
多尺度通道注意力融合网络的小目标检测算法
2021-12-13 12:54李文涛
计算机与生活 2021年12期
李文涛,彭 力
物联网技术应用教育部工程研究中心(江南大学 物联网工程学院),江苏 无锡 214122
小目标检测在日常生活中扮演着极为重要的角色[1-3],如无人机航拍领域、遥感图像、无人驾驶汽车对周边较远较小目标的检测以及工业领域对产品微小瑕疵的检测等。当前计算机领域对小目标物体还没有一个严格的定义与区分,每个数据集对小目标的像素划分也不尽相同。本文按照主流的小目标定义[4-5],规定图像中尺寸小于32×32 像素的物体为小目标。当前,目标检测领域对大中目标的检测效果已经达到了很高的水平[6-7],但是小目标因为其分辨率低,图像模糊,携带的信息少,所以导致特征表达能力弱,其检测已经成为目标检测中的一大难题。
目标检测领域发展了几十年,传统的基于手工设计特征的目标检测算法如Haar(joint Haar-like features)[8]、HOG(histograms of oriented gradients)[9]等由于其准确性低、鲁棒性差而逐渐被淘汰。随之而来的是近些年蓬勃发展的基于深度学习的各种神经网络算法,这些算法在缩短检测时间的同时大大提高了检测精度。基于卷积神经网络的检测算法大概可以分为两类,one-stage(单步)算法和two-stage(双步)算法。two-stage 检测算法将检测任务分成了两步,第一步生成候选区域,第二步对选出的候选区域进行分类预测,采用这种方式虽然牺牲了速度,但检测的精度较高。比较有代表性的是Girshick等人提出的R-CNN(region-based convolutional networks)[10]和Fast R-CNN(fast region-based convolutional networks)[11],以及Ren 等人提出的Faster R-CNN(faster region-based convolutional networks)[12]检测算法,均取得了很好的检测效果。
One-stage 类检测算法直接对不同区域的候选框尺度和长宽比进行预设,然后分类与回归,速度快,精度低。2016 年,Liu 等人提出利用不同尺度特征进行特征提取融合的SSD(single shot multibox detector)[13]算法,首次实现了精度与速度的相对平衡。其利用多尺度特征进行小目标检测,但是由于使用的低层特征图的感受野不够小,导致SSD 算法对小目标检测效果较差。很多学者研究了基于SSD 模型的小目标检测算法并进一步做出了改进。Fu等人提出了DSSD(deconvolutional single shot multibox detector)[14]模型,利用残差网络,同时增加了反卷积模块来融合上下文信息,但是由于计算量大无法实现实时性的目标检测。