
利用序列分析的远控木马早期检测方法研究
2021-12-13 12:54申国伟崔允贺
计算机与生活 2021年12期
王 晨,郭 春+,申国伟,崔允贺
1.贵州大学 计算机科学与技术学院,贵阳 550025
2.公共大数据国家重点实验室,贵阳 550025
远控木马(remote access Trojan,RAT)作为一类危害性极大且知名度极高的恶意程序,主要被用于控制目标主机、监控受害者的主机行为以及窃取机密信息等[1]。CNCERT 发布的2019 年度报告[2]指出,我国境内感染计算机恶意程序的主机数量约582 万台;ProofPoint 在其2019 年Q3 威胁报告[3]中显示,尽管恶意程序数量呈现整体下滑趋势,远控木马的数量相比第二季度却增长了55%。由此可见,远控木马相比于其他类型的恶意程序仍在高速增长,俨然成为了互联网所面临的主要安全威胁之一。
与勒索软件等以破坏信息系统可用性为主的恶意软件不同,远控木马以破坏信息系统机密性为主,其集成了键盘记录、文件上传和下载、系统信息窃取、桌面/摄像头监控、进程与注册表修改以及文件读写等一系列危险功能。远控木马被攻击者通过各种手段植入到目标主机后进行潜伏,待接收相关指令后向攻击者返回指令执行结果。由于远控木马具有高隐蔽性的特点,其常被用于APT(advanced persistent threat)攻击[4]的后渗透阶段以窃取机密信息。
为应对远控木马所引发的安全威胁,近年来国内外研究者提出了一系列远控木马检测方法。基于网络流量的检测方法是现阶段远控木马检测方法的主流[5-8],但是这类方法中大多使用从整条流中提取的统计特征,对木马通信流的完整性要求较高,致使可能出现在检测到远控木马流量的同时,被控主机已然执行部分攻击指令而泄露了隐私信息。因此,实现对远控木马的有效防御,对检测方法的检测及时性有着很高的要求。
为及时检测远控木马流量,从远控木马控制端和被控端建立会话后初期的流量中提取特征是一个可行思路。然而,若从远控木马会话建立后初期的流量中所提取的特征不能较好地反映木马的通信行为,则基于这些特征的检测方法容易出现较高的漏报率或误报率。针对上述情况,本文分析了远控木马会话建立后初期的网络流量行为,发现其控制端和被控端通常会在该时间段中出现不涉及人为操作而自动进行的、较为固定的数据包交互行为,且该行为与正常应用同时期的流量存在明显的差异。基于上述分析结果,本文提出了一种利用序列分析的远控木马早期检测方法。该方法针对远控木马会话建立后初期流量中的“上线包”及其后少量数据包所提取的包负载大小序列、包时间间隔以及包负载上传下载比三个特征,运用机器学习算法建立木马检测模型实现对远控木马的早期检测。
本文主要工作如下:
(1)对35 个远控木马与12 个正常软件的通信行为进行实验分析,通过比较远控木马和正常软件各自通信会话建立后初期的流量,发现它们在数据包负载大小、数据包时间间隔等方面存在明显区别,并进一步分析了远控木马通信会话建立后流量中首个具有较大负载的数据包(“上线包”)及其后数个数据包所具有的特性。
(2)基于远控木马和正常软件在会话建立后初期通信流量的差别,提出了一种利用序列分析的远控木马检测方法。该方法使用从“上线包”及其后少量数据包的负载大小序列与时间间隔序列中提取的三个特征,结合机器学习算法实现对远控木马的早期检测。
(3)搭建模拟环境对所提出的远控木马检测方法进行了实验测试,并探索了“上线包”后不同的数据包数量对于所提方法检测结果的影响。实验结果表明本文方法能够以通信会话建立后初期的数个数据包实现对已知和未知远控木马的高准确率检测,有助于及时检测出远控木马流量。
1 相关工作
现今远控木马检测方法主要分为两类,即基于主机的检测方法与基于网络的检测方法。
1.1 基于主机的检测方法
基于主机的检测方法主要通过分析木马源代码构建木马特征库以检测远控木马,亦或是在受控环境下(沙箱、虚拟机等)监测远控木马运行时的主机资源消耗情况、注册表编辑、端口隐藏以及关键API调用等敏感行为构建模型进行检测。
Ahmadi 等人[9]通过将程序运行中的API 调用转化为灰度图并运用图像识别相关技术来检测木马。Rhode 等人[10]通过收集恶意程序在沙箱中运行的早期行为来进行恶意程序判别。Canali 等人[11]基于n-gram 模型提出了一种木马程序的检测方法。基于主机的检测方法需要将检测系统部署在主机上,除了占用一定主机资源之外,还需要涉及对操作系统的底层操作,可能对主机的稳定性造成一定影响。并且随着隐蔽技术在远控木马中的应用及发展,基于主机的检测难度逐渐增加。
1.2 基于网络的检测方法
早期基于网络的检测方法通常采用报文负载匹配技术,提取数据包负载与木马特征库进行匹配以检测远控木马。该类检测方法检测速度快,同时还能具有较高的准确率,但是基于报文负载匹配方法的识别能力依赖于特征库的完备程度,且只能检测已知木马[12]。因此,基于通信行为分析的检测方法更受现阶段远控木马检测研究者的青睐,在网络入侵检测方法[13-14]中也常被运用。
李巍等人[15]通过分析远控木马的通信行为,将远控木马运行过程分为建立连接、命令控制与保持连接三个阶段,从每个阶段中提取不同的统计特征并结合C4.5 算法实现检测。该方法需要使用完整的数据流,因而其检测存在一定程度的滞后,这也是现今很多远控木马检测方法都存在的问题。姜伟等人在文献[16]及文献[17]中设计了一种基于异常网络行为的远控木马检测模型,但该方法同样需要使用较长的通信流。Jiang 等人[18]将远控木马通信流量中出现在TCP 三次握手后且相邻数据包时间间隔大于1 s之前的会话定义为早期阶段,从中提取了数据包数量、上下行数据包数量比等6 个统计特征来快速检测远控木马,但该方法的漏报率较高;Adachi 等人[19]在Jiang 研究的基础上将网络会话与主机进程进行关联,增加了4 个特征用于检测远控木马,但是其方法仍存在较高的误报率。宋紫华等人[20]从TCP 会话的前5 个数据包中提取了14 个特征,并以此设计了一种木马快速检测方法,但此方法的检测对象是TCP会话,因此需要对多个TCP 会话进行检测才能识别出具有主从连接的远控木马。Wu 等人[21]受文献[22]的启发,以远控木马的人为控制特性为检测出发点,先对数据流进行切片,再以每个切片中前3 个包的方向序列来判断数据流是否属于远控木马会话,但该方法需要分析每条流中250 个数据包以检测远控木马会话。Pallaprolu 等人[23]从每个数据包中提取出特征向量,并运用集成学习对每个分类器的检测结果进行投票来获得高检测率,但由于该方法以会话中全部数据包为分析对象,需要很长的训练时间和检测时间。
通过对上述文献的分析可知,现阶段基于网络的检测方法大多对数据流的完整性有较高的要求,其检测存在一定程度的滞后;已有的远控木马早期检测方法则较少考虑数据流的序列特性而仅使用统计特征导致误报率较高。因此,本文重点关注远控木马通信会话建立后初期流量的序列特性,旨在高准确率的前提下提高远控木马流量检测的及时性。
2 木马通信行为分析
远控木马包括控制端与被控端,植入受害主机的被控端通常会伴随系统的启动而启动,而攻击者通过控制端发送指令与被控端进行交互。早期的远控木马通常由控制端发出连接请求以连接被控端。但是随着防火墙的广泛应用和发展,越来越多的远控木马采用反弹式连接(即由被控端发起连接请求以连接控制端)来避开防火墙的筛查。如图1 所示,远控木马的运行过程可以划分为建立连接、命令交互和保持存活三个“阶段”。在建立连接阶段,被控端与控制端通过TCP 三次握手完成连接,之后被控端会主动回传受害者的上线信息;命令交互阶段中部分木马会在主连接存在的情况下建立次连接用于执行指令与回传结果;而在保持存活阶段,攻击者通过设计心跳行为来保持连接,部分木马的心跳包会以固定模式贯穿远控木马整个通信周期。
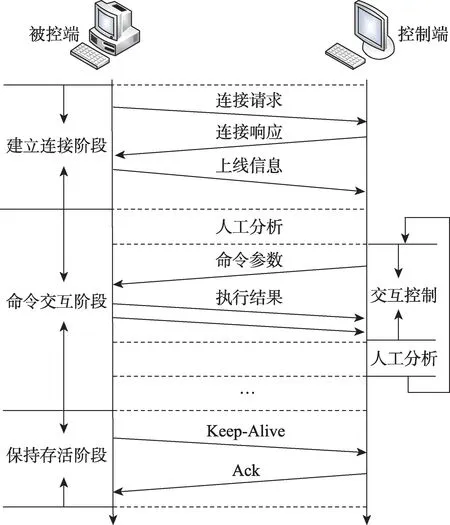
Fig.1 RAT communication flow chart图1 远控木马的通信流程图
据实验观察,远控木马建立连接阶段流量具有以下特性:远控木马为了逃避网络监控软件的查杀,通常会尽可能减少被控端与控制端的交互来隐藏自己,这使得远控木马在会话建立后初期传输的数据量不会太多;建立连接阶段被控端需要反复发出连接请求直至控制端对其进行响应,之后被控端将收集到的受害者主机信息主动回传给攻击者,这种回传信息的数据包的负载通常较大,与该阶段其余的数据包负载大小存在明显区别。本文将由{源IP 地址、目的IP 地址、传输层协议}三元组确定的网络通信流定义为IP 会话,并将IP 会话的第一条TCP 流中由内部主机向外部网络发送且数据包传输层负载大于α字节的第一个数据包定义为信息回传包,也称为上线包。表1 统计了35 个远控木马在建立连接阶段的上线包的负载大小情况,这些远控木马均使用TCP 协议进行信息回传。
由表1 可知,上线包的负载在远控木马建立连接阶段的数据传输总量(不含三次握手)中占了极大比重,且orion、qusar 等远控木马在该阶段只进行了上线操作。如图2 所示,不同远控木马的上线包负载大小因其传输内容不同而不同,为能够全部覆盖本文所分析远控木马的上线包,本文将α设定为60。远控木马被控端向控制端主动发送上线包后,控制端会发送一个ACK 包告知被控端已确认接收,在这之后的数个数据包可能出现在以下不同阶段从而具有不同特性:
(1)建立连接阶段:这些数据包对应控制端自动发出的控制命令或者心跳行为,但是由于该阶段下的所有行为均不涉及人为操作,远控木马发生大数据量交互的可能性较低,因而上线包之后数个数据包的负载大小往往小于上线包的负载大小。
(2)命令交互阶段:攻击者观察到受害者主机上线,在经过一定的人为反应时间后将向被控端发送指令以执行相应攻击操作。由于指令对应的数据包大多只包含少许指令参数,其负载通常较小。

