
人工智能基础软硬件架构的关键技术研究
2021-12-28 13:07范喜凯
科技尚品 2021年11期
范喜凯

摘 要:近年来,在我国科学技术快速发展的进程中,人工智能技术已经广泛应用于各个领域,取得了一定的进步,不仅能够增强数据信息分析的直观性,还能形成智能化辅助决策支持、智能化认知的支持,具有一定的应用价值。基于此,文章研究分析人工智能基础软硬件架构,提出关键技术建议,旨在为人工智能技术的良好应用、长远发展提供保障。
关键词:人工智能;基础软硬件架构;关键技术
中图分类号:TP391.7 文献标识码:A 文章编号:1674-1064(2021)11-0-03
DOI:10.12310/j.issn.1674-1064.2021.11.007
1 人工智能基础软硬件架构的设计措施
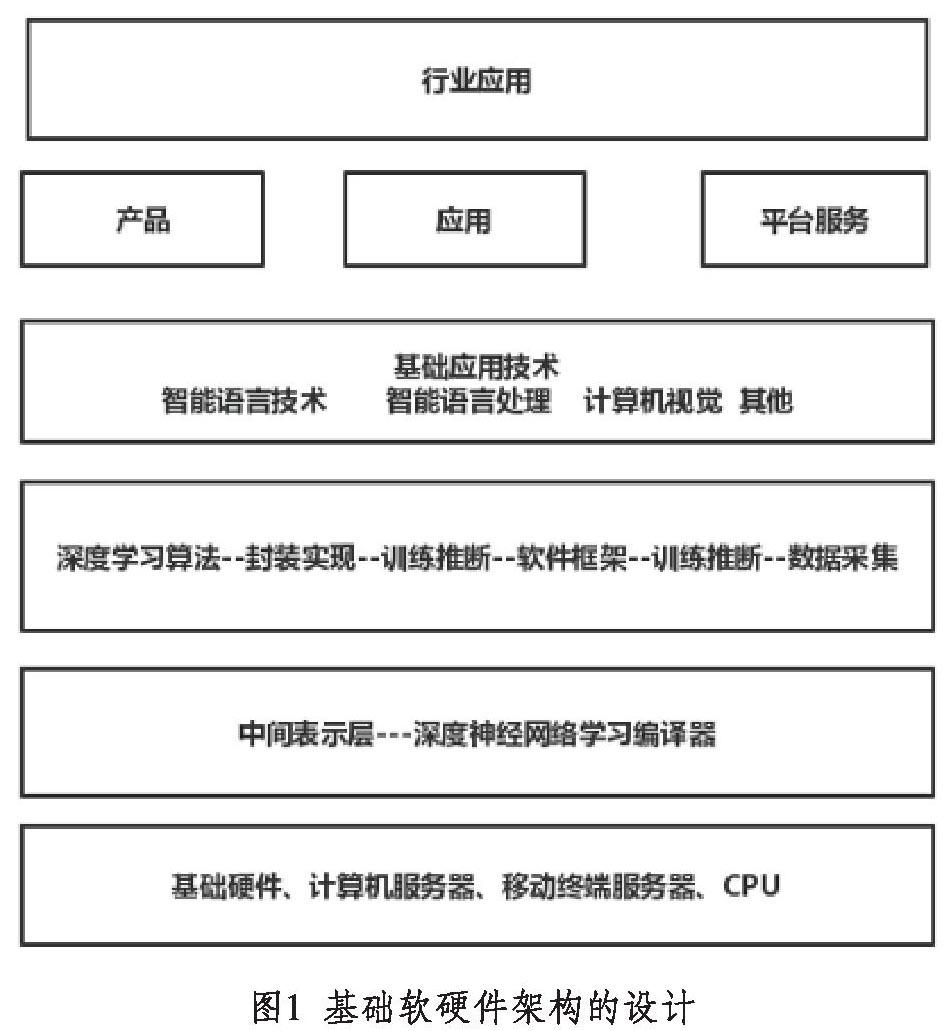
从本质层面而言,人工智能属于交叉类型的学科技术。目前,其在研究工作中主要涉及机器学习和深度学习方面的内容。其中,深度学习属于机器学习研究的分支部分,是2006年由领域中的专家学者提出的,以深度神经网络为核心的实现措施。而深度神经网络在应用过程中,需要有效地应对数据问题、算法问题和算力问题。因此,应结合实际情况合理设计相关的基础软硬件架构,并按照深度学习算法的计算机体系架构实现特点、原理等,完善体系架构的核心部分,确保能够高效化应用人工智能技术。软硬件架构的设计层次,如图1所示,应结合人工智能技术的应用特点和实际情况完善各个层次的内容。
1.1 基础硬件层面的设计
基础硬件层面指架构中的人工智能芯片,从实际情况而言,深度学习需要很多重复执行类型的矩阵乘法和激活函数的计算流程。而在使用通用类型CPU进行重复计算期间,性价比很低,所以,应设置专门使用的计算芯片材料。如AI计算芯片在应用过程中,可以设置CPU的架构、FPCA的架构或者ASIC的架构,利用对AI内的常用函数、计算硬件化的处理,加快硬件计算方面的计算速度,减少功耗数量。在此期间使用的关键性技术,主要就是指令集技术、硬件实现技术、异构计算技术、编译器技术等。按照我国目前的人工智能软硬件使用的安全需求,可设计定制类型的ASIC系统,设计安全性的专用计算机硬件电路,保证所有系统安全运行。
1.2 中间表示层面的设计
一般情况下,中间表示层面主要是利用深度神经网络模型编译器的技術设计,可以借鉴LLVM的设计模式,创建底层的硬件框架和软件框架,设置各类软件框架相互的桥梁部分。框架中设计的中间表示层部分,能够有效应对模型推理一侧的问题,使其可以在各类硬件平台中都能合理描述,完善NNVM/TVM和TensorFlowXLA两种阵营,其中的模型交换格式属于中间层次实现表示目的的定义部分。考虑到部分系统具有封闭性特点,因此在框架设计过程中,可以使用开源类型的ONNX设置解决方案和计划内容。
1.3 合理设计软件框架的层次
