
基于硬件加速的轻量级网络心音分类器
2021-12-12 02:52杜煜章潘家华王威廉
计算机工程与应用 2021年23期
杜煜章,潘家华,宗 容,粟 炜,王威廉
1.云南大学 信息学院,昆明 650504
2.云南省阜外心血管病医院,昆明 650102
心脏杂音是识别先天性心脏病(Congenital Heart Disease,CHD)最常见的体征,通过心脏听诊可以准确快速地进行新生儿先天性心脏病临床筛查[1]。然而,依靠医生人工进行先心病临床筛查难度大、成本高,因此,有研究者提出基于深度学习的先心病机器辅助诊断系统,辅助医生进行听诊,提高筛查效率,提升准确率[2]。
卷积神经网络(Convolutional Neural Networks,CNN)是一种重要的深度学习模型,广泛应用于计算机视觉、自然语言处理等领域。因其善于从海量数据中挖掘抽象的特征,且拥有高度的泛化性与出色的识别能力,近年来CNN也被运用于心音的分类研究中[3-4]。为满足传统卷积神经网络在运算量、存储空间方面的需求,目前CNN主要被部署在CPU或GPU上。但因CNN计算过程具有多种并行特征,可利用FPGA对CNN并行计算过程进行硬件加速[5-7]。
为充分利用FPGA的并行计算特性,许多研究团队在CNN的FPGA硬件加速与实现方面做了大量的研究[8-10]。Han等人提出“深度量化”,通过剪枝、权值共享、权值量化、哈夫曼编码等方法的共同协作,在不影响准确度的前提下,将卷积神经网络的存储需求减少35~49倍[11]。Zhao等人提出一种流设计思想,对不同的卷积层采用不同的量化精度与算法,在FPGA上实现了一种高性能的多精度多算法网络[12]。谷歌提出一种适用于嵌入式设备的轻量级神经网络MobileNet,该设计使用深度可分离卷积构建轻型深度神经网络,在准确度相近的情况下,相较于GoogleNet与VGG16参数与计算量减少了近90%[13]。
本文使用高层次综合(High Level Synthesis,HLS)设计并实现了一种适用于FPGA硬件平台的心音分类器,并对其进行硬件加速优化。采用滑动窗、参数重排序等优化方案实现卷积层多像素、多通道并行运算,加快了心音分类器在FPGA上的运行速率。通过16位定点量化缩小模型参数,减少心音分类器参数在FPGA上的内存消耗。采用AXI-Stream数据流进行数据传输,提升数据传输速率。对硬件加速优化后的心音分类器网络,以实验室心音数据库心音特征图为识别对象进行实验,验证心音分类器网络分类准确率与加速效果。
1 轻量级神经网络MobileNet
1.1 深度可分离卷积
MobileNet模型的核心思想是深度可分离卷积。深度可分离卷积将传统卷积过程分为了深度卷积和逐点卷积两步,如图1(b)所示。深度卷积对不同的输入通道使用不同的卷积核分别进行卷积,逐点卷积通过一个1×1的卷积核来结合深度卷积各个通道的输出产生新的特征。深度可分离卷积将传统卷积的滤波以及生成新特征这两个过程分离,这个分离过程可显著减少计算次数和模型大小。

