
基于改进YOLOv4及SR-GAN的绝缘子缺陷辨识研究
2021-12-29 07:00高伟周宸郭谋发
电机与控制学报 2021年11期
高伟,周宸,郭谋发
(福州大学 电气工程与自动化学院,福州 350108)
0 引 言
绝缘子作为输电线路中起着机械支撑和电气绝缘作用的部件,是输电线路中不可缺少的重要组成元件。因绝缘子终年曝露于户外,极易遭受自然气候灾害、机械负荷及人为因素的破坏,成为易发生缺陷的部件之一[1]。
绝缘子缺陷的快速检测一直是国内外学术界研究的热点问题。传统的检测方法是人工定期对输电线路进行巡视和观测[2]。该方法虽然简单,但效率不高,而且还需要借助外部仪器测量,如红外热成像仪[3]、超声波仪[4]等,在观察角度和光线的影响下,很容易出现误判。
近几年来,以低成本、易操纵、易悬停为特点的无人驾驶飞机逐渐应用于输电线路的巡检工作[5]。无人机巡检虽然可获得大量详实的输电线路图像,后期却需要人工进行图像的阅读和分析,工作量巨大。此外,工作人员由于自身专业水平的参差不齐以及视觉疲劳而导致的精力不足,常常容易判断疏漏。为解决这一问题,机器视觉和机器学习自动辨识图像成为当前研究的热门,其本质是利用算法代替人眼对图像进行阅读、处理和识别。此方法无需人工处理数据和经验判断,提高了巡检效率,增强了电网的安全可靠性[6-8]。
基于机器视觉的绝缘子缺陷检测方法需要在图像中定位绝缘子的位置,并将其与背景进行分割,透过特征提取或规则设定来区分正常和缺陷绝缘子。文献[9]使用最大类间方差法对绝缘子图像进行阈值分割,并用绝缘子对应位置的像素点个数来定位绝缘子的缺陷位置。文献[10]根据绝缘子片在图像中呈现椭圆形的特点,对分割后的绝缘子片轮廓点进行椭圆拟合,以缺陷绝缘子拟合椭圆误差大于正常绝缘子作为判据,区分正常与缺陷绝缘子。文献[11]对绝缘子片进行独立分割,根据分割后相邻绝缘子片间的欧氏距离判断其是否存在缺陷,文献[12]首先区分出绝缘子片是否重合或分离。对于重合的绝缘子片,沿轴向切成条状,然后按照分离式绝缘子篇的方式处理,即以固定的欧氏距离分割单个绝缘子片。最后,根据分割后的绝缘子片中心点连线是否为直线,对其缺陷进行判断。基于机器视觉的缺陷检测方法实现简单,在特定条件下能快速地定位缺陷位置,但也存在局限:算法的准确率严重依赖分割结果。由于输电线路的绝缘子多处于崇山峻岭之中,背景环境复杂,光线干扰严重,这些因素会严重影响分割质量。同时,人为确定的缺陷识别特征缺乏鲁棒性,当背景环境、拍摄角度、缺陷位置等发生变化时,将导致识别精确度下降。在图像处理方面,机器学习已经取得了很大的成功,利用机器学习算法来检测无人机航拍的绝缘子图像和识别缺陷已逐渐成为电力领域中一种新的巡检方法。文献[13]先采用Faster R-CNN算法定位绝缘子位置,接着将AlexNet与VGG16相结合实现绝缘子缺陷检测。然而,这种定位后再进行缺陷辨识的方法在诊断程序上比较复杂,并且使用了区域建议网络,使得检测速度降低,实时性差。文献[14]采用YOLOv2网络进行绝缘子定位,对定位的绝缘子通过垂直投影的曲线判别缺陷类型。但是,YOLOv2网络对同一个预测框内多个目标识别能力差,而且文献中提出的先定位再分类方案比较复杂,处理时间长。虽然机器学习算法能自适应的从海量的航拍图像中挖掘绝缘子的表层特征,对噪声干扰有很强的鲁棒性,但还存在诸多问题:
(1)缺陷检测模型的目标是既能准确地辨识出缺陷又能满足实时检测的要求,但事实上,检测速度与准确率无法同时提升。
(2)在实际的应用中,缺乏足够数量的缺陷样本,而充足的正负样本是保证目标检测算法精确度的关键。
