
3D物体检测的异构方法
2021-12-14 11:32姚治成贾玉祥包云岗
计算机研究与发展 2021年12期
吕 卓 姚治成 贾玉祥 包云岗
1(中国科学院计算技术研究所 北京 100190) 2(计算机体系结构国家重点实验室(中国科学院计算技术研究所) 北京 100190) 3(数学工程与先进计算国家重点实验室 郑州 450001) 4(郑州大学信息工程学院 郑州 450001) 5(中国科学院大学 北京 100049)
3D物体检测是计算机视觉的一个重要研究方向,其主要任务是预测物体的尺寸、世界坐标系下的坐标以及朝向等信息,从而提供物体所处的3D空间.3D视觉识别对于机器人感知外界环境、理解周围场景和完成特定任务十分重要[1].3D物体检测在自动驾驶、机器人和目标追踪等场景中都有所应用.在自动驾驶领域,3D物体检测获取到的相关信息可以帮助汽车完成路径规划、避免碰撞等任务,自动驾驶需要3D物体检测来保证驾驶安全性,因此,如何更有效地得到精确的3D物体检测结果成为近些年来研究的热点.
当前的3D物体检测方法基本都难以同时满足高精度、快速度和低成本这3个要求[2].如图1所示,当前方法在速度-精度图中的分布基本都在曲线附近,精度较高的方法速度较慢,速度较快的方法精度较低,而理想的3D物体检测需要同时兼顾速度和精度.当前的3D物体检测方法大多以RGB图像、RGB-D数据、雷达点云等作为网络的输入,采用端到端的深度神经网络进行相关计算,最终输出预测的物体3D边框.然而直接使用端到端深度神经网络来解决3D物体检测这种复杂的任务,存在着网络结构复杂、计算量大、实时性差等问题.
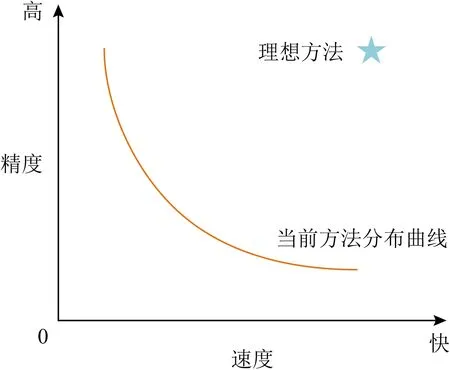
Fig.1 3D object detection method status diagram
本文提出了一种基于异构的3D物体检测方法,该方法以深度学习与传统算法相结合的形式,来进行3D物体检测.该方法的主要思路是将整个3D物体检测过程划分为多阶段:在预处理阶段,使用实例分割等深度学习的手段从RGB图片等原始数据中获取所需信息后,在后续的阶段中,使用聚类算法、图形处理算法等传统的方法来进行物体表面雷达点的获取、物体坐标及朝向的计算等.本文所提的方法适合用于检测汽车等可以在现实世界中获取到具体型号及对应尺寸的物体.
本文的主要贡献有4个方面:
1)从全新的角度来考虑3D物体检测问题,将传统算法应用到检测过程中,与深度学习方法相结合,实现了一种采用异构形式进行3D物体检测的方法;
2)提出的雷达点云筛选方法能够从巨大的雷达点云空间中,有效地筛选出目标物体的表面雷达点,并且去除其中存在的干扰点,在减少了雷达点计算量的同时,提升了计算精度;
3)提出的“最小点边距外接矩形算法”,以及“物体所在高度计算方法”,在汽车坐标的计算中显著提升了计算速度和精度;
4)经实验表明,本文方法与代表性的基于深度学习的3D物体检测方法相比,具有明显的优势.
1 相关工作
基于雷达点云的3D物体检测方法以激光雷达获取的点云数据作为输入,此外还有部分方法将RGB图像等数据作为额外的输入来帮助更好地进行检测,最终得到物体的3D边框,如图2所示:

Fig.2 3D bounding box of objects in radar point cloud
在最初的阶段,由于卷积神经网络(convolutional neural network, CNN)需要规则的输入,因此基于雷达点云的3D物体检测通常先将不规则的雷达点云转化为规则数据格式,再输入网络进行相关检测.例如Zhou等人[3]提出了一个端到端的将不规则点云转化为规则3D体素(voxel),进而检测3D物体的网络,该网络由特征提取层、3D中间卷积层和区域生成网络[4](region proposal network, RPN)组成,其中的特征提取层先将点云转化为规则的3D体素,并对其中点数量较多的体素进行随机采样以减少计算量和体素间差异,然后再由3D中间卷积层进行特征提取,最后由RPN进行分类检测和位置回归,得到检测结果.
除了将不规则点云转化为体素这种形式外,还有一些方法将点云转化为多视角图像几何,例如Chen等人[5]提出了一种基于多视角的3D物体检测方法,该方法分别将雷达点云投射到鸟瞰图上,通过鸟瞰图获取候选框并将其分别投影到鸟瞰图、前视图和RGB图像这3个视角上,之后对各个视角的特征进行联合,进而预测目标类别并回归出3D边框;Ku等人[6]则以RGB图像和雷达点云数据投射生成的鸟瞰图作为输入,通过特征提取得到2个相应的特征图,经融合后使用RPN生成无方向区域建议,并使用子网络生成有方向的3D边框,完成3D检测.将雷达点投射到鸟瞰图的3D物体检测方法可以避免物体遮挡所带来的问题,并且投射到鸟瞰图的物体能够保留原始尺寸,但是投射的过程中不可避免地会损失一部分点云信息,且不适应垂直方向有多个物体的场景.