图1 传统卷积过程与深度可分离卷积过程Fig.1 Traditional convolution process and depth separable convolution process
对于传统卷积过程,假设输入通道数目为M,输入特征图的宽和高均为GI,卷积核的宽和高均为FH,输出通道数目为N,该传统卷积层的计算次数CT为:

深度可分离卷积将传统卷积分为深度卷积与逐点卷积。深度卷积的计算次数CD为:
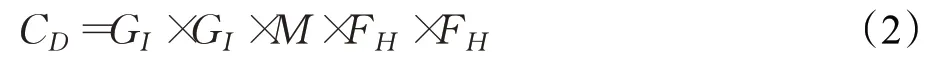
整个深度可分离卷积层的计算次数C为:

深度可分离卷积与传统卷积的计算次数之比P为:
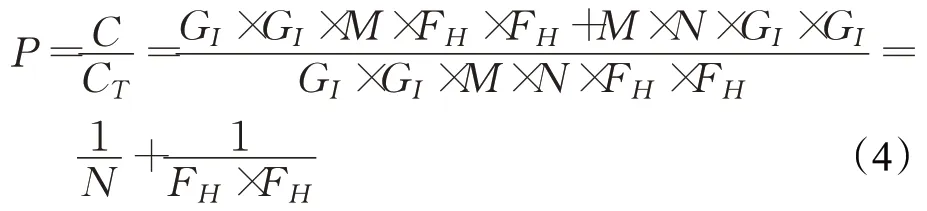
当深度卷积使用的卷积核宽和高FH=3,输出通道数目N=128时,在对精度造成的影响很小的情况下,深度可分离卷积的计算次数相较于传统卷积减少了8.41倍。并且随着输出通道数目的增加,卷积核宽和高的增加,计算次数减少得将会更加明显。
MobileNet模型利用深度可分离卷积,通过减少网络的计算次数,加速了网络在嵌入式设备上的运行速度,降低了网络运行的能耗。同时深度可分离卷积还减少了网络的参数数目,压缩了模型部署在嵌入式设备上所消耗的内存空间,降低了对于嵌入式设备硬件资源的消耗。
1.2 BN层与ReLU6层
传统卷积层结构在卷积运算结束后,加入批量归一化层(Batch Normalization,BN)与ReLU激活函数层对卷积运算结果进行处理。深度可分离卷积在深度卷积层与逐点卷积层后,均接入了BN层与ReLU6层,相较于传统卷积层结构加入的BN层与ReLU6层更多,其模型结构如图2所示。向模型中加入更多的ReLU6层,增加了模型的非线性变化,增强了模型的泛化能力。ReLU6相较于传统卷积层结构中的ReLU激活函数,限制了激活函数的最大输出值为6,这样使得该激活函数在低精度的fix16/int8的嵌入式硬件设施上性能良好,模型的鲁棒性更强。BN层的存在控制了梯度爆炸与梯度消失,并提高了神经网络的训练与收敛速度。

图2 传统卷积与深度可分离卷积结构Fig.2 Traditional convolution and depth separable convolution structure
1.3 心音分类器模型
本文构建的心音分类器网络模型运用Mobilenet轻量级网络中的深度可分离思想,将三层传统卷积神经网络,改进六层为深度可分离卷积网络,使其模型参数更少,更适合于课题组所构建的先心病心音数据库数据,同时也使其能更加便捷地部署于FPGA硬件平台。
2 心音分类器模型的硬件加速
2.1 卷积运算单元硬件加速
