
基于改进YOLOv3的高速公路隧道内停车检测方法
2021-12-12 02:52杨祖莨刘晋峰闫国亮
计算机工程与应用 2021年23期
丁 冰,杨祖莨,丁 洁,刘晋峰,闫国亮
太原理工大学 电气与动力工程学院,太原 030024
随着高速公路建设快速发展,高速公路隧道的运营里程不断增加,为人们带来很多便利。然而,由于隧道内空间狭小、具有一定密闭性、光照受限等特点,发生于隧道的高速公路交通事故比例最高[1]。尤其是载有易燃易爆物品的车辆在隧道内停车导致的问题将更为严重。例如2014年在晋济高速岩后隧道“3·1”特别重大道路交通危化品爆燃事故共造成40人死亡、12人受伤和42辆车烧毁[2]。为有效地减少交通事故的发生,尤其是避免二次事故的发生,准确快速的高速公路隧道内停车检测是十分必要的,对高速公路隧道管理系统的智能化发展意义重大。
在实际高速公路隧道中已经部署安装了大量的视频监控设备(包括高清网络摄像机、光纤传输线路、高速交换机等),这些设备含有丰富的车辆信息。基于此,越来越多的研究者将视频数据作为切入点研究车辆的各种行为状态,逐步提升管理效率,缓解海量监控摄像头与有限监控能力之间的矛盾。在基于视频图像的停车检测研究初期,研究主要集中于传统图像处理方向并且绝大多数是针对露天的场景,Guler等人[3]采用Peripheral多目标跟踪器从背景减法获得的前景中确定每辆车的位置,但该方法会将快速变化的背景错误地检测为车辆。Porikli等人[4]提出基于双背景的异常事件检测方法,该方法中用于建立长、短背景的时间常数存在很大不确定性。赵敏等人[5]基于混合高斯模型检测静止目标,根据车辆的区域特征对静止目标中的停车车辆进行识别,但仍然缺乏对车辆识别的鲁棒性。随着卷积神经网络在图像检测与识别领域的快速发展,在停车检测中也引入了卷积神经网络。文献[6]在传统图像处理方法基础上引入了卷积神经网络模型识别车辆,这样一定程度上克服了灯光干扰带来的误检,但并不能从车辆检测的根本上改进。于青青等人[7]将实时压缩跟踪方法与经典的KLT运动角点检测方法相结合,提取视频中车辆的运动轨迹,以检测车辆的侧路停车行为。姜明新等人[8]使用背景建模技术,检测监控区域内的运动目标,并通过计算联通区域面积来过滤其他物体的干扰,最终检测出违停车辆。石时需等人[9]利用混合差分技术提取视频中的车辆目标,用粒子滤波算法跟踪运动的车辆,实现车辆的停车检测行为。杜金航等人[10]也对YOLOv3进行改进,从而实现道路车辆目标检测,但此算法受光照及目标的快速运动影响较大,不适用于高速公路隧道内。
目前,虽然基于深度学习的目标检测模型已经有了广泛应用,但是这些模型对于高速公路隧道内车辆的检测并不适用,同时基于某省高速公路隧道管理的实际需求,利用真实的高速公路隧道内监测的视频图像来展开停车行为检测的研究是有必要的。相比于露天环境,高速公路隧道所特有的性质为停车检测增加了诸多难度,其中包括:(1)距离摄像头远近不同的车辆在画面中的大小显著不同,尤其是大型车在近距离和小型车在远距离的时候尺寸差异尤为明显;(2)车灯、环境照明灯光及路面的反射光等干扰,影响检测的准确率。因此,在实际需求的驱动下,开展了高速公路隧道中停车检测技术的研究。研究中技术的创新性在于:(1)改进了YOLOv3模型,使其更适用于车辆的检测,更适合于高速公路隧道内的停车检测任务,提高了其在车辆检测上的mAP;(2)在车辆检测数据集方面,修改整理了公开的数据集,并且制作了高速公路隧道车辆数据集;(3)将Deep SORT跟踪算法应用于停车检测中来,并提出根据双重速度阈值来判别停车。
