
基于PCA_NearMiss和XGBoost的产品质量预测
2021-12-14 01:44:45蒋金瑜
内燃机与配件 2021年1期
蒋金瑜



摘要:产品质量预测是产品质量控制的重要组成部分,从产品生产数据中挖掘产品质量信息,建立产品生产数据与产品质量之间的预测模型,对提高产品质量,降低生产成本具有重大意义。针对产品生产数据的高维,高不平衡性特点,提出PCA_NearMiss降采样算法,通过PCA算法降低数据维度,再通过NearMiss算法提取出具有代表性的样本,在平衡数据的同时保证数据信息的完整性,最后用选出的样本对XGBoost模型进行训练和测试。使用博世产品生产数据作为实例进行验证,说明了算法的有效性。
关键词:PCA;NearMiss;XGBoost;质量预测
中图分类号:TP181 文献标识码:A 文章编号:1674-957X(2021)01-0122-02
0 引言
在制造业中,产品质量的监测和控制是至关重要的。随着传感器技术和物联网技术的快速发展,大量工厂通过对制造过程的实时监测,来提高生产力和竞争力[1]。如何从工厂采集的大量数据获取产品质量信息,逐渐成为企业的重点工作。来自不同信息源的海量数据让分析变得极具挑战性。机器或传感器故障、噪声、断电等问题导致数据缺失,可能会严重影响模型效果。在实际生产过程中,对每个产品记录的生产数据往往高达上千维度,而且产品中的次品数量远低于合格产品的数量,而机器学习模型对数据平衡性具有很高要求。数据的冗余和高不平衡性会导致模型效果大大下降,对原始数据进行降采样,保证数据模型训练数据相对平衡,降低训练数据相关性,对模型效率和效果的提升具有重要意义。
1 PCA_NearMiss
NearMiss算法可从大量的正样本中选取具有代表性的样本。首先计算每个正例样本与负例样本之间距离,选择每个正例距离最小的前k个负例近邻,再计算正样本与其对应的近邻之间的平均距离,保留平均距离最小的那些正例样本,实现对数据的降采样。NearMiss降采样算法目的是在信息相似的样本中根据需要采样的比例仅保留少数具有代表性的样本,因此可在大量减少多数类样本的同时保持整体数据的信息。
为了解决产品质量数据的高不平衡性,通常采用降采样的方法。降采样在减少正样本数量平衡数据的同时,还需最大程度的保留原始数据的信息。每件产品在生产过程中记录的数据往往具有很高的维度,而基于距离的降采样算法对高维数据降采样质量很差。为提高降采样对高维数据的适用性,采用PCA降维算法降低原始数据维度,提高数据信息密度,提高不同样本之间的区分度,再通过NearMiss算法对降维后的数据进行降采样,得到最终参与模型训练的样本。
2 XGBoost
极端梯度提升算法(XGBoost),是一种基于分类和回归树集成的模型[3]。在XGBoost算法中,通过梯度提升优化树模型。令树模型的输出为:■,其中,x为输入向量,wq为对应叶节点q的分数。K个树模型集成的输出为:
利用梯度对损失函数进行二阶近似,求出最优权重w,则目标函数的最优值为:
3 AUC
