
大数据多租户技术应用研究
2021-12-14 07:11:14贺恒松何重阳
网络安全技术与应用 2021年11期
◆贺恒松 何重阳
大数据多租户技术应用研究
◆贺恒松 何重阳
(电科云(北京)科技有限公司 北京 210013)
随着全国数字化进程加快,很多组织机构都具备了海量的数据,都需要使用大数据平台来进行数据处理。然而,在同一个组织机构内部,大数据资源如果不进行限制,所有用户都可以访问到,可能会存在资源使用不合理与数据泄露等问题。为了解决这个痛点,本文通过对大数据多租户技术进行了深入研究,结合业务具体需求场景研究与设计了多租户技术落地方案,最后对多租户技术应用进行了总结与展望。
多租户;大数据;Hadoop
1 引言
随着大数据的普及,越来越多的组织机构将自己的海量数据的存储与运算放在Hadoop集群上。然而由于同公司不同项目或者部门之间对计算和存储的需求不同,原有提供一套底层Hadoop集群给用户使用已经不能满足用户的需求,主要存在以下几个问题:
(1)多个用户之间公用一套底层存储资源,彼此之间数据没有进行隔离,会导致存储的数据泄露;
(2)不同用户编写的不同计算任务公用底层全量计算资源,会导致计算资源要求高的任务无法获得足够资源等;
(3)对IO,CPU,内存等的要求不同的任务无法分配到具备相应特长的节点上运行。
正是上述问题,在没有对Hadoop集群资源进行精细化管理时,很容易出现数据与集群资源混乱无序的状态。
2 相关概念
在介绍多租户相关研究与设计前,首先需要对下述概念进行介绍:
(1)存储资源:分布式存储文件系统(Hadoop Distributed File System,HDFS)中的一个或者多个目录;
(2)计算资源:资源调度协调系统(Yet Another Resource Negotiator,YARN)中队列;
(3)队列:计算任务进行资源分配的最小单位。
3 多租户技术研究
目前,多租户的实现有多种方案,下面对相关技术方案进行分析。
基于容器的多租户大数据平台构建方案,通过容器化技术封装大数据组件成描述性文件,再通过云计算,云安全提供多租户安全的隔离与共享。该方案主要利用了云计算的租户隔离手段,来实现对所运行组件的隔离,但是由于其每个大数据组件所具有的数据是彼此隔离的,容易产生数据孤岛,在需要对各个租户数据进行全量计算时,难以适用。
基于Hadoop的多租户大数据平台方案主要是基于Hadoop生态的HDFS、YARN等的功能来对资源进行隔离。HDFS可以通过目录的访问权限,来对各个租户相关的用户访问权限进行隔离限制。YARN中的计算队列也可以通过相关配置来对其进行更细粒度的访问控制以达到不同租户的访问隔离。
4 多租户技术方案
由于可能需要对各租户数据进行更高层次的计算,本论文主要采用基于Hadoop生态的多租户实现方案。
但是由于不同版本的Hadoop在租户相关的功能上是有区别的。Hadoop2.7虽然也支持多租户能力,但是其对YARN中队列动态控制能力还有些欠缺。其无法做到对动态资源的删除,每次要彻底删除动态资源都需要对组件进行重启。其次由于系统需要对国产飞腾服务器(ARM架构)支持。所以选择了Hadoop3.3.0版本。
考虑到需要支持队列可选择不同特性的节点分区与需要支持多级租户,采用了容量调度器来实现对动态资源的管控。容量调度器的节点标签功能(NodeLabel)可以对计算节点进行打标签分类,然后通过对动态资源配置不同标签的节点资源池,来实现对动态资源的节点分区选择。
具体的租户与资源访问权限的配置,主要有两方面,一方面为存储资源权限,主要是基于POSIX模型,在创建完目录后对目录的访问权限进行设置;另一方面是动态计算资源的访问权限,主要是通过设置动计算态资源的acl_submit_applications与acl_administer_queue两个参数来控制。
本项目对Hadoop相关组件的整体管控方案如图1所示,通过平台层下发指令或者HTTP请求来实现对底层组件的控制。
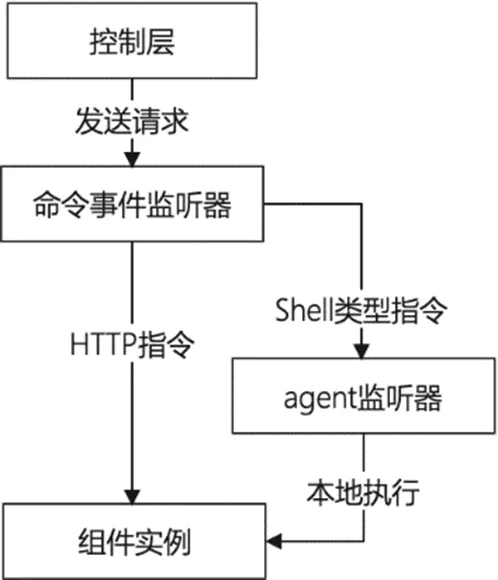
图1 整体管控方案
5 总结
本文所提出的大数据租户实现方案,相对于基于容器的租户方案,不存在集群化的数据隔离。对于使用者来说,避免了存储数据的泄露,对计算资源进行了更细化的管控,提高了机器的使用效率与计算任务的执行效率,在实际使用中有着不错的反馈。
[1]林伟伟,张子龙,刘凯,等. 一种基于容器的多租户大数据平台构建方法[P].CN106569895A,2017.
[2]张子龙. 面向大数据的多租户关键技术研究[D]. 华南理工大学.
[3]何美斌,胡精英. 基于Hadoop的大数据平台多租户管理策略研究[J]. 电脑编程技巧与维护,2017(23):58-60.
猜你喜欢
科学技术创新(2021年18期)2021-06-23 07:53:06
小学生学习指导(低年级)(2020年4期)2020-06-02 09:09:26
软件(2020年3期)2020-04-20 00:58:44
微型电脑应用(2019年10期)2019-10-23 11:23:04
军营文化天地(2018年2期)2018-12-15 17:39:08
计算机测量与控制(2017年12期)2018-01-05 01:10:55
计算机技术与发展(2017年12期)2017-12-20 09:59:12
产品可靠性报告(2017年7期)2017-09-05 09:49:12
计算机与数字工程(2016年11期)2016-12-13 06:51:06
特别文摘(2014年17期)2014-09-18 01:31:21