1 改进YOLOv3的高速公路隧道内车辆检测模型
在停车检测中首先需要建立车辆检测模型,从视频中检测出车辆,然后再判断是否发生停车。而对于深度学习车辆检测模型来说,模型的网络结构和训练所用的数据集起到非常关键的作用。
1.1 改进YOLOv3车辆检测网络结构
YOLOv3[11]是YOLO系列深度学习目标检测模型的最新研究成果,其检测精度和检测速度在均衡性上更适宜作为车辆检测的基础网络结构。相较于YOLOv1[12]和YOLOv2[13],YOLOv3特征图的尺寸是不同的,且应用在每一个特征图上的候选框的大小也是不一样的,这样对于不同尺寸的目标的适应能力更强。但对于高速公路隧道场景中的车辆检测,YOLOv3检测层的特征图语义信息不够丰富,缺少对低层深度特征的处理,尤其是低于36层的特征图,这样会导致在隧道内的停车检测中,远距离小型车辆的检测效果不好。因此,在对YOLOv3网络结构进行改进中,通过上采样、融合低层深度特征获得更大的特征图,提高了隧道内小目标车辆的检测准确率。
图1所示为设计的车辆检测网络结构,将其命名为YOLOv3-TunnelVehicle。YOLOv3-TunnelVehicle网 络结构的输入是监控视频的整幅图像,通过一系列不同的卷积层进行运算,输出检测到的所有车辆边界框的位置及尺寸。详细地来讲,首先该网络结构采用深度残差网络提取车辆特征,在深度残差网络结构的第11层、第36层、第61层和第79层分别获得128×128×128、64×64×256、32×32×512和16×16×512的特征图尺寸。其次,在残差网络之后添加多个卷积层,并将其分成4个分支,形成多尺度预测网络。为了获得更丰富的语义信息,YOLOv3-TunnelVehicle将预测网络中的特征图通过上采样的方式提高特征图的尺寸,与深度残差网络中相对应的特征图进行融合(第85层32×32×256与第61层32×32×512融合获得32×32×768的特征图,第97层64×64×128与第36层64×64×256融合获得64×64×384的特征图,第109层128×128×128与第11层128×128×128融合获得128×128×256的特征图)。最后,利用非极大值抑制的方法剔除重复的边界框,得到最终的车辆检测结果。

图1 YOLOv3-TunnelVehicle网络结构Fig.1 Network structure of YOLOv3-TunnelVehicle
