
基于深度学习的人脸属性识别方法综述
2021-12-14 11:33赖心瑜王大寒朱顺痣
计算机研究与发展 2021年12期
赖心瑜 陈 思 严 严 王大寒 朱顺痣
1(厦门理工学院计算机与信息工程学院 福建厦门 361024) 2(福建省模式识别与图像理解重点实验室(厦门理工学院) 福建厦门 361024) 3(厦门大学信息学院 福建厦门 361005)

Fig.1 Classification framework of DFAR methods
近年来,随着人工智能技术的发展,人脸属性识别逐渐成为计算机视觉与模式识别领域的一个热门研究方向.人脸属性通常指描述人类可理解的面部图像的抽象语义,比如表情、性别、年龄、种族、脸型等属性.人脸属性识别(或人脸属性分类)是利用计算机来分析和判断人脸图像的各类属性信息.人脸属性识别搭建了人类可理解的视觉描述和各类计算机视觉任务所需的抽象语义之间的一个桥梁.近几年,人脸属性识别在视频监控[1-2]、社交媒体[3]、人脸验证[4-5]、人机交互[6]等场景中得到了广泛的应用.
在目前众多人脸属性识别研究中,有些方法仅针对单一的人脸属性进行识别[7-11],我们称之为基于单标记学习的人脸属性识别方法,即一个样本只对应一个类别标记,如人脸表情识别[7-8]、年龄识别[9-10]、性别识别[11]等.而基于多标记学习的人脸属性识别方法[12-15]诣在学习一个样本到多个类别标记集合的映射.在基于多标记学习的人脸属性识别中,用(xi,yi)表示一个样本的输入、输出对,其中xi是第i个输入样本,yi是输出的包含M个属性类别的向量(yi1,yi2,…,yiM)T.yij代表第i个样本的第j个属性的类别(比如,对于二分类的情况,yij=1表示该属性存在,yij=0表示该属性不存在).因此,基于多标记学习的人脸属性识别方法可以同时识别出一张人脸对应的多个属性.
近年来,深度学习技术[16-18]在计算机视觉、自然语言识别、语言处理等任务上取得了卓越的进步.传统的人脸属性识别方法都是通过人工设计特征并提取,而相比于人工设计的特征,深度学习技术可以自动地从大量数据中学习到特征,从而弥补人工特征的不足.因此,受益于深度学习技术在特征提取方面强大的学习能力,深度学习技术也广泛地被应用在人脸属性识别方向.基于深度学习的人脸属性识别(deep learning based facial attribute recognition, DFAR)方法[12-15]还可将特征提取和属性分类结合在一起,实现端到端学习.相比于基于单标记学习的DFAR方法[8],基于多标记学习的DFAR方法[12-15]可以学习到更多的人脸属性信息,从而对人脸的描述更加全面.因此,本文将对后者进行详细综述.
按照模型构建方式的不同,DFAR方法可分为基于部分的DFAR方法[19-34]和基于整体的DFAR方法[35-71].基于部分的DFAR方法在输入的人脸图像中首先根据属性定位所在的面部区域,然后提取所在区域的特征进行识别.基于整体的DFAR方法直接考虑整张人脸图像,对整张图像进行特征提取再分类,不需要额外的属性区域定位步骤.图1给出了本文对DFAR方法的分类方式.此外,为了总结近几年DFAR方法的进展,图2给出了各时间点的代表性算法,后文将详细介绍各算法.

Fig.2 Representative DFAR methods in recent years
虽然人脸属性识别的研究热度在不断提升,但人脸属性识别领域还缺乏专门进行分析的综述性文章.与现有的仅针对单一的特定属性进行识别的综述[72-74]不同,本文主要关注能够同时对表情、性别、年龄等多种人脸属性进行识别的方法.再者,与现有的基于深度学习的人脸属性分析综述[75]不同,本文对基于部分的DFAR方法和基于整体的DFAR方法采用了不同的分类方式:1)由于部分区域的定位方式是影响基于部分的DFAR方法性能的关键因素,因此本文将对基于部分的DFAR方法按是否采用规则区域定位进行概述与分析;2)本文将对基于整体的DFAR方法分别从基于单任务学习、基于多任务学习的角度进行分类与对比,并对基于多任务学习的DFAR方法进一步根据是否采用属性分组进行细分与讨论,从而有助于学者对该研究方向有更全面的认识与理解.本文的详细分类方式如图1所示.
本文首先介绍人脸属性识别的总体流程;其次,分别对基于部分的DFAR方法和基于整体的DFAR方法进行综述与分析,并且阐述不同方法的主要原理、发展与改进、优缺点等;然后,介绍人脸属性识别的数据集、评价指标,并分析和对比各类方法的实验性能;最后,对人脸属性识别方法进行总结与展望.
1 人脸属性识别方法的流程
人脸属性识别方法的一般流程大致包括4个基本步骤,如图3所示,分别是人脸检测、人脸对齐、特征提取以及属性分类.首先输入人脸图像,其次对人脸图像进行预处理操作,如人脸检测和人脸对齐等,然后对人脸图像中的属性信息进行特征提取,再进行属性分类,最后获得识别结果.

Fig.3 General flow diagram of the facial attribute recognition method
1.1 人脸图像预处理
人脸检测与人脸对齐一般作为属性识别的数据预处理操作.人脸检测的目的是判断所给的图像中是否含有人脸,如果是则准确地定位到人脸的位置.例如,Li等人[76]提出一种级联卷积神经网络结构的快速人脸检测方法.Zhang等人[77]提出基于多任务的3阶段级联卷积神经网络的人脸检测方法.
针对输入的人脸图像的尺寸大小不一、角度也不一的问题,人脸对齐主要是根据人脸关键点坐标调整人脸的角度使不同的人脸对齐(比如将脸部置于图像中点,以及旋转脸部至相同的水平线且缩放到统一的尺寸).典型算法如Cootes等人[78]提出的基于点分布模型的主观形状模型(active shape models, ASM)算法,其将物体的几何形状通过若干个关键点坐标串联成一个向量表示,然后对人脸进行归一化和对齐操作.之后,Cootes等人[79]对ASM算法进行改进,提出主动外观模型(active appearance models, AAM)算法,在采用形状约束的基础上加入了整个面部区域的纹理特征.对于3D人脸对齐技术,典型算法如Zhu等人[80]提出的3D深度人脸对齐算法,利用基于回归的级联卷积神经网络从大姿态变化的图像中抽取有用的信息.此外,人脸检测和人脸对齐这2个预处理步骤也可以合为1个步骤完成,如Sun等人[81]提出深度卷积神经网络(deep convolutional neural network, DCNN)算法,首次将卷积神经网络用于人脸关键点检测及人脸对齐.也有一些人脸属性识别方法提出省略人脸关键点检测或人脸对齐的预处理步骤[28],或将预处理步骤合并到整个属性识别框架中一同完成[14].
1.2 特征提取
传统的人脸属性识别方法[82-83]的特征提取思路是从人脸区域中使用人工设计的方式来提取人脸特征表示.例如,局部二进制模式算子[84](local binary patterns, LBP)提取局部纹理特征;梯度直方图特征算子[85](histogram of oriented gradient, HOG)提取人脸外观和形状特征边缘结构.但是由于传统的人脸属性识别方法的特征描述能力有限,因此很难适应复杂场景下的人脸属性识别任务.随着深度学习技术在图像特征提取能力上取得了举目共睹的成绩,以卷积神经网络为代表的深度学习技术很大程度上优于传统的特征提取方法.因此,与传统的特征提取方法[84-85]相比,基于深度学习的特征提取方法[13-15]能够自动地从海量数据中学习到更有效的特征以辅助属性分类.
1.3 属性分类
属性分类是将人脸属性识别问题视为二值分类任务,即根据每个属性的类别判断该属性存在或不存在.传统的人脸属性分类方法在使用人工设计特征后,将提取的图像特征输入到属性分类器进行训练和识别.在深度学习技术发展的早期阶段,也是使用神经网络提取特征后再输入到传统分类器(比如支持向量机等)中进行训练与分类[19-20].而随着深度学习技术的发展,新近人脸属性分类方法[35-36]已经可以实现端到端地进行人脸属性识别任务,其将特征提取与属性分类2个步骤合在一起训练,使得属性识别任务变得更加简单.比如Sharma等人[36]提出的Slim-CNN网络可以实现从图像输入到识别结果输出的端到端人脸属性识别.
