
语音识别中说话人自适应方法研究综述
2021-12-13 12:53朱方圆马志强张晓旭王洪彬宝财吉拉呼
计算机与生活 2021年12期
朱方圆,马志强,2+,陈 艳,张晓旭,王洪彬,宝财吉拉呼
1.内蒙古工业大学 数据科学与应用学院,呼和浩特 010080
2.内蒙古工业大学 内蒙古自治区基于大数据的软件服务工程技术研究中心,呼和浩特 010080
自动语音识别(automatic speech recognition,ASR)是一种将语音序列转化成文本序列的技术,是人机交互的主要方式之一[1]。当ASR 系统的测试条件和训练数据不匹配时,其识别性能下降明显,主要包括以下几个原因:说话人的差异、声学环境的可变性和使用领域的不同。研究人员提出利用说话人自适应(speaker adaptation,SA)方法对说话人声学特性进行适应,主要是对特征提取和声学模型(acoustic model,AM)的修正和调节。利用说话人的若干数据,对说话人无关(speaker independent,SI)的语音识别系统进行调节,调节后系统对目标说话人的识别性能提升。
ASR 的说话人自适应任务是将一系列声学特征向量X={x1,x2,…,xt,…,xT},利用目标说话人的若干数据得到参数θE,使xt∈Rd映射到单词序列W。假设模型以框架方式运行,则可以将模型定义为:

其中,f(xt;θ;θE)是具有参数θ和参数θE的神经网络模型,yt是帧t的输出标签。传统的高斯混合模型-隐马尔可夫模型(Gaussian mixed model-hidden Markov model,GMM-HMM)语音识别系统的说话人自适应技术主要包括:最大似然线性回归(maximum likelihood linear regression,MLLR)[2-4]、特征层最大似然线性回归(feature-space maximum likelihood linear regression,fMLLR)[5-6]、最大后验概率线性回归(maximum a posteriori,MAP)[7-8]和声道长度规整(vocal tract length normalization,VTLN)[9-11]等。虽然GMM-HMM 语音识别系统的说话人自适应方法已经非常成熟,但GMM是一个生成式模型,通过对空间进行划分,利用权重和方差等描述声学单元特性;而神经网络(neural network,NN)是一个判别式模型,直接对后验概率进行建模来实现。两者的模型结构存在较大差异,导致传统GMM-HMM 语音识别系统的说话人自适应技术无法直接应用到基于神经网络的语音识别系统中。
在基于神经网络模型的说话人自适应技术研究中,自适应训练数据不足或者训练数据包含大量不同的说话人会导致自适应训练过程容易出现过拟合问题。在神经网络语音识别框架下如何更好地进行说话人自适应,使得自适应能够取得显著的效果提升且能够适应于各种语音识别应用模式,己经成为语音识别研究领域新的热点和难点。将说话人自适应方法根据自适应参数调整的方式不同,分为基于特征域和基于模型域的说话人自适应方法。基于特征域的说话人自适应方法是通过对训练集和测试集中的每个说话人的声学特征进行自适应或归一化;基于模型域的说话人自适应方法是通过对调整声学模型参数进行自适应。
1 基于特征域的说话人自适应方法
基于特征域的说话人自适应方法通过保持声学模型参数不变,从而对特征进行说话人相关(speaker dependent,SD)的变换,进而增加特征与模型的匹配度。在适应目标说话人时,需要对模型参数进行自适应,在自适应训练过程中通用声学模型的参数会发生变化。面临的问题有在自适应训练数据量不足时,自适应训练过程中容易出现过拟合现象,从而无法获得较好的自适应效果。针对从出现的问题中延伸出来基于特征域的说话人自适应方法,根据使用方法的不同将基于特征域的说话人自适应方法分为基于特征变换和基于辅助特征的说话人自适应方法。
1.1 基于特征变换的说话人自适应
1.1.1 基于特征变换原理
基于特征变换的说话人自适应方法通过对神经网络的输入特征或者隐藏层特征进行变换来实现自适应。利用说话人自适应数据进行特征变换,使得变换后的特征能够更好地反映目标说话人的特点,从而使目标说话人更加适应语音识别模型。
针对上述问题,文献[12]提出对输入特征进行线性变换的方法,如图1[13]所示。此技术采用可训练的线性输入网络(linear input network,LIN)将与SD 的输入矢量映射到SI 语音识别系统。通过在保持所有其他参数固定不变的同时最小化连接器系统输出上的损失来训练此映射。具体的是创建一个线性映射来变换完整的输入向量。在识别过程中,该变换后的向量用作SI 人工神经网络的输入。为训练LIN 用于新的说话人,映射的权重被初始化为一个单位矩阵。输入被前向传播到SI 人工神经网络的输出层。此时将计算误差并通过SI 人工神经网络反向传播(back propagation,BP)。由于该系统的模型参数保持不变,没有SI 人工神经网络的权重调整,仅在新的线性输入层的权重中执行调整。
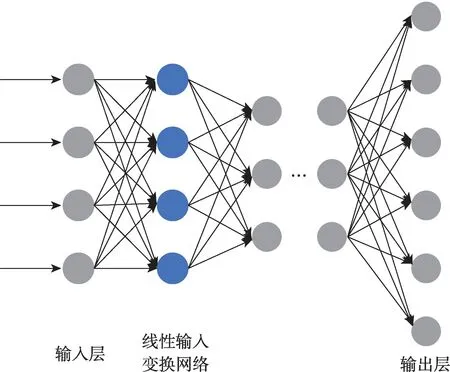
Fig.1 Adaptation method based on input features图1 基于输入特征的自适应方法
1.1.2 基于特征变换的改进方法
最初文献[12]指出随着神经网络的发展,声学模型参数量的增加,特征变换无法得到充分的训练从而无法得到更好的自适应效果,因此Gemello 等[14]提出对神经网络的隐藏层输出进行线性变换的方法,如图2 所示。文章描述线性变换不仅应用于输入层,而且还应用于隐藏层的输出。其动机是隐藏层输出代表输入模式的区分性特征。Li 等人[15]提出的线性输出层网络是在输出层之后增加一个线性变换层作为自适应参数。通过将输入和输出变换相结合的方式可以获得更好的性能。Trmal等人[16]提出了一种自适应多层感知器(multilayer perceptron,MLP)神经网络的方法,采用的参数是使用梅尔滤波器组的对数输出构建的,并且通过将第一层权重矩阵重构为梅尔滤波器组输出,能够显著限制自由变量的数量从而缓解过度训练问题。Xiao 等人[17]对基于上下文相关的深度神经网络-隐马尔可夫模型(context dependent deep neural network HMM,CD-DNN-HMM)的语音识别系统的任务自适应问题进行了初步探讨,采用了基于LIN 和基于神经网络再训练的方法。Yao 等人[18]研究一种直接改变顶层对数线性模型偏差参数的自适应方法,但是这类方法在层数较深的卷积神经网络和递归神经网络上带来的效果提升比较微弱。