随着能够直接处理点云数据的深度网络[7-8]的出现,一些3D物体检测方法基于原始雷达点云数据进行检测.例如Charles等人[9]提出了一种基于2D对象检测器和3D深度技术的3D物体检测方法,该方法首先使用2D检测器构建对象建议并据此定义3D视锥区域,然后基于这些视锥区域中的3D点云,使用PointNet[7]/PointNet++[8]实现3D实例分割和非模态3D边界框估计;Shi等人[10]提出了第1个仅使用原始点云作为输入的多阶段3D对象检测器,该检测器也利用了PointNet++,直接从原始点云中生成3D方案,再根据语义信息和局部特征等进行优化.
在基于规则数据的3D物体检测方法中,将不规则点云转化成规则格式需要额外的计算工作,并且存在不可避免的信息损失;而直接基于原始雷达点云进行3D物体检测,则需要处理巨大的点云空间,对目标的分类也较为复杂;而且无论是基于规则数据转换还是基于原始雷达点云的方法,基本上都使用了结构较为复杂的深度神经网络,从而可能导致计算时间较长,时间成本较高.
2 基于异构的3D物体检测方法
现有的3D物体检测大多采用端到端的深度神经网络,使用这种方式来解决3D物体检测这样复杂的问题,无疑会增加深度神经网络的复杂度,进而导致计算量增大、实时性不够等问题,而且不是3D物体检测中的所有步骤都适合使用深度学习的方法,为此本文提出了一种基于异构的3D物体检测方法,该方法的核心思想是将深度学习与传统算法相结合来进行检测,将整个检测流程划分为不同的子模块,分别承担不同的任务:在使用实例分割等深度学习手段从RGB图片等数据中获取信息后,根据深度学习获取的信息,采用传统算法,来进行点云筛选、坐标计算等任务.本文对该方法进行了实现,将其称为HA3D(a heterogeneous approach for 3D object detection).
HA3D由5个模块组成:数据预处理、雷达点云筛选、尺寸预测、坐标及朝向计算和结果展示,系统构成如图3所示.其中部分任务采用了非深度学习的方法来进行计算,例如雷达点云筛选使用了聚类的方法;坐标及朝向计算则使用了传统的计算机图形算法.以汽车的检测过程为例,HA3D的整个方法流程如图4所示,主要划分为4个步骤:
1)数据预处理.首先对原始数据进行处理,使用实例分割模型对RGB图像进行预测;读取雷达点云等原始数据并进行格式转换.
2)尺寸预测.对汽车这类物体构建尺寸数据库,通过简单分类神经网络获取物体种类,根据种类查询数据库获取物体准确尺寸.
3)雷达点云筛选.利用预处理得到的实例分割结果,结合聚类算法,从整个雷达点云空间中筛选出目标物体的表面雷达点,并去除其中干扰点,以用于下一步计算.
4)坐标及朝向计算.根据前面基础模块获得到的雷达点云、物体尺寸等数据,采用图形以及点云处理算法,计算物体的坐标以及朝向,得到最终的检测结果.
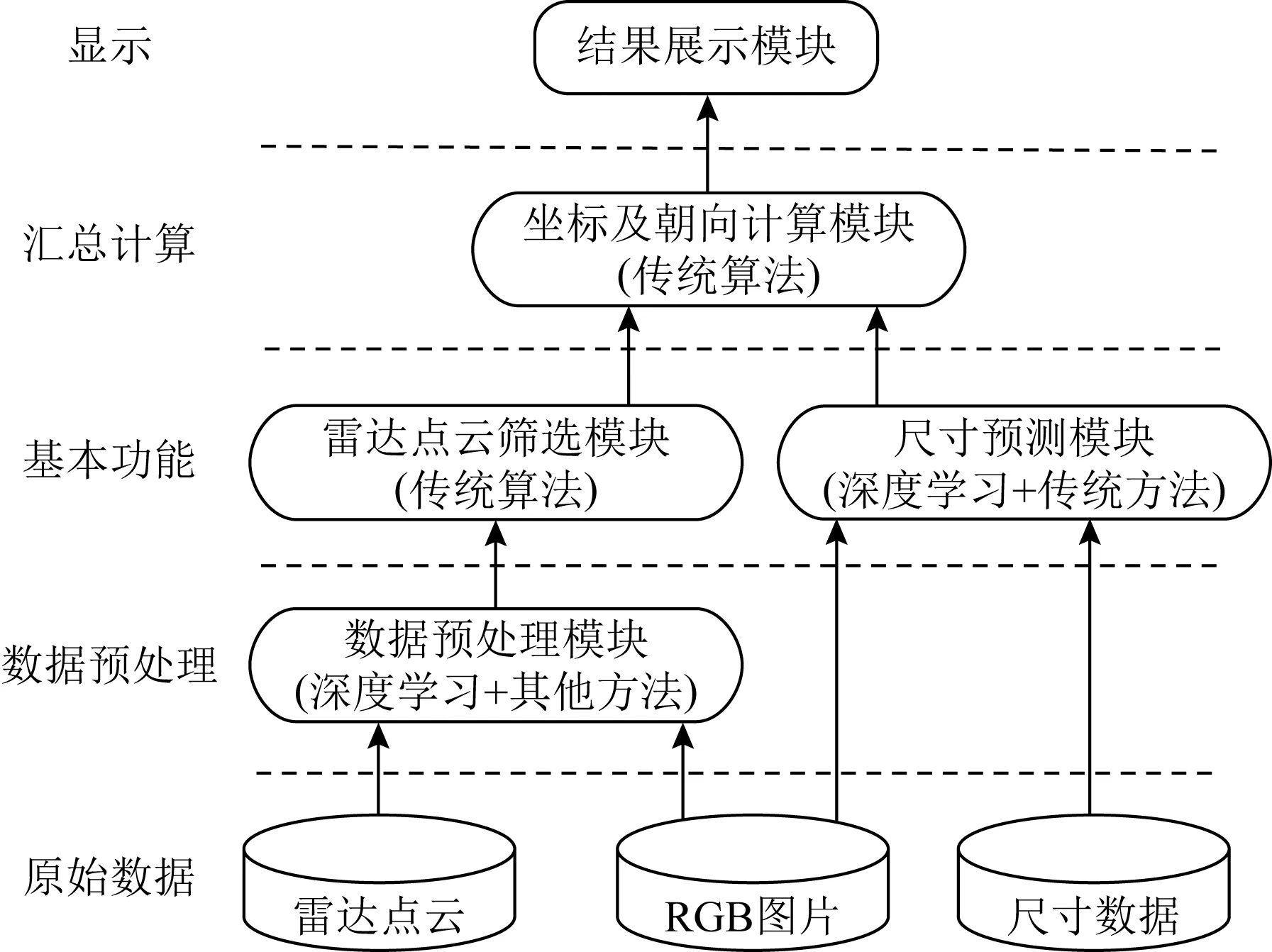
Fig.3 System composition diagram of HA3D

Fig.4 Flow chart of heterogeneous 3D object detection