(3)缺陷本身比较微小,在图像中表现为低分辨率目标,经过多次卷积后在特征图中存在信息丢失的情况。
针对以上问题,本研究的主要贡献为:
(1)提出了一种数据增强方法,通过分割图像前景与新背景融合,丰富训练数据的背景与数量,保证有足够的数据用于网络训练。
(2)在YOLOv4模型的训练过程中,通过多阶段迁移学习进行训练并动态改变各阶段的学习率,使训练后的模型整体性能得到提升。
(3)在YOLOv4模型的检测过程中,通过改变输出网络结构提高网络检测速度,对难以检测的图像通过SR-GAN生成高分辨率图像后进行检查,提升检测的准确性。
1 数据增强
基于深度学习的缺陷检测算法需要大量带缺陷的样本用于训练。针对缺陷样本不足的问题,一般使用数据增强技术进行处理。最常见的数据增强方式为对样本进行缩放、旋转、翻转。为了丰富数据样本背景,需要将分割后的目标融合各种不同的背景。本研究使用的数据增强步骤如图1所示,分别为:1)图像预处理;2)前景背景分割;3)前景与新背景融合;4)随机数据增强。
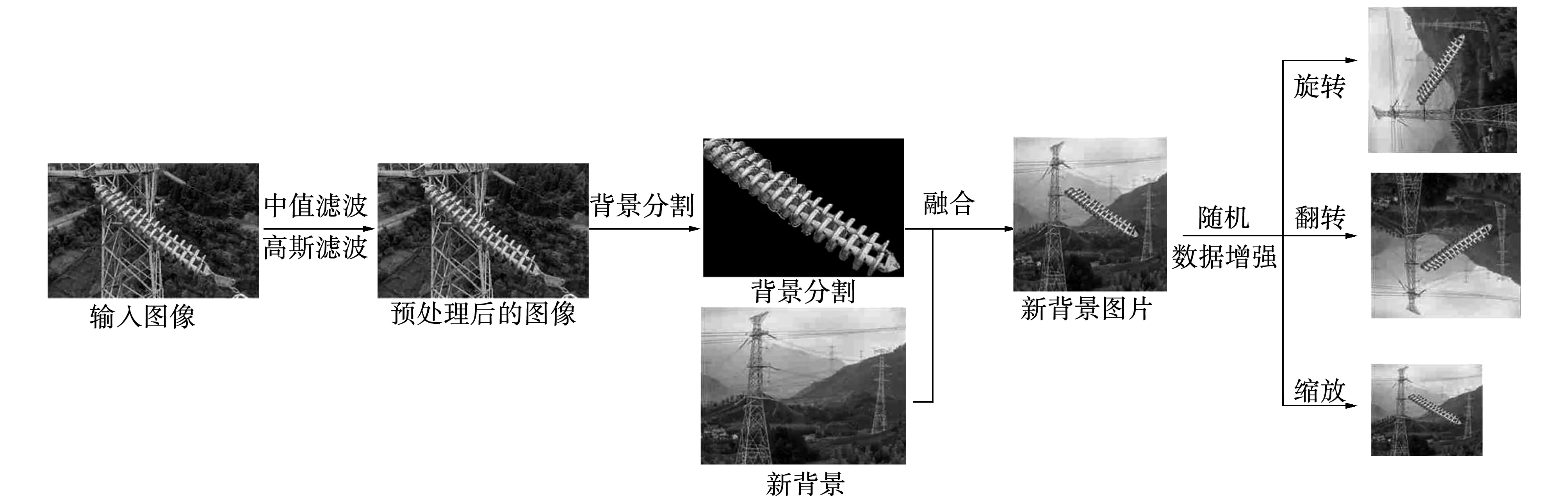
图1 缺陷绝缘子样本的生成过程Fig.1 Generation process of defective insulator samples
无人机拍摄的图像受制于现场环境条件,往往含有大量的噪声以及背景带来的干扰。为排除这些干扰对背景分割的负面影响,需要对图像进行预处理。一般会采用均值滤波与高斯滤波去除环境噪声以提高图像的对比度。接着使用Grabcut算法[15]结合模板匹配算法[16]对图像进行背景分割以获得较好的分割效果,步骤如图2所示。

图2 分割算法的流程Fig.2 Flow of segmentation algorithm
具体步骤是:1)模板库构建。模板匹配算法需要先构建一个模板库,模板库图像为从现场图像中提取出各尺度的绝缘子图像。2)使用模板匹配算法对输入图像进行处理。算法通过遍历整张图像,与模板库图像进行对比,画出与模板库图像相似部分的前景框。框中包含全部前景及少量背景,减少大部分背景的影响。3)Grabcut算法分割。对模板匹配画出的前景框通过Grabcut算法进行分割,得到所需前景的边界轮廓。最后,将前景图像放入新背景的随机位置进行像素融合,融合图像中的新背景为无人机在现场航拍中的背景图像。像素点融合的公式如式(1)所示:
(1)
式中:Pnew为新生成图像某一像素点的像素值;Pb为该像素点处背景图像像素;Pf为该像素点处前景图像像素;α,β分别为背景像素融合参数与前景像素融合参数,α,β∈[0,1]且α+β=1。图像融合参数的设置能使新生成的图像边缘更加平滑,融合后的像素点表现更为自然。
2 YOLOv4检测模型
YOLO(You Only Look Once)模型是一种基于深度学习的目标检测模型,运行速度较快,在实时系统中被广泛使用。YOLOv4模型[17]是最新的YOLO系列模型,由Alexey Bochkovskiy等人于2020年提出。与YOLOv3模型[18]相比,YOLOv4的检测精度与速度分别提升了10%与12%。
YOLOv4的结构如图3所示,由主干网络、外加模块和特征处理层构成。
2.1 主干网络
