
基于文本双表示模型的微博热点话题发现
2021-12-18 01:19:10刘梦颖
计算机与现代化 2021年12期
刘梦颖,王 勇
(北京工业大学信息学部,北京 100124)
0 引 言
随着信息技术的快速发展以及社交网络的兴起,通过互联网传播的信息量更是呈爆炸式增长。微博作为当前国内广泛使用的社交媒体平台之一,凭借其平台的开放性已经成为越来越多的网民表达自我情感、获取时事新闻、讨论社会舆论的重要平台[1]。
目前,针对微博平台的热点话题发现,众多学者已经开展了大量的研究工作。Chen等[2]通过计算每个单词的TF-ID值,即使用单词出现的频率衡量其是否为热词,进行热点话题挖掘。路荣等[3]采用LDA模型对微博文本进行隐主题建模,通过隐主题模型计算微博文本之间的相似度,进行话题聚类。Ye等[4]将微博中的点赞、评论、转发、时间、用户权限等微博特征信息添加到主题模型中,利用这些特征计算每个微博的关注价值、权威价值和词频,构造了微博新的主题模型MF-LDA,实验显示具有更好的准确性。陈珊珊[5]使用LDA模型来挖掘隐藏在数据中主题信息,使用主题信息来实现文本表示。Liu等[6]提出使用HowNet来扩展文本中单词的语义特征,以达到更好的聚类效果。为了进一步解决文本表示模型的高维问题,有学者提出将频繁词集的概念[7]应用于短文本聚类中,Zhang等[8]提出用挖掘的频繁词集作为特征来表示文本,并使用文本包含的频繁词集个数计算文本之间的相似度进行聚类。徐雅斌等[9]针对微博这一特殊媒体进行分析,提出使用频繁词集聚类FWSC(Frequent Words Sets Clustering)算法进行微博话题发现。彭敏等[10]提出了一种聚类簇数目自适应的频繁项集谱聚类算法CSA_SC,实现微博文本聚类与话题抽取。
由于微博文本具有篇幅较短、信息量少等特点,传统的话题发现方法仅仅考虑词的统计关系而无法兼顾低频描述词,大大影响了短文本的聚类效果。再加上微博文本内容随意,一些用语一词多义也增加了微博热点话题发现的难度。因此,提出一种行之有效的中文微博热点话题发现方法具有重要的现实意义。