2.1 数据预处理
数据预处理部分主要进行2部分工作:1)处理原始数据集,原始3D物体检测数据集中提供了RGB图像、相机参数、雷达数据和3D标注,在这里读取原始雷达数据,根据相机参数等对原始雷达数据进行格式转换、坐标系转换,并生成深度图和坐标转换矩阵,为进一步的计算提供数据;2)获取图像分割结果,在这里使用实例分割模型对RGB图片进行预测,获取图片中物体的种类、2D检测边框、mask等数据,用于下一步的尺寸预测和雷达点云筛选,过程如图5所示.本文中使用的实例分割方法有Mask R-CNN[11]和YOLACT[12],据文献[12]中所述,前者检测结果的精确率较高,在COCO test-dev上的mask AP比后者高出5.9%,但是后者的检测速度比前者提高了3.9倍,可以帮助我们更快地获取相关信息,从而提升计算速度.
2.2 尺寸预测
尺寸预测首先需要构建尺寸数据库,在现实世界中,汽车的型号及对应尺寸是可以获取的,例如,新浪汽车、edmunds等国内外各大汽车网站中都提供汽车的详细信息.基于此现实,我们可以搜集数据并构建汽车的数据库,其中存储汽车的具体车型类别和对应长宽高尺寸,并根据汽车尺寸划分小型车、中型车和大型车等尺寸类别.接下来将数据集中的汽车图片及对应具体车型类别作为训练数据,用于训练分类神经网络,可以基于ResNet[13],DenseNet[14]等结构较为简单的模型来构建分类网络,这样就能以较小的计算量预测汽车的具体车型类别.
构建完尺寸数据库并训练好分类神经网络后,就可以进行尺寸预测的工作,具体流程如图6所示,首先根据实例分割预测所得的2D检测边框,从RGB图像中裁剪出汽车的图片;然后对图片进行缩放等预处理操作后,输入分类神经网络进行种类预测;最后根据预测的具体类别查询尺寸数据库,获取汽车尺寸;当预测所得具体车型类别的置信度不高时,还可以根据该汽车具体车型所属的尺寸类别,查询出该尺寸类别汽车的平均尺寸,作为该汽车的尺寸.这种尺寸预测方法适合用于预测汽车等物体,在现实世界中,能够查询到这类物体的准确型号、对应尺寸和图片.
2.3 雷达点云筛选
整个雷达点云空间的数据规模非常大,如果直接对其进行搜索和处理,需要花费大量的时间,从而降低了检测速度.因此,本文实现了基于mask的区域筛选和密度聚类筛选这2个雷达点云筛选方法,用于从雷达点云空间中快速找到较为纯净的目标物体表面雷达点,以获取汽车表面雷达点为例,流程如图7所示.
基于mask的区域筛选被用于从较大的点云空间中快速确定物体表面雷达点分布的空间范围.该方法首先要获得目标物体mask内雷达点的像素坐标,由于整张图片的尺寸较大,搜索整张图片会花费大量的时间,因此这里只遍历目标种类物体2D检测边框内的像素点,将位于物体mask范围内的雷达点保留下来;然后利用数据预处理得到的坐标转换矩阵,得到这些雷达点的相机坐标系坐标,即真实坐标,这样就初步获得了mask内的雷达点集。通过对图7中该筛选方法的结果进行观察,可以看到该方法能够快速锁定物体表面雷达点的大致分布范围,大大缩小了后续所需处理的雷达点数量.