YOLOv4的主干网络为CSPDarkNet53,主要作用是提取目标对象的特征,具体结构如图3所示。对于一个输入维度为(416,416,3)的图像,由于1网络中每个残差块包含一个3×3的卷积核和一个1×1的卷积核,因此特征图每次经过残差块处理后,通道数翻倍,尺寸缩小为原来的二分之一。最后提取网络最后三层特征图用于后续处理,这三个残差块输出的特征图维度分别为(13,13,1 024)、(26,26,512)和(52,52,256)。高层特征图拥有较大的感受野,但分辨率较低,适合大目标检测。低层特征图分辨率高,细节信息表达能力强,适合小目标检测。
2.2 外加特征处理模块
YOLOv4模型的外加特征处理模块为SPPNet与PANet,具体作用如图3所示。SPPNet仅对残差块1输出的特征进行处理,该特征会输入四个大小分别为13×13、9×9、5×5和1×1最大池化核,将每个池化后的结果堆叠后再输出。PANet对高层特征进行上采样,特征图的维度变为原来的两倍后与上一层同维度特征进行堆叠。对低层特征进行下采样,特征图的维度变为原来的一半后与下一层同维度特征进行堆叠,输出包含三个特征层信息的特征供特征处理层使用。经过外加模块后,YOLOv4模型的三个输出层构成特征金字塔结构,维度大小分别为(13,13,75)、(26,26,75)、(52,52,75),特征中包含更多的细节和语义信息,能让特征处理层更好的利用这些特征进行分类及回归。
2.3 特征处理层
特征处理层对输出的特征进行解码,得出预测结果。预测过程如图3所示。经过YOLOv4网络处理后,输出特征的维度为n×n×75,然后将图片分成n×n的网格,确认每个网格中是否存在物体。存在物体的网格将构成先验框,最后根据特征中的信息,调整先验框后即为特征层的预测结果。每个特征层输出的特征都进行一次解码,取各特征层预测结果中置信度最大的那个作为最终的预测结果。
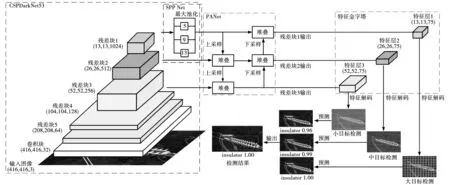
图3 YOLOv4模型结构Fig.3 Model structure of YOLOv4
3 改进YOLOv4的绝缘子缺陷检测方法
3.1 模型训练改进
(1)训练策略
本研究采用多阶段迁移学习[19]作为模型训练的迭代策略。迁移学习是一种将已经训练好且在其他目标检测领域辨识效果较好的模型用于另一个领域模型训练的方法。其通过发掘两个领域数据之间的内在联系,能有效减少训练时间,提高模型辨识准确率。多阶段迁移学习示意图如图4所示。首先,通过加载一个在ImageNet上使用VOC数据集训练完成的YOLOv4模型作为预训练模型。其次,将源域的图像特征迁移至目标域的图像,发掘两个域图像之间的共同特征,同时将源域模型参数迁移至目标域模型。最后,通过绝缘子数据集对模型进行两段训练。第一阶段在冻结n个残差块后训练余下的残差块及全连接层。n的大小与训练集大小有关,训练集越大,能训练的参数就越多,冻结的残差块越少。冻结的模块作为特征提取器参与训练但不改变权重。第二阶段解冻所有残差块进行训练。此时,只需要较小的学习率进行训练,并对整个模型进行微调。微调完成的模型即可用于绝缘子缺陷检测。
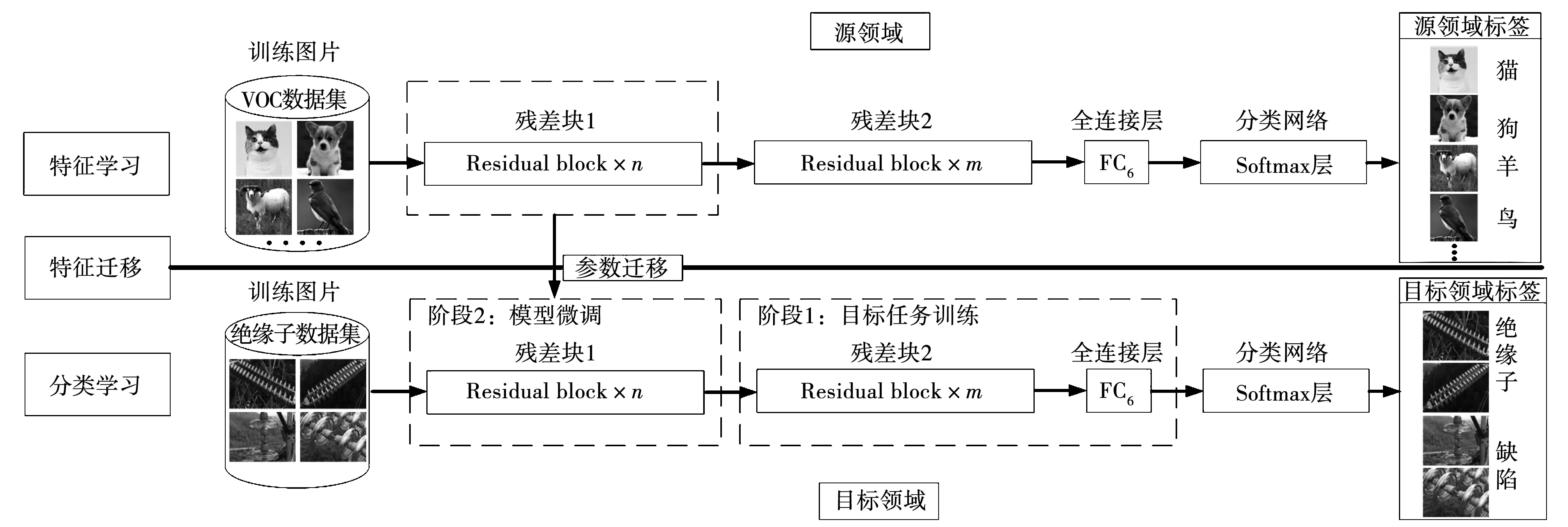
图4 迁移学习示意图Fig.4 Schematic diagram of transfer learning
(2)学习率设置
由于采用了多阶段迁移学习,冻结训练阶段与解冻训练阶段的学习率不同:冻结训练阶段需要较大的学习率加快网络收敛,解冻训练阶段只需要较小的动态学习率对模型进行微调。传统的动态学习率调整方法,在训练开始时设置较大学习率加快网络收敛,训练后期设置较小的学习率使网络更好地收敛。但较小的学习率在训练过程容易陷入局部最优,导致网络无法向全局最优点靠拢。为解决上述问题,本研究采用余弦退火学习率衰减法[20]进行学习率调节。它是一种在训练过程中动态调整学习率的方法,过程如图5所示。
