
基于语音和视频图像的多模态情感识别研究
2021-12-12 02:51王传昱李为相陈震环
计算机工程与应用 2021年23期
王传昱,李为相,陈震环
南京工业大学 电气工程与控制科学学院,南京 211816
识别情感一般有两种方式,一是检测生理信号(如心率、脑电、体温等),另一种是检测情感行为(如面部特征、语言特征、姿态等)[1]。按照准确性排序,目前应用于情感检测的单模态主要有生理参数(脑电图)、脸部表情、语音、肢体动作;按照采集难度和实用性排序,则为语音、脸部表情、肢体动作、生理参数(脑电图)[2]。其中肢体动作因为其准确性较低、实用性一般,通常作为其他模态的辅助识别方式;而生理参数的识别准确率虽然很高,但是由于采集需要配备专业设备,采集难度高,实用性一般,在实际场景中很少使用。而语音和人脸表情的采集难度中等,识别准确率较高,是当前研究的热门。丁名都等[3]将卷积神经网络(CNN)和方向梯度直方图(HOG)方法结合研究,提取更多的表情特征,在高兴情感上取得了90%的识别准确率;兰凌强等[4]提出基于联合策略(FRN+BN)识别人脸表情,在CK+数据集上提升了5.6%的识别准确率;李田港等[5]将KNN、SVM、BPNN分类方法进行集成,提高了语音情感识别率。随着融合算法研究的深入,多模态情感识别取得了快速的发展[6]。多模态融合能够提升识别率,且具有更好的鲁棒性[7-8]。目前常见的多模态情感检测方法主要有生理信号+情感行为组合,不同情感行为之间的组合。人脸表情和语音这两个模态由于在视频中直接可提取,所以具有数据采集方便、特征明显、精度高等优点,是实际应用中最广泛的情绪识别方法。Zeng等[9]提出了隐马尔科夫模型进行双模态情绪识别,使用最大熵原理和最大互信息准则进行了人脸表情和语音的模态融合,通过单模态和多模态情绪识别的对比实验,验证双模态情绪识别算法的合理性。Li等[10]用LSTM-RNN网络模型进行样本训练,并使用条件注意融合策略完成人脸表情和语音的情绪识别研究,提高了情绪识别模型的实时性。多模态融合识别可以在信号、特征、决策层进行,对不同模态信号可以采取不同的融合策略,以达到最佳的识别结果[11]。
心理学家Mehrabian[12]通过研究发现,人们日常交谈时文字体现7%的情感,声音及其特征(例如语调、语速)体现了38%的情感,表情和肢体语言体现55%的情感。这说明了在研究情感识别问题上,面部表情和声音传达了主要信息。