另外,值得一提的是车辆检测模型中车辆边界框的预测采用K-means聚类进行边界框的初始化。该方法基于Faster R-CNN[14]中的Anchor机制,但其区别在于默认框的尺寸大小是采用K-means聚类确定的,而非人为设定。如图2所示,tx、ty、tw、th为模型直接的预测输出值。cx、cy为单元格相对于左上角的坐标,每个单元格的单位长度为1,图中示例为cx=1,cy=1。tx、ty分别经过Sigmoid函数后得到0至1之间的偏移量,该偏移量与cx、cy相加后得到边界框中心点的位置(bx,by)。pw、ph是边界框初始化后的宽和高(即默认框的尺寸),tw、th分别与pw、ph作用后得到边界框的宽和高bw、bh,在宽度和高度的计算中引入了对数空间的变化,以使计算出的宽度和高度始终不为负,确保在训练过程中针对具有不等条件约束的优化问题解决求梯度过程。(bx,by,bw,bh)即为预测边界框的位置及尺寸。

图2 车辆边界框的预测Fig.2 Projections of vehicle boundary frames
1.2 数据集
由于当前公开数据集没有针对隧道内车辆的图片,针对数据集展开了两项工作:(1)对公开数据集Pascal VOC[15]进行修整,考虑车辆的类别和外形、位置、光照强度及场景等因素,筛选出与高速公路隧道内车辆相似的数据;(2)为了进一步体现高速公路隧道内车辆的特点,制作了高速公路隧道车辆数据集。
在对VOC数据集的修整中,为了防止冗余数据拖慢网络训练效率,开展了所做工作如下:(1)从原始VOC数据集的20类目标中筛选出car、bus和train这三类。VOC数据集经过筛选后,含有car、bus、train中一类或多类的样本情况为:VOC2007为2 249个样本,VOC2012为2 134个样本。(2)将VOC数据集中car、bus和train这三类合并为一个类别并命名为vehicle。
图3分别展示了VOC数据集和使用实际高速公路车辆图片制作的数据集。从图中可以看出,即使挑选出的VOC数据集中的车辆图片与实际高速公路隧道内的车辆图片仍然存在较大差别,因此,制作高速公路隧道数据集是十分必要的。所制作的高速公路隧道数据集所有图片均来源于实际的高速公路隧道监控视频,总共为1 599张。

图3 车辆图片Fig.3 Vehicle pictures
对于修整完的数据集xml标签文件,将其转换为深度学习框架Darknet[16]所需的txt样式标签文件。其中,各个目标标注框的坐标做如下转换:
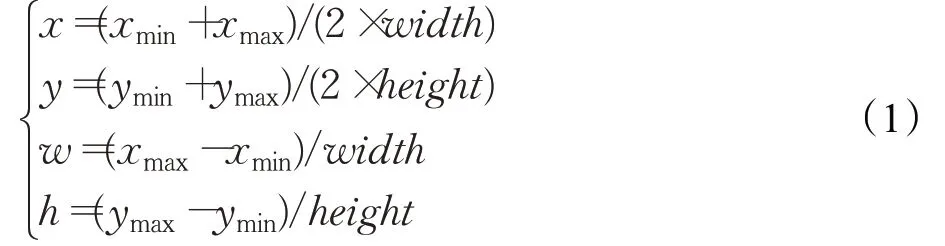
其中,(xmin,ymin)、(xmax,ymax)分别为标注框的左上角坐标和右下角坐标,而width和height为图像的宽和高。
1.3 车辆检测模型的实验结果与分析
在实验中,对改进的车辆检测模型进行了对比,其中VOC-20类数据集训练YOLOv3模型的结果来自于文献[17],其余结果均来自于本实验。实验分为:采用VOC-carbustrain三类目标数据集训练YOLOv3模型;采用VOC-vehicle一类目标数据集训练YOLOv3模型;采用VOC-vehicle一类目标数据集分别训练YOLOv3模型和YOLOv3-TunnelVehicle模型;采用Tunnel-vehicle一类目标数据集分别训练YOLOv3模型和YOLOv3-TunnelVehicle模型。本实验中采用轻型的深度学习框架Darknet进行训练与测试。在整个训练过程中,进行10 000轮次的迭代,其中动量和权重衰减分别配置为0.9和0.000 5,批量大小设置为64,学习率初始为0.001。