Fig.7 Flow chart of radar point cloud screening
密度聚类筛选被用于进一步去除物体表面雷达点中的干扰点.由于物体遮挡、mask存在误差等原因,经过初步筛选得到的雷达点中除了汽车表面雷达点外,还存在一部分干扰点.同一物体的表面雷达点分布较为集中,密度较高,因此使用Scikit-learn[15]所实现的密度聚类算法DBSCAN[16]来去除其中的干扰点.具体的聚类筛选操作为:首先,对获得的雷达点集进行DBSCAN聚类计算,得到m个聚类簇和1个离群异常簇Poutlier,将聚类簇的集合记为P={P1,P2,…,Pm},并记录下每个聚类簇中包含的点的数目Npts={n1=|P1|,n2=|P2|,…,nm=|Pm|};然后,从m个聚类簇中选出一个簇作为汽车表面雷达点集Pres,选取方法如式(1)所示:
(1)
其中pcenter是位于汽车mask中心位置的雷达点.这样选取的原因是:位于汽车mask中心的点pcenter大概率为汽车表面雷达点,因此包含pcenter的聚类簇Pi大概率就是汽车表面雷达点集;如果表面雷达点过于稀疏导致pcenter不存在,由于汽车mask范围内的主要物体就是汽车,汽车表面雷达点在整个点集中所占比例较高,所以此时选取P中点数量最多的簇Pj,来作为最后筛选出的汽车表面雷达点集.
这里将部分筛选结果投射到xOz平面来进行观察,如图8所示,可以清晰地观察到:在xOz平面上,圆点分布明显符合汽车顶部的矩形形状,而叉点分布过于离散,明显不是汽车表面的雷达点.由此可见,基于mask的聚类筛选和密度聚类筛选2种筛选方法能较为有效地保留物体表面雷达点,去除其他干扰点,可以为进一步计算输入较为纯净的物体表面雷达点,从而达到减少计算量、提升计算精度的效果.

Fig.8 Display of radar point cloud filtering results
2.4 坐标及朝向计算
需要利用2.3节获取到的物体表面雷达点等数据,通过传统算法来替代深度神经网络,计算出物体的坐标以及朝向,其中包括xOz平面坐标的计算以及物体所在高度的计算.
2.4.1xOz平面坐标计算
以计算汽车的xOz坐标为例,整体流程如图9所示,接下来对该计算方法进行详细的描述:
1)将雷达点投射到xOz平面并求得外接矩形
由于汽车从xOz平面观察呈现矩形形状,因此将所获汽车表面雷达点投影到xOz平面后,可以求出这些雷达点的外接矩形,来代表汽车在xOz平面的分布情况,外接矩形需要尽量贴近雷达点的边缘点,以便更准确地描述汽车的朝向以及所在位置.
本文最初采用的是OpenCV实现的最小面积外接矩形,该方法最终得到的是各个角度的外接矩形中具有最小面积的外接矩形,因此在部分情况下,该方法所求得的外接矩形并不能贴合物体表面雷达点在xOz平面的边缘点,计算效果不理想.为了进一步提升该方法的效果,本文对原始雷达点云进行线性填充,使用稠密雷达点进行最小面积外接矩形计算,虽然提高了检测效果,但填充雷达点云和去除干扰点的过程带来了巨大的时间成本.因此本文希望通过原始雷达点云就可求得效果较好的外接矩形,于是对外接矩形算法进行改进.首先尝试了分段折线拟合法来求外接矩形,但该方法难以确定分段的转折点,不适用于本文方法.最终本文提出了最小点边距外接矩形,该算法求得的外接矩形能够较好地贴合边缘点,更能代表汽车在xOz平面的分布情况,效果最好.
“最小点边距外接矩形”中的“点”是指物体表面雷达点的凸外包点,“边”是指外接矩形的边.该方法的思路是:先求出物体表面雷达点的凸外包点集Pconvex={p1,p2,…,pn},紧接着将初始外接矩形rect旋转不同角度θ(0°≤θ≤180°)得到rectθ,将点pi(1≤i≤n)到矩形rectθ边框的欧氏距离记为dis(pi,rectθ),找到其中的最佳旋转角度θbest,该角度满足的条件为

pi∈Pconvex, 0°≤θ≤180°,
(2)
旋转角度为θbest的外接矩形就是我们所需要的最小点边距外接矩形,由于该方法的原理可以计算得到较为贴近凸外包点的外接矩形,并且只对凸外包点进行相关计算,时间开销较低,满足本文方法对外接矩形的要求,综合效果最佳.
2)补全外接矩形
以汽车为例,由于受到雷达探测器所处位置和物体遮挡等因素的影响,雷达一般只能检测到汽车部分表面,导致获取到的物体表面雷达点不完整,进而导致求得的外接矩形也不“完整”.也就是说,所求得的外接矩形的长和宽可能与汽车真实的长和宽存在一定的差距,所以还需要使外接矩形的长和宽分别等于汽车的真实长和宽,即补全外接矩形,如图9所示:

Fig.9 Flow chart of calculation method of xOz plane coordinates
按照图9中方法补全的外接矩形,可以更好地描述汽车在xOz平面的分布情况.补全的外接矩形的中心坐标就是汽车在xOz平面的坐标,补全的外接矩形的长边与相机坐标系x轴的夹角即汽车的朝向.