本文使用改进的卷积神经网络(LBPH+SAE+CNN)训练并测试fer2013数据集,完成视频图像通道的模型搭建,使用反向传播算法(BP)改进的长短期记忆人工神经网络(DBM+LSTM)训练chaeavd2.0视频情感数据库的训练集语音信号搭建模型,并在决策层对识别结果进行融合,输出情感分类及在不同情感分类上的可能性。除了验证本文所提方法的有效性,本文还实现了对使用者情感的实时分析:通过调用摄像头和麦克风采集一段视频和语音,用LBPH算法识别并锁定人脸区域,再通过SAE+CNN神经网络模型分析使用者情感状态,完成对图像通道的识别;使用Spleeter和FFmpeg分离工具分离背景音和人声,经过对语音信号的滤波和分帧加窗的预处理后,调用opensmile工具提取声学特征并分类,完成对语音模态的识别,最后在决策层对两种模态的分类结果进行融合并输出最终结果。实验结果表明,本文提出的研究方法可以提升识别的准确性,且具备处理速度快,可移植性强的优点,有较强的使用推广价值。
1 视频图像模态设计
1.1 LBPH算法
局部二值法(LBP)在1996年由Ojala等[13]提出。LBP算子定义在像素3×3的邻域内,以邻域中心像素为阈值,相邻的8个像素的灰度值与中心进行比较,若大于中心像素值,则该像素点的位置被标记为1,否则为0。
图像的尺度产生变化时,LBP特征编码在反映像素点周围的纹理信息时会出现错误。鉴于这种情况,本文使用Extended LBP特征,改进后的方法使用圆形、可拓展的邻域。图像的尺度产生变化时,LBP特征编码在反映像素点周围的纹理信息时会出现错误。鉴于这种情况,本文使用Extended LBP特征,改进后的方法使用圆形、可拓展的邻域。对于给定中心点(xc,yc),其邻域像素位置为(xp,yp),令p的值小于P,则(xp,yp)可以用公式(1)表示:

其中,R是采样半径,p是第p个取样点,P是总采样数目。由于计算的值可能不是整数,即计算的点不在图像上,所以采用双线性插值的方法来避免这种情况。公式(2)如下:
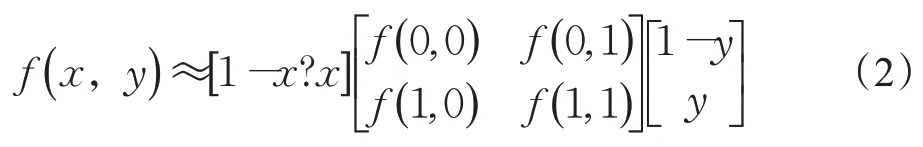
Ahonen等提出LBPH方法[14],将LBP特征图像分成局部块并提取直方图,再依次将这些直方图连接起来形成的统计直方图即为LBPH。本文所采用的LBPH算法添加了实时获取人脸特征数据的功能,其流程如图1所示。
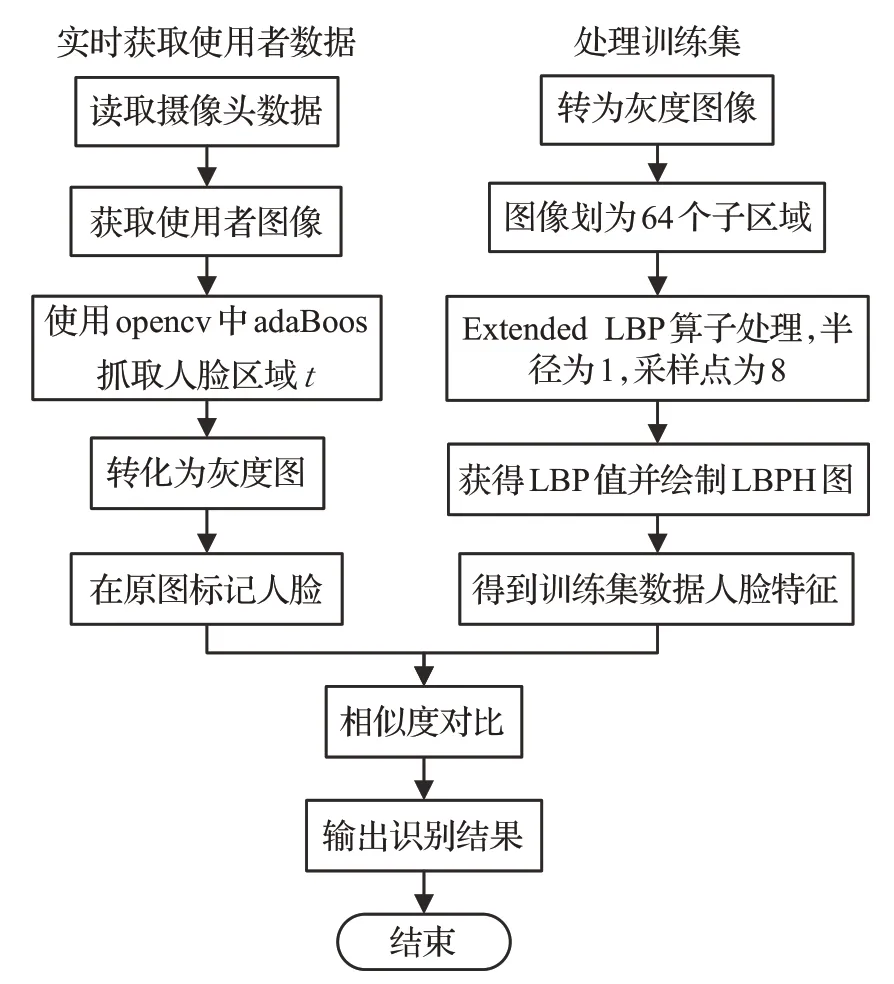
图1 LBPH算法流程图Fig.1 LBPH algorithm flow chart
1.2 SAE算法
人脸表情的边缘信息拥有丰富的情绪特征,本文加入了稀疏自动编码器(Sparse AutoEncoder,SAE)获取图像的情绪细节信息。稀疏自动编码器是一种3层的无监督网络模型,是将输入图像压缩后进行稀疏重构。SAE的主要思想是对隐藏层施加稀疏性约束,迫使隐藏节点数量小于输入节点,从而使网络能学习到图像的关键特征。SAE网络追求的是输出数据约等于输入数据x,并通过反向传播计算网络代价函数来训练模型。