在模型训练完成后,各个实验分别取得的mAP为85.06%、85.44%、86.50%、97.54%和98.19%,如表1所示。第一个对比实验针对原始YOLOv3,采用剔除无用目标的VOC-carbustrain数据集来训练,车辆检测的mAP提高了0.56个百分点,表明VOC-carbustrain数据集对于提升车辆检测的准确率是有效的。第二个对比实验是为了验证将car、bus、train三类目标变为vehicle一类目标的有效性,采用相同网络结构和先验框进行对比实验,实验结果表明:将car、bus、train三类目标变为vehicle一类目标使得mAP提高了0.38个百分点。第三个对比实验是用来验证所设计的YOLOv3-TunnelVehicle网络结构的有效性,实验中采用相同的先验框和相同的数据集,结果表明YOLOv3-TunnelVehicle相比于YOLOv3在VOC-vehicle数据集和Tunnel-vehicle数据集上车辆检测的mAP分别提升了1.06个百分点和0.65个百分点。最终,得到了在Tunnel-vehicle数据集上训练的mAP为98.19%的高速公路隧道车辆检测模型。
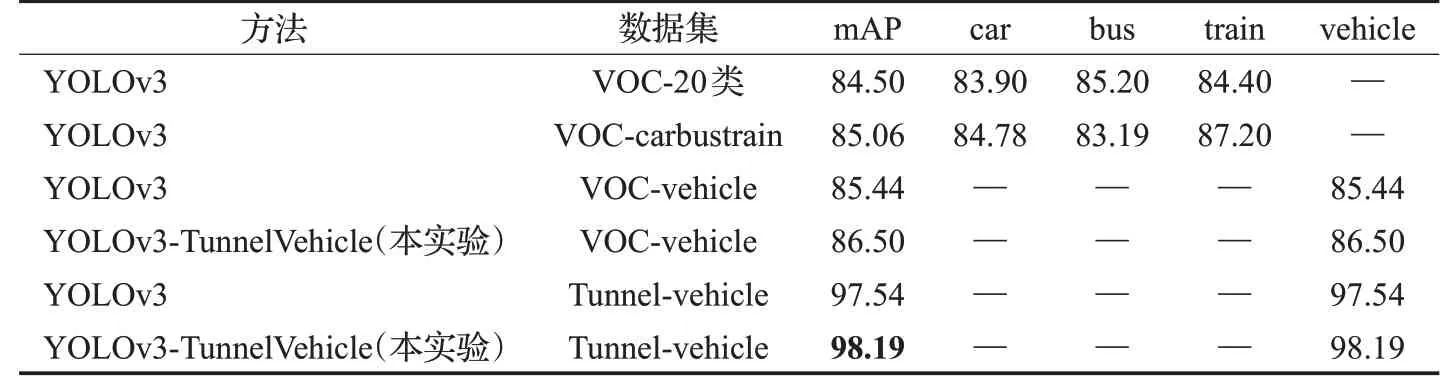
表1 YOLOv3网络结构优化实验结果Table 1 Results of YOLOv3 network structure optimization experiment %
2 提出的高速公路隧道内停车检测方法
2.1 基于改进YOLOv3的高速公路隧道内停车检测
图4为提出的高速公路隧道内停车检测方法的结构。首先,采用1.2节中所改进的YOLOv3车辆检测模型检测出车辆的位置;其次,在获得车辆的具体位置后,将其输入给Deep SORT(Deep Simple Online and Realtime Tracking)[18]多目标跟踪算法来跟踪车辆,进而计算被跟踪车辆的速度来判断是否停车。

图4 提出的高速公路隧道内停车检测方法结构图Fig.4 Structural diagram of proposed method for detecting vehicle stopping in highway tunnels
Deep SORT是基于SORT算法改进的,利用运动信息和外观信息进行数据关联。对于视频输入,通过车辆检测模型可以得到车辆的边界框,但是无法判断每个边界框属于哪个跟踪目标,因此需要匹配算法将当前帧中检测到的车辆边界框与上一帧的车辆跟踪目标进行匹配。在匹配过程中,由于车辆跟踪目标常常是运动的,因此先采用卡尔曼滤波来估计车辆跟踪目标的状态再完成匹配。车辆检测目标的跟踪分配包括运动匹配、外观匹配和级联匹配。其中,运动匹配是通过平方马氏距离来测量历史帧中跟踪目标的卡尔曼状态与当前帧中车辆检测边界框之间的运动匹配程度。在外观匹配中,采用余弦深度特征表示车辆检测目标和跟踪目标的外观。在获得外观特征后,使用余弦深度特征之间的余弦距离测量两者的外观相似度,从而进行外观匹配。级联匹配将运动匹配和外观匹配结合在一起,实现车辆检测边界框与最近出现的跟踪目标相匹配。