卷积层在整个网络的各个层中,占据了超过90%的运算次数,消耗了大量运算时间。因此卷积运算单元的并行加速设计是整个硬件加速设计部分的核心。卷积运算过程具有多种并行特征,可以使用不同的并行优化方法。本文中使用两种并行优化方法来对卷积运算单元进行硬件加速,一种是同通道上的并行加速,另一种是不同通道上的并行加速。
心音分类器模型中共包含两种卷积运算:深度卷积运算与逐点卷积运算。针对深度卷积与逐点卷积的不同运算特性,深度卷积采用同通道上的并行加速,逐点卷积采用不同通道上的并行加速。
2.1.1 同通道并行加速
对一张32×16的输入图片的一个通道,用一个3×3的卷积核进行卷积运算。不进行任何优化,每次运算都需要取、算、存三个时钟周期,运算整张输入图片,共需要32×16×9×3个时钟周期。
(1)对运算过程进行Pipeline(流水线)约束
Pipeline(流水线)约束,在第一个数据进行运算同时,对第二个数据进行读取。在第二个数据进行运算同时,并行执行第一个数据运算结果的写入与第三个数据读取。对整张输入图片进行卷积运算,仅需要32×16×9+2个时钟周期。相较于不对算法进行任何优化,运行时间减少大约3倍。
(2)3×3卷积核的9次乘法并行计算
传统的卷积运算单元中,执行3×3卷积乘法运算需要9个时钟周期。本文在高层次综合中对卷积窗口进行循环展开(UNROLL),实现卷积核9次乘法运算并行计算,其并行思想如图3所示。高层次综合中的循环展开将例化额外的硬件,消耗9个DSP(Digital Signal Processing)并行计算,通过牺牲硬件资源与面积,提升卷积运算速度。

图3 同通道多像素并行运算Fig.3 Parallel computing with multiple pixels in the same channel
循环展开实现了卷积核9次乘法并行运算,但内存带宽需求增高。传统卷积运算单元每个时钟周期进行1次内存存取操作。循环展开后,9次乘法并行计算,对内存带宽的要求增加至每个时钟周期9次内存存取操作。在高层次综合中,外部内存存在多个端口,通过高层次综合生成的模块只能连接到其中一个端口上,且每个时钟周期只能进行一次数据传输。因此,本文将内存带宽需求从外部内存端口转移至高层次综合编译器生成的本地内存。
高层次综合生成的本地内存类似于CPU的高速缓存,在高层次综合中被称为行缓存。
缓存整张输入图片将消耗大量的硬件资源,并且对于卷积操作,并非所有的数据都将在短期内被重复调用,行缓存仅用于存储正常执行卷积操作所需要的最小数量的像素值。对于3×3的卷积乘法窗口操作,行缓存必须存储2个完整的图像行以及第3行的前3个像素,才能计算得到第一个输出像素值,因此需要三行行缓存,每行行缓存可缓存输入图片列数个像素值。
通过使用FPGA中的BRAM硬件资源实现行缓存。分别将图片的三行像素值存储在三块BRAM中,每块BRAM在每个时钟周期内都可存取1个像素。因此,可用于算法计算的内存带宽将从原先每个时钟周期1个像素提高3倍,达到每个时钟周期3个像素。