2 基于部分的DFAR方法
基于部分的DFAR方法首先定位某个属性所在的面部区域位置,然后在该区域内特征提取,再进行进一步的属性分类,其一般可以分为属性定位、特征提取和属性分类3个部分,如图4所示.进一步地,基于部分的DFAR方法根据不同的定位方式又可以分为基于规则区域定位的识别方法[19-30]和基于不规则区域定位的识别方法[31-34].

Fig.4 Overview of part-based DFAR methods
2.1 基于规则区域定位的识别方法
目前,基于规则区域定位的DFAR方法首先采用规则的边界框(一般为矩形框)定位出人脸区域,再进行属性的分类识别,如图5所示.
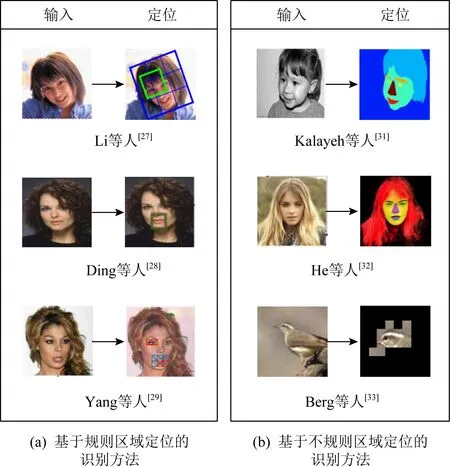
Fig.5 Representative DFAR methods based on regular area localization and based on irregular area localization
早期的方法通常使用卷积神经网(convolutional neural network, CNN)进行特征提取,然后使用支持向量机(support vector machine, SVM)进行分类.例如,Zhang等人[19]提出PANDA方法,其首先使用Poselets算法对图像进行局部区域的定位,并将这些标准化为规则的区域合并到深度卷积神经网络中提取特征,然后将提取的特征进行融合,最后使用SVM作为分类器进行属性预测.Gkioxari等人[20]同样是利用Poselets部件检测器,用以检测不同姿势下捕捉的规则图形的人体部件区域,对输入的多尺度图像提取特征得到多尺度部件概率图,然后将部件及整个图像用线性SVM分类器进行分类.Liu等人[21]提出的LNet+ANet方法构建了2个卷积网络,其中LNet网络用矩形框根据属性过滤器的响应图来定位出人脸的具体位置,ANet网络用于提取人脸属性信息,最后将ANet网络所提取的特征输入到SVM中进行属性预测.该方法采用的是人脸属性识别算法中最常见的交叉熵损失函数(cross-entropy loss).假设第i个样本xi共有M个属性标记,该样本总的损失为所有属性损失之和,具体表示为
(1-yij)log(1-P(yij|xi))],
(1)
其中:
(2)
式(2)表示样本xi的第j个属性存在的概率.f(xi)表示第i个样本的第j个属性的输出值.
针对遮挡和脸部区域误检等问题,不少学者提出通过定位属性最相关的脸部区域来提高属性识别的鲁棒性.例如Luo等人[22]提出用判别决策树对面部区域的关系进行建模,对每个属性学习一棵二元判别决策树以发现判别区域,每个节点对应一个矩形区域,并且每个节点都包含一个用于定位面部区域的检测器和一个用于属性识别的分类器,再将学习到的决策树转换为和积树(sum-product tree)以充分利用被划分区域之间的相互依赖性,同时可以自动发现并排除错误的检测区域,从而提高属性识别的准确性.Kang等人[23]提出基于属性感知关联图(attribute-aware correlation map)和门控(gated)卷积神经网络的人脸属性识别方法.该方法利用属性感知相关图,根据像素位置和属性标签之间的相关性进行属性定位,并将这些相关图调整至固定大小的矩形框后输入到门控卷积神经网络中,进而从相关图中提取特征.Li等人[24]提出的深度多任务学习同时考虑属性相关区域检测和属性识别这2个任务,其中第1个子网是用于特征提取的全卷积网络,第2个子网是利用感兴趣区域池化(ROI pooling)以得到属性相关的矩形区域的网络,最后将这2个任务的输出连接成1个向量得出属性识别结果.Ge等人[25]提出基于属性间单向推理相关的人脸属性识别方法,根据属性标签将人脸区域分割为多个矩形区域,并利用多个卷积层对该区域进行特征提取,从而计算出所有属性的单向推理相关性来设计属性识别的分类模型.Singh等人[26]提出对属性进行定位与排序的端到端深度卷积网络.该网络将定位模块和排序模块相结合,通过基于弱监督学习的成对比较自动发现属性的相关空间范围,能够更准确地定位属性对应的规则矩形图像块.定位模块是利用变换参数θ以定位出与该属性对应的最相关区域,这里θ=[s,tx,ty],s表示图像均衡缩放程度,tx和ty分别表示图像水平和垂直平移距离.具体变换为
(3)
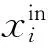
为了动态地选择不同的面部区域进行人脸属性识别,不少学者提出不需要进行人脸对齐预训练的属性识别方法.例如,Li等人[27]提出一种不需要进行人脸关键点检测和人脸对齐的属性识别方法.该方法由一个全局定位网络和一个局部定位网络组成,首先全局定位网络获取脸部的全局信息并且从局部定位网络中捕捉到最具有鉴别力的属性对应的矩形框位置,再将全局信息和最具判别力的区域融合表示,实现利用全局变换优化属性识别的最终目标,最后通过自适应定位局部位置进行属性识别.全局定位网络是通过全局变换函数来学习图像的位置,假设全局变换的参数集表示为Tg,则全局变换函数具体表示为
(4)
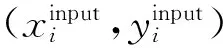
类似地,Ding等人[28]也提出了一种不需要进行人脸对齐的深度级联网络.与文献[27]不同的是,该方法为每个属性检测定位一个矩形关注区域,并由分类网络自动选择面部区域信息对属性进行最终的识别.再者,为了减少网络参数以生成更简洁的模型,该方法设计一个hint损失,将预先训练得到的定位网络作为教师网,而后面属性识别部分作为学生网,以教师网的输出作为监督信号去训练学生网.具体hint损失函数为
(5)
其中,T和S分别表示教师网和学生网的网络函数,k表示教师网的迁移监督层,l表示学生网的添加监督层.xi为输入的第i个样本,w为待学习学生网的权值.该方法再联合学生网属性识别的交叉熵损失LCE, 则样本xi的最终损失函数为
LS=λ1Lhint+λ2LCE,
(6)
其中,λ1和λ2分别为2种损失的权值.
除了在一般场景下的人脸属性识别方法外,还有其他在特定场景下的人脸属性识别方法.例如在人机交互场景下,Yang等人[29]提出采用梯度加权激活映射来指导深度网络对属性识别中的重要区域进行定位,即用预训练好的分类器DNN激活映射以定位出十个预训练的矩形面部区域,并且结合一种交互式的分类方法,将分类器的注意力集中在用户手动指定的面部区域进行识别.此外,在非实验室场景下,葛宏孔等人[30]提出将人脸图像分割为多个规则矩形的局部区域作为输入,再采用迁移学习从多个不相邻卷积层中提取特征以构建一个属性识别网络.
因此,基于规则区域定位的识别方法一般采用固定形状的边界框对人脸区域进行定位,这种规则区域的定位方式可以将图像中所感兴趣的目标尽可能地包含在内,并不断地调整区域边缘以得到更为准确的目标位置.而不同属性的常用人脸规则区域也不相同,大致可以分为2类:1)可以定位到某个局部区域的属性[22-23,29],如戴眼镜(eyeglasses)、眼袋(bags_under_eyes)对应到眼部区域,张嘴(mouth_slightly_open)、大嘴唇(big_lips)、微笑(smiling)对应到嘴部区域,胡渣(5 o’clock shadow)、山羊胡子(goatee)对应到下巴区域,发际线后移(receding_hairline)、秃头(bald)对应到头部周围区域等.2)无法直接利用局部区域进行定位的属性[21,24-25,28,30],该类属性需要框出整张人脸的全局区域或利用其他属性进行辅助判断,如性别男性(male)的判断则通常需要关注整张人脸的特征,或通过关注涂口红(wearing_lipstick)、胡子(mustache)等属性来辅助判断;年轻(young)的判断也需要关注人脸的全局区域或关注秃头(bald)、灰发(gray_hair)等属性来辅助判断;属性浓妆(heavy_makeup)也需要关注人脸的全局区域或关注涂口红(wearing_lipstick)、玫瑰色脸颊(rosy_cheeks)等属性来辅助判断.然而,基于规则区域定位的识别方法在人脸属性所占据的人脸区域较小或在形状上不规则时,将某一属性对应区域利用规则边界框(例如矩形框)进行定位可能会导致非属性区域的引入,从而降低识别的性能.
