
基于VGG网络不同模型的建筑物自动提取
2021-12-17 11:18刘于昆高郭瑞王淑焜戚慧王振华张家佑
电子测试 2021年22期
刘于昆,高郭瑞,王淑焜,戚慧,王振华,张家佑
(郑州大学地球科学与技术学院,河南郑州,450000)
0 引言
建筑物作为城市或城郊的重要特征,精确识别建筑物在土地利用分析、交通规划、地图更新、城市规划及环境保护等领域具有重要意义。随着高分辨率卫星的发射,遥感影像空间分辨率的提升,具有更加丰富的地物空间结构和纹理特征信息,使得建筑物的精准识别定位成为可能,但同谱异物和同物异谱的现象也更加严重。传统目视解译消耗大量人力物力,基于传统机器学习自动解译也稍显落后,而基于深度学习的卷积神经网络算法自动提取建筑物在计算机发展下逐渐成为热门,对于绝大部分的计算机视觉问题, 基于深度卷积神经网络( DCNN)方法的效果明显优于其他传统方法。
本文基于VGG16(Visual Geometry Group Network 16)网络模型,改进构建FCN、U-net、SegNet三种网络结构,并对同一地区遥感图像进行实验,对比三种网络结构对大多伦多地区(Greater Toronto Area,GTA)数据集自动提取的效果,比较三种模型的优劣性。
1 研究方法
VGG网络是经典的卷积神经网络,由13个卷积层、5个池化层、3个全连接层组成。通过“卷积层+池化层”得到特征图,然后将得到的特征图转换成一维向量输入到全连接层,最后一层全连接层通常被传到Sigmoid激活函数或Softmax激活函数中,用于二分类或多分类任务[1]。
本文以VGG16为基础网络结构,舍弃了它的全连接层,搭建FCN、U-net、SegNet三种模型,通过对同一数据集进行分类识别,多次试验得到建筑物提取结果,对比分析其分类精度,找到最佳建筑物自动提取模型。
1.1 FCN模型
FCN网络将传统卷积神经网络VGG16中的全连接层替换为卷积层,提高了分割效率、降低了计算复杂度。网中包括卷积层、激活函数层、池化层、反卷积层、裁剪层以及Eltwise层。其中卷积、池化、反卷积是最主要的操作[2]。
卷积层是FCN神经网络的核心层,通过对输入图像进行卷积操作,类似图像滤波的过程,得到初步的特征图。池化层对输入的特征进行压缩,减小特征图尺寸,突出影像中的主要特征,使得网络计算复杂度降低。反卷积层用于将经过卷积及池化操作后的特征影像进行上采样操作,从而恢复特征影像的尺寸,反卷积层可以使得网络学习到更加复杂的特征。
1.2 U-net模型
U-net模型是基于FCN对语义分割的探索,实现了像素级的数据提取。该模型采用VGG16网络(去除全连接层)作为编码器,并且在VGG16网络的每一个卷积模块的末尾部分增加了Dropout层,避免模型出现过拟合现象。在解码器部分,通过步长为2的转置卷积实现特征图的上采样,并通过跳跃连接方式来融合编码器的多层语义特征,从而还原图像的分割细节[3]。U-net的网络架构类似于一个U型结构,FCN反卷积过程是利用了最后三层,U-net模型解码过程将每层的输出结果进行小步幅上采样,然后通过不断拼接特征图完善细节,得到最终高精度的结果。
1.3 SegNet模型
SegNet模型是由编码网络、解码网络和逐像素分类器组成的网络模型。SegNet沿用了FCN中图像语义分割的思想,在池化过程中记录了每一个最大权重的位置优化了反卷积过程。SegNet是基于像素的端到端的网络架构,但融合了编码-解码结构和跳跃网络的特点[3]。
2 实验及分析
2.1 实验数据集
实验数据集为GTA建筑数据集。该数据集由大多伦多地区的遥感图像组成。大多伦多地区大约600平方公里,是加拿大人口密度最高的都市区,同时也是北美第五大都会区。因此,大多伦多地区有很多大型城市建筑和错综复杂的交通道路,对其进行建筑物提取有较大的难度。
2.2 实验设计与结果评价
2.2.1 实验设计
