
神威太湖之光可靠性及可用性设计与分析
2021-12-14 11:32高剑刚龚道永方燕飞何王全金利峰李宏亮
计算机研究与发展 2021年12期
高剑刚 胡 晋 龚道永 方燕飞 刘 骁 何王全 金利峰 郑 方 李宏亮
(国家并行计算机工程技术研究中心 北京 100190)
过去数十年,随着半导体集成电路工艺与系统规模的不断提升,高性能计算机计算性能得到了快速的发展.当前,为了满足气象、生命科学、高能核物理等大规模科学应用对计算能力的超高需求,E级计算(1000PFLOPS)已成为高性能计算领域的下一个研制目标.然而,由于系统规模与复杂度的不断增加,故障失效成为超级计算机系统运行过程中的普遍事件,当系统性能由P级(PFLOPS)向E级扩展时,系统保存全局检查点的时间可能达到甚至超过系统的平均无故障时间(mean time between failures, MTBF)[1],可靠性墙[2]正成为构建E级计算机系统所面临的一项巨大挑战.
可靠性是指系统在规定的条件和规定的时间内,完成系统功能的能力,而可用性是指系统在规定的条件和时间区间内处于可执行规定功能状态的能力,是可靠性和维修性的综合体现.超级计算机系统结构复杂、规模庞大,可靠性与可用性问题日益严峻,必须研究采用可靠性增强技术,提高系统基础可靠性,同时必须有效采用故障容错技术,提高系统在频繁故障环境下的运行效率,破解高性能计算机系统高可用难题.
神威太湖之光是世界首台性能超过10亿亿次并行规模超千万核的超级计算机.本文对神威太湖之光超级计算机系统可靠性与可用性进行全面的研究,分析高性能计算机失效特性与故障容错技术,对于未来E级计算机系统高可靠与高可用设计具有重要的意义.
本文的主要贡献有3个方面:
1)系统提出神威太湖之光超级计算机可靠性增强技术,结合3种典型寿命周期分布,对系统故障间隔时间分布进行数据拟合分析,建立神威太湖之光超级计算机失效分布模型,计算系统平均无故障时间;
2)设计提出故障预测、主动迁移与任务局部降级主被动容错技术,建立神威太湖之光超级计算机多层次主被动统一、软硬件协同的容错系统,结合系统应用课题,具体分析多种容错技术的时间开销与容错效果;
3)以神威太湖之光超级计算机系统可靠性与可用性研究分析为基础,提出未来E级计算机系统高可靠与高可用技术发展建议.
本文首先介绍高性能计算机系统可靠性与可用性研究领域相关工作,并概要描述神威太湖之光超级计算机系统结构;随后系统提出神威太湖之光超级计算机可靠性增强技术与主被动容错技术,建立神威太湖之光系统多层次主被动统一、软硬件协同的容错系统;通过系统运行故障统计与实际应用测试,建立系统失效分布模型,计算系统平均无故障时间,分析多种容错技术的时间开销及容错效果;进一步以此为基础,提出E级计算机系统高可靠与高可用技术发展建议,最后总结全文并提出后续工作方向.
1 相关工作
1.1 可靠性技术
为了提高高性能计算机系统的可靠性,业界研究采用了多种可靠性增强技术.Summit,Sierra超级计算机InfiniBand高速网络通过自适应路由、冗余设计等技术,提升互连网络系统的可靠性[3].IBM Power处理器芯片设计支持指令重试恢复(instruction retry recovery, IRR)[4],通过定义状态检查点,提供寄存器错误恢复功能.纠错码(error correcting code, ECC)是一种信息冗余技术,通过附加冗余数据信息,实现错误检测与纠正.Cray XC系统Aries网络芯片采用ECC与循环冗余码(cyclic redundancy code, CRC),实现数据路径有效防护[5].此外,硬件冗余设计也是高性能计算机系统提高可靠性的常用技术,例如IBM Z系列服务器主机设计2套时钟卡用于冗余备份[6],当主卡发生故障时,时钟源可以动态切换至从卡.超级计算机系统规模庞大,特别是计算节点与存储系统器件数量显著增加,对系统可靠性设计提出严峻挑战.本文结合神威太湖之光超级计算机组成结构,系统提出神威太湖之光系统可靠性增强技术.