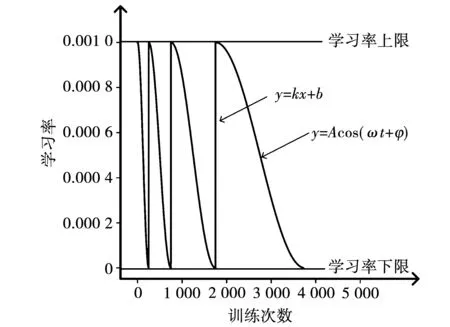
图5 余弦退火学习率衰减法Fig.5 Cosine annealing learning rate decay
首先,设置一个学习率上限和下限。接着,随着训练次数增加,学习率先是线性增加至上限,再以余弦函数的形式降至下限。然后,重复这个过程直至训练完成。当学习率由大变小时,网络逐渐向一个局部最优点靠拢;当学习率线性增大时,网络能够跳出该局部最优点,向下一个局部最优点靠拢,最终以各局部最优点的最优值作为输出结果。
3.2 目标检测过程改进
(1)输出层改进
图像经过YOLOv4网络处理后,输出3个n×n×75维的张量进行预测。这里的75是由(3×(1+4+20))计算得到。其中,3代表3个不同尺度的先验框;1代表先验框中预测物体的置信度;4代表先验框的调整策略,包括中心点x,y坐标调整策略和长宽调整策略,调整先验框中心点的位置及长宽;20代表VOC2007数据集的类别个数。但绝缘子串检测中输出的类别不足20类时,可以根据绝缘子串检测的具体需求对网络输出结构进行适应性改进,将网络输出张量变为n×n×x。其中x的定义如下:
x=num_anchor×(num_class+5)
(2)
式中,num_anchor为先验框的数量,num_classes为要分类的数量,5为输出对应类的置信度和先验框的调整策略中的中心点调整策略和宽高调整策略。本研究将绝缘子类型分为正常绝缘子与缺陷绝缘子两类,因此网络的输出张量变为n×n×21。
(2)检测图像改进
训练好的模型在目标检测中,有时候会生成不止一个预测框,此时就要设置约束条件对生成的预测框进行筛选。首先,设置一个置信度阈值,当预测框置信度大于阈值时,预测框才会被保留。其余的预测框被删除。其次,当剩余的多个预测框重叠时,通过非极大值抑制算法(non-maximum suppression,NMS)[21]筛选出某一片区域置信度最大的预测框。保留它,同时抑制其余的框,最后剩下的框即为预测结果。
在绝缘子缺陷检测中,缺陷在整张图像中属于非常微小的一部分,图像在模型中经过进一步压缩后,图像中的小目标容易出现特征丢失的现象,产生小目标漏检问题。为此,本研究提出了结合超分辨率生成网络(super-resolution reconstruction generative adversarial networks,SR-GAN)[22]的绝缘子缺陷目标检测方法。SR-GAN是利用图像重建技术,将低分辨率(low Resolution,LR)图像生成高分辨率(high resolution,HR)图像。最后将生成的HR图像用于目标检测。
对抗生成网络(generative adversarial networks,GAN)[23]主要由生成器(Generator,G)和判别器(Discriminator,D)两个模型构成。生成器通过输入的信息伪造数据,判别器则判断伪造数据属于真实数据的概率。当判别器判断伪造数据是真实数据的概率小于0.5,优化生成器重新生成数据用于判别;当判别器判别伪造数据是真实数据的概率大于0.5,优化判别器重新判别数据[24]。通过生成器和判别器的不断对抗,直至G模型和D模型达到博弈平衡,最终将训练完成的生成器用于生成数据。SR-GAN是GAN衍生模型,训练过程如图6所示,具体步骤为:(1)对原始图像进行下采样获得LR图像;(2)将LR图像放入生成器G中生成高分辨率图像;(3)把高分辨率图像与原始图像输入判别网络D判定:若D网络判断生成图像属于输入图像的概率小于0.5,则模型返回G网络中继续训练;若判断生成图像属于输入图像概率大于0.5,则模型返回D网络中继续训练,直至优化判别网络次数大于一百次时,训练结束;(4)将生成器G用于图像超分辨率重建。
