
基于循环神经网络的中文文本情感分类应用
2021-12-08 13:40刁天宸张俊坤陈尧李炜明
无线互联科技 2021年19期
刁天宸 张俊坤 陈尧 李炜明

摘 要:中文文本情感分类应用是商家面对用户改进产品的一种重要手段。传统机器学习中one hot编码效率低下且向量十分稀疏,维度很高。文章通过词嵌入(word embedding)和循环神经网络(RNN),结合精确筛选的数据集,构建了针对用户评论的中文文本情感分类模型,在亚马孙商品评论数据集以及电影数据集上实验结果表明,使用该分类器,实际预测精度达99.32%,能较好地为商家提供用户情感分类服务,便于商家分析产品反馈。
关键词:循环神经网络;词嵌入;情感分类;中文文本
0 引言
中文文本情感分类是自然语言处理领域中一个重要研究方向。随着信息技术的逐步发展而带动的电子商业的繁荣,面对每天数百万级的用户评论,如何从如此巨大的数据集中,准确分类用户评论情感并提取高价值的信息,成为企业和商家市场调研以及改进产品过程中极为重要的环节[1]。
本文通过词嵌入(word embedding)和循环神经网络(RNN)构建模型,会为中文文本返回0-1之间的情感倾向置信度。置信度越接近1,文本为积极情感可能性越高;置信度越接近0,文本为消极情感可能性越高。
1 相关工作
1.1 数据清洗
数据清洗的根本目的是为了删除重复信息,纠正存在的错误,并保持数据一致性。本文采用亚马逊商城评论数据集、online shopping数据集、豆瓣电影数据集。由于原数据集存在较多缺失值和重复内容,为了保证决策数据的精准性以及模型的预测和泛化能力,需要将这些重复内容和缺失值除去。
1.2 特征提取
特征提取是深度学习的重要步骤,往往好的特征选择能达到更高的精度[2]。为了保证更高的精确度,本文通过机器加人工的方式筛选出情感倾向较为明显的文本作为自定义词典部分内容。筛选后总文本量为522 948行,筛选后的部分文本如表1所示。
1.3 中文词典的构建
由于中文语意主要由词语决定而不是单独的汉字,因此需要对待训练的中文文本进行分词处理,并以此构建词典。
本文字典由数字、英文字母、待训练的中文文本构建。
(1)将Python字典中键0对应的值设为空字符串。
(2)将常用数字,英语字母直接添加至Python字典中,如:1234567890abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ。
(3)将待训练的中文文本分词和去标点。这里使用Python的Jieba中文分词组件。Jieba分词组件为開源分词组件,主要使用动态规划查找最大概率路径,找出基于词频组合的最大切分组合。对未登录词组,采用HMM语言模型[3],以修正分词效果。Jieba分词有4种分词模式,本文采用精确模式对清洗过后的数据集进行分词,相关函数为jieba.cut()。
经如上处理,最终得到字典键值对261 089对,部分字典内容如表2所示。
1.4 中文编码
由于机器不能识别自然语言而只能将向量(数字数组)作为输入数据,因此需要对文本进行向量化(将字符串转为数字),再将其输入模型。传统One-hot的编码得到的向量是二进的、稀疏的,纬度很高。为了规避以上问题,本文采用词嵌入(word embedding)编码方式,这种编码较One-hot编码更加高效且密集,使得相似的词组具有相似的编码,且操作人员不必手动指定编码。
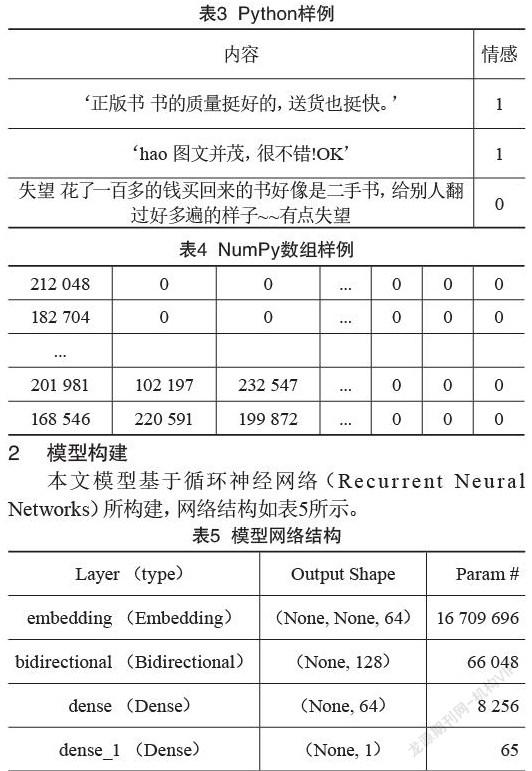
本文编码内容具体如下:(1)将特征提取后的文本保存为Python列表,部分列表如表3所示。(2)对列表中的句子进行分词,并查找词语对应的中文词典索引,将其保存为NumPy数组,部分NumPy数组如表4所示。
2模型构建
本文模型基于循环神经网络(Recurrent Neural Networks)所构建,网络结构如表5所示。
2.1 Embedding层
Embedding层是模型的输入层,是表示一个句子的实数矩阵。Embedding层中每一行表示一个词组向量,行数为一句话中的词组数量。通过统计发现,大多数文本长度未超过400词(因本文设置基准长度为400),将每一条原文文本表示为400×64的实数矩阵。
2.2 Bidirectional层
为了克服常规RNN的限制,本文采用双向神经网络(BRNN)进行训练。BRNN是将传统RNN的状态神经元拆分为两部分,一部分负责positive time direction(forward states),另一部分负责negative time direction(backward states)。由于Forward states的输出并不会连接到Backward states的输入,因此与传统RNN相比,BRNN的结构提供给了输出层输入序列中每一个点的完整的过去和未来的上下文信息,使得在任何时刻都能够获取到所有时刻的输入信息。
3 实验验证
3.1 实验数据
本实验数据由亚马逊商城评论数据集,online shopping数据集,豆瓣电影数据集经处理后构成,总计693 573条,其中训练数据集554 858条,测试数据集138 715条。
3.2 实验结果及分析
经多次实验发现,RNN的迭代次数设置为5轮,模型即可达到最优。模型试验结果如表6所示。
通过表6可以得出,本模型对用户评论情感分类具有较高精确度,能为企业和商家分析产品回馈节约大量时间。
4 结语
中文文本情感分类是在自然领域中很热门的方向,本文中构建了一种基于循环神经网络(RNN)的模型,经测试能较好地对用户评论进行情感分析。
[参考文献]
[1]缪亚林,姬怡纯,张顺,等.CNN-BiGRU模型在中文短文本情感分析的应用[J].情报科学,2021(3):1-6.
[2]张腾,刘新亮,高彦平.基于卷积神经网络和双向门控循环单元网络注意力机制的情感分析[J].科学技术与工程,2021(1):269-274.
[3]宋祖康,阎瑞霞.基于CNN-BIGRU的中文文本情感分类模型[J].计算机技术与发展,2020(2):166-170.
(编辑 姚 鑫)