本文在深入分析目前国内外已有的热点话题发现技术基础上,研究其在短文本聚类结果和热点话题评估等方面都不是很理想的原因,考虑在传统的基于统计词频的方法基础之上融入BERT句向量语义进行主题聚类,通过改进相似性度量的Affinity Propagation(AP)聚类算法进行微博话题挖掘,并引入H指数进行话题热点评估分析,提出一种更适合微博热点话题发现的方法。
1 基于文本双表示模型的微博热点话题发现方法
本文提出的基于文本双表示模型的微博热点话题发现方法如图1所示。首先,对微博数据集进行数据预处理,然后对文本进行频繁词集挖掘和BERT句向量表示,通过构造FWS-BERT文本双表示模型计算文本相似度进行谱聚类,之后再对主题聚类结果进行话题挖掘,最后通过话题描述词进行微博热点话题评估。
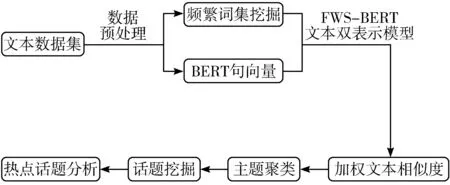
图1 基于文本双表示模型的微博热点话题发现方法流程
1.1 FWS-BERT文本双表示模型
1.1.1 频繁词集挖掘
在文本中,经常同时出现的特征词往往存在一定的关联性,同一主题下不同短文本之间包含的特征词也经常重复出现。因此,利用微博文本之间共有的特征词数量来衡量微博文本相似度是目前普遍采用的一种标准。
本文采用韩家炜教授等人[11]提出的FP-Growth算法作为频繁词集挖掘算法。FP-Growth算法是频繁模式挖掘领域的经典算法,相比Apriori等算法在大数据集上较为高效。本文根据微博文本的数据量设置最小支持度,对清洗处理后的微博文本进行频繁词集挖掘。相关定义如下:
定义1 文本集合。进行数据预处理及特征词汇筛选后的微博文本组成文本集合D={D1,D2,D3,…,Dn}。
定义2 最小支持度。文本集合D中所有特征词集合T={t1,t2,t3,…,tn}。文档Di包含的所有特征词集合WDi∈T。词集U为T的子集,U的支持度为support(U)=|{Di|U⊂WDi,Di∈D}|,表示包含词集的文本数量。考虑到频繁词集挖掘算法效率对实验复杂度的影响,设置一个控制频繁词集数量的阈值θ,称该阈值θ为最小支持度。
定义3 频繁词集。通过对数据文本集合D进行FP-Growth频繁词集挖掘,得到大于设置的最小支持度阈值的频繁词集集合U={U1,U2,U3,…,Un},其中Ui表示每个频繁词集,每个频繁词集由多个词语组成Ui={w1,w2,w3,…,wn}。