2.2 基于不规则区域定位的识别方法
针对规则区域定位方法的弊端,学者们提出了若干基于不规则区域定位方法.该类方法一般采用语义分割[31]、生成对抗网络(generative adversarial network, GAN)[32]、多网格连通区域定位[33]等技术对属性进行不规则区域定位,如图5(b)所示.
Kalayeh等人[31]提出利用语义分割来改进人脸属性识别,利用语义分割技术将人脸分割为7个类,且根据不同的语义信息分割为不规则的区域,其结合深层语义信息建立人脸属性分割网络,并利用分割网络所学到的定位信息将识别注意力关注在属性对应的定位区域中.不同于直接从图像上定位出属性所在位置,He等人[32]利用生成对抗网络(GAN)生成含有面部位置信息和纹理信息的人脸抽象图像来间接地达到辅助定位的目的.与pix2pixHD[86]方法输入分割图像生成逼真的自然图像相反,He等人[32]利用GAN生成抽象的人脸图像,并将每个图像用11个类进行注释(如背景、面部皮肤、左眉、右眉、左眼、右眼、鼻子、上唇、内嘴、下唇和头发).该方式可以消除原图中无用的背景信息,同时保留面部位置信息和面部纹理信息,最后将GAN生成图像的位置信息和纹理信息与原图相结合进行最终的属性识别.
Berg等人[33]提出采用多网格连通区域的技术来对图像进行定位,其定位方式是先将图像分割成若干个网格,用训练好的SVM给每个网格一个权值并对权值阈值化,然后在所有网格中找到大于阈值的最大连通区域(即由若干个网格组成的不规则区域),进而用最大连通区域的特征来训练分类器.此外,Zhong等人[34]首先使用一个定位网络进行属性区域定位,接着利用现有的人脸识别网络架构进行训练,再进行人脸属性的识别.该文通过实验验证得出,不同深度的卷积层对属性的识别性能是不同的,并且认为网络的中层(mid-level)特征包含更多空间信息,其更适合于描述人脸属性.
2.3 小 结
基于部分的DFAR方法可分为基于规则区域定位的识别方法和基于不规则区域定位的识别方法,并且这2类都认为某一特定属性仅仅需要关注与之对应的面部区域,而其他面部区域无法提供有用的信息,甚至会干扰该属性的识别,因此仅利用该属性相关联的区域进行识别来提高准确率.但其缺点是需要先进行属性定位再识别,这对属性定位技术的准确性有一定的要求.在复杂场景下人脸外观剧烈变化时,对人脸属性所关联的面部区域的定位变得困难,一旦定位错误往往就会导致识别性能不佳.
3 基于整体的DFAR方法
基于整体的DFAR方法[35-71]则不是对属性存在的面部区域先进行定位再特征提取,而是对输入的整张人脸图像进行特征提取.基于文献[46],基于整体的DFAR方法可以根据不同的模型训练方式分为基于单任务学习的方法、基于多任务学习的方法.如图6(a)所示,每个属性对应一个任务,并且每个任务对应一个独立的训练模型的方法称之为基于单任务学习的属性识别方法[35-41].该类方法的各个任务之间的模型空间是相互独立的.相比较于单任务学习方法,基于多任务学习的属性识别方法[56-71]则是将每个属性或是将每个属性分组分别看成一个任务,并且浅层网络进行特征共享,而高层网络独立学习各个任务的特征,其更注重每个任务之间的联系和差异,如图6(b)所示.多任务学习方法的多个任务之间的模型空间是共享的,使得模型在训练过程中,多个任务可以相互促进,从而提升模型性能.
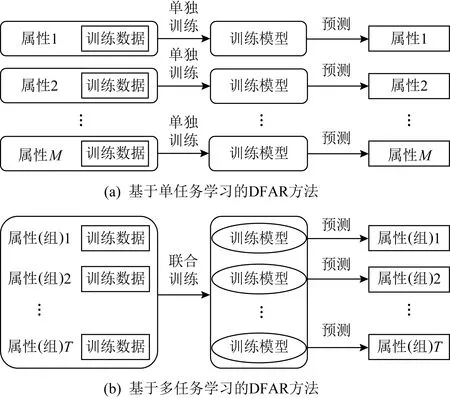
Fig.6 Overview of holistic DFAR methods
3.1 基于单任务学习的识别方法
对基于单任务学习的人脸属性识别方法的研究,学者通常有2个不同的出发点,分别是网络结构的设计和图像信息的理解.在网络结构的设计方面,将传统的卷积神经网络进行改进,使其适用于人脸属性识别任务是目前研究的常用思路.Zhong等人[35]认为卷积神经网络的中层特征表示可以实现较好的人脸属性识别,该方法也设计从人脸区域中学习更具有判别性的中层特征,使得识别性能更加准确.Sharma等人[36]将研究重点放在卷积神经网络轻量级设计上.考虑到传统的卷积神经网络虽应用广泛但存储负担和计算成本较大,该方法利用深度可分离卷积和点卷积设计轻量级的卷积神经网络并应用在属性识别上,从而提高计算效率并减少模型参数.Speth等人[37]则提出基于孪生网络的多标记验证框架来识别错误标记的样本,其将验证为错误标记的样本标记为噪声.除此之外,将新的卷积神经网络应用到属性识别中也是一个重要的研究方向.Nian等人[38]首次在人脸属性识别领域提出利用图卷积神经网络来构建属性之间的关系,同时提出解耦矩阵(decoupling matrix)将一般的面部特征通过元素乘积转换为特定的属性表示用以更好地区分特征.
在图像信息的理解方面,学者们更注重通过图像上下文信息[39]、数据增强[40]或者聚类[41]等方式来挖掘图像本身的重要信息,进而辅助网络训练.例如,Wang等人[39]提出利用视频和上下文信息来学习人脸属性表示.该方法认为对于种族、头发颜色等属性与人们所在的地理位置有关,而对于穿戴的服饰如帽子、墨镜等属性则与天气条件有关,于是利用位置和天气的数据作为弱标记来构建丰富的面部属性表示以帮助识别.Günther等人[40]通过对图像进行缩放、旋转、移动及模糊等操作进行数据增强,从而对人脸图像信息进行进一步挖掘来提升无对齐的人脸属性识别网络模型的性能.此外,Abate等人[41]通过对深度特征进行聚类等方式来挖掘人脸图像的潜在信息,其首先预训练网络模型,然后将网络中提取到的深度特征进行聚类,经过聚类后,从每个簇中收集到更为紧凑的特征,这些特征在一定程度上可以避免因图像拍摄场景不同而导致的识别错误,从而提高模型的判别能力.
3.2 基于多任务学习的识别方法
多任务学习方法在相关任务间共享表示信息,并挖掘不同任务之间隐藏的共用数据特征,其设计的模型对识别任务的泛化性能往往更好.如图6(b)所示,基于多任务学习的DFAR方法可将每个单一属性当做一个学习任务,也可将每个属性组当作一个学习任务.本文将人脸属性识别中把每个单一属性当作一个学习任务,然后级联学习所有任务的方法称之为基于单属性的多任务学习方法[12,14-15,42-53,56-61].另一方面,由于人脸属性的个数较多,很多学者则根据属性的相关性对属性进行分组,每组属性对应一个学习任务,然后级联学习各个任务,我们将这种方法称为基于属性分组的多任务学习方法[13,62-71].因此,本节将进一步从基于单属性的多任务学习方法、基于属性分组的多任务学习方法这2个方面分别进行综述.
3.2.1 基于单属性的多任务学习方法
基于单属性的多任务学习方法将每个单一的属性当做一个学习任务,而这些学习任务之间都具有相关性,通过挖掘属性之间的关系,即可以学习到更多的鉴别特征.为了提高基于单属性的多任务学习方法的性能,目前不少学者通过侧重考虑属性间的相关性[42-46]、数据分布[12,15,48-49]、多层特征信息[50-51]、神经结构搜索[52-53]或其他辅助任务[14,56-61]等方面提出了相关研究方法.