Jeong 等人提出了RSSD(rainbow single shot multibox detector)[15]模型,通过反复堆叠池化和反卷积的操作来融合不同特征图,检测性能与DSSD 持平。Li 等人提出了FSSD(feature fusion single shot multibox detector)[16]算法,通过建立一个轻量级的特征融合模块提高了与浅层特征的交互能力,速度和精度都得到了提高,但是精度提高有限。
针对上述小目标检测中遇到的问题,本文提出了一种基于SSD 的多尺度通道注意力融合网络的小目标检测算法。首先,针对小目标存在的特征不足情况设计出了一种基于K邻域的局部通道注意力模块,实现特征通道间的信息交互,通过对每个通道的特征进行权重分配来学习不同通道间特征的相关性和重要性。其次,为了能有效地把信息融合起来,构造了Bottleneck 模块,通过在卷积神经网络中加入该模块来实现更好的特征融合,利用网络低层和高层的特征进行多尺度检测,提高了小目标检测的精度。同时将基础网络由原来的VGG16 替换为特征表达能力强和速度快的ResNet[17],在获取更多网络特征的同时保证了网络的收敛性。损失函数采用在标准交叉熵损失函数基础上修改得到的Focal Loss[18],通过减少易分类样本的权重,使得模型在训练时更关注于难分类的样本。实验结果表明,该算法在提升整体检测精度的同时保证了速度,并且对小目标的检测能力有了较大的提高。
1 改进方法
1.1 基础网络
目标检测算法中通常会选取在分类任务中表现较好的网络模型作为其基础网络,基础网络完成大部分特征提取的任务,对目标检测的性能有非常大的影响。卷积神经网络能够提取低、中、高层的特征[19],网络的层数越多,意味着能够提取到的特征越丰富,目标检测需要提取更多的特征信息使得对目标的分类更加精准。但是简单的直接增加网络层数会存在信息丢失、损耗问题,导致梯度爆炸。ResNet 残差网络的残差单元解决了由网络深度增加导致的退化问题,使网络深度得到大幅增加,拥有更多的特征信息,提高了网络对小目标的识别和分类能力,因此本文将其作为基础网络。
1.2 损失函数
卷积神经网络在进行前向传播阶段,依次调用每个网络层的前向传播函数,得到逐层的输出,最后一层与目标函数比较得到损失函数,计算误差更新值,通过反向传播逐层到达第一层,所有权值在反向传播结束时一起更新。一个好的损失函数可以让预测值一直逼近真实值的效果,当预测值和真实值相等时,损失最小。本文采用He 提出的焦点损失函数Focal Loss,真实目标预测概率公式定义如下:

这里以二分类为例,y表示label,y的取值为1和-1,p表示预测样本属于1 的概率,1-p表示预测样本属于-1 的概率。损失函数如下:
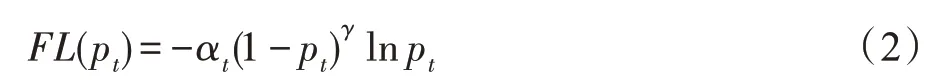