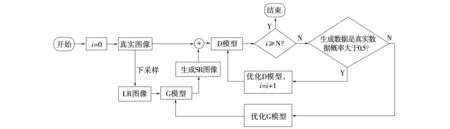
图6 SR-GAN训练流程图Fig.6 Training flow of SR-GAN
使用SR-GAN生成的高分辨率图像,如图7所示。可以看出,所生成的高分辨率图像突出了图像中的细节特征,使目标物体的纹理更为清晰。虽然生成的高分辨率图像能有效提升图像质量,提高目标检测精度,但SR-GAN生成高分辨率图像需要较长的运行时间,影响网络的实时性。而且许多图片并不需要生成高分辨率图像就能获得准确的结果。

图7 高低分辨率图片对比Fig.7 Comparison of high and low resolution pictures
通过观察发现,现场采集的绝缘子图像中,绝缘子数量少于三个时,图像中的绝缘子一般属于较大目标,这类图像不需要生成高分辨率图像即可定位绝缘子及缺陷位置。在固定尺寸的图像中绝缘子数量越多,越容易出现小目标。图像中的小目标,经过特征提取后,容易出现目标信息部分丢失,导致检测结果表现为出现低置信度的预测框,再经过NMS时就被抑制了。而置信度低于0.3的预测框中大部分为非绝缘子的误检目标,不需要考虑。因此,鉴于SR-GAN使用过程的局限性,在使用SR-GAN进行目标检测时,本研究设定了两个约束:
(1)图像中检测到三个及以上置信度大于0.3且预测框无重合的绝缘子。
(2)图像中存在置信度为0.3~0.5的预测框。
对同时满足上述两个约束的图像采用SR-GAN生成高分辨率图像后再进行检测,将此次的检测结果作为最终预测结果。
3.3 基于改进YOLOv4的绝缘子缺陷检测
对于输入为(416,416,3)的图像,经过YOLOv4后输出的三个特征层维度为(13,13,21)、(26,26,21)、(52,52,21),对特征层解码后即为预测结果。以输出维度为(13,13,21)的特征层为例,对输入图像的解码过程如图8所示。首先,将输入图像分为13×13的网格,每个网格负责检测其区域内的目标。若物体的中心点位于图中红色的网格内,则物体就由这个网格点来预测。接下来,该网格点生成三个蓝色的先验框,先验框根据特征层中坐标调整策略与长宽调整策略进行调整后,模型预测出调整后三个先验框的置信度。取调整后三个先验框中置信度最高的黄色框,作为最后的预测框,输出该预测框及其置信度。最后,判断该图片是否满足约束1及约束2:若不满足,则该预测框即为最终预测结果;若满足,则将图片输入SR-GAN网络生成高分辨率图像后用高分辨率图像重新检测,将此次的检测结果为最终的预测结果。
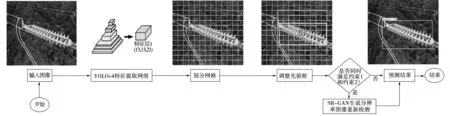
图8 绝缘子缺陷检测过程Fig.8 Process of insulator defect detection
4 实验结果及分析
4.1 实验介绍
(1)数据集
在无人机航拍过程中收集到2 100张正常绝缘子和40张缺陷绝缘子图像,分辨率为1 200×900,所有的标签采用VOC2007格式。图9展示了正常和缺陷绝缘子的航拍图像。由于缺陷绝缘子的数量太少,因此对40张进行数据增强,得到1 840张新生成图像,从而构成1 880张缺陷绝缘子数据集,效果如图10所示。绝缘子数据集由2 100张正常绝缘子和1 880张缺陷绝缘子图像构成,从中随机选取3 600张组成训练集,剩余的380张图像作为测试集。置信度阈值取0.6。