Table 1 Payload of information return packet during phase of connection establishment表1 上线包在建立连接阶段中的负载情况
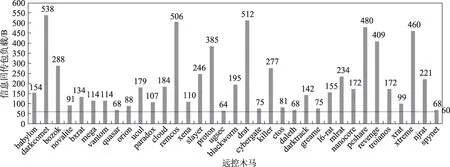
Fig.2 Payload distribution of information return packet of used RATs图2 实验所用远控木马的上线包负载分布
(3)保持存活阶段:出现在该阶段的原因是此时攻击者未能及时观察到被控端上线,通信双方在静默状态下进入了通过心跳包维持通信的保持存活阶段。由于心跳包在大多数情况下不涉及信息交互,其负载通常较小。
由以上分析可知,远控木马在上线包之后的数个数据包倾向于使用小包传输,而正常应用程序为实现资源快速交互会在建立连接后进行大量数据交换行为,其第一个传递数据的“大包”(负载大于α字节,本文方法将其视为正常应用程序的“上线包”)发生之后通常会继续传递大量由正常应用服务端发出的响应信息,由于不需要隐藏自身行为,后续几个数据包的负载通常会很大,这与远控木马形成了鲜明对比。同样,此行为也使得正常程序在这几个数据包的上下行字节比值较小(其中,本文将由远控木马被控端(对应正常应用客户端)向远控木马控制端(对应正常应用服务端)的传输流量统称为上行流量,反之为下行流量),远控木马则与之相反。另外,对于在建立连接阶段仅进行上线操作的远控木马,上线包与其后的数个数据包之间会因人为反应或心跳间隙造成较大的时间间隔,而正常程序在网络不发生堵塞时较少发生该情况。因此,本文在后续章节中将基于远控木马的以上特点进一步分析远控木马通信会话建立后初期流量中的上线包及其之后的数个数据包所具有的特性,对其提取特征并结合机器学习算法建立模型及进行检测。
3 基于序列分析的远控木马早期检测方法
3.1 检测方法
基于第2 章的分析结果,远控木马在建立连接阶段中存在自动且相对固定的数据包交互行为,且该行为与正常应用存在明显区别。如果能在远控木马实现命令交互以获取受害者隐私信息前发现其流量,则能够有效降低受害者隐私泄露的风险。因此,本文在对远控木马通信会话建立后初期的数据包序列进行分析的基础上,运用时序特征与统计特征,提出了一种利用序列分析的远控木马早期检测方法,该方法能够在远控木马会话建立后初期及时且高准确率地检测出远控木马流量。由于部分远控木马存在主从连接的情况,为能够及时检测出木马流量,本文将检测单元设定为IP 会话中的第一条TCP 流,由{源IP 地址、源端口、目的IP 地址、目的端口、传输层协议}五元组确定。如图3 所示,本文所提出的利用序列分析的远控木马早期检测方法首先对数据包进行过滤并抽取通信会话,选取每个会话中的第一条TCP 流,以内部主机向外部网络发送的上线包为标志,加上其后数个数据包共同用于提取时序特征及统计特征,然后运用机器学习算法训练检测模型,最后由训练好的检测模型对待检流量进行判断,以判别该流量是正常应用流量还是远控木马流量。
3.2 特征提取
本文选择上线包及其后续数个数据包的传输负载大小序列、传输字节数和时间间隔作为特征,具体介绍如下。

