
基于Web的数据挖掘模型研究
2021-12-24 04:30蒲道北
中国新通信 2021年19期
蒲道北



【摘要】 从海量、复杂的Web数据中获取有价值的信息一直以来都是互联网研究的热点,本文在基于Web数据挖掘的研究中,优化出一种新的面向Web的数据挖掘模型,该模型利用Robot程序采集到的Web数据与特征信息进行匹配规范,然后在数据层中进行容差处理,调整差值数据,最终通过模式分析得到有用信息。实验结果表明,利用提出的模型对Web数据的挖掘结果质量上有了明显的改善和提升。
【关键词】 Web数据 数据挖掘 模型 数据智能
引言:
Web有着分布广泛的、全球性的信息,成为人们获取信息的主要渠道。然而如何在Web上搜索找到适合它使用者兴趣的信息呢?目前,人们主要通过3中主要方式查找:1.使用基于关键字或主路径浏览的搜索引擎,如百度或Google,它们通过使用关键字索引或人工建立路径来查找文档;2.查询深度Web资源。如amazon.com的书籍数据和realtor.com的固定资产数据;3.随机访问,通过网页链接一页一页浏览[1-2]。尽管基于关键字、IP地址和主题的搜索引擎支持Web信息搜索,但还存在着返回结果太多、查询质量低、查询覆盖面小、缺乏多维分析和数据挖掘支持等缺点。为了克服以上缺点,业界提出将数据挖掘技术应用在Web数据上,并形成一个新的研究方向,本文就现有的web数据挖掘技术基础上优化出一种新的Web数据挖掘的模型,该模型充分利用了XML的优点,采用Robot程序采集Web中的有用数据,并将得到的数据与特征信息进行匹配,匹配成功后在数据层中进行数据容差处理,调整差值数据,得到数据模式,通过模式分析最终得到有用数据。
一、Web数据挖掘技术
Web数据挖掘是指将数据挖掘方法运用到 Web信息挖掘上,针对web页面的内容、页面之间的关系和结构、使用者所需要访问的信息、电子商务资料等各类Web数据,应用数据挖掘手段和方法去分析并发现其所蕴含的、不可预测的、具有潜在价值的模型等过程。
1.1 Web数据挖掘的任务
为了更好地获得Web上的信息,通过Web进行商业决策,在Web上有效应用数据挖掘技术,必须完成以下任务和解决研究中的问题:
1.分析Web搜索引擎得到的数据;
2.分析Web的链接结构;
3.Web文档自动分类;
4.挖掘Web页面语义结构和内容;
5.挖掘Web动态特征;
6.建立多层和多维Web信息库。
1.2常用Web数据挖掘技术
1.路径分析技术:主要采用图进行分析,将网站上的页面定义成节点,页面之间的超链接定义成图中的边,从图中确定最频繁的路径访问模式或最大参引访问序列[1]。
2.关联规则挖掘技术:挖掘出用户在一个访问期间从服务器上访问的页面/文件之间的联系,这些页面之间可能并不存在直接的参引关系。
3.序列模式挖掘技术:要挖掘出页面上交易集之间的有时间序列的模式[2]。例如,有70%的用户访问了页面A 之后在一定的时间内又访问了页面B,也就是70%以上的用户对页面A和页面B都敢兴趣。
4.聚类分类技术:按照某个特定标准把一个数据集分割成不同的类或簇,使得同一个簇内的数据对象的相似性,从而以挖掘出某些共同的特性。
二、Web数据智能挖掘模型和实现分析
为了更好的对Web信息进行挖掘和运用,本文对现有Web数据挖掘模型进行了优化,优化后的模型可以向用户提供个性化的深层次服务,不仅能提供原始的Web资料,还可以根据用户的需求对内容和结构进行充分的挖掘,包括数据采集层、数据层、数据分析层等。
2.1 数据采集层
整个过程主要分六个步骤[4-6]来完成:
1.用户接口:根据用户提供的目标信息,将信息与系统相连。
2. 提取特征信息:根据目标信息中的信息,提取相应的特征向量,并根据特征向量计算出对应的权值;
3.Web信息获取:即先用搜索引擎选择待采集Web站点,再利用Robot程序采集静态Web页面文档,利用XML结构信息作为搜索条件,通过对其标记的匹配率进行文档过滤。