稀疏自动编码器具体实现过程为首先计算第j个隐藏神经元的平均活跃度,公式(3)如下所示:

式中,xi和n分别表示输入层的样本和数量,表示第j个隐藏神经元的激活度。

因此,SAE网络的总体代价函数为:
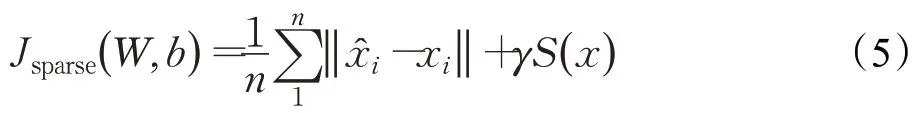
在式(5)中,γ表示稀疏性惩罚项的权重,W和b分别表示各层神经元的权重和偏移量。
最后,通过训练调整SAE网络的参数,来最小化总代价函数,从而可以捕捉输入图像的细节特征。
1.3 改进CNN网络设计
卷积神经网络(Convolutional Neural Network,CNN)是一种包含卷积计算且有深度结构的前馈型网络,神经元之间存在局部连接并共享权值。其主要包括卷积层、池化层、全连接层和输出层[15]。
增加神经网络模型的深度会得到更多特征[16],但获得特征过多时,由于全连接层上要与每一个特征建立连接,会消耗更多的时间且容易发生过拟合。为了攻克这一难题,本文使用了Global Average Pooling(GAP)层取代全连接层。GAP是对空间信息的求和,应对空间变化具有更强的鲁棒性。GAP方法简化了特征图与分类的转换过程,能够有效地减少参数的数量。
假设卷积层的最后输出是h×w×d的三维特征图,具体大小为6×6×3,经过GAP转换后,变成了大小为1×1×3的输出值,也就是每一层h×w会被平均化成一个值。可以看出GAP对降低模型复杂度起到很大的作用,其工作原理如图2所示。
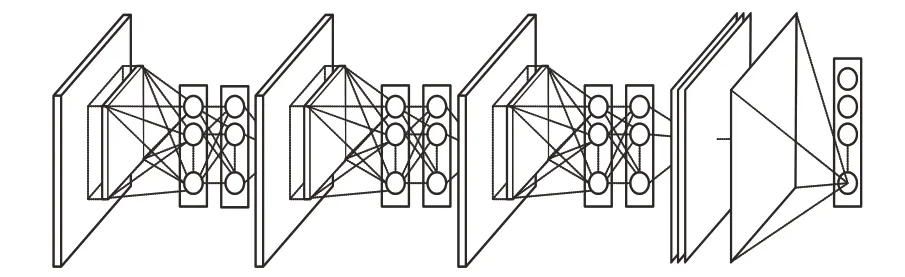
图2 GAP工作原理示意图Fig.2 GAP working principle diagram
除此之外,为减少参数的计算量,本文所用的卷积操作为深度可分离卷积。假设输入特征图的尺寸为DL×DL标准卷积层使用尺寸为DK×DK×M×N,其中DL代表输入图片的长度,DK代表空间维数,M为输入通道数,N为输出通道数。令stride步长为1,则输出特征图的计算量为DK×DK×M×N×DL×DL,深度可分离算法计算量则为DK×DK×M×DL×DL+M×N×DL×DL。将两者进行对比可以得到如下公式:

从此公式中不难看出,深度可分离卷积方法的计算量大幅度减少,这也就意味着处理相同数量参数的情况下网络层数可以做得更深。本文神经网络如图3所示。
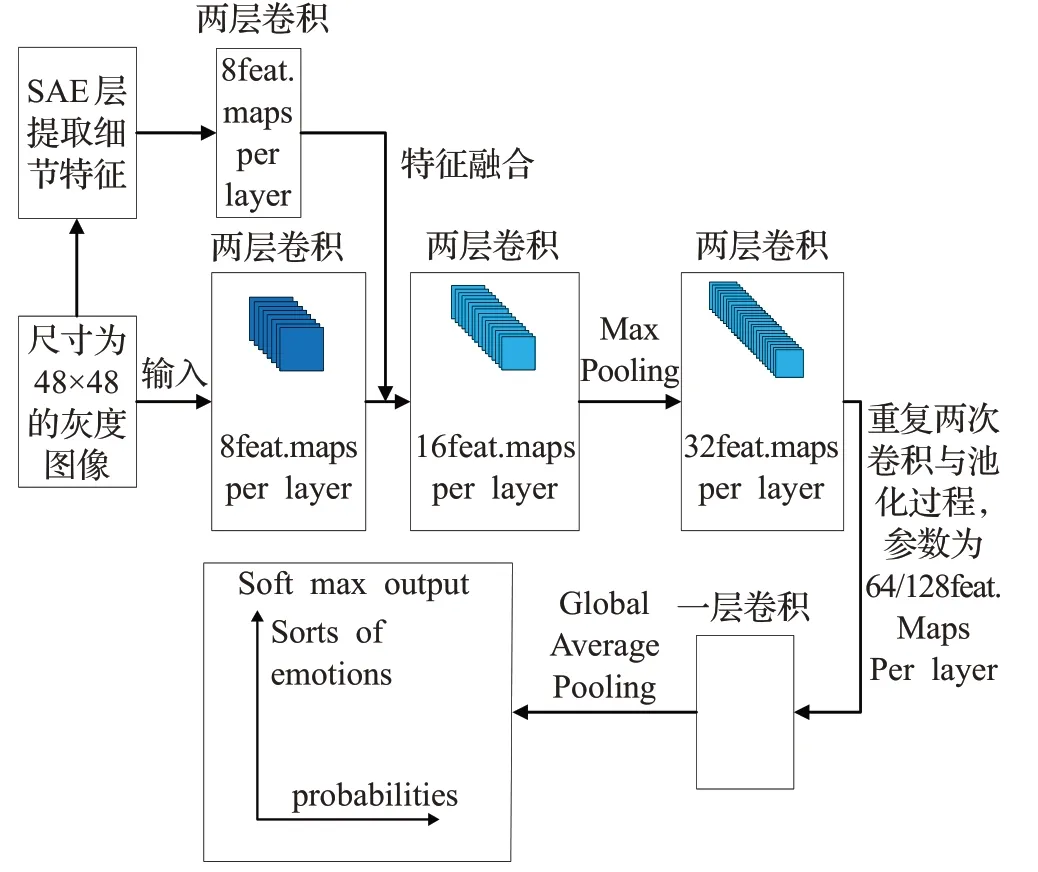
图3 改进神经网络结构Fig.3 Structure of improved neural network
