
基于混合密码的互联网大数据隐匿性特征提取研究
2021-12-07 07:45:46赵放,任远
电子设计工程 2021年23期
赵 放,任 远
(1.西安工程大学科技处,陕西西安 710048;2.陕西工商职业学院中瑞旅游与酒店管理学院,陕西西安 710075)
混合密码可在对称密码条件下,对数据消息加密处理,由于所使用编码密钥的长度值始终小于消息数据样本长度,因此由公钥密码加密产生的转码速率条件可以直接忽略不计。通常情况下,混合密码的生成需要公钥密码、对称密码、伪随机数生成器的共同配合,且在同一转码时间内,三者必须同时保持高强度连接状态[1-2]。在公钥密码与对称密码同时存在的情况下,前者的转码强度必须时刻高于后者。
在互联网应用环境中,随着信息覆盖面积的增大,一部分大数据文件会出现明显的隐匿性特征[3]。为获得准确的文件信号管控与识别结果,传统AEC编码型提取手段借助公钥密码体系对大数据参量进行处理,再通过串行加密的形式,实现对信息文件的整合与调用。但该方法不具备顺、逆向信息转存同步执行的能力,很难实现对已隐藏大数据信息参量的精准提取。为解决该问题,引入混合密码原理,搭建一种新型的互联网大数据隐匿性特征提取模型,在公钥密码组、数字签名、样本数据库模块等多个执行处理条件的作用下,建立必要的隐匿递归算法,再通过对比实验的方式,突出该模型的实际应用价值。
1 基于混合密码的互联网大数据传输环境
基于混合密码的互联网大数据传输环境由公钥密码组、数字签名、摘要函数3 部分共同组成,具体搭建方法如下。
1.1 公钥密码组
公钥密码组是一个完整且独立的大数据信息转码依据文件,由于保密度等级水平相对较高,因此该文件可被直接应用于互联网数字签名结构体之中。在互联网存储能力相对较大的情况下,大数据信息的待转存数量级水平越高,与之匹配的公钥密码组编码能力也就越强[4-5]。设α0代表互联网环境下最小的公钥密码传输系数,αn代表互联网环境下最大的公钥密码传输系数,一般情况下,公钥密码定义量n的取值结果越大,最终计算所得的公钥密码组完整性程度也就越高。联立上述物理量,可将基于混合密码的公钥密码组结果定义为ω:

式中,λ1代表公钥密码取值为1 时的大数据原解码参量,λn代表公钥密码取值为n时的大数据原解码参量,代表理想情况下的互联网大数据转码均值,代表实际的互联网大数据转码均值。
1.2 数字签名
数字签名是存在于互联网环境中的大数据信息特征参考条件,随公钥密码组定义原则的不同,最终所得到的数字签名连接形式也会有所改变。若不考虑其他数值指标对互联网数字签名形态的干扰,则这种连接协议的接入权限只受到混合密码传输周期、大数据参量隐藏显示比两项物理条件的直接影响[6-7]。混合密码传输周期常表示为,大数据参量隐藏显示比常表示为β,该项物理量可被看作隐藏大数据与显示大数据间的数值比例,一般情况下,会随着传输大数据总量的提升而出现明显的数值增大状态。在上述物理量的支持下,联立公式(1),可将基于混合密码的互联网数字签名条件定义为Q:

1.3 摘要函数
由于数字签名必须依赖于效率非常高的混合密码公钥编译机制,且通过这种手段验证互联网大数据完整性在实际应用中极难实现,因此通过抽取数据摘要的方式,建立完整的数字签名结构十分必要,而实现数据摘要的抽取需采用摘要型函数[8-9]。摘要函数为一种满足哈希调取关系的数据处理行为,可在已知数字签名存储形式的基础上,确定与函数主体相关的大数据特征隐匿性存储标准,从而实现对固有特征值的提取与处理[10]。设s0代表与互联网数字签名相关的最小哈希调取系数,sn代表与互联网数字签名相关的最大哈希调取系数,δ代表固有的大数据隐匿性特征参量值,联立公式(2),可将基于混合密码的摘要函数定义为R:

式中,D1代表已输入的第一个大数据隐匿性特征指标,Dn代表已输入的第n个大数据隐匿性特征指标,代表D1与Dn的平均数值。
2 互联网大数据隐匿性特征提取
在混合密码原则的支持下,按照样本数据库模块搭建、大数据主成分分析、隐匿性递归算法实施的处理流程,完成互联网大数据隐匿性特征提取模型的设计。
2.1 样本数据库模块
样本数据库模块由分类样本数据库、全量样本数据库两部分共同组成。其中,分类样本数据库能够区分混合密码信号的现有连接形式,并可在明确各类型数据样本存储能力的同时,对互联网环境中的大数据信息进行分类调度与调节[11]。全量样本数据库中包含多个不同的业务表单结构,可在分析样本数据源信息的同时,对大数据隐匿性特征进行区分与查询,再按照既定规则条件,完善原有的混合密码样本,从而使互联网主机对于大数据参量的特征提取需求得以满足。简单来说,在混合密码编译条件的作用下,分类样本数据库与全量样本数据库两者相互作用,对互联网传输环境进行合理化的构建与平衡[12]。