Fig.3 RAT early detection method using sequence analysis图3 利用序列分析的远控木马早期检测方法
3.2.1 传输负载序列
远控木马在建立连接阶段的主要操作目的是向攻击者传输被控主机信息。据实验分析发现,部分远控木马会在连接建立后主动上传受害者信息;部分远控木马则是在接收到控制端自动发出的请求信息之后再发送上线包;少数远控木马还会在发送上线包之前进行确认版本以及握手等操作,但是相比于上线包,这些数据包由于只传递命令参数其负载往往较小。本文以上线包的大小作为阈值,将包负载字节数小于上线包大小(60 B)的数据包称为小包并记为0,反之则称为大包并记为1。表2 统计了717条正常会话与985 条远控木马会话上线包之后3 个数据包的负载大小序列(Slength)的分布情况,其中正常会话来源于实验室内部主机流量,木马会话包括35 个远控木马的流量,表中序列长度小于3 时表示网络流中上线包后出现的数据包数量不足3 个。可以看出,正常应用所产生的数据包的负载序列多集中在“011”与“11”类型,这与正常应用在建立连接后需要接收来自于服务器的资源响应有关;而远控木马出于对自身隐蔽性的考虑,上线包后的数个数据包多为小包。因此,将上线包后的数个数据包的负载序列作为检测远控木马流量的特征之一。
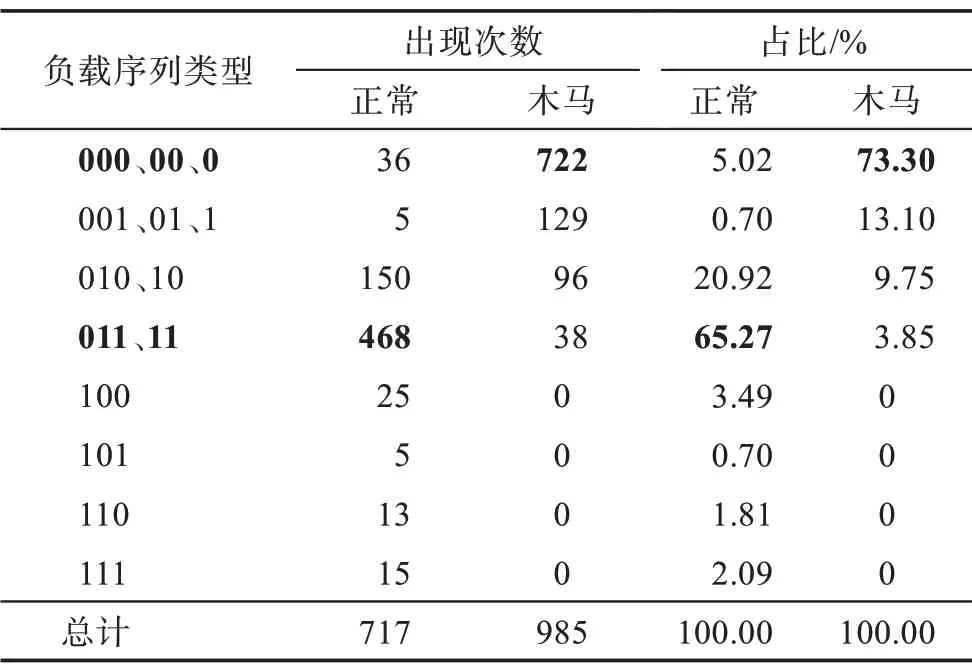
Table 2 Statistics of different software's load sequence times of following three packets after information return packet表2 不同软件的上线包之后3 个数据包负载序列次数统计
为方便机器学习算法进行训练,本文将上线包后的数据包负载大小序列转化为十进制。对一个长度为m的数据包负载序列d={d1,d2,…,dm},将其每个字符di乘以2 的m-i次方后再进行累加,即对应的特征值应表示为:
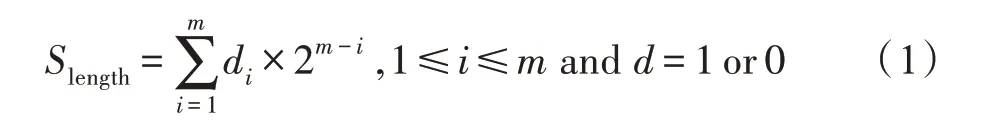
3.2.2 传输字节数