目标检测中存在着难易样本不平衡问题,易分类样本对模型来说是一个简单样本,模型很难从这个样本中得到有用的信息,难分类样本对模型来说是一个困难的样本,它产生的梯度信息会更丰富,指导模型优化的方向。然而易分样本数量在总体样本中占有绝对优势,即使单个样本损失函数较小,累计的损失函数会主导损失函数,但这部分引导的参数更新不会改善模型的判断能力。难分类样本占总体样本的比例较小,训练贡献低,导致训练效率变低,甚至模型不能收敛。本文使用的Focal Loss 损失函数很好地解决了这个问题,在式(2)中,当pt趋向于1的时候,此时分类正确而且是易分类样本,调制系数(1-pt)γ趋于0,也就是对于总的损失贡献很小。当pt<0.5 时,此时为困难样本,即难分类样本,(1-pt)γ趋于1,对于总的损失贡献大,这样的话困难样本的权重就相对提升了很多,增加了那些误分类的重要性。其中,可以通过设定αt的值来控制正负样本对于总的损失的共享权重,αt取比较小的值来降低负样本的权重。本文损失函数参数取γ=2,αt=0.25。
通过这个损失函数可以解决目标检测中的难易样本不平衡问题,减少了易分类样本的权重,使得模型在训练时更关注于难分类的样本。在消融实验中,Focal Loss 损失函数对比SSD 原始损失函数将mAP 提高了0.24 个百分点,取得了更高的精确度。
1.3 K 邻域通道注意力模块
在进行特征图融合时,采用的是Concat(串联)操作,但是Concat 操作只是在通道维度上将特征连接,不能反映出不同通道间特征的相关性和重要性。为了能使网络自动学习特征图通道之间的相关性和重要性,本文采用了一种不降维的K邻域通道注意力模块(K-neighbor channel attention module,KNCA)。现有的注意力模块为实现更好的性能,加入了大量的参数计算,增加了模型的复杂性[20-21]。KNCA 模块则没有采取降维和全部通道进行关联的做法,在大大降低了复杂度的同时提高了模型的检测性能。
如图1 所示,KNCA 模块首先对输入特征块的每个通道分别进行不降低维数的全局平均池化GAP 操作,输出维度为1×1×C的特征图,此输出特征图反映了全局的感受野。然后通过卷积核为K的Conv1d(一维卷积)操作来捕获每个通道及其K个通道邻域之间的局部交互信息。利用Sigmoid 激活函数输出维度为1×1×C的权值。接着对输入的特征图与激活函数得到的权值进行乘积运算,从而对各通道特征进行权值重新分配。KNCA 模块可以使网络自动地学习特征通道之间的相关性和重要性。在获取通道信息时,捕获所有通道之间的依赖是低效而不必要的,这在后面的对照实验中有所体现。需要注意的是,本文的KNCA 模块可以通过大小为K的一维卷积来有效实现,其中卷积核大小为K,代表了局部跨通道交互的覆盖率,即该通道及附近共K个通道参与了这个通道的注意力预测。图2 直观展示出了加入KNCA 模块前后卷积神经网络学习到的特征,该模块促进了各通道间信息交流,使得特征块各个通道不再是一个个独立的个体,信息关联加强了目标整体特征对最终模型检测结果的贡献,对目标检测提升效果显著。
