
建立药品抽检品种筛选数学模型的设计与探讨
2021-12-07 00:04:26欧淑芬黄卉谭敏
中国药学药品知识仓库 2021年12期
欧淑芬 黄卉 谭敏



摘要:药品抽验是药品监管的重要工具,对日常抽验而言,目前国内尚未有统一的品种筛选指标体系。文章提出了一种适用于数量基数极大的终端药品市场抽验优先顺序的品种筛选数学模型。研究基于对某市2017-2021年药品使用及抽检历史数据的实证分析,运用比例分析法及主、客观赋权法排出抽验品种的优先顺序。该方法经过验证,能科学筛选出群众关注度高的品种,确保药品抽验的代表性。
关键词:药品抽验;模型
【中图分类号】R97 【文献标识码】A 【文章编号】2107-2306(2021)12--03
正文
药品抽验是药品监管的重要工具,是监督和评价上市药品质量的重要手段和方法。目前,我国执行的是国家、省两级抽验制度,部分地市也会拨出专项经费开展本地药品的监督抽验。从组织形式上看,国家药品抽验品种目录由国家制定。省(含部分地市)药品抽验目录由各省市根据市场情况自行制定,作为国家抽验的补充。
在实际执行层面,各省(含部分地市)分散制定的抽验品种目录,在设计上多采用和国家级抽验类似的理念,较多关注的是市场不良反应问题多,稳定性程度较低的品种。以此为依据的抽验结果,虽然能在一定程度上反映当地药品的使用安全情况,把控药品风险,但是由于设计上考虑的因素较为单一,对广大群众关心的市场占有量大的品种,或者市场占有量不大但经济份额较大的治疗重大疾病罕见病药品考虑不足,容易出现重复检验或者抽验盲区,不能全面的反映当地药品使用的质量状况。因此,在有限的政府监管资源情况下,需要建立一个标准化模型,通过科学的方法进行筛选,来确保药品抽验的代表性,使其更有效的发挥监督抽验的效果和影响力。
鉴于此,本文主要通过参照有关文献和其它产品抽验标准设计原理,结合药品特点,从质量、市场及资源等多维度出发,设定指标参数和权重,同时基于对某市2017-2021年药品使用及抽检历史数据的实证分析,结合专业统计学方法,提出构建药品抽验品种筛选数学模型的新方法。
1 研究背景及总体思路
当前,随着我国医改进入深水区,医药行业的格局正发生着深刻的转变。其中,受国家一致性评价、国家、省级带量集中采购、医保目录动态调整等政策影响,药品市场重点品种出现结构性变化。这对监管部门紧跟市场变化、开展针对性监督抽验工作提出了新的要求。更进一步,随着科学监管体系的发展和大数据、数据挖掘技术的不断成熟,在药品各监管领域,对药品不良反应、药品注册审评、药品历史抽验、药品销售等大量数据的互联分析提出了更高要求。如何充分利用这些数据,从中挖掘潜在的具有宝贵价值的信息和影响因素;这些信息或影响因素如何进行定性或定量分析以提高抽验品种筛选的科学性等等,这些问题是构建药品抽验品种筛选模型的重要问题。通过查询文献、专家咨询、以及实证分析,确定设计思路如下:
根据《药品质量抽查检验管理办法》第十一条规定,药品抽检分成两大类,一类为靶向抽检,一类为日常抽检。靶向抽验以确保药品安全重点品种得到有效监管为目的;日常抽验则是针对“临床用量较大、使用范围较广”品种。两种抽验对品种要求不同,靶向抽验品种应尽可能100%覆盖到位,日常抽验则需要进行品种筛选。因此,本研究认为靶向抽验品种可直接从各类药品监管数据中调取。日常抽验由于数据庞杂,适宜通过引入经济性评价指标,综合产品风险等级设置权重建立综合评价模型,按品类对品种进行分层抽验,尽可能覆盖市场主要品种,保障药品安全大局。