如第2 章所述,远控木马在上线包之后的数个数据包倾向于使用小包传输。因此,远控木马被控端所发出的上线包及之后交互的数个数据包的上下行字节比(Rlength)通常也会较大。图4 展示了4 个远控木马被控端与5个正常应用客户端所发出的上线包及其后交互的3 个包(4Pks)的上下行字节比值。由图4可知,这些木马流量的上下行字节比值在10 左右,而正常应用的该值小于1。这是因为上线包的负载较大,无论远控木马在上线包发出后进入操作状态或静默状态,其后产生的数个数据包对应的控制命令包或心跳包均多为小包;而正常应用行为如浏览网页、观看视频以及下载文件时产生的下行方向的数据包的负载较大,故正常应用在其上线包及之后几个数据包的上下行字节比值较小。
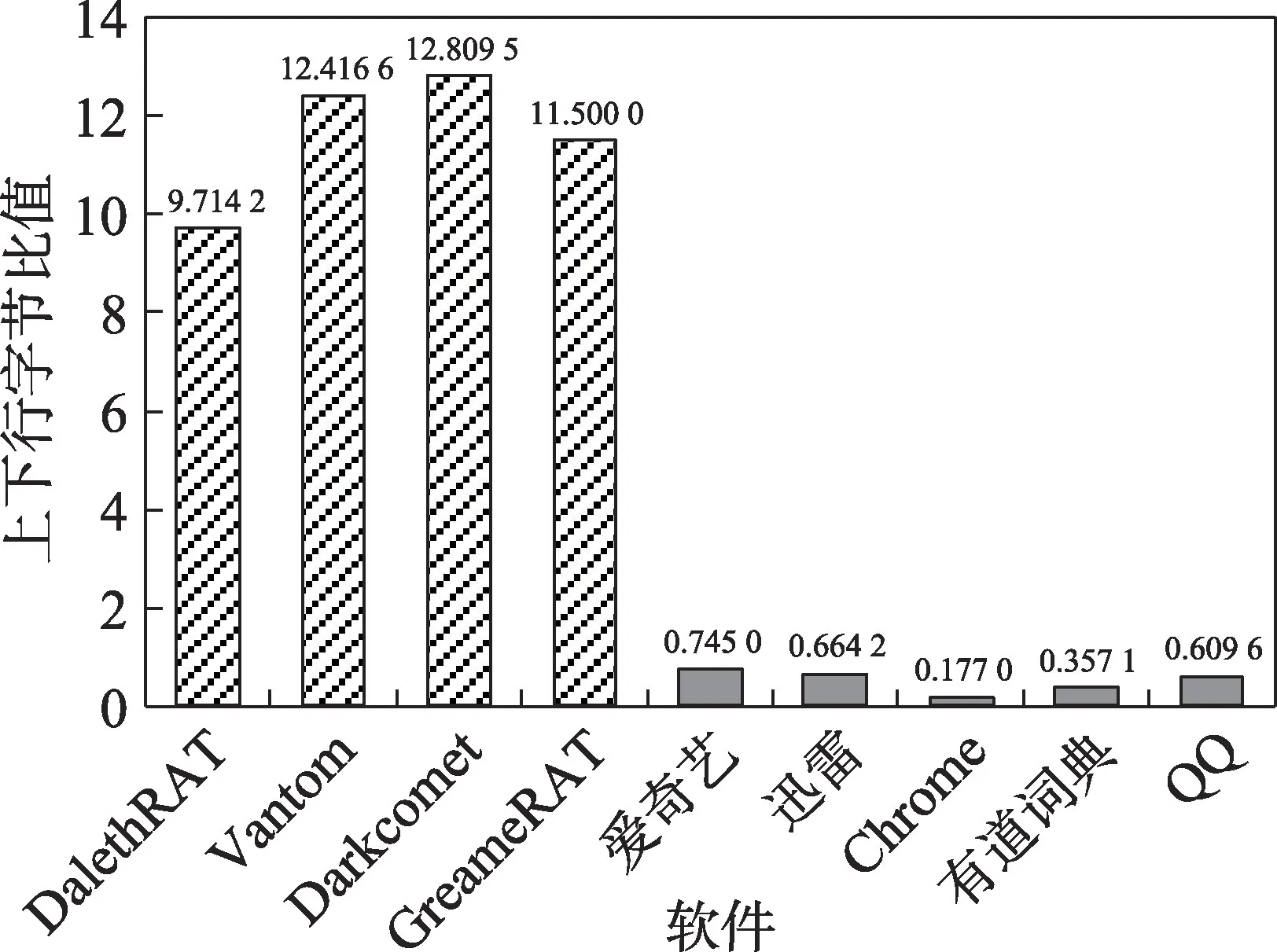
Fig.4 Ratio of different software's upstream and downstream bytes of information return packet and next 3 packets(4Pks)图4 不同软件的上线包及之后3 个数据包(4Pks)上下行字节比
由于本文方法需要使用的数据包数量较少,有可能出现下行数据包负载之和为0 的情况。本文方法在下行数据包负载之和为0 时将选择所有上行数据负载之和作为特征值。对一个长度为m的数据包负载序列d={d1,d2,…,dm},当其上行数据负载总和为Ulength,下行数据负载总和为Dlength,则上下行数据包负载字节比特征值为:
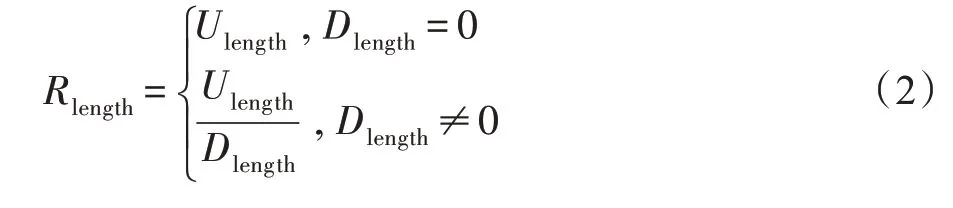
3.2.3 时间间隔
有别于建立连接阶段,远控木马在其命令交互阶段的行为更多包含攻击者的人为控制因素。该阶段攻击者可以通过控制端向被控端发送攻击指令执行恶意操作,包括但不限于下载文件、监控摄像头等,不同的恶意操作对应着不同的指令。通过第2 章的分析可知,部分远控木马在建立连接阶段中仅包含建立连接及上线包操作,之后便进入命令交互阶段或保持存活阶段,但由于远控木马的人为控制特性,在建立连接阶段到进入命令交互阶段或保存存活阶段之间的数据包间会出现相对较长的时间间隔,这是由攻击者需要一定的反应时间或者由攻击者自行设定的心跳间隔所导致的;而正常应用在连接建立初期,其客户端和服务端交互频繁,因此处于该时期的数据包的时间间隔会相对较小。该过程的示意图如图5 所示,远控木马在上线包发出后到接收到控制命令之间需要的攻击者反应时间为t(单位:s),而正常应用客户端在发出资源请求后服务器会很快返回大量的响应数据包。
因此,本文选取上线包及其后数个数据包中最大的一个时间间隔作为特征,记为Tinterval。对一个长度为m-1 的数据包时间间隔序列T={T1,T2,…,Tm-1},其最大时间间隔特征值为:

Fig.5 Comparison of RAT and normal application in data stream transmission图5 远控木马与正常应用数据流传输对比

综上所述,所提方法提取特征的对象为n个数据包(nPks),即上线包及其后续n-1 个数据包,从会话时间与传输字节数两方面提取了三维特征,具体描述如表3 所示。

Table 3 Feature description表3 特征描述
3.3 训练与检测
本阶段的主要工作是基于上述特征提取阶段所得到的特征向量构建一个检测模型用于区分远控木马流量与正常应用流量。为实现该目标,本文通过搭建实验环境采集了多个知名的远控木马流量和正常应用流量,从这些流量中提取传输负载大小序列、传输字节数和时间间隔等特征并添加类别标签(正常流量或远控木马流量)以构建训练集Dtr(Dtr={(x1,Y1),(x2,Y2),…,(xM,YM)},其中Yi∈{正常流量,远控木马流量},xi=(Tintervali,Rlengthi,Slengthi))。然后通过Dtr结合分类算法建立一个远控木马检测模型。为得到高准确率的检测结果,本文分别运用了支持向量机(support vector machine,SVM)、贝叶斯(naïve Bayes,NB)、K近邻(K-nearest neighbor,KNN)、随机森林(random forest,RF)以及决策树(decision tree,DT)5 种分类算法训练检测模型并对其检测结果进行对比。
在检测阶段,训练好的检测模型将对测试集中的每条待检流量进行检测,以判别各条流量属于正常应用流量还是远控木马流量。
4 实验
4.1 实验环境
在搭建实验环境时,为保护内网主机安全,本文将远控木马的控制端安装在具有公有IP 的云服务器上,而被控端安装在局域网内的Vmware 虚拟机中,虚拟机采用Windows 7 操作系统。检测模型所在主机的硬件配置为8 GB 内存,Intel i7-6700HQ 处理器,使用Wireshark 抓包,编程语言采用Python3.7,并使用scikit-learn 0.22.1 库进行检测模型训练。实验拓扑如图6 所示。