近年来,若干基于多任务学习的DFAR方法通过学习属性之间的相关性来提高识别的性能.如Rudd等人[42]最早在属性识别中提出多任务学习框架,充分利用属性的潜在关联性,引入新型混合目标网络,优化加权混合目标的平方误差损失,将多个任务目标及损失进行自适应加权.设M为属性个数,N为输入图像的个数,则域适应多任务(domain-adapted multi-task, DAM)损失函数为
(7)
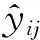
在数据分布方面,为了解决数据集中出现的类别不平衡问题,Huang等人[48]提出一种多任务深度学习网络来约束类内距离和类间距离,从而处理数据中的类不平衡问题.同时,为了学习更具有判别性的特征,该方法提出引入簇之间的软k近邻聚类度量(softk-nearest-cluster metric)的损失函数,在处理不平衡数据集的性能上优于采用标准的Softmax损失和Triplet损失的方法.Hand等人[12]提出了一种用于多标记平衡的选择性学习方法,根据每个标记的期望分布自适应地平衡每批数据.通过这种方法将数据集中不平衡的数据加以修正,从而训练出更为鲁棒的预测模型.另一方面,为了更好地利用大量未标记数据来训练网络,Zhuang等人[15]提出的基于多标记深度迁移网络的人脸属性识别方法可以解决未标记属性的学习问题.该方法首先训练一个人脸检测网络(FNet),然后利用有标记属性来训练一个多标记学习网络(MNet),最后训练一个迁移网络(TNet)对未标记属性数据进行学习.此外,毛龙彪等人[49]提出基于生成式对抗网络和自监督学习的人脸属性识别方法,该方法通过自监督学习的方式为大量未标记数据构造监督信息来学习通用特征,最后用少量有标签数据微调属性识别网络.
为了结合多层卷积神经网络的特征信息,Duan等人[50]提出了多任务张量相关神经网络.除了在浅层共享特征,该方法在深层分支特异性学习时也设计从其他分支网络的同一层中提取特征,从而可以从其他分支的网络中得到有用的信息增强自身的识别,同时也在最后1层卷积中添加1个张量相关分析算法将特征投射到高度相关的空间中,最后根据相关矩阵进行属性识别.除此之外,Liu等人[51]提出嵌入式多任务学习的特征融合分析模型.该方法也是为了充分利用深度卷积神经网络中各个卷积层的特征信息,将卷积网络中前几层的特征图进行特征融合.
传统基于多任务学习的DFAR方法[50-51]通常是根据特定任务的先验知识或属性间的相关性来人工设计一种网络架构用于识别属性,而随着神经结构搜索(neural architecture search, NAS)技术的发展,目前学者已将NAS技术引入人脸属性识别.例如,Huang等人[52]提出将贪心神经结构搜索(greedy neural architecture search, GNAS)方法与属性识别任务相结合,该方法将自动地搜索适合于属性学习的最优树形结构,从而克服传统人工设计网络架构在面对各种复杂场景的实际应用中缺乏灵活性的问题.Saxen等人[53]提出用2种简单而有效的轻量级的卷积神经网络MobileNetV2[54]和Nasnet Mobile[55]对人脸属性进行识别,其中MobileNetV2是一种用于移动设备的CNN架构;Nasnet是由神经结构搜索组成的CNN架构.该方法在精度和速度方面都表现良好,同时也能在移动设备上使用.
此外,还有部分研究[14,56-61]是利用辅助任务来促进目标任务的学习,通过挖掘辅助任务和目标任务之间的内在关联性来提高目标任务的性能.若干代表性的辅助任务如表1所示.例如,Tan等人[47]提出基于空间转换器网络(spatial transformer network)的端到端多任务人脸属性识别方法,在人脸属性识别中引入空间转换器网络来学习变换参数,并用于对齐人脸图像.该方法的辅助任务为人脸对齐任务,目标任务为人脸属性识别.不同于在图像上做数据增强的研究,Bhattarai等人[56]提出在标签空间上做扩充,在多任务学习的基础上提出增加一种利用分类标记的语义表示来生成连续标记的方法.该方法的辅助任务为利用word2vec生成新的人脸属性分类标签,即增强标签(augmented labels),而目标任务为人脸属性识别,同时学习这2个任务的参数以实现目标任务的最佳性能.类似地,还可以利用其他人脸分析任务,例如人脸关键点检测、人脸识别等来辅助提高基于单属性的人脸属性识别的性能.例如,Zhuang等人[14]提出级联人脸检测、人脸关键点检测来辅助人脸属性识别,在统一框架下同时训练3个相关的人脸分析任务,而在人脸属性识别中通过输入单属性来进行多任务学习.He等人[57]提出级联人脸检测和人脸属性识别的深度网络,共享浅层特征可以缓解人脸大规模变化所带来的影响.Wang等人[58]提出用于联合人脸识别和人脸属性识别的深度神经网络,并利用人脸识别的身份信息为属性识别增加一个约束(即同一个人的部分属性是不会改变的,如脸型、性别等).因此,在识别相同身份的样本属性时利用多数投票机制来调整识别的结果.Taherkhani等人[59]提出基于人脸属性识别的深度人脸识别网络.该网络利用特征融合的方法识别人脸属性信息去提高人脸识别性能.为了更有效地得到网络框架中的共享信息,Ehrlich等人[60]提出基于受限玻尔兹曼机(restricted Boltzmann machine,RBM)的学习模型,将利用图像主成分分析PCA和人脸关键点检测得到的2组数据输入到受限玻尔兹曼机来识别属性.Chang等人[61]提出将人脸属性识别、人脸动作单元检测、情感价值和响应度估计级联到一个深度网络中.并且在卷积的中间层共享3个不同人脸分析任务的通用特征以辅助识别人脸属性任务.

Table 1 AuxiliaryTasks for Single Attribute Based Multi-task Learning Methods
3.2.2 基于属性分组的多任务学习方法
基于多任务学习的DFAR方法大多设计为基于卷积神经网络的分支结构,在浅层的卷积层共享特征,在深层的卷积层则开始分支对每个任务分别学习.基于属性分组的多任务学习方法根据属性之间的相关性对属性进行分组,并将每个属性组对应一个学习任务.若干代表性的属性分组形式如表2所示.
许多学者主要根据属性的空间位置相关性对属性进行分组.例如,Hand等人[62]提出利用属性之间隐式和显式的关系对每个属性采用多任务学习进行识别,并将属性主要按空间位置相关性进行分组与训练.Yip等人[63]提出基于分组的多任务卷积网络的属性识别方法,将属性分为8个组,其中包括1个全局的属性组和7个与属性空间信息相关的局部属性组.Aly等人[64]提出一种类似注意力机制的方法(即模糊掉感兴趣区域之外的图像)来提取特征.该方法也同样考虑属性的空间位置相关性,将属性分为头部、眼睛、鼻子、脸颊、嘴巴、肩部和全局共7个属性组.Cao等人[65]基于相同身份的人脸具有相似的属性信息提出一种考虑人脸身份来引导属性识别的网络 FR-ANet.该网络根据属性所在的空间位置分为6组,所有属性共享浅层特征,而深层特征除了用于属性组之间的学习之外,还考虑了人脸身份信息进行人脸身份识别.Wang等人[66]提出在多任务卷积神经网络中引入IdentityNet网络、AgeNet网络和RaceNet网络分别利用人脸身份、年龄和种族特征来构建面部特征信息,然后将融合的特征再进行多任务的属性识别,同时将属性按空间位置相关性划分为9个组,每组对应一个任务,并设计一个在线批处理损失与交叉熵损失联合优化网络.He等人[67]提出基于加权损失惩罚和自适应阈值学习的多任务人脸属性识别方法,将属性按五官位置分为6组,在训练阶段设计1个加权损失来优化预测结果,使得预测结果尽可能接近真实结果,同时在测试阶段用自适应阈值算法自适应地预测每个属性.在考虑属性的空间位置相关性的同时,Han等人[68]提出属性之间由于不同的数据类型、规模以及语义信息还存在一定的异构性,因此通过同时考虑属性的相关性和异构性,又可将属性分为全局与局部、可排序与不可排序等属性组来进行多任务学习.例如需要考虑整张人脸特征的男性、鹅蛋脸、浓妆等属性为全局属性,而只用考虑人脸部分区域特征的属性,如胡子、厚嘴唇等则为局部属性.另一方面,头发长度、年龄这种可按数值排列的属性为可排序属性,而性别、双下巴等不能按数值排列的属性则为不可排序属性.因为可排序性组(group ordered)具有可排序性,即可以按数值排列,所以其可以采用Euclidean损失:

Table 2 Related Information of Several Attribute Grouping Based Multi-task Learning Methods
(8)
此外,还可以根据属性的外观特征相关性对属性进行分组,Gao等人[69]提出在多任务卷积神经网络上通过分组和不同深度的分支来实现人脸属性识别.考虑属性的外观特征将属性分为颜色相关属性组、穿戴打扮属性组和表观特征属性组,并且每组利用不同深度的网络实现以达到较好的识别性能.除了这些分组方法外,还有依据属性的主客观性进行分组的方法,例如,Mao等人[70]提出了基于深度多任务多标记的卷积神经网络的人脸属性识别DMM-CNN方法.该方法以人脸关键点检测辅助属性识别,为属性识别提供了位置信息.其次还将属性分为客观属性组和主观属性组进行识别,分别设计了2种不同的网络结构来提取2组属性的特征.损失函数的定义则是通过设计不同任务的均方误差损失.人脸关键点检测的损失函数定义为
(9)
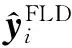
(10)
(11)
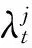
不同于根据先验知识人工地对属性进行分组的方法,Fanhe等人[71]认为各属性间的相关程度不同,因此可以采用聚类技术自动地对属性进行分组,将某一属性所有标记视为一个向量,计算属性之间的相关系数矩阵C(M,M),具体表示为
C(M,M)=(ci,j),i,j=1,2,…,M,
(12)
(13)
其中,Ai表示第i个属性所有标签的1维矩阵,σ(Ai)表示其标准差,Cov(Ai,Aj)表示第i个属性与第j个属性之间的协方差,于是计算得到属性之间的相关系数矩阵.根据相关系数矩阵再采用谱聚类的方式形成一个相关性强的属性组和一个相关性弱的属性组来进行多任务学习.