在可靠性分析方面,高性能计算机系统失效特性分析得到了业界广泛关注.文献[7]总结了高性能计算机不同系统组件的失效类型并提供了系统整体失效率.文献[8]分析了2台典型P级超级计算机的故障来源及失效特性;文献[9]则分析了异构服务器系统失效经验数据与统计特性;可靠性、可用性与可维护性(reliability availability serviceability, RAS)日志通常是记录系统故障事件的主要来源,有大量文献[10-13]基于RAS日志对Blue Gene P/L等高性能计算机系统开展失效特性分析.RAS日志往往包含大量冗余信息,需要结合过滤算法滤除冗余信息,以便于进行后续失效分析.本文根据系统故障统计数据,开展神威太湖之光超级计算机系统失效特性分析,建立神威太湖之光系统失效分布模型.
1.2 可用性技术
为了实现高性能计算机系统高可用目标,业界提出了多种不同的故障容错技术.保留恢复[14-16]是大规模并行计算中最常用的容错机制,通过状态保存和恢复执行进行容错.Rollback[17]和Rerun[18]则是通过重新加载和重新执行来进行恢复.迁移模型[19-20]通过透明在线或离线的迁移执行来增强超级计算机的容错能力.双机接管[21]是在主设备无法工作时备用设备自动接管系统.进程冗余[22]通过作业内的冗余进程副本来实现局部故障的容错.算法容错[23]是通过增加数据编码或存储的冗余性来实现局部故障的容错.各种容错方法都有自己的适用场景和优势,然而,如何将各种手段有机融合为一体,同时给出面向具体应用场景的特色化容错技术,适时启用最佳的容错方法,是一个需要迫切关注的焦点.为此,本文基于神威太湖之光超级计算机系统开展实用化特色容错技术的研究,建立了多层次主被动协同容错系统,在此基础上具体分析了故障预测、主动迁移、任务局部降级等容错技术的实际开销.
2 系统概述
神威太湖之光超级计算机是由国家并行计算机工程技术研究中心于2015年研制完成的1台超大规模并行计算机.神威太湖之光超级计算机共安装40 960个国产众核处理器,全机运算核心达到10 649 600个,主存容量达到1.3PB,理论峰值计算性能及Linpack计算性能分别达到125.43PFLOPS与93.01PFLOPS.根据TOP500榜单[24],神威太湖之光于2016—2017年,连续4次排名世界第一.
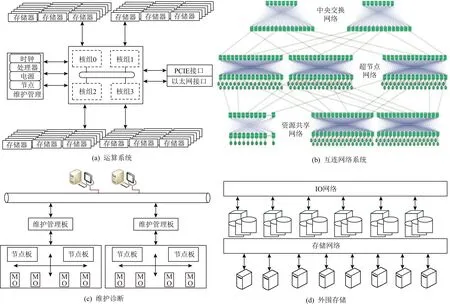
Fig.1 Sunway TaihuLight supercomputer hardware system
神威太湖之光超级计算机系统包括硬件系统、软件系统与应用系统.其中硬件系统由运算系统、互连网络系统、维护诊断、外围存储、电源及冷却系统组成,如图1所示.软件系统由国产众核处理器基础软件、并行操作系统环境、高性能存储管理系统、并行语言与编译环境以及并行开发环境组成.应用系统包括应用平台基础框架、行业应用平台和典型应用软件.
神威太湖之光超级计算机基于国产申威26010处理器构建.申威26010是1款异构众核处理器,共包含260个运算核心.申威26010众核处理器采用片上计算阵列集群和分布式共享存储相结合的异构众核体系结构.申威26010众核处理器集成4个核组,每个核组包括运算控制核心、运算核心阵列和协议处理部件,其中运算控制核心提供管理服务和计算功能,运算核心阵列采用8×8阵列结构,集成64个运算核心,提供主体计算能力,而协议处理部件用于处理数据一致性问题.同时,申威26010众核处理器还提供DDR3(double data rate generation 3)存储器接口、PCIE3.0(peripheral component interconnect express generation 3)通信接口、以太网及维护接口,支持高带宽存储访问与数据通信[8].