Fig.6 Experimental topology图6 实验拓扑
4.2 数据集
本文实验的远控木马程序包括35 个知名远控木马程序:black_worm、daleth、darkcomet、darktrack、killer、nanocore、njrat、pshare、quasar、remcos、revenge、slayer、spynet、troianos、ugsec、babylon、bozok、bxrat、cybergate、greame、mlrat、mega、paradox、ucul、orion、novalite、drat、proton、cloud、l6-rat、ctos、vantom、xena、xrat、xtreme。为体现正常应用流量的覆盖率,本文从浏览器、电子邮件、即时通信、视频软件、P2P 下载、云服务以及游戏7 种不同类型的正常应用中共选取12款代表性程序。选取的正常应用类型及程序如表4所示。实验中正常流量采集于实验室内部主机正常使用表4 中的正常应用程序时所产生的网络流量。对于远控木马,由于本文所提的检测方法只涉及远控木马会话建立后的少量数据包,对每个远控木马每次采集约5 min 流量数据。由于正常应用流量在实际通信环境中通常远多于远控木马的流量,本文实验将正常流量与木马流量按照约10∶1 的比例混合以模拟真实网络环境的流量占比情况。本文将收集到的正常流量和木马流量划分为训练集、已知远控木马测试集和未知远控木马测试集,其中未知远控木马测试集对应未在训练集中出现过的killer、njrat、xrat、spynet 4 个远控木马的流量,用于测试本文方法对于未知远控木马流量的检测能力。具体而言,如表5 所示,本次实验的训练集包括5 462 个正常应用会话和452 个远控木马会话;已知远控木马测试集包括5 513 个正常应用会话和449 个远控木马会话;未知远控木马测试集包含717 个正常应用会话和84 个远控木马会话。

Table 4 Normal applications used in experiment表4 实验所用正常程序
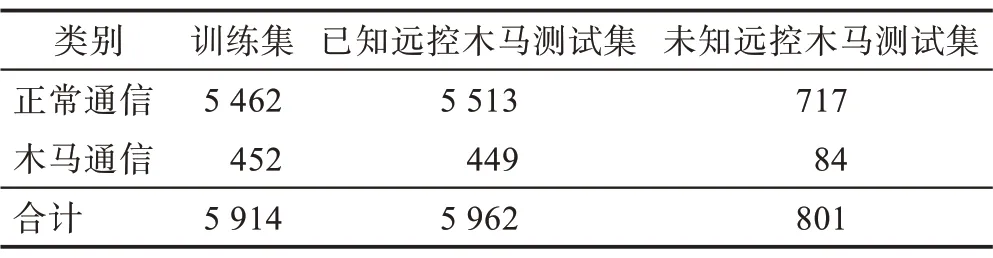
Table 5 Experimental data表5 实验数据
4.3 评估标准
本文采用准确率(Accuracy)、漏报率(false negative rate,FNR)以及误报率(false positive rate,FPR)这3 个常用评价指标来衡量本文方法的检测效果。这些指标可以通过TP、TN、FP、FN计算得到。TP表示远控木马流量被正确检测的数量,FN表示远控木马流量被误判为正常应用流量的数量,FP表示正常应用流量被误判为远控木马流量的数量,TN表示正常应用流量被正确检测的数量。3 个指标的含义及具体的计算方法为式(4)~(6)。
Accuracy表示预测的准确率:

FNR表示所有预测为正的样本中实际为负的比例:

FPR表示所有预测为负的样本中实际为正的比例:

4.4 实验结果及分析
4.4.1 实验结果
本文实验采用SVM、NB、KNN、RF 和DT 在内5种机器学习算法,利用相同的训练集构建检测模型,再使用已知远控木马测试集与未知远控木马测试集来分别测试检测模型对已知远控木马和未知远控木马的检测能力,并进一步分析本文方法在不同数量数据包(上线包及其之后的数据包)下的检测效果。
表6 显示了本文方法在分别使用3、4、5 和6 个数据包时(包含上线包)运用不同机器学习算法在已知远控木马测试集上获得的Accuracy、FNR以及FPR值。其中,使用4 个数据包(4Pks)时运用RF 算法获得的Accuracy最高,达到0.994,而对应的FNR与FPR分别为0.029 与0.004。
如图7 所示,当本文方法在3Pks 进行检测时,DT与RF 能够实现0.989 的Accuracy;当使用数据包数达到4 时,RF的Accuracy值能够达到0.994;RF使用5Pks 与6Pks分别获得了0.989 与0.987 的Accuracy。值得注意的是,5 种算法中SVM 与NB 的Accuracy较低,其余3 种算法均在4Pks 时取得最佳的Accuracy。经分析发现,这是因为方法所使用的部分特征随着用于提取特征的数据包数量增加,其特征值在正常应用流量和远控木马流量中愈发趋同。图8 给出了本文训练集与测试集中正常与远控木马流量在不同数据包下其特征Tinterval的值大于1 s 的样本数量。可以看到用于提取特征的数据包数为4Pks 时,Tinterval的值大于1 s 的木马流量样本多于正常流量样本;而当用于提取特征的数据包数为5Pks 时,Tinterval的值大于1 s 的流量中正常流量样本占了大部分。因此本文所提检测方法将检测数据包数设定为4Pks。
表7 为本文方法在4Pks 时对未知远控木马测试集所得到的Accuracy、FNR与FPR值。表7 的结果显示RF 的检测效果最佳,其Accuracy达到0.985,FNR和FPR分别为0.012 与0.015。
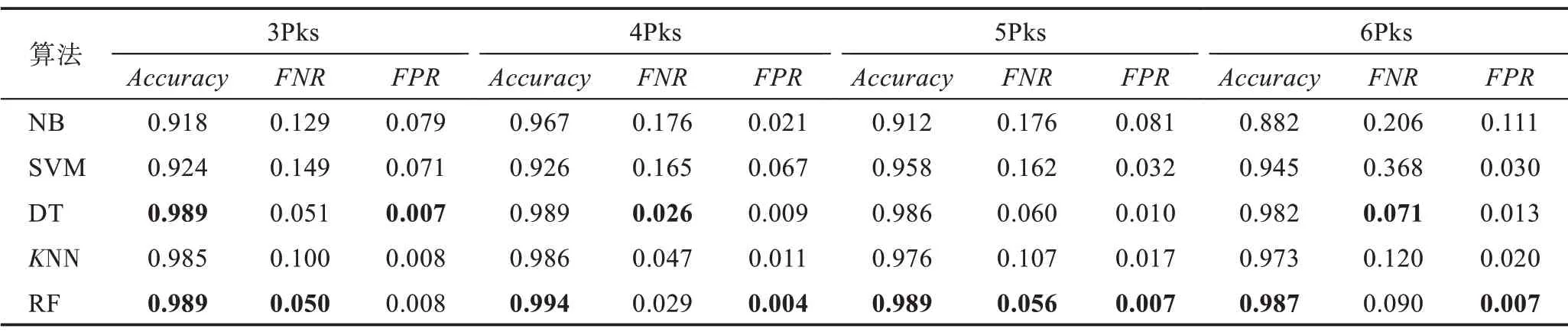
Table 6 Results of 5 algorithms on known RAT test set with different packets表6 5 种算法在不同数据包数下对已知木马测试集的检测结果