在基于属性分组的多任务方法中,如何设计有效的多任务分支结构也是一个值得研究的问题,如最优节点的选择,即从网络的哪一层开始分支才能达到最佳的识别效果.此外,神经网络的深层特征具有很强的语义信息,而分支结构的深层网络之间却相互独立,没有充分利用到深层网络的高级语义信息.基于这些问题,Cao等人[13]提出的PS-MCNN方法是基于局部共享单元的多任务学习框架,其不采用分支结构,而是独立设计一个由局部共享单元组成的共享网络以学习其余属性组之间的共享信息.设第i个样本xi的第t个属性组的损失函数定义为
(14)
其中,Kt表示第t个属性组的属性个数,yik表示第i个样本的第k个属性.由于共有4个属性组,则所有N个样本的损失函数定义为
(15)
此外,为了考虑身份信息还提出加入一个局部几何约束损失:
(16)
其中,feati和feats分别表示第i个样本和第s个样本的属性特征,wis表示损失权重,即
(17)
基于损失函数LLC,具有相同身份的样本在属性空间上会更靠近对方.因此PS-MCNN方法的联合损失函数为
LOBJ=LA+λLLC,
(18)
其中,λ是LLC的权重参数.
3.3 小 结
基于整体的DFAR方法可分为基于单任务学习的识别方法和基于多任务学习的识别方法.基于整体的DFAR方法认为不同的属性之间是相互联系的,因此对于每个属性在整个面部区域都应该得到同等考虑,并且不额外进行某属性所在的面部区域位置的定位.基于整体的DFAR方法更考虑属性与属性之间的相关性,利用属性之间的关系可以促进彼此的识别准确率.然而,该类方法的缺点是考虑过多的区域也会对属性的识别造成干扰,因此如何设计属性识别网络来有效地利用不同属性之间的关系是值得研究的问题.
4 数据集与性能对比
本节首先对人脸属性识别主要的数据集及算法性能评价指标进行介绍;然后对近年来代表性的DFAR算法的实验性能进行对比与分析.
4.1 数据集介绍
随着基于深度学习的人脸属性识别研究领域的不断发展,越来越多的人脸属性数据集被用于测试各种DFAR算法的性能.其中人脸属性识别算法中最为常见且使用最为广泛的数据集为CelebA[21]和LFWA[21]数据集.除此之外,还有LFW[87],PubFig[4],YouTube Faces[88]等.目前公开的主要10种人脸属性数据集及其细节情况如表3所示.
在LFW(labeled faces in the wild)数据集[87]是由美国马萨诸塞大学阿默斯特分校计算机视觉实验室整理完成的数据库,主要是从互联网上搜集的图像.LFW数据集一共有5 749个人,其中含有13 233张人脸图像,每张图像都有标识出对应的人的名字,当中有1 680个人包含2张以上的人脸图像.每张图像的像素为250×250.该数据集一开始由Kumar等人[87]收集了65个属性,后扩展为73个.
Table 3 RelatedInformation of Ten Main Public Datasets for Facial Attribute Recognition
PubFig(public figures face)数据集[4]是哥伦比亚大学采集的公众人物人脸数据集,主要从互联网上收集.PubFig数据集是一个真实大型的人脸数据集,其中包含有200人的58 797张图像,平均每个人的图像较多.该数据集主要用于非限制场景下的人脸识别.与大多数现有人脸数据集不同,这些图像是在完全不受控制的情况下拍摄的.因此该数据集的姿态、表情、照明等因素都有较大的变化.
YouTube Faces数据集[88]是从YouTube视频网站上收集人脸图像的,是一个用于研究视频中无约束人脸识别问题的人脸视频数据库.YouTube faces数据集包含3 425个视频,其中有1 595个不同的对象.每个主题平均有2.15个视频,最短的剪辑时间为48帧,最长的剪辑是6 070帧,平均长度是181.3帧.数据集在视频中每隔4帧的图像上标注了40个属性.
Berkeley Human Attributes数据集[89]是从PASCAL VOC数据集和H3D数据集的训练集和验证集中收集的.该数据集包含了8 033张人脸图像,其中包含2 003张图像的训练集,2 010张图像的验证集和4 022张人脸图像的测试集.该数据集还采用5个独立的注释器标记了9个属性标记,其图像是以人的全身为中心的图像,含有大量的变化(如姿势、遮挡等).
Attribute 25K数据集[19]的图像出自Facebook,其中包含24 963名对象,并将其分为训练集、测试集和验证集.Attribute 25K数据集包含的图像在遮挡、姿势、照明等方面有很大的变化.且不是每个属性都被标记在每个图像中.
CelebA(celeb-faces attributes)数据集[21]是由香港中文大学汤晓鸥教授实验室公布的大型人脸属性数据集,其图像由互联网收集,是一个规模较大的人脸属性数据库.其中包括有10 177个名人身份202 599张面部图像,每张图像标注了5个关键点以及40个属性.CelebA数据集中的图像覆盖了大的姿势变化和杂乱背景等复杂场景,有超过800万个属性标记,是一个有大量属性标注的数据集.同时可用作人脸属性识别,人脸检测和人脸关键点定位等人脸分析任务的训练集和测试集.
LFWA数据集[21]是通过标记LFW数据集,由专业的标记公司注释了40个主要面部属性和5个关键点的拓展数据集.该数据集含有5 749个人,共有13 233张人脸图像,总共超过50万的属性标记.
Chalearn FotW数据集[90]是通过从互联网上收集可公开获取的图像创建的,包含2个数据集:一个用于访问分类,另一个用于性别和微笑分类.访问分类数据集包含5 651张图像的训练集,2 826张图像的验证集和4 086张人脸图像的测试集.每张人脸图像都有7个二进制属性的注释.性别和微笑数据集包含6 171张图像的训练集,3 086张图像的验证集和8 505张人脸图像的测试集.
LFW+数据集[68]扩展了LFW数据集,用于研究无约束人脸图像的属性估计(比如年龄、性别和种族等),注释了3个主要的面部属性.因为LFW数据集里的孩子以及青少年数量(0~20岁年龄组)很少(在5 749个人中只有209个孩子以及青少年).所以使用谷歌图像搜索服务,用“孩子”和“青少年”等关键词,搜索大约5 000张图像,再采用人脸检测器和手动删除了不符合的对象.LFW+数据集包含15 699张人脸图像,约8 000名对象.