4.信息特征匹配:即提取“文档暂存库”中的信息特征向量,将符合阀值条件的信息送入下一步。
5.数据规范:采用XML结构存储规范。例如中国电信业务可采用“电信业务cnXML”作为规范。
6.文档知识库:按照数据规范将规范好的数据存入数据库中,建立一个电子数据交换规范库,并阶段性地更新数据库中的信息。
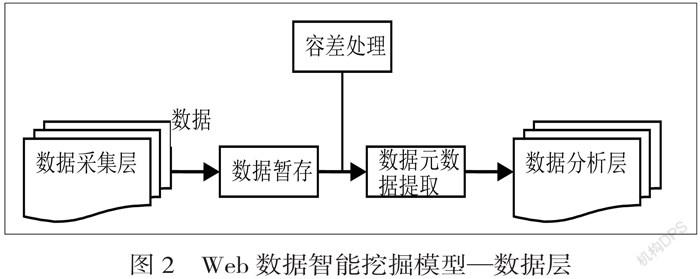
2.2 数据层
采用XML形式存储数据,并检查、纠正数据中可能存在的错误信息,再采用矢量空间模型法(VSM)进行元数据处理,最后,将提取的元数据发送到数据分析层[7]。
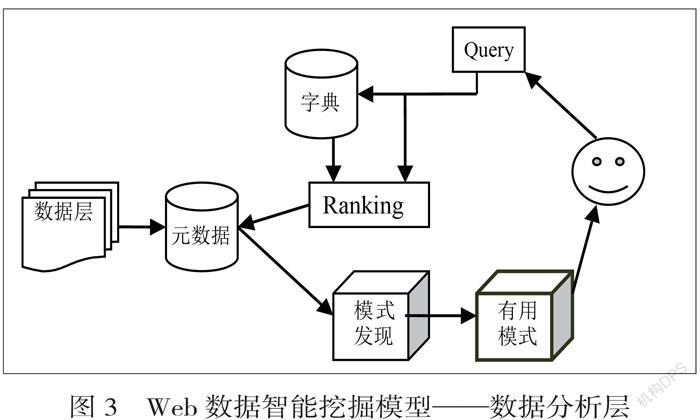
2.3 数据分析层
在数据分析层中,首先是把查询结果按照优先级进行排序,再进行模式提取,得到有用的模式。在此分析的方法很多,有回归分析、遗传算法、聚类分析等数十种,在实际分析时,应针对其目标采用适当的分析方法。最后还需要将结果通过友好的界面提供给用户。
三、仿真实例及其分析
根据模型的思路开发出一个仿真系统,并在该系统上主要进行了计算机编程软件的搜索实验。并将得到数据进行分析和处理,最终得到预期的结果。
实验如下:
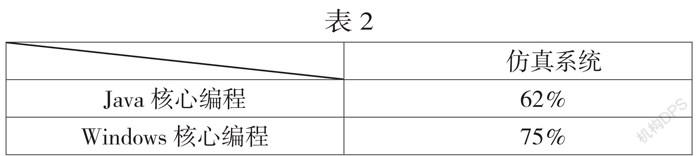
第一步:在仿真系统上查询java核心编程、Windows核心编程两个主题得到如下数据:
第二步:选择前100项搜索结果进行筛选,得到有用如下数据的比例:
第三步:将得到的数据建立文档知识库,采用聚类算法对采集到的数据进行有效的分析。
通過仿真实验的结果可以看出,该模型能够成功地在网上进行资源查找,并建立文档知识库,通过数据挖掘算法对文档知识库中的内容进行有效地挖掘,得到有利于数据决策地信息。达到了预期的效果。
四、结束语
由于Web信息大多数是异质、异构的半结构化或非结构化信息[8],因而Web数据挖掘一直以来都是业界研究的热点,本文在基于Web数据挖掘的研究中,优化出一种新的面向Web的数据挖掘模型,可以提高对Web数据的采集和分析性能,可为业界Web数据挖掘提供参考。
参 考 文 献
[1]方传霞, 闫仁武. 基于Web挖掘的电子商务推荐系统研究[J]. 电子设计工程, 2015, 000(011):30-32,35.
[2]王玉珍. 基于电子商务的Web挖掘技术研究[J]. 北京电子科技学院学报(4):22-25.
[3]王剑锋, 乔冬, 麻丽娜,等. 基于潜在语义分析的网页文本分类研究[J]. 应用能源技术, 2009, 000(011):41-44.
[4]王剑霞, 邢晶晶. 基于WEB数据挖掘的网络舆情分析研究[J]. 数字化用户, 2014, 000(005):126-127,129.
[5]张丽霞. 基于Web的数据挖掘模型[J]. 菏泽学院学报, 2007, 29(2):44-46.
[6]魏和平. Web内容大数据挖掘的特征匹配法探究[J]. 信息技术与信息化, 2020, No.242(05):70-71.
[7]王琦超, 李广辉. 云计算在Web数据挖掘技术中的应用[J]. 九江学院学报:自然科学版, 2020(1):74-76.
[8]刘爱琴, 赵慧敏, 尚珊. Web环境下语义挖掘模型的构建[J]. 图书馆理论与实践, 2018, 228(10):61-65.
猜你喜欢
小天使·三年级语数英综合(2022年4期)2022-04-28
西部交通科技(2021年9期)2021-01-11
初中生世界·九年级(2020年2期)2020-04-10
汽车导报(2017年5期)2017-08-03
速读·下旬(2016年8期)2017-05-09
高中生学习·高三版(2017年4期)2017-04-14
求学·理科版(2017年1期)2017-03-02
电子技术与软件工程(2016年24期)2017-02-23
哈尔滨理工大学学报(2016年2期)2016-09-12
中学生数理化·高二版(2016年4期)2016-05-14