软件框架层次设计的优化性直接决定深度学习算法封装的效果,是非常关键的部分。同时,其还能为应用开发提供集成性的软件工具包,主要涉及到训练部分和推理部分。一般情况下,对软件框架的可用性和操作便利性产生影响的就是分布式训练因素和生态因素。目前,在技术应用过程中,生态较为良好的云端训练框架是TensorFlow和PyTorch两种框架,在应用过程中也可以提供分布式训练的支持。目前,我国部分人工智能系统已经具有丰富的生态功能,可以在设计深度学习软件的过程中借鉴和使用。
1.4 重点设计基础应用技术层次
目前,我国人工智能技术开始向着商业化方向发展,可以将计算机视觉技术、智能语言处理技术和自然语言处理技术等作为基础性部分。在软硬件框架设计期间,需结合相应的技术应用特点和具体状况,有效应对智能信息感知问题、融合问题和决策问题,积极运用相应的关键性技术,完善技术模式和机制,确保各项工作的高质量实施[1]。
2 人工智能基础软硬件架构的关键技术
2.1 一站式开发技术
由于在当前人工智能软硬件框架应用领域,经常会出现数据信息收集困难的现象、训练标记门槛过高的问题、开发时间过长等现象,因此,需结合具体状况使用一站式开发技术,相关开发技术基本框架如图2所示。
在采用一站式开发技术的过程中,其一,底层部分需要支持异构计算平台,能够达到规模很大的分布式训练目标,并且具备较为完善的、性能良好的分布式通信系统,可以增加吞吐量。基于分布式数据一定的支持,可以同步处置模型和数据,同时还需容器化地完成部署工作、运维工作,加快移植的速度。其二,在开发设计深度学习框架的过程中,还需给予主流训练框架一定的支持,设置预留的框架接口,自定义训练的部分。训练期间,主要涉及数据信息的预处理、算法开发和模型训练等方面,要确保系统的良好应用。其三,在算法开发的具体工作中,需要完善AI算法的框架部分,和传统类型的机器学习算法之间相互兼容,可以提供在线交互算法开发的良好环境。
2.2 采用深度学习模型压缩技术
一般情况下,在嵌入式与移动终端设备的算法处理工作中,由于计算和存储资源受到一定的限制,要想确保算法的有效处理,就应针对模型进行压缩和加速。其中,模型压缩指的就是,通过数据及实践已经训练完成的模型精简处理目的,获得轻量性与精确性的网络模型。压缩处置后的模型结构很小、参数信息很少,能够减少计算成本和存储成本。在此期间,就可以使用深度学习模型压缩技术,通过精细化的模型设计方式与模型剪裁方式、量化方式等进行处置,将其划分成前端类型和后段类型压缩技术。
对于前端类型的压缩技术,在不对网络结构造成破坏的情况下,以原本的模型为基础降低filter数量,或者减小网络深度。而后端类型的压缩技术,目的是在最大程度上减小模型的规格,对原本的网络结构会产生一定的破坏。从训练模型压缩和优化的层面讲,可以使用自动化的流程工具设计方式,将其分成模型压缩与加速算法组件和超参数优化组件这两个结构,借鉴成功的案例,有效进行权重的稀疏化处理、量化处理、网络蒸馏处理等。将各类算法组件相互有机整合,减小精度方面的损失,不断提升深度学习模型压缩的自动化水平。
2.3 深度学习编译器技术