本文所设计的神经网络包在输入层增加SAE层并包含6个卷积层,SAE层通过两层卷积提取图像的细节特征,filter过滤次数为8,并在CNN的第二层将特征输入到网络中;CNN前5个卷积层每一层进行两次卷积并归一化,然后池化后连接下一层,其filter过滤次数由8到128递增,最后一个卷积层进行一次卷积后与GAP层连接,filter数为1,然后进入输出层得到分类结果。全局采用3×3的卷积核,选择ReLU激活函数;池化方法为最大池化,使用GAP代替全连接层,输出层用Softmax做表情的分类。视频图像通道工作流程如图4所示。
2 语音模态设计
2.1 语音特征提取
语音特征的提取需要先对视频进行处理实现音频分离,目前有很多软件可以实现该功能,本文选择组合使用FFmpeg和Spleeter音频分离工具,其中Spleeter可以将摄像头采集到的视频中的声音信号抽离出来,FFmpeg则可以将音频做进一步处理,区分出人声和背景音乐。两款工具都可以使用python工具包调用。
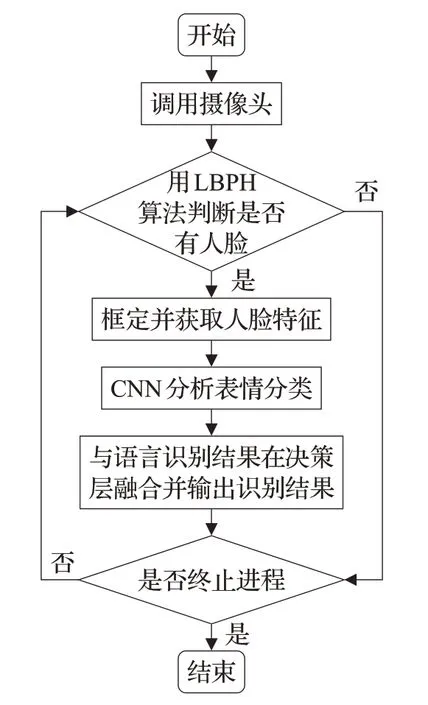
图4 视频图像模态工作流程图Fig.4 Flow chart of video image modal operation
语音信号是一种时变信号,其特征参数是不断变化的,但从微观的角度上看,很短时间的尺度上其特征可以保持一个稳定的状态,这种短时间的语音片段成为帧,一般帧长取10 ms到30 ms[17]。本文选用汉明窗函数ωn和语音信号sn1相乘得到加窗语音信号sω(n),完成分帧操作,汉明窗函数公式如下:
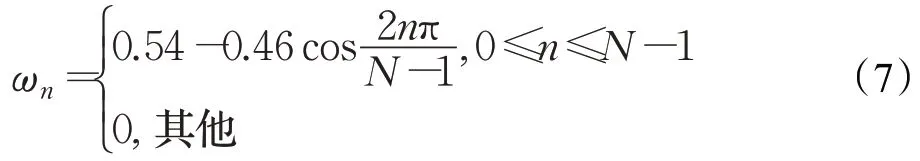
分帧处理完成后,即可对这些预处理的语音片段进行特征提取。使用传统特征(如韵律特征、音质特征、谱特征、Mel频率倒谱系数)虽然在实验中取得了不错的识别效果[18-19],但是语音信号是不平稳的信号,只使用这些传统的特征会出现识别效果受到局限的现象。因此本文选择了韵律特征、梅尔倒谱系数(Mel),并引入了非线性属性、非线性几何特征在特征层进行融合。具体用深度受限波尔兹曼机(Deep-restricted Boltzmann Machine,DBM)实现。
DBM是受限波尔兹曼机(Restricted Boltzmann Machine,RBM)的一种。RBM包含一层可视层和一层隐藏层,在同一层的神经元之间是彼此独立的,但是不同层的神经元之间存在双向连接,在网络进行训练时信息在两个方向上流动,且两个方向上的权值相同。RBM是一种基于能量的概率分布模型。
多个RBM自下向上堆叠,下层输出成为上层的输入组成DBM,从而得到输入特征的深层表示。本文采用三层RBM组成DBM,此时的能量函数如式(8):

联合概率如式(9):
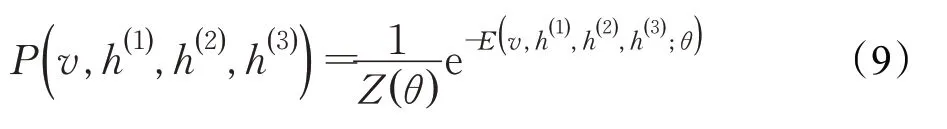