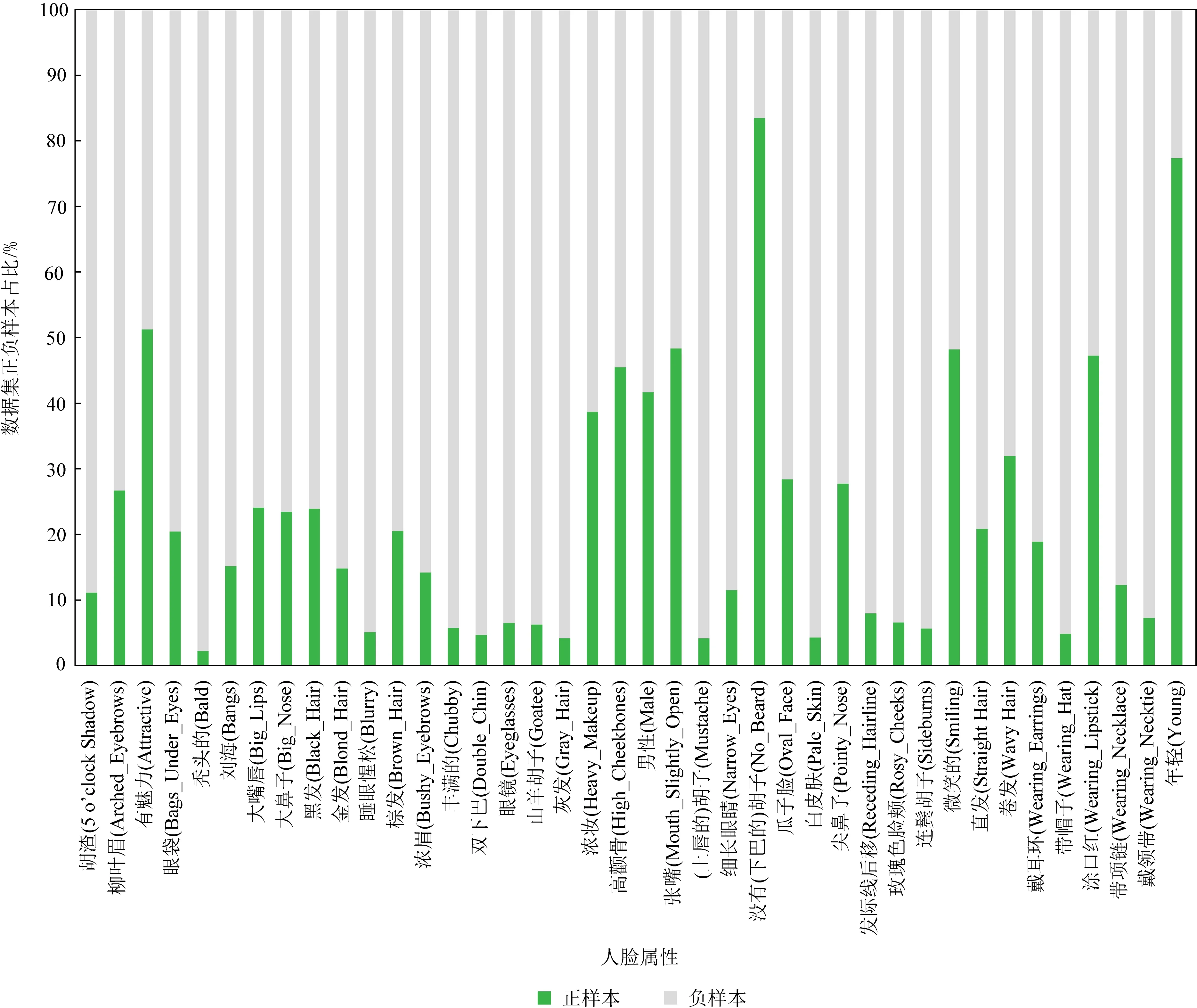
Fig.7 Data distribution of the CelebA dataset
UMD-AED(University of Maryland attribute evaluation dataset)数据集[12]是由马里兰大学提出,来自以40个属性作为搜索项的图像搜索UMD-AED 数据集由2 800个人脸图像组成,其中共标记了40个属性.UMD-AED数据集含有大量的变化(例如,年龄变化、光照变化、姿势变化等),且每个属性均有正负样本各50个,但是不是每个属性都被除了以上的公开数据集之外,还有一些早期数据集,标记在每张图像中.
例如,由Martinez等人[91]在U.A.B的计算机视觉中心(CVC)创建的AR人脸数据集.该数据集仅包含6个属性,126名对象的4 000多张彩色图像.此外,还有哥伦比亚大学脸部跟踪Facetracer数据集[92]包含10个属性,总共15 000多张图像.
目前,对于现有的人脸属性数据集还存在不少问题,例如数据集中有很多图像主要是正面的或者是摆好姿势的名人所组成,由大量这样的图像所组成的数据集的泛化性能不高,即由其训练得到的模型在识别另一个非名人或低质量的数据集时的性能表现不佳.其次,数据集里还存在部分类别不平衡问题,即某一类别的正样本过多或某一类别的正样本过少.图7统计了最为常用的大规模人脸属性数据集CelebA中的数据分布.从图7中可见,不同属性正负样本分布严重不均,如有属性年轻(young)的正样本占总样本的比例约为77.36%,而有属性胡渣(5 o’clock shadow)的正样本则很少,其占比约为11.11%,这会导致训练得到的模型在测试时对属性胡渣的识别性能不佳.此外,在现有的人脸属性识别数据集中,还存在一些错误标记[37],例如一些有鹅蛋脸(oval_face)属性的图像被分类为没有鹅蛋脸属性标记的类别里.因此,除了考虑扩大数据集和改善网络模型结构之外,也需要针对这些问题进行改进的人脸属性识别方法.
4.2 评估指标
为了比较各个算法的性能,人脸属性识别主要有3个性能指标,分别是准确率(accuracy,ACC)、错误率(error rate,ER)以及均值平均精度(mean average precision,mAP).其中准确率为
(19)
其中,真阳性(true positive,TP)表示该属性真实值为1(即存在该属性)且模型判断预测值也为1的样本数.真阴性(true negative,TN)表示该属性真实值为0(即不存在该属性)且模型判断预测值也为0的样本数.假阳性(false positive,FP)表示该属性真实值为0且模型判断预测值为1的样本数,假阴性(false negative,FN)表示该属性真实值为1且模型判断预测值为0的样本数.因此准确率表示的是模型预测样本中所有被正确分类的样本数与样本总数的比值.此外,平均准确率ACCAvg是对所有属性的ACC求平均值.错误率则恰恰相反,其表示的是该属性下模型预测中分类错误的样本数与样本总数的比值,即
ER=1-ACC.
(20)
同理,平均错误率ERAvg是对所有属性的ER求平均值.而均值平均精度为
(21)
其中,M表示属性类别总数,APj为第j个属性的平均精确度,其中精确率为
(22)
召回率为
(23)
由此可以计算出APj及mAP的值,因此mAP表示的是各属性的平均精度之和与属性总数的比值.
此外,针对正负样本数量不平衡问题,可用平衡准确率指标(balanced accuracy metric,BAM)[31]来计算样本的准确率:
(24)
4.3 性能对比
本节对新近具有代表性的DFAR方法的实验性能进行对比与分析,主要评估了近几年发表在国际权威期刊或者顶级会议上的比较有代表性的10余种DFAR方法,并讨论了新近人脸属性识别方法的特点.
表4和表5分别对基于部分的DFAR方法和基于整体的DFAR方法的发表情况、基础网络、损失函数、实验性能进行总结与对比.从表4和表5可以看出,大多数DFAR方法使用的基础网络为VGGNet[93],ResNet50[94]和自定义的CNN网络.在损失函数方面,DFAR方法最常使用的损失函数是交叉熵损失.由于网络模型结构设计存在差异,故不同DFAR方法也侧重使用不同的损失函数,如Euclidean损失[27, 68]、均方误差损失[70],并均取得较好的识别性能.由于大多数方法是在CelebA和LFWA上进行验证,因此表4和表5主要展示了在这2个数据集上的实验结果.总体看来,基于部分的DFAR方法自2014到2020年以来,在CelebA数据集上准确率从87%上升到91.81%;在LFWA数据集上准确率从84%上升到86.13%.而基于整体的DFAR方法自2016年到2020年,在CelebA数据集上准确率从85.05%上升到93%;在LFWA数据集上准确率从73.03%上升到87.22%.