由于频繁词集长度较短、信息量较小,难以依据传统的文本相似度度量方法,如余弦相似度或欧氏距离来评估频繁词集之间的相似度。因此,本文采用Jaccard系数来度量微博文本之间的频繁词集相似度,如公式(1):
(1)
其中,Jaccard_Sim(Di,Dj)表示2个微博文本之间的相似度,分子表示2个文本所包含的频繁词集交集数量,分母表示2个文本所包含的频繁词集并集数量。
1.1.2 BERT句向量
BERT[12](Bidirectional Encoder Representation from Transformers)是2018年Google AI团队发布的一种新的语言模型,其结构如图2所示。BERT采用Transformer[13]编码器作为模型核心结构,E1,E2,…,EN为模型的输入向量,T1,T2,…,TN为模型的输出向量。
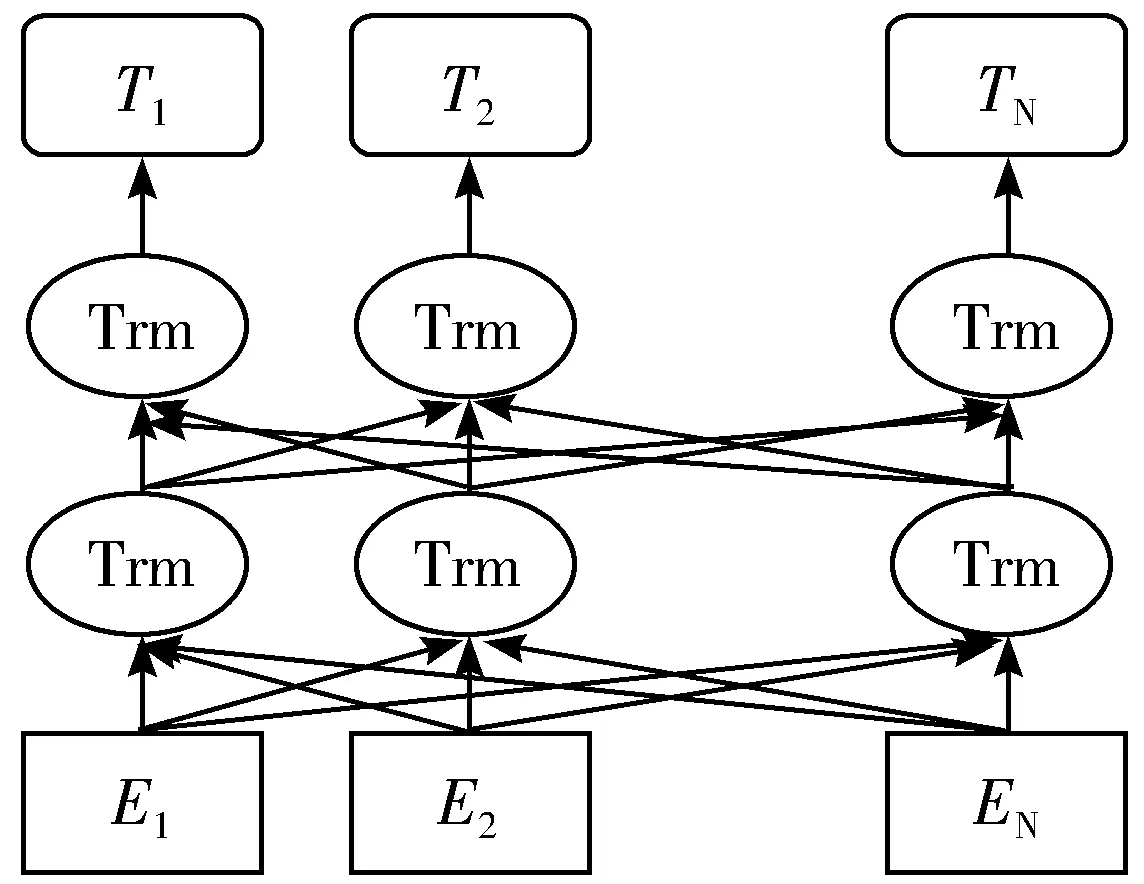
图2 BERT语言模型结构
BERT作为一个多任务模型,其预训练过程是由2个自监督任务组成,即掩码语言模型(MLM)任务和句子连贯性判定(NSP)任务。MLM是指在训练的时候随机将输入语料中15%的词遮盖起来,然后通过上下文预测被遮盖的词,通过迭代训练可以学习到词的上下文特征、语法结构特征、句法特征等,保证了句子特征提取的全面性。NSP的任务是判断某个句子X是否是另一个句子Y的下文,通过迭代训练学习到句子之间的关系。
BERT预训练语言模型抛弃了传统的RNN和CNN,通过多层Transformer使用自注意力机制(self-attention)同时并行提取输入序列中每个词的特征,有效地解决了棘手的长期依赖问题。与传统循环神经网络相比,BERT模型使用双向Transformer对当前单词的上下文信息做特征提取,能够较完整地保存文本语义信息;同时BERT模型根据上下文信息动态调整文本句向量能解决一词多义问题。Transformer的网络架构如图3所示。
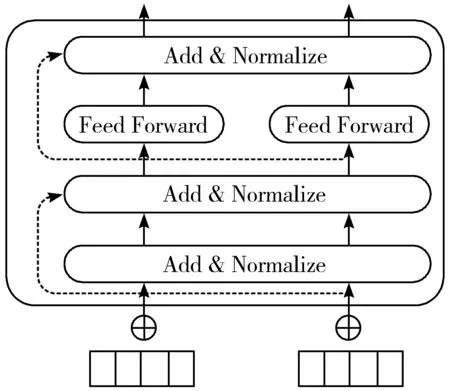
图3 Transformer网络架构