Fig.2 Adaptation method based on hidden layer transformation图2 基于隐藏层变换的自适应方法
Karthick 等人[19]在卷积神经网络(convolutional neural network,CNN)中使用子空间高斯混合模型(subspace Gaussian mixture model,SGMM)方法,通过全协方差高斯估计相关特征的fMLLR 变换,其次用声学特征补充说话人特定子空间向量,以在CNN模型中提供说话人信息。Yi 等人[20]对每个说话人的测试数据重新计算所有批次标准化层的平均值和方差(means and variances,MV),使得测试数据的分布可以接近训练数据分布。特征变换方法也被引入到端到端模型中,Tomashenko 等人[21]使用双向长短期记忆-连接主义时序分类(bidirectional long short term memory-connectionist temporal classification,BLSTMCTC)模型,通过与fMLLR 自适应技术相结合可以提高准确率。将基于特征变换的说话人自适应方法研究现状总结到表1 中。
1.2 基于辅助特征的说话人自适应
1.2.1 基于辅助特征原理
基于辅助特征的说话人自适应是通过在声学特征中添加特定说话人信息并利用新特征训练声学模型实现自适应。目前身份向量(identity vectors,i-vectors)是主流的说话人特征表达方法之一。文献[22]中ivectors 的提取主要基于高斯混合模型-通用背景模型(Gaussian mixture model-universal background model,GMM-UBM),声学特征向量xt∈RD被视为从通用背景模型生成的样本,通用背景模型表示为具有K个对角协方差的GMM:

其中,ck、μk(s) 和Σk分别表示GMM 的各种参数,xt(s)表示第s个说话人的声学特征。
虽然i-vectors 技术属于说话人识别领域,但是文献[22-24]已经将其成功应用于说话人自适应。具体的,首先利用说话人识别技术提取出训练集中每个说话人的i-vectors,然后将该说话人的每帧语音频谱特征与其对应i-vectors 进行拼接作为输入特征,训练SD 的神经网络模型。
1.2.2 基于辅助特征的改进方法
本小节根据辅助特征获取方式的不同将基于辅助特征的改进方法分为两类:第一类是通过某种方法提取得到带有说话人信息的辅助特征改进方法;第二类是利用说话人编码的改进方法。本小节将研究现状总结到表2 中。

Table 1 Speaker adaptation method based on feature transformation表1 基于特征变换的说话人自适应方法
1.2.2.1 添加辅助信息的改进方法
受i-vectors 方法启发,Cardinal 等人[25]将瓶颈特征(bottleneck vectors,BN-vectors)的方法用于说话人自适应。该方法首先训练一个瓶颈神经网络用于说话人分类,并将训练集的每帧数据输入到训练好的具有区分说话人的瓶颈神经网络,计算出最后一个隐藏层的输出向量,然后将该向量与i-vectors 进行拼接后共同作为表达说话人的特征向量,用于SD 模型的训练。因为BN-vectors 与i-vectors 的提取过程不同,导致两者存在差异,前者包含较多的局部环境信息,而后者包含较多的说话人层面信息。两者结合能够提高对说话人信息的表达。Cui等人[26]引入一个控制器网络,将i-vectors 作为输入,输出每个隐藏层的仿射变换矩阵,解决了将i-vectors 与神经网络输入特征直接进行拼接造成i-vectors 信息利用不充分的问题。金超等人[27]通过添加说话人共享的自适应层,去除说话人差异信息保留说话人语义信息,将SD 特征变换成SI特征。

Table 2 Speaker adaptation method based on auxiliary features表2 基于辅助特征的说话人自适应方法
有些方法需要经过训练来区分说话人,或者通过多层的神经网络模型的瓶颈层来提取特征,然后在单独的声学模型中进行降维处理。如使用瓶颈说话人V 扇区嵌入[28],训练前馈网络以预测来自拼接梅尔频率倒谱系数(Mel-frequency cepstral coefficients,MFCC)的说话人标签(参见图3[28])。Tan 等人[29]提出增加第二个目标来预测多任务设置中的单音。瓶颈层尺寸通常设置为i-vectors 常用的值。实际上如果说话人标签目标被说话人与UBM 的偏差所取代,则瓶颈特征可能被认为是帧级i-vectors。提取的特征通过给定说话人的所有语音帧Ts的平均值进行简单的平均:


Fig.3 Bottleneck feature extraction architecture using preprocessed speaker classifier图3 使用预处理说话人分类器的瓶颈特征提取架构
Rownicka 等人[30]研究了嵌入在DNN 的说话人自适应训练中的使用,重点是每个说话人的少量自适应数据。
目前将许多添加辅助信息的方法统称为⋆-vectors,像瓶颈特征一样,这些方法通常经过训练来区分说话人的神经网络中提取嵌入,但不一定使用低维层。在2014 年,Variani 等人[31]提出说话人信息的深度特征向量(deep vectors,d-vectors),DNN 经过训练可以在帧级别上对说话人进行分类,通过提取说话人的d-vectors,并将说话人所有d-vectors 的均值作为说话人的特征表示。在2018 年,Snyder 等人[32]提出说话人特征向量x-vectors,利用DNN 提取说话人特征信息替代传统的i-vectors。相关的方法还有rvectors[33]使用了x-vectors 的结构,h-vectors[34]使用分层注意力机制产生话语级嵌入但是只应用于说话人识别任务。
后来Veselý等人[35]采用摘要网络产生输入特征的序列级概要,并且与⋆-vectors 方法密切相关(参见图4[35])。辅助特征由序列摘要神经网络(sequence summarizing neural network,SSNN)产生一个“摘要向量”,它表示话语的声学摘要,该神经网络将与声学模型相同的特征作为输入,并通过对输出的时间平均进行嵌入。Sari 等人[36]使用长短期记忆网络(long short-term memory,LSTM)作为辅助网络进行说话人自适应。还有一种相关的方法是Xie等人[37]从具有嵌入式平均的独立网络中产生学习性隐藏单元分布(learning hidden unit contributions,LHUC)特征向量。