Table 4 Performance Comparisons of State-of-the-art Part-based DFAR Methods
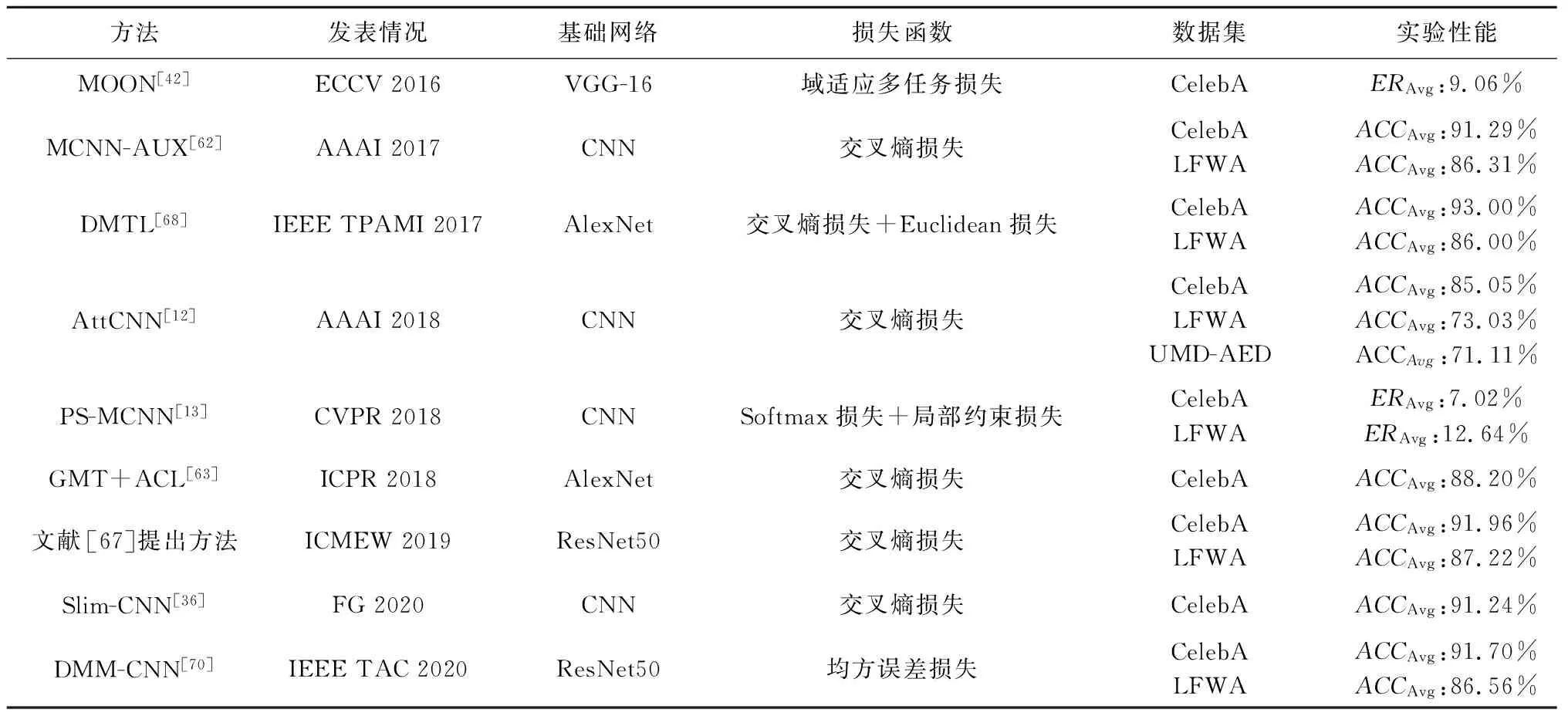
Table 5 Performance Comparisons of State-of-the-art Holistic DFAR Methods
为了更直观地对比基于部分与基于整体的DFAR方法的性能,表6分别展示了2016—2020年DFAR方法在CelebA数据集上每年识别率最高的5种算法及其准确率结果.表6的结果表明,相比较于基于部分的DFAR方法,近2年基于整体的DFAR方法的研究工作相对较多,并且取得了较好的性能,其主要原因可以从2个方面分析:1)因为基于部分的DFAR方法过于依赖定位信息,仅从定位网络中所定位的位置中提取相关特征,一旦定位不准确则会导致后续属性识别不准确[75];2)因为基于部分的DFAR方法舍弃了有用的信息,例如当属性所对应的区域出现遮挡现象时,基于部分的DFAR方法由于只关注定位区域的特征则无法从遮挡区域中获取有用的特征信息[22],而基于整体的DFAR方法由于考虑整张脸的特征以及属性之间的相关性则可以从未被遮挡的区域推断出遮挡区域的属性特征.

Table 6 Comparisons of the DFAR Methods with Top Five Accuracy on CelebA in the Recent Years
表5中除了Slim-CNN[36]是基于单任务学习的DFAR方法,其余都是基于多任务学习的方法.由表5可见,基于整体的多任务学习的DFAR方法是准确率较高的模型.为此,图8进一步对比了2016—2020年基于单属性与基于属性分组的多任务学习DFAR方法在CelebA数据集上的性能.
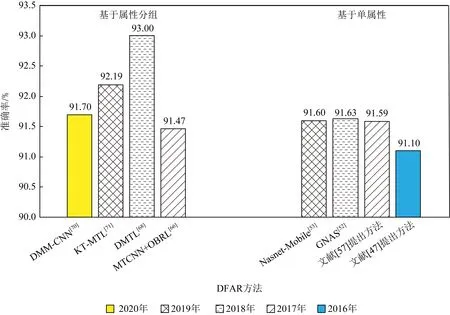
Fig.8 Comparisons of the highest accuracy of the DFAR methods based on single attribute and based on attribute grouping on CelebA from 2016 to 2020
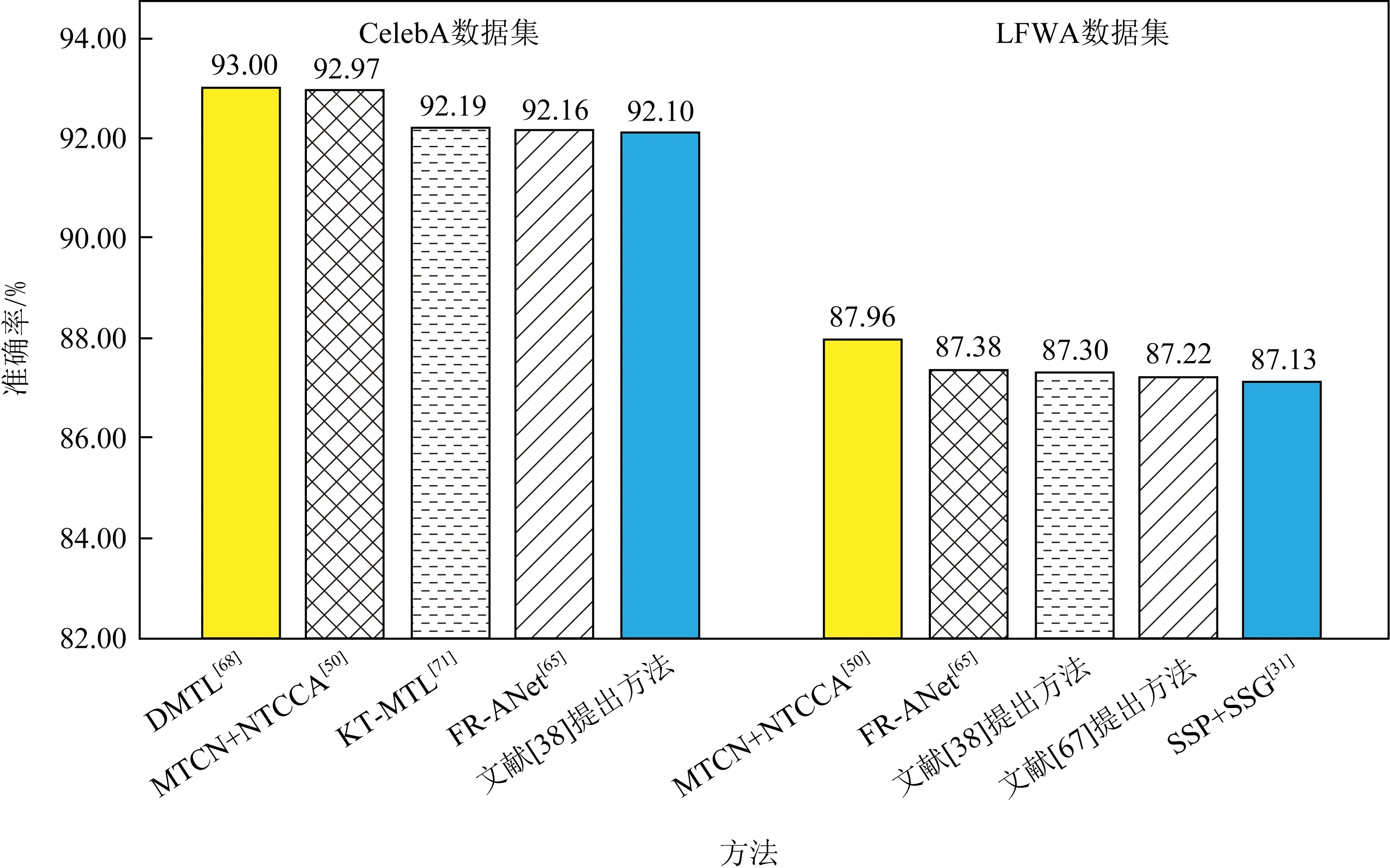
Fig.9 Comparisons of the DFAR methods with top five accuracy on LFWA and CelebA in the recent five years
由于2016年未检索到基于属性分组的多任务学习的DFAR方法,2020年未检索到基于单属性的多任务学习的DFAR方法,因此,图8分别列出从2016—2019年中每年识别率最高的基于单属性的多任务学习DFAR方法以及从2017—2020年每年识别率最高的基于属性分组的多任务学习DFAR方法的性能.如图8所示,只有2017年的基于属性分组的MTCNN+OBRL方法[66]的准确率低于2017—2019年识别率最高的基于单属性的方法.而2018—2020年识别率最高的基于属性分组的方法均比2016—2020年基于单属性的方法的准确率高.2016—2020年,与识别率最高的基于单属性的方法GNAS[52]相比,识别率最高的基于属性分组的方法DMTL[68]的准确率高了1.37%.结果表明,基于属性分组学习的多任务学习方法比其他方法更具有优势.