“BERT-Base,Chinese”是Google开源的BERT中文预训练模型,模型总参数大小为110 MB。为了将BERT预训练模型用在特定的微博领域,当前通用的做法是在BERT预训练模型上继续使用特定领域语料对该模型进行继续训练[14]。因此,本文使用海量的微博文本作为继续训练BERT预训练模型的语料库,使得到的BERT模型更加符合微博语言环境。将训练好的模型载入后,可以直接将微博文本输出为768维的句向量。微博文本的BERT句向量语义相似度采用余弦距离来表示,2个向量夹角的余弦值越接近于1,代表2个向量越相近,2个文本越相似。如公式(2):
(2)
其中,Di、Dj表示由BERT模型训练而得到文本句向量。
1.1.3 构建FWS-BERT文本双表示模型
由于微博短文本的特殊性,目前单一的基于文本特征词统计关系往往不能准确表示文本内容,容易发生相似度漂移现象,大大影响了短文本的聚类效果。因此本文选择采用BERT文本句向量所计算的外部语义关系并将其融合到基于频繁词集计算文本相似度的方法中,构建基于特征词的统计关系和上下文语义关系的文本双表示模型来处理微博文本,从更全面的角度对微博文本进行表示。
最终文本相似度由频繁词集相似度(公式(1))和BERT句向量语义相似度(公式(2))这2个部分加权集成得到,如公式(3):
Sim(Di,Dj)=αJaccard_Sim(Di,Dj)+(1-α)Vec_Sim(Di,Dj)
(3)
其中,α是调节2种相似度所占比重的重要参数,根据实验结果确定,0<α<1。
通过FWS-BERT文本双表示模型构建的微博文本融合相似度矩阵M如下:
(4)
其中,Simij表示由文本双表示模型计算出的下标为i与下标为j的2个微博文本融合相似度。
最后,本文通过融合相似度矩阵M采用谱聚类算法[15]对微博文本进行主题聚类。
1.2 话题挖掘
对于聚类后每个主题下所有微博数据文本,本文使用FP-Growth算法分别设置不同的最小支持度对每个主题下文本进行频繁词集挖掘,考虑到只有一个词的频繁词集对话题表示意义不大,因此选取了长度大于等于2的频繁词集作为每个主题的聚类结果。
为了准确检测到各个主题下的隐含话题,本文将MinHash算法[16]引入AP聚类算法[17]中,代替原有的欧氏距离度量来构建频繁词集相似性矩阵进行话题聚类。实验表明,本文在主题聚类结果上使用改进相似性度量的AP聚类算法能有效地挖掘到各个主题下的隐含话题。