Fig.7 Accuracy of 5 algorithms on known RAT test set图7 5 种算法在已知远控木马测试集上的Accuracy
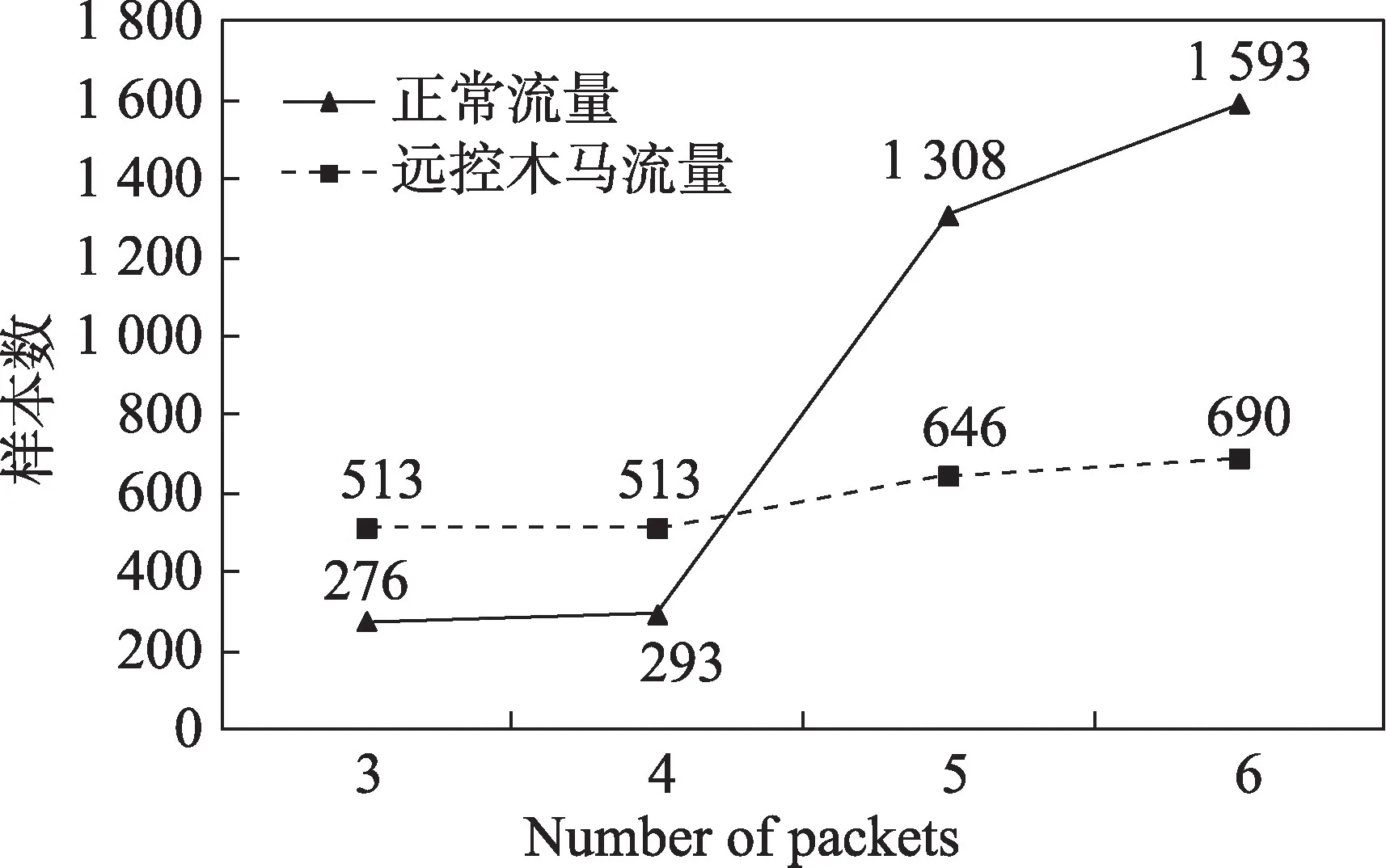
Fig.8 Number of samples with Tinterval value greater than 1 s for different number of packets图8 不同数据包数下Tinterval的值大于1 s的样本数