本次实验使用GTA数据集,在网络模型VGG16基础上搭建FCN、U-net、SegNet模型。通过修改输入参数进行训练和预测,不断调整学习率搭建好网络模型,最后用于建筑分类。本文实验训练方式较为不同,将输入图片分为了三部分,即彩色通道、灰度通道、边缘通道,进行输入,在此基础上,还对效果最好的U-net网络进行了单输入,做不同的对比试验,比较三种网络的优劣,并对其分类结果进行评价。
2.2.2 实验结果
在网络方面,为对比突出,卷积层均选择VGG16的卷积层架构,卷积层之后则采用不同网络的处理方式。在分类精度方面,U-net网络的精度最佳。并且实验发现,通过三通道输入会使模型精度得到一定的提升。本文三种网络分类结果如图1所示。
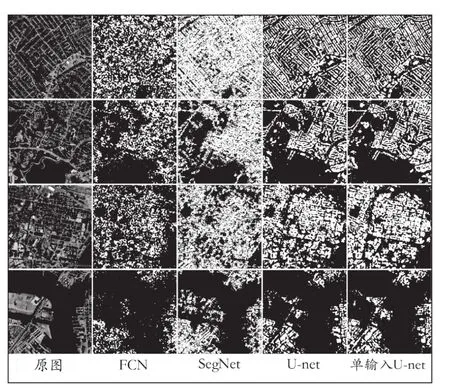
图1 三种模型的建筑物提取结果
从图1可以看出,Seg-Net在大目标预测方面表现较好,但对于建筑图象的细节部分,SegNet表现较差。FCN网络虽然在整体上略强于SegNet网络,但针对密集建筑物地区存在较多的虚假现象,容易将道路错误提取为建筑物,对建筑物密集区的提取结果较差。U-net网络具有更精准的分割细节,对建筑物密集区区分能力更强,但是由于上采样的弊端导致许多细小图案之间存在粘连。实验结果中还可以发现,许多圆形建筑均被检测到,却表现为正方形的预测值,进一步证实了上采样的弊端,因此在该方面仍需改进。
2.2.3 实验分析
为了更好地定量评价各种模型的分类效果,本文采用查准率(Precision)、查全率(Recall)及综合分数(F1),见式(1)—(3)。

式中,TP为正确提取出的建筑物(单位为像素,下同),FP为虚警,即与参考结果无匹配的建筑物提取结果,FN 为漏分,即未提取出的建筑物,F1值越大,表明算法提取效果越好。
本次实验中,对输入方式做出了改变,将输入图片分为三个部分输入:彩色通道、灰度通道、边缘通道分别利用网络提取不同类型特征,最后将特征结合以语义分割FCN网络架构,同时也在U-net和SegNet网络上进行了测试。从表1中可以看出来,在U-net网络上训练,其精确率相比在FCN有了有效的进步,也进一步证实了U-net网络在二分类方面性能方面的强大。但当将本实验输入应用于SegNet网络时,由于参数过多导致训练难以进行,并且训练也将会受到设备的限制,因此使用原始SegNet网络进行实验。
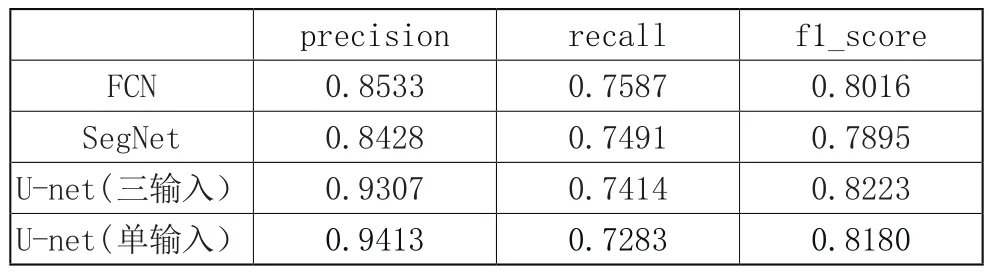
表1 三种模型对建筑物的分类精度
由图1和表1可以发现,三类网络得到的预测图片在特征定位方面表现良好,但在细节方面明显U-net网络会强于其他两类。但由于实验所利用的图片来源为同种图片,来自同一地区,导致模型泛化性能较差。同时,通过对U-net网络进行单输入与多输入进行实验,虽然精确度有所下降,但对比发现整体预测得分有略微提升。
3 结论
本文以VGG16网络进行构建,对同一数据集迭代计算,通过对比FCN、U-net、SegNet三种网络结构对高分辨率遥感影像建筑物自动提取的结果,得出U-net网络结构特征提取结果最优的结论。在多次实验中发现FCN模型虽然可以实现像素级别的特征提取,但在池化过程中往往会丢失部分细节信息,使得结果不够完整,且计算量较为复杂。U-net模型基于VGG网络搭建,将其作为编码器,实现对建筑物像素级别的提取,并且增加Dropout层有效避免过拟合现象,还提高处理的效率和精度。所以,U-net网络相比FCN和SegNet对细节的处理会更强。
猜你喜欢
北京航空航天大学学报(2021年9期)2021-11-02
铁道建筑技术(2021年4期)2021-07-21
小学生学习指导(低年级)(2019年9期)2019-09-25
电子制作(2019年11期)2019-07-04
北京航空航天大学学报(2018年1期)2018-04-20
北京信息科技大学学报(自然科学版)(2016年6期)2016-02-27
管理现代化(2016年3期)2016-02-06
管理现代化(2016年3期)2016-02-06
智能系统学报(2015年4期)2015-12-27
小天使·二年级语数英综合(2015年12期)2015-12-04