图1 样本数据库模块结构图
2.2 大数据主成分分析
大数据主成分分析在对隐匿性特征进行提取时,需要将混合密码矩阵拉成一个行向量或一个列向量。通常情况下,这类一维向量矩阵的维数值相对较大,不仅会增加大数据主成分分析的运算负担,也会削弱互联网大数据的实际存储能力,从而造成隐匿性特征值的丢失。基于此,为减轻大数据主成分在特征值提取时的计算处理量,可在建立混合密码协方差矩阵的同时,确定互联网大数据信息所占据的存储空间,再通过计算信息复杂度权限的方式,得到准确的大数据主成分分析结果[13-14]。设z0代表最小的混合密码矩阵向量,zn代表最大的混合密码矩阵向量,联立公式(3),可将互联网大数据主成分分析结果表示为L:

其中,j1代表第一个互联网大数据隐匿性特征的位置信息,jn代表第n个互联网大数据隐匿性特征的位置信息,χ代表特征值提取权限量,ΔH代表混合密码编译信息在单位时间内的传输变化量。
2.3 隐匿性递归算法
隐匿性递归算法的建立是基于混合密码互联网大数据隐匿性特征提取模型设计的末尾处理环节,可在已知大数据主成分分析结果的基础上,对大数据特征的提取原则进行集中性归纳,再根据既定的密码编译理论,对这些信息参量进行转录与存储处理[15]。在不考虑其他干扰条件的情况下,隐匿性递归算法的构建标准只受到编译性行为指标、互联网信息存储参量两项物理指标的直接影响[16]。其中,编译性行为指标可表示为μ,在既定数据存储时间内,该项物理量的实际数值水平越高,最终归纳得出的隐匿性递归算法原则也就越完善。互联网信息存储参量可表示为C,一般情况下,该项物理量与隐匿性递归算法建立结果保持反比影响关系,即存储参量值越大,递归算法的应用能力也就越弱,反之则越强。在上述物理量的支持下,联立公式(4),可将隐匿性递归算法原则定义为V:
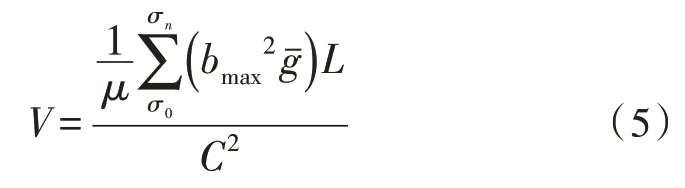
式中,σ0代表最小的大数据密码编译指标,σn代表最大的大数据密码编译指标,bmax代表待提取的大数据隐匿性特征最大值,代表混合型编译密码的解码均值量。至此,完成各项系数应用指标的计算与处理,在混合密码原则的支持下,实现互联网大数据隐匿性特征提取模型的设计与搭建。
3 实验设计与结果分析
为验证基于混合密码互联网大数据隐匿性特征提取模型的设计应用价值,设计如下对比实验。搭建如图2 所示的互联网实验环境,分别将实验组编码主机与对照组编码主机接入服务器应用平台之中,其中实验组编码主机搭载基于混合密码互联网大数据隐匿性特征提取模型,对照组编码主机搭载AEC 编码型提取手段,在大数据输入量趋于稳定的情况下,分析各项实验指标的实际变化情况。

图2 互联网实验环境
已知顺、逆向信息转存效率均能反映互联网主机对于已隐藏大数据信息参量的精准化提取能力,一般情况下,顺、逆向信息转存效率越高,互联网主机对于已隐藏大数据信息参量的精准化提取能力也就越强,反之则越弱。表1、表2 分别记录了实验组、对照组顺、逆向信息转存效率的具体数值变化趋势。

表1 顺向信息转存效率对比表
分析表1 可知,在实验过程中,实验组顺向信息转存效率始终保持不断上升的变化趋势,全局最大值达到了91%。对照组顺向信息转存效率在实验前期一直不断上升,而从第40 min 开始,这种变化趋势逐渐趋于稳定,全局最大值仅能达到65%,与实验组极大值相比,下降了26%。综上可知,应用基于混合密码互联网大数据隐匿性特征提取模型后,顺向信息的转存效率值得到有效促进,可增强联网主机对于已隐藏大数据信息参量的精准化提取能力。
分析表2 可知,随着实验时间的延长,实验组逆向信息转存效率在一段时间的稳定状态后,开始不断上升,全局最大值达到了96%。对照组逆向信息转存效率则始终保持不断下降的变化趋势,全局最大值仅能达到56%,与实验组极值相比,下降了40%。综上可知,应用基于混合密码互联网大数据隐匿性特征提取模型后,逆向信息转存效率开始不断增大,完全满足增强联网主机对于已隐藏大数据信息参量的精准化提取能力的实际应用需求。

表2 逆向信息转存效率对比表
4 结束语
与AEC 编码型提取手段相比,基于混合密码互联网大数据隐匿性特征提取模型所具备的顺、逆向信息转存效率值更高,在公钥密码组、数字签名等执行条件的作用下,样本数据库模块可在分析大数据主成分的同时,建立隐匿性递归算法,能够较好地实现编码主机对于文件信号的管控与识别处理。
猜你喜欢
网络安全技术与应用(2020年9期)2020-09-17 01:45:44
信息通信技术(2018年6期)2019-01-18 05:21:28
信息安全研究(2016年3期)2016-12-01 06:06:39
衡阳师范学院学报(2016年3期)2016-07-10 07:16:27
信息安全研究(2016年11期)2016-02-10 03:21:41
医学研究杂志(2015年11期)2015-06-10 06:44:03
肝胆胰外科杂志(2015年5期)2015-02-27 11:12:43
中国卫生标准管理(2015年7期)2015-01-27 05:24:31
华东师范大学学报(自然科学版)(2014年1期)2014-04-16 02:54:52
中国中医药现代远程教育(2014年15期)2014-03-01 04:27:54