3 技术体系
3.1 总体设计方法
神威太湖之光超级计算机规模庞大,为实现系统长时间稳定运行,需要协同系统软硬件,通过可靠性分析、可靠性设计与可用性设计3个层次,全面提升系统可靠性与可用性.
可靠性分析基于系统组成单元功能逻辑关系,建立全机系统可靠性分析模型,采用元器件应力分析法,开展系统可靠性预计与评估,分析可靠性薄弱环节,合理分配可靠性指标.可靠性设计针对系统关键部件及可靠性薄弱环节,采取器件选型、冗余、热设计等一系列可靠性增强技术,改进系统工艺与设计,防止错误发生,提高系统硬件基础可靠性.可用性设计基于主被动统一的容错思想,构建高效容错控制体系,协同采用多种容错技术,有效实现故障的检测、诊断与恢复,降低系统容错开销,实现应用级高可用目标.
3.2 多层次容错体系
神威太湖之光超级计算机基于体系化容错设计理念,在体系结构、软硬件系统、应用系统等多个层次全面贯彻高可靠与高可用设计思想.遵循容错设计要求,优化制定系统性能指标,达到系统功能实现与故障容错的深度融合.

Fig.2 Fault tolerance system of multi-level active and passive collaboration
系统采用以最小容错替换单元(minimum toler-ance replaceable unit, MTRU)设计为核心的故障局部化、轻量化容错设计,综合运用故障隔离、替换与修复技术,通过硬件系统、基础支撑、容错控制等协同设计,构建主被动统一、软硬件协同的多层次容错系统,如图2所示.神威太湖之光通过系统维护、心跳检测、容错数据库构建容错基础支撑,通过容错控制台、容错中间件和插件环境构建容错控制系统,通过系统和应用层的多样化容错提供多层次容错功能.在系统层提供故障预测、主动迁移等主动容错和消息重传、作业回卷、局部降级、故障接管等被动容错功能.在应用层提供基于局部保留和透明迁移恢复的局部检查点(local checkpoint, LC)与基于进程冗余的冗余检查点(redundancy checkpoint, RC)容错功能,并通过容错控制接口,将应用级容错纳入统一的自动化容错系统,实现系统感知的应用级容错.神威太湖之光系统通过软硬件协同容错设计和多层次容错方法,提高多场景容错措施的覆盖面,降低容错的影响范围和容错开销,提升系统的可用性.
3.3 可靠性增强技术
神威太湖之光超级计算机系统规模庞大,主机元器件数量达到亿量级,国产众核处理器集成度高,性能指标先进,存储、网络与电源冷却子系统设计复杂,面临严峻的可靠性挑战.为此,神威太湖之光在器件、部件、系统等不同层次,设计采用了一系列可靠性增强技术,有效提升系统基础可靠性.
申威26010众核处理器是神威太湖之光超级计算机的核心器件.为保证芯片的稳定可靠,提出基于余数域分配律计算结果在线校验技术,建立片上一体化检验和故障异常处理技术体系.运算核心浮点乘加检错部件基于余数校验码原理,根据运算主通路输入,生成预期结果的余数码,与运算主通路输出结果的余数码进行比较,支持浮点和整数多种运算的实时在线检错.通过算法优化与功能复用,降低时序及面积开销,检错覆盖率达到93.33%.结合系统级校验体系与软件容错,可以有效检测并纠正由芯片内部噪声或外部放射性粒子所引发的瞬态故障,从而提高众核处理器的稳定性与可靠性.
与Summit等超级计算机基于双列直插内存模块(dual inline memory module, DIMM)构建存储系统所不同,神威太湖之光计算节点存储系统选用DDR3存储器颗粒,通过焊接贴装于印制板上,避免因DIMM存储条电气与机械连接所引起的可靠性问题.此外,申威26010众核处理器存储控制接口设计支持ECC,Chipkill,RS多种校验编码,利用存储器冗余数据位,实现单比特错自动检测与纠正,存储器失效率可降低约80%[25],显著提升计算节点存储系统可靠性.
在互连网络系统可靠性设计中,提出泛树网络结构与双轨联动高效高可靠通信机制,网络芯片设计冗余互连端口,有效提升互连网络容错能力.通过采用高速信号传输技术,14 Gbps高速串行链路传输误码率降低至10-15量级,结合前向纠错编码技术,实现网络数据不间断稳定可靠传输.