2 靶向抽验品种筛选
9类靶向抽验品种均有明确的指向性,整理相关数据来源如下:具体见表1。
3 日常抽验品种筛选模型的建立
日常抽验品种筛选模型是本次研究的重点。对日常抽验而言,目前国内尚未有统一的筛选指标体系,无法保障在终端大量用药基础上,筛选出代表性品种,使其能充分的反映广大人群的關注,确保使用量大、高风险品种的质量始终在监管视线范围内。为了实现科学、系统的排序筛选,模型所建立的指标体系必须具备全面实际性、客观公平性以及科学典型性等特征。基于以上原则,本研究采用的方法为比例分配法以及主、客观赋权法。按药品销售渠道及药品类别进行分层,依据各层级销售比例规模占比确定抽验比例;针对药品使用终端较大的变量,设立评价指标;随后用主观赋权法算出主观权重、客观赋权法的熵值法算出客观权重,然后再用矩阵法得出组合权重;最后用极值法和赋值法加上权重对药品使用终端品种的相关评价指标进行计算,按综合得分排出抽验优先顺序,得到各层主要品种排名,实现科学筛选。
3.1确定分层规则及各层抽验比例
3.1.1按销售渠道分层
受医院和零售药店消费群体购药的差异,将药品市场按不同销售渠道进行分层(见表2),具体制定抽检计划时,可根据销售渠道的不同,选取对应的抽验环节。
3.1.2按药品类别分层
西药(含化学药品、生物制品)、中成药、中药饮片在不同销售渠道销售使用特性不一,且不同大类之间数量存在不可比因素,故在将产品按照西药(含化学药品、生物制品)、中成药、中药饮片三大类,也保持和医保统计口径一致。结合医院和零售药店销售渠道,共分为五层,分别为医院渠道西药、医院渠道中成药、零售渠道西药、零售渠道中成药、零售渠道中药饮片。
3.1.3确定各层抽验比例
比例分配法是抽验实际工作中最常用的确定每层抽取样本容量的方法。考虑到中药饮片与西药、中成药的数量计算单位不同,医院渠道与零售药店渠道药品规格的不同,难以用数量指标计算各层比例。故使用各层销售额规模大小的比例作为确定各层抽取样本比例参考,利用某市药品使用终端销售数据进行测算,得表3:
3.2确定抽验品种筛选模型指标
综合“临床用量较大、使用范围较广”以及产品风险等级要求,分析药品使用终端变量以及数据可获取性,初步确定以临床使用的产品数量,产品金额、是否国家集中采购品种,是否是医保品种为评价指标。利用某市药品使用终端的销售数据分别对4个评价指标进行测算,经验证,是否医保品种与其他指标出现高度重复情况,因此,最终确定以临床使用的产品数量,产品金额、是否国家集中采购品种为评价指标。
3.3确定抽验品种筛选模型指标权重
综合评价是指对多指标体系结构描述的对象系统做出全局性、整体性的评价。在综合评价中,需要确定每个指标的权重,即该指标在整体评价中的相对重要程度,权重越大则该指标的重要性越高,对整体的影响就越高。确定指标重要性的赋权方法有很多,但从大范围上来看,可以分成两大类:主观赋权和客观赋权。
主观赋权法是根据专业知识、时间经验通过主观分析研究后确定各个评价指标的重要权数的方法,如序关系分析法,该方法不受样本采集的限制,且原理简单、操作灵活。但其缺点是容易根据自身的主观意愿和偏好来确定指标的重要性,指标权重易受个人学识、经验、习惯等因素影响。