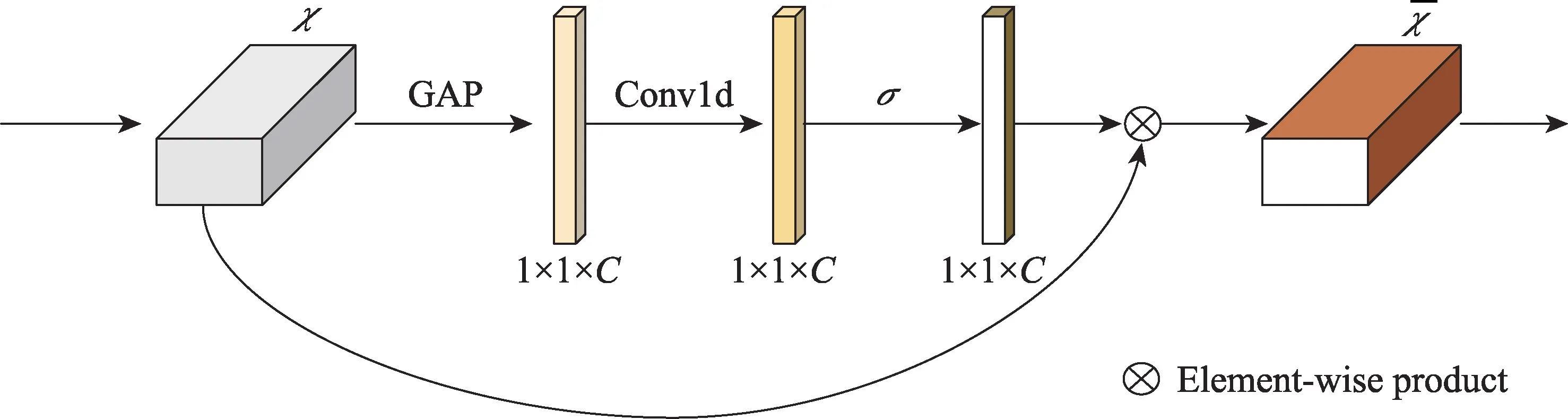
Fig.1 K-neighbor channel attention module structure图1 K 邻域通道注意力模块结构图

Fig.2 Heat maps before and after adding K-neighbor channel attention module图2 K 邻域通道注意力模块添加前后热力图
KNCA 模块的通道权重公式可以表示如下:
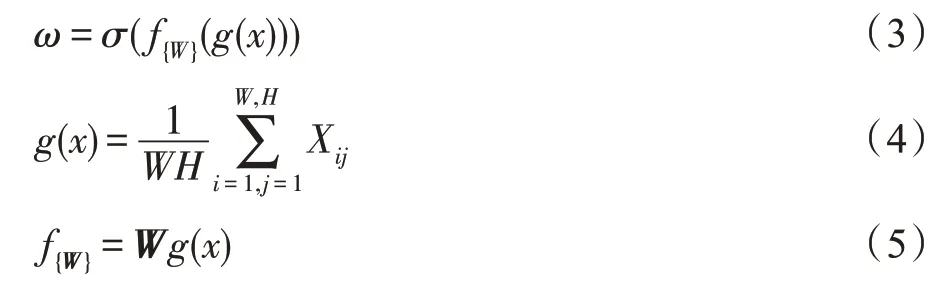
其中,g(x)代表通道级的全局平均池化GAP 操作,式(4)中W和H分别代表特征块的宽和高,其余的W均表示为一个C×C的参数矩阵,f{W}为K个通道邻域的交互函数,σ代表Sigmoid 函数。
现令y=g(x),则ω=σ(Wy),对于每一个通道权重:
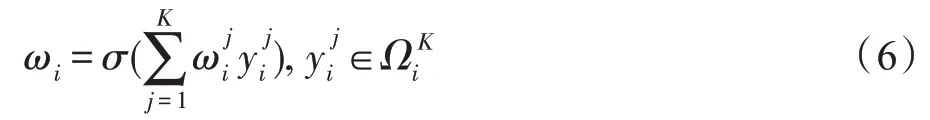

此时,该算法可以由一个卷积核为K的一维卷积实现,公式进一步简化为:

式中,Conv1dK代表卷积核为K的一维卷积。卷积核K计算公式如下:

其中,Nin=Nout,S=1,故K=2P+1 为奇数,卷积核的大小K对KNCA 模块有一定的影响,分别取K值为3、5、7 进行对比,选取最优的邻域K值,在消融实验中,K=3 时模型取得了最好的效果。
1.4 特征融合模块
在一个多层卷积神经网络中,低层的特征往往能很好地表示图像的纹理、边缘等细节信息,而越往高层走,随着神经元感受野的扩大,高层的特征往往能很好地表示图像的语义信息,相应的就会忽视一些细节信息[22]。为了进一步验证这个结论,把ResNet卷积神经网络不同深度的特征层提取出来,进行了特征图可视化。从图3 的可视化特征图中可以看出,低层网络提取的是小目标检测更关注的纹理、细节特征等细节信息,高层网络提取的是轮廓、形状特征等语义信息。小目标的检测需要更多的细节信息,因此本文在对特征图进行融合时既考虑了包含细节信息的低层特征图,又结合了包含语义信息的高层特征图。选取ResNet 的Conv3_4、Conv4_23 和Conv5_3层特征图,首先通过双线性插值法对特征图尺寸进行统一,然后利用Concat 操作将各深度的特征融合。但是Concat 操作只是在通道维度上将特征连接,不能反映出不同通道间特征的相关性和重要性。在特征图尺度缩减的同时为了使网络自动学习特征图通道之间的相关性和重要性,设计了包含通道注意力机制的Bottleneck 模块,利用该模块对融合后的特征块进行尺度缩减得到7 组尺度不同的特征图,共利用7 组特征图构建多尺度检测网络。