冷却散热是影响超级计算机系统可靠性的一个关键因素,随着器件结温增加,元器件失效率呈指数级增长[26].由电子设备可靠性预计手册[27],半导体集成电路每运行百万小时失效率λ可以估算得到:
λ=(C1πTπV+(C2+C3)πE)πQπK,
(1)
其中,πT为温度应力系数,取决于电路工艺和结温,πV,πE,πQ,πK分别为电压、环境、质量与成熟度系数,C1,C2为电路复杂度失效率,C3为封装复杂度失效率.申威26010众核处理器设计选用低热阻封装,主机系统采用间接液冷散热,运算插件冷板设计立体流道布局结构,结合流场均衡与刚柔复合表贴接触技术,将众核处理器芯片结温有效控制在50℃量级,显著提升众核处理器运行稳定性,进而提高系统整体可靠性.
系统广泛采用冗余设计机制,外围存储采用成熟的冗余独立磁盘阵列,冷却与电源系统的冷水机组、水泵、空调、电源转换模块等均采取冗余设计,避免单点故障引发系统失效.同时,广泛支持热拔插与在线维修,实现系统故障快速恢复,有效提升系统可靠性与可维性.
3.4 高可用设计
超级计算机系统规模庞大、应用课题类型多样、程序模型千差万别,容错需求差异很大.为此神威太湖之光集合应用容错需求,提出故障预测、主动迁移与局部任务降级等主被动容错技术,通过协同多种容错技术,提升系统可用性.
3.4.1 故障预测
神威太湖之光采用基于滑动时间窗口和准确度约束的数据关联分析方法,对大规模系统实时和历史数据进行多维分析,深入挖掘同源多次故障、非故障多维特征数据与故障之间的相关性,提取故障发生的分布规律,结合实时故障验证,建立多层次系统资源故障失效时间分布模型,指导进行故障预测分析.考虑到系统在生命周期不同阶段、不同负载、不同应用场景下的故障概率变化情况,采用机器学习方法对故障预测模型进行周期性最优近似求解并持续迭代,优化调整预测模型参数,提高故障预测准确率.故障预测主要考虑关键因素如表1所示:

Table 1 Key Factors for Failure Prediction
在预测结果的计算过程中,主要参考了各种关键因素的故障历史、临近时间段内的状态数据、挖掘获得的合理阈值和迭代求解得到的系数.故障预测:
Ewarning=

(2)
其中,Ewarning为通过预测函数f(x)得到的预测结果即预警事件,g(x)表示基于关联分析建模得到的模型函数,{Fxy}表示时间区间内的故障集合,{Txy}表示时间区间内的状态数据集合,{Thxy}表示阈值参数,{Wxy}表示求解系数,Sx表示取值集合,C,M,N,T,P,L分别代表处理器、存储器、网络接口、温度、电源和负载.系统运行过程中,持续采样状态数据,根据预测模型函数计算预测结果,一旦相关因素的状态数据满足故障概率条件则形成故障预警,触发并驱动容错系统进行容错决策,并择机启动策略化的主动容错.在实际系统中,支持处理器核心、存储器、网络接口等主要部件的故障预测.
3.4.2 主动迁移容错
主动迁移是一种基于预警事件驱动的透明化容错技术,适用于各种类型的应用,对提高系统的可用性非常重要.与事务处理及数据只读型应用不同,高性能计算迁移容错面临着多进程间的共享内存、消息通信、文件处理等复杂耦合关系,控制复杂.神威太湖之光针对主动预警容错需求,设计实现了面向高性能计算消息模型特征的局部预警主动迁移容错技术,采用冻结—迁移—恢复设计思想,其控制原理如图3所示:
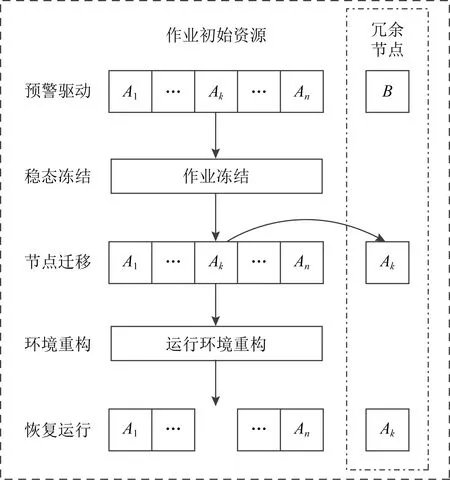
Fig.3 Active migration fault tolerance
基本算法如算法1所述:
算法1.基于耦合识别的节点迁移算法.