图9 现场绝缘子图片Fig.9 Insulator image on site

图10 生成缺陷绝缘子图片Fig.10 Generated image of defective insulator
(2)实验环境配置
计算机配置为Xeon(R)W-2123处理器、2块NVDIA GeForce GTX 1080Ti显卡和32G内存;操作系统为Ubuntu16.04;深度学习软件架构是Pytorch。
(3)评价标准
包括精确度(Precision,Pre)、召回率(Recall,Rec)、每类目标的平均精度(Average Precision,AP)、平均精度均值(mean Average Precision,mAP)和每秒传输帧数(Frames Per Second,FPS)。其中,精确度用于衡量算法找出样本的准确性;召回率用于衡量算法找出数据集中某类样本的能力,计算公式如下:
(3)
(4)
式中:TP为模型判定为正样本且本身也为正样本的样本数;FP为模型判定为正样本但本身为负样本的样本数;FN为模型判定为负样本但本身为正样本的样本数。
当交并比(intersection over union,IOU)的阈值不同时,检测结果的精确度与召回率也会发生改变,因此使用单一的精确度或者召回率作为评价指标都存在局限性。当选取的IOU值足够多时,各IOU值的精确度与召回率组成的曲线称为PR(Precision-Reacll)曲线。AP值[25]定义为P-R曲线与坐标轴所围成的面积,其同时衡量了算法在检测某类目标时的精确度与召回率。AP值越大,算法对该目标的检测效果越好。当求出所有目标的AP值后,mAP的计算公式为:
(5)
式中:n为分类的总数;APi为第i类的AP值。mAP值越大,表明算法整体检测效果越好。FPS定义为算法每秒处理的图片数量。FPS越大,每秒处理的图像数量越多,代表算法运行速度越快。
(4)参数设置
由于采用了多阶段迁移学习的训练策略,每阶段的学习率、批处理尺寸和迭代次数都不一样。具体参数如表1所示。
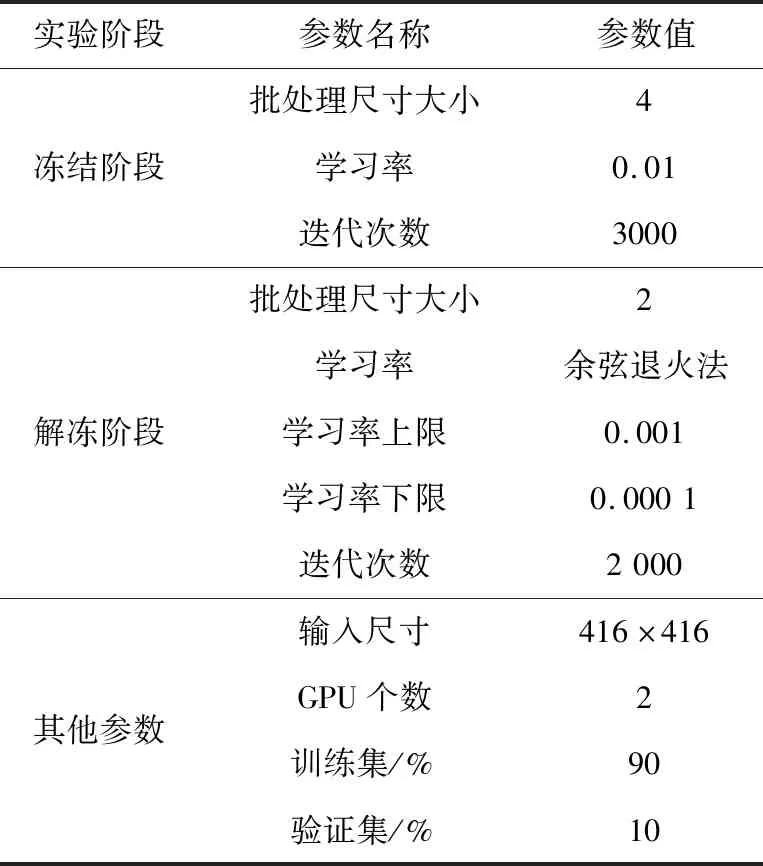
表1 实验参数Table 1 Experimental parameters
4.2 改进措施的性能验证
为了提高绝缘子缺陷辨识的准确率,本研究提出了改进YOLOv4模型,通过施加一些方法改善网络的整体性能。包括在训练过程采用多阶段迁移学习、余弦退火学习率衰减法,检测过程通过优化输出层结构和SR-GAN实现对缺陷快速准确的辨识。为此,本节评价了各种改进措施对网络整体性能的影响,并通过实验确定各种措施所对应的最佳参数。
多阶段迁移学习冻结的层数需要根据数据集的大小来确定。数据集越小,需要参与训练的参数就越少,冻结的层数就越多。因此,通过对不使用迁移学习和冻结不同层数的迁移学习模型的检测效果对比,寻找最合适的训练参数,结果如表2所示。可以看出,由于多阶段迁移学习载入预训练权重训练,训练过程只需对模型未冻结部分进行微调,显著提升网络的训练速度及模型的整体性能。相比于传统的无迁移学习,迁移学习训练出的模型使算法的mAP值至少提升了14%,训练速度提高了三倍。针对本研究使用的数据集,发现在网络冻结25层时检测效果最好,由此确定最佳的冻结参数。接着,结合本研究提出其他不同改进措施进行测试,其表现如表3所示,其中,“√”表示施加了对应的措施。
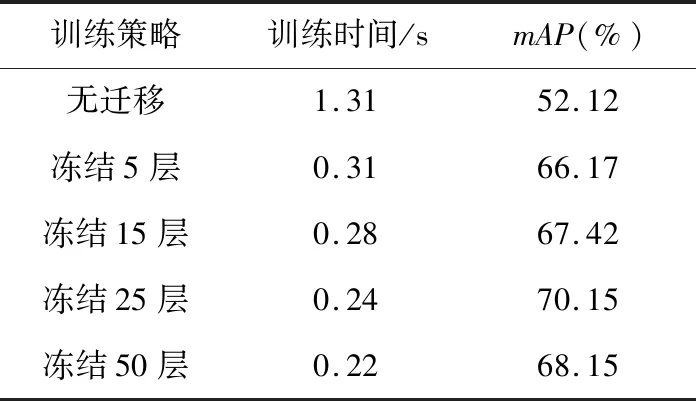