观测者操作特性曲线(receiver operating characteristic curve,ROC),常用于说明二分类模型在不同阈值条件下的分类能力。ROC曲线的横坐标为假阳性率FPR,表示在所有正例中,模型错误的把正例预测成负例的数量占负例总数的比例。纵坐标为真阳性率TPR,其含义为在所有负例中,模型的预测输出值为负例的数量占正例总数的比例。ROC曲线下方区域的面积AUC用于区分模型的效果,AUC值越大说明模型效果越好。当AUC小于0.5,即ROC曲线在左下方时,表示分类器总是分成错误的类。AUC接近0.5时,说明分类器为随机猜测。通常情况是AUC大于0.5的情况,且AUC值越大,说明模型区分正负例的能力越强,模型预测效果越好。AUC值即使在数据不平衡的情况下,也能同时反应分类模型区分正例和负例的能力。
4 实验验证
为验证模型对产品质量预测的有效性,使用kaggle竞赛“Bosch Production Line Performance”数据集作为训练和验证数据。该数据集包含1183747个产品样本数据,每个样本包含968个数值特征,2140个类别特征,1156个时间特征,由于类别特征缺失率高于99%,时间特征数据信息密度低,在本次实验中只选用数值特征进行进一步处理和模型训练。所有数值特征均经过匿名处理,特征名称形式为L0_S20_F45,其中L1表示生产线,S20表示测量值所属的站别,F45为测量编号。在PCA_NearMiss算法中PCA降维维度设为100,NearMiss近邻数设为3。并具有表示产品质量的标签,其中0表示合格,1表示不合格。不合格产品样本占样本总数的0.58%,即正例样本与负例样本的比例为172:1,数据极端不平衡,经过降采样后,正例与负例样本的比例为4:1。此外,数据集中数据缺失率达到78.5%,在本次实验中,对缺失数据进行零值填充。
5 实验结果
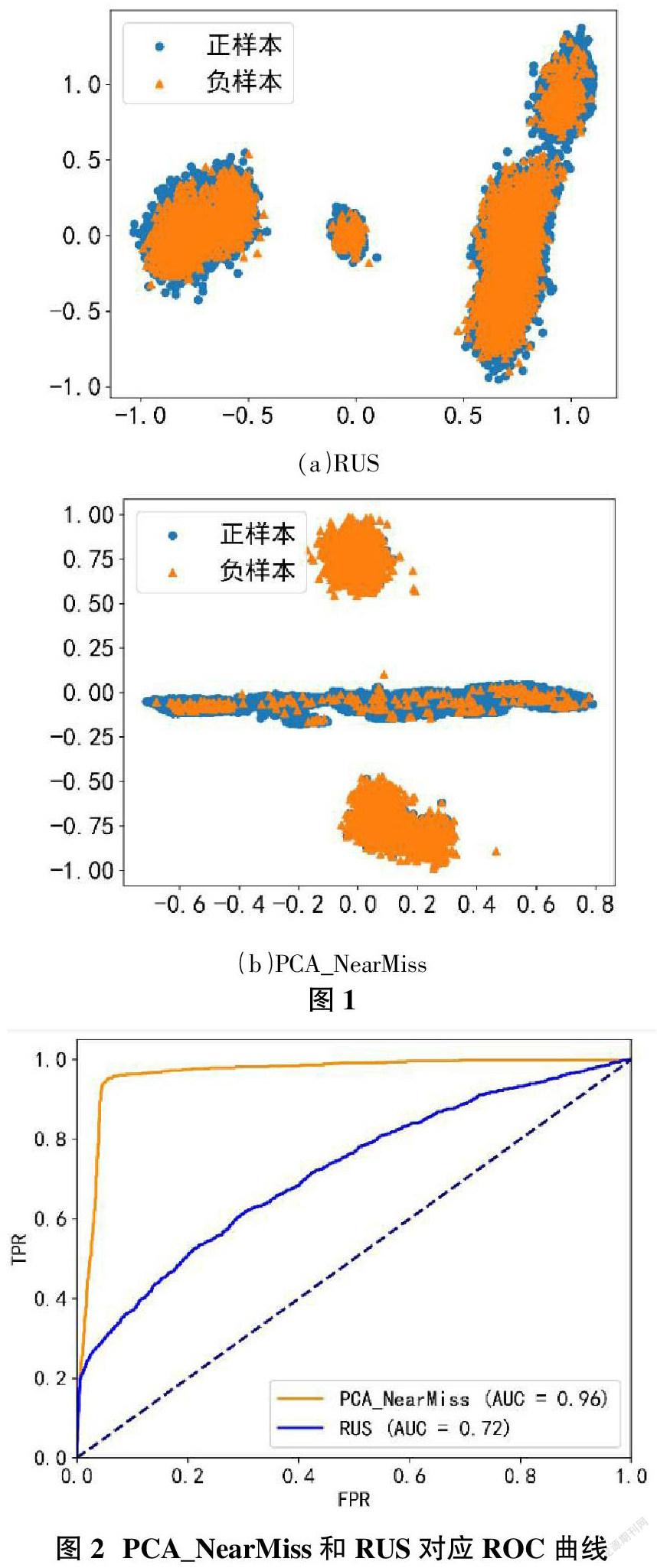
为验证PCA_NearMiss降采样算法的有效性,对随机降采样(RUS)和PCA_NearMiss降采样后的样本进行PCA降维可视化,可視化结果如图1所示。从图1中可以看出,经PCA_NearMiss降采样后的正负例样本较随机降采样更具有区分性。
分别将随机降采样和PCA_NearMiss降采样后的样本,划分成训练集和测试集,训练集占降采样后样本的80%,测试集占20%,最终训练集样本数为26749,训练集样本数为6688。并使用相同参数的XGBoost模型作为分类器,XGBoost模型,学习率设为0.1,每棵树随机采样的比例为0.8,最大深度为3,最小叶子节点权重和为1。实验结果如图2所示。
从图2中可以看出,PCA_NearMiss对应的ROC曲线位于随机降采样的左上方且靠拢(0,1)点,AUC值为0.96,大于随机降采样的AUC值0.72,说明PCA_NearMiss降采样的效果比随机降采样效果更好。
6 结论
针对产品生产数据高维、高不平衡的特性,采用PCA_NearMiss降采样算法,能从大量的产品数据中选择出具有代表性的样本,并有效平衡正负例数据。通过降采样后的数据对XGBoost算法进行训练,可实现对产品质量的有效预测。
参考文献:
[1]贺正楚,潘红玉.德国“工业4.0”与“中国制造2025”[J].长沙理工大学学报(社会科学版),2015,30(3):103-110.
[2]刘振宇,李伟光,林鑫,等.基于PCA和希尔伯特谱的柔性薄壁轴承故障诊断研究[J].机床与液压,2019(16).
[3]Chen T, He T, Benesty M, et al. Xgboost: extreme gradient boosting[J]. R package version 0.4-2, 2015: 1-4.
