
基于规则约束的深度学习网络用于文本信息抽取
2021-12-23 04:35洪艳伟
计算机工程与设计 2021年12期
赖 娟,洪艳伟+
(1.乐山师范学院 互联网自然语言智能处理四川省高校重点实验室,四川 乐山 614000; 2.乐山师范学院 人工智能学院,四川 乐山 614000)
0 引 言
信息抽取(information extraction,IE)通过抽取一段文本中的指定类信息,将自然语言文本中表达的非结构化信息转换为结构化表示形式,以供用户查询使用的过程[1]。IE涉及到命名实体识别、实体链接、意见目标抽取以及关系抽取等多类问题[2],在医疗、金融以及网络安全等领域具有广阔的应用空间[3,4]。目前,研究人员针对信息抽取提出了多种方法。在传统方法中,将目标关系及手工提取的模式作为输入,用于解决小型同质语料库的预定义目标问题[5]。由于需要手动定义新的提取规则,因此该类方法依赖于人员的广泛参与,应用十分有限。深度神经网络的发展为IE提供了新的突破方法,这类方法可以自动学习特征,能够大大减少人员工作量。同时,在准确性方面,神经网络学习的特征比人工设计的特征要好,精度更高。基于机器学习的信息抽取方法大致分为流水线法[6]和联合抽取法[7]两种。流水线法首先训练实体抽取模型,然后基于抽取的实体独立预测关系,方法操作简单,但是容易出现错误传播和产生冗余信息。为了解决这个问题,学者提出了实体识别和关系分类联合方法,通过共享参数来学习两个子任务之间的共享信息。Li等[8]利用双重嵌入CNN模型来学习上下文感知和高级特征,并与基于知识的注意模型相结合,通过充分利用知识库中的监督信息来选择实体。Gasmi等[9]采用了LSTM模型来捕捉文本语句中的信息。由于单向LSTM网络无法有效地学习上下文信息,因此,Lee等[10]使用双向LSTM模型对文本语句进行编码,并引入多头注意力机制学习语句信息的向量表示。但是,深度网络需要大量带有手动注释的语料库进行训练才能得到较高精度的分类结果,当训练样本不足时,深度网络的精度会降低。
为解决这一问题,提出了一种基于规则约束的深度学习模型,所提模型由深度学习网络、规则逻辑库和差异单元组成:深度学习网络将一系列文本句子作为输入,通过在多个维度上计算复杂的单词级别相关性来为每个单词生成一个预测向量;逻辑模块由一组一阶逻辑表示的逻辑规则组成,这些规则明确指定了输出标签空间中的复杂关系,同时为每个逻辑规则分配了一个非负的权重用于表明其置信度;差异单元则根据差异损失来衡量深度学习模块与逻辑系统之间的分歧,负责将神经输出与逻辑库的输出对齐。
1 命名实体识别与关系抽取
在传统的自然语言处理(natural language processing,NLP)中,命名实体识别(named entity recognition,NER)与关系抽取(relation extraction,RE)是两个独立的任务,两者的主要目标是从文本中识别实体并抽取实体之间的语义关系。其中,NER的任务是在一个文本句子中寻找具有可描述意义的实体,RE则是对文本句子中的两个实体间的关系进行抽取,通过将非结构化文本数据转换成关系元组做进一步分析。命名实体识别是RE的前提,关系抽取是在NER获取的实体间构建联系。两者的结合通常被用于数据简化、大量文本语料理解以及知识图谱构建的领域中。
对于输入数据,首先需要正确识别自然语言的实体,其中实体是指具有可描述意义的单词或短语,通常是地名、人名、产品名称或者在某个领域内具有一定含义的内容。然后对获取到的实体,进行RE任务,抽取它们之间的关系。由于传统的抽取方法是在实体抽取的基础上进行实体之间关系的识别,因而先期实体识别的结果会影响到关系抽取的结果,前后容易产生误差累积。针对这一问题,基于深度学习的联合模型被用于对这一类的自然语言处理任务进行联合学习。
给定用户输入的一段自然语言,用E和R分别表示可能的实体类型和关系类别的集合。对于给定的输入句子{ω1,ω2,…,ωm},实体提取既涉及实体分段又涉及实体类型。因此,一般将BIO编码方案与实体类型结合使用以形成输出标签y={y1,y2,…,ym}的序列。关系抽取旨在输出一组三元组(e1,e2,r),其中e1和e2分别表示第一实体和第二实体,而r表示它们之间的关系类型。在这项工作中,将实体提取视为序列标签问题,将关系提取视为基于已识别实体的分类问题。图1给出了基于神经网络的联合模型具体流程。
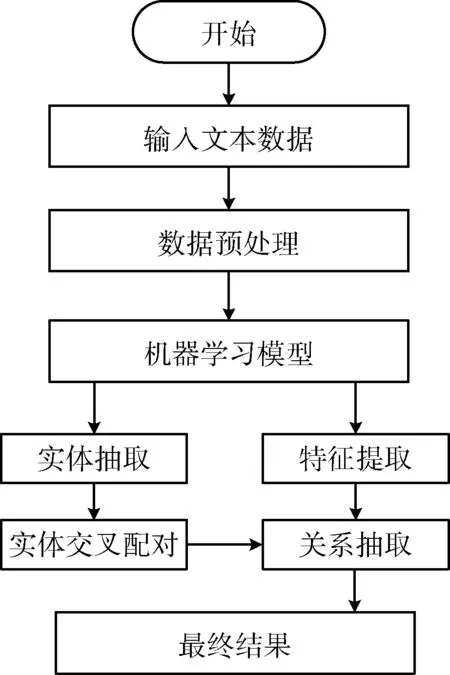
图1 实体联合抽取流程
2 基于规则约束的深度学习模型
尽管当前已经存在许多基于深度学习结构的联合抽取方法,但是大多数模型未能充分考虑NER和RE任务之间的隐形的相关性和特征关系。为了解决这个问题,本文将逻辑规则引入深度学习框架中,用于指定联合推理的任务关系。为了能够有效地将离散符号系统与分布式表示学习相结合,采用概率的方式计算逻辑规则,并通过定义映射函数把深度神经网络DNN的连续输出映射到逻辑单元中。此外,文中还提出了一种差分损失来度量DNN输出和逻辑输出之间的差异,保证两个模块之间的一致性。差分损失可以通过领域知识对DNN进行正则化,同时更新逻辑模块,使之符合训练数据。
图2给出了所提出方法的总体架构。它由3个单元模块组成,即深度神经网络、逻辑库和差异单元。首先,DNN模块将一系列单词作为输入,经过表征学习后为每个单词以及可能的候选关系生成一个预测向量。然后DNN的输出被馈送到逻辑模块以产生逻辑输出,其中逻辑库中填充了易于获取的通用领域知识,并将该知识形式化为一组一阶逻辑规则。最后,差异单元通过计算DNN与逻辑模块的输出分布之间的距离,来负责将神经输出与逻辑库的输出对齐。