行缓存中的数据移动如图4所示。输入图片数据以数据流的形式输入,数据从第三行缓存的第一个位置开始,依次填满第三行缓存。当第三行缓存填充满时,第三行缓存第一个位置的数据存储至第二行缓存的第一个位置。当行缓存存满2个完整图像行与第三行前3个像素时,进行第一次计算。
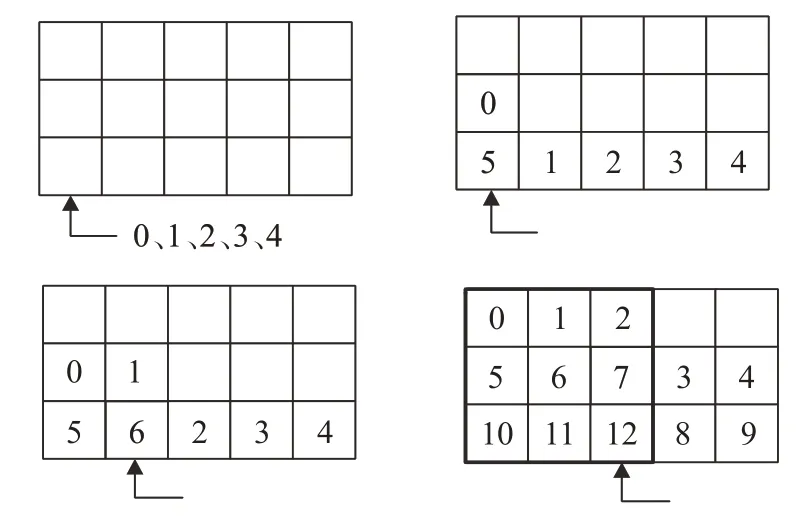
图4 行缓存中的数据移动Fig.4 Data movement in line buffer
行缓存可实现每个时钟周期存取3个像素。为满足每个时钟周期存取计算9个像素,使用FPGA中的FF硬件资源实现滑动窗(图4中方框部分)。滑动窗每个寄存器均可供所有其他寄存器独立访问或同时访问。对整张输入图片进行卷积运算,当流水线充满时,需要的时钟周期为32×16。与CPU串行运算相比,运行的时钟周期数目减少大约9倍。
2.1.2 不同通道上并行加速
卷积运算在不同通道上也存在并行特性,可运用不同的卷积窗口对不同通道并行运算,如图5所示。一张RGB三通道图像,三通道并行运算消耗的运算时间将比单通道依次运算减少三倍。但不同通道上的并行运算同样是以牺牲硬件资源为代价,用面积换取运算速度的提升。综合考虑网络每层的输入通道数目与输出通道数目均为四的整数倍,且DMA数据位宽为64 bit,经定点量化后的数据为16 bit定点数,DMA一次能传输四个数据,因此选取四通道并行运算,对模型进行硬件加速。
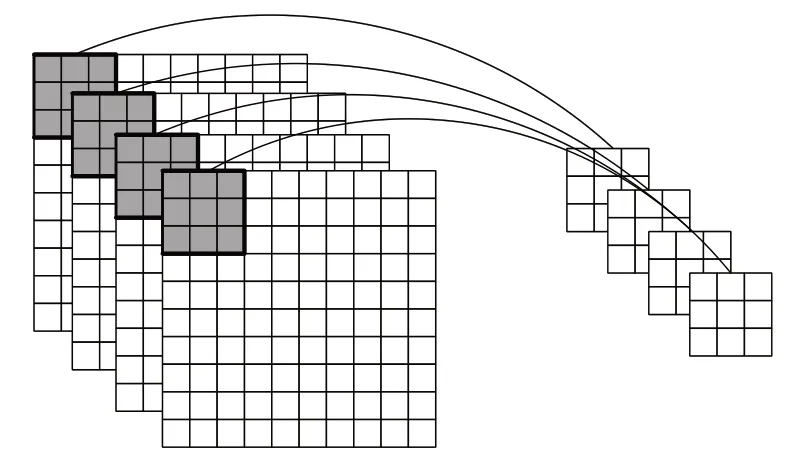
图5 多通道并行运算Fig.5 Multi-channel parallel computing
2.2 像素重排序
卷积运算的特征图,需要先计算完成所有输入通道,然后将每个输入通道上的运算结果进行累加。以一张RGB的三通道图像为例,图像大小为32×16,在内存中的存储方式如图6(a)所示。在读取输入图片时,首先32×16个“R”通道的像素点被传输,然后依次传输32×16个“G”通道像素点与32×16个“B”通道像素点。通过这种方式存储与传输数据,对于每一个输出通道,需等待最后一个输入通道运算完成才可以得到卷积结果。将耗费大量的缓存来存储运算的中间结果。
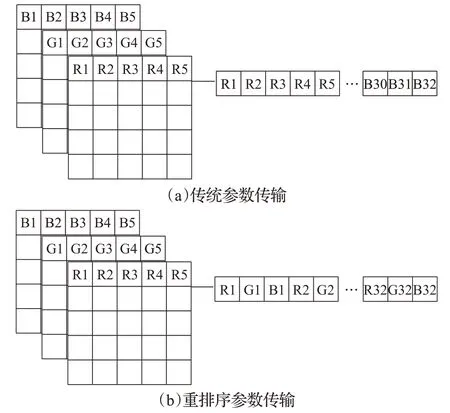
图6 参数重排序Fig.6 Parameter reordering
因此将输入图像像素在内存中的存储进行重新排序。如图6(b)所示,读取输入图片时,首先传输输入图片“R”“G”“B”三通道的第一个像素点,然后依次传输三通道的第二个像素点以及第三个像素点,直至整张输入图片传输完成。通过这种方式传输图片,因首先进行了不同输入通道上的像素循环,故可直接进行叠加得到输出结果,不需要消耗缓存来存储运算的中间结果。
2.3 定点量化