对于TensorFlow、PyTorch而言,此类前端类型的学习框架模型,需要先将其转变成计算图IR,通过NNVM组件处理。对于原本的计算图IR部分,则在设计过程中优化计算图,保证操作融合方面、内存分配方面的优化性,最终获得最为优化的计算图。在计算图方面,各个OP的获取都应使用张量表达语言描述计算表达方式,对需要拥有的硬件平台,使用最小计算语言生成相关的schedule,这个步骤主要使用TVM组件处理。另外,在训练模型方面需要结合IR层面规定的标准要求表达和存储,利用可以将源码表达的数据结构或者代码进行编译器的处理。对于具备扩充特点的中间表示层面,则需要将深度学习计算在内的各类前端训练软件框架打通,设置各类后端表达桥梁,有效应对目前框架相互之间的移植问题[2]。
传统编译器在实际应用的过程中缺乏深度学习算法基础算子优化,缺少在人工智能多种异构计算芯片方面的适配性,只有合理扩展传统编译器架构,有效应对人工智能底层计算芯片和上层部分软件框架相互之间的适配性问题和优化问题。例如,采用先进的CUDA编译器技术、NNVM/TVM编译器技术,主要是将LLVM框架作为基础进行设计,可以直接在多种深度学习端的框架之内,对工作负载进行编译,使其成为具有一定优化性的机器代码,可以在高层图中间表示中进行深度学习工作负载的表示、优化,还可以在各种类型硬件后端区域进行计算图的转换处理、最高程度上减少内存占用量、实现数据分布的优化性处理、将各类计算模式相互融合。
NNVM在应用期间可以进行计算图的生成,而TVM又能够进行张量运算的映射,主要的应用流程是:其一,通过组件实现TensorFlow、PyTorch等各类前端类型的学习框架模型转变成为计算图IR的目的,之后利用操作融合的方式、内存分配优化的方式等使得原计算图IR更为优化,获得优化以后的计算图;其二,对优化以后的计算图内部各个OP的获取,主要通过张量表达语言的方式进行Tensor计算表达式的描述,按照具体的硬件平台需求,使用很小的计算原语生成schedule,明确如何针对底层部分的硬件进行调度,这个步骤是利用TVM组件实现;其三,将机器学习的Automated Optimizer作为基础,生成优化的部分,最终就能够生成硬件设备方面的二进制程序,生成能够进行部署的module。如果主流方案中设置了GraphIR+TensorIR的双层次优化结构,那么就能够有效应对软件框架抑制问题、硬件优化的核心问题,因此需要按照具体情况科学设置双层次优化结构。
除此之外,目前在工程领域中使用训练模型,都是结合IR层次提出的规定存储与表达,而IR又属于翻译器用作源码表达的数据结构亦或者是代码,因此必须要按照具体的情况进行IR处理,满足技术的应用要求。
2.4 深度学习样本的增强技术措施
一般情况下,数据增强主要分成有监督类型、无监督类型两种形式。前者主要是对单个样本或是多个样本数据信息进行增强,后者可以分为生成新数据、学习增强两种形式。由于有监督类型的数据增强技术,主要通过以往的工作经验制定完善的设计规则,经常会出现各个任务存在过大差异性的问题、质量不足的问题。所以,目前在系统设计工作中,主要使用无监督类型的数据增强技术,如借助模型学习数据信息的分布处理,随机性生成和训练数据集分布状态相同的图片,生成对抗网络CAN。