在对特征图进行尺度缩减时设计的Bottleneck模块结构如图4 所示。图中的第一个Conv1×1(卷积核为1 的二维卷积)的作用是对输入特征图进行降维,以降低计算量。BatchNorm(批归一化)可以加快网络的训练和收敛速度,防止梯度消失,对于网络比较深的ResNet 非常合适,加入BatchNorm 后还可以适当增大学习率,加快训练速度。ReLU 层的作用是增加神经网络各层之间的非线性关系,避免过拟合问题的发生。Conv3×3(卷积核为3 的二维卷积)的作用是使输入特征图的尺度减半,得到不同尺度的特征图。第二个Conv1×1 的作用是升维,返回输入时的特征维度,以减少原特征图特征信息的损失。KNCA模块即K邻域通道注意力模块,该模块增加了特征图不同通道之间特征的相关性,提高了小目标的检测准确率。
目前特征融合的方法手段很多,Faster R-CNN 算法仅对最后一个特征块进行预测,虽然包含了高层特征,但是低层特征信息没有被使用,在消融实验中检测精度仅为73.2%。SSD 算法采用了特征图大小递减的特征金字塔对不同尺度特征进行预测,效果得到提高,但对低层特征的关注度还是不够,检测精度为77.2%。DSSD 采用了特征图大小先递减后反卷积递增的特征金字塔融合方式,融合过程复杂耗时,检测速度为13 frame/s。本文仅先对3 个不同深度的特征块进行串联,得到一个融合特征块,再从这个特征块得到不同尺度的特征金字塔进行预测,检测精度为82.7%,速度为30 frame/s。

Fig.3 ResNet visualization feature map图3 ResNet可视化特征图
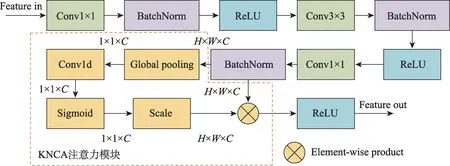
Fig.4 Bottleneck module structure图4 瓶颈模块结构图
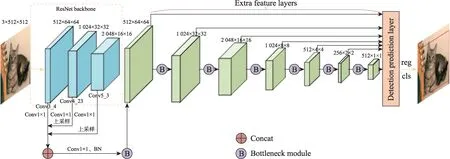
Fig.5 Overall algorithm structure of this paper图5 本文整体算法结构图
图5展示了本文整体算法结构图,首先选取ResNet的第三、四、五层卷积块后的特征图,大小分别为64×64、32×32、16×16,通过选取3 个不同尺度特征图组成的密集块,在接下来的Concat 操作中对不同尺度的特征信息进行融合,提升了以低层特征为主要检测依据的小目标检测精度。然后对第一组特征图采用Conv1×1 进行降维,第二组和第三组特征图先降维再进行上采样,这里上采样选取双线性插值法,使3 组特征图的尺度相同。这样接下来就可以进行Concat操作,将3 组特征图进行串联操作,尺度不变,通道数相加。合并为一组特征图后,采取Conv1×1进行降维和BN 即BatchNorm 进行加速训练,防止梯度消失。然后,基于该组特征图依次进行尺度缩减,获取检测用的不同尺度的特征图。这里利用了刚才提出的Bottleneck 模块,其中的降维操作有效降低了训练参数,减少了训练时间。位于Bottleneck 模块中的KNCA 注意力模块促进了通道间的信息流通,增加了特征图不同通道之间特征的相关性。最终得到了7组特征图,尺寸分别为64×64、32×32、16×16、8×8、4×4、2×2、1×1,将这7 组特征图送入预测模块,进行分类与回归,得到预测结果。