2.4.2 物体所在高度计算
需要计算物体底面所在高度,即物体在相机坐标系下的y轴坐标.为了提升计算速度,本文提出了一种新的物体所在高度的计算方法,该方法的思路就是将计算物体底面的y轴坐标,转化为计算物体2D边框底边的y轴坐标.以汽车底部所在高度的计算为例,计算示意图如图10所示.在数据预处理中已经获得了汽车的mask,2D检测边框及其像素坐标(xmin,ymin,xmax,ymax),在尺寸预测中获取到了汽车尺寸(l,w,h),并且已经通过前面的雷达点云筛选方法获得了汽车表面雷达点;从mask中心区域随机选取1个汽车表面雷达点p,其相机坐标系坐标(真实坐标)是已知的,记为(xc,yc,zc)(此处下标c代表camera),该点在单目RGB图像中对应的像素坐标(xp,yp)(此处下标p代表pixel)也是已知的.
点p到2D边界框底边的像素距离占边界框像素高度的比例,等于点p到2D边界框底边的真实距离占汽车高度h的比例,据此可以计算出边界框底边的相机坐标系y轴坐标,即汽车的所在高度ycar:
(3)
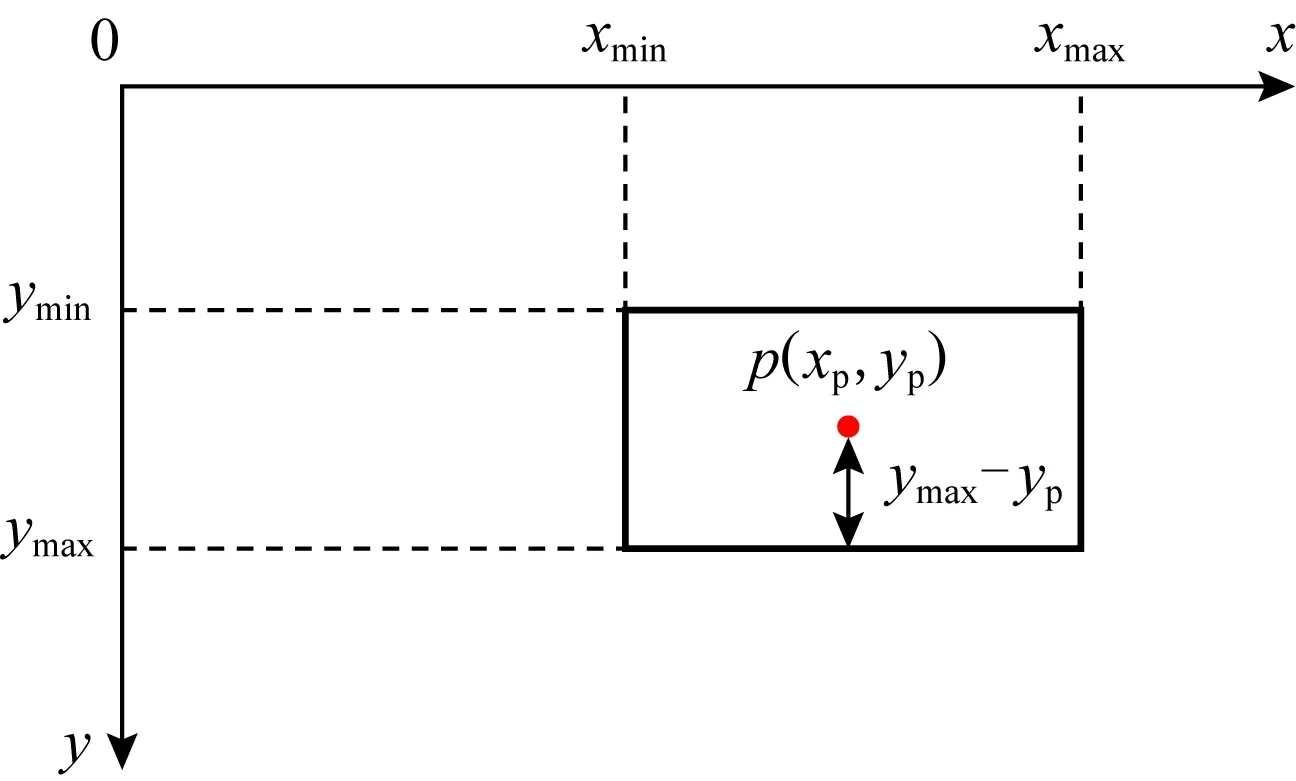
Fig.10 Schematic diagram of calculating the height of the car
该方法能够较快地求得物体所在高度,但是较为依赖实例分割模型预测所得物体2D检测边框的准确性,实例分割模型预测的2D边框越准确,该方法所求的物体所在高度也越准确.
3 实验与结果
3.1 实验环境和相关设置
本文实验全部都在服务器上进行,服务器系统版本为CentOS Linux release 8.1.1911(Core),使用的CPU为Intel®Xeon®CPU E5-2650 v4@2.20 GHz.实验所使用的主要依赖库及版本信息如表1所示:

Table 1 Dependency Library and Version Information Used in the Experiment
实验以KITTI[17]作为3D物体检测数据集.由于KITTI数据集中未标出汽车种类,所以汽车分类神经网络缺少训练数据,暂时无法获得效果较好的汽车分类神经网络,因此无法通过网络预测车型,进而查询获得尺寸.所以在这里,我们假设能够通过本文所提出的尺寸预测方法获取汽车的尺寸,在实验中暂时使用KITTI中人工标注的汽车尺寸作为替代.