图2 所提方法总体架构
2.1 深度学习模型
深度学习模型由1个Bi-GRU网络和多层变换神经网络组成,其中,单层变换神经网络包括1个多头自注意模型和1个Bi-GRU网络,主要对句子的序列关系和空间距离进行建模。不同于NLP中常用的循环神经网络RNN,变换神经网络不需要进行循环操作,而是并行处理序列中的单词或者符号,同时自注意力机制还能够将上下文与较远的单词结合起来。通过并行处理所有单词以及注意到与句子上下文中的其它单词相联系,使得网络的训练时间比 RNN 少很多且性能更加优越。
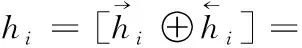
(1)


(2)
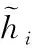
图3 GRU和Bi-GRU结构

(3)
(4)

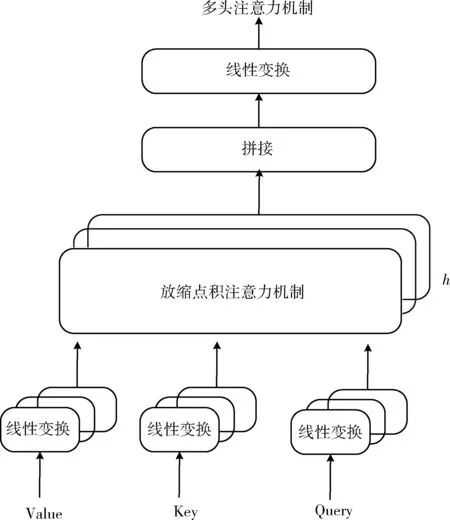
图4 多头注意力机制的框架
假定变换神经网络模型中最后一层Bi-GRU的特征输出表示为hT,则实体预测yE的神经输出可以由一个全连接层和softmax层生成
(5)
(6)