客观赋值法来源于客观实际,是根据指标所提供的信息量大小和相互关联程度来确定指标权重的方法。熵值法,是最具代表性的一种客观赋权法。其原理是通过熵值大小测度已知指标数据的有效信息量并进一步计算出权重,即通过评价对象给的指标差异程度来确定各项指标的权重。熵值法的优点是完全依靠指标的样本观测值自身的信息来判断指标的有效性和重要性,不受人为因素的干扰,可以依据客观实际对系统作出客观、公正的评价。该方法的缺点是容易受样本观测值差异性大小的影响,造成客观赋权时产生误差,出现某个重要性指标权重很小,非重要性指标权重很大的现象。
为减弱主观因素对序关系分析法赋权的干扰,亦可以弱化因样本数据不足导致的熵值法赋权产生偏差的问题,得到更为客观和合理的指标权重,本研究建立了基于序关系分析法和熵值法的动态组合赋权模型,以下为其计算步骤:
3.3.1 序关系分析法计算主观权重w
3.3.1.1 确定序关系及各指标权重比值r
假定有n个评价指标,已知X重要性最小,重要性程度r=1,以其为基准进行两两比较,设评价指标X(n=1,2,j,…,n)相对于某评价目标的重要性程度大于(或不小于)X,则评价指标X,X,X,…,X之间确立了序关系。并按照排序结果,对各指标赋予分值,基于专家关于评价指标X与X的重要性程度之比X/X的理性判断,即各指标与重要性最小的指标的权重比值为r=X/X(3-1)
3.3.1.2 权重系数wn的计算
当r的理性赋值满足关系式(3-1)时,则
w=r/(r+r+r+…+r)
本研究組织10位专家对3个指标进行赋值打分根据产品数量、产品金额、是否国家医保目录品种3个指标对筛选日常抽检中“临床用量较大、使用范围较广”品种的重要程度,通过两两比较的方法确定3个指标的排序,并将10位专家对3个指标的赋值进行算数平均值计算得出各指标的主观权重系数w。
3.3.2 熵值法计算客观权重V
根据熵的特性,采用熵值来判断某个指标的离散程度,指标的离散程序越大,该指标对综合评价的权重越大。同时,根据信息熵定义,计算各指标的信息熵和信息效用,并最终计算出每个指标的熵权重。
3.3.2.1 建立评价矩阵
假设评价指标体系中含有m个评价样本,n项评价指标,用n个指标作综合评价的问题,可根据样本观测数据建立原始的评价矩阵,其中X为第m个评价样本在第n项指标上的状态值(m=1,2,i,…,m;n=1,2,j,…,n)。
3.3.2.2数据标准处
由于不同的评价指标衡量的事物性质不同,导致指标之间存在度量即数量级差异,降低了数据的可比性,为了尽可能的反映实际情况,消除各项指标的度量及数量级间的悬殊差异带来的影响,避免不合理现象的发生,本研究基于极值处理法将各指标归一化到[0,1]区间,并以此计算指标信息熵、信息效用及权重系数,得:
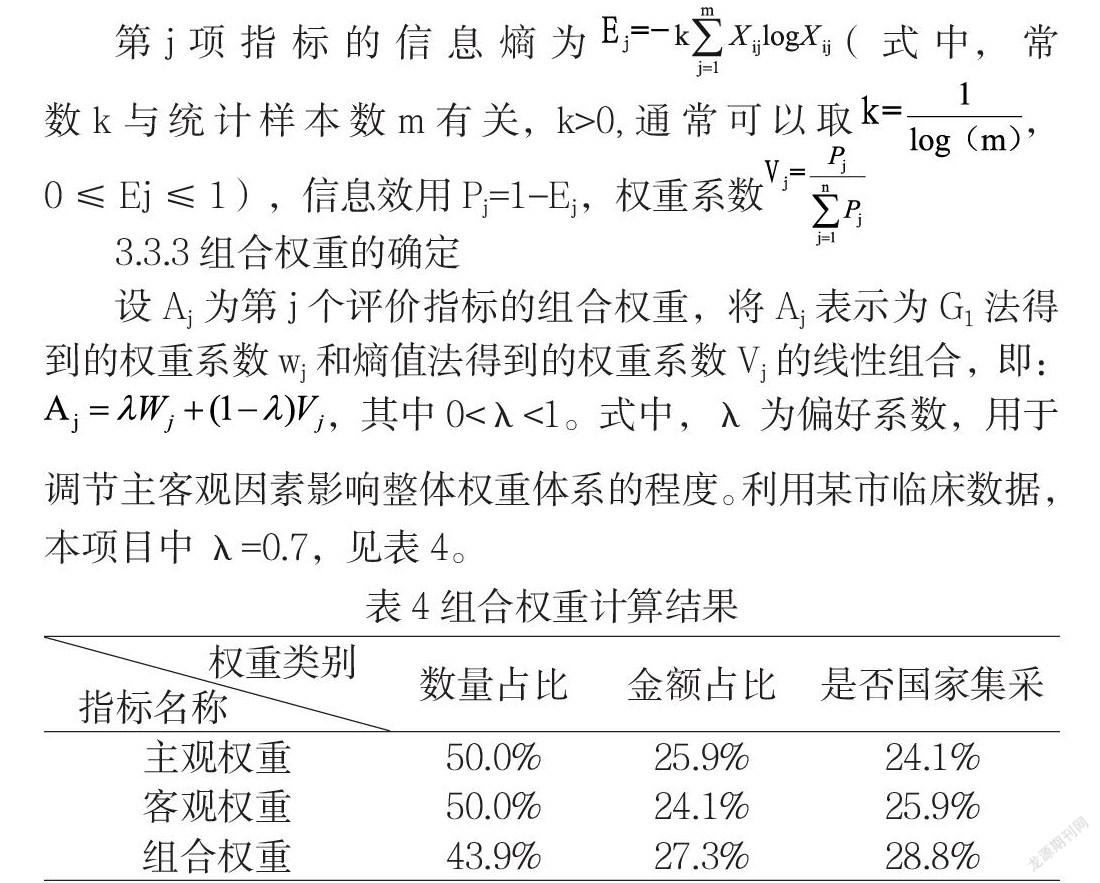
第j项指标的信息熵为(式中,常数k与统计样本数m有关,k>0,通常可以取,0≤Ej≤1),信息效用P=1-E,权重系数
3.3.3 组合权重的确定
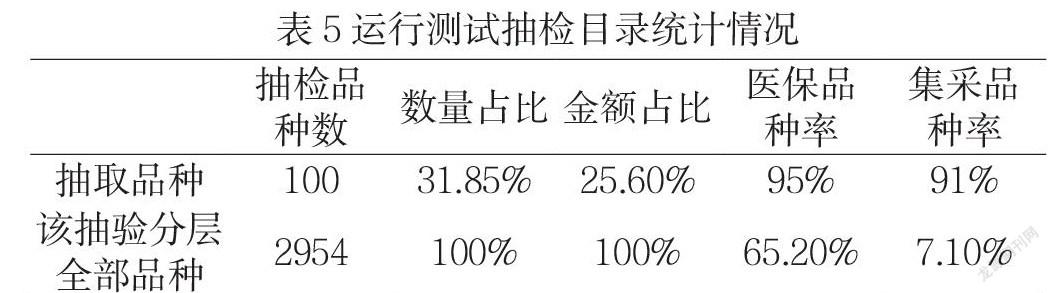
设A为第j个评价指标的组合权重,将A表示为G法得到的权重系数w和熵值法得到的权重系数V的线性组合,即:,其中0<λ<1。式中,λ为偏好系数,用于调节主客观因素影响整体权重体系的程度。利用某市临床数据,本项目中λ=0.7,见表4。
3.4计算各产品的综合得分
3.4.1指标描述:
(1)数量占比:A产品在其抽验分层中数量占比=A产品采购数/广州市样本医院该分层采购总数;
(2)金额占比:A产品在其抽验分层中金额占比=A产品采购额/广州市样本医院该分层采购总额;
(3)是否国家集采:以国家药品集中采购“4+7”、联盟采购(“4+7”扩面)、第二批、第三批、第四批、第五批的品种目录为标准,区分是否国家集采品种;
3.4.2指标得分计算方式:
(1)通过极值法对产品数量占比和金额占比数据进行标准化处理,归至0-1之间。
(2)按相关要求,国家集采品种要求100%抽检,非国家集采品种没有强制要求,即可能抽检又可能不抽检,故设定国家集采品种分值为1,非国家集采品种为0.5。
(3)计算三项指标分值的加权总分。为了便于数值观察,将最终得分放大100倍。
4 日常抽验品种筛选模型运行测试及结果分析
依据本研究确定的抽验品种筛选模型,分别对某市医院渠道销售西药、中成药以及零售药店渠道销售的西药、中成药、中药饮片各层产品计算综合得分,按综合得分排出抽验优先顺序。以各层中销售规模占比最大的医院渠道西药产品为例,在抽取排名前100的品种时,所抽产品的统计情况如下(见表5):
结论:
(1)筛选模型显示:在抽取了医院渠道西药中全部品种的3.4%的情况下,该模型覆盖了抽验分层31.85%的品种数量和25.60%的品种金额;筛选出的100个品种中,医保品种率为95%,国家集采品种率为91%。表明该模型可以较好地筛选出“临床用量较大、使用范围较广的”重点品种,并兼顾医保与国家集采品種。
(2)通过指标筛选与测算,该模型筛选出来的品种中,其加权总分排名在“医院渠道销售西药”下前30的品种中有7个是该市近五年抽检未覆盖到的品种,如抗肿瘤和免疫调节剂类的注射用培美曲塞二钠、甲磺酸奥希替尼片、替莫唑胺胶囊、多西他赛注射液、聚乙二醇化重组人粒细胞刺激因子注射液,血液和造血系统药物利伐沙班片、消化系统及代谢药盐酸帕洛诺司琼注射液。这7个品种均为重症疾病治疗药物,显示该模型加入经济性指标进行权重测算后,较以往的品种选取方式更具科学性和代表性,以此为基础的药品监督抽验工作可以更准确的反映地区药品安全水平,有助于实现有效监管。
参考文献:
[1]张礼智,一种面向药品靶向抽检的预测模型[J].中国医药导刊,2020,22(12):883-888.
[2]罗曦,国家食品抽检数据分析挖掘系统研建[D].北京林业大学,2018.
[3]张士侠,大数据在药品监管领域的应用研究[J].中国医药导刊,2017,19(12):1412-1416.
[4]汪海萍,药品大数据的数据挖掘研究[J].信息与电脑,2019(24):110-112.
猜你喜欢
华人时刊(2022年9期)2022-09-06 01:02:32
中国西部(2022年2期)2022-05-23 13:28:20
出版人(2021年11期)2021-11-25 07:34:04
南大法学(2021年6期)2021-04-19 12:27:30
当代陕西(2020年17期)2020-10-28 08:18:18
活力(2019年15期)2019-09-25 07:22:12
测控技术(2018年6期)2018-11-25 09:50:24
人大建设(2018年5期)2018-08-16 07:09:00
电信科学(2017年6期)2017-07-01 15:44:57
营销界(2015年29期)2015-02-27 02:38:32