1.3 热点话题评估分析
对于微博话题的热度估计,目前没有一个统一的度量标准[18]。本文通过对微博话题传播规律进行分析,综合考虑微博话题热度的影响因素,通过引入文献计量学中的H指数[19-21]并选取话题词热度和用户参与度这2个维度进行话题热度值计算,综合得出微博热点话题。
1)话题词热度。首先将某个话题描述词所在微博的被转发数、被评论数、被点赞数分别从高到低进行排序,直到前H篇微博的被转发数、被评论数、被点赞数各不少于H,得到某话题描述词的H指数。如公式(5):
(5)
其中,Hz、Hp、Hd分别是包含某话题词所在微博的被转发、被评论、被点赞的H指数。
2)用户参与度。本文假设粉丝数达到10万的用户为大用户。用户参与度由包含话题词的微博总条数、包含话题词的微博参与用户数和参与用户中大用户数量来度量。如公式(6):
(6)
其中,sum是包含某话题词的微博总数,sum_user是包含某话题词的微博参与用户数,user_v是参与用户中大用户数。
设某话题包含k个话题词,综合话题词热度和用户参与度得出话题的热度计算如公式(7):
(7)
2 实验结果与分析
2.1 数据集
本文对新浪开放平台API进行分析,利用Python爬虫技术在新浪微博上采集了2类数据,第一类是随机爬取的微博文本共3.609 GB,作为BERT语言模型的训练数据;第二类是采用定主题的方式爬取了2020年11月5日至12月3日之间的微博数据,包含微博内容数据和微博用户数据2个部分。
通过对微博内容数据集进行筛选,选取了新冠、5G、直播3个主题,每个主题下5个热点话题,共5359条数据,该数据集没有进行对主题及话题的人工标注;与之对应微博用户数据集共4611条。数据集的详细信息如表1~表3所示。

表1 新冠主题下话题数据详细信息

表2 5G主题下话题数据详细信息

表3 直播主题下话题数据详细信息
本文使用Jieba分词工具包实现分词,并通过构建停用词表匹配去掉停用词。利用TF-IDF[22-23]和TextRank[24]分别提取关键词并进行合并形成关键词集合,使用该集合对微博文本进行关键词筛选,降低数据的稀疏性以及建模的维度。
2.2 实验结果分析