Fig.4 Speaker embedding framework of sequence summarizing network图4 序列摘要网络的说话人嵌入框架
Pan 等人[38]提出了一个完整的框架,称为记忆感知网络,它由主网络、记忆模块、注意力模块和连接模块组成,基本框架如图5 所示。记忆模块中的记忆单元表示为M={m1,m2,…,mK}。通过注意力机制从记忆模块中选择最接近的说话人特征,用固定大小的常规遗忘编码(fixed-size ordinally forgetting encoding,FOFE)等方法对说话人特征进行组合,组合后的特征称为聚合说话人向量ct。最后使用连接模块将ct与主网络进行连接从而实现说话人自适应。随后Sari等人[39]提出无监督说话人自适应方法,所提出的模型同样包含着一个记忆模块,但目前只应用于端到端(end-to-end,E2E)ASR。

Fig.5 Framework of memory-aware networks图5 记忆感知网络的框架
1.2.2.2 说话人编码的改进方法
说话人编码方法是给定一个说话人编码后,将每一个说话人的特征映射到一个SI 的特征空间。对于一个新的说话人学习其相应的说话人编码是非常容易的,且用BP 算法时不会改变神经网络的模型参数。说话人编码与辅助特征方法的不同是在DNN 训练过程中进行矢量估计。在训练阶段,说话人编码由训练数据训练自适应网络时得到。该方法主要优势是说话人编码非常小,能够在只有少量自适应数据时实现快速自适应。
Abdel-Hamid 等人[40]提出一种针对DNN 模型的快速说话人自适应方法,自适应通过对所有的说话人及其对应的说话人编码联合学习一个大的自适应网络来实现。联合训练方法使用所有的训练数据及其对应的说话人标签来更新自适应网络的权值和说话人编码,更新使用的算法为标准的BP 算法。古典等人[41]在原有LHUC 方法的基础上,加入i-vectors 特征,弥补自适应数据量的不足,提高获取自适应数据的能力。Xue 等人[42]扩展基于说话人编码的自适应的思想,并提出了一种替代的直接自适应方法,该方法无需使用自适应神经网络就可以在模型空间中执行说话人自适应。
基于特征域的说话人自适应方法同样可以用于基于CTC 的多语言端到端ASR 系统中,使用表示目标语言的辅助特征[43]。考虑到i-vectors 在传统ASR系统中的成功应用,i-vectors 可能是代表说话人的辅助特征的自然选择[16]。然而很难在E2E 系统中集成i-vectors 提取过程,因为很难将其表示为可集成到E2E 模型计算图中的神经网络操作。
2 基于模型域的说话人自适应
基于模型域的说话人自适应方法通过更新声学模型参数来匹配测试条件。在利用目标说话人的自适应数据直接进行声学模型参数的更新时面临的问题有:在现实环境中满足数据量要求的说话人几乎是不存在的,因此如何最大程度地利用目标说话人自适应数据成为难点;在自适应模型和SI 模型输出层分布之间存在一定距离,使网络模型每次更新时会偏离原模型太远。根据上述问题和对应方法将基于模型域的说话人自适应方法分为基于模型参数的和基于正则化的说话人自适应方法。
2.1 基于模型参数的说话人自适应
2.1.1 基于模型参数的原理
基于模型参数的说话人自适应方法是只更新声学模型的部分参数,这些参数通常兼具鲁棒性和有效性。文献[44]提出一种方法:代替添加新层,重新训练隐藏单元的子集。首先通过原始网络传输自适应数据,并选择活动量最大的隐藏节点。最大活动被定义为最大方差(在自适应数据上计算),因为具有高方差的隐藏节点会将大量信息传输到输出层。通过将每个节点的方差与所有自适应数据中隐藏节点的最大值进行比较,从而选择进行自适应的隐藏节点的数量。如果节点方差低于给定最大值的百分比,则会进行修剪。在第二步中,对这些节点进行重新训练以使其最小化神经网络输出与目标值之间的交叉熵。此方法的核心公式给出一个要选择的最小隐藏节点l的权重wlj,公式为:

其中,yj(t)和分别表示网络输出和神经元j和时间帧t的目标值,wlj表示从隐藏节点l到输出节点j的权重,而zl(t)表示隐藏节点的激活节点l。
2.1.2 基于模型参数的改进方法
本小节根据方法不同将基于模型参数的改进方法分为三类:第一类是对某部分参数进行自适应的改进方法;第二类是利用奇异值分解(singular value decomposition,SVD)的改进方法;第三类是使用学习性隐藏单元分布的改进方法。将研究现状总结到表3 中。
(1)部分参数自适应的改进方法
部分参数自适应是在自适应过程中,首先通过搜检网络的隐藏层输出结果并且选择其中一部分活跃节点,然后将这部分活跃节点相连接的权重参数使用自适应数据进行重新训练。Siniscalchi 等人[45]只对隐藏层节点的激活函数中的参数进行重训。Wang等人[46]针对深度神经网络中通常会采用的批量归一层中的参数进行自适应,关键思想是调整批量标准化声学模型中的缩放因子和移位因子,以便测试数据在每个隐藏层的分布与训练数据的分布更好地匹配。Mana等人[47]表明,批量归一化层也可以通过在线方式重新计算统计数据均值和标准偏差来更新。Liu等人[48]针对LSTM 声学模型进行自适应,对LSTM 的各部分参数在自适应时的有效性和鲁棒性进行分析。

Table 3 Speaker adaptation method based on model parameters表3 基于模型参数的说话人自适应方法
(2)SVD 的改进方法
奇异值分解[49]方法是对隐藏层进行分解,分解后的SVD 层插入线性层。利用SVD 方法对模型权重矩阵进行更新,这种比直接插入线性层的方法更能减少参数量,减轻过拟合问题。Jian 等人[50]在DNN 的权重矩阵上应用SVD,然后基于原始矩阵的固有稀疏性对模型进行重构。重组后可以显著减小DNN 模型的大小,而精度损失可忽略不计。在2014 年,Jian等人[51]提出两种基于奇异值分解的DNN 自适应方法:其一是SVD 瓶颈自适应方法,使用SI 模型格式,其中每层的权重矩阵近似为两个低秩矩阵的乘积;其二是SVD 增量压缩,在每个层中调整权重矩阵,但只存储调整后的权重和SI 权重之间的差异。可以通过使用奇异值分解并只存储分解后的矩阵来减少增量矩阵的占用空间,分解后的矩阵的参数数量要少得多。
(3)LHUC 的改进方法
LHUC 方法是在给定自适应数据的情况下学习说话人特定的隐藏单元分布。为解决在只对神经网络的某一层输出特征进行变换时,对所有层的输出特征均进行变换导致自适应参数数量成倍增加的问题,Swietojanski 等人[52]采用对角阵的特征变换,即为每个隐藏层输出单元配置一个放缩因子作为自适应参数。通过为说话人m定义一组SD 参数来修改SI模型,,l=1,2,…,L,其中是第l个隐藏层的SD 参数向量。如果是约束范围的元素函数,定义SD 隐藏层l的输出:

其中,◦是逐元素乘法,Wl是权重矩阵,φl是第l个隐藏层的非线性传递函数,φ是输出层变换。该方法可以理解为对于每个不同的说话人,对各个隐藏层节点进行筛选,放大对目标说话人识别有用的节点,而过滤对目标说话人识别有害或者无用的节点。该方法具有少量的自适应参数,并且作用于声学模型的所有层,因此取得更好的自适应效果,同时保持自适应时的计算效率,更能体现特定说话人的信息且不需要说话人自适应训练。Xie 等人[53]对该方法进行进一步的改进,提出使用贝叶斯的LHUC 的方法(Bayes LHUC,BLHUC),如图6 所示。作者引入变分学习的理论,认为放缩因子不是一个固定的参数,而是符合一个高斯分布,这样当自适应数据量较少时,自适应参数的不确定性会被该分布的方差所吸收,从而降低自适应训练过拟合的风险,提高自适应模型的泛化能力。