使用Keras和TensorFlow训练得到的网络模型,数据精度为float32/float64。FPGA中并无专用的浮点运算单元,进行浮点运算需要消耗较多的DSP资源与LUT资源。由文献[14]和实际实验可知,HLS中的浮点32位乘法需要三个DSP资源,浮点32位加法需要两个DSP资源。定点16位乘法需要一个DSP资源,而定点16位加法仅消耗LUT资源实现。对比可知,对权重数据与输入图像数据进行定点量化,可以减少硬件资源消耗。将32位数据替换为16位数据,占用的内存减少一半,模型大小缩小,运算速度加快。
3 FPGA硬件实现
3.1 心音分类器计算架构
MobileNet模型包含传统卷积层、深度卷积层、逐点卷积层、最大池化层、全连接层与Softmax层等六种类型的层。通过Mobilenet模型改进的心音分类器模型删除了部分层。假设将每一层封装成独立的IP,在FPGA上利用单独的硬件资源进行运算,由于对每一层进行了定制,可最大程度地提高运算效率以及吞吐量,但将消耗大量的FPGA硬件资源,使一些模型较大、层数较深的神经网络无法部署在FPGA上。
另一种设计方法将每一层的硬件设计分布在不同比特文件中,当每一层的计算结束后,通过比特文件重新配置FPGA,这种方法保证了每一层硬件设计性能最优,且不会因为层数较深导致硬件资源消耗过多。但每一次通过比特流重新配置FPGA都需要消耗数百毫秒的时间,尽管每层的延时都是最佳的,但整体性能将会受到明显影响[15]。
由于FPGA上实现的仅为心音分类器模型的前向传播算法。与CNN相似,心音分类器模型的前向传播算法不同层之间的运算过程相互独立,所以本文将深度卷积层、逐点卷积层与最大池化层封装成可实现复用的IP,通过复用这些IP核实现完整的深层次神经网络。
3.2 心音分类器模型FPGA硬件实现
将心音分类器模型中的深度卷积层,逐点卷积层与最大池化层通过FPGA实现,并对其进行硬件加速。具体硬件系统设计如图7所示。
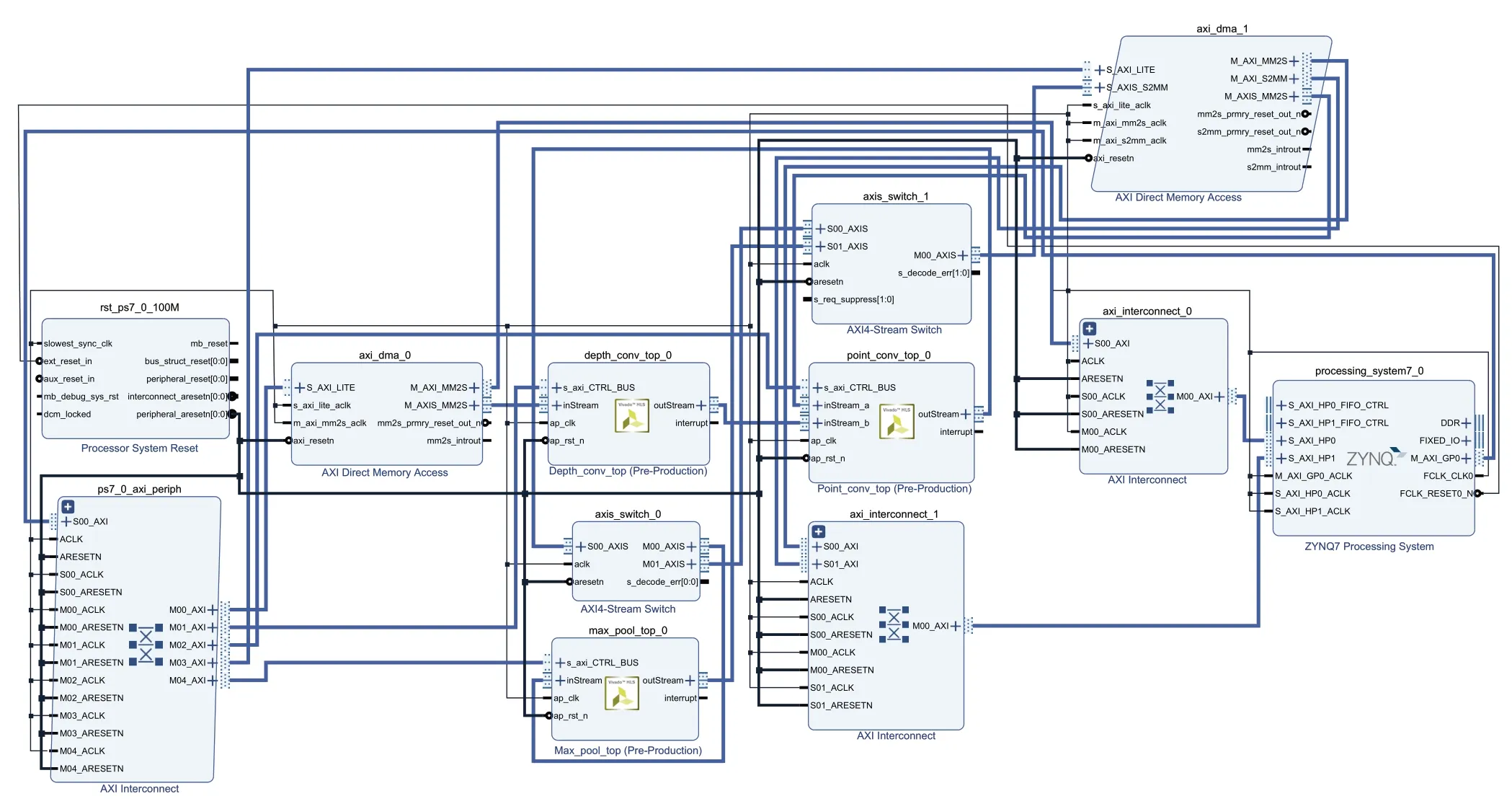
图7 心音分类器FPGA硬件系统设计Fig.7 FPGA hardware system design of heart sound classifier
DMA0将AXI4数据转换为AXI-Stream数据。AXI-Stream数据相较于AXI4数据减少了地址线,可降低延时。DMA0分两次向高层次综合生成的深度卷积IP传输数据,第一次传输深度卷积权重数据,第二次传输图像数据,运算结果由深度卷积IP传输至逐点卷积IP。然后由DMA1向逐点卷积IP传输逐点卷积权重数据,运算结果由逐点卷积IP传输至Xilinx官方定义的Switch IP。心音分类器模型仅在最后一次逐点卷积运算结束后接入最大池化层,可通过Switch IP进行选择,当并未进行至最后一次逐点卷积,将逐点卷积运算结果直接经过Switch IP传输至DMA1,由DMA1传送回DDR。本文采用双DMA分别传输深度卷积权重值与逐点卷积权重值,并将DMA的数据位宽设定为64位,适应于卷积四通道并行运算。