(7)
(8)
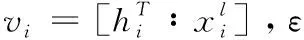
2.2 一阶逻辑

B1∧…∧Bk⟹H
(9)
式中:H为规则结果,B1∧…∧Bk为前提条件。子句的基础是一种替换,它将子句中每个出现的变量映射到一个常量
B1(φ)∧…∧Bk(φ)⟹H(φ)
(10)
式中:φ表示替代量。Herbrand解释[11]是一种映射,它为每个基态原子分配一个真值。要使其成为Herbrand模型,必须满足所有的逻辑公式。为了找到一个Herbrand模型,一个可行的方法是通过直接后果算子,即从Herbrand解释到它自身的一个映射

(11)
式中:I表示Herbrand解释,P是一组子句。给定已知的基态原子,可以找到其它的基态原子作为逻辑公式的直接结果。在本文公式中,使用神经网络来模拟直接后果算子,并应用概率逻辑,其中每个公式都被赋予一个置信度,并且每个基态原子有一个连续的真值在[0,1]内,以表示其为真的概率。
2.3 差异单元
深度学习模块通过特征学习能够隐式地利用单词级进行交互,但是无法考虑输出之间更复杂的关联信息。例如,实体类型与关系之间的内涵关联,这些复杂的关联信息不容易被DNN捕捉,但是可以有效地表述为逻辑规则。本文构造2种FOL来指定实体和关系标签之间的关联。第一种类型专注于分段标签的相关性,即segb(Z)⟹sega(X),这意味着如果变量Z的分段标签为b,则变量X的分段标签就可以推导为a,其中a,b∈{B,I,O}。第二种类型是对实体类型和关系之间的相关性进行建模,例如,entityc(X)∧rell(X,Z)⟹entityd(Z),这意味着只有当第一个实体和第二个实体分别具有类型c和d时,关系l才会出现。
为了使逻辑规则与DNN输出兼容,本文采用了概率逻辑,其中在[0,1]中为每个原子分配一个连续值,然后将布尔运算转换为以概率单位工作。因此,将从FOL语言到连续空间R的映射Γ定义为
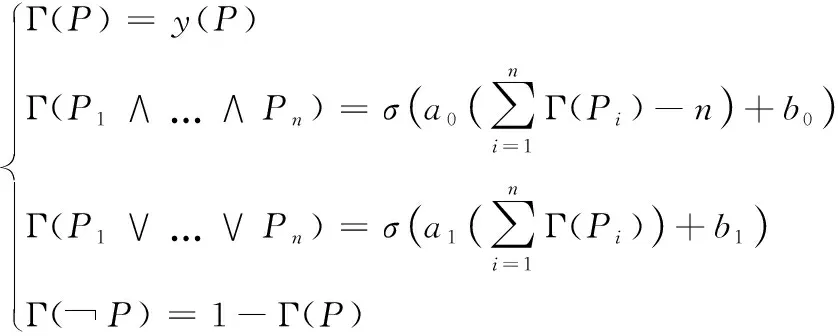
(12)
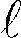
(13)