Fig.6 BLHUC adaptation used in DNN acoustic model图6 在DNN 声学模型中使用BLHUC 自适应
2.2 基于正则化的说话人自适应
2.2.1 基于正则化原理
基于正则化的说话人自适应方法是在声学模型自适应过程中增加正则化项。文献[54]引入自适应模型和SI模型输出层分布之间的KL(Kullback-Leibler)散度作为正则化,使网络模型每次更新时不会偏离原始模型太远,是目前基于模型域的说话人自适应方法中重要方法之一。文献动机是研究如何重新训练网络的一部分和网络的大小如何影响说话人适应性能。通过将平方惩罚项的一半添加到误差函数来完成,以最小化更新的权重和未适应的网络权重之间的差异,因此被称为L2 先验正则化。等式中的权重更新变为:

其中,β是L2 惩罚项的权重衰减因子,它将权重衰减至原始模型权重。惩罚项越大,更新后的权重越难偏离原始模型权重w。
2.2.2 基于正则化的改进方法
基于正则化的改进方法是通过限制原始模型和调整后的模型之间的距离,从而防止调整后的模型参数偏离原始模型参数的方法。Liao[55]提出使用原始SD 参数θs与适应的说话者相关参数θs之间的距离的L2 正则化损失:

Dong 等人[54]提出使用KL 散度来测量适应模型和原始模型的senone分布之间的距离:
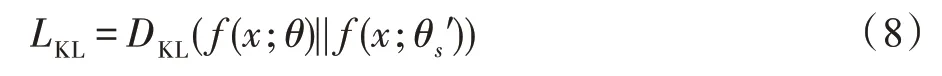
如果使用交叉熵考虑整体适应损失:

可以证明这种损失等于与目标分布的交叉熵:
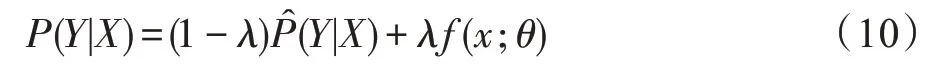
Meng 等人[59]指出KL 散度不是分布之间的距离度量,因为它是不对称的。因此建议使用对抗式学习来保证正则化项的局部最小值只有在SI 模型和SD 模型的senone 分布相同的情况下才能达到。他们通过反向训练鉴别器d(x;φ)来实现这一点,该鉴别器的任务是区分SD 和SI 的特征提取器获得的SD 深层特征h′和SI 的深层特征h。该过程在图7[59]中示出,鉴别器的正则化损失为:
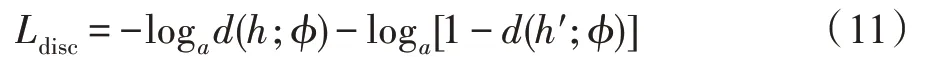
其中,h是说话人独立模型的隐藏层激活,h′是适配模型的隐藏层激活,a为常数。鉴别器在自适应期间通过以相对于φ最小化Ldisc和相对于θs最大化Ldisc的方式以最小最大化的方式训练。因此,SI 模型的第i个隐藏层的激活分布与SD 模型的第i个隐藏层的激活分布是相似的,这会使说话人自适应的性能更好。Huang 等人[60]通过添加一个或多个模拟宽声单元的辅助输出层来解决基于DNN 的用于自动语音识别的声学模型的参数自适应中的自适应效率问题。将原始的senone 分类任务作为主要任务,并添加辅助senone-cluster 分类作为次要任务,采用多任务学习(multi-task learning,MTL)来适应DNN 参数。Tóth 等人[61]使用KL 散度正则化与多任务训练技术结合的方法,解决了上下文相关的深度神经网络声学模型的适应性问题。
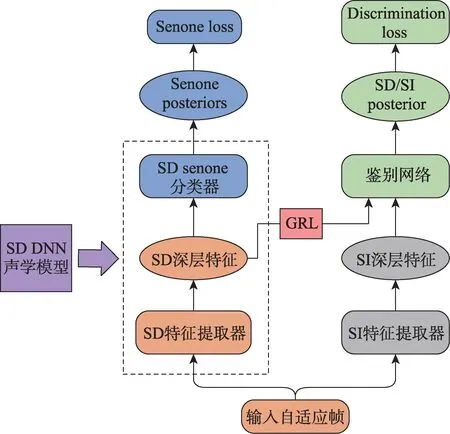
Fig.7 Adversarial speaker adaptation speech recognition framework图7 对抗说话人自适应语音识别框架
虽然最初提出的KL 散度正则化方法是为了适应混合模型,但也可以用于E2E模型的说话人自适应[62]。Li等人[63]提出了KL散度正则化和对端到端CTC 模型的说话人自适应方法,KL散度自适应约束了自适应模型与SI 模型的接近,以减少适应集的过拟合。Meng等人[64]对SI的基于注意力的编码器-解码器(attentionbased encoder-decoder,AED)模型中的所有参数在训练期间没有更新,因此只在AED 损失中添加SD AED模型参数相关项作为KL 散度正则化。最小化了SD和SI AED 模型输出分布之间的KL 散度以及AED 损失,以避免过拟合。将基于正则化的说话人自适应方法研究现状总结到表4 中。
3 总结与展望
本文对基于神经网络的说话人自适应方法在语音识别任务中存在的问题、解决方法以及改进方法进行介绍和总结。在过去的十年里,语音识别的快速发展是由声学的深层神经网络模型驱动的。与以前基于GMM-HMM 的说话人自适应方法相比,目前基于神经网络的系统具有更少的约束和更灵活的模型,但是说话人自适应方法在语音识别任务中的以下领域中会有更大的发展空间。