2 实验结果与分析
本文使用两类不同的数据集对算法的精确性和有效性进行验证:第一类VOC 数据集,包括PASCAL VOC[23]-2007 公共数据集和PASCAL VOC-2012 公共数据集;第二类为自建的航拍小目标数据集[24]AP(aerial photography)数据集。VOC 数据集中包含人物、动物、交通工具、生活用品等20 类常见目标,其中PASCAL VOC-2007包含9 963张图片,PASCAL VOC-2012 包含12 031 张图片。AP 数据集中有22 761 张来自不同传感器和采集平台的航拍样本,包含了车辆、船舶、飞机等13 类小尺度目标。
训练时为了防止过拟合现象的发生,在训练前先对输入图片采取了数据增强,包括对图片平移旋转、灰度变换、随机裁剪和尺度变换等操作,增强模型的鲁棒性。图片的先验框长宽比为2 和3,7 张特征图的先验框数量分别为4、6、6、6、6、4、4。
本次训练基于Pytorch1.0 框架,计算机操作系统为64 位的Ubuntu16.04,内存16 GB,处理器为Intel®CoreTMi5-8500@3.00 GHz 六核,显卡为一块英伟达GTX 1080Ti,显存11 GB。训练参数方面,batch size设置为8,maxiteration 设置为60 000,动量为0.9,权值衰减为0.000 5。初始学习率为0.000 35,前500 个iteration 是热身阶段,学习率逐渐增长,该操作有利于模型更快收敛。之后保持0.001 的学习率,当iteration是36 000 和48 000 时,学习率分别乘以0.1。
本文提出的多尺度通道注意力融合小目标算法在PASCAL VOC-2007 和PASCAL VOC-2012 训练集上训练60 000 iteration 时,训练时的损失函数曲线和测试集mAP 曲线如图6 所示。
首先对算法各模块进行了对照实验,此时训练maxiteration 为200 000,其中包括KNCA 注意力模块的使用与否;fusion module特征融合模块的使用与否;Focal Loss 焦点损失函数的使用与否;fusion method 3 张特征图进行融合时的方法选择,有Concat 和Element-wise[25]sum(元素级求和)两种特征图融合方式;scale reduction 尺度缩减方法选择,对比第一种仅使用Conv3×3 进行尺度缩减,第二种先使用Conv1×1进行降维再使用Conv3×3 进行尺度缩减和升维,第三种就是本文提出的Bottleneck 模块;KNCA 模块中邻域K的大小选择,本文测试了K=3,5,7 时的mAP精确度。算法各模块在VOC 数据集上的检测结果如表1 所示。