Table 7 Detection results of 5 algorithms using 4Pks on unknown RAT test set表7 4Pks时5 种算法对未知远控木马测试集的检测结果
为进一步对比所提方法的检测效果,本文采用文献[18]与文献[23]的检测方法分别对相同的流量进行处理并提取特征,其中文献[18]使用RF 算法训练模型并进行检测;文献[23]使用集成学习方法训练模型,其所用分类算法包括KNN、J48 决策树与SVM 三种。表8 和表9 分别给出了文献[18]与文献[23]的检测方法对已知与未知远控木马测试集的检测结果。

Table 8 Detection results of different methods on known RAT test set表8 不同方法在已知远控木马测试集上的检测结果

Table 9 Detection results of different methods on unknown RAT test set表9 不同方法在未知远控木马测试集上的检测结果
由表8 的结果可知,本文方法在已知木马测试集上的Accuracy和FPR分别为0.993 79 和0.004 35,优于文献[18]和文献[23]方法所得到的Accuracy和FPR。在FNR指标上,由于文献[23]的方法是通过木马控制端和被控端的所有数据包来提取特征,所获得的FNR优于仅使用部分数据包来提取特征的文献[18]方法和本文方法;同时,本文方法在FNR指标上优于文献[18]的方法。由表9 可知,在对未知远控木马数据集的检测结果上,本文方法在仅使用会话中少量数据包的情况下获得了0.985 02 的Accuracy和0.015 34 的FPR,该结果与文献[23]方法使用会话中全部数据包所获得的Accuracy和FPR相近。因此,从实验结果可以看到,本文方法能够在远控木马被控端和控制端开始通信的初期,通过少量数据包来有效地区分正常应用的通信会话和远控木马的通信会话。
4.4.2 结果分析
本小节给出了本文方法分别运用5 种不同机器学习算法在4Pks 时所需要的训练时间和检测时间。如表10 所示,5 种算法中最长的训练时长为SVM 的0.315 s,最长的检测时长为KNN 的0.040 s,而RF 的训练时长为0.045 s,检测时长为0.017 s,表明本文方法使用这5 种算法均能获得高的检测效率。
此外,为进一步分析本文方法对远控木马流量及时检测的能力,本文对比了文献[18]与文献[23]所用特征需要检测的数据包数量(从通信会话建立后开始统计),并依据是否有攻击者操作木马分别进行统计,即静默状态与操作状态,结果如表11 所示。
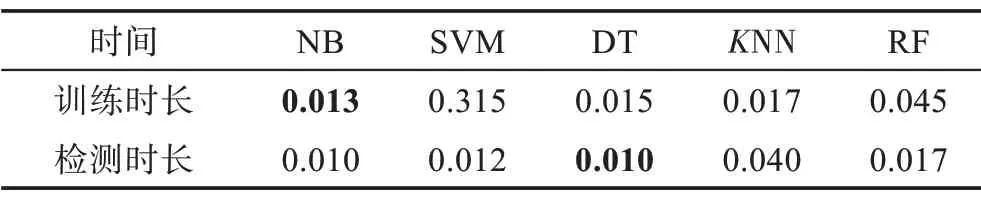
Table 10 Training and detection time of 5 algorithms on known RAT test set using 4Pks表10 4Pks时5 种算法对已知远控木马测试集的训练及检测时长 s

Table 11 Average number of packets need to be detected by different methods表11 不同方法所需要检测的平均数据包数
由表11 可知,按照文献[18]中对远控木马早期的定义,由于正常应用早期不需要隐藏自己的行为,通信双方在会话建立后的短时间内即进行大量数据交互,导致该方法在正常程序流量中抽取数据包数量远多于本文方法;文献[23]由于其检测对象是数据包级,需要检测通信双方的所有交互数据包,而正常应用的交互流量中存在多达几万个数据包的长会话,因此该方法所需要检测的数据包数量大且效率较低,无法实现木马通信流量的早期检测;而本文方法关注于上线包,仅需要检测通信会话建立后初期的少量数据包。综上,本文方法所需的会话数据包数量较少,能够较早地检测出远控木马通信流量。
5 结束语
本文通过分析远控木马会话建立后初期的通信行为,发现木马程序与正常应用在该时期内存在数据包序列差异,然后进一步提出了一种利用序列分析的远控木马早期检测方法。本文实验通过提取上线包及其后续数个数据包的特征并采用五种不同机器学习算法进行模型训练和检测,实验结果表明本文方法运用RF 算法能够在4Pks 时对已知远控木马测试集与未知远控木马测试集分别获得0.993 79 和0.985 02 的Accuracy,说明本文方法能够及时且以高准确率检测远控木马流量。后续本文方法将在实际办公环境中进行测试,并研究如何进一步降低检测方法对未知远控木马检测的漏报率与误报率。
猜你喜欢
计算机与数字工程(2022年3期)2022-04-07
科普童话·学霸日记(2021年6期)2021-09-05
环球时报(2020-08-11)2020-08-11
小读者之友(2019年10期)2019-09-10
物联网技术(2018年8期)2018-12-06
中国新通信(2016年2期)2016-03-11
小朋友·快乐手工(2014年4期)2014-08-16