为了证明本文提出的尺寸预测方法的可行性,我们查询了相关资料,发现当前车型识别的相关研究工作已经较为成熟,根据车型识别精度的排行榜[18],其中提及的29个车型识别方法在Car Dataset[19]上的车型识别的精度均在90%以上,并且最高精度已经达到了96.2%,所以如果下一步能够获得较为充足的训练数据,我们应该可以训练得到较为准确的车型识别的分类神经网络,实现本文所提出的尺寸预测思路.
3.2 评价指标
HA3D采用的是异构的方法,最终的检测结果没有置信度输出,而传统的3D物体检测评估方法会将置信度也作为评估因素,不适合用于评估本文提出的方法,所以本文对传统3D物体检测评估方法进行改造,形成新的评估方法.
本文使用交并比(intersection over union, IoU)来描述检测结果和标注数据中边框的重叠率,使用IoU阈值来描述当检测结果中的3D边框与标注中边框的重叠率大于何值时,方为合格的检测结果.此外还根据标注中物体的遮挡程度、截断指数、2D边界框高度、物体到相机的距离等设置评估范围,在评估范围内的标注数据和检测结果视为有效的数据,进行下一步的评估,不满足该条件的标注数据和检测结果不予评估.
参考KITTI[17]的3D物体检测评估程序,本文使用2个概念来描述检测结果:真正例(true positive,TP),以及假正例(false positive,FP).TP表示与有效标注数据的IoU大于检测阈值的有效检测结果数量;FP表示与任意有效标注数据的IoU都不大于检测阈值的有效检测结果数量.由于KITTI标注中存在‘DontCare’标注,这类标注数据未对物体的3D空间进行标注,因此不应该将该类区域的检测结果纳入评估范围,在这里使用STUFF来表示与‘DontCare’标注的2D检测边框的重叠率大于检测阈值的有效检测结果数量.
明确定义之后,使用精确率(Precision)对检测结果进行评估,精确率也叫查准率,它用来描述检测出的TP占检测出的所有正例(TP和FP)的比例,计算为
(4)
但是为了避免将对应‘DontCare’标注的检测结果的数量计入FP,需要将STUFF从检测出的FP中去除,重新定义评估方法中所使用的精确率:
(5)
为了评估方法的检测速度,本文使用平均每张图片所需的计算总时间以及每秒处理图片数目(frames per second, fps)作为检测速度的评价指标,同时为了更准确地评估3D检测的效率,将总时间细分为平均每张图片所需的数据预处理时间以及3D检测时间.为了同时评估方法的精度和速度,将平均每张图片所需的计算时间记为t,使用精确率与计算时间的比值(ratios of precision and time,RPT),作为评价方法综合表现的指标,比值越大,说明检测效果越好,其计算方法为
(6)
3.3 实验结果和分析
3.3.1 不同外接矩形算法
在相同的CPU实验环境下,从KITTI[17]训练集中随机选取1 000张图片,分别使用OpenCV的最小面积外接矩形、稠密点云下的最小面积外接矩形、分段折线拟合法和最小点边距外接矩形这4种算法对其中的汽车进行检测,并使用相同的评估范围,检测阈值设置为0.7,评估不同方法的精确率和速度的综合表现,评估结果如图11所示.