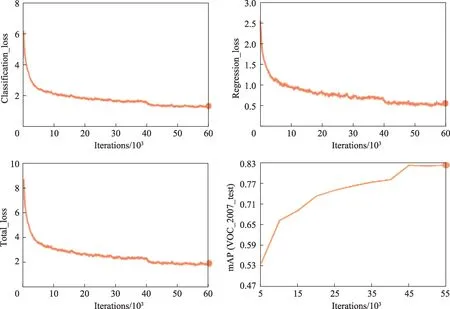
Fig.6 Loss function convergence curve and mAP curve of algorithm in this paper图6 本文算法的损失函数收敛曲线和mAP 曲线
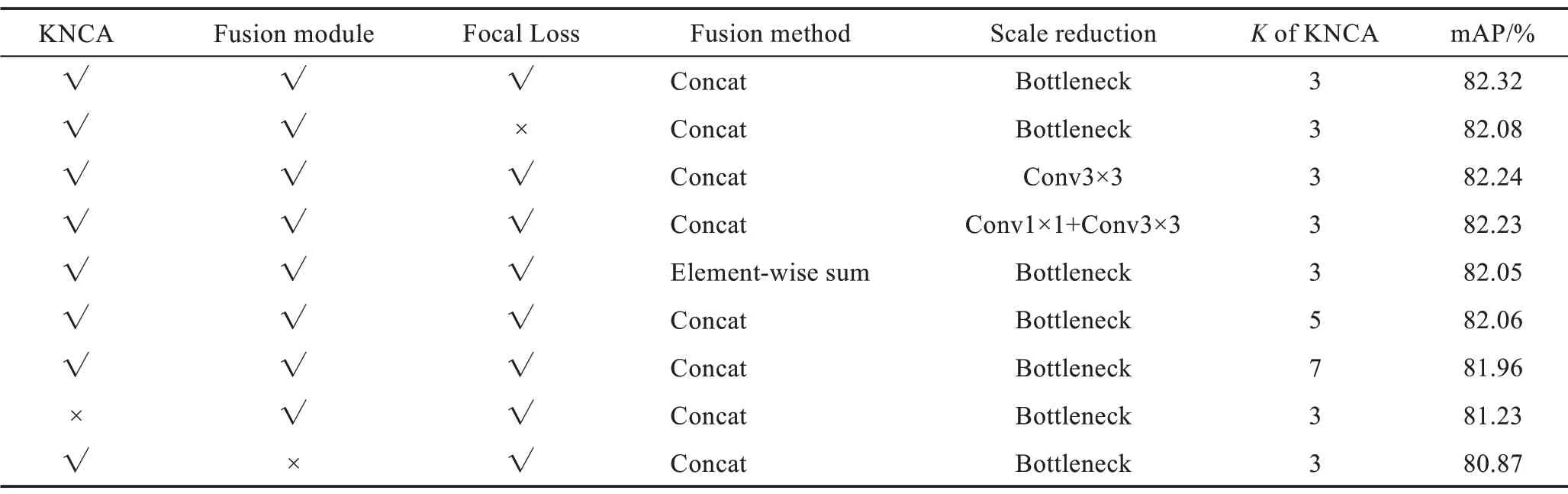
Table 1 Detection results of each module of algorithm on VOC data set表1 算法各模块在VOC 数据集上的检测结果
对比表1 中的第1 行和第2 行数据可以看出,在使用Focal Loss 后确实带来了mAP 精确度的提升,提升了0.24 个百分点,原因在于Focal Loss 解决了训练时的正负样本不平衡问题。对比表中的第1、3、4 行结果,可以发现尺度缩减方式对模型的影响较小,在0.1 个百分点左右。采取单独一个Conv3×3 或者是Conv1×1 和Conv3×3 组合的方式都没能改善模型的性能,同时两者效果差不多。本文提出的Bottleneck模块取得了较好的效果,因为该模块首先进行了降维,降低了计算量,最后进行升维,保证了原特征图的特征信息不会丢失。第1 行和第5 行对比了特征融合模块中3 组特征块进行信息融合的方式,第5 行所采取的Element-wise sum 特征融合方法是将3 组特征图对应元素分别进行加和的方式,这种方式会得到新的特征,这个新的特征可以反映原始特征的一些特性,但是原始特征的一些信息会在这个过程中损失,然而Concat 操作是直接对原始特征进行串联,让网络去学习如何融合特征,不会造成信息的损失。通过实验对比可以看出,Concat操作的检测精确度更高,因此本文选择了Concat操作来对3 组特征块进行融合。由第1、6、7 行可以看出,随着KNCA 模块中邻域K的增大,模型的精度越来越低,过多的通道之间的交互确实是低效且不必要的,这里选取K=3能取得最优的效果。第1 行和最后两行的对比较好地展示了KNCA 注意力模块和特征融合模块对目标检测性能的重大影响,检测精确度均提高了1~2 个百分点。KNCA 注意力模块对通道间信息的关注和特征融合模块对低层高层特征信息的融合都能很好地改善目标检测中小目标信息缺乏的问题。
PASCAL VOC 数据集上各算法性能对比如表2所示。PASCAL VOC-2007 测试集上测试得到的mAP 为82.7%,相比SSD 算法有5.5 个百分点的提升,较DSSD 算法的mAP 提高了4.1 个百分点。本文算法在检测鸟、瓶子等小目标时,检测效果明显优于其他算法。