(14)
所提模型利用梯度下降方法通过损失函数进行端对端训练,更新神经和逻辑输出
(15)
(16)
当神经输出与逻辑输出相差很大时,通过损失函数的约束,深度模型将修改其网络,使其更符合逻辑规则;同时逻辑模块将调整其权重及传递回神经元的映射。
3 实验与结果分析
为了验证所提方法的有效性,对信息抽取中的意见目标抽取(opinion target extraction,OTE)和端对端关系提取(end-to-end relation extraction,RE)2个任务进行实验,实验过程中采用5个数据集进行了测试,并将测试结果与现有方法进行了对比。所有实验均在操作系统为Windows10 64位操作系统,CPU Inter Xeon-E5-2667@3.3 GHz,RAM 64 GB的环境中进行。
OTE任务中,使用了SemEval 2014和SemEval 2015中的3个基准数据集[7],其中两个数据集包含有关餐厅的评论,另一个包含笔记本电脑的评论。表1中给出了3个数据集的详细说明。对于词向量初始化,在其它数据集上使用python中的gensim库所包含的Word2Vec工具对单词嵌入进行预训练,训练数据采用了Yelp数据集和Amazon reviews数据集[12]中有关餐厅和笔记本电脑方向的电子数据。RE任务中,使用了TREC和ACE05数据集[13]进行测试,其中TREC数据集中具有人、位置、组织和其它4种实体类型,包含Located_In、Live_In、OrgBased_In、Work_For和Kill这5种关系;ACE05数据集具有7个粗粒度实体类型和6个实体之间的粗粒度关系类型的带注释数据。2个数据集的详细描述见表1。RE任务的词向量初始化过程使用Glove工具在Wikipedia语料库上对嵌入词进行了预训练。
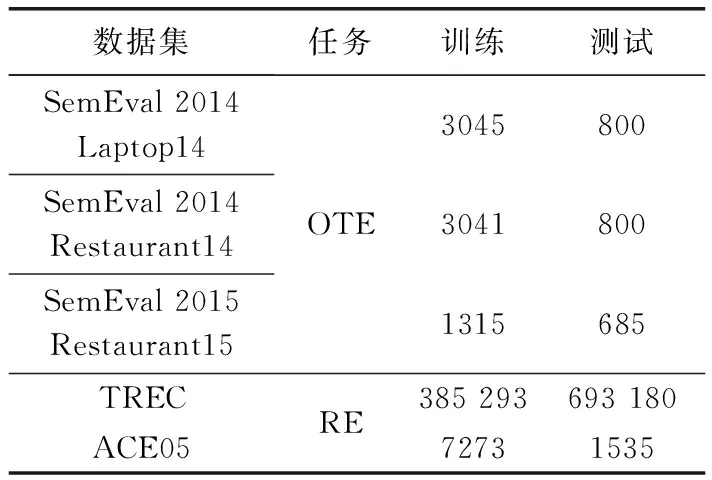
表1 5个基准数据集的详细描述
对于所有实验,单词嵌入和POS嵌入的尺寸分别设置为300和50,标签嵌入的尺寸设置为25,隐藏层的尺寸为200。多头自我注意采用10个,此外还使用了添加到输入向量的位置编码。为了训练模型,采用AdaDelta算法,初始率为1.0,丢失率为0.1。为了评估算法性能,采用F1-分数进行度量。在评估过程中,基于匹配原理,如果匹配成功则一个实体被视为正确;如果一个关系的两个实体都正确,且关系类型与规则标签匹配,则该关系是正确的。