在给定可视层v/h的条件下,隐藏层第j个节点为1或者0的概率如式(10):

其损失函数如式(11):
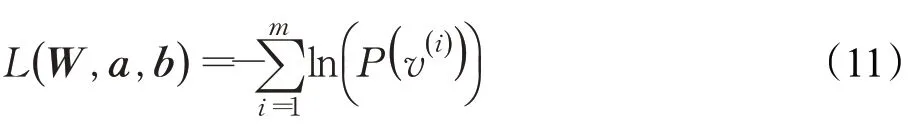
其中,矩阵W表示信息在网络中流动的权值,hj和vj表示hidden layer与visible layer中第j个神经元的状态,向量a和向量b表示偏置,h和v表示神经元的状态向量,θ表示由W、向量a和向量b组成的参数集合。
将样本输入RBM中后,根据隐藏层每个神经元的激活概率P(hj=1|v)和期望E(hj=1|v)组成输出特征向量。训练流程如图5所示。
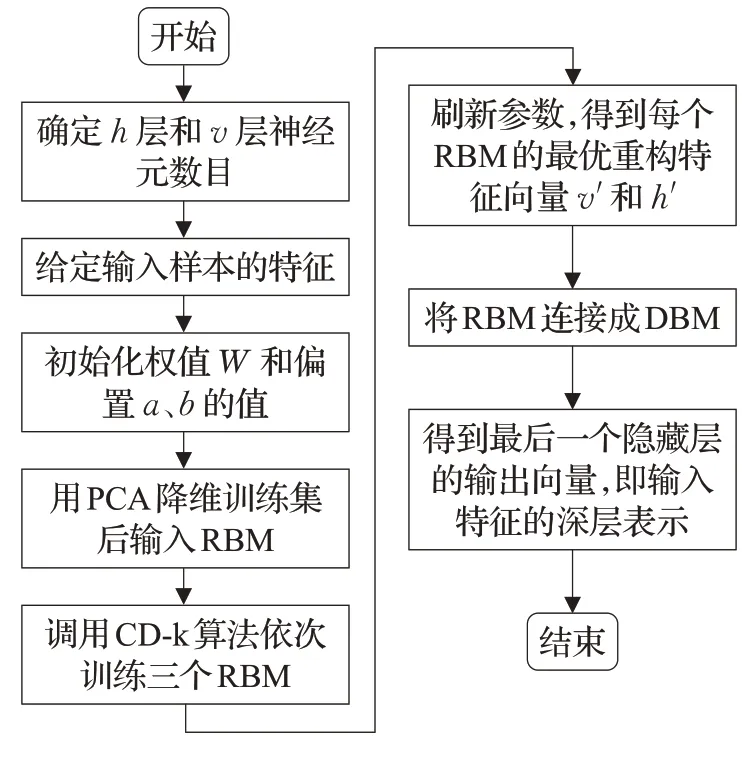
图5 DBM训练过程图Fig.5 DBM training process diagram
搭建三层DBM网络,将选取的四类特征在DBM中进行融合,得到深度的融合特征。每层DBM都是由三层RBM组成。首先将特征输入到DBM1层中进行深度融合并降维,隐藏层输出了特征1、特征2、特征3、特征4;将特征1、2,特征3、4线性拼接并输入到DBM2层,经过深度融合并降维后得到特征5和特征6;重复该过程,特征5、6在DBM3层中成为融合特征,也就是输入特征的深层表示。该过程如图6所示。
2.2 改进LSTM网络设计
在使用DBM网络得到融合特征之后,还需要对语音情感进行分类。本文使用改进的长短期记忆网络(Long-Short Term Memory,LSTM)。LSTM能存储较长一段时间的有用信息,且能优化时间序列的分类任务,在语音识别的应用中,相较于传统模型(时间递归神经网络、隐马尔科夫模型等),拥有更好的性能[20]。LSTM的优势在于当前时刻的输出受输入和前一时刻的输出的影响,可以考虑到特征的时序特性。使用的损失函数为交叉熵代价函数,其表达式为:
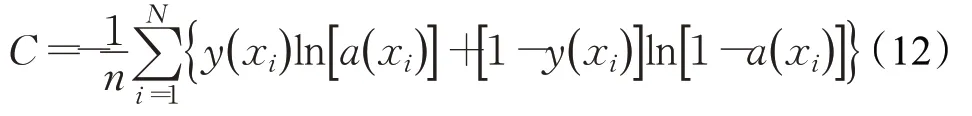
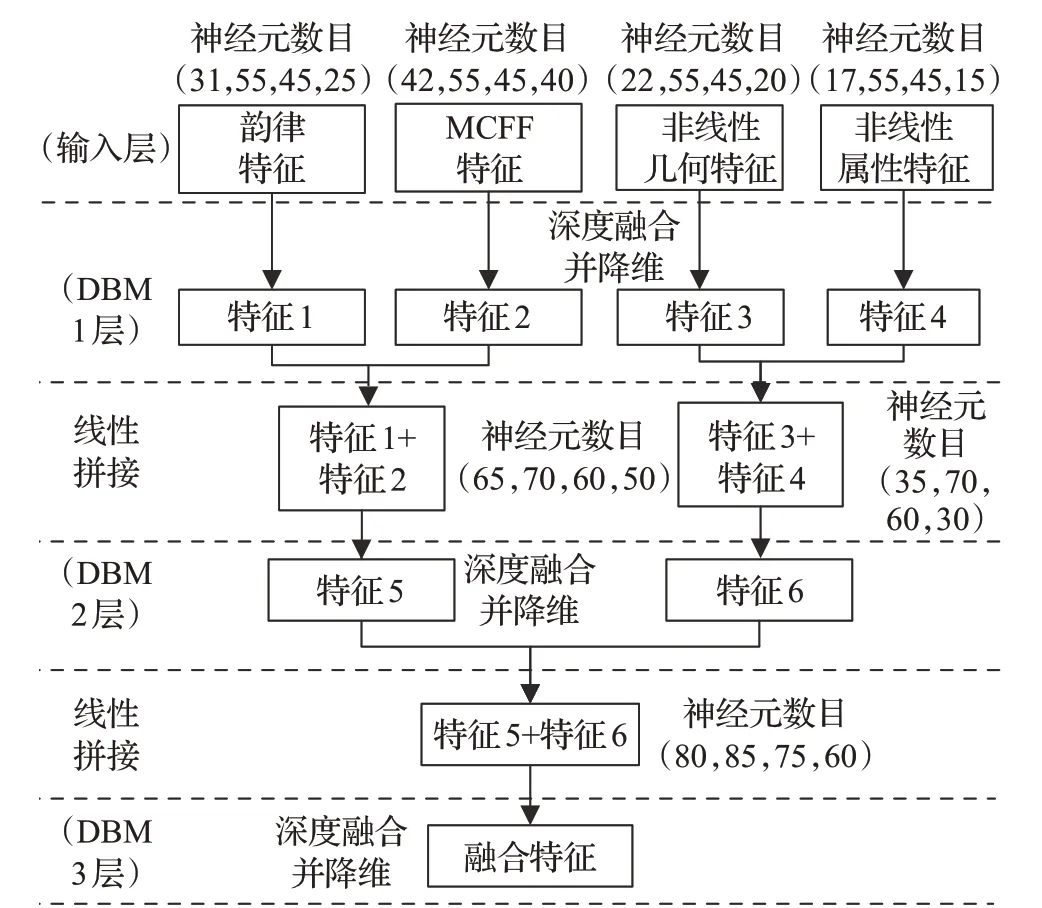
图6 DBM网络结构图Fig.6 DBM network structure diagram
其中,xi代表语音数据,y(xi)表示xi对应的标签,a代表数据的输出值,a(xi)代表具体的xi对应的输出值,n是数据的总数量。交叉熵代价函数在误差大时权重调整的速度更快,误差小时则权重更新慢,有效地提升了系统的处理速度。
在DBM和LSTM网络中使用了可变权值的反向传播算法(Back Propagation,BP)进行优化。对语言通道的网络中增加BP可以增加网络的非线性映射能力,用于处理获取的非线性特征。BP使用梯度下降法调整节点间的权值ωij和节点b阈值,函数表达式(13)为:

其中,η代表神经网络学习率,∂代表偏微分运算,E表示标准误差,为了解决随着迭代次数的增加学习率η会下降的问题,改进的BP神经网络学习率按照公式(14)进行更新:

其中,m为迭代次数,a为大于1小于2的常数,s是迭代学习率的寻找范围。
识别网络部分由三层LSTM堆叠,相较于传统应用在语音识别中的两层LSTM结构网络结构更深,可以得到更多的特征,为了避免发生过拟合现象并提升处理的速度,用GAP层代替了全连接层,最后与softmax层连接。其输入为DBM层处理后的融合特征,输出为通过softmax层输出的情感所属分类与概率。语言通道神经网络结构如图7所示。
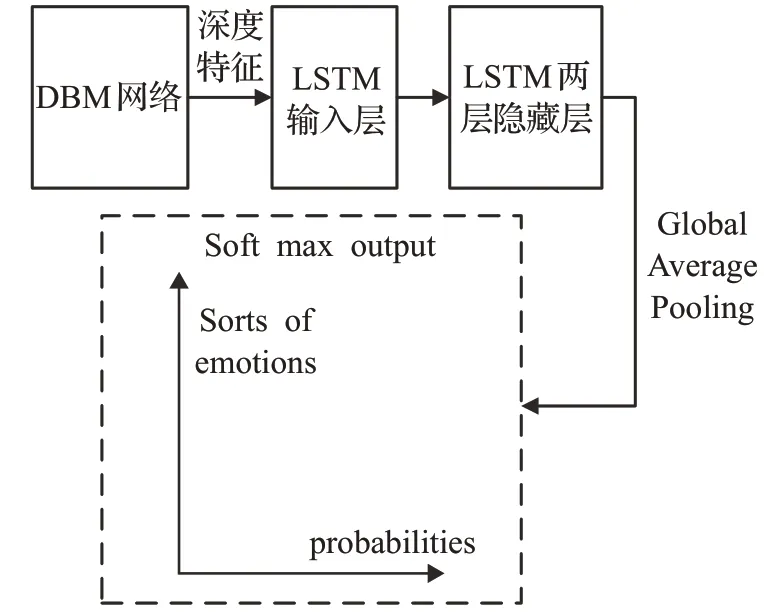
图7 语言通道神经网络结构Fig.7 Neural network structure of language channel
3 实验与实验结果分析
3.1 数据集处理
本文选用fer2013图像数据集[21]和Cheavd2.0视频数据集[22]进行实验。fer2013由35 886张人脸表情图片组成,是目前涵盖不同国家及年龄跨度最广的人脸表情数据库,其样本数量多且已经经过预处理,相比较从cheeavd2.0视频中截取的图片而言质量更高,以此作为训练集可以使模型更加健壮,所以视频图像通道选用f2013数据集进行训练,情感标签为angry生气、disgust厌恶、scared担心、happy开心、sad伤心、surprised惊讶、natural自然。Cheavd2.0语音数据集由7 030个影视及综艺情感视频片段组成,涵盖数据量大且接近真实环境,其平均长度在3.3 s,情感标签为natural自然、angry生气、happy快乐、sad悲伤、worried忧虑、anxious焦虑、surprise惊讶、disgust厌恶。两者在情感分类上非常相似,在前期数据处理中将worried忧虑、anxious焦虑归为scared担心,使两个数据库在情感分类上保持一致,以便在决策层的融合。处理后的Cheavd2.0数据构成如表1所示。
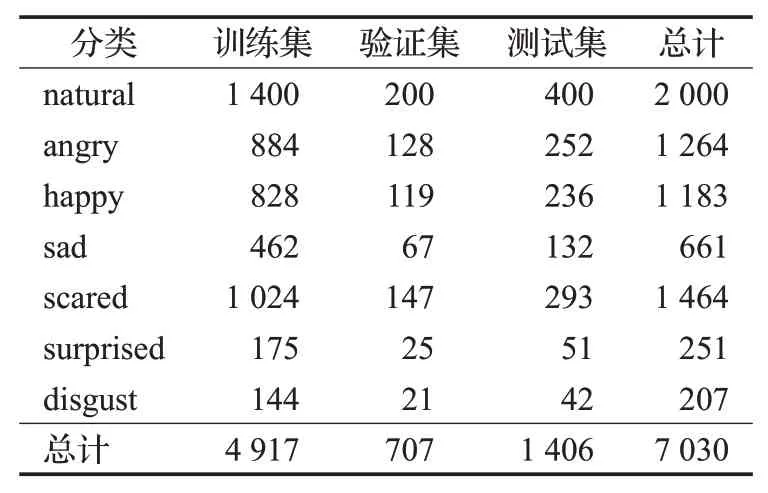
表1 Cheavd2.0数据集Table 1 Cheavd2.0 data set
3.2 决策层融合策略
不同通道采用不同的神经网络可以使单通道的识别率达到最高,而在决策层融合可以使识别结果的准确率得到提升。本文对CNN和LSTM网络进行优化,在视频图像通道使用SAE获取图像的细节特征并与CNN获取的特征进行融合,在语音通道的输入中加入了非线性特征进行特征层融合,并在决策层依据权值准则对不同通道的识别结果进行融合,输出识别结果与在各个分类上的概率。权值准则如下式所示:
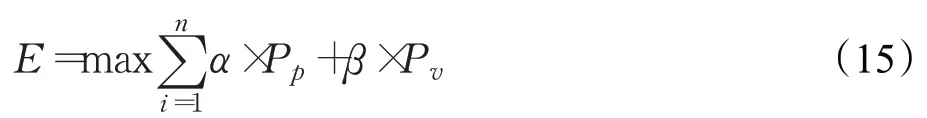
其中,E为情感的类别,Pp为在视频图像通道上分类的概率,Pv为在语音通道上分类的概率,α和β分别为在两个通道上的权值,本文取α=0.6,β=0.4。
3.3 实验结果分析
表2统计了语音通道和视频图像通道的单模态改进算法相较于其他算法的识别效果对比。在语言通道上统一使用柏林语言情感数据集(EMO-DB)进行对比实验,在视频图像通道上统一使用fer2013数据集进行对比实验。

表2 单模态上识别效果对比Table 2 Comparison of identification results on single mode
由表2可知,在语音模态的对比中,本文所用方法优于其余三种方法;在图像模态的对比中,本文所用方法的识别准确率仅略低于VGGNet+Focal Loss法,也取得了较好的识别效果。由此可知,本文提出的改进CNN和LSTM在单模态上是能进行有效识别的。
对于多通道融合的识别效果,本文用cheavd2.0的测试集进行验证。由表3可知,图像通道在使用SAE后可以提升识别准确率,语言通道经过DBM对特征融合后可提升识别的准确率,多模态融合后取得更高的识别准确率。由此可知多模态融合识别策略可以取得更好的识别效果。
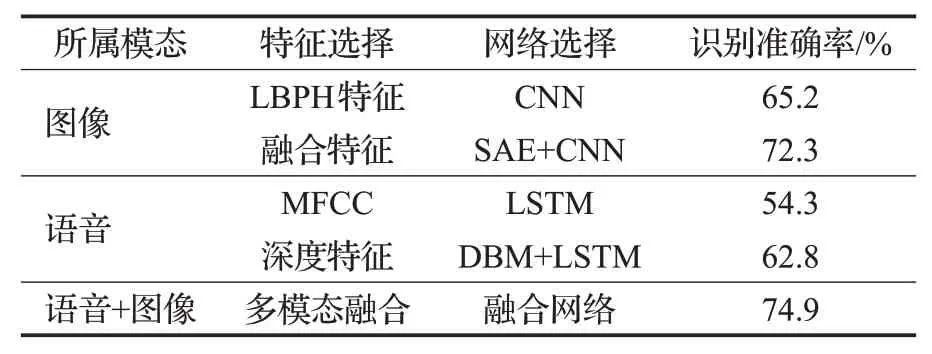
表3 单模态与多模态识别效果对比Table 3 Comparison of single-mode and multi-mode recognition results
其在各类情感上的识别准确率如表4所示,在测试集上各种分类上识别结果的混淆矩阵如图8所示。混淆矩阵的横坐标代表预测情感分类结果,纵坐标代表样本在不同情感上的实际分布情况。横纵坐标一致时代表正确识别,不一致时则说明横坐标所指情感被错分到纵坐标所指情感类型;混淆矩阵可视性更强,可以看到样本在所有情感类型上的分布情况,每个混淆矩阵代表一种识别结果,是对该识别统计表的补充。由表4和图8可知在自然、开心、愤怒、伤心等情感识别中能取得很好的效果,被分到错误的情感类型上的样本也较少,其中被错分到自然情感类型上的样本较多;由于厌恶情感的样本数量较少,导致其识别准确率较低,只有59.5%,其中被错分到自然和愤怒情感类型上的样本最多。整体的识别准确率达到了74.9%,相较于传统的单模态在识别精度上有所提升。
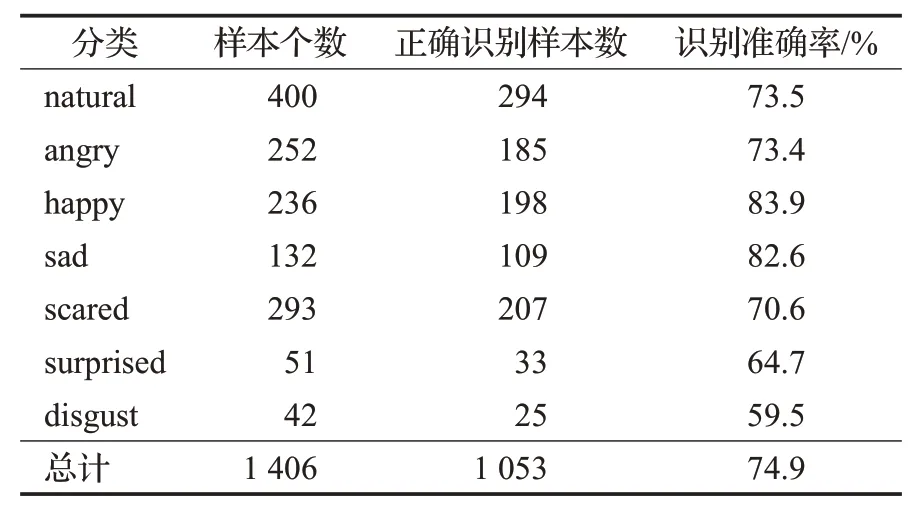
表4 Cheavd2.0测试集各类情感识别准确率统计表Table 4 Cheavd2.0 test set all kinds of emotion recognition accuracy statistical table