2.2.1 FWS-BERT模型参数确定实验
在FWS-BERT文本双表示模型中,α决定了计算文本相似度时频繁词集和BERT语义所占的比重,是影响微博主题聚类效果的重要参数。α取值较大时,FWS-BERT模型过多地考虑微博文本的统计特征而忽略了上下文语义挖掘;α取值较小时,由于微博短文本自身包含的信息量较少、上下文特征不足,FWS-BERT模型过多地关注短文本的语义信息,可能也不能很好地实现主题聚类。
为了达到更为理想的实验结果,本文在新冠、5G、直播3个主题的数据集上进行主题聚类实验。本文采用轮廓系数(Silhouette Coefficient)作为实验结果评价标准,记录每个α值下多次聚类实验结果的轮廓系数平均值,如图4所示。通过对比不同α值下的轮廓系数平均值,发现当α值太大或太小时都不能达到较好的主题聚类实验效果,最终取α为0.6。
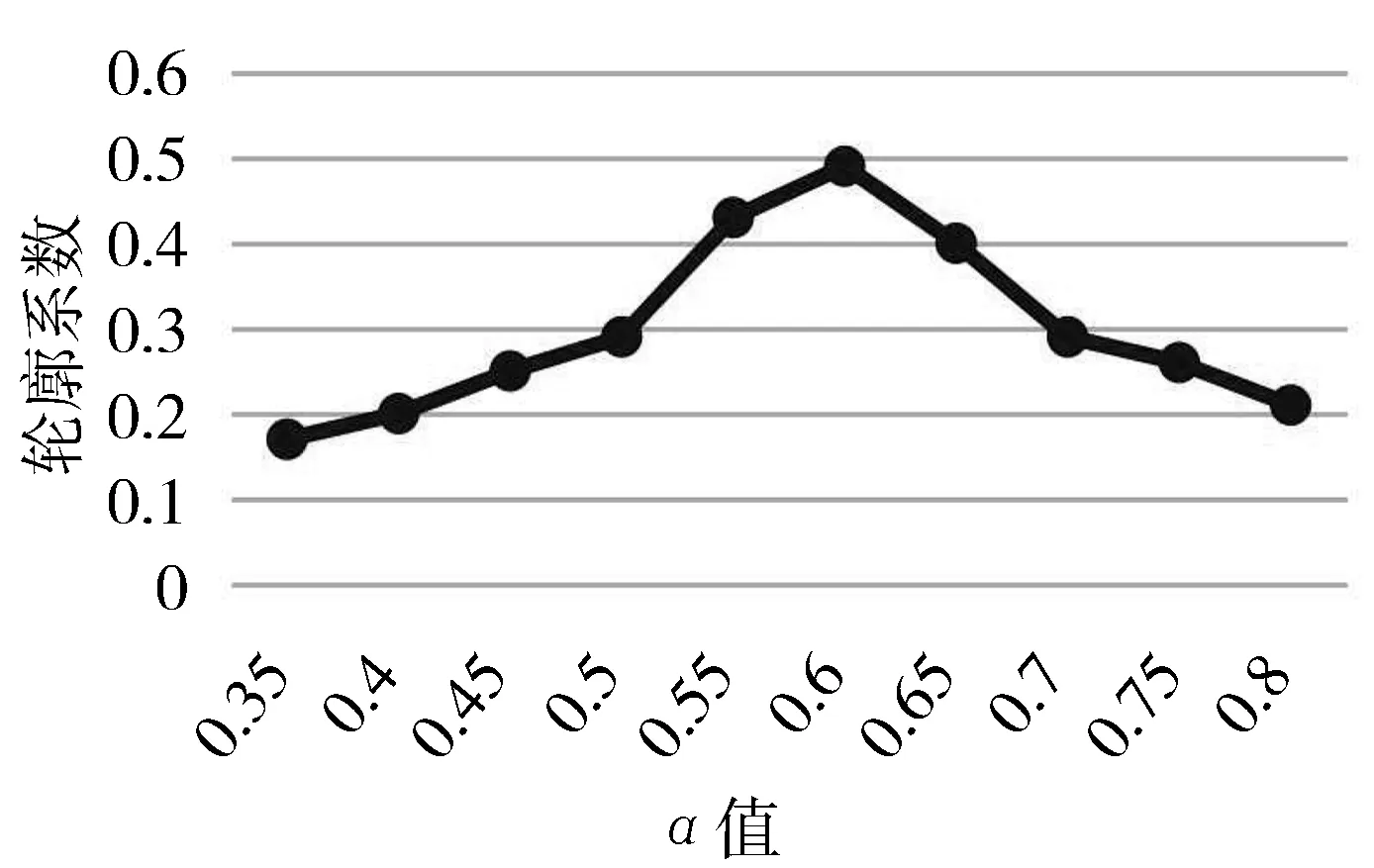
图4 不同α值下的轮廓系数
2.2.2 FWS-BERT模型聚类有效性实验
为验证使用本文提出的FWS-BERT模型进行主题聚类的有效性,采用轮廓系数和Calinski-Harabaz指数作为本实验的评价标准,分别对比了以下4种文本表示方法:
1)FWS-BERT-S。本文的FWS-BERT模型谱聚类。
2)FWS-BERT-K。本文的FWS-BERT模型K-means聚类。
3)FWS-S。基于频繁词集的单一文本表示谱聚类。
4)LDA-S。基于LDA主题模型谱聚类。
在实验过程中,分别使用这4种方法在不同的数据量下进行实验,记录不同方法在每次实验中聚类结果的轮廓系数和CH值。重复实验多次,记录多个轮廓系数和CH值,并计算得到对应文本表示方法的平均轮廓系数和平均CH值,实验结果如图5和图6如示。

图5 不同数据量下4种聚类方法的轮廓系数
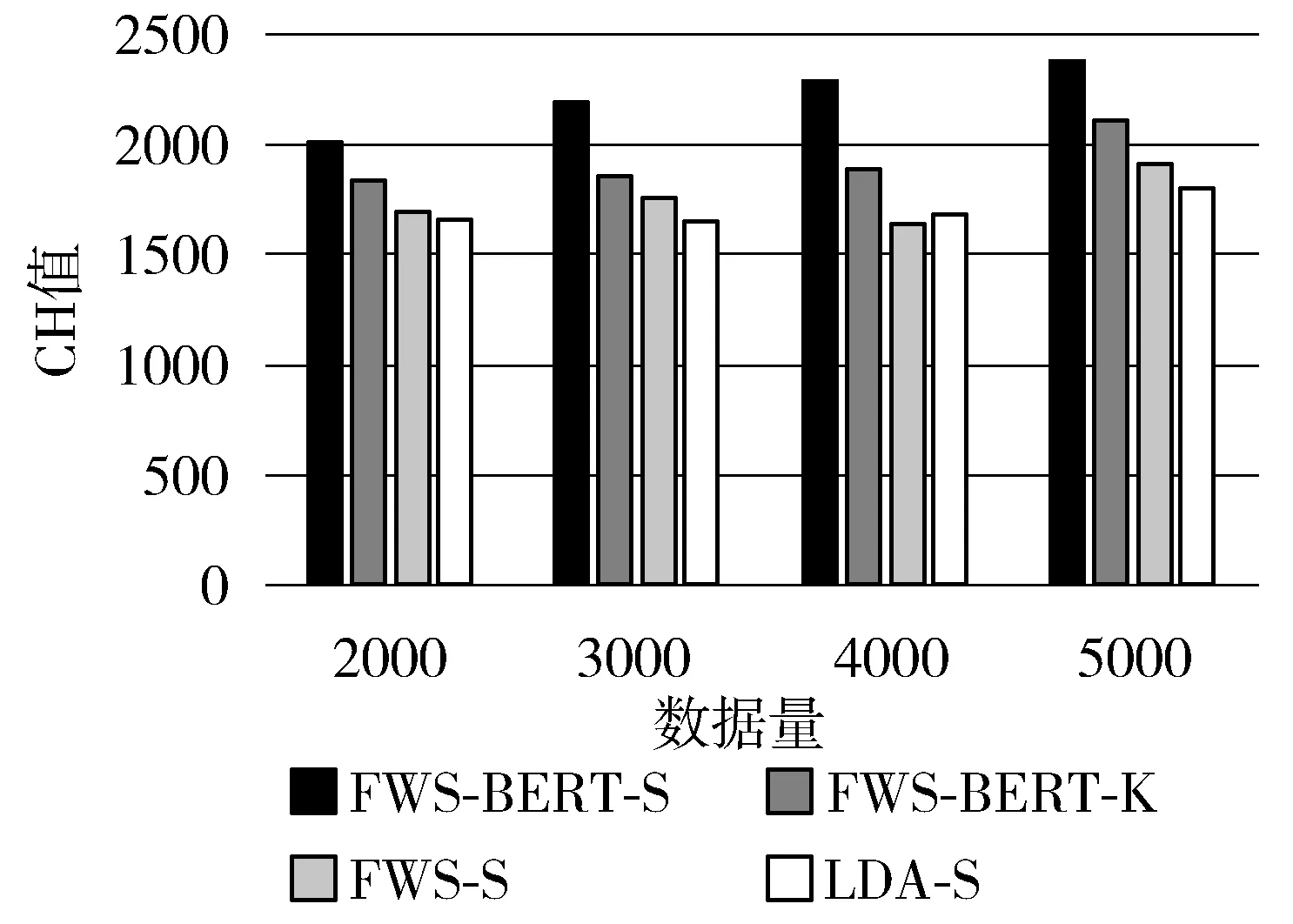
图6 不同数据量下4种聚类方法的CH值
