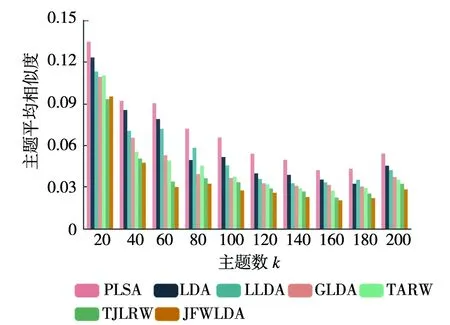
图5 各方法在Twitter上主题间平均相似度对比
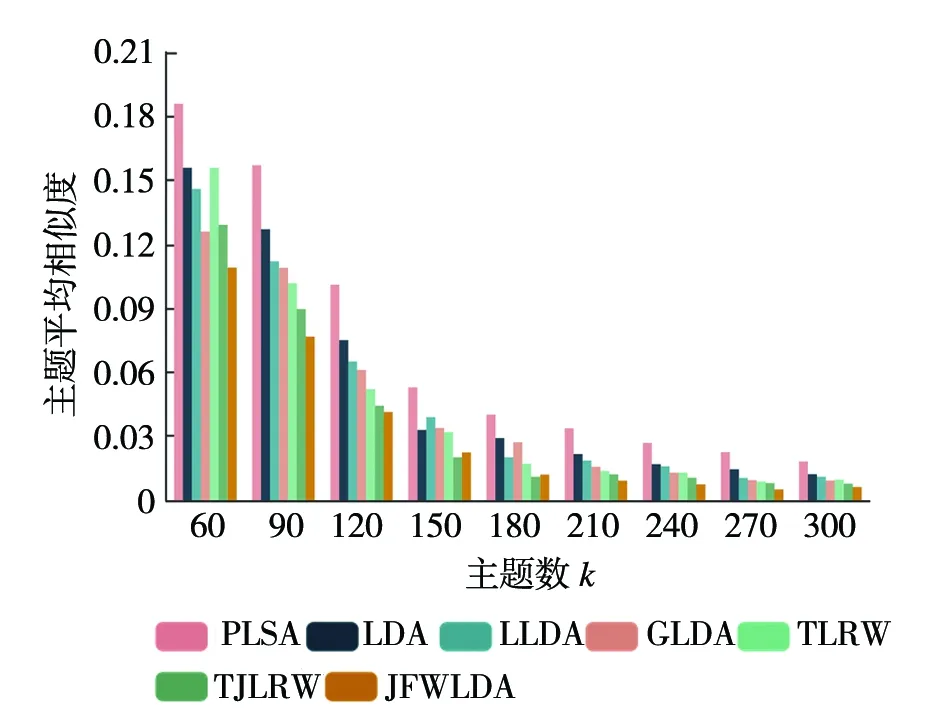
图6 各方法在Yelp上主题间平均相似度对比
图4~图6展示了各种主题方法在CiteULike,Twitter和Yelp数据集上的主题间平均相似度的评价指数。可以看出TJLRW主题模型优于PLSA、LDA、LLDA、GLDA、TLRW五种主题模型,从图4中显示出JFWW-LDA在CiteULike主题数k
=160时逐渐趋于稳定,在建模稳定时主题平均相似度为0.007 3,较TJLRW主题平均相似度指数平均降低约12%,从图5和图6中显示出相对于TJLRW主题平均相似度平均降低约9%和13%。从主题平均相似度可以看出在CiteULike和Twitter数据集上k
=160,在Yelp数据集上k
=280时,JFWLDA主题生成上更具有稳定性。图7~图9可以看出TJLRW相对于PLSA、 LDA、 LLDA、 GLDA和TLRW在困惑度评价方法上依旧具有优势,并得出JFWLDA最优困惑度指数在CiteULike、Twitter和Yelp分别为1 390,1 520和1 822,相对于TJLRW在困惑度评价方法上相对降低约7%、6%、8%。