从图11中可以发现:虽然稠密雷达点云下的最小面积外接矩形算法,相对于稀疏雷达点云下的最小面积外接矩形算法,精确率高出5.81%,但检测速度极慢;而分段折线拟合法显然不适用于本文方法,检测结果的精确率仅仅只有4.88%;最小点边距外接矩形算法的检测结果的精确率远高于其他方法,并且其检测速度也非常快.因此,本文所提出的最小点边距外接矩形算法所求矩形更为贴合边缘点,计算的速度较快、精度最高,在HA3D中应用效果最佳.
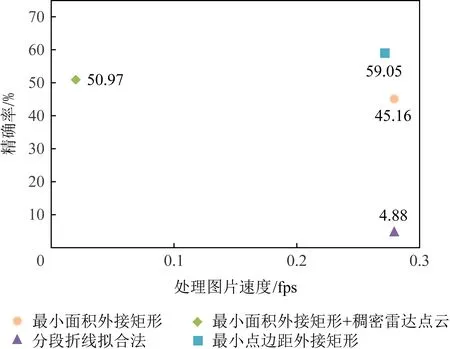
Fig.11 FPS-Precision scatterplot of different bounding rectangle algorithms
3.3.2 与其他3D物体检测方法对比
本节将对比HA3D和部分具有代表性的3D物体检测方法.在相同的CPU环境下,我们对所有方法的检测结果使用相同的评估范围,测试每张图片所需的预处理时间、3D检测时间以及总的计算时间,同时对比检测阈值分别为0.7和0.5时的精确率,以及检测阈值为0.5时的RPT综合指标,评估结果如表2所示:
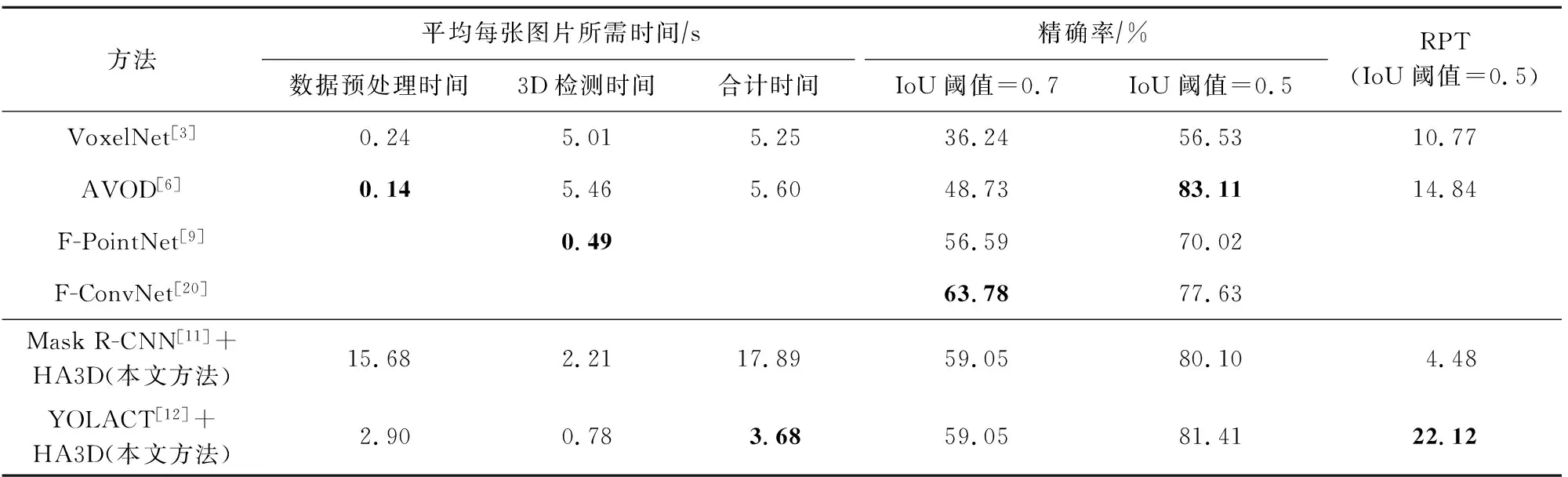
Table 2 Comparison with Other 3D Object Detection Methods
VoxelNet的代码与预处理模型来源为github项目[21];AVOD代码来源为官方实现,预训练模型来自Pseudo-LiDAR[22];F-PointNet和F-ConvNet的代码及预训练模型为官方实现.在这里还绘制了散点图来对各个方法的综合表现进行直观的对比(其中处理图片速度是根据各个方法3D检测部分的平均时间进行计算,Precision是IoU为0.5时的精确率),如图12所示:
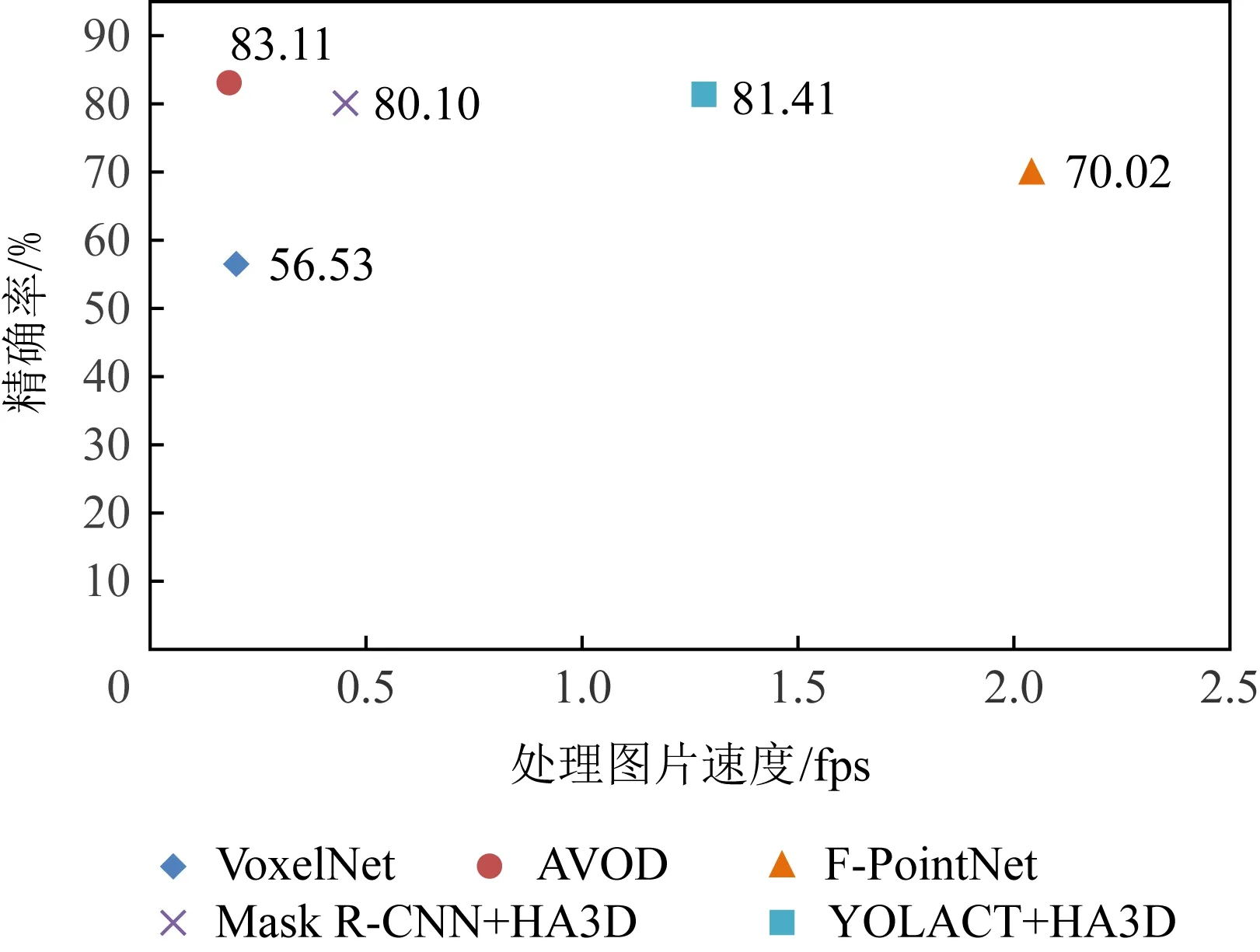
Fig.12 FPS-Precision scatterplot of different 3D object detection methods
表2中的F-PointNet和F-ConvNet均未给出完整的3D检测代码,两者均直接使用了提前生成的2D检测边框和3D视锥体点云,导致本文无法对其进行完全复现,进而无法测试其完整的计算时间.此外,F-PointNet检测流程中的视锥体提案生成部分采用了基于FPN[23]的神经网络,传统的FPN网络模型通常比较复杂,GPU推理时间在100 ms以上,而本文中用到的YOLACT[12]网络GPU推理时间约30 ms,比传统FPN网络快3倍以上,类比到CPU设备,结合表2中的数据,可推断出F-PointNet的数据预处理时间大于8.7 s,由此可以推测其检测总用时约9.19 s,是本文工作HA3D检测总时长的2.5倍,因此F-PointNet的检测时间并不占优势.而且F-PointNet在3D物体检测部分使用的是轻量级的PointNet[7],虽然减少了少量的3D检测时间,但造成了其精确率的下降,相对于HA3D,其精确率下降了11.39%,因此HA3D的综合表现更优.因此,本方法相对其他基于深度学习的方法(例如F-PointNet)无论是在总体检测速度,还是检测精度上都有明显优势.