此外,不同方法与不同数据集之间的契合度也存在着较大差异.图9分别列出了在CelebA数据集和LFWA数据集上识别率最高的前5种算法名称及准确率结果.对于CelebA数据集,DMTL[68]方法的识别准确率最高(达93%),而MTCN+NTCCA[50]方法只有92.97%.但对于LFWA数据集,则是MTCN+NTCCA[50]方法的识别准确率最高(87.96%),而DMTL[68]方法只有86%.由此可见,不同算法在不同数据集的表现存在差异,因此需要对不同数据集进行测试才能更好地评价算法的性能.值得注意的是,CelebA数据集与LFWA数据集中训练样本和测试样本的个数比值是有着明显不同的,具体比值分别为162 770/19 960(接近8∶1)和6 263/6 970(接近1∶1).由图9可见,在训练集与测试集的个数比值较大的CelebA数据集上,所有对比算法的准确率都相对较高,这表明模型训练相对较好.这是因为模型在训练阶段中所学习到的知识更多,可以使用的辅助信息也更有效.
5 总结与展望
近年来,随着深度学习技术的不断发展,学者对DFAR方法的研究已取得了一定的进展.本文分别从是否采用规则区域定位、多任务学习的角度,对基于部分与基于整体的DFAR方法进行详细的概述与对比.虽然目前DFAR方法的性能有所提高,但DFAR方法在复杂场景、数据分布不平衡、数据噪声、少样本等情况下仍面临着许多挑战和亟待解决的问题.因此,DFAR方法的未来研究方向可以从6个方面进行考虑:
1)复杂场景下的人脸属性识别.目前的人脸属性识别方法在面对光线良好的室内摆拍,且是近距离拍摄的高质量人脸图像时,可以取得较好的识别性能.但是在面对复杂场景,如视野广阔的室外场景、人数较多的商场、光照不佳以及部分遮挡等的场景下,现有的人脸属性识别方法容易受到各种环境因素的影响,导致难以准确地识别出属性类别.文献[32]利用GAN生成抽象人脸图像来消除原图中无用的背景信息,其为解决复杂场景下的人脸属性识别提供了一种思路.因此,如何处理好复杂场景下的人脸属性识别任务也将是未来研究的主要方向之一.
2)数据分布不平衡下的人脸属性识别.当前人脸属性的数据集存在数据分布不平衡的问题,主要体现在2个方面:①针对单个数据集而言的不同属性类别之间的不平衡,即某一类的样本过多而某一类的样本过少,这就会导致对少量样本的类别识别性能不佳.②不同训练数据集与测试数据集之间的偏差,即领域差异,这会使模型的泛化能力降低,从而导致虽然在训练数据集中识别性能良好但在测试数据集中性能表现不佳.因此,可以从损失函数优化[67]、自适应阈值调整[49]、网络结构设计[12]上进一步提高数据分布不平衡时的人脸属性的识别率,这也将是未来的研究的方向之一.
3)数据噪声下的人脸属性识别.基于深度学习的研究方法是一种数据驱动的方法,往往需要通过大量的数据来学习得到一个分类或回归模型,所以训练得到的模型性能的好坏很大程度上依赖于训练数据的数量和质量.而当前人脸属性的数据集存在着部分数据标记错误的问题,例如有些非圆脸的图像被标记为圆脸,有些没有刘海的图像被标记为有刘海.再者,数据集中采集的人脸图像质量也参差不齐.因为拍摄人脸的距离不同、分辨率也不同,所以部分图像含有噪声.文献[95-96]研究了如何去除噪声数据来建立一个纯净的人脸数据集,还有若干人脸识别方面的研究工作[97-98]旨在学习噪声鲁棒的人脸表示,这些方法均为解决数据噪声下的人脸属性识别提供了思路.通过构建更高质量的标准数据库或提出自动去除错误标记样本的技术,也将更好地提高属性识别方法的鲁棒性.
4)少样本下的人脸属性识别.基于深度学习的人脸属性识别技术往往需要通过学习大量有属性标记的样本才能训练出一个优秀的模型,而标记大量的样本十分耗时耗力.少样本学习(few-shot learning)可以使得模型在学习了一定已知类别的数据后,对于新的类别只需要少量的样本就能快速学习.而元学习(meta learning)[99]作为少样本学习的主要技术之一,也被称为学习如何学习,即利用以往的知识经验来指导新任务的学习,使得机器具有学会学习的能力.目前还很少基于元学习或少样本学习的人脸属性识别方法,但这也是未来一个有潜力的研究方向.
5)设计轻量级的属性识别网络.DFAR方法需要在一个网络模型中同时训练识别众多人脸属性,其网络模型较为复杂.此外,若在模型设计中考虑多任务学习,则中间共享的模型参数会更多,加上人脸数据集的数据量十分庞大,导致训练起来比较耗费时间.文献[36]利用深度可分离卷积和点卷积设计了轻量级卷积神经网络并用于人脸属性识别,但这方面的研究还为之较少.因此,设计更鲁棒且高效的轻量级网络模型对于人脸属性识别的实际应用具有重要意义,也将是未来值得研究的方向.
6)结合基于部分与基于整体的DFAR方法.由于基于部分的DFAR方法更注重每个属性所处的脸部位置,从而通过提取属性所对应的局部特征来进行识别.而基于整体的DFAR方法则以整张人脸图像作为输入,主要更关注属性之间的关系.Mahbub等人[100]提出既要注重每个属性所处的脸部位置,又要考虑整张人脸的特征.该方法还假设每个属性均由多个人脸区域预测,根据预训练模型自动分配不同的人脸区域来选择所对应识别的属性,并在网络最后融合多个区域的预测结果.但这种方法计算复杂,且容易受到初始模型准确率的影响.因此,如何将局部属性特征与属性之间的相互关系有机结合,均衡考虑这2类方法的优缺点,对于实现更优性能的属性识别将是一个有潜力的发展方向.
猜你喜欢
应用心理学(2022年5期)2022-11-05
农业工程学报(2022年12期)2022-09-09
计算技术与自动化(2022年1期)2022-04-15
北京大学学报(自然科学版)(2022年1期)2022-02-21
北京航空航天大学学报(2021年9期)2021-11-02
北京航空航天大学学报(2021年9期)2021-11-02
少儿美术·书法版(2021年9期)2021-10-20
奥秘(2021年5期)2021-06-15
现代信息科技(2021年21期)2021-05-07
中国新技术新产品(2016年23期)2016-12-26