从主题平均相似度指数和困惑度指数总体上可以看出,在三种数据集上结合两种平均评价指数降低约9%、7%和10%。通过七种不同的主题模型在三种数据集上的评价方法可以得出,总体上JFWW-LDA的评价指数均优于TJLRW模型和其他主题模型。
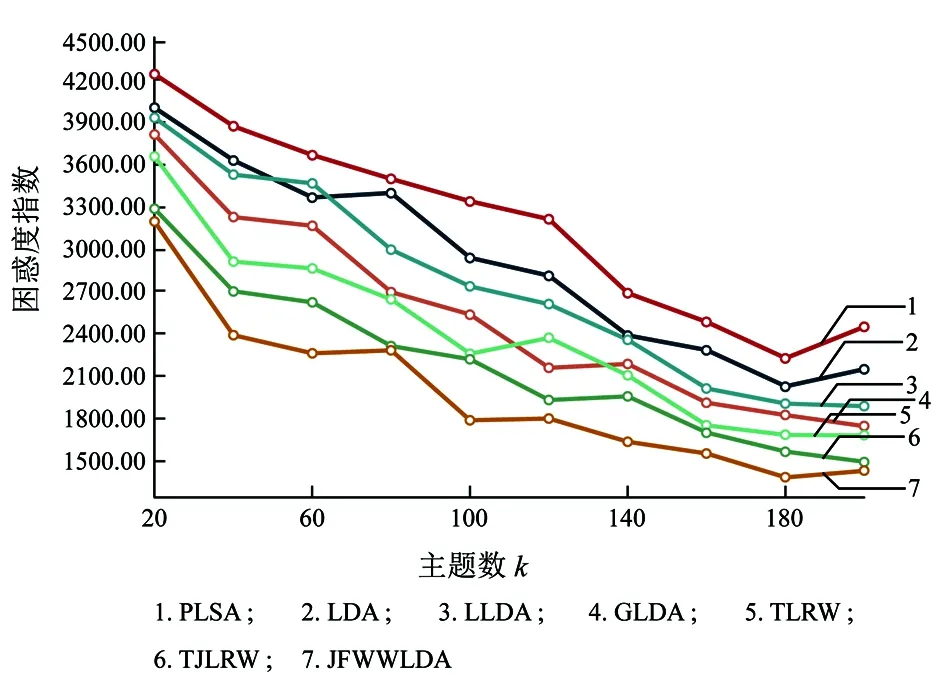
图7 各方法在CiteULike上困惑度指数对比
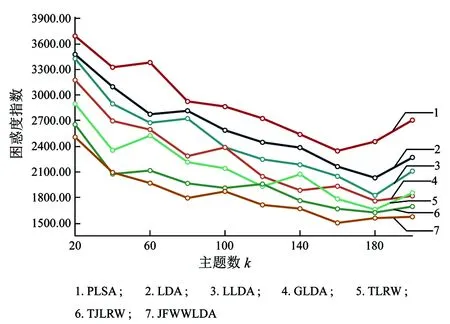
图8 各方法在Twitter上困惑度指数对比
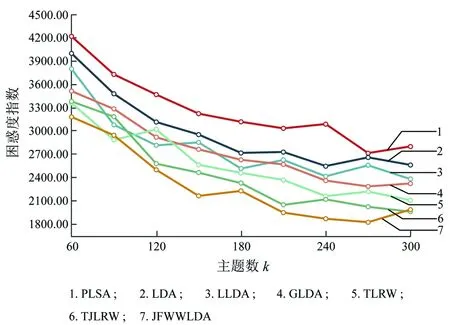
图9 各方法在Yelp上困惑度指数对比
4 结论
针对社会化标签资源,本文从信息熵相似度角度出发,试图建立独立性资源的潜在关联,消除传统LDA的词袋模型结构,提出了JFWW-LDA的主题识别方法。本文对社会化标签系统数据集进行实验验证,通过实验结果表明JFWW-LDA主题识别方法对社会化标签具有较好的主题识别效果。