本文通过对比各个方法的检测时间来衡量各个方法的复杂度,从表2中可以观察到HA3D的3D物体检测时间远远少于VoxelNet和AVOD,相对于AVOD的检测时效提升了600%,且通过分析,可以得知F-PointNet的检测时间并不占优势.因此,本文利用传统图形算法来进行3D边框的计算,相对于部分利用深度神经网络进行3D边框回归的检测方法,所需要的检测时间更少.这说明了HA3D方法进行3D物体检测的算法复杂度更低、计算规模更小,因此进行检测的速度更快.
从表2和图12中综合比较各个方法的检测速度和精确率,其中AVOD方法的精确率比HA3D方法高1.7%,但它采用了较为复杂的网络结构,导致计算量较大,总体运行时间约为HA3D方法的1.5倍;F-PointNet处理图片的速度虽高于HA3D方法,但从之前的讨论中可以得知这是因为它采用了轻量级的网络,也因此导致了精确率的大幅度下降.从图12中也可以看到本文提出的YOLACT+HA3D方法位于右上角,这说明HA3D方法的综合表现最好.经结果对比分析可得出:本文提出的HA3D方法在检测精度下降可接受范围内,大幅度地提高了总体检测速度,相比于传统的基于端到端的深度学习方法,更适合于自动驾驶等实时性要求高的工作场景.
因此,在汽车的3D检测中,相对于部分具有代表性的端到端的3D物体检测方法,HA3D在精确率和速度的综合方面上表现突出,这说明了传统方法确实适合用来完成3D物体检测过程中的部分任务,使用聚类算法等来进行雷达点云筛选和坐标计算,取得了很好的检测精度,并且减少了计算量,提升了检测速度.
4 总结与展望
本论文提出的HA3D方法从全新的异构角度来考虑3D物体检测问题,将传统算法应用到3D物体检测中,实现了“深度学习+传统算法”的异构3D物体检测方法.从实验结果中来看,本文方法相对于部分基于端到端深度学习的3D物体检测方法,在速度和精确率的综合表现上具有优势(速度提升52.2%,RPT指标提升49%),该结果说明传统算法确实适合用于解决3D物体检测中的坐标计算等问题.这样将深度学习和传统算法相结合进行3D物体检测的方法,相对于直接使用端到端的深度神经网络,不仅保证了较高的准确率,还具有更快的检测速度,并且该方法通过多模块的形式来实现,具有更加灵活的结构和更好的可拓展性.
本文提出的方法还有进一步的优化空间,例如:1)本文方法还可以通过算法优化和GPU加速,进一步提升计算速度;2)可以尝试通过路面检测来获取物体所在高度,从而避免2D检测边框准确性对结果的影响,可能会进一步提高3D检测结果的精确率;3)如果能够获得充足的汽车分类神经网络的训练数据,就可以训练出汽车分类神经网络,进而预测获得汽车尺寸数据,实现本文所提出的汽车尺寸预测思路.
猜你喜欢
China’s foreign Trade(2021年6期)2021-12-26
中学生数理化·八年级数学人教版(2020年4期)2020-10-29
中学生数理化·八年级数学人教版(2017年4期)2017-07-08
福建中学数学(2016年4期)2016-10-19
小雪花·成长指南(2016年9期)2016-10-12
消费电子(2015年7期)2015-12-11
中华奇石(2015年7期)2015-07-09
中华奇石(2015年5期)2015-07-09
读者(2010年8期)2010-08-30
数码摄影(2009年1期)2009-01-22