输入:节点故障预警事件E、预警处理策略P;
输出:节点迁移结果result.
① 判断预警事件所影响的作业J和节点N;
② 代价收益评估,确定最佳容错策略P;
③ 申请冗余资源R;
④ 驱赶J中的消息和IO;
⑤ 将缓存数据刷新到主存;
⑥ 识别用户数据区UD和关键系统数据区SD;
⑦ 冻结作业J;
⑧ 将节点N上的UD和SD迁移到R上;
⑨ 重构作业J的运行控制环境;
⑩ 恢复作业J;
在迁移算法中,通过动态分析节点内存数据的访问特征,识别用户数据区、关键系统数据区和其他数据区,确保只迁移用户数据区和关键系统数据区空间,降低迁移数据量和开销.通过作业运行阶段和多样化容错特征识别,进行容错代价和收益的评估,从而选择最合适的容错手段.从策略和手段上降低开销,提升实用性.
3.4.3 局部降级容错
消息重传、作业回卷、故障接管等被动容错是故障发生后的补救型容错,其目的是减少故障的影响.高性能计算系统运行并行应用程序期间,一旦发生本地资源故障,通常只能取消作业.否则不仅不能获得正确的结果,而且作业也不能成功退出.动态任务分区是一种应用广泛的程序模型,它通常有一个主进程和其他从进程.主进程动态地将任务分配给从进程.任务完成后,从进程继续向主进程申请新任务,主从进程通过消息相互交互.针对这种应用特点,在动态任务划分的基础上,神威太湖之光提出一种特殊的局部降级容错技术.当故障发生时,对故障资源和任务过程进行动态切割,重构运行环境.剩余的资源和任务进程可以继续执行,而不会导致任务丢失.当从进程资源失败时,主进程将所有未完成及后续任务重新分配给其他进程,终止从进程并释放故障资源.当主进程失败时,从进程通过投票算法选举一个新的主进程来替换任务分配功能.局部降级后,底层运行时重新映射剩余的资源和进程列表,重新构建作业环境,以确保作业能够连续运行并成功退出,如图4所示.

Fig.4 Job local degradation
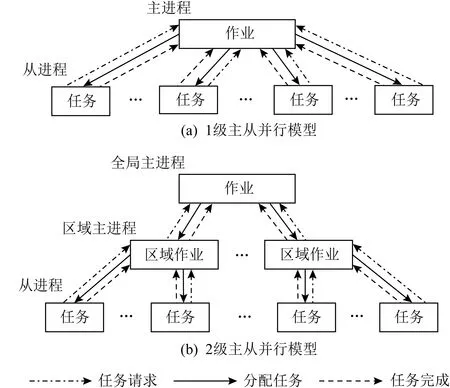
Fig.5 Task distribution model
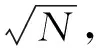
4 数据分析
4.1 可靠性分析
本文利用神威太湖之光系统运行以来故障统计数据进行失效分析.神威太湖之光超级计算机系统中发生故障的部件主要有计算节点(包含CPU与DDR3存储器)、互连网络、维护诊断子系统、外围存储、电源与冷却子系统.故障统计数据包含了故障发生的时间、故障发生的物理位置、故障类型以及故障场景等多种信息.由于故障数据内可能包含相同时刻相同故障类型的重复记录,还可能包含因系统配置或用户代码所引发的警告信息[28],因此在对故障统计数据进行数据整理预处理后开展分析.
根据故障类型及其影响程度,故障可以进一步分为非致命性故障与致命性故障2类.非致命性故障可以自动通过硬件冗余资源或软件容错技术进行修复,不会导致系统任务中断.而致命性故障则会导致系统失效,必须及时进行修复.本文主要对致命性故障及其所引发的系统失效进行分析.