全连接层通过Zynq的ARM核进行软件实现。Softmax层则由比较器进行替代。Softmax层的作用是将最终的运算结果映射为[0,1]之间的实数,并且运算结果之和恰好为1。本文使用心音分类器进行二分类,分类结果为阴性与阳性。通过传统Softmax层运算将进行大量指数运算,增加运行时间。本文使用比较器替换传统Softmax层,仅需从运算结果找出较大的值,便可得到分类结果,取代了复杂的指数运算,加快了运行速度。
4 实验结果及分析
4.1 实验环境
本文实验采用Xilinx公司的ZYNQ-7000系列xc7z020clg400-2芯片作为硬件平台,该芯片中包含两大部分:PS(Processing System)部分,集成两个ARM cortexa9处理器。PL(Programmable Logic)部分,即FPGA部分。其中FPGA部分BRAM_18K、DSP48E、FF、LUT资源分别为280、220、106 400及53 200。CPU软件训练平台采用Intel®Core™i7-9750H,主频为2.6 GHz。训练所用的软件为TensorFlow2.1.0及Keras2.3.1。
本文使用实验室先天性心脏病心音数据库数据构建数据集,该数据库研究经云南大学医学院伦理委员会审查通过。数据集特征谱图由先天性心脏病心音数据库心音信号通过心音分割后,使用子带包络方法进行特征提取获得。所有异常心音信号均由超声心动图确诊。数据集训练集由5 370例心音信号构成,其中正常心音信号2 345例,异常心音信号3 025例,经心音分割与特征提取获得特征谱图96 729张(阴性42 210张,阳性54 519张),测试集由324例心音信号构成,其中正常心音信号160例,异常心音信号164例,经心音分割与特征提取获得特征谱图5 837张(阴性2 878张,阳性2 959张),每张特征谱图的维数均为32×16。
本文在软件平台CPU上实现与FPGA相同的神经网络,通过Keras进行训练,将训练后得到的权重参数,通过16位定点量化下载至FPGA中。FPGA硬件平台中不进行训练,只进行前向分类过程。
4.2 心音分类器性能与资源消耗评估
4.2.1 资源消耗评估
本文采用多通道、多像素并行性,定点量化等加速方法,设计并实现了与文献[16]网络模型相同的传统卷积网络。然后将该传统卷积网络改进为深度可分离卷积网络。其FPGA硬件资源消耗情况如表1所示。
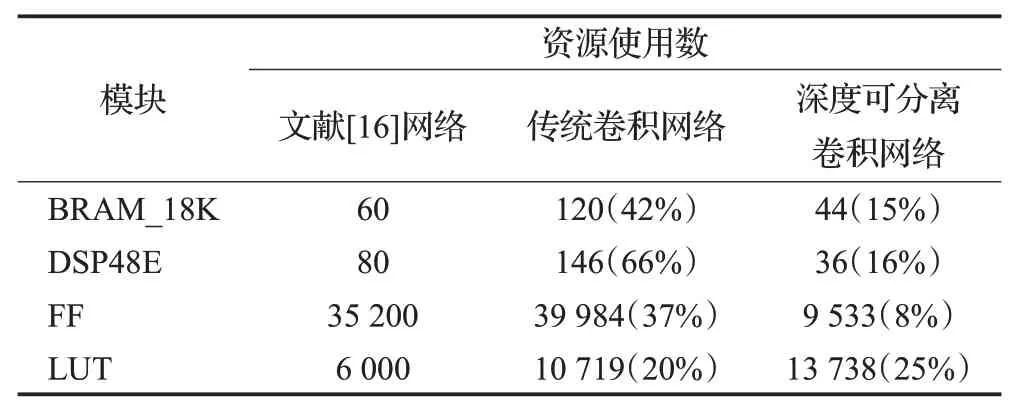
表1 FPGA硬件资源消耗对比Table 1 FPGA hardware resource consumption comparison
硬件加速以消耗大量的硬件资源为代价,用资源换取速度。由表1可知,经过硬件加速的传统卷积网络相较于文献[16]网络消耗了更多硬件资源,将传统卷积网络改进为深度可分离卷积网络,减少了运算次数与参数数目,可在增加运算速率同时,降低硬件资源消耗。深度可分离卷积的BRAM_18K、DSP48E、FF等模块的消耗相较于文献[16]都有明显降低。