通常情况下有监督的数据增强主要是通过研究者经验规划设计,很容易因为个人的主观因素不能结合各种任务的差异性进行设计,也可能会导致最终数据增强的多元化和质量不足,在此情况下应使用无监督数据增强的方式。例如,利用模型学习数据的分布处理,随机性生成和训练数据信息集合分布相同的图片,可以采用最具有代表性的生成对抗网络CAN措施操作。再如,利用模型学习出与目前任务相互适应的数据增强措施,借鉴谷歌的数据增强成功经验,通过增强学习从数据自身之内提取良好的图像变换措施,对各类任务学习不同的数据增强方法。
2.5 创建嵌入式的边缘智能化开发平台
虽然开发一站式的开发平台能够有效完成数据中心训练的相关任务,但是要想合理使用嵌入式端开展模型部署工作,还需开发面向边缘的智能化计算平台,可以将其划分成为轻量级别、模型推理部署两个部分,首先需要给予一站式开发平台已经完成训练模型的部署支持,有效應对硬件框架方面的问题,创建模型中间表示的层次。
例如,FPGA在应用的过程中具有一定灵活性,主要通过DNN加速设计的方式进行硬件架构神经网络的快速、高效化计算,按照自动化模型压缩流程,合理设计软件工具集,将模型深度压缩工具作为整体平台的核心部分,主要设计大模型剪枝工具、优化工具、量化工具等,提升剪枝的效果、定点运算的水平。
另外,重点使用神经网络编译器技术,使得神经网络算法能够被编译成为可以运行、可以使用的指令流,在工具应用的过程中营造良好支持环境,完成神经网络加载处理、资源管控、调度处理的操作。通过此类嵌入式平台的开发设计,可以继承到一站式的平台内部,算法框架层次将轻量级别的推理框架作为主要部分,可以将其当作训练框架的精简模式,通常只能完成推理,无需进行训练操作。
3 结语
综上所述,在人工智能技术基础软硬件开发和设计的过程中,为有效解决目前存在的问题,应制定完善的软件系统和硬件系统开发方案,按照目前存在的关键性技术问题针对性处理。同时,还需重点使用一站式开发技术、深度学习模型压缩技术和深度学习编译器技术等,增强软硬件架构的完善性。
参考文献
[1] 陈小平.人工智能伦理体系:基础架构与关键问题[J].智能系统学报,2019,8(4):5-10.
[2] 于汉超,汪峰,蒋树强.中国人工智能发展的若干紧要问题[J].科技导报,2018,11(17):40-44.
猜你喜欢
农业灾害研究(2022年1期)2022-05-07
中国信息化(2022年4期)2022-05-06
中国信息化(2022年4期)2022-05-06
中国新通信(2022年4期)2022-04-23
电化教育研究(2022年3期)2022-04-14
科学Fans(2019年6期)2019-07-26
商界(2019年12期)2019-01-03
IT经理世界(2018年20期)2018-10-24
小康(2017年16期)2017-06-07
南风窗(2016年19期)2016-09-21