由系统故障统计数据,系统部件失效分布饼图如图6所示.可以看出,计算节点失效最高,占比达到58.92%.针对神威太湖之光超级计算机计算节点,进一步分析其失效原因,计算节点失效主要为众核处理器故障和DDR3存储器故障,众核处理器故障包括运算控制核心故障、运算核心阵列故障、协议处理部件故障、存储控制器故障、片上网络故障以及系统接口故障,而DDR3存储器则主要表现为多比特错(multiple bit error, MBE).显然,配置众核处理器与大量DDR3存储器的计算节点作为系统核心计算部件,是神威太湖之光硬件系统失效的主要来源,对于系统可靠性具有最重要的影响作用.其次为电源子系统,由于全机电源板及电源器件数量众多,因此电源子系统失效也较为可观,其失效占比达到18.60%.维护诊断子系统失效占比为12.79%.相对而言,互连网络、外围存储与冷却子系统受益于高效的网络容错机制与广泛的冗余配置,具有较高的可靠性,其失效占比分别为6.20%,1.94%,1.55%.
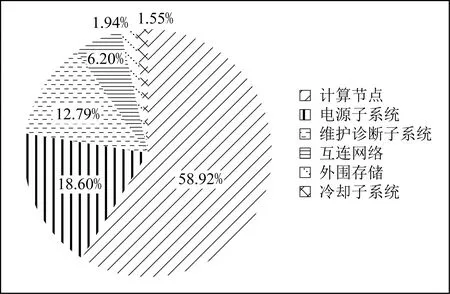
Fig.6 Failure distribution of Sunway TaihuLight system
进一步来分析神威太湖之光系统故障间隔时间分布特性,设T为系统故障发生时间集合,即
T={t1,t2,…,tn},
(3)
则故障间隔时间Tbetween failures可以表征为
Tbetween failures={ti+1-ti},i=1,2,…,n-1.
(4)
由系统故障发生时间可以计算得到故障累计时间分布函数F(t),则神威太湖之光系统可靠度R(t)可以表征为
R(t)=1-F(t).
(5)
指数分布、对数正态分布与韦布尔分布作为3种典型寿命周期分布模型[29],在数据统计分析领域得到了广泛的应用,其失效概率密度分布函数f(t)如表2所示:

Table 2 Typical Life Cycle Distribution Probability Density Function
本文选择这3种寿命周期分布模型,对神威太湖之光系统故障间隔时间分布进行数据拟合分析.寿命周期分布具体数值可由最大似然估计得到,进而与故障累计时间经验数据进行拟合分析.随后,利用K-S(Kolmogorov Smirnov)检验来评估寿命周期分布模型与经验数据之间的拟合度.K-S检验产生的p值用于表征统计数据的拟合度.一般而言,当p>0.05时,表示经验数据与寿命周期分布具有较好的拟合度,可以认为经验数据服从寿命周期分布模型,当p<0.05时,则表示经验数据与寿命周期分布不具有相关性.

Fig.7 Comparison of empirical and three typical life cycle distribution CDF
系统故障经验累积分布函数(cumulative distri-bution function, CDF)与指数分布、对数正态分布及韦布尔分布对比如图7所示,图7中实线为由故障统计数据得到的神威太湖之光系统故障经验累积分布函数曲线,虚线分别为数据拟合得到的指数、对数正态、韦布尔累积分布函数曲线.
图8进一步对比了神威太湖之光系统故障经验数据直方图与指数、对数正态及韦布尔概率密度分布函数(probability density function, PDF)曲线.在显著性水平为0.05的条件下,指数、对数正态与韦布尔分布K-S检验p值分别为0.1298,0.3201,0.0845,K-S假设检验成立.可以看出,指数、对数正态与韦布尔3种典型寿命周期分布模型与神威太湖之光系统故障经验数据均得到了较好的拟合,而对数正态分布拟合程度最好.通过对故障数据的拟合分析,基于拟合度最佳的对数正态分布,建立神威太湖之光超级计算机失效分布模型.由失效分布模型参数,计算对数正态分布的数学期望值,得到系统平均无故障时间MTBF为11.84 h.此外,经最大似然估计,韦布尔分布形状参数m=1.0712(近似为1,此时韦布尔分布等同于指数分布),表明神威太湖之光系统基本处于可靠性浴盆曲线的偶然失效期,系统运行稳定,失效率较低.