分析图5、图6的实验结果,在不同的数据量下,本文提出的FWS-BERT模型谱聚类结果在轮廓系数和CH值上均优于基于LDA主题模型谱聚类算法和基于频繁词集的单一文本表示谱聚类算法,同时也表明使用谱聚类算法在微博短文本上的聚类效果要明显优于K-means算法。由于短文本中特征词较少,在LDA主题模型中会出现数据稀疏性问题,单一的频繁词集表示虽然在一定程度上降低了短文本表示的维度,但由于该方法只考虑文本中特征词的统计关系而忽略了上下文语义信息,仅仅使用频繁词集对文本进行建模会大大影响聚类效果。本文提出的基于FWS-BERT的谱聚类算法既使用频繁词集挖掘考虑了短文本的统计信息,又通过BERT句向量中融入了更多的语法、词法以及语义信息,从而能更准确地表示文本中词语之间的潜在语义关系,达到了很好的聚类实验效果。
2.2.3 话题聚类算法有效性对比
为了验证本文提出的改进AP聚类算法对于微博话题聚类的有效性,本文设置了原始的AP聚类算法、经典的K-means算法和本文提出的改进AP算法进行对比,其中原始的AP算法使用频繁词集作为文本表示,K-means算法分别使用TF-IDF(K-means1)和频繁词集(K-means2)文本表示。实验评价指标仍采用轮廓系数和CH值。在实验过程中,将每个微博主题下所有文本数据当成一个整体,分别对每个主题进行话题聚类实验,每组实验运行多次,计算得到聚类结果的平均轮廓系数和平均CH值,观察不同聚类算法在结果上的差异,实验结果如图7、图8所示。
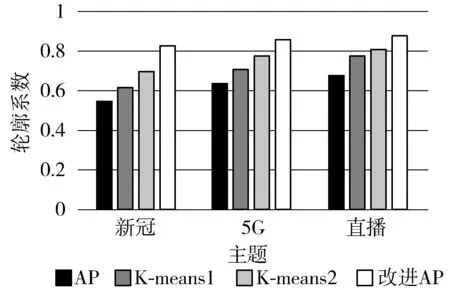
图7 不同主题下4种聚类方法的轮廓系数

图8 不同主题下4种聚类方法的CH值
由图7、图8的实验结果可知,本文提出的改进AP聚类算法在轮廓系数和CH值上均取得了较好的实验效果。首先,AP算法相比于经典的K-means算法而言,不用事先指定每个主题下聚类的结果簇数目,从而对话题检测具有一定的灵活性。基于频繁词集的文本表示方法在一定程度上优于TF-IDF,主要是频繁词集提取的文本特征更加完整,比TF-IDF能够较为准确的表示文本。同时,实验结果表明,引入MinHash算法计算文本集合之间的相似度更加符合微博文本的特点,能有效实现对各个主题下的微博话题检测。
2.2.4 话题挖掘及热度评估实验