首先进行第一个实验,在OTE任务中所提方法在3个基准数据集的测试结果与MTLSTM方法[7]、GRU方法[14]以及CNN方法[15]等进行了比较。由于OTE任务可视为单类实体抽取,因此所提模型可以通过忽略关系预测来适应此任务。图5给出不同方法的测试结果。从图中可以看出,所提方法在3个基准数据库取得最佳结果,即使不引入逻辑库,所提深度模型在Restaurant14和Laptop14中的测试结果也是最优的,在Restaurant15中的结果稍差,这说明该深度模型在隐式交互建模中的有效性。在考虑逻辑知识时,使用分词规则来强制2个相邻词使用可能的分词标签。此外,还引入了隐式关系规则,在深度学习模块中保留关系预测层来实现高准确率。
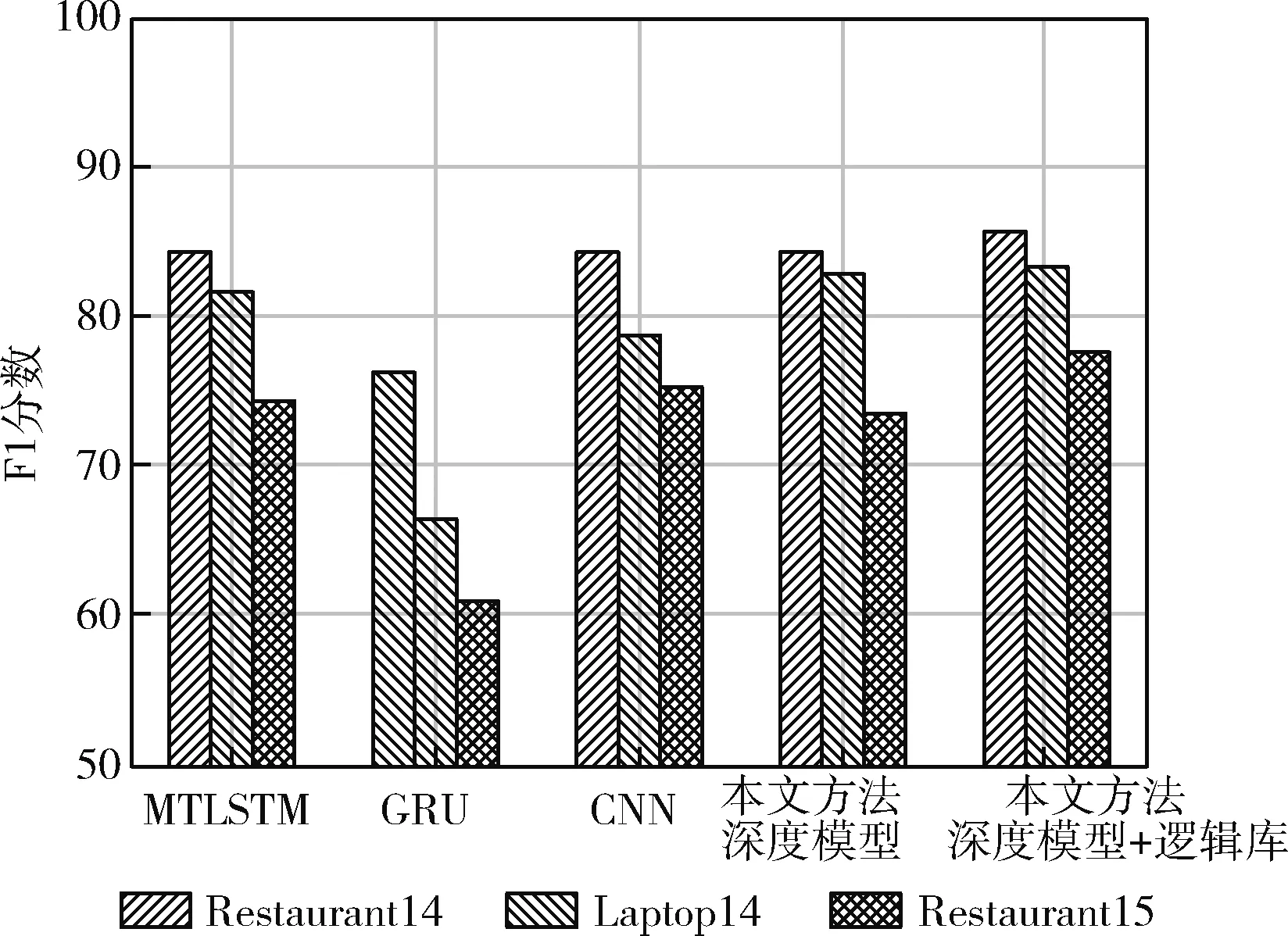
图5 不同方法在OTE任务中的测试结果
然后进行第二个实验,在RE任务中所提方法在TREC和ACE05两个数据集上进行测试,并将结果与CNN与注意力机制混合方法DCNN-ATM[8]、对抗训练方法AT[13]、基于远程监督的DBpedia方法[16]、MRT方法[17]以及基于多头注意力机制的双指针生成网络DPN-MATM方法[18]等进行了比较。在测试过程中假设给定实体边界,任务是预测实体类型和关系。图6和图7分别给出了不同方法在TREC和ACE05数据集上的结果对比。从图中可以看出,实体预测的精度要高于关系预测。此外,在所有方法中,本文方法的测试结果是最优的。

图6 不同方法在TREC上的结果

图7 不同方法在ACE05上的结果
4 结束语
本文提出了一种基于规矩约束的深度学习文本信息抽取方法,用于解决由于训练样本不足而导致深度学习网络性能下降的问题。该方法将逻辑规则引入到深度学习框架中,使得深度学习模型在训练过程中以多个约束条件进行学习,同时规则库中的每个逻辑规则也会根据深度模型的学习进行更新置信权重,适应不同情况的数据样本。为了保证深度模块与规则库之间的一致性,本文还构造了一个新的损失函数,用于衡量两者之间的分歧。实验结果表明,所提方法在意见目标抽取和关系抽取等任务中性能显著,比其它方法更具优势。
猜你喜欢
法律方法(2022年2期)2022-10-20
中学生百科·大语文(2021年11期)2021-12-05
纺织科学研究(2021年7期)2021-08-14
阅读(快乐英语高年级)(2020年8期)2020-01-08
中国外汇(2019年18期)2019-11-25
智慧少年·故事叮当(2018年11期)2018-05-14
37°女人(2017年11期)2017-11-14
哲学评论(2017年1期)2017-07-31
意林(绘英语)(2017年5期)2017-05-15
领导决策信息(2017年9期)2017-05-04