综上,提出新的停车检测算法融合了深度学习车辆检测模型YOLOv3-TunnelVehicle和Deep SORT跟踪算法。首先,通过YOLOv3-TunnelVehicle模型进行车辆检测,获得车辆边界框的位置坐标和形状参数;其次,将车辆检测的结果输入Deep SORT跟踪算法中得到当前车辆跟踪的情况,这些情况共分为新加入跟踪序列的车辆、正在跟踪序列中的车辆和离开跟踪序列的车辆;最后,对于上一步中“正在跟踪序列中的车辆”,在Deep SORT跟踪算法后将获得该类车辆在当前帧中的质心坐标位置。因此采取了基于车辆在相邻检测帧中的质心坐标信息检测停车方法,具体为:计算被跟踪车辆的质心移动距离,如果该距离小于5个像素则判定该车辆区域为疑似停车的区域;之后对于被判定为疑似停车的车辆进行“更严格”的判断,即当车辆的质心移动距离小于2个像素时,判定该车辆区域为确认停车的区域。
值得注意的是,上文中所提到的判定疑似停车的阈值“5”和判定确认停车的阈值“2”是在实际高速公路隧道视频的实验中获得的经验值。在此经验值的基础上,如果将第二个阈值设置得过于精确,那么本应该被判为确认停车的车辆,则有可能被漏检。如果第一个阈值设置得不够精确,则会造成较多未停车辆被判定为疑似停车,对第二次判别进行干扰,增高误检率,为了更加直观地说明此情况,增加以双重阈值设置为“10”和“2”的实验,将此实验结果与双重阈值为“5”和“2”的结果进行对比。
2.2 停车检测的实验结果及分析
在本停车检测实验中,改进的YOLOv3车辆检测模型是基于Darknet训练得到的,但是Darknet对于停车检测算法的实现并不便捷,因此在停车检测的部分采用Keras框架来构建。Keras是用Python编写的高级神经网络API,它具有模块化和易扩展性的优点,使得代码紧凑,易于调试。经过模型文件的转换,将Darknet框架下的“.weights”文件转换为Keras框架下的“.h5”文件。
在实验中,采用实际高速公路隧道场景下的视频做测试,双重阈值分别设置为上文提到的“5”和“2”,即相邻检测帧中的车辆质心坐标移动距离小于5个像素时,判定其疑似停车,接着当疑似停车车辆的质心移动距离小于2个像素时,判定其确定停车。图5为本实验结果的展示,其中箭头所指处即为检测到的停车。为了验证此方法的广泛适用性,所测试的视频包括了高速公路隧道内各种典型的车辆:近距离大型车、一般中型车和远距离小型车。详细的实验统计结果如表2所示。

图5 基于改进YOLOv3车辆检测的停车检测结果示例Fig.5 Example of stopping detection results based on improved YOLOv3 vehicle identification
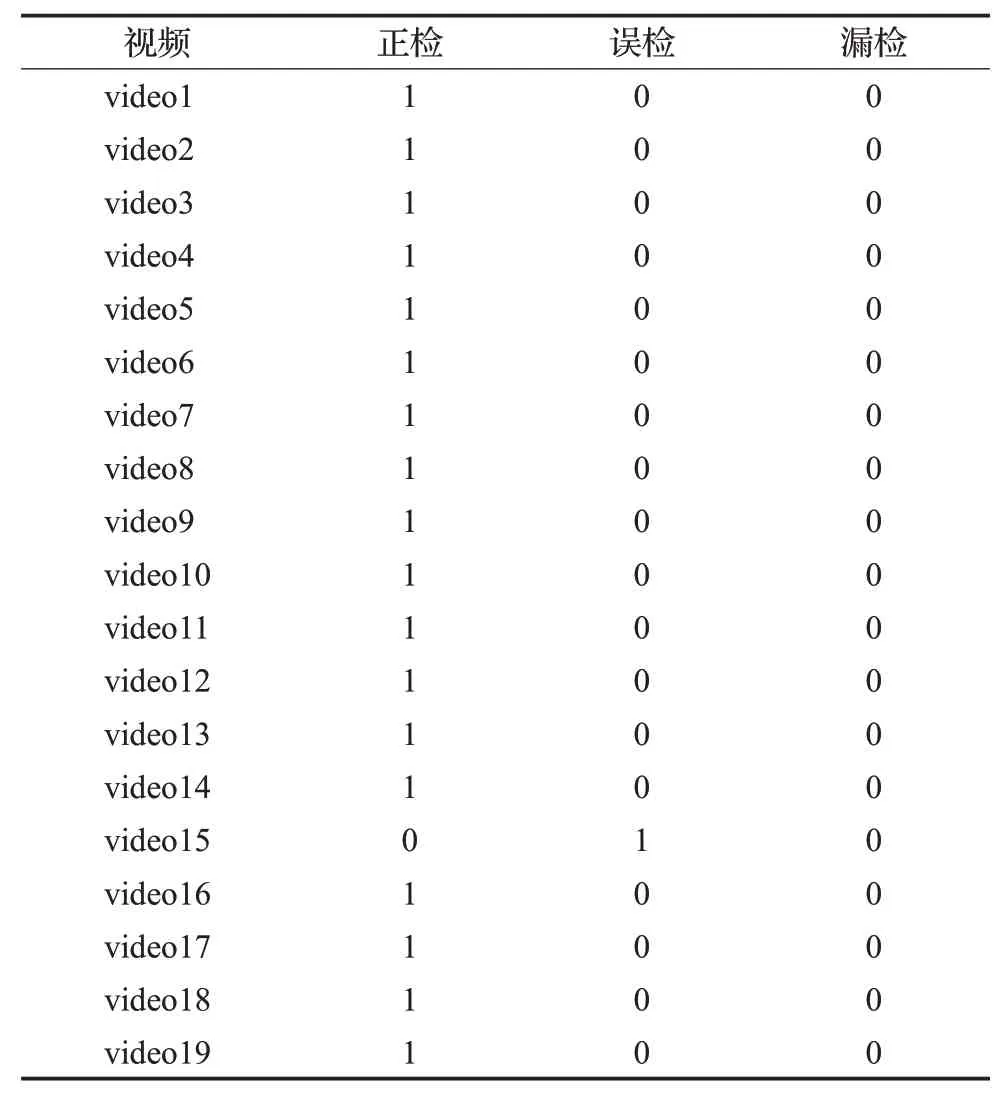
表2 基于改进YOLOv3车辆检测的停车检测详细实验结果Table 2 Detailed experimental results of stopping detection based on improved YOLOv3 vehicle identification