BRAM_18K资源主要用于实现存储量大的缓存。本文卷积运算单元硬件加速部分为保证高并行度运算,进行大量缓存操作,输入行缓存,输出行缓存,权重缓存,因此消耗BRAM_18K资源相对较多。
4.2.2 性能评估
本文使用深度可分离卷积思想构建心音分类器。比较了三层传统卷积神经网络,以及由三层传统卷积网络改进来的六层深度可分离网络对数据集中测试集心音特征谱图进行分类的准确率,如表2所示,证明了深度可分离卷积在对分类准确率影响较小的前提下,缩小了模型的大小,减少了模型参数。

表2 不同神经网络心音分类准确率Table 2 Heart sound classification accuracy of different neural networks
表3是不同网络在不同运算平台下针对心音进行分类的前向过程运行速度对比。参考文献[16]网络在FPGA上处理一张图片需耗时19.41 ms,使用本文的加速方法对参考文献[16]网络进行硬件加速,处理一张图片需耗时7.12 ms,相较于文献[16]中的方法,运行速度提升近3倍。本文的心音分类器模型在CPU平台上处理一张图片需耗时15.95 ms,在FPGA上进行硬件加速后,处理一张图片需耗时1.138 ms,相较于CPU平台上相同网络,运行速度提升近14倍。

表3 不同平台不同网络运行速度对比Table 3 Comparison of different network computing speeds on different platforms
本文通过Xilinx官方提供的Vivado设计工具中的Implementation design估算FPGA运行功耗。传统卷积网络功耗为2.507 W,本文心音分类器功耗为1.819 W,本文心音分类器相较于传统卷积网络在FPGA平台上的运行功耗更低。
5 结束语
本文设计了一种基于轻量级神经网络的心音分类器,针对心音信号进行分类,在FPGA上完成了网络的前向传播过程。并根据卷积运算不同并行特征对其进行多像素多通道并行加速。实验结果表明,该方案在尽可能减少硬件资源消耗的基础上,加快了心音分类器的运行速率。未来进一步的改进主要有两个方面:(1)在FPGA硬件平台上实现心音信号预处理部分;(2)提高逐点卷积并行度。
猜你喜欢
昆钢科技(2022年4期)2022-12-30
昆钢科技(2022年1期)2022-04-19
昆钢科技(2021年6期)2021-03-09
小学科学(学生版)(2019年4期)2019-05-11
计算机技术与发展(2018年5期)2018-05-28
计算机技术与发展(2017年12期)2017-12-20
无线互联科技(2017年6期)2017-04-26
光学精密工程(2016年4期)2016-11-07
光学精密工程(2016年3期)2016-11-07
电测与仪表(2014年15期)2014-04-04