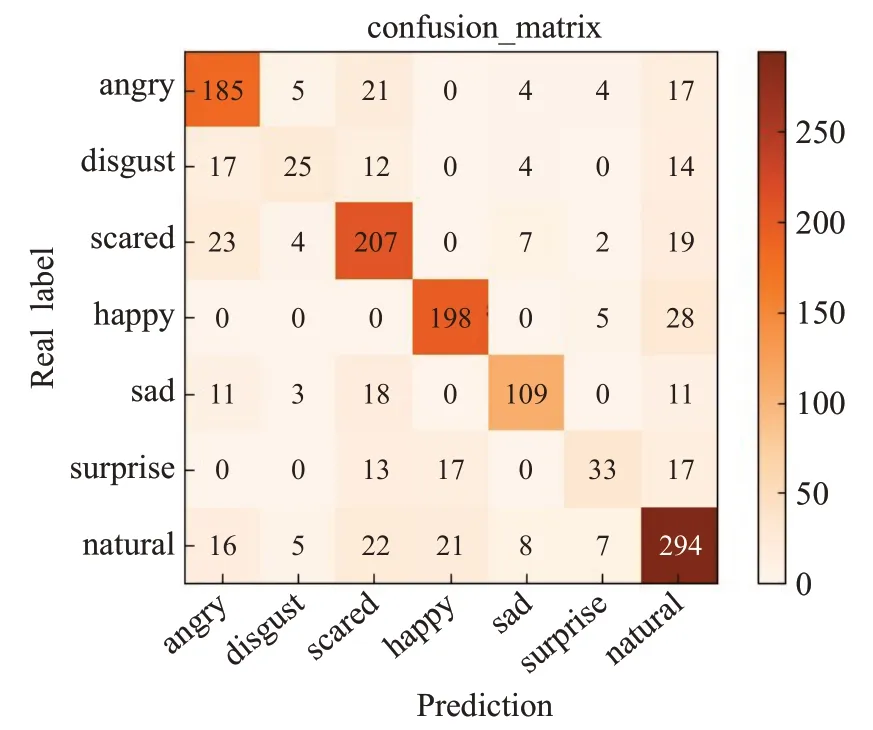
图8 多模态识别结果混淆矩阵Fig.8 Confusion matrix of multimodal recognition results
表5统计了在多模态上,增加在eNTERFACE’05视频情感数据集上进行的多模态情感识别对比实验。数据集中情感分类的数目不一致,eNTERFACE’05数据集相较于Cheacd2.0数据集缺少了一个“自然”情感类型,因此对本文所提方法做出分类数量变化及其相关修改后进行实验。由表5可知,本文设计的算法识别准确率在该数据集上也取得了较好的识别效果,仅略低于刘菁菁等[30]所提的基于Arousal-Valence Space法。
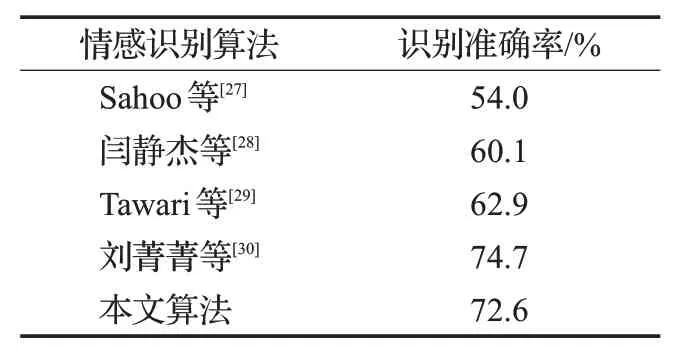
表5 多模态上识别效果对比Table 5 Comparison of identification results in multiple modes
本文实验在Python3.6上实现,硬件平台为Intel®Xeon®Silver 4210 CPU,主频为2.2 GHz,内存为32 GB,GPU为NVIDIA Quadro P4000(8 GB)。本文除了验证了所提方法在cheavd2.0数据集上的识别准确率,还实现了对使用者的情感实时检测,实验效果如图9所示。

图9 实验效果展示Fig.9 Experimental effect display
4 结束语
本文提出一种基于视频图像和语音的多模态情感检测方法并进行相关实验,结果显示,与传统单一模态相比,多模态融合策略可以显著提升情感分类的准确率;但是在某些情感分类上仍然较难,例如厌恶(disgust);由于这些情感的特征和其他情感相似,样本的个数也较少,所以网络需要进一步改良来强化对相似特征的区分。此外,融合脑电信号和肢体动作等对情感识别的准确率也有较明显的提升,获取可靠的其他模态的数据集并搭建合理的融合模型将成为接下来工作中的研究重点。
猜你喜欢
北京航空航天大学学报(2021年9期)2021-11-02
健康之家(2021年19期)2021-05-23
医学食疗与健康(2021年27期)2021-05-13
农业科技与信息(2021年2期)2021-03-27
阅读(快乐英语高年级)(2019年5期)2019-09-10
电子制作(2019年14期)2019-08-20
电子制作(2019年11期)2019-07-04
电子制作(2019年9期)2019-05-30
小说界(2018年5期)2018-11-26
中国交通信息化(2018年5期)2018-08-21