Table 4 Speaker adaptation method based on regularization表4 基于正则化的说话人自适应方法
(1)在线说话人自适应
目前大部分的说话人自适应方法是离线的,然而在线场景应用中大部分的离线说话人自适应语音识别模型不会利用使用者的历史语音数据对模型进行更新,因此在一定程度上模型的性能效果不佳。在线说话人自适应通常面临两个难点:其一是在线自适应过程中,能够用于在线说话人自适应的数据极短,说话人表征的稳定性难以保证;其二是在实时语音识别服务中,不能花费大量的时间进行模型的重新训练,而且对于实时语音识别的响应时间有着非常严格的要求。由于这两个难点的存在,在线说话人自适应是一个研究的难点问题。
当前解决在线自适应方法是利用对抗训练的机制,通过引入额外的训练目标,能够更好地去除说话人相关的因子,提取说话人无关特征。但是采用了对抗训练的方法,声学模型的训练过程变得不稳定,模型的训练收敛成为一个问题。目前端到端模型同样在解决在线问题,因此与说话人自适应技术结合起来是未来的研究方向。
(2)无监督说话人自适应
大多数说话人自适应方法都需要较多的有人工标注的历史数据,因此有监督说话人自适应方法在语音识别任务中成功应用且具有良好的识别性能。但是在无人工标注的情况下和自适应数据极少的情况下进行声学模型自适应成为该领域的一个挑战。
为了解决标记数据非常有限或根本没有标记数据的问题,有学者提出一种无监督说话人自适应方法。文献[39]通过引入神经图灵机的读取机制,该模型包含一个记忆模块(记忆模块记忆了从训练数据中提取的说话人特征),并通过注意力机制从记忆模块中读取相关说话人特征。这种方法不需要自适应数据,也不需要测试时说话人信息等附加标签信息。
(3)面向端到端模型
E2E 建模不如混合模型方法成熟,E2E 建模的大部分研究重点是改进通用建模技术。因此本文主要介绍了在混合系统的背景下的说话人自适应方法,然而E2E 模型通常包含与混合模型中的声学模型和语言模型对应的子网络,因此大多数成功应用于混合模型的说话人自适应方法同样应该适用于E2E 模型。
由于端到端模型的规模远小于混合模型,端到端模型在部署到设备时具有明显的优势。因此E2E模型的个性化或适应性是一个发展迅速的领域。虽然可以在云端自适应每个用户的模型,这需要克服有限内存问题和计算能力问题。E2E 模型说话人自适应的另一个研究方向是如何利用没有标签的数据。
猜你喜欢
智慧电力(2022年4期)2022-05-19
心理学报(2022年5期)2022-05-16
当代陕西(2020年17期)2020-10-28
南方周末(2020-01-02)2020-01-02
人大建设(2018年5期)2018-08-16
证券市场红周刊(2018年3期)2018-05-14
上海师范大学学报·自然科学版(2018年3期)2018-05-14
华东师范大学学报(自然科学版)(2018年3期)2018-05-14
神州·上旬刊(2017年9期)2017-10-15
中学生数理化·中考版(2014年5期)2016-12-22