Fig.8 Comparison of histogram and three typical life cycle distribution PDF
4.2 可用性分析
对神威太湖之光超级计算机运行以来系统容错数据库中的容错历史日志进行统计分析,数据表明业务运行期间,系统故障预测平均准确率约70%,其中53%的预测故障进行了主动迁移容错,剩余17%的预测故障区别不同情况,分别采用了主动接管、主动避错等方法避免潜在故障中断课题运行.
使用神威太湖之光经典流体力学应用Open-Foam进行测试,主动迁移过程的时间开销如图9所示.每次迁移一个节点,每个节点内存32 GB.由于单个节点的内存大小固定,网络带宽不变,数据迁移的时间基本没有变化.随着作业规模的增加,消息和IO一致性驱动器和冻结处理的时间开销也会增加,但是总时间开销仍然在可接受的范围内.通过采取主动迁移容错,提前干预处理,将故障预测节点上的任务进程迁移到健康节点上,以较小的迁移容错开销为代价,有效避免了因节点瞬间故障导致的程序中断损失,该容错过程对系统可见,但对应用完全透明,从而提高了应用可感知的系统平均无故障时间.统计分析系统容错数据库中的历史迁移容错日志,得到应用程序感知到的系统平均无故障时间为24.2 h,相对系统平均无故障时间,提升约1倍.

Fig.9 Active migration fault tolerance time overhead

Fig.10 Job local degradation fault tolerance time overhead
对于因预测失败而产生的瞬态故障,通过自动容错评估决策,按需采用任务局部降级与作业回卷容错.任务局部降级可以应用于具有动态任务分配属性的多个应用程序.局部降级模型本质上只涉及多节点间具有良好可扩展性的协同控制,并不存在复杂的大量数据迁移过程.经测试,典型情况下神威太湖之光任务局部降级时间开销如图10所示.可以看出,局部降级容错时间开销小,且对作业规模不敏感,是一种非常有效的被动容错技术.通过采取被动容错,虽然没有降低系统应用可感知的平均无故障时间,但有效控制了故障的影响范围,使课题可以带错继续运行并得到正确结果,减少了因系统故障而增加的应用课题回卷执行时间.统计分析系统数据库中的历史降级容错日志,可以发现,针对可降级容错课题,局部降低容错可将平均单个节点故障导致的应用课题容错损失(因降级增加的执行时间相比因回卷容错增加的执行时间)降低90%以上.
因此,神威太湖之光超级计算机系统基于多层次主被动统一的容错控制体系,通过采用面向不同应用场景的多样化容错技术,实现了融合故障预测、评估决策、容错控制于一体的全流程自动按需容错,降低容错时间开销,有效提升神威太湖之光超级计算机系统的可用性水平.
5 技术展望
不难预测,未来E级计算机将对系统可靠性与可用性提出极高的要求.这里,本文以神威太湖之光超级计算机系统可靠性与可用性研究分析为基础,分别从硬件和软件2个层次,提出未来E级计算机系统高可靠与高可用技术发展建议.
5.1 可靠性技术
5.1.1 高密度组装
显而易见,系统元器件数量越多,系统整体基础可靠性越低.神威太湖之光超级计算机采用3维高密度组装,每个运算机仓共安装1 024个CPU,组装密度达到世界领先的523.10TFLOPS/m3.得益于高密度组装,神威太湖之光超级计算机运算机仓数量仅40个,系统部件及元器件数量得到有效缩减,十分有助于提升系统的整体可靠性.E级计算机系统规模不断扩大,迫切需要在封装、PCB板、背板等不同层次广泛应用高密度组装技术,提高系统集成度,平衡机仓规模数量,这不仅有利于提升系统基础可靠性,同时对于系统硬件设计实现以及可扩展性都具有极其重要的作用.