在19个高速公路隧道测试视频的实验中,最终获得的正检率为95%,误检率为5%,漏检率为0。实验结果表明基于改进YOLOv3车辆检测的停车检测可以较好地在高速公路隧道中完成停车检测的任务,进一步提高停车检测的效率,为高速公路管理系统赋予更多的智能化与高效化。对于引起误检的情况进行分析,发生误检的停车检测如图6所示,主要原因是:(1)该大型货车行驶速度缓慢;(2)车身长度较长;(3)绿色的车篷布在一段时间内表现出几乎完全相同的特征。因此,停车检测算法出现了误判。
在此实验中,检测结果的准确性也受双重阈值设定的影响。如果第一个阈值设定不够精确,则同一段视频中判定为疑似停车的数目会有所增加,对第二次判定进行干扰,从而增大了误检率,为了更详细地说明此情况,将车辆检测模型的双重阈值设为“10”和“2”进行实验,详细的实验结果统计如表3所示。

图6 发生误检的停车检测Fig.6 Vehicle stopping with false detection

表3 基于改进YOLOv3车辆检测的停车检测详细实验结果(双重阈值设定为“10”和“2”)Table 3 Detailed experimental results of stopping detection based on improved YOLOv3 vehicle identification(1st and 2nd thresholds are“10”and“2”separately)
由表3可知,当双重阈值分别设定为“10”和“2”时,在19个高速公路隧道测试视频的实验中,正检率为95%,误检率为37%,漏检率为0。此结果相较于双重阈值为“5”和“2”的实验结果,虽然正检率相同,漏检率为0,但是误检率由5%增加为37%,相对地降低了停车检测的准确率,还会使执行检测任务的效率降低。通过对比可以得出,当双重阈值设定为“5”和“2”时,基于改进YOLOv3的车辆检测模型可以较准确、较高效地完成高速公路隧道内停车检测的任务。
3 结束语
本文提出了一种基于改进YOLOv3车辆检测模型的停车检测方法。对于YOLOv3车辆检测的改进,在VOC-vehicle数据集和Tunnel-vehicle数据集上的车辆检测mAP分别提升了1.06个百分点和0.65个百分点。最终,训练得到了mAP为98.19%的高速公路隧道车辆检测模型。获得车辆检测模型后,结合Deep SORT进行车辆跟踪并通过计算车辆速度来判断停车。在高速公路隧道停车测试视频上的正检率达到95%。本文取得了一定成果,但仍然存在值得进一步研究的地方,例如:可继续扩充训练数据,提高模型的鲁棒性,使其适用于更加复杂多变的场景[19];对于视频画面中由于烟雾导致的模糊问题,可采用暗通道去雾算法[20]进行修正或研究其他方法。
猜你喜欢
制造技术与机床(2019年9期)2019-09-10
中国外汇(2019年6期)2019-07-13
小读者(2019年24期)2019-01-10
西南交通大学学报(2018年6期)2018-12-18
河北遥感(2017年2期)2017-08-07
小天使·四年级语数英综合(2016年11期)2016-11-29
衡阳师范学院学报(2016年3期)2016-07-10
中国交通信息化(2016年9期)2016-06-06
中国交通信息化(2015年7期)2015-06-06
小说月刊(2014年4期)2014-04-23