表2 训练策略对算法的影响Table 2 Impact of training strategy on algorithm
从表3中可以看出,单独使用YOLOv4模型进行检测,mAP值达到70.15%。倘若训练过程采用余弦退火法改进学习率,由于算法从各局部最优点中选出最优值生成最终模型,其mAP值提升了4%。根据目标检测任务的实际需求,将网络输出维度由n×n×75变为n×n×21,降低了检测网络的计算量,极大提高了检测速度。通过SR-GAN生成的图像能够增强图像的细节纹理信息,提高图像的质量,许多原图中检测不到的东西,能在新的图像中得到检测,如图11所示。可以发现,高质量的检测图像能显著提高网络对小目标的辨识能力,相比于改进前,mAP值又提升了9%。
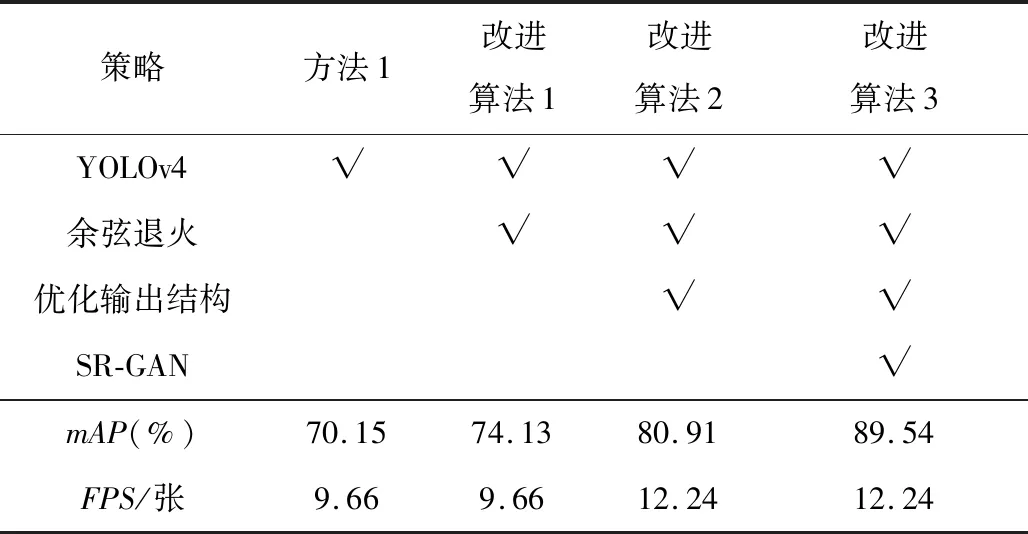
表3 改进策略对算法的影响Table 3 Impact of training strategy on algorithm

图11 检测结果对比Fig.11 Comparison of test result
4.3 实验过程及结果
测试集中有380张图像,所有图像中存在551个绝缘子与181个缺陷。检测过程中统计出各类别目标在对应置信度下的TP、FP与FN,并根据公式(3)和(4)计算出各类目标在不同置信度下的精确度与召回率,围成的曲线如图12所示。
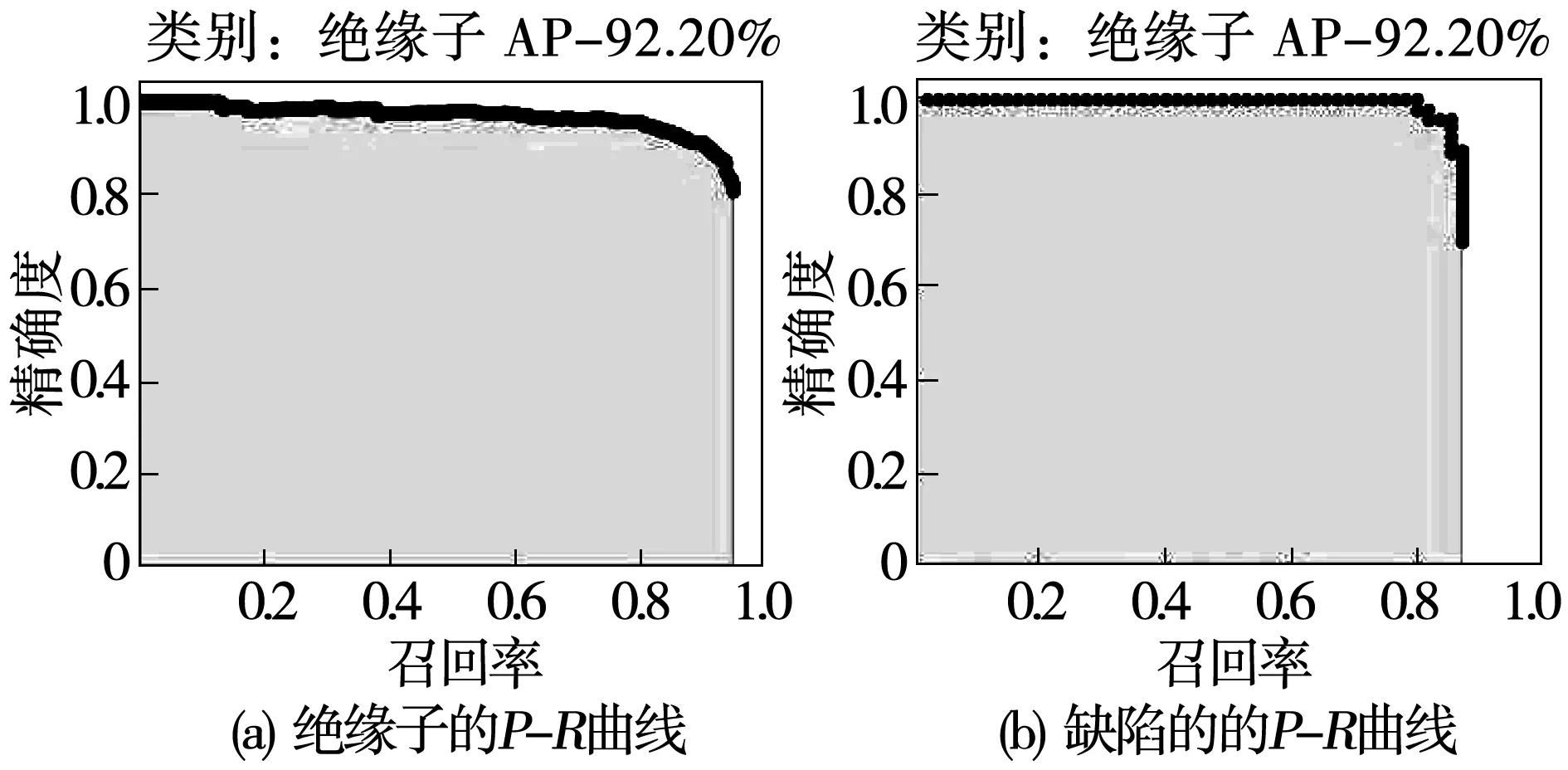
图12 检测结果P-R曲线Fig.12 Test result expressed by P-R curve
根据图12得知,绝缘子的AP值为92.2%,缺陷的AP值为86.88%。最后根据公式(5)计算出的mAP值为89.54%,检测结果如图13所示。可以看出,算法对于山地、平原、房屋、杆塔等复杂背景环境中的绝缘子,都能给出较好的辨识效果;改进模型本身结合SR-GAN生成高分辨率图像能准确的辨识出绝缘子及其微小的缺陷。实验结果表明算法能精确且快速的辨识出绝缘子缺陷。

图13 检测结果展示Fig.13 Show off detection result
为了检验训练模型的鲁棒性和对新缺陷的识别能力,又从现场获得20张带缺陷绝缘子的照片,用训练好的模型进行测试。测试结果如下:绝缘子检测的AP值92.5%,缺陷的AP值为85.5%,mAP值为89%。测试结果和380张数据集的结果接近,说明所训练的模型在测试新缺陷的时候,不会降低或丧失辨识能力。
所提算法在实际应用的鲁棒性和实时性值得进一步探究,为此采用现场拍摄的未经任何处理的无人机视频进行测试。在无人机巡检时,图像中可能存在很多背景绝缘子,但是一般会围绕一个焦点绝缘子进行观测。因此,本研究以焦点绝缘子为分析对象,从绝缘子辨识和缺陷定位能力方面进行评价。选取一段总时长10 s的视频,每秒30帧画面。算法对每张图像的识别时间是0.08 s,为保证检测过程的流畅性,以每十帧提取一张图片进行检测,即每秒识别3张。
视频的拍摄角度为:无人机由远及近、从上往下拍摄绝缘子,当绝缘子完全出现在画面中,再环绕拍摄。从图14可以看出,绝缘子识别的置信度逐渐提高,由于本研究的置信度阈值为0.6,因此,对于绝缘子,算法能100%检测到出来。在视频播放至第3.67 s(第11张图片)时,缺陷轮廓暴露在画面中,缺陷检测的置信度瞬间从0变化到0.8,算法立刻定位到缺陷的位置。随着角度的变化,在第8 s(第24张图片)时,缺陷消失于画面中,置信度又瞬间跌落到0。视频检测实验证明所提方法在实际应用中具有良好的鲁棒性和实时性。