本实验主要是验证本文提出的话题挖掘及话题热度评估分析方法有效,实验前在微博热搜搜索引擎上逐一使用关键词“新冠”“5G”“直播”查询每个主题下各个话题的热度值并进行记录和排名。利用本文提出的基于改进相似性度量的AP聚类算法对话题进行挖掘,并使用公式(7)话题热度计算公式分别计算每个主题下各个话题的热度值,与所记录的真实微博热度排名进行对比,验证本文方法的有效性。各个主题下话题表示、话题热度真实值及实验结果如表4~表6所示。

表4 新冠主题下话题热度真实值及实验结果

表5 5G主题下话题热度真实值及实验结果
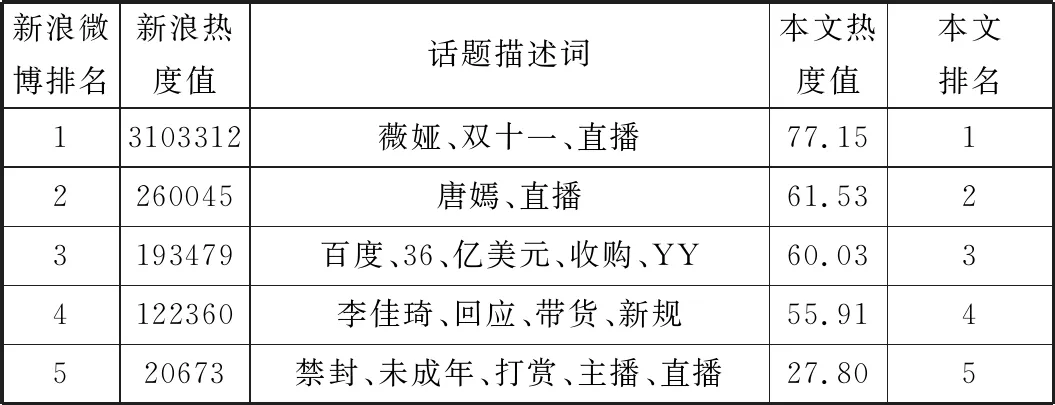
表6 直播主题下话题热度真实值及实验结果
分析表4~表6的实验结果,各个主题下的话题描述词基本能准确描述话题内容,没有出现话题描述重叠、无法辨识话题内容的现象。受到采集数据和聚类结果的影响,新冠主题和5G主题各个话题热度值排名与真实的微博热度值排名稍有偏差,直播主题下各个话题热度值与真实的微博热度值排名一致。本实验验证了本文提出的话题挖掘方法及话题热度评估分析方法的有效性。
3 结束语
本文针对传统的热点话题发现方法中存在的单一文本表示不准确、热点话题发现效果差等问题,提出了一种切实可行的微博热点话题发现方法,并通过实验证明了本文提出的方法在微博主题聚类、话题挖掘、话题热度评估等方面是有效的,可为市场行业的调研、政府对舆论的预警和正确引导提供重要的参考。下一步将在更大规模的微博数据集上研究FWS-BERT模型中α取值问题,进一步细化α取值梯度以得到更为理想的实验效果。
猜你喜欢
作文大王·低年级(2022年3期)2022-03-19 18:09:52
小学生作文·小学低年级适用(2018年12期)2018-04-11 03:10:42
电子测试(2017年15期)2017-12-18 07:19:27
作文通讯·高中版(2017年6期)2017-07-10 03:21:34
网络空间安全(2016年3期)2016-06-15 20:27:07
校园英语·下旬(2016年2期)2016-03-18 10:23:20
智能系统学报(2015年4期)2015-12-27 09:38:39
电子设计工程(2015年6期)2015-02-27 12:04:53
快乐作文·低年级(2014年10期)2015-01-14 23:43:55
中国有色金属(2014年23期)2014-03-13 02:10:27