由于拍摄位置的原因,航拍数据集AP 的侧重点更偏向于小目标,且其场景更复杂,目标尺度变换较大。表3 显示了本文在AP 数据集上的检测表现,可以看出,本文所提出的小目标检测算法性能指标明显高于其他几种算法,进一步展示了本文在小目标检测方向所做出的改进成效显著,具备了大部分小目标检测场景的精度要求。在所引用的航拍数据集中的mAP 为86.8%。
为了更直观地分析本文的检测结果,图7 和图8分别可视化地展示出了一些PASCAL VOC-2007 测试集和航拍测试集上的检测结果。将SSD 目标检测算法和本文算法检测效果进行了对比,可以发现,在图片中具有多个小目标的情况下,本文算法检测出的目标数量和精确度均领先于SSD 检测算法,取得了更好的小目标检测效果。
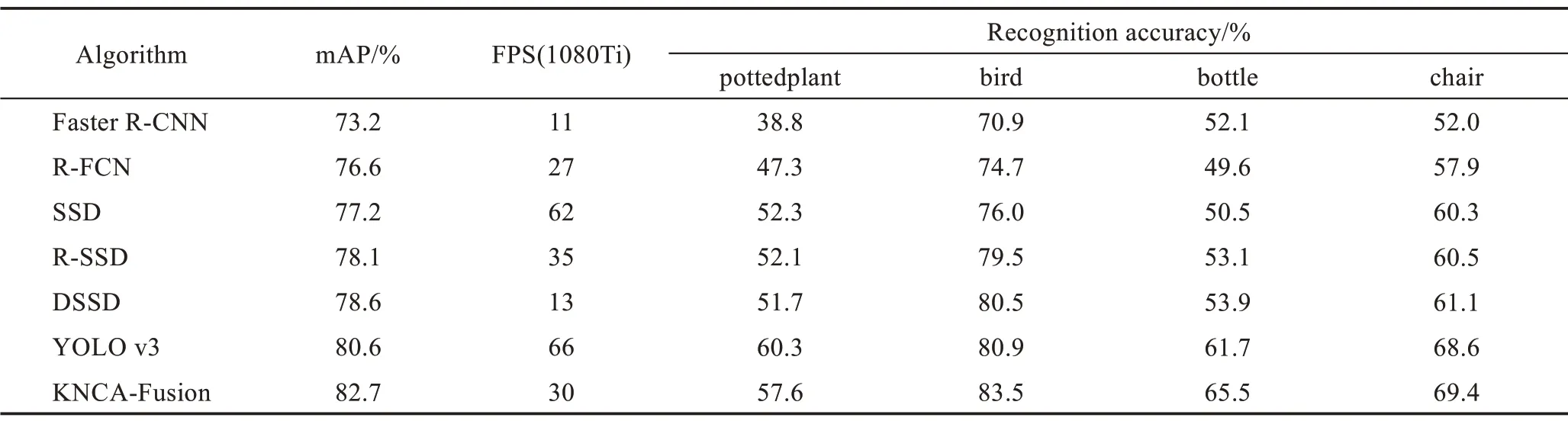
Table 2 Performance comparison of algorithms on PASCAL VOC data set表2 PASCAL VOC 数据集上各算法性能对比

Table 3 Performance comparison of algorithms on aerial photography data set表3 AP 航拍数据集上各算法性能对比

Fig.7 Comparison of SSD and proposed algorithm on PASCAL VOC data set图7 SSD 和本文算法在PASCAL VOC 数据集上对比结果

Fig.8 Comparison of SSD and proposed algorithm on aerial photography data set图8 SSD 和本文算法在航拍数据集上对比结果
3 结束语
本文针对目标检测中的小目标信息缺失、检测精度低的问题提出了K邻域通道注意力模块(KNCA)。通过对特征图特征通道权重的重新分配有效地增强了小目标的特征信息。同时提出了基于Bottleneck 模块的特征融合网络,该网络先对浅层和深层特征进行融合,再结合降维和尺度缩减的方式获得多尺度特征图,降低了模型的复杂度和计算量。并且,检测模型将ResNet 和Focal Loss 结合在一起,丰富了网络的特征信息且避免了训练时难易样本不平衡的问题。通过在PASCAL VOC 数据集和AP 航拍数据集上的训练测试,本文算法在保证检测速度的情况下检测精度取得了大幅提高。
猜你喜欢
农业工程学报(2022年12期)2022-09-09
社会科学战线(2022年7期)2022-08-26
计算技术与自动化(2022年1期)2022-04-15
北京航空航天大学学报(2021年9期)2021-11-02
北京航空航天大学学报(2021年9期)2021-11-02
领导决策信息(2018年16期)2018-09-27
人大建设(2017年10期)2018-01-23
数学学习与研究(2017年3期)2017-03-09
中国信息化周报(2015年1期)2015-04-09
时代英语·高三(2014年5期)2014-08-26