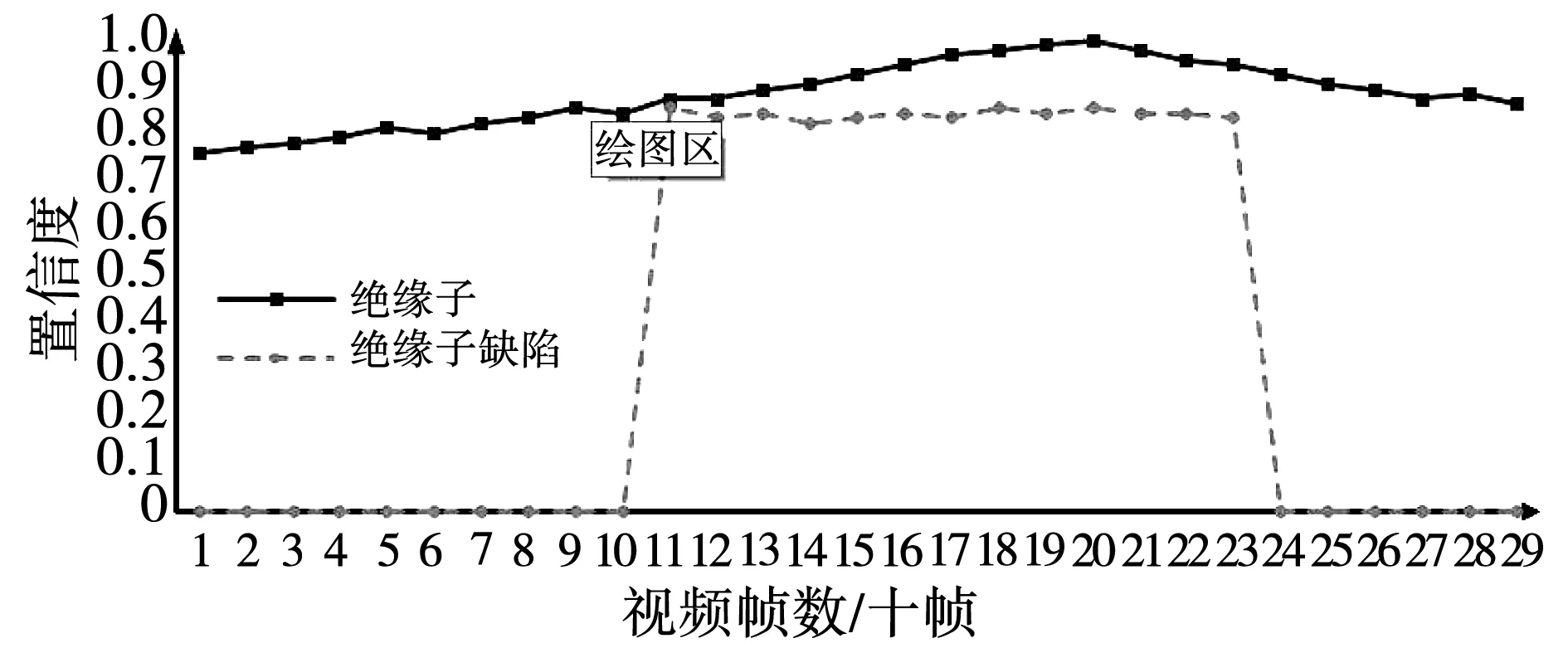
图14 动态视频检测结果Fig.14 Dynamic video detection results
4.4 方法对比
目前,目标检测算法按照检测过程可以分为一阶段检测算法(One-stage)和两阶段检测算法(Two-stage)。一阶段检测算法通过主干网络给出的特征张量直接回归目标的类别置信度与预测框位置;两阶段检测算法先通过区域建议网络生成候选框,再通过目标区域检测网络回归目标类别置信度与预测框位置。一阶段检测算法检测速度较快,以YOLO系列算法为代表;两阶段检测算法检测速度虽然不如前者,但精度更高,以Faster-RCNN算法为代表。因此,通过将所提方法与YOLOv3及Faster-RCNN进行对比,以评估所提方法在目标检测上的性能差异。对比指标为mAP与FPS。
Tao等人[26]提出了一种级联型Faster-RCNN网络用于绝缘子缺陷检测,通过级联两个Faster-RCNN模型完成绝缘子缺陷检测。模型一的主干网络为VGG-16,用于绝缘子定位;模型二的主干网络为ResNet-101,用于缺陷检测。吴涛等人[27]采用YOLOv3网络用于检测缺陷绝缘子,通过删除网络中的冗余卷积块构成轻量级网络,网络提取出的特征构成特征金字塔结构并用于绝缘子及其缺陷的分类及定位。
对比结果如表4所示。可以发现,Faster-RCNN算法在绝缘子定位的准确率上高于YOLOv3算法;YOLOv3算法采用了特征金字塔结构,通过多层次特征进行检测,在检测缺陷这种小目标的准确率大于Faster-RCNN算法;所提方法使用了外加模块SPPNet与PANet实现特征融合,拓展网络的感受野,极大提高了网络辨识的准确率。在处理速度上,Faster-RCNN不如YOLO系列算法。相对于YOLOv3算法,所提方法的处理速度比前者快了一倍。
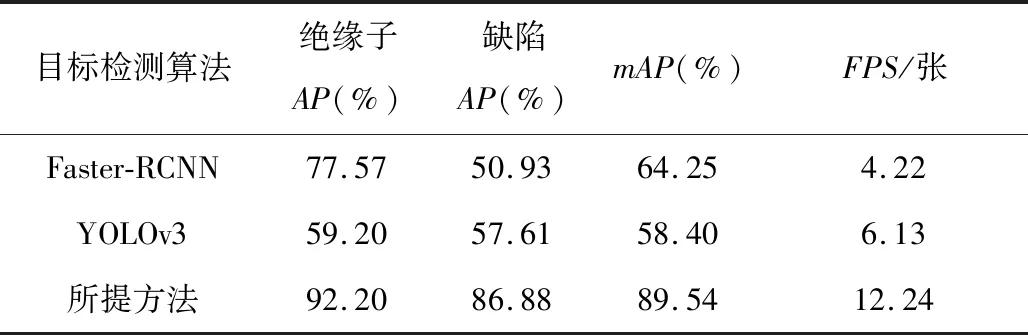
表4 不同目标检测算法对比Table 4 Comparison of different target detection algorithms
5 结 论
本研究提出了基于YOLOv4的绝缘子定位及缺陷检测的方法。相比于现有方法,YOLOv4模型具有速度更快,精度更高的特点。针对缺陷检测中出现的缺陷样本不足、模型对小目标泛化能力低下问题,提出了一种数据增强和基于SR-GAN的高分辨率图像检测的方法,同时在训练过程中采用了多阶段迁移学习和余弦退火衰减学习率策略显著提高了模型整体的性能。实验结果表明,所提方法的缺陷检测mAP值达到89.54%,FPS达到每秒12.24帧,高于Faster-RCNN和YOLOv3算法。所提方法在实际应用中可以满足绝缘子缺陷检测的准确性和实时性要求。未来,可进一步开展对低照度以及模糊背景下所提方法应用和性能提高的研究工作。
猜你喜欢
核科学与工程(2021年4期)2022-01-12
疯狂英语·新策略(2019年10期)2019-12-13
当代陕西(2019年10期)2019-06-03
计算机应用(2018年5期)2018-07-25
数学小灵通·3-4年级(2017年9期)2017-10-13
轴承(2015年2期)2015-07-25
电力建设(2015年2期)2015-07-12
电测与仪表(2014年6期)2014-04-04
电气传动自动化(2014年6期)2014-03-20
河南科技(2014年23期)2014-02-27