5.1.2 高效冷却
随着高性能处理器功耗与系统规模的不断提升,E级计算机系统能耗预计将达到几十至上百MW量级,系统冷却成本和使用成本显著增加,同时对系统稳定性与可靠性提出极大挑战.当前以相变冷却、2.5/3D封装微通道冷却等为代表的新型高效冷却技术,对于降低计算节点众核处理器等核心器件芯片结温,提高计算节点与主机系统可靠性与可用性具有重要的作用,在未来E级计算机系统中具有广阔的应用前景.
5.1.3 主存防护
计算节点存储系统故障失效在神威太湖之光硬件系统失效中占据了较高的比重.随着E级计算机系统访存带宽与主存容量需求的不断提高,存储系统元器件数量与规模也不断增加,计算节点主存防护对于提升系统整体可靠性至关重要.基于序列模式挖掘的主存故障特征识别方法[30],通过建立计算节点主存失效序列规则模型,从而实现对存储系统故障特别是MBE故障的有效预测,是一种具有启发性的技术发展思路.此外,GPU+高带宽存储(high bandwidth memory, HBM)已成为化解E级计算访存墙问题的主流解决方案.HBM颗粒针对数据与命令信号设计了冗余微凸点,可以在发生故障时,为HBM堆叠芯片提供冗余互连通道,提高芯片可靠性.未来需要研究采用更为有效的故障避错与容错技术,构建稳定鲁棒的存储系统,确保E级计算机系统稳定可靠运行.
5.2 可用性技术
5.2.1 轻量级修复技术
轻量级修复是一种能够在环境发生软硬件故障时快速恢复的技术.局部硬件复位是在计算核、计算阵列等局部硬件故障时软件驱动的快速修复方法,通过局部复位来避免全芯片复位,以降低系统开销,对于网络设备或端口故障,也可以采用类似的快速化局部复位修复机制.在发生软环境故障或异常时,则可以通过虚拟机或容器的重置与接管来避免硬件初始化的开销,从而快速将软件环境恢复至可用状态.
5.2.2 应用级容错算法与模型
基于数据冗余分布的新型容错算法[31]与模型、基于进程和线程级的任务冗余机制等是近年来发展迅速的应用级局部故障容错技术,值得密切关注.同时,针对大规模系统中广泛使用的保留恢复技术容错成本高、效率低的问题,业界研究提出了基于多混合存储介质和数据压缩算法等多级检查点技术,有效降低容错开销,提高容错算法与模型的实用性.
6 结束语
故障失效成为高性能计算机系统的普遍事件.本文针对神威太湖之光超级计算机系统可靠性与可用性开展全面的研究分析.系统提出神威太湖之光超级计算机可靠性增强技术,分析系统失效与故障间隔时间分布特性,开展系统故障经验数据与典型寿命周期分布数据拟合度分析.系统故障统计数据表明:计算节点是神威太湖之光超级计算机硬件系统失效的主要来源,对系统可靠性具有最重要的影响作用.由最大似然估计与K-S检验可以看出,对数正态分布与系统故障经验数据取得了较好的拟合度,进而建立神威太湖之光系统失效分布模型,通过计算故障间隔时间的数学期望值,得到系统平均无故障时间.设计提出了故障预测、主动迁移与局部任务降级等主被动容错技术,建立多层次主被动统一、软硬件协同的容错系统.系统容错数据库统计数据与课题测试结果表明:系统故障预测平均准确率约70%,主动迁移容错时间开销可控,系统应用可感知的平均无故障时间可提升约1倍,局部降级容错对作业规模不敏感,可以有效控制故障的影响范围,平均单个节点故障导致的应用课题容错损失可降低90%以上.通过有效协同多种容错技术,显著提升神威太湖之光超级计算机系统的稳定性与可用性.最后,以神威太湖之光超级计算机可靠性与可用性研究分析为基础,从硬件和软件2个层次,归纳提出了E级计算机系统高可靠与高可用技术发展建议.后续我们将继续针对系统级高效容错机制开展研究分析.
猜你喜欢
凤凰动漫(军事大王)(2022年9期)2022-11-05
现代计算机(2021年14期)2021-11-20
福建中学数学(2021年3期)2021-03-01
中国计算机报(2020年8期)2020-03-25
中国计算机报(2018年42期)2018-01-31
文史春秋(2017年9期)2017-12-19
中国教育信息化·基础教育(2016年4期)2016-05-30
